如果你正在寻找一种通过 API 将 PDF 文档转换为文本进行交互的方案,不妨看看这款最近颇受欢迎的 Markdown 转换工具------MarkItDown
MarkItDown 是什么
MarkItDown 是一个轻量级的 Python 工具,用于将各种文件转换为 Markdown,以便与 LLM 和相关的文本分析管道一起使用。如下图所示:
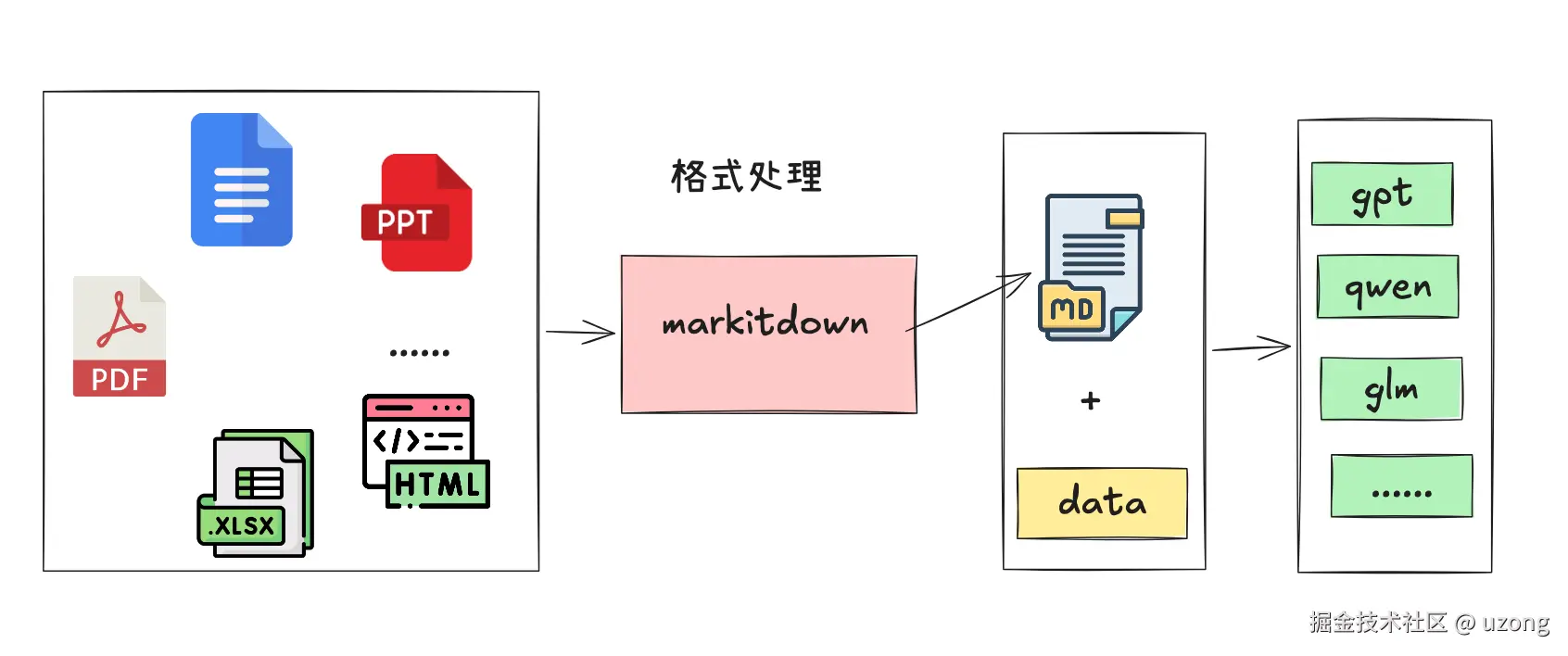
目前markitdown 支持的转换格式(截止2026.4.14):
PDF、PowerPoint、Word、Excel、Images (EXIF metadata and OCR)、Audio (EXIF metadata and speech transcription)、HTML、Text-based formats (CSV, JSON, XML)、ZIP files (iterates over contents)、Youtube URLs、EPubs
注意事项:专注于将重要的文档结构和内容保留为 Markdown(包括:标题、列表、表格、链接等)。 注意这个工具不能实现像预览工具那样,实现文档的高保真还原(包括样式、版式等)。
如果有这个能力,在很多地方都有不错的应用场景。
- RAG 转换各种文档
- PDF 内容加入到上下文对话
- ......
补充一下为什么是 Markdown 格式
格式非常接近纯文本,几乎没有标记或格,但依然能呈现重要的文档结构,Markdown 对于 LLM ,格式在响应和训练时,理解友好、高效。
体验一下
注意 MarkItDown 需要 Python 3.10 或更高版本,建议使用虚拟环境以避免依赖冲突
第一步:clone
bash
git clone git@github.com:microsoft/markitdown.git
cd markitdown第二步: Anaconda 创建虚拟环境,也可以使用标准的 Python 安装、或者UV
ini
conda create -n markitdown python=3.12
conda activate markitdown第三步: 安装 MarkItDown
bash
# 安装所有功能(包括 PDF、OCR 等)
pip install 'markitdown[all]'
# 安装特定功能
pip install 'markitdown[pdf]' # 仅 PDF 支持
pip install 'markitdown[ocr]' # 仅 OCR 支持第四步: Command-Line 运行。(体验一下PDF的转换)
另外也支持 Python 语法的集成, 核心库默认主要处理文本转换,但通过 OCR 插件可扩展支持图片内容的提取。
OCR的能力
markitdown-ocr 插件为 PDF、DOCX、PPTX 和 XLSX 转换器添加了 OCR 支持,通过 LLM Vision 从嵌入的图像中提取文本。
arduino
pip install markitdown-ocr
pip install openai # or any OpenAI-compatible client代码实例
ini
from markitdown import MarkItDown
from openai import OpenAI
md = MarkItDown(
enable_plugins=True,
llm_client=OpenAI(),
llm_model="gpt-4o",
)
result = md.convert("document_with_images.pdf")
print(result.text_content)注意:如果没有提供 llm_client ,插件仍然会加载,但 OCR 会被静默跳过,因此不会处理图片内容。
最后总结
这是一个 python 工具包,没有 GUI 能力,可以自行集成应用中,目前支持将多种文件转换成 Markdown 文本内容,针对图片的转换借助 LLM 能力;如果没有OCR,投喂给大模型的文本还是稍微薄弱。
注意:这里的 Markdown 转换不是给人看的,没有那么好的还原度和保真,更多的是投喂给 LLM 的,所以这里的定位不要搞错了。
将其作为 RAG 处理各种文本、图片 Chunking ,可能是一种不错的选择,作为管道的一环是一种好的技术选型。
参考资料
- github.com/microsoft/m...
- MarkItDown 也提供 MCP(模型上下文协议)服务器,用于与 Claude Desktop 等 LLM 应用程序集成:github.com/microsoft/m...