在人工智能从单一模态向全场景多模态融合演进的关键节点,智能系统不仅需要理解文本与图像,更需深度解析视频流、音频信号、传感器数据及复杂环境上下文。然而,传统计算架构在处理 TB 乃至 PB 级异构多模态数据时,普遍面临存储瓶颈、计算效率低下、扩展性不足等挑战,严重制约了模型迭代速度与性能突破。
应对这些挑战,关键在于构建一套深度融合高效计算与统一存储的新型技术架构。阿里云人工智能平台 PAI 与流式数据湖仓 Paimon 构建了从数据存储到数据处理的高性能、高弹性开发链路。我们将结合典型多模态场景(如智能视频监控、多媒体内容分析、人机交互系统等),详细演示如何构建视频及多源异构数据处理流水线,为多模态大模型的规模化落地提供切实可行的技术路径。
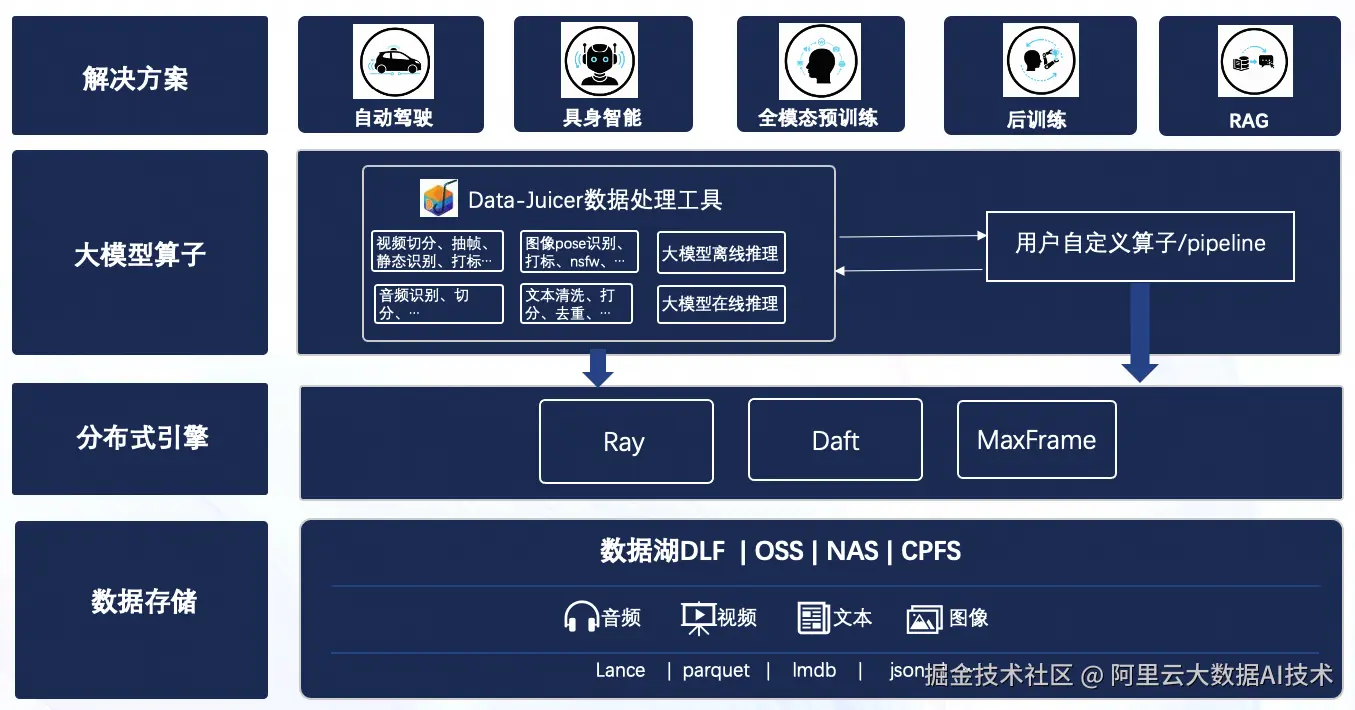
一、多模态数据流水线介绍
为系统性地构建多模态数据处理链路,我们将依托 DataJuicer 的组件化能力,融合其丰富的预置算子与灵活的自定义 UDF 算子,共同搭建一套标准化的视频处理流程。我们同步提供两套可选的实现 Demo:一套基于高性能分布式计算框架Ray,另一套基于新兴的分布式数据处理框架Daft。这两种实现方式将展示在不同技术栈下,如何高效完成从原始视频数据到训练就绪数据的完整处理过程。 
1、场景分割
使用内容检测算法(ContentDetector)对输入视频进行分析,当帧间差异超过设定阈值时,即将视频切分为不同的场景镜头。此步骤确保了后续处理的基本单元是内容连贯的视频片段。
2、时长过滤
对上一步产出的所有视频片段进行初步筛选,剔除过短或过长的异常片段,保证后续处理数据的规范性。
3、视频抽帧
采用均匀抽帧或关键帧检测的策略,从每个视频片段中提取具有代表性和信息量的帧图像。此过程会同步进行基础质量检查,过滤掉无效或损坏的帧,并为后续分析步骤提供高质量的帧数据源。
4、内容安全过滤
这是一个关键的质量与合规控制点。它使用特定的NSFW(不适宜工作场所)检测模型,对视频片段进行内容安全审核。通过分析片段中的关键帧,计算出一个安全评分,并过滤掉平均得分超过某个预置的片段。
