大家好,我是孟健。
昨天 Kimi Code 悄悄推了一条通知:K2.6-code-preview 已上线,向所有订阅用户开放。今天我把 Hermes 里 23 个 Agent 全切了过去,跑了整整一天。
结论先说:K2.6 目前是我用过的国产编程模型里最强的,思考和执行都比昨天刚切的 GLM 5.1 更稳定、质量更高。但有两个真实痛点,有一个比较重。
01 为什么从 GLM 5.1 切过来
昨天我刚把 Hermes 换到了 GLM 5.1,体验还不错,速度也快。但没跑多久就遇到了一个实际痛点:429 限流。
Hermes 有 23 个 Agent,多 Agent 并发场景下,GLM 5.1 的频率限制会频繁触发。一旦某个 Agent 跑长任务触发限流,整个流水线就得等,后面的 Agent 也跟着卡。
今天看到 K2.6-code-preview 上线的通知,正好解决这个问题------Kimi Code 的订阅套餐 API 不设速率限制,多 Agent 可以并发跑。我直接下了切换指令。
02 怎么接入的
我的 Agent 基础设施跑在 Hermes 上------23 个 Agent 各有分工,通过 Telegram 协调,模型配置集中管理。
Hermes 有个内置的批量切换技能,一条命令下去:23 个配置文件同步更新,provider 切到 kimi-coding,base_url 指向 https://api.kimi.com/coding/v1,然后重启全部 gateway 服务。
从下指令到全部 Agent 上线,不到 5 分钟。
中间遇到一个坑:全局 .env 里有 KIMI_API_KEY,但 23 个 Agent profile 各自的目录里没有。K2.6 skill 自动检测到这个问题,把 key 同步到所有 profile 的 .env,重启生效。
切完之后 Hermes 就在跑了------下面这个站,就是今天 K2.6 驱动的结果之一。
这是 hermes101.pages.dev,Hermes 的小白入门站,今天用 K2.6 跑完整做站流水线的成果。
03 今天跑了什么
换上 K2.6 之后,我直接让它接着干活:完整跑了一遍 hermes101 的做站流水线。
整个流程分 11 步,今天 K2.6 跑完了前 7 步:
- Step 1 墨探:市场侦察 + 关键词调研(输出 12KB 报告)
- Step 2 墨策:产品定义 + PRD(13KB,方向拍板)
- Step 3+4 墨账+墨盾:定价校准 + 合规评估(并行执行)
- Step 5 墨引:SEO 策略规划
- Step 6 墨影:转化页设计(design-system + 高保真 mockup)
- Step 7 墨界:Astro 静态站前端开发(构建通过,部署上线)
全程我没有人工介入执行细节。 K2.6 驱动小墨在 Telegram 群里协调各 Agent,自动派单、追踪进度、发现卡点就补推。今天共产生 26 个 sessions。
中间有个插曲:墨策第一版 PRD 把"入门站"写成了"AI 编程评测站",完全跑偏。K2.6 发现后主动回滚,删掉全部错误产物,重新发起第二轮。
它没有等我,自己判断出了问题,自己清场重来。 这是 GPT 时代我没有明显感受到的东西。
04 优点:不限流、稳定、质量高
用了一整天,三个点是真实体感:
第一,不限流。 这是今天从 GLM 5.1 切换过来的核心原因。23 个 Agent 同时在线,高频工具调用,全天没有遇到 429 报错。多 Agent 并发场景下,这一点价值很明显。
第二,稳定。 整天 26 个 sessions,没有遇到模型返回乱码、工具调用失败、或者输出结构崩掉的情况。Agent 在跑复杂多步任务时(比如墨策写 PRD、墨引做 SEO 规划),输出结构清晰、前后一致。比 GLM 5.1 更稳。
