文章目录
- [8.1 在线程间分配工作的技术](#8.1 在线程间分配工作的技术)
-
- 8.1.1处理开始前在线程间划分数据
- 8.1.2递归划分数据
-
- 解决方案A:递归直接启动新线程(简单但危险)
- [解决方案B:线程安全栈 + 任务窃取](#解决方案B:线程安全栈 + 任务窃取)
- 结果同步:Promise/Future机制
- 关键概念
- [8.1.3 按任务类型划分工作](#8.1.3 按任务类型划分工作)
-
- [专家线程模式(Master of One)](#专家线程模式(Master of One))
- 流水线模式(Pipeline)
- [8.2 影响并发代码性能的因素](#8.2 影响并发代码性能的因素)
-
- 8.2.1有多少处理器?
- 8.2.2数据争用和缓存乒乓
-
- [数据争用(Data Contention)](#数据争用(Data Contention))
- [缓存乒乓(Cache Ping-Pong)](#缓存乒乓(Cache Ping-Pong))
- [互斥锁争用 vs 原子操作争用](#互斥锁争用 vs 原子操作争用)
- [伪共享(False Sharing)------ 隐藏杀手](#伪共享(False Sharing)—— 隐藏杀手)
- 关键概念
- [8.3 为多线程性能设计数据结构](#8.3 为多线程性能设计数据结构)
-
- [8.3.1 为复杂操作划分数组元素](#8.3.1 为复杂操作划分数组元素)
-
- [策略1:按行划分(Row-wise Partitioning)](#策略1:按行划分(Row-wise Partitioning))
- [策略2:按列划分(Column-wise Partitioning)](#策略2:按列划分(Column-wise Partitioning))
- [策略3:子矩阵划分(Block/Tile Partitioning)](#策略3:子矩阵划分(Block/Tile Partitioning))
- [8.3.2 其他数据结构中的数据访问模式](#8.3.2 其他数据结构中的数据访问模式)
- [8.4 并发设计时的额外考虑因素](#8.4 并发设计时的额外考虑因素)
-
- 8.4.1并行算法中的异常安全
- [8.4.2 可扩展性与Amdahl定律](#8.4.2 可扩展性与Amdahl定律)
- [8.4.3 隐藏等待与异步策略](#8.4.3 隐藏等待与异步策略)
- [8.4.4 使用并发分离关注点](#8.4.4 使用并发分离关注点)
- [8.5 设计并发代码实践](#8.5 设计并发代码实践)
-
- [8.5.1 std::for_each的并行实现](#8.5.1 std::for_each的并行实现)
- [8.5.2 std::find的并行实现](#8.5.2 std::find的并行实现)
- [8.5.3 std::partial_sum的并行实现](#8.5.3 std::partial_sum的并行实现)
- 三种策略对比总结
8.1 在线程间分配工作的技术
8.1.1处理开始前在线程间划分数据
数据被划分给不同的线程,每个线程独立地处理其分配到的数据块,直到完成处理,而不需要与其他线程进行通信。
就像把一大块蛋糕切成几份,每人吃自己的那份,最后把吃完的盘子摞在一起。
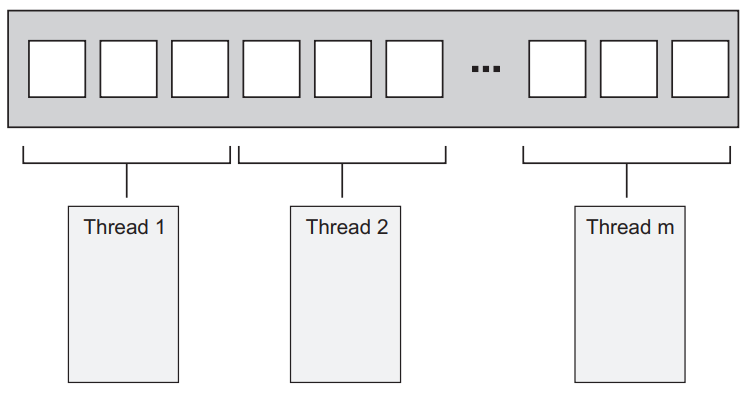
技术本质:静态任务划分(Static Partitioning) ------ 在程序开始执行前,就将数据集预先分割成若干连续的数据块,每个线程负责处理一个数据块。例如下图:在线程之间分配连续的数据块
| 场景 | 问题 | 解决方案 |
|---|---|---|
| 大规模数据处理 | 单线程太慢 | 拆分成多块并行处理 |
| CPU密集型计算 | 多核利用率低 | 让每个核都有活干 |
| 数据已知的算法 | 如矩阵运算、数组求和 | 提前规划,避免运行时开销 |
关键前提:数据在开始时就能被整齐地分割,且各数据块之间的处理相互独立。如果当数据不能在初始阶段就被整齐地分割,这种方法就难以应用。
| 优势 | 说明 |
|---|---|
| 实现简单 | 逻辑清晰,代码易于编写和调试 |
| 开销最小 | 无动态任务分配的运行时开销 |
| 缓存友好 | 连续数据访问,利于CPU缓存命中 |
| 无同步开销 | 处理阶段各线程完全独立 |
典型案例:递归算法(如快速排序)
快速排序的划分依赖于pivot的选择,每次划分后左右子数组大小不确定
无法在开始前预知任务量,因此"难以应用"静态划分
8.1.2递归划分数据
上节讲了静态划分,但如果数据量一开始不确定怎么办?
典型案例:快速排序(Quick Sort),快速排序算法的两个基本步骤是:
分区:选择一个元素作为基准pivot,然后重新排列数组,使得所有小于基准的元素位于基准之前,所有大于基准的元素位于基准之后
递归排序:对基准元素前的子数组和基准元素后的子数组分别递归地进行快速排序
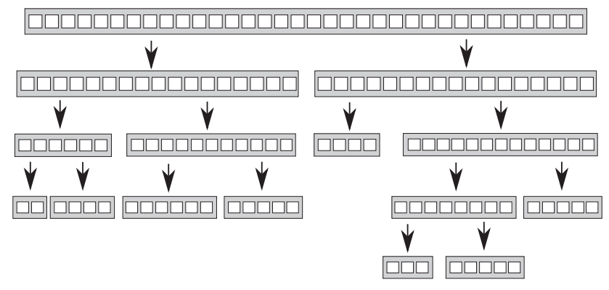
- 选定pivot后,左右子数组大小取决于数据分布,无法在编译时或启动前确定
- 递归深度也不确定
结论:不能使用block_size = length / num_threads这种静态划分
解决方案:动态任务生成与分配(Dynamic Task Generation) ------ 运行时根据数据实际情况动态产生新任务,通过任务窃取(Work Stealing)或线程安全队列/栈实现负载均衡。
为什么需要递归/动态划分?
| 对比维度 | 8.1.1 静态划分 | 8.1.2 递归/动态划分 |
|---|---|---|
| 数据特征 | 总量已知、分布均匀 | 总量动态变化、分布不均 |
| 算法结构 | 线性遍历(for_each, accumulate) | 分治递归(快速排序、归并排序、树遍历) |
| 任务生成时机 | 程序启动前 | 运行过程中动态产生 |
| 线程数控制 | 固定线程池 | 可能产生大量潜在并行任务 |
| 负载均衡 | 预设均衡 | 运行时动态调整 |
解决方案A:递归直接启动新线程(简单但危险)
cpp
// 伪代码:并行快速排序的朴素实现
template<typename T>
struct sorter {
void parallel_quick_sort(iterator first, iterator last) {
if (last - first < threshold) {
std::sort(first, last); // 小到一定程度就串行
return;
}
iterator pivot_pos = partition(first, last);
// ⚠️ 问题:为每个递归调用启动新线程!
std::thread left_thread(
&sorter::parallel_quick_sort, this, first, pivot_pos
);
// 当前线程处理右半部分
parallel_quick_sort(pivot_pos + 1, last);
left_thread.join(); // 必须等待
}
};以上代码有什么问题?
答案:线程爆炸!快速排序平均有O(log n)层递归,如果每层都开新线程,线程数会指数级增长,系统会崩溃。
解决方案B:线程安全栈 + 任务窃取
除了为递归调用启动一个新线程,可以选择将需要排序的区块推入一个线程安全的栈中。如果一个线程没有其他事情要做,它可以从栈中取出一个区块并对其进行排序
核心机制:
- 线程安全栈(Thread-safe Stack):存储待处理的数据区间(任务)
- 任务窃取(Work Stealing):空闲线程从栈中"偷"任务执行
- 线程池模式:固定数量的工作线程,避免线程爆炸
cpp
// 教学版伪代码(基于PPT思想)
template<typename T>
class thread_pool_sorter {
thread_safe_stack<std::pair<iterator, iterator>> work_stack;
std::vector<std::thread> workers;
public:
void sort(iterator first, iterator last) {
// 1. 初始任务入栈
work_stack.push({first, last});
// 2. 启动固定数量工作线程
for (int i = 0; i < num_threads; ++i) {
workers.emplace_back(&thread_pool_sorter::worker_loop, this);
}
// 3. 等待完成
for (auto& t : workers) t.join();
}
void worker_loop() {
while (true) {
auto task = work_stack.pop(); // 取任务
if (!task) break; // 栈空且完成
auto [first, last] = *task;
if (last - first < threshold) {
std::sort(first, last);
} else {
auto pivot = partition(first, last);
// 关键:不直接递归开线程,而是推入栈中让其他线程偷取
work_stack.push({first, pivot}); // 左半部分
work_stack.push({pivot + 1, last}); // 右半部分
}
}
}
};结果同步:Promise/Future机制
获取与新数据块关联的promise对象的future,用于获取排序结果,缘由:
- 在动态任务模型中,子任务可能由不同线程执行
- 父任务需要知道子任务何时完成、结果如何
- std::promise/std::future提供了异步结果传递机制
cpp
// 每个子任务关联一个promise
std::promise<result_type> promise;
std::future<result_type> future = promise.get_future();
// 将任务推入栈时,同时传递promise
work_stack.push({data_range, std::move(promise)});
// 工作线程完成任务后设置值
promise.set_value(result);
// 等待线程通过future获取结果
auto result = future.get(); // 阻塞直到结果可用与8.1.1的对比:静态划分中线程分工明确,可以直接join;动态划分中任务关系复杂,需要promise/future进行点对点的同步。
关键概念
1."任务" vs "线程"
线程是执行实体(固定数量,昂贵)
任务是工作单元(动态生成,轻量)
核心思想:任务数 >> 线程数,通过任务队列解耦
2.终止条件(Termination Condition)
快速排序何时停止递归?→ 区间小于阈值时转串行排序
工作线程何时退出?→ 栈空且无新任务产生时
| 问题 | 深度解析 |
|---|---|
| "为什么不一直递归开线程,而是要用栈?" | 资源限制 :线程是OS资源,创建/销毁开销大;调度开销 :线程过多导致上下文切换;缓存失效:线程切换破坏缓存局部性 |
| "如果所有线程都很忙,新任务会怎样?" | 在栈中等待;这是负载均衡的自然体现------快的线程多做,慢的线程少做 |
| "这和8.1.1的'预先划分'本质区别在哪?" | 信息获取时机 :静态划分在开始前 就知道工作量;动态划分在执行中 才知道;适用算法:数据驱动 vs 结构驱动 |
8.1.3 按任务类型划分工作
核心思想:让专业的人干专业的事------水管工只管水管,电工只管电路,而不是每个人既敲墙又铺线。
技术本质:功能并行(Functional Parallelism) 或 流水线并行(Pipeline Parallelism) ------ 根据处理阶段/功能模块划分线程职责,而非根据数据量。
对于前面两节的数据划分方法,如果数据是动态生成的,或者来自外部输入,那么这种方法就不起作用了。
典型场景:
网络服务器:请求随机到达,无法预先分块
用户交互程序:按键、鼠标事件不定时产生
流式数据处理:视频流、传感器数据持续输入
多阶段处理:视频解码(读取→解压缩→渲染→显示)
单线程时代的痛苦
cpp
// 单线程"状态机"模式------代码噩梦
while (true) {
// 干一点任务A
task_a_do_partial();
task_a_save_state(); // 必须保存状态!
// 干一点任务B
task_b_do_partial();
task_b_save_state();
// 检查输入
if (check_key_input()) {...}
if (check_network()) {...}
// 回到任务A继续... 状态管理极其复杂
}问题:
任务A的代码被碎片化,到处保存/恢复状态
响应性差:如果在任务A中耗时太久,无法及时响应用户输入
代码耦合:不同任务逻辑纠缠在一起
专家线程模式(Master of One)
分配工作的另一种方法是让线程成为某方面的专家,每个线程执行一个不同的任务,就像在建造房屋时,水管工和电工执行不同的任务一样
实现架构:
cpp
Thread A (UI专家): 监听按键 → 处理用户输入 → 更新界面
Thread B (网络专家): 监听socket → 解析数据包 → 存入队列
Thread C (计算专家): 从队列取数据 → 复杂计算 → 通知UI更新多线程带来的三大好处
| 好处 | 解释 | 课堂案例 |
|---|---|---|
| 简化编程 | 每个线程专注单一任务,无需保存中间状态 | UI线程只管UI,不用在计算中途检查输入 |
| 提高响应性 | OS负责调度,I/O线程不会被计算阻塞 | 视频播放时拖动进度条不卡顿 |
| 并行处理 | 多核CPU上真正同时执行不同功能 | 解码核+渲染核+网络核并行工作 |
流水线模式(Pipeline)
假设有20个数据项需要在4个CPU内核上处理,每个数据项都需要经过4个步骤,每个步骤需要3秒钟。
方案1:纯并行(数据划分)
把20个数据项分给4个核,每核处理5个
每个核串行处理5项 × 4步 × 3秒 = 60秒
总时间:60秒(理想情况)
方案2:流水线(任务类型划分)
cpp
时间轴 →
Core 0: [Step1: Item1] [Step1: Item2] [Step1: Item3] ...
Core 1: [Step2: Item1] [Step2: Item2] ...
Core 2: [Step3: Item1] [Step3: Item2] ...
Core 3: [Step4: Item1] [Step4: Item2] ...启动延迟:12秒(填满流水线)
稳定吞吐:每3秒完成1个数据项
总时间:约60秒(理论相同,但特性不同!)
关键点:
在处理视频解码这类任务时,用户体验不仅取决于处理速度,还取决于输出的稳定性和连续性。观众通常可以接受视频开始播放时的几秒钟延迟,但不能接受播放过程中的卡顿或不连贯。
流水线的优势:
吞吐稳定:数据像水流一样持续输出,无停顿
延迟隐藏:单个数据项处理时间可能更长,但整体流畅
资源利用率高:每个核专职一步,缓存命中率高
二者对比:
并行处理:延迟最优(单个数据项最快完成),但吞吐受限于最慢核
流水线处理:吞吐最优(单位时间处理最多),但单个数据项需流经所有阶段
cpp
// 数据划分(8.1.1/8.1.2):控制流分散,数据在一起
// 每个线程执行完整算法,只是数据不同
Thread 0: Sort(Data[0..100])
Thread 1: Sort(Data[100..200])
// 任务划分(8.1.3):数据流动,控制流分散
// 数据像接力棒一样在 specialist 线程间传递
Data → [Read线程] → [Decode线程] → [Render线程] → [Display线程]生产者-消费者基础模型
cpp
// 线程A(生产者):读取文件/网络
void reader_thread(thread_safe_queue<Data>& queue) {
while (has_data()) {
Data d = read_from_source(); // 可能阻塞等待输入
queue.push(d);
}
}
// 线程B(消费者):处理数据
void processor_thread(thread_safe_queue<Data>& queue) {
while (true) {
Data d = queue.pop(); // 阻塞等待数据
if (d.is_end()) break;
process(d);
}
}视频解码流水线(简化版)
cpp
// 三个专家线程,通过队列连接
thread_safe_queue<Packet> network_queue;
thread_safe_queue<Frame> decoded_queue;
void network_thread() {
while (true) {
Packet p = recv_from_network();
network_queue.push(p); // 推给解码专家
}
}
void decoder_thread() {
while (true) {
Packet p = network_queue.pop();
Frame f = decode(p); // 专职解码
decoded_queue.push(f); // 推给渲染专家
}
}
void render_thread() {
while (true) {
Frame f = decoded_queue.pop();
render(f); // 专职渲染,保证流畅显示
}
}8.2 影响并发代码性能的因素
8.2.1有多少处理器?
前面8.1节我们讲了各种并行算法,但有一个致命的假设------我们假装有无限多的处理器。现在回到现实:硬件是有限的,而且千奇百怪。
实际上:并发的速度瓶颈不在算法,而在硬件拓扑;不了解处理器数量和结构,高性能并发就是盲人摸象。
客户的系统可能有一个多核处理器,或者有多个单核处理器,甚至可能有多个多核处理器。
cpp
配置A:单处理器多核(SMP - 对称多处理)
┌─────────────────────────────────┐
│ CPU Package │
│ ┌─────────┐ ┌─────────┐ │
│ │ Core 0 │←──→│ Core 1 │ │
│ │ L1/L2 │ │ L1/L2 │ │
│ └────┬────┘ └────┬────┘ │
│ └────────┬─────┘ │
│ L3 Cache │
└─────────────────────────────────┘
特点:共享L3,内存访问均匀(UMA),线程切换代价小
配置B:多处理器(NUMA - 非均匀内存访问)
┌──────────┐ ┌──────────┐
│ CPU 0 │←────→│ CPU 1 │
│ [4 Cores]│ QPI │ [4 Cores]│
│ +本地内存 │ │ +本地内存 │
└──────────┘ └──────────┘
特点:跨处理器访问内存慢,线程在处理器间迁移代价大
配置C:异构计算(大小核/混合架构)
┌─────────────────────────────────┐
│ P-Core (性能核) × 4 │
│ 高频率、高功耗、超线程 │
├─────────────────────────────────┤
│ E-Core (能效核) × 8 │
│ 低频率、低功耗、单线程 │
└─────────────────────────────────┘
特点:Intel 12代+,ARM big.LITTLE,任务放置策略关键并发程序在这些不同情况下的行为和性能特征可能会有相当大的差异
线程数与硬件并发度的匹配
std::thread::hardware_concurrency() 可以返回"硬件支持的并发线程数",但开发者不应依赖这一点
| 因素 | 说明 | 影响 |
|---|---|---|
| 系统限制 | 容器/虚拟机限制了可用CPU | 返回值可能是4,实际只能用2核 |
| 功耗管理 | 笔记本插电vs电池模式 | 电池模式可能关闭部分核心 |
| 超线程(SMT) | 逻辑核≠物理核 | 返回值8,实际物理核只有4个 |
| 其他进程 | 系统正在运行其他应用 | 即使核存在,也被占用 |
"线程池大小"的决策:
cpp
// ❌ 错误做法:盲目相信硬件并发度
unsigned int num_threads = std::thread::hardware_concurrency();
std::vector<std::thread> threads(num_threads); // 可能过多了!
// ✅ 正确做法:考虑任务特性
unsigned int num_threads;
if (cpu_intensive_work) {
// CPU密集型:线程数 ≤ 物理核心数(避免超订)
num_threads = physical_cores(); // 通常≈hardware_concurrency/2(考虑超线程)
} else if (io_intensive_work) {
// I/O密集型:线程数可以 > 核心数(利用等待时间)
num_threads = hardware_concurrency() * 2 + 1; // 经验值
}动态适应与std::async
std::async() 可以考虑所有应用程序运行的异步任务总数,智能地调度线程。
核心优势:
托管调度:线程池由标准库/运行时管理,不是每次启动新线程
系统感知:可以感知当前系统负载,避免过载
延迟优化:某些调用可能在调用get()时才同步执行(延迟求值)
cpp
// 手动管理(容易出错)
void manual_approach() {
std::vector<std::thread> threads;
for (int i = 0; i < 100; ++i) {
threads.emplace_back(do_work, i); // 可能创建100个线程!
}
for (auto& t : threads) t.join();
}
// 使用async(推荐)
void async_approach() {
std::vector<std::future<void>> futures;
for (int i = 0; i < 100; ++i) {
futures.push_back(std::async(std::launch::async, do_work, i));
// 实际线程数由库控制,可能是硬件并发度的合理倍数
}
for (auto& f : futures) f.get();
}关键概念
- "过载"(Oversubscription)
定义:运行线程数 > 硬件并发度
后果:上下文切换开销 > 并行收益,性能断崖式下降
cpp
void oversubscription_demo() {
const int data_size = 1000000;
// 情况A:合理线程数(如4核机器用4线程)
parallel_process(data_size, 4); // 快
// 情况B:严重过载(创建1000个线程)
parallel_process(data_size, 1000); // 极慢!大部分时间在切换上下文
}- 物理核 vs 逻辑核
cpp
// 示例:Intel i7-8700K(6核12线程)
std::cout << hardware_concurrency(); // 输出12(逻辑核)
// 但12个CPU密集型线程会争夺6个物理核,超线程竞争反而慢
// 最佳可能是6个线程,或者考虑超线程特性选择8-10个8.2.2数据争用和缓存乒乓
并行编程的第一定律:不要让线程'碰'同一数据。如果必须碰,让它们碰得越少越好、越分散越好。缓存行是64字节,但性能差距是100倍------原子操作不是免费的,共享数据是并行的天敌。8.1节讲的划分策略,只有配合8.2节的数据布局,才能真正高性能。
上节我们知道处理器数量有限,但这只是资源约束;这节讲的是性能杀手------即使核足够,错误的内存访问模式也能让并行程序比串行还慢。
多核不是免费的午餐,共享数据的代价可能吞噬所有并行收益。
数据争用(Data Contention)
定义:当两个线程尝试修改同一数据时。这可能导致一个线程必须等待另一个线程完成修改,从而引起延迟。
cpp
时间轴 →
Thread 0: [读取X]→[修改X]→[写入X]──────────────→[读取X]...
Thread 1: ───────────────[读取X]→等待→等待→[修改X]→[写入X]
↑
这里发生争用,T1必须等待T0完成原子操作示例
cpp
std::atomic<unsigned long> counter(0);
void processing_loop() {
while (counter.fetch_add(1, std::memory_order_relaxed) < 100000000) {
do_something();
}
}fetch_add是RMW操作(Read-Modify-Write),不是简单的写
每次操作都需要:
1.从内存/缓存读取当前值(Read)
2.在寄存器加1(Modify)
3.写回内存(Write)
假设单次fetch_add需要100ns(含缓存同步)
1亿次操作 = 10秒
如果4个线程同时跑,不是2.5秒,而是接近40秒!
因为每次操作都要在所有缓存间同步
缓存乒乓(Cache Ping-Pong)
当两个线程在不同的处理器核心上运行,并且都尝试修改相同的缓存行时,数据可能会在两个缓存之间来回传输.。
详细步骤:
1.初始:Core A和B都有X的副本(Shared状态)
2.Core A写X:A获得独占权(Exclusive),B的副本失效(Invalid)
3.Core B要读X:必须从A的缓存偷数据(Ping!),A状态变Shared,B状态变Shared
4.Core B要写X:B请求独占,A失效(Pong!)
5.循环往复:缓存行在A↔B之间来回弹跳
互斥锁争用 vs 原子操作争用
| 特性 | 互斥锁(Mutex) | 原子操作(Atomic) |
|---|---|---|
| 争用级别 | 操作系统级 | 处理器/缓存级 |
| 等待行为 | 线程阻塞,OS调度其他线程 | 线程自旋(Spin),占用处理器 |
| 上下文切换 | 有(成本高) | 无(但浪费CPU周期) |
| 适用场景 | 临界区长、争用中等 | 临界区极短(计数器、标志位) |
| 缓存影响 | 锁本身可能乒乓,但数据保护较好 | 数据本身可能乒乓 |
互斥锁的争用效果通常与原子操作的争用效果不同
使用互斥锁,会在操作系统级别上而不是处理器级别上对线程进行了排序。如果有足够的线程准备好运行,当一个线程正在等待互斥锁时,操作系统可以调度另一个线程运行
而处理器的停顿会阻止任何线程在该处理器上运行
cpp
// 场景:高争用计数器(100个线程各加1万次)
// 方案A:原子操作(缓存乒乓严重)
std::atomic<int> counter{0};
// 每个线程:for(i=0;i<10000;i++) counter.fetch_add(1);
// 结果:极慢,缓存行在100个核间疯狂弹跳
// 方案B:互斥锁(可能反而更好!)
std::mutex m; int counter=0;
// 每个线程:for(i=0;i<10000;i++) { lock_guard l(m); counter++; }
// 结果:虽然串行化了,但避免了100路缓存乒乓
// 实际上:线程在锁外可并行执行其他任务,锁内串行但短暂
// 方案C:最优解------减少共享(见8.3节)
// 每个线程先算局部和,最后合并
std::vector<int> local(100, 0);
// 每个线程写自己的local[thread_id],最后sum(local)
// 无共享!无乒乓!极速!伪共享(False Sharing)------ 隐藏杀手
即使某个特定的内存位置只被一个线程访问,由于一种称为伪共享(false sharing)的效应,你仍然可能会遇到缓存乒乓
机制详解:
缓存行(Cache Line)通常是64字节
数组元素通常是4/8字节
即使Thread 0访问array0,Thread 1访问array1,它们可能在同一缓存行
cpp
缓存行(64字节)包含:
├─ array[0] (Thread 0修改) ← 同一行!
├─ array[1] (Thread 1修改) ← 同一行!
├─ array[2] (Thread 2修改) ← 同一行!
└─ array[3] (Thread 3修改) ← 同一行!
结果:4个线程"无辜"地互相拖累,缓存行在4个核间弹跳解决方案是将数据结构化,使得由同一个线程访问的数据项在内存中彼此靠近(因此更可能位于同一个缓存行中),而那些将由不同线程访问的数据则在内存中远离
关键概念
- 争用谱系(Contention Spectrum)
cpp
无争用 ──────────────────────────────→ 高争用
只读共享 不同变量 原子操作 互斥锁
(最好) (伪共享风险) (中等) (串行化)- 缓存一致性的代价模型
共享读:低成本(各缓存可同时持有Shared副本)
独占写:高成本(需使其他缓存失效)
频繁读写同一变量:极高成本(乒乓)
代码:缓存乒乓的可视化
cpp
// 严重乒乓(所有线程改同一变量)
std::atomic<int> shared_counter{0};
void bad() {
for (int i = 0; i < 10000000; ++i) {
shared_counter.fetch_add(1, std::memory_order_relaxed);
}
}
// 4线程各改自己的变量(但可能伪共享)
struct BadData {
int a; // Thread 0用
int b; // Thread 1用(与a同一缓存行!)
int c; // Thread 2用
int d; // Thread 3用
} data;
// 无乒乓(填充后)
struct GoodData {
alignas(64) std::atomic<int> a;
alignas(64) std::atomic<int> b; // 确保不同缓存行
alignas(64) std::atomic<int> c;
alignas(64) std::atomic<int> d;
} data;8.3 为多线程性能设计数据结构
8.3.1 为复杂操作划分数组元素
数组划分不是简单的"切蛋糕",而是缓存对齐、访问模式、计算负载的三维优化。
矩阵乘法。通常情况下,非稀疏矩阵在内存中由一个大型数组表示,首先是第一行的所有元素,然后是第二行的所有元素,以此类推:
cpp
逻辑矩阵(3×3): 内存实际存储(行优先Row-Major):
┌───┬───┬───┐ 地址:0 1 2 3 4 5 6 7 8
│ a │ b │ c │ 数据:[a][b][c][d][e][f][g][h][i]
├───┼───┼───┤
│ d │ e │ f │ 缓存行(假设4个元素/行):
├───┼───┼───┤ Line 0: [a][b][c][d]
│ g │ h │ i │ Line 1: [e][f][g][h]
└───┴───┴───┘ Line 2: [i][..][..][..]
关键观察:
- 同一行元素:内存连续(缓存友好 ✓)
- 同一列元素:内存跳跃(缓存不友好 ✗)
例如列1(b,e,h):分布在3个不同缓存行!三种划分策略的深度对比
策略1:按行划分(Row-wise Partitioning)
结果矩阵C的每行分配给不同线程
每个线程计算Ci\*(第i行的所有列)
内存访问特征:
cpp
Thread 0 计算 C[0][0..N-1]: 需要读取 A[0][*](连续)和 B[*][*](跳跃)
Thread 1 计算 C[1][0..N-1]: 需要读取 A[1][*](连续)和 B[*][*](跳跃)如果是按结果矩阵的行数划分,就更简单
优势:
写入C的行是连续的(缓存友好)
A的行也是连续读取(缓存友好)
实现简单,无需复杂索引计算
劣势:
读取B的列需要跳跃(Cache Miss高)
策略2:按列划分(Column-wise Partitioning)
结果矩阵C的每列分配给不同线程
每个线程计算C\*j(第j列的所有行)
如果按结果矩阵的列数划分计算量,如果由每行N(每个线程处理的列数)个元素占据的空间正好是缓存行的整数倍,那么就不会发生虚假共享,因为线程将在不同的缓存行上工作
cpp
// 避免伪共享的条件:
(column_count_per_thread × sizeof(element)) % cache_line_size == 0
// 例如:int占4字节,缓存行64字节
// 每个线程应处理 16个int(64字节)的整数倍列数
// 即:16列、32列、48列...如果列数不是缓存行对齐,相邻线程的列可能共享缓存行 → 伪共享
策略3:子矩阵划分(Block/Tile Partitioning)
将矩阵划分为小矩形块(Tiles)
每个线程负责一个子矩阵的所有元素
cpp
原始矩阵(8×8) 划分为4个线程(2×2块结构):
┌───────┬───────┐ Thread 0 │ Thread 1
│ T0 │ T1 │ ─────────┼─────────
│ │ │ Thread 2 │ Thread 3
├───────┼───────┤ ─────────┼─────────
│ T2 │ T3 │
│ │ │
└───────┴───────┘优势:
负载均衡:每个线程计算量相同(假设矩阵均匀)
缓存效率:子矩阵可以完全载入L1/L2缓存
减少伪共享:块边界可以缓存行对齐
复杂度:
索引计算复杂(需处理块边界)
需要额外的循环嵌套(块外循环+块内循环)
8.3.2 其他数据结构中的数据访问模式
矩阵是规则的数组,但现实中我们还有树、图、链表、哈希表等不规则结构。本节探讨这些结构的并行优化策略。
不规则数据结构更复杂,但核心原则不变:让线程的数据局部、分散、对齐。
通用优化原则
在尝试优化其他数据结构的数据访问模式时,基本上与优化数组访问时考虑的因素相同,三个原则:
| 原则 | 解释 | 实现手段 |
|---|---|---|
| 1. 局部性分配 | 彼此接近的数据由同一线程处理 | 按子树/子图划分,而非按节点类型 |
| 2. 最小化数据量 | 减少单个线程的缓存工作集 | 只加载必要节点,延迟加载 |
| 3. 避免伪共享 | 不同线程的数据在内存中远离 | 内存池按线程分块,填充对齐 |
二叉树案例深度分析
cpp
数组(连续内存):
[Node0][Node1][Node2][Node3]...
访问Node0→Node1→Node2:预取缓存命中率高
二叉树(堆分配,指针链接):
Node0 (addr: 0x1000)
/ \
Node1 Node2 (addr: 0x5000, 0x8000 - 分散!)
/ \ / \
Node3 Node4... (更分散)
问题:
- Node0,1,2逻辑上接近,物理上可能相距甚远
- 每个节点在不同缓存行
- 遍历树=缓存未命中频发- 劣势("需要更多缓存"):
每个节点访问都可能Cache Miss
指针解引用是随机访问模式,破坏预取 - 优势("避免虚假共享"):
节点分散 → 不同线程访问的节点天然不在同一缓存行
无需像数组那样刻意填充对齐
自由分配的天然隔离
树的节点布局优化
树的每个节点通常包含两部分数据:一部分是用于维护树结构的数据(如指向父节点、子节点、兄弟节点的指针),另一部分是节点数据本身(节点存储的实际信息)
优化策略:
方案A:分离结构域与数据域(AoS vs SoA)
cpp
// 传统方式(Array of Structures)- 不利于并行
struct TreeNode {
TreeNode* left; // 8字节
TreeNode* right; // 8字节
TreeNode* parent; // 8字节
char data[256]; // 256字节(实际载荷)
}; // 总大小280字节,跨越5个缓存行
// 优化方式(Structure of Arrays)- 并行友好
struct TreeData {
std::vector<TreeNode*> left; // 所有左指针
std::vector<TreeNode*> right; // 所有右指针
std::vector<char*> data; // 数据指针(可分散存储)
// 线程0处理索引0..N,线程1处理N..2N...
// 结构信息连续,数据可离散
};方案B:按子树划分(Subtree Partitioning)
cpp
// 线程分配策略
Thread 0: 负责根左子树(所有节点)
Thread 1: 负责根右子树(所有节点)
优势:
- 每个子树局部遍历,缓存相对集中
- 不同子树天然分离,无伪共享
- 符合8.3.2原则1:"彼此接近的数据由同一线程处理"互斥锁与数据的内存布局
当互斥锁和数据项在内存中紧密相连时,可能会导致缓存行争用,从而影响性能
对于获取该互斥锁的线程来说可能是理想的,因为它所需的数据可能已经在处理器的缓存中,这是因为加载互斥锁时一并加载的
然而,互斥锁的锁定通常通过执行原子的读修改写操作来实现,如果互斥锁与线程使用的数据共享一个缓存行,那么当其他线程尝试锁定互斥锁时,持有互斥锁的线程可能会因为缓存行争用而遭受性能损失
cpp
内存布局A(锁与数据相邻 - 危险):
┌─────────────────────────────────┐
│ Mutex (64字节中的前40字节) │
│ Data (64字节中的后24字节) │
└─────────────────────────────────┘
↑ 同一缓存行
Thread 0: 锁住Mutex,修改Data
Thread 1: 尝试锁Mutex(需读取同一缓存行)→ 导致Thread 0的缓存行失效!
结果:Thread 0刚修改的Data被踢出缓存,即使Thread 1只想要锁优化布局B(锁与数据分离):
cpp
struct alignas(64) PaddedMutex {
std::mutex m;
char padding[64 - sizeof(std::mutex)]; // 填充至64字节
};
struct alignas(64) DataItem {
int value;
char padding[64 - sizeof(int)];
};
// 现在锁和数据在不同缓存行
// Thread 1抢锁不会踢出Thread 0的数据8.4 并发设计时的额外考虑因素
8.4.1并行算法中的异常安全
前面我们优化了性能,但如果线程抛出异常怎么办?C++默认不跨线程传播异常,一个线程崩溃会导致整个程序终止。
异常安全是健壮并行程序的底线,必须确保"异常发生时,线程仍能正确汇合,资源不泄漏"。
cpp
// 灾难代码
void disaster() {
std::thread t([]{
throw std::runtime_error("Boom!"); // 子线程抛出异常
});
t.join(); // 主线程等待
// 结果:std::terminate被调用,程序崩溃!
}根本原因:
每个线程有独立栈,异常在自己的栈上传播
主线程的try-catch无法捕获子线程的异常
std::thread析构时若线程仍在运行且未处理异常 → std::terminate
解决方案:std::future与std::packaged_task
cpp
// 安全代码
template<typename Iterator, typename T>
T parallel_accumulate(Iterator first, Iterator last, T init) {
// ... 线程创建代码 ...
std::vector<std::future<T>> futures(num_threads - 1); // 存储期值
for (unsigned long i = 0; i < num_threads - 1; ++i) {
std::packaged_task<T(Iterator, Iterator)> task(
accumulate_block<Iterator, T>() // 包装任务
);
futures[i] = task.get_future(); // 获取future
threads[i] = std::thread(std::move(task), block_start, block_end);
}
// 主线程计算最后一块
T last_result = accumulate_block<Iterator, T>()(block_start, last);
// 关键:通过get()获取结果,异常会在此重新抛出!
for (auto& f : futures) {
last_result += f.get(); // 若线程异常,这里抛出
}
return last_result;
}异常传播路径:
工作线程抛出异常 → 被packaged_task捕获 → 存储在future中
主线程调用future.get() → 异常被重新抛出到主线程
主线程可以正常try-catch处理
线程汇合:join_threads类
cpp
class join_threads {
std::vector<std::thread>& threads;
public:
explicit join_threads(std::vector<std::thread>& threads_) : threads(threads_) {}
~join_threads() {
for (unsigned long i = 0; i < threads.size(); ++i) {
if (threads[i].joinable()) {
threads[i].join(); // 析构时自动汇合
}
}
}
};异常安全场景:如果parallel_accumulate中间抛出异常,栈回滚 → join_threads析构 → 所有线程被join
避免资源泄漏:不join或detach的线程会导致程序终止
对比手动管理:try-catch中手动join代码重复且易遗漏
使用方法:
cpp
T parallel_accumulate(...) {
std::vector<std::thread> threads(num_threads - 1);
join_threads joiner(threads); // RAII守卫
// 若此处或之后抛出异常,joiner析构自动汇合所有线程
// 无需手动try-catch-finally
}多异常处理:std::nested_exception
如果多个工作线程抛出异常,通常情况下只有一个异常会被传播到主线程... 如果同时捕获多个异常很重要,可以使用std::nested_exception
场景:4个线程同时崩溃,如何收集所有异常?
cpp
std::exception_ptr first_exception;
std::mutex exc_mutex;
try {
// 并行代码
} catch(...) {
std::lock_guard<std::mutex> lk(exc_mutex);
if (!first_exception) {
first_exception = std::current_exception(); // 保存第一个
} else {
// 后续异常作为嵌套异常保存(C++11起支持)
}
}
// 稍后重新抛出
if (first_exception) {
std::rethrow_exception(first_exception);
}8.4.2 可扩展性与Amdahl定律
可扩展性是关于随着添加更多处理器而减少执行操作所需的时间,或者增加在给定时间内可以处理的数据量
Amdahl定律:程序可以简化为串行部分(只有一个线程在工作)和并行部分(所有处理器都在工作)... 如果增加处理器的数量,那么并行部分的性能理论上会提升... 串行部分的性能不会改变
S ( N ) = 1 ( 1 − P ) + P N S(N)=\cfrac{1}{(1-P)+\cfrac{P}{N}} S(N)=(1−P)+NP1
S(N) :N个处理器时的加速比
P :程序中可并行部分的比例
(1−P) :串行部分比例(无法加速的瓶颈)
即使处理器无限多(N→∞ ),最大加速比 S m a x = 1 ( 1 − P ) S_{max}=\cfrac{1}{(1-P)} Smax=(1−P)1
若10%代码必须串行(P=0.9 ),最大加速比只有10倍!
8.4.3 隐藏等待与异步策略
线程并不总是有有用的工作要做。有时它们必须等待其他线程,或等待I/O完成,或等待其他事情。如果在等待期间给系统一些有用的工作,可以有效地'隐藏'等待
也就是不要让CPU闲着等I/O,让其他线程(或异步任务)利用这段时间。
例子:
一个病毒扫描应用程序,它使用流水线将工作分配给线程:
一个线程负责搜索文件系统中的文件,并将它们放入队列;其他线程从队列中取出文件进行扫描
搜索文件的线程是 I/O 密集型的,因为它大部分时间都在等待磁盘 I/O 操作
利用 I/O 密集型线程的等待时间,可以运行额外的扫描线程来提高 CPU 利用率
由于扫描线程也可能涉及磁盘 I/O,可能需要更多的扫描线程来进一步提高性能
| 策略 | 适用场景 | 机制 |
|---|---|---|
| 增加扫描线程 | I/O等待高时 | 一个线程阻塞,其他线程用CPU |
| 异步I/O | 高并发I/O | 线程不阻塞,注册回调继续执行 |
| 无锁编程 | 高竞争共享数据 | 自旋替代阻塞,避免上下文切换 |
| 工作窃取 | 负载不均 | 空闲线程"偷"其他线程任务 |
通过启动额外的线程,可以使得在某些线程等待时,CPU依然被有效利用,执行其他有用的工作
但是,线程会太多,系统会再次变慢,因为它花费越来越多的时间进行任务切换【过载(Oversubscription)】
更改线程数量是一种性能优化手段,优化前后应测量性能,以确定最佳的线程数量
8.4.4 使用并发分离关注点
大多数GUI框架都是事件驱动的... 通过使用并发分离关注点,可以将耗时的任务放在一个全新的线程上,同时留下一个专用的 GUI 线程来处理事件
传统单线程GUI的问题:
cpp
// 单线程事件循环(问题版本)
while (true) {
event_data event = get_event(); // 非阻塞/轮询?
if (event.type == quit) break;
process(event); // 如果耗时10秒,GUI冻结10秒!
}症状:
点击按钮 → 触发计算 → 界面卡死 → 用户以为程序崩溃
无法响应窗口重绘、鼠标移动、取消操作
并发解决方案:
cpp
std::thread task_thread; // 工作线程(专家)
std::atomic<bool> task_cancelled(false); // 取消标志
void gui_thread() {
while (true) {
event_data event = get_event();
if (event.type == quit) {
task_cancelled = true; // 通知工作线程
if (task_thread.joinable()) task_thread.join();
break;
}
if (event.type == start_task) {
// 启动耗时任务,不阻塞GUI
task_thread = std::thread([]{
if (!task_cancelled) do_heavy_work();
});
}
process(event); // 快速响应,不阻塞
}
}关键机制:
专用GUI线程:只处理事件循环,永远不被阻塞
后台工作线程:执行耗时任务,通过原子标志与GUI通信
取消机制:用户可随时取消长时间任务(通过atomic<bool>)
8.5 设计并发代码实践
8.5.1 std::for_each的并行实现
算法特征与并行策略
std::for_each是完全并行友好的操作:对每个元素应用函数,元素间无依赖
不需要合并结果(void返回),不需要提前终止
理想情况:完美的" embarrassing parallel "(易并行)问题
代码框架:
cpp
template<typename Iterator, typename Func>
void parallel_for_each(Iterator first, Iterator last, Func f) {
unsigned long const length = std::distance(first, last);
if (!length) return;
// 1. 线程数决策(与8.1.1一致)
unsigned long const min_per_thread = 25;
unsigned long const max_threads = (length + min_per_thread - 1) / min_per_thread;
unsigned long const hardware_threads = std::thread::hardware_concurrency();
unsigned long const num_threads =
std::min(hardware_threads != 0 ? hardware_threads : 2, max_threads);
unsigned long const block_size = length / num_threads;
// 2. 存储期值(异常安全,8.4.1)
std::vector<std::future<void>> futures(num_threads - 1);
std::vector<std::thread> threads(num_threads - 1);
join_threads joiner(threads); // RAII
// 3. 启动工作线程
Iterator block_start = first;
for (unsigned long i = 0; i < num_threads - 1; ++i) {
Iterator block_end = std::next(block_start, block_size);
std::packaged_task<void()> task([=]{
std::for_each(block_start, block_end, f);
});
futures[i] = task.get_future();
threads[i] = std::thread(std::move(task));
block_start = block_end;
}
// 4. 主线程处理最后一块
std::for_each(block_start, last, f);
// 5. 等待并捕获异常(通过future.get())
for (unsigned long i = 0; i < num_threads - 1; ++i) {
