ComfyUI + SVD 系列(三):最小图生视频工作流拆解------节点含义、输入输出、参数作用与核心实验
1. 写在前面
上一篇已经把 ComfyUI + SVD 的环境装好了,也已经成功跑通了一个最小的单图生成视频工作流。
但如果只是"照着图把节点连起来",其实还不算真正学会。
对新手来说,更关键的问题通常是:
- 这个节点到底是干什么的?
- 它为什么有这些输入口?
- 为什么它会输出这些东西?
- 为什么这个输出一定要接到下一个节点?
- 参数改了以后,到底会发生什么?
- 为什么最后看起来主要是主体在动,而不是整个场景都在动?
这篇文章就专门解决这些问题。
这次不再只是讲"怎么做",而是要进一步讲清楚:
这套最小 SVD 图生视频工作流,为什么要这么搭。
同时实验了一个失败的视频生成,想想为什么会这样
视频地址:直接看B站视频地址
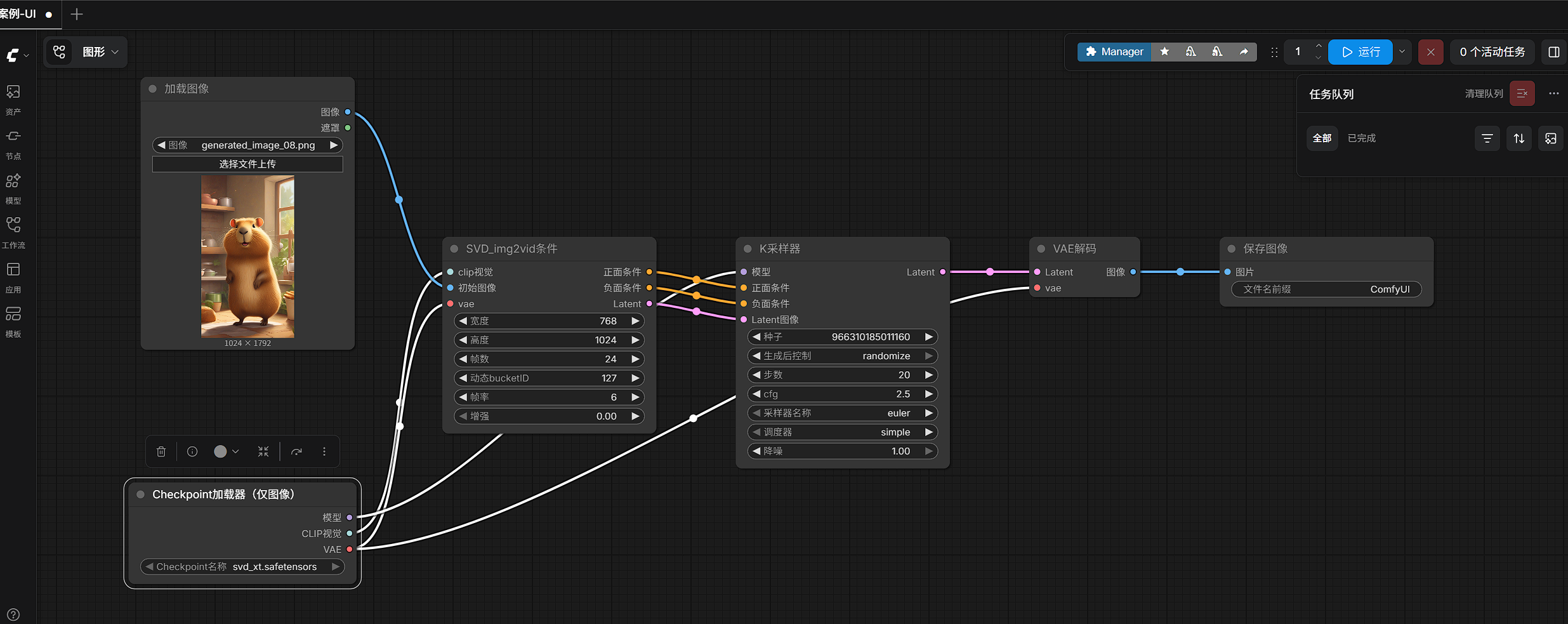
2. 先看当前已经跑通的工作流
当前这套最小工作流使用的输入图片是:
text
generated_image_08.png使用的模型是:
text
svd_xt.safetensors工作流中的核心节点包括:
LoadImageImageOnlyCheckpointLoaderSVD_img2vid_ConditioningKSamplerVAEDecodeSaveImage
从整体上看,这条链路做的事情并不复杂:
- 先把输入图片读进来
- 再把 SVD 模型加载进来
- 把"图片 + 视频参数"整理成可生成视频的条件
- 交给采样器执行生成
- 把 latent 结果解码成图片
- 最后保存成图片序列
如果用最简单的话来讲,它就是:
输入一张图,输出 24 张连续帧图片。
3. 当前工作流的核心参数
在理解节点之前,先把当前已经跑通的基线参数列出来。
因为后面你不管做实验,还是理解现象,都要回到这一组参数上。
3.1 输入图片
当前输入图片为:
text
generated_image_08.png3.2 模型
当前加载的模型为:
text
svd_xt.safetensors3.3 SVD 条件节点参数
SVD_img2vid_Conditioning 当前参数为 :
width = 768height = 1024video_frames = 24motion_bucket_id = 127fps = 6augmentation_level = 0
3.4 KSampler 参数
KSampler 当前参数为 :
seed = 966310185011160steps = 20cfg = 2.5sampler_name = eulerscheduler = simpledenoise = 1
3.5 输出参数
输出通过 SaveImage 节点保存,前缀为:
text
ComfyUI也就是说,最终会得到类似这样的文件:
text
ComfyUI_00001_.png