第三,质量高。 K2.6 的回答比 GLM 5.1 更有"规划感"。墨策写 PRD,会主动列出竞品对比、用户故事、功能优先级;墨引做 SEO 规划,先分析搜索意图再给内容方向,逻辑更清楚。
拿来做横向对比:目前国产编程模型里,K2.6 是我实测下来最强的。 思考和执行比 GLM 5.1 更稳定,质量更高。
05 痛点一:慢
K2.6 最明显的缺点是推理速度慢。
这不是感觉,是实打实的等待。单个请求从发出到第一个 token 返回,比 GLM 5.1 慢了一个量级。Agent 在执行多步任务时,每一步之间都有明显停顿。
今天跑 hermes101 流水线,单个步骤的 Agent 执行时间偏长,整个流程下来比预期花了更多时间。GLM 5.1 同样的任务节奏更紧凑。
K2.6 底层是 MoE 架构(1T 参数,激活 32B),推理时的调度开销比稠密模型大,这个速度差距在预期内。K2.6-code-preview 目前还是 preview 状态,推理优化应该还没到位。
如果像我这样把它当 Agent 底座跑长流程多步任务,慢是真的痛。 等一个工具调用返回,有时候要比 GLM 多等 5-10 秒。23 个 Agent 同时在跑,这个感受会被放大。
06 痛点二:额度消耗比预想快
这个是今天发现的,有点超预期。
Kimi Code 订阅分几档,我用的是 Allegretto 会员。额度是按周刷新的,不是按月。
今天一天的测试下来,检查了一下控制台:
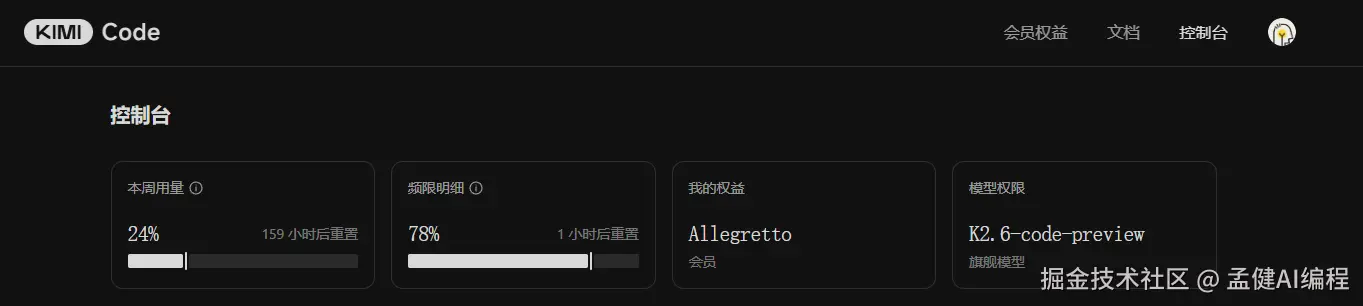
截图显示:本周用量 24%,频限明细 78%(1 小时后重置)。周额度 159 小时后重置。
这是今天一天高强度跑完整做站流水线的消耗。
账怎么算:
- 今天跑了 7 步完整流水线,26 个 sessions,本周额度已消耗 24%
- 频限明细已到 78%------再高强度跑 1 小时,今天的频次额度就顶了
- 按本周用量的节奏,如果每天都这样高强度跑,一周内周额度会见底
- 周额度 159 小时后才重置,不是随时能补的
这两个数字放在一起看:频限 78% 说明今天已经接近触顶,周额度 24% 说明这才周一。重度 Agent 开发的用量压力,比普通用户感知要强一个量级。
Kimi Code 的额度机制是按周刷新,这个细节很多人不知道。不是每月额度,是每周。
做重度 Agent 开发的,要提前算好账再订阅。199 套餐不是买断,是每周的窗口期。
07 值不值得切?
给一个判断:
如果你用 AI 辅助日常编程(单次对话、改代码、解释报错),K2.6 性价比很高。不限流、稳定、质量好,订阅完全够用。
如果你像我一样把它当 Agent 底座跑长流水线,两个问题都会被放大:慢的感受更明显,额度也消耗得更快。需要判断是否值得为质量提升付出这两个代价。
我个人还会继续用,原因很直接:
- 多 Agent 并发场景,不限流是刚需。GLM 5.1 的 429 问题不解决,流水线跑不稳
- K2.6 的思考质量和执行稳定性,比 GLM 5.1 有明显提升,对复杂任务影响很大
- 速度问题随着版本迭代会改善,现在还是 preview
如果你只是想找一个便宜好用的 AI 编程助手,不跑 Agent 框架,GLM 5.1 也是一个不错的选择,速度更快,价格更低。
K2.6 的能力天花板已经到了一个新高度。问题是基础设施还没跟上:推理速度和套餐额度,都需要给出更好的答案。
工具就摆在那里。要不要切,账算清楚再说。
本文所有测试均基于今日实际运行记录,截图来自真实控制台和站点。
👋 我是孟健,前腾讯 T11 / 前字节技术 Leader,现在全职做 AI 编程。
🔥 更多 AI 编程实战:
- GitHub:@mengjian-github
- 专栏:AI编程实战
觉得有用?点赞+收藏 就是最大支持 🙏