5、动态评分过滤
用于评估视频的动态丰富度。它以每秒2帧的速率采样,计算片段的运动强度分数,并筛选掉得分低于某个预置的、相对静态或动态不足的片段。
6、美学评分过滤
进一步提升数据质量,该步骤使用美学评分模型对视频片段的视觉美感进行量化评估。它均匀地采样帧,最终保留平均美学分数在指定范围的优质片段。
7、视频描述生成
根据多模态模型(例如"Video BLIP"),为通过前面所有严格筛选的、最终保留下来的高质量视频片段,自动生成文本描述。这为后续的模型训练提供了宝贵的"视频-文本"配对数据。
二、计算性能实测
以上流水线,我们以Youku-AliceMind/caption/validation视频数据进行测试。
小规模测试
输入数据:6865 个视频文件,总时长:52.4 h
输出数据量:17000 左右的视频切片
机型 L20 : 8 GPU 128 CPU
耗时:20min 左右
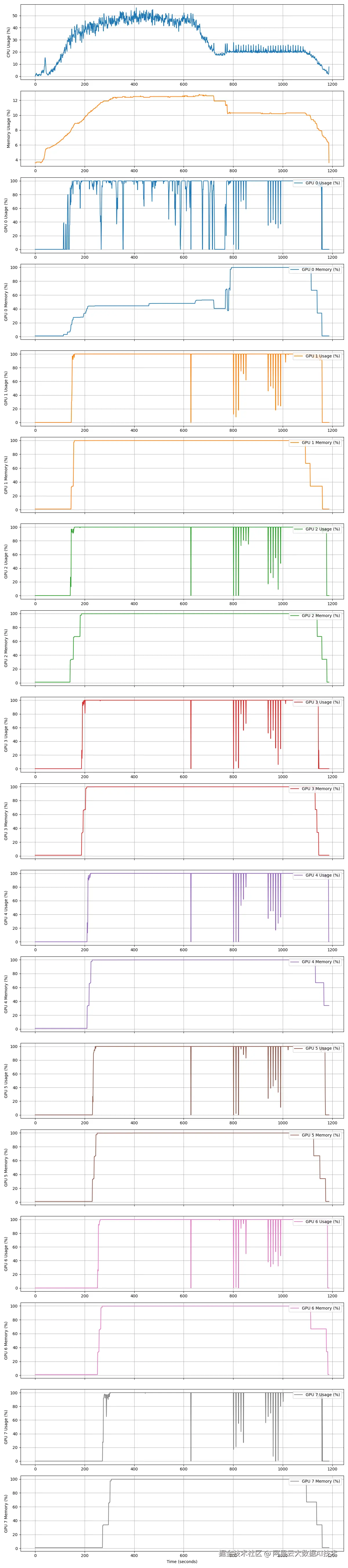
GPU利用率如下:
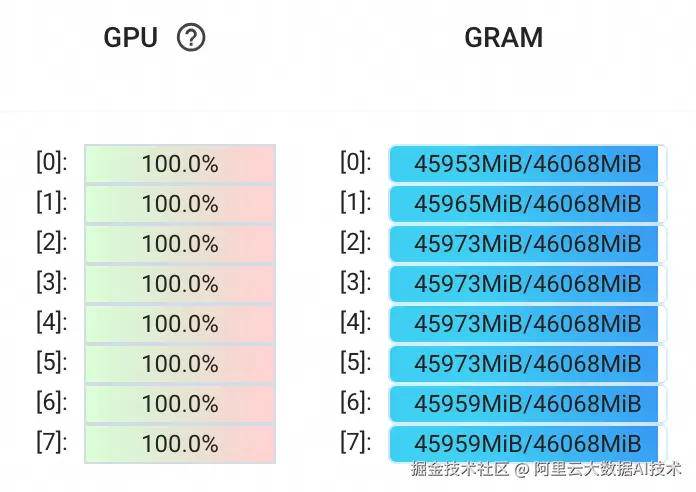
CPU + 8个GPU利用率曲线统计:
大规模测试
大规模测试我们使用PAI的DLC启动DataJuicer分布式作业。
输入数据:200万个视频文件,总时长:3万小时
输出数据量:1000多万的视频切片
机型 5090 : 8 GPU 180 CPU
节点数量:45台 5090
耗时:200 min
GPU利用率如下:
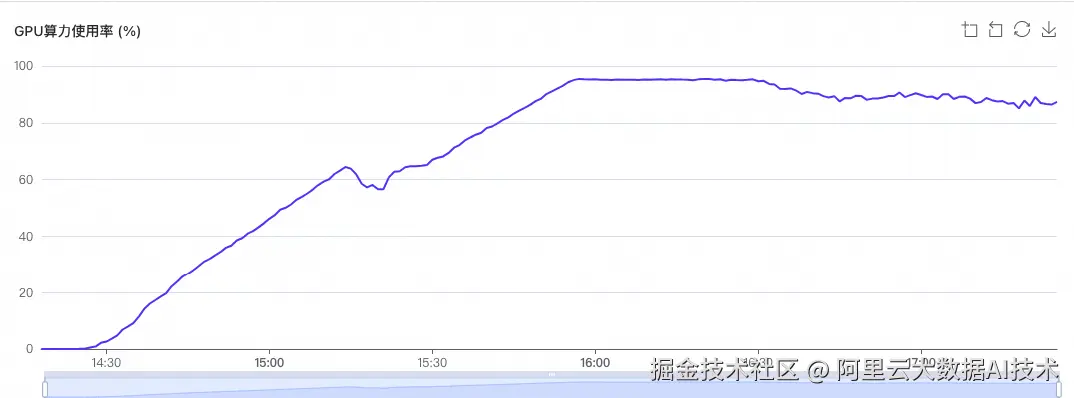
Ray dashboard显示如下: 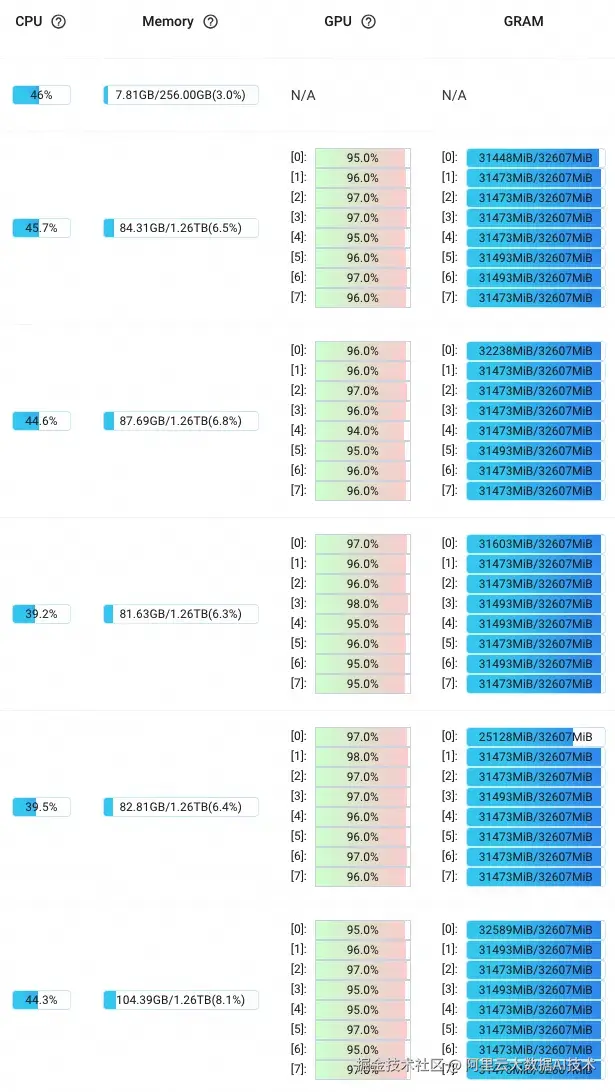
三、多模态数据链路搭建最佳实践
准备工作
使用阿里云 PAI 的 DataJuicer 框架,请参考文档:
help.aliyun.com/zh/pai/user...
环境准备
- 数据湖开通
参考文档:
help.aliyun.com/zh/dlf/dlf-...
help.aliyun.com/zh/emr/emr-...
- 安装依赖包
shell
$ pip install py-data-juicer
$ pip install pypaimon数据准备
我们以魔搭社区开源的 Youku-AliceMind 数据集为例,根据官方文档下载视频文件: modelscope.cn/datasets/mo...
湖数据写入:
python
import os
import pyarrow as pa
from pypaimon import Schema
from pypaimon import CatalogFactory
from pypaimon.common.file_io import FileIO
from pypaimon.table.row.blob import BlobDescriptor, Blob
def to_blob_data(video_path, external_oss_options={}):
try:
from pypaimon.common.file_io import FileIO
external_file_io = FileIO(video_path, external_oss_options)
video_file_size = external_file_io.get_file_size(video_path)
# print(f"Video file size: {video_file_size / 1024 / 1024:.2f} MB")
except Exception as e:
raise FileNotFoundError(f"Failed to access video file from OSS: {video_path}, error: {e}")
external_blob_uri = video_path
blob_descriptor = BlobDescriptor(external_blob_uri, 0, video_file_size)
descriptor_bytes = blob_descriptor.serialize()
return descriptor_bytes
def read_table(catalog, table_name: str):
table = catalog.get_table(table_name)
read_builder = table.new_read_builder()
table_scan = read_builder.new_scan()
splits = table_scan.plan().splits()
table_read = read_builder.new_read()
result = table_read.to_arrow(splits)
print(f"Read {result.num_rows} rows")
print(f"Columns: {result.column_names}")
if __name__ == '__main__':
# load local video files
data_dir = '/your/path/to/Youku-AliceMind/caption/validation/videos'
videos_list = [os.path.join(data_dir, video) for video in os.listdir(data_dir)] # 支持OSS路径,例如:oss://your-bucket/your-path/video.mp4
print(f'>>> Found {len(videos_list)} videos.')
catalog_name = 'your_catalog_name' # replace with your catalog name
region = 'cn-beijing' # replace with your region
database_name = 'your_database_name' # replace with your database name
table_name = 'demo_data' # replace with your table name
external_oss_options = {
'fs.oss.accessKeyId': os.environ['accessKeyID'],
'fs.oss.accessKeySecret': os.environ['accessKeySecret'],
'fs.oss.endpoint': f"oss-{region}.aliyuncs.com",
'fs.oss.region': f"{region}",
}
catalog_options = {
'metastore': 'rest',
'uri': f"http://{region}-vpc.dlf.aliyuncs.com",
'warehouse': f'{catalog_name}',
'dlf.region': f"{region}",
"token.provider": "dlf",
'dlf.access-key-id': os.environ['accessKeyID'],
'dlf.access-key-secret': os.environ['accessKeySecret'],
'dlf.oss-endpoint': f"oss-{region}.aliyuncs.com",
**external_oss_options
}
catalog = CatalogFactory.create(catalog_options)
catalog.create_database(
name=database_name,
ignore_if_exists=True,
)
pa_schema = pa.schema([
('text', pa.string()),
('video_path', pa.string()),
('video_bytes', pa.large_binary())
])
schema = Schema.from_pyarrow_schema(
pa_schema=pa_schema,
partition_keys=None,
primary_keys=None,
options={
'row-tracking.enabled': 'true',
'data-evolution.enabled': 'true',
'blob-field': 'video_bytes', # Specify blob field
'blob-as-descriptor': 'true' # Enable blob-as-descriptor mode
},
comment='my test table with blob')
table_identifier = f'{database_name}.{table_name}'
catalog.create_table(
identifier=table_identifier,
schema=schema,
ignore_if_exists=True
)
table = catalog.get_table(table_identifier)
print(f"Table schema fields: {[f.name for f in table.table_schema.fields]}")
print(f"Table schema field types: {[str(f.type) for f in table.table_schema.fields]}")
from pypaimon.schema.data_types import PyarrowFieldParser
table_pa_schema = PyarrowFieldParser.from_paimon_schema(table.table_schema.fields)
print(f"Table PyArrow schema: {table_pa_schema}")
print(f"Input PyArrow schema: {pa_schema}")
write_builder = table.new_batch_write_builder()
table_write = write_builder.new_write()
table_commit = write_builder.new_commit()
data_dict = {
'text': [''] * len(videos_list), # empty text field
'video_path': videos_list,
'video_bytes': [to_blob_data(v, external_oss_options) for v in videos_list]
}
table_write.write_arrow(pa.Table.from_pydict(
data_dict,
schema=pa_schema))
table_commit.commit(table_write.prepare_commit())
table_write.close()
table_commit.close()
# test reading
read_table(catalog, table_identifier)方式一:基于分布式计算框架Ray
基于原生Ray框架搭建pipeline,我们采用"Ray + DataJuicer"的联合方案。DataJuicer 本身即构建于 Ray 底座,这意味着其丰富的算子库能被原生的 Ray 框架直接调用,实现分布式能力的开箱即用,大幅提升开发与运算性能。
DLF数据读取
读取数据湖数据并转换为 Ray dataset 对象:
python
import os
def load_catalog(catalog_name, region):
external_oss_options = {
'fs.oss.accessKeyId': os.environ['accessKeyID'],
'fs.oss.accessKeySecret': os.environ['accessKeySecret'],
'fs.oss.endpoint': f"oss-{region}.aliyuncs.com",
'fs.oss.region': f"{region}",
}
catalog_options = {
'metastore': 'rest',
'uri': f"http://{region}-vpc.dlf.aliyuncs.com",
'warehouse': f'{catalog_name}',
'dlf.region': f"{region}",
"token.provider": "dlf",
'dlf.access-key-id': os.environ['accessKeyID'],
'dlf.access-key-secret': os.environ['accessKeySecret'],
'dlf.oss-endpoint': f"oss-{region}.aliyuncs.com",
**external_oss_options
}
from pypaimon import CatalogFactory
catalog = CatalogFactory.create(catalog_options)
return catalog
def read_dlf_table_to_ray_ds(database_name, catalog_name, table_name, region):
catalog = load_catalog(catalog_name, region)
table = catalog.get_table(f'{database_name}.{table_name}')
read_builder = table.new_read_builder()
table_scan = read_builder.new_scan()
splits = table_scan.plan().splits()
# convert the splits into a Ray Dataset and handle it by Ray Data API for distributed processing
table_read = read_builder.new_read()
ray_dataset = table_read.to_ray(splits)
return ray_dataset
region = 'cn-beijing'
database_name = 'your_database_name' # replace with your database name
catalog_name = 'your_catalog_name' # replace with your catalog name
table_name = 'your_table_name' # replace with your table name
ds = read_dlf_table_to_ray_ds(
database_name=database_name,
catalog_name=catalog_name,
table_name=table_name,
region=region
)视频分割
我们采用基于关键帧的视频分割方法,通过识别并提取视频中具有代表性的关键帧,实现对连续视频流的语义划分。
该方法首先通过帧间差异分析或内容特征提取,检测视频中因主体动作显著变化、环境切换或视角转换所产生的关键节点,并从中选取最具信息量的关键帧作为场景分割的边界标识。通过设定合理的关键帧选取阈值与最小场景间隔,能够在保留核心动作连贯性的同时,有效过滤冗余画面与过渡内容,从而实现对视频流的紧凑语义分段。最终,系统可自动输出以关键帧为标记的视频片段,并为每个分段生成对应的独立剪辑,便于后续的行为建模、内容检索与高层语义分析。
使用 DataJuicer 算子,将切分后的 clip 保存在clips字段下,clip 文件保存到./outputs/clips/文件夹下:
python
from data_juicer.ops.mapper import VideoSplitByKeyFrameMapper
split_video_op = VideoSplitByKeyFrameMapper(
keep_original_sample=False,
legacy_split_by_text_token=False,
save_dir='./outputs/clips',
save_field="clips",
ffmpeg_extra_args="-movflags frag_keyframe+empty_moov",
output_format="bytes", # path
skip_op_error=False,
batch_mode=True,
video_backend='ffmpeg',
video_key='video_bytes'
)时长过滤
在视频片段筛选阶段,我们依据预设的时长阈值对候选片段进行过滤,剔除不符合要求的无效片段。设置这一环节主要基于以下考虑:
-
过长的视频片段可能包含冗余信息或无关内容,影响语义理解与特征提取效率
-
超出模型处理上限的片段会导致计算资源浪费与推理性能下降
-
合理控制输入时长有助于提升多模态任务的准确率与系统稳定性
因此,我们通过设定最小与最大时长边界,筛选出时长适中、内容紧凑的有效视频片段,为后续的语义解析、行为识别等任务提供高质量输入,同时优化系统资源利用率。
使用 DataJuicer 的算子,处理clips字段下的视频内容,保留视频时长大于2s的视频:
python
import sys
from data_juicer.ops.filter import VideoDurationFilter
dutation_filter = VideoDurationFilter(
min_duration=2,
max_duration=sys.maxsize,
video_key="clips",
# skip_op_error=True,
batch_mode=True,
video_backend='ffmpeg'
)视频抽帧
在视频理解任务中,模型通常需要从连续的视频流中提取具有代表性的视觉片段作为输入。为此,我们通过关键帧抽取操作将视频内容转化为结构化的图像序列,便于后续的特征提取与时空建模。
该视频抽帧模块采用全关键帧采样策略,能够自动识别视频中的显著性画面,确保所提取的每一帧都承载着丰富的视觉信息。通过设定输出路径格式与帧存储目录,系统会将采样结果组织为规范的图像文件集合,为后续的时序分析提供稳定可靠的数据基础。
使用 DataJuicer 的算子抽取关键帧,抽取clips字段下的视频帧,帧内容存储在video_frames字段下。
python
from data_juicer.utils.constant import MetaKeys
from data_juicer.ops.mapper import VideoExtractFramesMapper
extract_frames_op = VideoExtractFramesMapper(
frame_sampling_method="all_keyframes",
output_format="bytes",
frame_field=MetaKeys.video_frames,
video_key="clips",
legacy_split_by_text_token=False,
# skip_op_error=True,
video_backend='ffmpeg',
batch_mode=True,
)内容安全过滤
在视频内容安全检测环节,我们引入了一个专门用于识别不适宜工作场所内容的过滤模块。该模块对解码后的视频帧进行内容安全性评估,确保只有符合安全 标准的视频片段能够进入后续处理流程。
这一步骤通过预训练的NSFW检测模型实现,能够有效识别包含敏感内容的画面,为后续的智能分析构建安全的内容基础。
使用 DataJuicer 算子,对video_frames字段下 每个视频对应的帧进行打分,并对所有帧的得分取平均值,平均值得分在0.0-0.5范围内的样本将被保留。
python
import sys
from data_juicer.ops.filter import VideoNSFWFilter
nsfw_filter = VideoNSFWFilter(
hf_nsfw_model="Falconsai/nsfw_image_detection",
trust_remote_code=True,
min_score=0.0,
max_score=0.5,
frame_field=MetaKeys.video_frames,
frame_num=sys.maxsize,
reduce_mode="avg",
video_backend='ffmpeg',
# skip_op_error=True,
batch_mode=True
)动态评分过滤
在视频质量评估流程中,我们额外引入基于运动强度的筛选机制,保留运动幅度在合理范围内的视频样本。该步骤主要用于排除两类极端情况:
-
运动过弱:画面几乎静态,缺乏动态信息,难以支撑时序建模需求
-
运动过强:存在剧烈抖动或快速缩放,影响内容连贯性与特征提取稳定性
我们采用光流分析法计算视频帧间运动强度,通过设定上下阈值筛选符合要求的样本。支持"any"/"all"多视频判定策略,可适配单视频或多视角场景的筛选需求。此操作能有效提升后续动作识别、行为分析等时序任务的输入质量,避免无效样本对模型训练的干扰。
我们将运动强度下限设为0.25,上限不设限制,确保保留具有明显动态特征且运动幅度可控的有效视频片段。
python
from data_juicer.ops.filter import VideoMotionScoreFilter
motion_score_filter = VideoMotionScoreFilter(
min_score=0.25,
max_score=sys.float_info.max,
size=None,
any_or_all="any",
frame_field=MetaKeys.video_frames,
# skip_op_error=True,
batch_mode=True
)美学评分过滤
该模块基于预训练美学评估模型,通过设定分数阈值区间与多帧聚合策略,有效剔除画面质量不佳的样本。可确保输入后续模块的视频样本均具备良好的视觉质量基础,为语义理解、内容分析等下游任务提供可靠的视觉素材。
使用 DataJuicer 算子,对video_frames字段下 每个视频的对应帧进行打分,并对所有帧的得分取平均值,平均值得分在0.4-1.0范围内的样本将被保留。
python
from data_juicer.ops.filter import VideoAestheticsFilter
aesthetics_filter = VideoAestheticsFilter(
hf_scorer_model="shunk031/aesthetics-predictor-v2-sac-logos-ava1-l14-linearMSE",
trust_remote_code=True,
min_score=0.4,
max_score=1.0,
frame_field=MetaKeys.video_frames,
frame_num=sys.maxsize,
reduce_mode="avg",
# skip_op_error=True,
batch_mode=True
)视频描述生成
在完成视频片段的预处理与筛选后,接下来进入语义生成环节。该模块基于预训练的多模态大模型,对输入的视频帧序列进行时序感知与场景解析,生成符合需求的自然语言描述。
使用 DataJuicer 算子,对video_frames字段下 每个视频的对应帧 作为模型输入 生成视频的 caption 描述。
python
from data_juicer.ops.mapper import VideoCaptioningFromVideoMapper
video_caption = VideoCaptioningFromVideoMapper(
hf_video_blip='kpyu/video-blip-opt-2.7b-ego4d',
trust_remote_code=True,
caption_num=1,
keep_original_sample=False,
frame_field=MetaKeys.video_frames,
frame_num=3,
legacy_split_by_text_token=False,
text_update_strategy='rewrite',
)运行pipeline
使用 Ray data 框架,端到端运行整个链路:
python
import os
import sys
import copy
import pyarrow
from functools import partial
import time
import uuid
import pyarrow as pa
import ray
from ray.data import ActorPoolStrategy
from data_juicer.core.data.ray_dataset import filter_batch
from data_juicer.utils.constant import Fields, MetaKeys
from data_juicer.ops.base_op import Mapper, OPERATORS
from pypaimon import Schema
from pypaimon import CatalogFactory
from pypaimon.common.uri_reader import FileUriReader
from pypaimon.common.file_io import FileIO
from pypaimon.table.row.blob import BlobDescriptor, Blob
def prepare_ds_for_dj_op(ds, add_meta_fileds=True, add_stats_fields=True):
columns = ds.columns()
# if op._name in TAGGING_OPS.modules and Fields.meta not in columns:
if add_meta_fileds and Fields.meta not in columns:
def process_batch_arrow(table: pyarrow.Table):
new_column_data = [{} for _ in range(len(table))]
new_table = table.append_column(Fields.meta, [new_column_data])
return new_table
ds = ds.map_batches(
process_batch_arrow,
batch_format="pyarrow",
# batch_size=1000
)
if add_stats_fields and Fields.stats not in columns:
def process_batch_arrow(table: pyarrow.Table):
new_column_data = [{} for _ in range(len(table))]
new_talbe = table.append_column(Fields.stats, [new_column_data])
return new_talbe
ds = ds.map_batches(
process_batch_arrow,
batch_format="pyarrow",
# batch_size=1000
)
return ds
if __name__ == '__main__':
s_time = time.time()
ray.init(address='auto', ignore_reinit_error=True)
region = 'cn-beijing'
database_name = 'your_database_name' # replace with your database name
catalog_name = 'your_catalog_name' # replace with your catalog name
table_name = 'your_table_name' # replace with your table name
out_table = 'output_table' # replace with your output table name
ds = read_dlf_table_to_ray_ds(
database_name=database_name,
catalog_name=catalog_name,
table_name=table_name,
region=region
)
@OPERATORS.register_module('dlf_blob_parser')
class DLFBlobParser(Mapper):
"""读dlf多模态数据,适配datajuicer list格式的videos字段"""
_batched_op = True
def __init__(self, database_name, catalog_name, table_name, region, *args, **kwargs):
super().__init__(*args, **kwargs)
self.catalog = load_catalog(catalog_name, region)
self.table = self.catalog.get_table(f'{database_name}.{table_name}')
def process_single(self, sample, *arg, **kwargs):
video_bytes = sample[self.video_key]
blob_descriptor = BlobDescriptor.deserialize(video_bytes)
# print(f"Row {i}: BlobDescriptor URI={blob_descriptor.uri}, "
# f"Offset={blob_descriptor.offset}, Length={blob_descriptor.length}")
uri_reader = FileUriReader(self.table.file_io)
blob = Blob.from_descriptor(uri_reader, blob_descriptor)
blob_data = blob.to_data()
sample[self.video_key] = [blob_data] # 兼容datajuicer video list格式
return sample
ds = ds.map_batches(
DLFBlobParser,
fn_constructor_kwargs={
"database_name": database_name,
"catalog_name": catalog_name,
"table_name": table_name,
"region": region,
'video_key': 'video_bytes'
},
batch_size=10,
num_cpus=1,
batch_format="pyarrow",
compute=ActorPoolStrategy(
min_size=1,
max_size=50
),
)
# add_meta_fileds = op._name in TAGGING_OPS.modules
ds = prepare_ds_for_dj_op(ds, add_meta_fileds=False, add_stats_fields=True)
ds = ds.map_batches(
split_video_op,
batch_size=10,
num_cpus=2,
batch_format="pyarrow",
)
# 将clips平铺,其他字段保持原样
def flat_clips(sample):
clips = sample['clips']
flat_samples = []
for idx in range(len(clips)):
flat_sample = copy.deepcopy(sample)
flat_sample['clips'] = [clips[idx]] # 兼容datajuicer video list格式
flat_samples.append(flat_sample)
return flat_samples
ds = ds.flat_map(flat_clips)
ds = ds.map_batches(
dutation_filter,
batch_size=10,
num_cpus=2,
batch_format="pyarrow"
).map_batches(
partial(filter_batch, filter_func=dutation_filter.process),
zero_copy_batch=True,
batch_format="pyarrow"
).map_batches(
extract_frames_op,
batch_size=10,
num_cpus=2,
batch_format="pyarrow"
)
ds = ds.map_batches(
nsfw_filter.__class__,
fn_constructor_args=nsfw_filter._init_args,
fn_constructor_kwargs=nsfw_filter._init_kwargs,
batch_size=10,
num_gpus=0.05, # 1GB / 49140MiB
compute=ActorPoolStrategy(
min_size=10,
max_size=50
),
batch_format="pyarrow"
).map_batches(
partial(filter_batch, filter_func=nsfw_filter.process),
zero_copy_batch=True,
batch_format="pyarrow"
).map_batches(
motion_score_filter.__class__,
fn_constructor_args=motion_score_filter._init_args,
fn_constructor_kwargs=motion_score_filter._init_kwargs,
batch_size=10,
num_cpus=2,
compute=ActorPoolStrategy(
min_size=10,
max_size=50
),
batch_format="pyarrow"
).map_batches(
partial(filter_batch, filter_func=motion_score_filter.process),
zero_copy_batch=True,
batch_format="pyarrow"
).map_batches(
aesthetics_filter.__class__,
fn_constructor_args=aesthetics_filter._init_args,
fn_constructor_kwargs=aesthetics_filter._init_kwargs,
batch_size=10,
num_gpus=0.05, # 1500MB /49140MB
compute=ActorPoolStrategy(
min_size=10,
max_size=50
),
batch_format="pyarrow"
).map_batches(
partial(filter_batch, filter_func=aesthetics_filter.process),
zero_copy_batch=True,
batch_format="pyarrow"
).map_batches(
video_caption.__class__,
fn_constructor_args=video_caption._init_args,
fn_constructor_kwargs=video_caption._init_kwargs,
batch_size=10,
num_gpus=0.3,
compute=ActorPoolStrategy(
min_size=5,
max_size=25,
),
batch_format="pyarrow")
def postprocess_fn(item):
stats = item[Fields.stats]
item = {
'id': uuid.uuid4().hex,
'clips': item['clips'][0],
'text': item['text'],
'video_duration': stats['video_duration'][0], # output field of VideoDurationFilter
'video_frames_aesthetics_score': stats['video_frames_aesthetics_score'][0], # output field of VideoAestheticsFilter
'video_nsfw_score': stats['video_frames_aesthetics_score'][0], # output field of VideoNSFWFilter
}
return item
ds = ds.map(postprocess_fn)
# paimon write
catalog = load_catalog(catalog_name, region)
catalog.create_database(database_name, ignore_if_exists=True)
schema = Schema.from_pyarrow_schema(pa.schema([
('id', pa.string()),
('clips', pa.binary()),
('text', pa.string()),
('video_duration', pa.float64()),
('video_frames_aesthetics_score', pa.float64()),
('video_nsfw_score', pa.float64()),
]),
partition_keys=None, # ['id'],
primary_keys=None,
options={
'row-tracking.enabled': 'true',
'data-evolution.enabled': 'true',
'blob-field': 'video_bytes', # Specify blob field
'blob-as-descriptor': 'true' # Enable blob-as-descriptor mode
}
)
try:
catalog.drop_table(f'{database_name}.{out_table}')
print(f'>>>> remove table: {database_name}.{out_table}')
except:
print(f'>>>> table: {database_name}.{out_table} does not exist')
catalog.create_table(f'{database_name}.{out_table}', schema, ignore_if_exists=True)
saved_table = catalog.get_table(f'{database_name}.{out_table}')
write_builder = saved_table.new_batch_write_builder()
table_write = write_builder.new_write()
table_write.write_ray(
ds,
overwrite=False,
concurrency=10,
ray_remote_args={"num_cpus": 1}
)
table_commit = write_builder.new_commit()
commit_messages = table_write.prepare_commit()
table_commit.commit(commit_messages)
table_write.close()
table_commit.close()
print(f'>>> total cost time: {time.time() - s_time}')方式二:基于分布式数据处理框架Daft
DataJuicer 丰富的算子库能被原生的Ray框架直接调用,经过简单的包装同样适用于Daft框架。
对流水线中的算子均基于 Daft 框架进行了实现,具体分为两种方式:部分算子完全基于 Daft 开发,另一部分则直接调用 DataJuicer 的现有算子。为帮助用户了解如何在 Daft 框架中直接使用 DataJuicer 算子,我们提供了一个适配器函数作为示例。该函数作为封装层,可将 DataJuicer 算子包装为 Daft 的 UDF 函数,便于后续调用。
python
from typing import List, Optional
from typing import List, Dict
from data_juicer.ops.base_op import Filter, Mapper
import daft
from daft import DataType, col, Series
# 通用装饰器/适配器:将 Data-Juicer 算子转换为 Daft UDF 类。
def dj_operator_to_daft(
dj_op_instance,
input_columns: List[str],
output_columns: Optional[Dict[str, DataType]] = None,
resource_config: Dict = None):
"""
通用装饰器/适配器:将 Data-Juicer 算子转换为 Daft UDF 类。
Args:
dj_op_instance: 初始化的 Data-Juicer 算子实例。
input_columns: 算子需要的输入列名列表 (对应 Data-Juicer 的 text_key, image_key 等)。
output_columns: 算子输出的列名及类型 (用于 Daft return_dtype)。
resource_config: Daft 资源配置 (gpus, num_cpus 等)。
"""
is_batched_op = dj_op_instance.is_batched_op()
is_filter_op = isinstance(dj_op_instance, Filter)
is_mapper_op = isinstance(dj_op_instance, Mapper)
is_struct_output = (output_columns and len(output_columns) > 1)
if is_mapper_op:
output_column_keys = list(output_columns.keys())
# 1. 定义 Daft UDF 类
class DaftDJOperator:
def __init__(self):
self.op = dj_op_instance
def __call__(self, *args):
# args 是对应 input_columns 的 Series 列表
batch_size = len(args[0])
results = []
if is_batched_op:
# 注意:这里 args 里的数据顺序和 input_columns 要保持一致
data_dict = {col: arg.to_pylist() for col, arg in zip(input_columns, args)}
# TODO: 将 __dj__stats__ 里存的结果一并输出到新的列
batch_size = len(data_dict[input_columns[0]])
if is_filter_op and "__dj__stats__" not in data_dict:
data_dict["__dj__stats__"] = [{} for _ in range(batch_size)]
dj_inputs = data_dict
if is_filter_op:
# Filter 逻辑: compute_stats -> process
# 1. 计算统计值 (如 nsfw score)
sample_with_stats = self.op.compute_stats(dj_inputs)
# 2. 根据统计值决定是否保留
results = list(self.op.process(sample_with_stats))
elif is_mapper_op:
# Mapper 逻辑: 直接 process
processed_sample = self.op.process(dj_inputs)
# 提取输出列
# 注意:Mapper 可能修改原列或新增列,这里简化为提取 output_columns 定义的列
# 如果是多列输出,需要返回 Struct
if is_struct_output:
# struct datatype: [{'text': '', 'frames': ['1.jpg']}, {'text': '', 'frames': ['2.jpg']}]
results = [dict(zip(output_column_keys, values)) for values in zip(*(processed_sample[k] for k in output_column_keys))]
else:
try:
results = processed_sample[output_column_keys[0]]
except Exception as e:
# raise e
return [None] * batch_size
else:
raise NotImplementedError
else:
data_list = [{} for _ in range(batch_size)]
for k_i, key in enumerate(input_columns):
for b_i in range(batch_size):
data_list[b_i][key] = args[k_i][b_i]
if is_filter_op and "__dj__stats__" not in data_list[0]:
for i in range(batch_size):
data_list[i]["__dj__stats__"] = {}
samples = data_list
for sample in samples:
if is_filter_op:
# Filter 逻辑: compute_stats -> process
sample_with_stats = self.op.compute_stats(sample)
results.append(self.op.process(sample_with_stats))
elif is_mapper_op:
# Mapper 逻辑: 直接 process
processed_sample = self.op.process(sample)
# 提取输出列
# 注意:Mapper 可能修改原列或新增列,这里简化为提取 output_columns 定义的列
# 如果是多列输出,需要返回 Struct 或 Tuple,这里为了通用性,
# 建议 Mapper 返回 Struct,Filter 返回 Boolean
if is_struct_output:
row_res = {k: processed_sample[k] for k in output_column_keys}
else:
row_res = processed_sample[output_column_keys[0]]
results.append(row_res)
else:
raise NotImplementedError
return Series.from_pylist(results)
# 2. 应用 Daft 装饰器
if resource_config is None:
resource_config = {}
if output_columns:
if is_struct_output:
ret_dtype = DataType.struct(output_columns)
else:
ret_dtype = list(output_columns.values())[0]
elif is_filter_op:
ret_dtype = DataType.bool()
else:
raise ValueError('output_columns must be provided for Mapper')
@daft.udf(return_dtype=ret_dtype, **resource_config)
class WrappedBatchOp(DaftDJOperator):
def __call__(self, *args):
return super().__call__(*args)
return WrappedBatchOp视频分割
这个功能我们直接在 Daft 框架中 引用 DataJuicer 的算子进行处理。采用基于关键帧的视频分割方法,通过识别并提取视频中具有代表性的关键帧,实现对连续视频流的语义划分。该过程能够自动输出划分后的场景片段,并为每个片段生成对应的视频剪辑 clip。
将视频切分后的clip保存在save_dir参数指定的路径下:
将切分后的clip保存到./outputs/clips/文件夹下,并返回clip bytes:
python
import os
from data_juicer.ops.mapper import VideoSplitByKeyFrameMapper
output_path = './outputs'
split_video_op = VideoSplitByKeyFrameMapper(
keep_original_sample=False,
legacy_split_by_text_token=False,
save_dir=os.path.join(output_path, 'clips'),
save_field="clips",
ffmpeg_extra_args="-movflags frag_keyframe+empty_moov",
output_format="bytes", # 'path'
skip_op_error=False,
batch_mode=True,
video_backend='ffmpeg',
)
# 使用通用适配器转换算子
VideoSplitByKeyFrameMapperUDF = dj_operator_to_daft(
dj_op_instance=split_video_op,
input_columns=["videos", "text"], # 需要和运行daft时,输入的列 df["text"], df["nested_keyframes"]保持一致
output_columns={"clips": DataType.list(daft.DataType.binary())},
resource_config={
"num_cpus": 4,
"batch_size": 10}
)时长过滤
获取每个视频的时长(单位:s),如果视频不存在或者读取失败,时长记为-1。
python
import os
import logging
import subprocess
import tempfile
import daft
@daft.udf(return_dtype=daft.DataType.float64(), num_cpus=2)
def get_video_duration(video_series):
"""UDF函数:获取视频时长(秒)"""
videos = video_series.to_pylist()
results = []
for video in videos:
if isinstance(video, bytes):
with tempfile.NamedTemporaryFile(suffix='.mp4', delete=True) as temp_file:
# 写入视频数据
temp_file.write(video)
temp_file.flush() # 确保数据写入磁盘
video = temp_file.name
cmd = [
"ffprobe",
"-v", "error",
"-show_entries", "format=duration",
"-of", "csv=p=0",
video
]
result = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
if result.returncode != 0:
logging.error(f"FFprobe error: {result.stderr.strip()}")
results.append(-1.0) # 用-1表示文件不存在
continue
try:
results.append(float(result.stdout))
except Exception as e:
logging.error(f"Failed to parse output of FFprobe: {e}")
results.append(-1.0) # 用-1表示文件不存在
else:
if not os.path.exists(video):
results.append(-1.0) # 用-1表示文件不存在
continue
cmd = [
"ffprobe",
"-v", "error",
"-show_entries", "format=duration",
"-of", "csv=p=0",
video
]
result = subprocess.run(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
if result.returncode != 0:
logging.error(f"FFprobe error: {result.stderr.strip()}")
results.append(-1.0) # 用-1表示文件不存在
continue
try:
results.append(float(result.stdout))
except Exception as e:
logging.error(f"Failed to parse output of FFprobe: {e}")
results.append(-1.0) # 用-1表示文件不存在
return results视频抽帧
支持抽取视频的所有帧(extract_all_frames)或者关键帧(extract_key_frames),并且将帧保存在output_dir参数指定的路径下。
python
import io
from PIL import Image
@daft.udf(num_cpus=2, return_dtype=DataType.list(DataType.binary()))
def extract_keyframes(video_series):
videos = video_series.to_pylist()
results = []
from data_juicer.utils.video_utils import create_video_reader
for video in videos:
video_reader = create_video_reader(video_source=video, backend='ffmpeg')
frames = video_reader.extract_keyframes().frames # numpy rgb
cur_frames_bytes = []
for i, frame in enumerate(frames):
frame = Image.fromarray(frame)
stream = io.BytesIO()
frame.save(stream, format="jpeg")
cur_frames_bytes.append(stream.getvalue())
results.append(cur_frames_bytes)
return results内容安全过滤
通过预训练的 NSFW 检测模型实现,识别包含敏感内容的画面,为视频帧打分。可以根据打分结果过滤不合格的剪辑 clip。
该 UDF 输入为一个视频的多帧路径,返回该视频的安全得分值。
python
from PIL import Image
import torch
from transformers import AutoModelForImageClassification, ViTImageProcessor
def load_image(path_or_bytes):
if isinstance(path_or_bytes, bytes):
img = Image.open(io.BytesIO(path_or_bytes)).convert("RGB")
else:
img = Image.open(path_or_bytes).convert("RGB")
return img
@daft.udf(
return_dtype=DataType.float64(),
num_gpus=0.02, # 1GB
concurrency=50
)
class VideoNSFWUDF:
def __init__(self, reduce_mode: str = "avg"):
self.reduce_mode = reduce_mode
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.model = AutoModelForImageClassification.from_pretrained("Falconsai/nsfw_image_detection").to(self.device)
self.processor = ViTImageProcessor.from_pretrained('Falconsai/nsfw_image_detection')
def __call__(self, videos_frames_series):
videos_frames = videos_frames_series.to_pylist()
results = []
for frames in videos_frames:
images = [load_image(frame) for frame in frames]
with torch.no_grad():
inputs = self.processor(images=images, return_tensors="pt")
inputs = inputs.to(self.model.device)
outputs = self.model(**inputs)
logits = outputs.logits
cur_scores = [scores[1] for scores in torch.softmax(logits, dim=-1)]
cur_scores = torch.Tensor(cur_scores)
if self.reduce_mode == "avg":
cur_score = cur_scores.mean()
elif self.reduce_mode == "max":
cur_score = cur_scores.max()
else:
cur_score = cur_scores.min()
results.append(float(cur_score))
return results美学评分过滤
基于预训练美学评估模型,剔除画面质量不佳的样本。可确保输入后续模块的视频样本均具备良好的视觉质量基础,为语义理解、内容分析等下游任务提供可靠的视觉素材。
该 UDF 输入为一个视频的多帧路径,返回该视频的美学得分值。
python
from transformers import CLIPProcessor
import aesthetics_predictor as aes_pred
@daft.udf(