ComfyUI_00002_.png
...
ComfyUI_00024_.png4. 每个节点到底是干什么的:从输入、输出和职责三个角度理解
这一节是全文最重要的部分。
因为如果这一节理解了,后面你就不只是"照着图搭工作流",而是开始真正理解:
- 节点在整条链路里的位置
- 输入为什么要接这里
- 输出为什么要送到那里
4.1 LoadImage:把输入图片读进工作流
这个节点的作用最简单,但必不可少。
它的输入是什么?
它没有外部输入口。
因为它本身就是用来"读取文件"的,你只需要在节点内部选一张图片就行。
当前节点里读取的是:
text
generated_image_08.png它的输出是什么?
它会输出两个结果 :
IMAGEMASK
在你当前这条最小工作流里,真正用到的是:
IMAGE
也就是"已经读进工作流的一张图片"。
为什么要有这个输出?
因为后面的 SVD 图生视频流程,必须先知道:
这次要基于哪一张图来生成视频。
如果没有这个输出,后面的条件节点就没有"初始图像"。
为什么这个输出要接到 SVD_img2vid_Conditioning?
因为你现在做的是 单图生成视频 。
所以这张图必须送到:
SVD_img2vid_Conditioning.init_image
它的作用就是:
告诉模型,后面的视频帧应该围绕这张图来生成。
4.2 ImageOnlyCheckpointLoader:把 SVD 模型加载进来
这个节点是模型入口。
它的职责不是读图片,而是把图生视频模型准备好。
它的输入是什么?
它也没有外部输入口。
你只需要在节点里选择一个模型文件。
当前加载的是:
text
svd_xt.safetensors它的输出是什么?
它会输出三个关键对象 :
MODELCLIP_VISIONVAE
这里很多新手第一次看到会比较懵,觉得:
- 为什么一个节点会输出这么多东西?
- 这些输出分别用来干嘛?
可以先这么理解:
MODEL
这是真正负责生成视频帧 的主模型。
后面的 KSampler 要用它来执行采样 。
CLIP_VISION
这是视觉条件信息 。
它帮助模型理解图片里"是什么内容",所以会送给 SVD_img2vid_Conditioning 。
VAE
这是图像和 latent 之间转换需要用到的组件 。
后面条件构造和解码都要用它 。
为什么要有这三个输出?
因为后面的节点做的事情不一样:
KSampler需要主模型MODELSVD_img2vid_Conditioning需要视觉信息CLIP_VISION和VAEVAEDecode也需要VAE
所以这个节点的作用不是"简单读一个模型文件",而是:
把模型拆成后面各节点需要的几部分。
4.3 SVD_img2vid_Conditioning:把图片和视频参数整理成生成条件
这是这条最小工作流里最关键的节点之一。
可以用一句话来理解它:
它负责把"输入图片 + 模型信息 + 视频参数"整理成采样器能真正使用的条件。
它的输入是什么?