futures[i].get(); // 阻塞+异常传播
}
}要点分析
- 块大小选择(min_per_thread = 25)
原理:线程创建开销约几千个时钟周期
经验法则:每个线程至少处理25个元素,确保"计算量 >> 线程开销"
可调整:对于轻量级函数(如++i),需要更大块(100+);重量级函数(如复杂IO)可减小 - 异常安全设计
使用packaged_task+future组合(8.4.1)
join_threads确保异常时线程被正确汇合
通过future.get()捕获工作线程异常 - 负载均衡
静态划分:前num_threads-1块大小相同,最后一块处理剩余(可能略大或略小)
适用于均匀计算;若函数f的执行时间差异大,需动态任务窃取(8.1.2)
8.5.2 std::find的并行实现
算法特征:提前终止的挑战
与for_each的关键差异:
std::find需要提前终止:一旦找到目标,其他线程应停止搜索
这是"搜索算法"的典型特征,与"处理算法"(for_each)有本质区别
通过使用原子变量作为标志并在处理每个元素后检查该标志,可以中断其他线程。缺点是原子加载可能是慢操作,因此这可能会阻碍每个线程的进展
实现架构详解
数据结构:
cpp
std::promise<Iterator> result; // 存储找到的迭代器
std::atomic<bool> done_flag(false); // 原子标志,用于提前终止
std::vector<std::thread> threads;工作函数(find_element):
cpp
void find_element(Iterator first, Iterator last,
MatchType match,
std::promise<Iterator>* result,
std::atomic<bool>* done_flag) {
try {
for (; first != last && !done_flag->load(); ++first) {
if (*first == match) { // 找到目标
// 尝试设置结果(竞态条件处理)
if (!done_flag->exchange(true)) {
// 只有第一个成功的线程能设置promise值
result->set_value(first);
}
return; // 本线程结束
}
}
} catch (...) {
// 捕获异常尝试设置promise(可能已被设置,需捕获异常)
try {
result->set_exception(std::current_exception());
done_flag->store(true);
} catch (...) {
// promise已被设置,忽略
}
}
}结果获取:
cpp
// 主线程等待结果
if (futures[i].valid()) {
return futures[i].get(); // 返回找到的迭代器
}性能权衡分析
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 原子标志检查 | 实现简单,能终止 | 每次循环都有原子操作开销 | 大数据集,目标在中后段 |
| 不检查标志 | 无额外开销 | 即使已找到,线程仍继续搜索 | 数据集小,或目标通常在前段 |
| 结合方案 | 每N个元素检查一次标志 | 代码复杂,响应延迟 | 通用最佳实践 |
竞态条件处理
多线程同时找到的情况:
cpp
Thread A: 在位置100找到 → 检查done_flag=false → 设置flag=true → 设置promise
Thread B: 在位置200找到 → 检查done_flag=true → 直接返回(不设置promise)异常处理:
若Thread A设置promise后抛出异常,Thread B可能也捕获到异常并尝试设置
需捕获std::future_error(promise已设置)
8.5.3 std::partial_sum的并行实现
算法特征:数据依赖的挑战
算法定义:
"std::partial_sum 计算一个范围内的累积总和,因此每个元素被替换为该元素与原始序列中它之前所有元素的和"
示例:1, 2, 3, 4, 5 → 1, 3, 6, 10, 15
关键难点:
数据依赖:计算第i个元素需要第i-1个元素的结果
不可简单分块:若分块并行,块间依赖无法解决
有两种策略
策略一:块间串行+块内并行(两阶段法)
阶段1:并行计算局部和
cpp
数据:[1,2,3] [4,5,6] [7,8,9] (分3块)
↓ ↓ ↓
T1计算 T2计算 T3计算
结果:[1,3,6] [4,9,15] [7,15,24] (局部partial_sum)阶段2:传播块末尾值
T1块末尾=6,加到T2块所有元素 → 10,15,21
T2块末尾=21,加到T3块所有元素 → 28,36,45
最终结果:1, 3, 6, 10, 15, 21, 28, 36, 45
实现关键:使用promise/future传递前一块的末尾值
cpp
std::vector<std::promise<value_type>> end_values(num_threads - 1); // 本块末尾
std::vector<std::future<value_type>> previous_end_values; // 前块末尾策略二:树形归约(并行前缀和)
这种方法在处理器能够同步执行加法操作时效果最佳... 代码必须为更一般的情况设计,即在每一步都需要显式地同步线程
Step 1:相邻元素求和(间隔1)
cpp
原始:[1] [2] [3] [4] [5] [6] [7] [8] [9]
↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
[1] [3] [5] [7] [9] [11] [13] [15] [17] (i += i-1)Step 2:间隔2求和
cpp
[1] [3] [6] [10] [14] [18] [22] [26] [30] (i += i-2)Step 3:间隔4求和
cpp
[1] [3] [6] [10] [15] [21] [28] [36] [44] (i += i-4)Step 4:间隔8求和(最终)
cpp
[1] [3] [6] [10] [15] [21] [28] [36] [45] (i += i-8)复杂度:
时间:O(log n)步,每步O(n)操作,总O(n log n)(比串行O(n)差!)
并行度:每步内部并行,适合n极大、处理器极多的情况
同步机制:屏障(Barrier)
cpp
struct barrier {
std::atomic<unsigned> count; // 当前屏障需等待线程数
std::atomic<unsigned> spaces; // 剩余需到达线程数
std::atomic<unsigned> generation; // 屏障周期标识
void wait() {
unsigned const gen = generation.load();
if (!--spaces) { // 最后一个到达
spaces = count.load(); // 重置
++generation; // 进入下一代
} else {
while (generation.load() == gen) {
std::this_thread::yield(); // 自旋等待
}
}
}
};屏障作用:确保所有线程完成第k步后,才进入第k+1步
数据竞争:若无屏障,线程A可能还在读旧值,线程B已写新值 → 错误结果
自旋 vs 阻塞:PPT使用yield()自旋,适合同步时间短的场景
三种策略对比总结
| 策略 | 并行度 | 同步复杂度 | 适用场景 | 与串行速度比 |
|---|---|---|---|---|
| 串行 | 1 | 无 | 小数据 | 基准 |
| 块间串行 | 高(块内) | 中等(需传递末尾值) | 中等数据,核心数少 | 接近1:1(块大小合适时) |
| 树形归约 | 极高 | 高(每步需屏障) | 超大规模数据,超多核心 | 可能慢于串行(小数据时) |