return_dtype=DataType.float64(),
num_gpus=0.03, # 1500MB
concurrency=30
)
class AestheticsScorerUDF:
def __init__(self,
hf_scorer_model: str = "shunk031/aesthetics-predictor-v2-sac-logos-ava1-l14-linearMSE",
reduce_mode: str = "min"):
"""初始化美学评分模型"""
device = "cuda" if torch.cuda.is_available() else "cpu"
model_params = {}
if device.startswith("cuda"):
model_params["device_map"] = device
self.processor = CLIPProcessor.from_pretrained(hf_scorer_model, **model_params)
if "v1" in hf_scorer_model:
self.model = aes_pred.AestheticsPredictorV1.from_pretrained(hf_scorer_model, **model_params)
elif "v2" in hf_scorer_model and "linear" in hf_scorer_model:
self.model = aes_pred.AestheticsPredictorV2Linear.from_pretrained(hf_scorer_model, **model_params)
elif "v2" in hf_scorer_model and "relu" in hf_scorer_model:
self.model = aes_pred.AestheticsPredictorV2ReLU.from_pretrained(hf_scorer_model, **model_params)
else:
raise ValueError("Not support {}".format(hf_scorer_model))
self.need_normalized_by_ten = "shunk031/aesthetics-predictor" in hf_scorer_model
self.reduce_mode = reduce_mode
def __call__(self, videos_frames_series):
videos_frames = videos_frames_series.to_pylist()
results = []
for frames in videos_frames:
if not frames or not len(frames):
results.append(0.0)
continue
images = [load_image(frame) for frame in frames]
# compute aesthetics_scores
inputs = self.processor(images=images, return_tensors="pt").to(self.model.device)
with torch.no_grad():
outputs = self.model(**inputs)
if self.need_normalized_by_ten:
aesthetics_score = outputs.logits / 10.0
else:
aesthetics_score = outputs.logits
if self.reduce_mode == "avg":
aesthetics_score = float(aesthetics_score.mean())
elif self.reduce_mode == "max":
aesthetics_score = float(aesthetics_score.max())
else:
aesthetics_score = float(aesthetics_score.min())
results.append(aesthetics_score)
return results视频描述生成
这里我们直接在 Daft 框架中 引用 DataJuicer 的算子进行处理。
同"动态评分过滤算子",这里为适配 DataJuicer 的数据格式,也使用了nested_keyframes嵌套字段。该 UDF 输入为一个视频的多帧路径(嵌套结构),返回该视频的文本描述。
python
from data_juicer.ops.mapper import VideoCaptioningFromVideoMapper
video_caption_op = VideoCaptioningFromVideoMapper(
hf_video_blip='kpyu/video-blip-opt-2.7b-ego4d',
trust_remote_code=True,
caption_num=1,
keep_original_sample=False,
frame_field='nested_keyframes',
frame_num=3,
legacy_split_by_text_token=False,
text_update_strategy='rewrite',
skip_op_error=False,
batch_mode=True
)
# 使用通用适配器转换算子
VideoCaptionUDFClass = dj_operator_to_daft(
dj_op_instance=video_caption_op,
input_columns=["text", "nested_keyframes"], # 需要和运行daft时,输入的列 df["text"], df["nested_keyframes"]保持一致
output_columns={"text": DataType.string()},
resource_config={
"num_gpus": 0.33, # 20GB
"concurrency":24,
"batch_size": 10}
)运行pipeline
使用daft框架,端到端运行整个链路:
python
import os
import time
import uuid
import daft
from daft import DataType, Series
if __name__ == "__main__":
# 设置ray backend
daft.set_runner_ray(address="auto")
s_time = time.time()
data_dir = './data/Youku-AliceMind/caption/validation/videos'
output_path = './outputs/daft/'
df = daft.from_glob_path(data_dir).with_column_renamed('path', 'videos')
df = df.with_column(
'videos',
df['videos'].apply(
lambda x: [x.replace('file://', '')],
return_dtype=DataType.list(DataType.string())
)
)
df = df.with_column('text', daft.lit("")) # 占位,后续会被VideoCaptionUDFClass覆盖
df = df.with_column("clips", VideoSplitByKeyFrameMapperUDF(df["videos"], df["text"]))
df = df.explode("clips")
df = df.with_columns({
"id": daft.lit(uuid.uuid4().hex) # 随机 ID 列
})
df = df.with_column(
"video_duration",
get_video_duration(df["clips"])).where(daft.col("video_duration") >= 2)
df = df.with_column(
"keyframes",
extract_keyframes(df["clips"]))
video_nsfw_udf = VideoNSFWUDF.with_init_args(reduce_mode="avg")
df = df.with_column(
"video_nsfw_score",
video_nsfw_udf(df["keyframes"])
).where(daft.col("video_nsfw_score") <= 0.5)
# 嵌套列表以适配后续DataJuicer算子UDF输入格式要求
df = df.with_column(
"nested_keyframes",
df["keyframes"].apply(
lambda x: [x],
return_dtype=daft.DataType.list(daft.DataType.list(daft.DataType.binary())))
)
aesthetics_scorer = AestheticsScorerUDF.with_init_args(
hf_scorer_model="shunk031/aesthetics-predictor-v2-sac-logos-ava1-l14-linearMSE",
reduce_mode="min")
df = df.with_column(
"video_frames_aesthetics_score",
aesthetics_scorer(df["keyframes"])
).where(daft.col("video_frames_aesthetics_score") >= 0.4)
df = df.with_column(
"text",
VideoCaptionUDFClass(df["text"], df["nested_keyframes"])
)
df = df.select(
'id',
'clips',
'text',
'video_duration',
'video_frames_aesthetics_score',
'video_nsfw_score')
df.write_parquet(
os.path.join(output_path, 'out_parquet'),
write_mode="overwrite"
)
print(f'>>> total cost time: {time.time() - s_time}')四、产品介绍
阿里云人工智能平台PAI
PAI是企业级的一站式AI工程平台,凭借弹性高性能计算集群、卓越的资源调度与管理、与开源生态深度集成、全托管体验 等核心优势,使其成为处理多模态海量数据的理想选择。同时,对于数据处理管线,PAI与通义实验室 DataJuicer 团队合作,致力于构建一套高丰富度、高易用,高性能,高稳定性的数据处理管线,PAI-DLC 已上线 DataJuicer 框架,为用户提供丰富的算子、大规模数据、样本级/job级的自动容错、资源预估功能和卓越的线性扩展性能。
阿里云流式数据湖仓 Paimon
Apache Paimon 是一种流批统一的湖存储格式,支持高吞吐的写入和低延迟的查询。目前阿里云开源大数据平台 E-MapReduce 常见的计算引擎(例如Flink、Spark、Hive或Trino)都与 Paimon 有着较为完善的集成度。可借助 Apache Paimon 快速地在 HDFS 或者云端 OSS 上构建自己的数据湖存储服务,并接入上述计算引擎实现数据湖的分析,详情请参见 Apache Paimon。
产品架构