ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
来自 ReTool: Reinforcement Learning for Strategic Tool Use in LLMs,感觉非常的toy,其实就是把大模型的一部分计算过程给用tool替换掉:

参考文档
REASONING AS REPRESENTATION: RETHINKING VISUAL REINFORCEMENT LEARNING IN IMAGE QUALITY ASSESSMENT
这篇主要是做IQA(Image Quality Assessment,图像质量评估任务)
多模态大语言模型(MLLMs)经强化学习训练后,可借助自身推理能力,将冗余的视觉表征转化为紧凑且跨域对齐的文本表征,而这一转化过程正是此类基于推理的 IQA 模型具备泛化能力的核心来源 。
基于该核心发现,本文提出一种新型算法RALI(Reasoning-Aligned Lightweight IQA )。该算法采用对比学习方式,将图像与强化学习习得的泛化性文本表征直接对齐,既摆脱了对推理过程的依赖,甚至在推理阶段无需加载大语言模型(LLM)。在图像质量评分任务中,该框架实现了与基于推理的模型相当的泛化性能,同时所需模型参数量与推理耗时均不足后者的 5%。
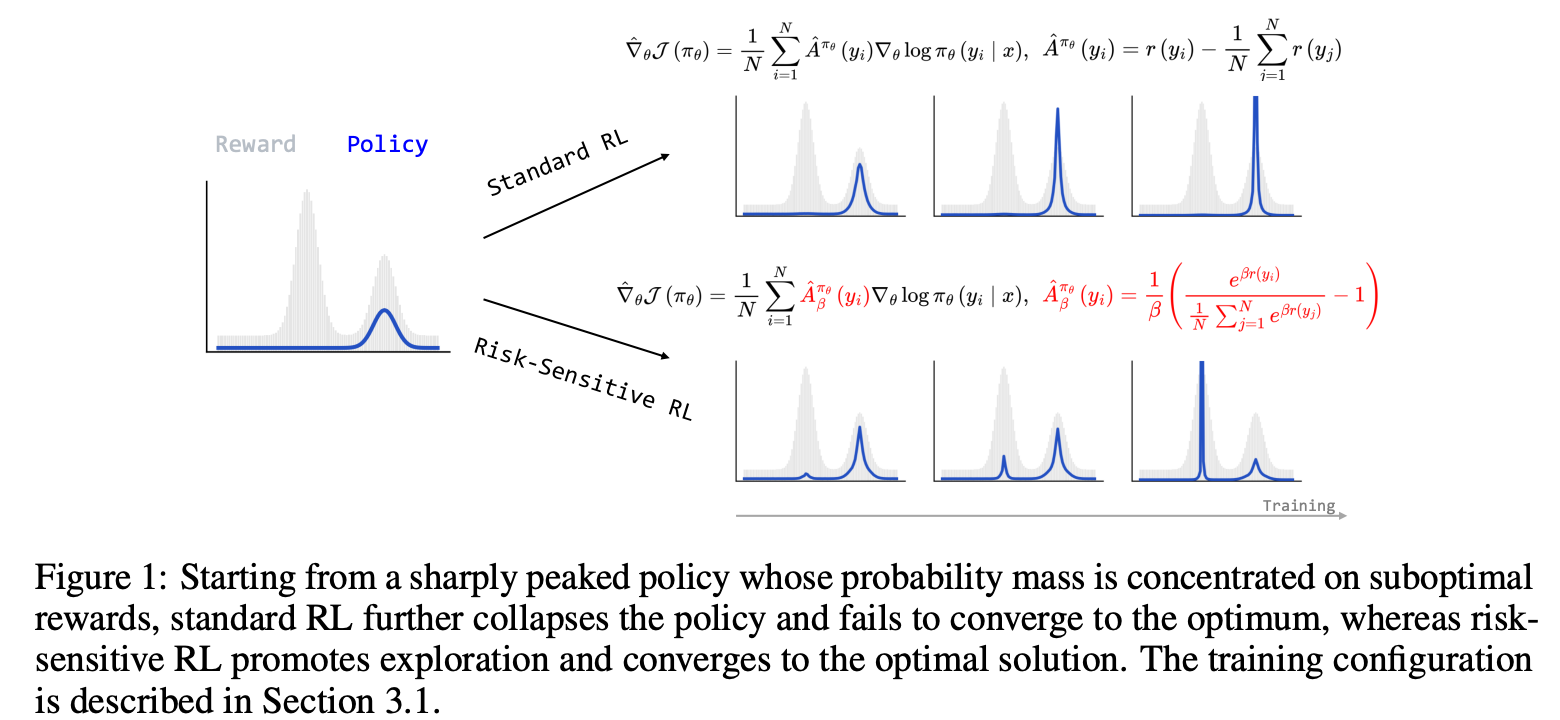
RISK-SENSITIVE RL FOR ALLEVIATING EXPLORATION DILEMMAS IN LARGE LANGUAGE MODELS
提出了RS-GRPO,下图概括了核心贡献,把advantages的估计给改了一下
AgentGym-RL: Training LLM Agents for Long-Horizon Decision Making through Multi-Turn Reinforcement Learning
AgentGym 则从系统层面提出了统一的 agent 强化学习框架,通过分阶段交互训练提升模型在长时程任务中的稳定性。其核心观点在于,复杂 agent 的能力不应仅依赖内部 token 推理的扩展,更有赖于与外部环境的高效交互。
该论文旨在解决缺乏一个统一、端到端、可扩展的多轮交互式强化学习(RL)框架来从零开始训练大语言模型(LLM)智能体,使其能够在多样化、真实场景中完成长周期、多轮决策任务,而**不依赖监督微调(SFT)**作为前置步骤。
具体而言,论文关注以下核心问题:
现有RL研究多局限于单轮静态任务,无法应对智能体在复杂环境中进行多轮交互、长期规划与反思的挑战。
已有智能体训练方法依赖专家轨迹或SFT,成本高、扩展性差,且难以通过环境交互自我改进。
多轮RL训练存在优化不稳定、探索-利用权衡困难、训练崩溃等问题,尤其在交互步数较长时更为突出。
社区缺乏一个模块化、可扩展、支持多种RL算法与真实环境的标准化框架,以系统性地研究和训练LLM智能体。
为此,论文提出:
AgentGym-RL框架:一个模块化、解耦的端到端RL训练框架,支持多种真实环境(如网页导航、深度搜索、数字游戏、具身任务、科学实验)和主流RL算法(PPO、GRPO、REINFORCE++等),无需SFT即可从零训练智能体。
ScalingInter-RL方法:一种渐进式扩展交互步数的课程学习策略,初期限制交互步数以稳定训练、后期逐步增加步数以促进探索,缓解训练崩溃问题,提升长周期任务表现。
参考文档
MEMAGENT: RESHAPING LONG-CONTEXT LLM WITH MULTI-CONV RL-BASED MEMORY AGENT
MemAgent 把无限长文档切成 5 k token 的块,每次只让模型在 8 k 窗口内看到 SYS+Query+1024 token 动态记忆+当前块,用新生成的 1024 token 直接覆盖旧记忆并进入下一轮
借助最终答案正误的 0/1 奖励通过 DAPO(GRPO 的多轮扩展)广播给每一轮记忆更新,使得模型学会"该留什么该扔什么"。
由于 KV-Cache 恒定在 8 k,推理复杂度严格 O(N),且无需额外向量或外部存储,同时从自回归视角看,它把长上下文似然拆成 T 个短上下文似然的乘积,因此可复用现成 8 k 模型即可外推到 3.5 M token,实现线性复杂度、无性能衰减的无限长文本处理。
参考文档
IN-PLACE TEST-TIME TRAINING
Test-Time Training(TTT)这个思路其实早有人提,核心想法是在推理时也允许模型更新一部分参数,叫做"快权重"。即每读入一段新内容,就往这些快权重里压缩一些信息,后续再用它们来辅助预测。
但在真实大模型生态里,TTT一直有三个困难:现有TTT方法需要引入全新的专门层,跟预训练模型架构不兼容,等于要从头重训;更新机制是逐token串行的,并行跑不起来;还有就是学习目标是"重建当前token的representation",跟大模型真正要干的事(next-token pred)其实是两回事。
这篇论文把这三个问题一口气解决了,方法叫 In-Place TTT。
1️⃣它不引入新层,直接把Transformer里已有的MLP块的最后一个投影矩阵(W_down)当快权重用。这样对模型架构零修改,预训练权重原样保留,给现有LLM加上TTT能力只需要一个继续训练的过程,代价远比从头训练低。
2️⃣效率问题靠分块更新解决。因为这套机制只更新MLP不动注意力,不需要像替代注意力的TTT方法那样用极小的chunk来保证因果性,可以直接用512到1024的大块一次处理一批token,充分利用GPU并行。
3️⃣学习目标的改法是这篇论文理论上最充实的部分。作者把目标改成包含未来token信息的向量,用卷积从embedding上拿,再接一个可学习的mlp投影。
论文给出了定理证明:在归纳头(Anthropic 2022的研究)这个分析框架下,对齐NTP目标的快权重更新,在期望意义上能明确提升正确下一个token的logit,而原来的重建目标对正确token在统计上没有帮助。这个结论跟DeepSeek里MultiToken Pred有效的现象也能对上。