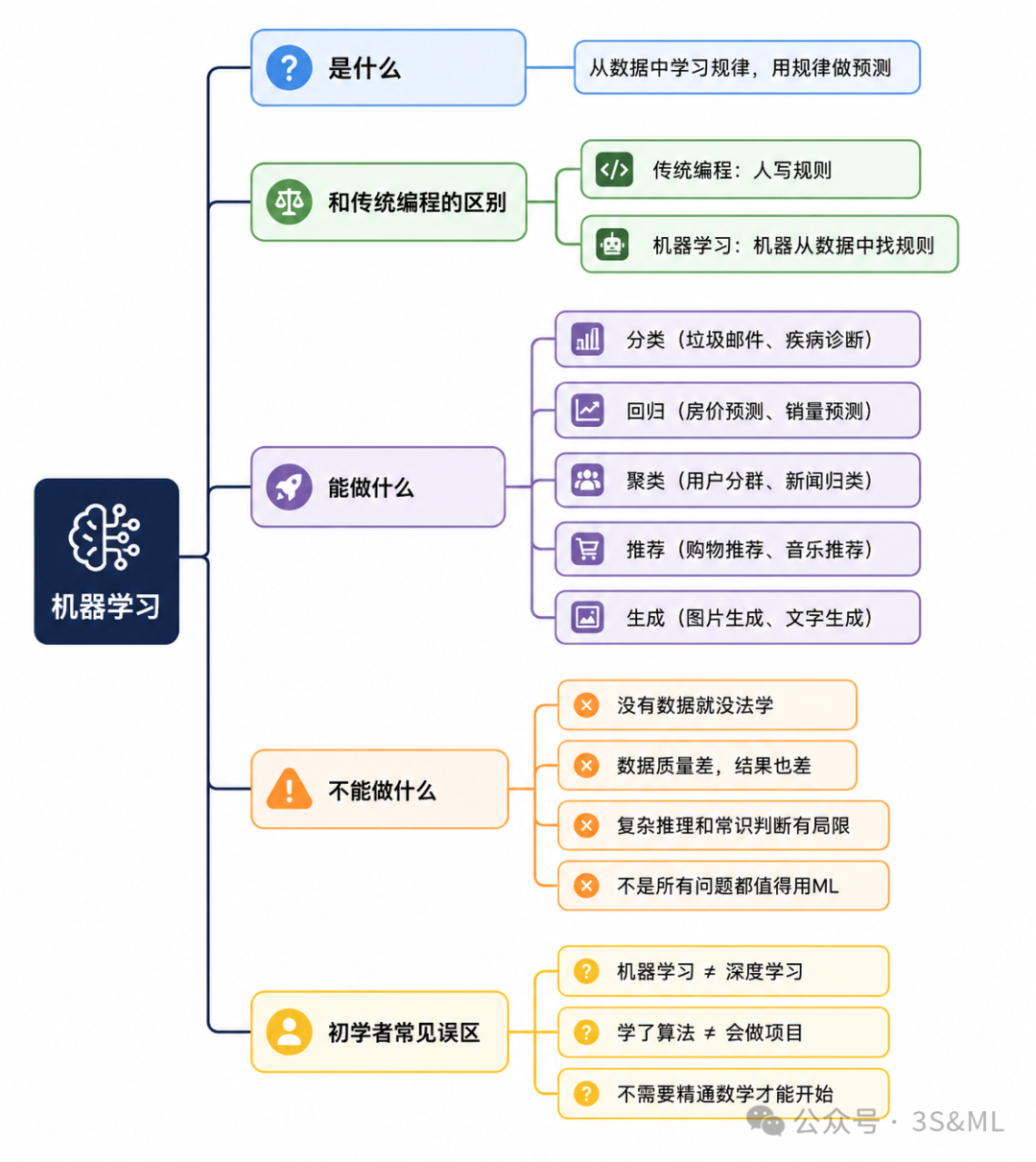
机器学习到底是什么?
一篇讲清它能做什么、不能做什么
这是「机器学习从 0 到 1」系列的第 1 篇。
这个系列会用通俗的语言,带你系统学完机器学习的核心知识。
不需要任何基础,从这里开始就好。
先从一个你熟悉的场景说起
你有没有遇到过这种情况:
打开网易云音乐,它推荐的第一首歌,你一听,哎,就是这个味儿。
打开淘宝,首页第一个商品,你昨晚刚查过类似的。
给朋友发了一张照片,手机相册自动识别出照片里的人是谁,顺手帮你分好了类。
收到一封邮件,还没等你看,它已经被扔进垃圾箱了。
这些事情,你可能习以为常了。
但如果你停下来想一想:这背后到底是谁在做决定?
没有人在盯着你的账号帮你挑歌。没有人在看你浏览了什么商品然后手动给你推荐。是一个程序在做这些事。
但这个程序,和我们平时认知里的"程序"不太一样。
传统程序是怎么工作的?