它接收三个输入 :
clip_visioninit_imagevae
分别来自:
ImageOnlyCheckpointLoader.CLIP_VISIONLoadImage.IMAGEImageOnlyCheckpointLoader.VAE
为什么需要这三个输入?
init_image
因为这是图生视频,不是纯文本生成。
所以必须先告诉模型:
后面的视频是基于哪一张图来生成。
clip_vision
因为模型不只是看像素,它还需要更抽象的视觉理解信息。
这就是为什么要把 CLIP_VISION 喂进来 。
vae
因为后续的视频生成是围绕 latent 表示展开的,vae 在这个转换过程中要参与 。
它的输出是什么?
它会输出三个结果 :
positivenegativelatent
positive
可以先把它理解成:
告诉采样器:应该朝什么方向生成。
negative
可以理解成:
告诉采样器:尽量避开什么方向。
latent
可以理解成:
采样器真正开始工作的起点。
为什么要有这三个输出?
因为后面的 KSampler 不是拿到图片就能直接开工。
它需要:
- 应该遵循的条件(
positive) - 应该避免的条件(
negative) - 起始 latent(
latent)
所以这个节点的作用就是:
把前面的图片和模型信息,变成采样器真正能用的"生成条件包"。
当前这个节点里设置了哪些参数?
当前参数是 :
width = 768height = 1024video_frames = 24motion_bucket_id = 127fps = 6augmentation_level = 0
这些参数分别控制:
- 输出分辨率
- 输出总帧数
- 播放速度
- 动态强弱
- 输入图保真和变化之间的平衡
4.4 KSampler:真正开始生成的地方
如果说前面的节点都在做准备工作,
那 KSampler 就是:
正式开始生成视频帧 latent 的地方。
它的输入是什么?
它接收四个输入 :
modelpositivenegativelatent_image
分别来自:
ImageOnlyCheckpointLoader.MODELSVD_img2vid_Conditioning.positiveSVD_img2vid_Conditioning.negativeSVD_img2vid_Conditioning.latent
为什么它需要这么多输入?
因为采样器不能"凭空生成",它必须同时知道:
1)用哪个模型生成
也就是:
model
2)朝什么方向生成
也就是:
positive
3)尽量避开什么
也就是:
negative
4)从哪个 latent 起步
也就是:
latent_image
少任何一个,采样都没法完整进行。
它的输出是什么?
它输出的是:
LATENT
注意,这里输出的还不是图片,而是生成好的 latent 结果。
为什么输出的不是图片?
因为在扩散模型里,采样器处理的是 latent 表示。
你可以把它理解成:
视频帧的核心内容已经算出来了,但还没翻译成肉眼能直接看的图片。
当前这个节点里设置了哪些参数?
当前参数如下 :
seed = 966310185011160steps = 20cfg = 2.5sampler_name = eulerscheduler = simpledenoise = 1
这些参数主要影响:
- 随机性
- 生成耗时
- 约束强度
- 采样策略
4.5 VAEDecode:把 latent 还原成真正图片
这一节是很多新手第一次最不理解的地方:
为什么
KSampler后面还要接一个VAEDecode?
原因很简单:
因为 KSampler 输出的是 latent,不是图片。
它的输入是什么?
它接收两个输入 :
samplesvae
其中:
samples来自KSamplervae来自ImageOnlyCheckpointLoader
为什么还要再喂一个 vae?
因为 latent 不是普通图像,它必须通过 VAE 才能被解码回真实图片 。
它的输出是什么?
它输出的是:
images
也就是说,到这一步,你才真正拿到了能看的图片帧。
为什么要有这个输出?
因为后面的 SaveImage 节点只能保存图像,不能保存 latent。
所以 VAEDecode 的职责就是:
把模型内部结果翻译成真正的图片。
4.6 SaveImage:把图片帧真正保存下来
这是整条工作流的最后一步。
它的输入是什么?
它接收:
images
这个输入来自:
VAEDecode.images
它的输出是什么?
它没有继续给别的节点输出。
因为它已经是终点了。
它真正的"输出"是:
磁盘上的 PNG 文件。
为什么要有这个节点?
因为如果没有它,前面即使生成成功了,也不会真正落成文件。
也就是说:
- 你在内存里完成了一次推理
- 但结果没有保存下来
当前输出是什么样?
当前前缀是:
text
ComfyUI所以最终会生成类似:
text
ComfyUI_00001_.png
ComfyUI_00002_.png
...
ComfyUI_00024_.png5. 为什么当前结果看起来主要是主体在动
这个问题特别重要,因为你已经实际观察到了这个现象:
- 输入图像里主体是动物
- 输出结果里明显是主体在动
- 背景变化不明显
这个现象其实很正常,而且和当前工作流配置是吻合的。
5.1 当前工作流没有做局部运动控制
你现在的最小工作流只有基础 6 个节点 ,并没有加入:
- 遮罩
- 局部控制
- 景深控制
- 镜头路径控制
所以模型不是"指定让某个地方动",而是:基于整张图生成一段最合理的短时序变化。
5.2 主体是整张图里最显眼的区域
当前输入图里,动物就是画面中心,主体特别明确。
模型通常会优先让最容易形成"生命感"的区域动起来,比如:
- 头部
- 嘴巴
- 身体轮廓
- 姿态轻微摆动
所以你第一眼会觉得:主要是主体在动。
5.3 当前参数更偏向"主体轻动态、背景稳定"
当前关键参数是 :
motion_bucket_id = 127augmentation_level = 0
这组参数更偏向:
主体轻微动起来,但背景尽量不要乱。
所以背景很多时候不是完全不变,而是变化很弱,比如:
- 光影轻微变化
- 边缘细节轻微重绘
- 很弱的"呼吸感"
如果不逐帧盯着背景固定区域看,很容易忽略。
6. 新手最值得先做的三个实验
这一节建议一定保留。
因为对小白来说,最重要的不是一次看懂所有参数,而是:
先用少量关键实验建立感觉。
实验 1:修改 video_frames
当前基线:
text
video_frames = 24建议试三组:
142432
观察什么?
- 视频是不是更长了
- 生成耗时是不是明显变长了
- 后半段是否更容易不稳
本次设置为48,生成的图片就开始飘了

这组实验能学会什么?
你会真正理解:
帧数控制的是视频长度和生成成本。
实验 2:修改 fps
当前基线:
text
fps = 6建议试三组:
468
观察什么?
- 播放是不是更慢或更快
- 视频节奏是否自然
- 当前素材最适合哪一个 fps
这组实验能学会什么?
你会真正理解:
fps 控制的是播放节奏,而不是生成内容多少。
实验 3:修改 motion_bucket_id
当前基线:
text
motion_bucket_id = 127建议试四组:
6496127180
观察什么?
- 主体是不是更明显在动
- 背景是不是也更容易变化
- 是否更容易漂移或失真
这组实验能学会什么?
你会真正理解:
动态强度增强,不一定等于效果更好;很多时候稳定的轻动态更有价值。
综合实验
text
motion_bucket_id = 63
video_frames = 48
fps = 8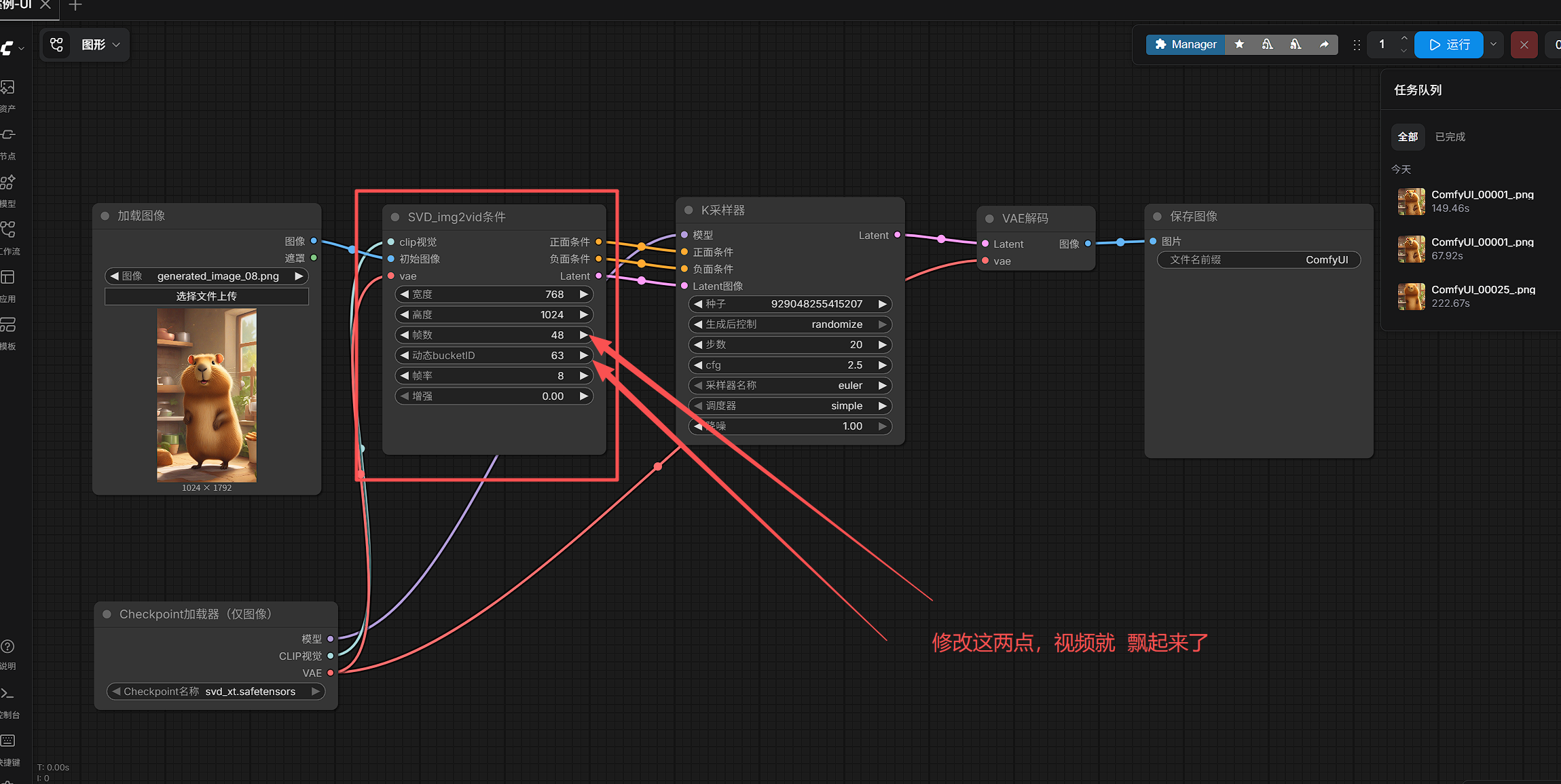
视频地址:直接看B站视频地址
7. 这一篇真正要学会什么
这一篇最重要的,不是死记节点名字。
真正要学会的是下面这些最基础的判断:
LoadImage:把输入图送进工作流ImageOnlyCheckpointLoader:把模型拆成后面要用的几个部分SVD_img2vid_Conditioning:把图像和参数整理成视频生成条件KSampler:真正开始生成VAEDecode:把 latent 还原成图片SaveImage:把结果保存到磁盘
只要这些逻辑真正明白了,后面再去做:
- 改参数
- 保存工作流
- 导出 API JSON
- 用 Python 调 ComfyUI
都会顺很多。
8. 本文小结
当前这套最小 SVD 图生视频工作流使用:
- 输入图片
generated_image_08.png - 模型
svd_xt.safetensors
核心节点包括 :
LoadImageImageOnlyCheckpointLoaderSVD_img2vid_ConditioningKSamplerVAEDecodeSaveImage
其中:
LoadImage负责读图ImageOnlyCheckpointLoader负责读模型并输出MODEL / CLIP_VISION / VAESVD_img2vid_Conditioning负责把图片和视频参数组织成生成条件KSampler负责采样生成 latentVAEDecode负责把 latent 解码成图片SaveImage负责把图片保存到磁盘
同时,通过对现象的分析也可以看出:
在当前参数下,结果更偏向"主体轻动态、背景尽量稳定",所以很多时候看起来主要是主体在动。