实验环境确认(在开始前)
在开始前,请确保:
- ✅ Hadoop 已启动(
jps能看到 NameNode、DataNode 等) - ✅ MySQL 已启动(
systemctl status mysqld) - ✅ Hive 已安装并初始化元数据库(参考实验一)
- ✅ Hive 元数据库使用 MySQL(不是 Derby)
- ✅ 已创建实验数据表:
tbDate、tbStock、tbStockDetail(第九周需要) - ✅ IDE:IntelliJ IDEA 已安装
- ✅ 虚拟机与宿主机网络互通(如果是远程连接)
第九周实验:Hive JDBC 访问
步骤1:配置 Hive 并启动 HiveServer2
1.1 修改 Hive 配置文件
编辑 $HIVE_HOME/conf/hive-site.xml,在 <configuration> 内添加以下内容:
xml
<!-- 允许不模拟用户 -->
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<!-- 绑定所有网卡,允许远程连接 -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>0.0.0.0</value>
</property>
<!-- HiveServer2 端口 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
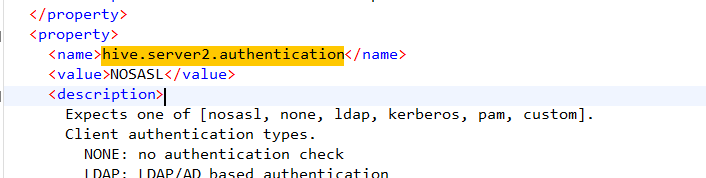
<!-- 认证方式:简单模式 -->
<property>
<name>hive.server2.authentication</name>
<value>NOSASL</value>
</property>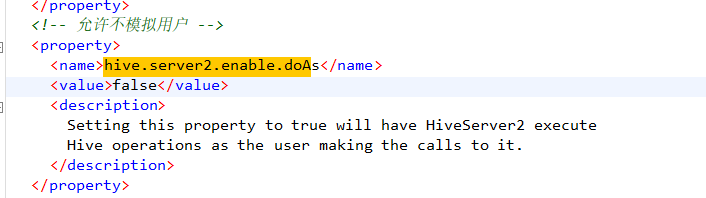


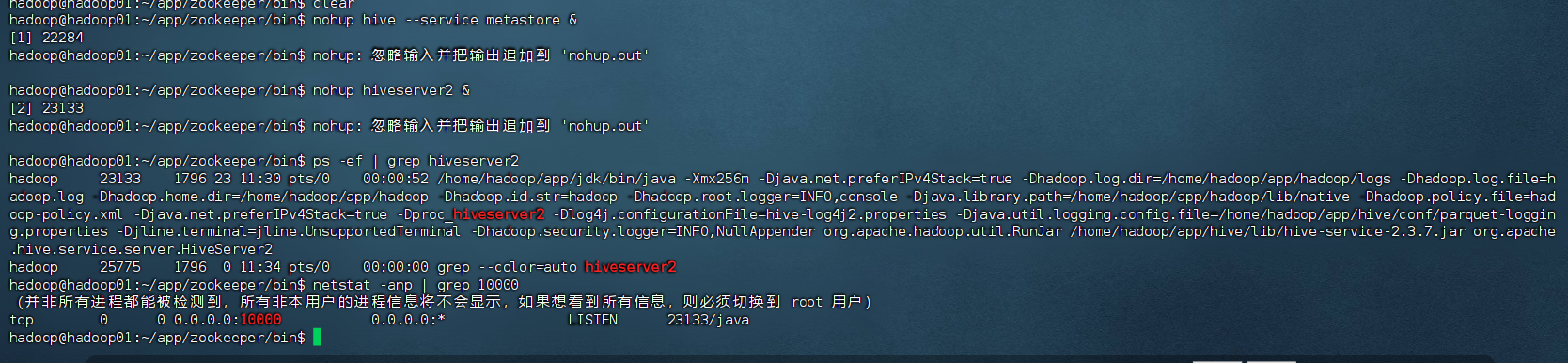
1.2 启动 Metastore 和 HiveServer2
bash
# 启动 Metastore(后台运行)
nohup hive --service metastore &
# 启动 HiveServer2(后台运行)
nohup hiveserver2 &
# 检查是否启动成功
ps -ef | grep hiveserver2
netstat -anp | grep 10000⚠️ 如果端口被占用,可以换一个端口(如 10001),并同步修改
hive-site.xml和 Java 代码中的连接串。
步骤2:创建 Maven 项目
- 打开 IntelliJ IDEA → New Project → Maven
- GroupId:
com.example,ArtifactId:hive-jdbc-demo - 在
pom.xml中添加依赖(见下文)
pom.xml 完整依赖
xml
<dependencies>
<!-- Hive JDBC -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.3.7</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- log4j 必须和 Hive 匹配 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.6.2</version>
</dependency>
</dependencies>点击 Maven 刷新按钮(Reload All Maven Projects)
步骤3:JDBC 操作 Hive(核心代码)
创建一个 Java 类:HiveJDBCExample.java
3.1 连接测试(Show Databases)
java
package com.example;
import java.sql.*;
public class HiveJDBCExample {