在解释机器学习之前,我们先说说传统编程是怎么工作的。
传统程序的逻辑很直接:
程序员写规则 → 程序按规则处理数据 → 得到结果
举个例子:
你想写一个程序,判断一封邮件是不是垃圾邮件。
用传统编程的思路,你可能会这样写:
如果邮件里包含"中奖"→ 垃圾邮件
如果邮件里包含"免费领取"→ 垃圾邮件
如果邮件里包含"点击链接"→ 垃圾邮件
如果发件人在黑名单里 → 垃圾邮件
......听起来还行。
但问题来了:
垃圾邮件的发送者也在进化。他今天把"免费领取"改成"0元获得",明天把"中奖"改成"恭喜您被选中"。
你的规则永远在追,永远追不上。
规则越写越多,漏洞越来越多。有时候正常邮件被误判,有时候垃圾邮件漏过去了。
而且更根本的问题是:很多事情,人类自己也说不清规则是什么。
比如你怎么认出一张照片里的人是你妈?
你能写出规则吗?眼睛长什么样?鼻子多宽?脸的轮廓怎么描述?
几乎不可能。但你一眼就认出来了。
机器学习换了一个思路
机器学习的做法,和传统编程完全相反。
它不是让程序员去写规则,而是:
给机器大量数据和对应的答案 → 让机器自己去找规律 → 用学到的规律做预测
还是垃圾邮件的例子。
机器学习的做法是:
给机器看 100 万封邮件,告诉它哪些是垃圾邮件,哪些不是。
让机器自己去发现:垃圾邮件里通常有什么词、什么句式、什么发件人模式......
学完之后,来一封新邮件,机器根据学到的规律,自己判断是不是垃圾邮件。
你没有告诉它任何规则。它自己找到的。
这就是机器学习的核心思想:
从数据中学习规律,用规律对新数据做预测。
用一张图把这个区别记住
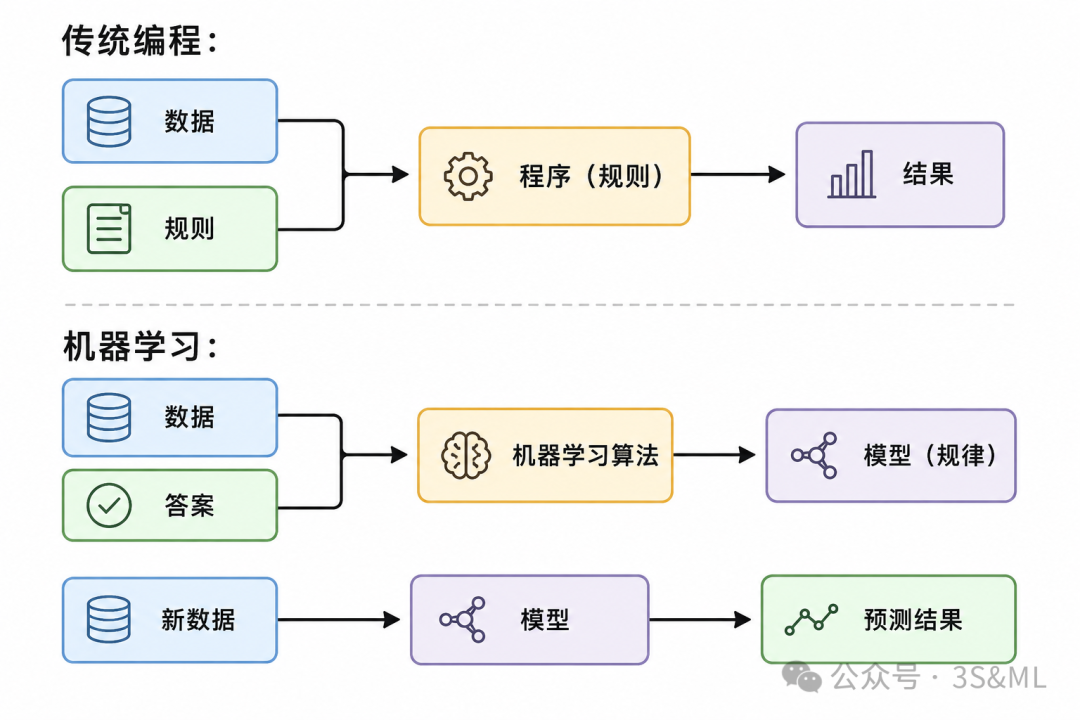
两者最大的区别就是:
-
• 传统编程,规则是人写的
-
• 机器学习,规则是机器从数据里学出来的
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

机器学习能做什么?
现在你大概知道机器学习是什么了。那它具体能做哪些事?