public static void main(String[] args) {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
// 1. 加载驱动
Class.forName("org.apache.hive.jdbc.HiveDriver");
// 2. 获取连接(IP、端口、用户名、密码根据实际修改)
// conn = DriverManager.getConnection(
// "jdbc:hive2://192.168.66.200:10000/default",
// "root",
// "123456"
// );
conn = DriverManager.getConnection(
"jdbc:hive2://192.168.255.145:10000/default;auth=noSasl",
"aaaa",
"aaaa"
);
// 3. 创建 Statement
stmt = conn.createStatement();
// 4. 执行查询
String sql = "show databases";
rs = stmt.executeQuery(sql);
// 5. 输出结果
while (rs.next()) {
System.out.println(rs.getString(1));
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 6. 关闭资源
try { if (rs != null) rs.close(); } catch (Exception e) {}
try { if (stmt != null) stmt.close(); } catch (Exception e) {}
try { if (conn != null) conn.close(); } catch (Exception e) {}
}
}
}
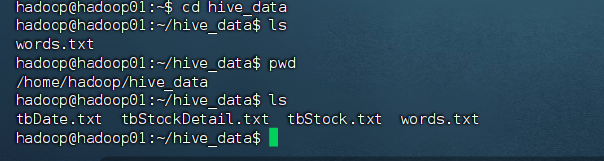
从超星下载 tbDate.txt、tbStock.txt、tbStockDetail.txt)
先说原理:
3.2 创建数据库
java
String createDbSQL = "CREATE DATABASE IF NOT EXISTS mytest";
stmt.execute(createDbSQL);
System.out.println("数据库创建成功");3.3 创建雇员表(示例)
java
String createTableSQL = "CREATE TABLE IF NOT EXISTS employee (" +
"id INT, " +
"name STRING, " +
"age INT, " +
"department STRING" +
") ROW FORMAT DELIMITED FIELDS TERMINATED BY ','";
stmt.execute(createTableSQL);
System.out.println("表创建成功");3.4 插入数据
java
// Hive 通常不支持单条 INSERT,常用 LOAD DATA 或 INSERT ... VALUES(较新版本支持)
String insertSQL = "INSERT INTO employee VALUES " +
"(1, '张三', 30, '技术部'), " +
"(2, '李四', 25, '市场部')";
stmt.execute(insertSQL);
System.out.println("数据插入成功");3.5 查询数据
java
String querySQL = "SELECT * FROM employee";
rs = stmt.executeQuery(querySQL);
while (rs.next()) {
System.out.println(rs.getInt("id") + ", " +
rs.getString("name") + ", " +
rs.getInt("age") + ", " +
rs.getString("department"));
}步骤4:基于给定表结构的查询(实验要求)
你需要先创建三张表并加载数据
建表语句示例
sql
-- tbDate
CREATE TABLE tbDate(
date_id STRING,
year_month STRING,
year INT,
month INT,
day INT,
week STRING,
week_of_year INT,
quarter INT,
xun STRING,
half_month STRING
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
-- tbStock
CREATE TABLE tbStock(
order_id STRING,
location STRING,
date_id STRING
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
-- tbStockDetail
CREATE TABLE tbStockDetail(
order_id STRING,
line_no INT,
product STRING,
quantity INT,
amount DOUBLE
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';加载数据(Hive 内执行)
sql
// LOAD DATA LOCAL INPATH '/path/to/tbDate.txt' INTO TABLE tbDate;
// LOAD DATA LOCAL INPATH '/path/to/tbStock.txt' INTO TABLE tbStock;
// LOAD DATA LOCAL INPATH '/path/to/tbStockDetail.txt' INTO TABLE tbStockDetail;
LOAD DATA LOCAL INPATH '/home/hadoop/hive_data/tbDate.txt' INTO TABLE tbDate;
LOAD DATA LOCAL INPATH '/home/hadoop/hive_data/tbStock.txt' INTO TABLE tbStock;
LOAD DATA LOCAL INPATH '/home/hadoop/hive_data/tbStockDetail.txt' INTO TABLE tbStockDetail;实验要求的三个查询(JDBC 执行)
① 按年统计销售额,年份升序
sql
SELECT d.year, SUM(detail.amount) AS total_sales
FROM tbStockDetail detail
JOIN tbStock s ON detail.order_id = s.order_id
JOIN tbDate d ON s.date_id = d.date_id
GROUP BY d.year
ORDER BY d.year ASC;② 按交易日期-订单号分组统计销售额
sql
SELECT s.date_id, s.order_id, SUM(detail.amount) AS total
FROM tbStockDetail detail
JOIN tbStock s ON detail.order_id = s.order_id
GROUP BY s.date_id, s.order_id;③ 统计年度销售额最大的交易日期-订单号
sql
SELECT year, date_id, order_id, total
FROM (
SELECT d.year, s.date_id, s.order_id, SUM(detail.amount) AS total,
RANK() OVER (PARTITION BY d.year ORDER BY SUM(detail.amount) DESC) AS rk
FROM tbStockDetail detail
JOIN tbStock s ON detail.order_id = s.order_id
JOIN tbDate d ON s.date_id = d.date_id
GROUP BY d.year, s.date_id, s.order_id
) t
WHERE rk = 1;接着是操作:
完整代码:
java
package com.example;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class HiveJDBCExample {
public static void main(String[] args) {
Connection conn = null;
Statement stmt = null;
ResultSet rs = null;
try {
// 1. 加载驱动
Class.forName("org.apache.hive.jdbc.HiveDriver");
// 2. 获取连接
conn = DriverManager.getConnection(
"jdbc:hive2://192.168.255.145:10000/default;auth=noSasl",
"aaaa",
"aaaa"
);
System.out.println("Hive 连接成功");
// 3. 创建 Statement
stmt = conn.createStatement();
// =========================
// 步骤1:创建数据库并切换
// =========================
String createDbSQL = "CREATE DATABASE IF NOT EXISTS mytest";
stmt.execute(createDbSQL);
System.out.println("数据库 mytest 创建成功");
stmt.execute("USE mytest");
System.out.println("已切换到数据库 mytest");
// =========================
// 步骤2:创建三张实验表
// =========================
String createTbDate = "CREATE TABLE IF NOT EXISTS tbDate(" +
"date_id STRING, " +
"year_month STRING, " +
"year INT, " +
"month INT, " +
"day INT, " +
"week STRING, " +
"week_of_year INT, " +
"quarter INT, " +
"xun STRING, " +
"half_month STRING" +
") ROW FORMAT DELIMITED FIELDS TERMINATED BY ','";
String createTbStock = "CREATE TABLE IF NOT EXISTS tbStock(" +
"order_id STRING, " +
"location STRING, " +
"date_id STRING" +
") ROW FORMAT DELIMITED FIELDS TERMINATED BY ','";
String createTbStockDetail = "CREATE TABLE IF NOT EXISTS tbStockDetail(" +
"order_id STRING, " +
"line_no INT, " +
"product STRING, " +
"quantity INT, " +
"amount DOUBLE" +
") ROW FORMAT DELIMITED FIELDS TERMINATED BY ','";
stmt.execute(createTbDate);
stmt.execute(createTbStock);
stmt.execute(createTbStockDetail);
System.out.println("三张表创建成功");
// =========================
// 步骤3:加载数据
// =========================
stmt.execute("LOAD DATA LOCAL INPATH '/home/hadoop/hive_data/tbDate.txt' OVERWRITE INTO TABLE tbDate");
stmt.execute("LOAD DATA LOCAL INPATH '/home/hadoop/hive_data/tbStock.txt' OVERWRITE INTO TABLE tbStock");
stmt.execute("LOAD DATA LOCAL INPATH '/home/hadoop/hive_data/tbStockDetail.txt' OVERWRITE INTO TABLE tbStockDetail");
System.out.println("数据加载成功");
// =========================
// 步骤4:查询1
// 按年统计销售额,年份升序
// =========================
String sql1 = "SELECT d.year, SUM(detail.amount) AS total_sales " +
"FROM tbStockDetail detail " +
"JOIN tbStock s ON detail.order_id = s.order_id " +
"JOIN tbDate d ON s.date_id = d.date_id " +
"GROUP BY d.year " +
"ORDER BY d.year ASC";
rs = stmt.executeQuery(sql1);
System.out.println("===== 查询1:按年统计销售额 =====");
while (rs.next()) {
System.out.println(rs.getInt("year") + " : " + rs.getDouble("total_sales"));
}
rs.close();
// =========================
// 步骤5:查询2
// 按交易日期-订单号分组统计销售额
// =========================
String sql2 = "SELECT s.date_id, s.order_id, SUM(detail.amount) AS total " +
"FROM tbStockDetail detail " +
"JOIN tbStock s ON detail.order_id = s.order_id " +
"GROUP BY s.date_id, s.order_id";
rs = stmt.executeQuery(sql2);
System.out.println("===== 查询2:按交易日期-订单号分组统计销售额 =====");
while (rs.next()) {
System.out.println(rs.getString("date_id") + " , " +
rs.getString("order_id") + " , " +
rs.getDouble("total"));
}
rs.close();
// =========================
// 步骤6:查询3
// 统计年度销售额最大的交易日期-订单号
// =========================
String sql3 = "SELECT year, date_id, order_id, total " +
"FROM ( " +
" SELECT d.year, s.date_id, s.order_id, SUM(detail.amount) AS total, " +
" RANK() OVER (PARTITION BY d.year ORDER BY SUM(detail.amount) DESC) AS rk " +
" FROM tbStockDetail detail " +
" JOIN tbStock s ON detail.order_id = s.order_id " +
" JOIN tbDate d ON s.date_id = d.date_id " +
" GROUP BY d.year, s.date_id, s.order_id " +
") t " +
"WHERE rk = 1";
rs = stmt.executeQuery(sql3);
System.out.println("===== 查询3:年度销售额最大的交易日期-订单号 =====");
while (rs.next()) {
System.out.println(rs.getInt("year") + " , " +
rs.getString("date_id") + " , " +
rs.getString("order_id") + " , " +
rs.getDouble("total"));
}
System.out.println("实验完成");
} catch (Exception e) {
e.printStackTrace();
} finally {
try { if (rs != null) rs.close(); } catch (Exception ignored) {}
try { if (stmt != null) stmt.close(); } catch (Exception ignored) {}
try { if (conn != null) conn.close(); } catch (Exception ignored) {}
}
}
}运行代码
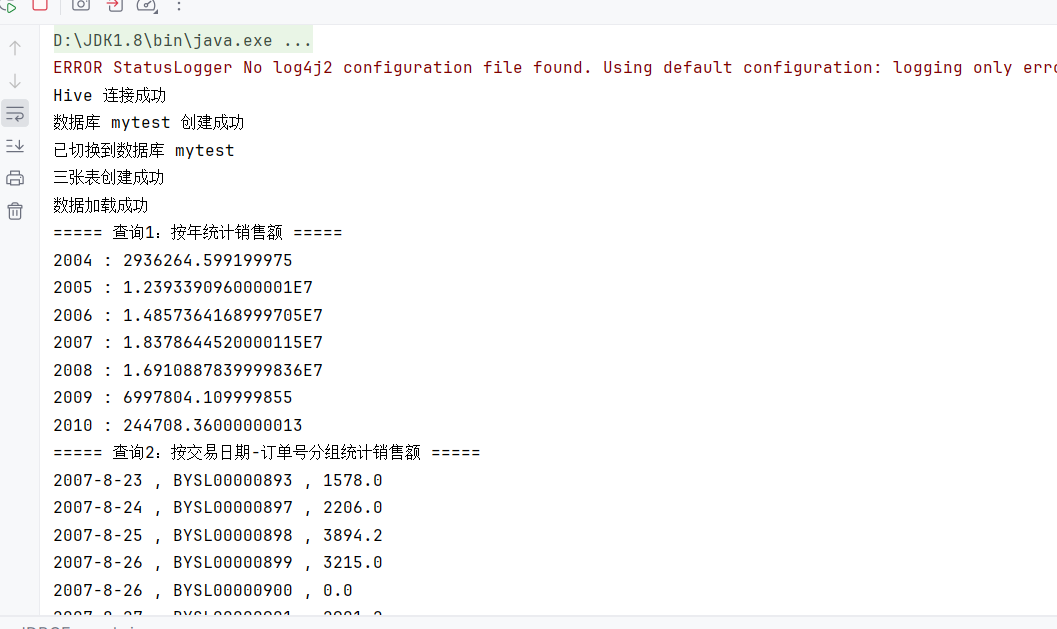
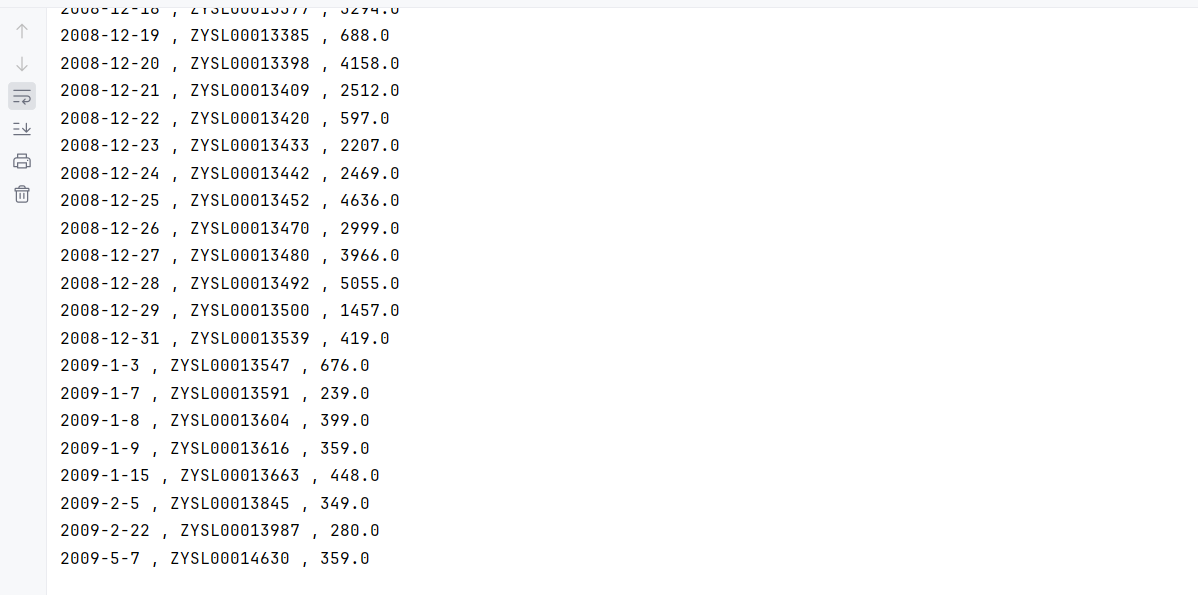
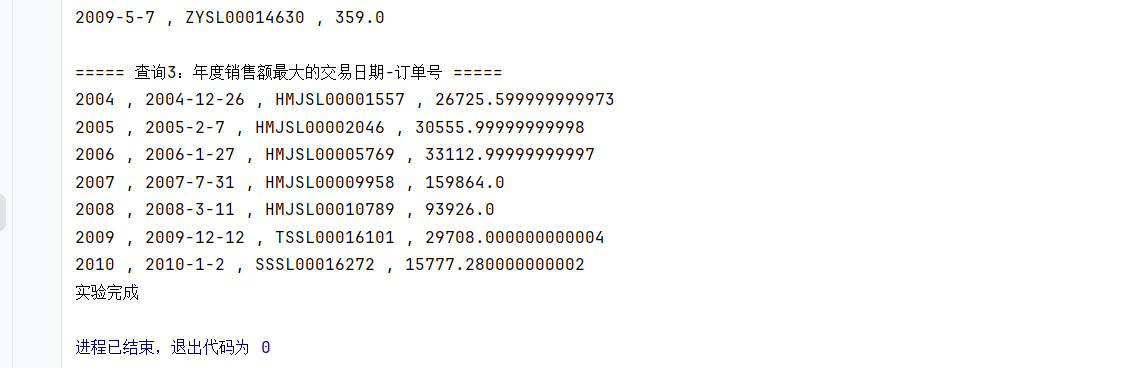
运行了 Java 程序,就已经完成了:建库 + 建表 + 加载数据 + 查询
本实验完成
四、第十周实验:Hive Metastore 元数据获取
步骤1:启动 Metastore 服务(如果未启动)
bash
nohup hive --service metastore &检查端口(默认 9083):
bash
netstat -anp | grep 9083步骤2:Maven 项目配置
新建一个 Maven 项目或在原项目基础上添加依赖:
xml
<dependencies>
<!-- Hive JDBC -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.3.7</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
</dependency>
<!-- log4j 必须和 Hive 匹配 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.6.2</version>
</dependency>
</dependencies>步骤3:Java 代码获取元数据
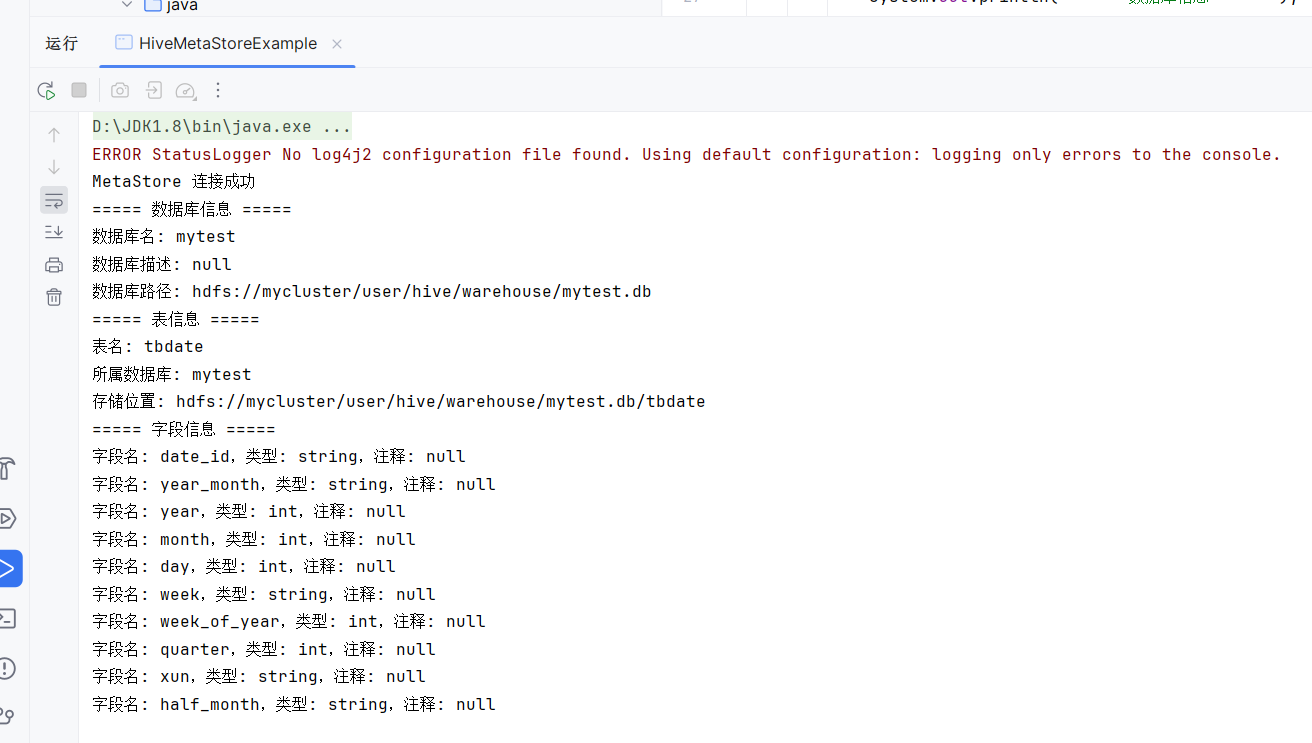
创建 HiveMetaStoreExample.java:
java
import org.apache.hadoop.hive.conf.HiveConf;
import org.apache.hadoop.hive.metastore.HiveMetaStoreClient;
import org.apache.hadoop.hive.metastore.api.Database;
import org.apache.hadoop.hive.metastore.api.FieldSchema;
import org.apache.hadoop.hive.metastore.api.Table;
import java.util.List;
public class HiveMetaStoreExample {
public static void main(String[] args) {
HiveMetaStoreClient client = null;
try {
// 1. 配置连接
HiveConf conf = new HiveConf();
// 改成你的虚拟机实际IP
conf.set("hive.metastore.uris", "thrift://192.168.255.145:9083");
// 2. 创建 MetaStore 客户端
client = new HiveMetaStoreClient(conf);
System.out.println("MetaStore 连接成功");
// 3. 获取数据库信息
Database db = client.getDatabase("mytest");
System.out.println("===== 数据库信息 =====");
System.out.println("数据库名: " + db.getName());
System.out.println("数据库描述: " + db.getDescription());
System.out.println("数据库路径: " + db.getLocationUri());
// 4. 获取表信息
Table table = client.getTable("mytest", "tbDate");
System.out.println("===== 表信息 =====");
System.out.println("表名: " + table.getTableName());
System.out.println("所属数据库: " + table.getDbName());
System.out.println("存储位置: " + table.getSd().getLocation());
// 5. 获取字段信息
List<FieldSchema> fields = client.getSchema("mytest", "tbDate");
System.out.println("===== 字段信息 =====");
for (FieldSchema field : fields) {
System.out.println("字段名: " + field.getName()
+ ",类型: " + field.getType()
+ ",注释: " + field.getComment());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (client != null) {
client.close();
}
} catch (Exception ignored) {
}
}
}
}⚠️ 注意:
employee表需要提前创建,如果没有,可以换成你已有的表名(如tbStock)。
五、常见问题排查
| 问题 | 解决方法 |
|---|---|
Connection refused |
检查 HiveServer2 是否启动,端口 10000 是否开放,防火墙是否关闭 |
ClassNotFoundException |
确认 pom.xml 依赖已下载,IDEA 已刷新 Maven |
No suitable driver |
确认 Class.forName("org.apache.hive.jdbc.HiveDriver") 正确 |
Access denied |
检查 HiveServer2 认证配置,可先设为 NOSASL |
| 连接 Metastore 失败 | 确认 hive --service metastore 已启动,端口 9083 正常 |
| 表不存在 | 先用 Hive CLI 创建表,再用 JDBC/Metastore 访问 |