我把常见的应用分成几类,每类给你一个你熟悉的例子。
第一类:分类
把东西归到某一个类别里。
-
• 邮件是不是垃圾邮件?→ 垃圾 / 不是垃圾
-
• 这张图片里是猫还是狗?→ 猫 / 狗
-
• 这个交易是不是欺诈?→ 欺诈 / 正常
-
• 这个肿瘤是良性还是恶性?→ 良性 / 恶性
分类问题的特点是:答案是有限的几个选项。
第二类:回归
预测一个具体的数值。
-
• 这套房子能卖多少钱?→ 350万
-
• 明天的气温是多少度?→ 22℃
-
• 这款产品下个月能卖多少件?→ 8000件
-
• 这个用户在这个 App 上还会用多少天?→ 23天
回归问题的特点是:答案是一个连续的数字。
第三类:聚类
把相似的东西自动归到一组,但事先不知道有哪些组。
-
• 把几百万用户自动分成几类人群,供运营参考
-
• 把新闻文章按主题自动归类
-
• 把基因数据里相似的样本归到一起
聚类问题的特点是:没有"标准答案",机器自己发现结构。
第四类:推荐
根据你的历史行为,预测你可能喜欢什么。
-
• 你可能喜欢这首歌
-
• 你可能想买这个商品
-
• 你可能对这篇文章感兴趣
推荐系统背后用到了很多机器学习的思想,是应用最广泛的场景之一。
第五类:生成
创造出新的内容。
-
• 生成一张从未存在过的人脸
-
• 把一张照片变成油画风格
-
• 根据描述写一段文字
-
• 把语音转成文字
这类应用通常用到了深度学习(机器学习的子集),是近几年发展最快的方向。
机器学习不能做什么?
这部分很多入门文章都不讲,但我觉得它同样重要。
因为知道一个工具的边界,才能真正用好它。
没有数据,就没有机器学习
机器学习的核心是从数据中学习。
如果你的问题没有历史数据,或者数据量极少,机器学习几乎帮不上忙。
比如:你想预测一个从未有过先例的新型产品的销量。没有历史数据,机器没有可学习的东西。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

数据质量差,模型就差
有一句话在机器学习圈子里人尽皆知:
Garbage in, garbage out.
垃圾进去,垃圾出来。
你给机器的数据如果有大量错误、缺失、偏差,那训练出来的模型也一样有问题。
甚至更危险的是:模型会把数据里的偏差当成规律学进去。
历史上真实发生过的案例:一个招聘算法因为训练数据里男性被录用更多,学到了"男性更适合这份工作"这个错误规律,导致系统对女性候选人系统性地打低分。
机器学习不能替代常识和推理
你问 ChatGPT"1 + 1 等于几",它能答对。
但你问它"如果我把大象放进冰箱,需要几步",它能回答,但它并不真正"理解"这个问题。
对于需要深层逻辑推理、常识理解、因果关系判断的问题,机器学习目前仍然有很大局限。
不是所有问题都值得用机器学习
这一点经常被忽略:
很多问题,用简单的规则或统计就能解决,根本不需要机器学习。
如果你的问题逻辑很清晰,规则很容易表达,数据量也不大------传统方法可能更合适。
机器学习的引入会带来额外的复杂性:数据收集、模型训练、维护更新......
工具要匹配问题,而不是为了用而用。
初学者最容易踩的 3 个认知坑
讲完能做什么和不能做什么,再来说说初学者最常见的误区。
误区一:机器学习 = 深度学习
很多人一听"机器学习",脑子里出现的画面是:神经网络、大模型、GPU训练......
但实际上,深度学习只是机器学习的一个子集。
机器学习里有大量经典算法:线性回归、决策树、随机森林、支持向量机......
这些算法在很多实际业务场景里仍然是主力,而且通常比深度学习更容易理解、更容易落地。
初学者往往被深度学习的热度吸引,一上来就学神经网络,反而把基础跳过去了。
学机器学习,建议先从经典算法开始。
误区二:学了算法,就会做项目
这是初学者最经典的坑。
很多人学了一堆算法,但一面对真实数据就懵了:
数据有缺失怎么办?类别特征怎么处理?模型训练完怎么评估?过拟合了怎么调?
这些问题,算法本身不告诉你答案。
真实的机器学习项目,算法只占整个工作量的一小部分。更多的时间花在了:数据探索、数据清洗、特征工程、模型评估、调参优化......
学算法是地基,但盖房子还需要很多其他东西。
这个系列后面会专门讲这些内容。
误区三:要精通数学才能入门
"我线性代数没学好,能学机器学习吗?"
"我概率论忘光了,是不是要重新补?"
这是很多人迟迟没有开始的原因。
答案是:入门不需要精通数学,但数学会让你走得更远。
一个实际可行的学习路径是:
先动手,遇到数学就查,用到哪里学哪里。
与其在数学上打转半年再开始,不如先跑通第一个项目,再回头补你需要的数学。
开始比完美准备更重要。
为方便大家学习 这里给大家整理了一份学习资料包 需要的同学 根据下图自取即可

总结
我们用一张思维导图把这篇文章的核心记住: