一、安装spark服务
停止部分服务
在开始安装spark服务之前,我们需要关闭部分服务,因为我们是单独的笔记本并不是真实的计算机集群,可能出现内存不够的情况,我们选择关闭hbase和phoenix服务。
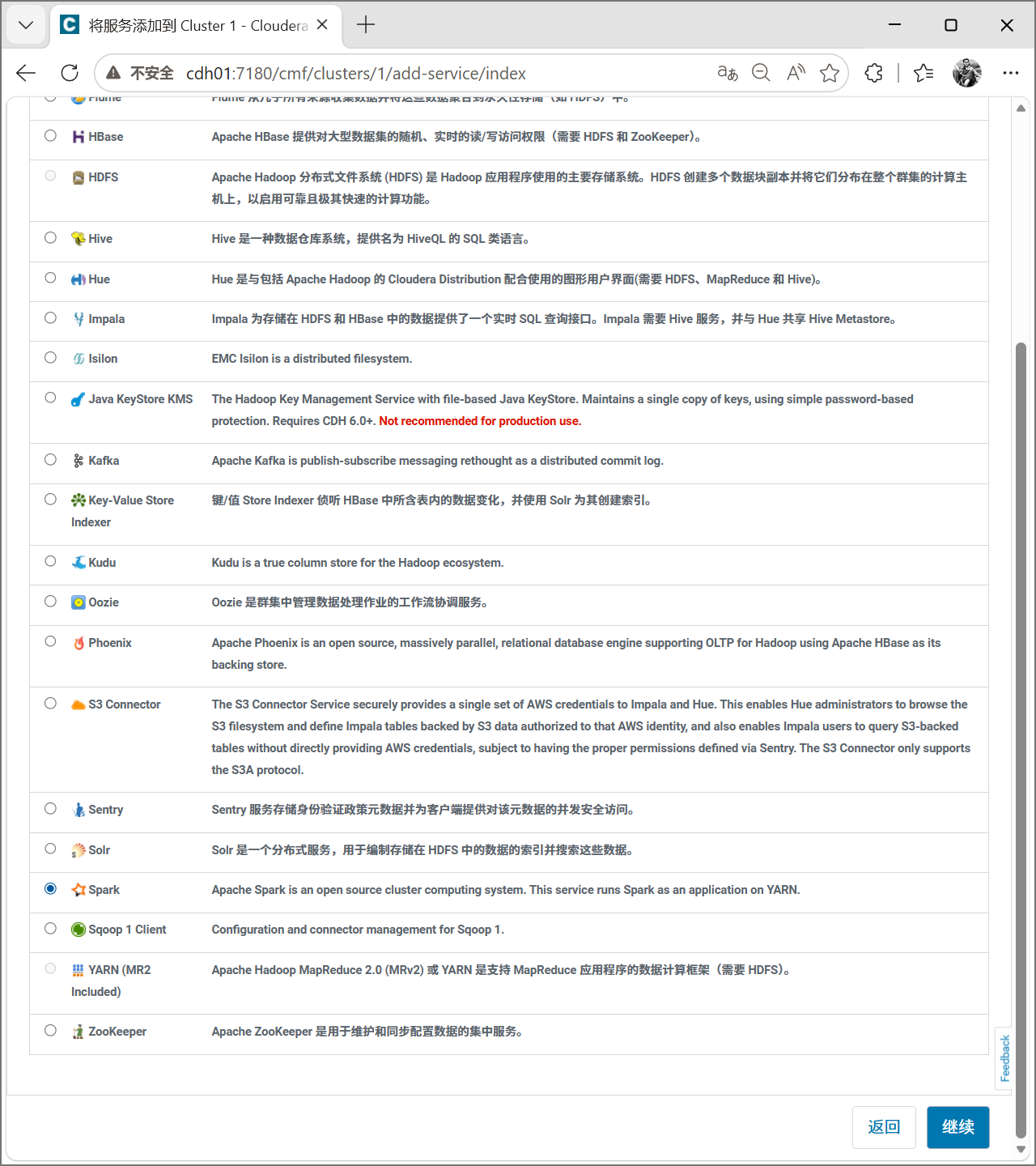
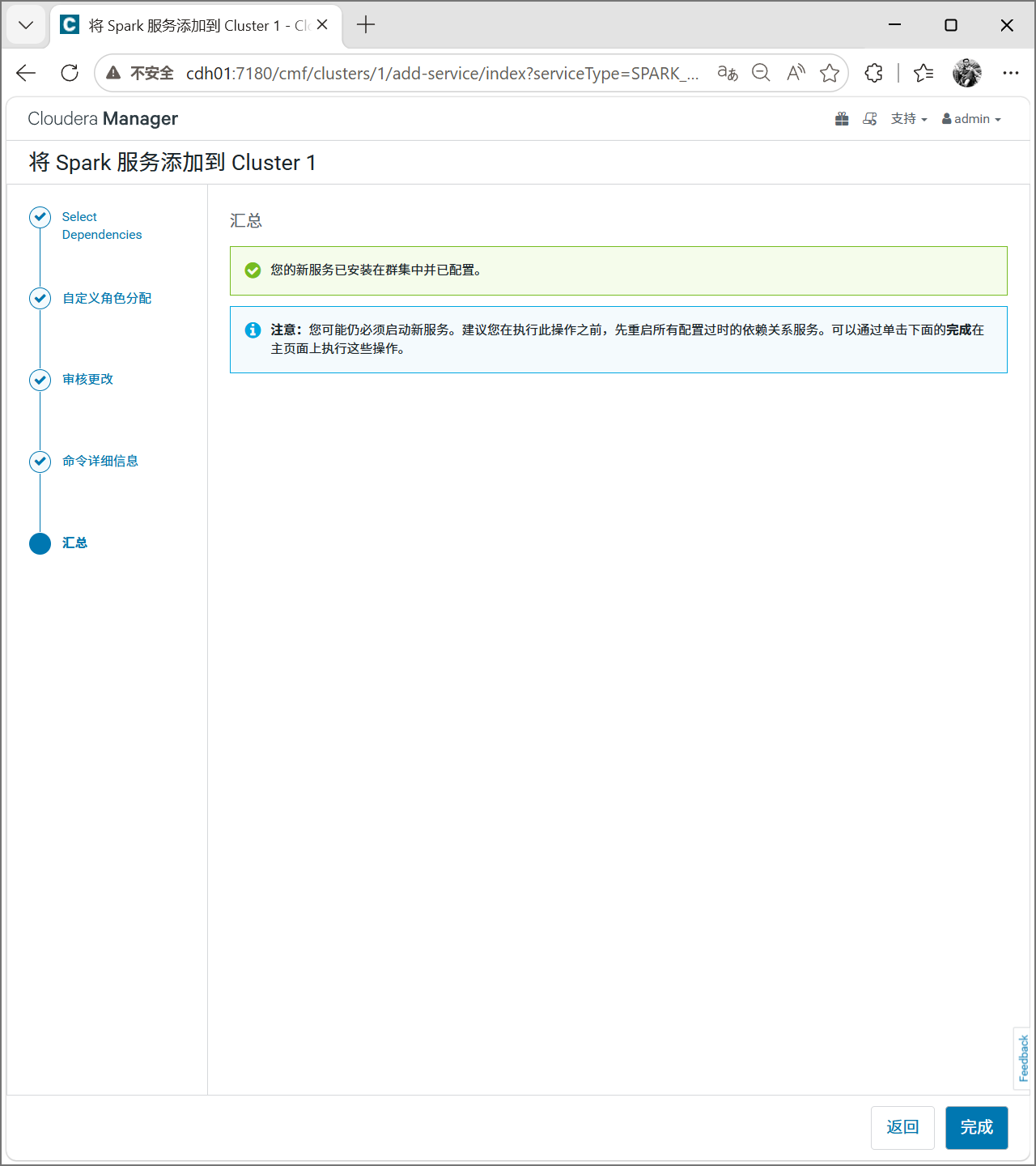
添加服务
配置hive
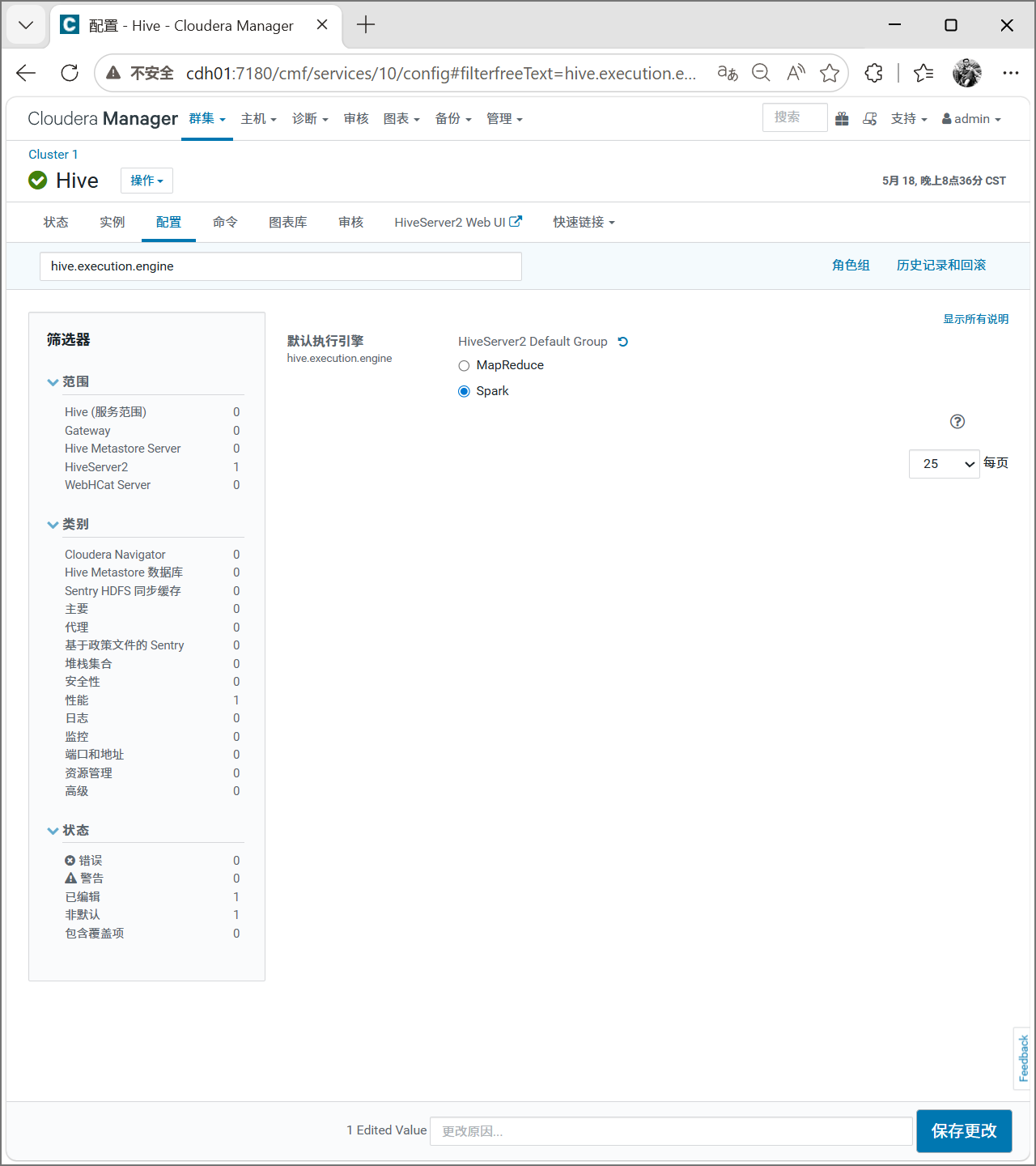
在主页面点击hive进入hive后点击配置,在搜索框中输入hive.execution.engine
接着继续输入Spark on YARN
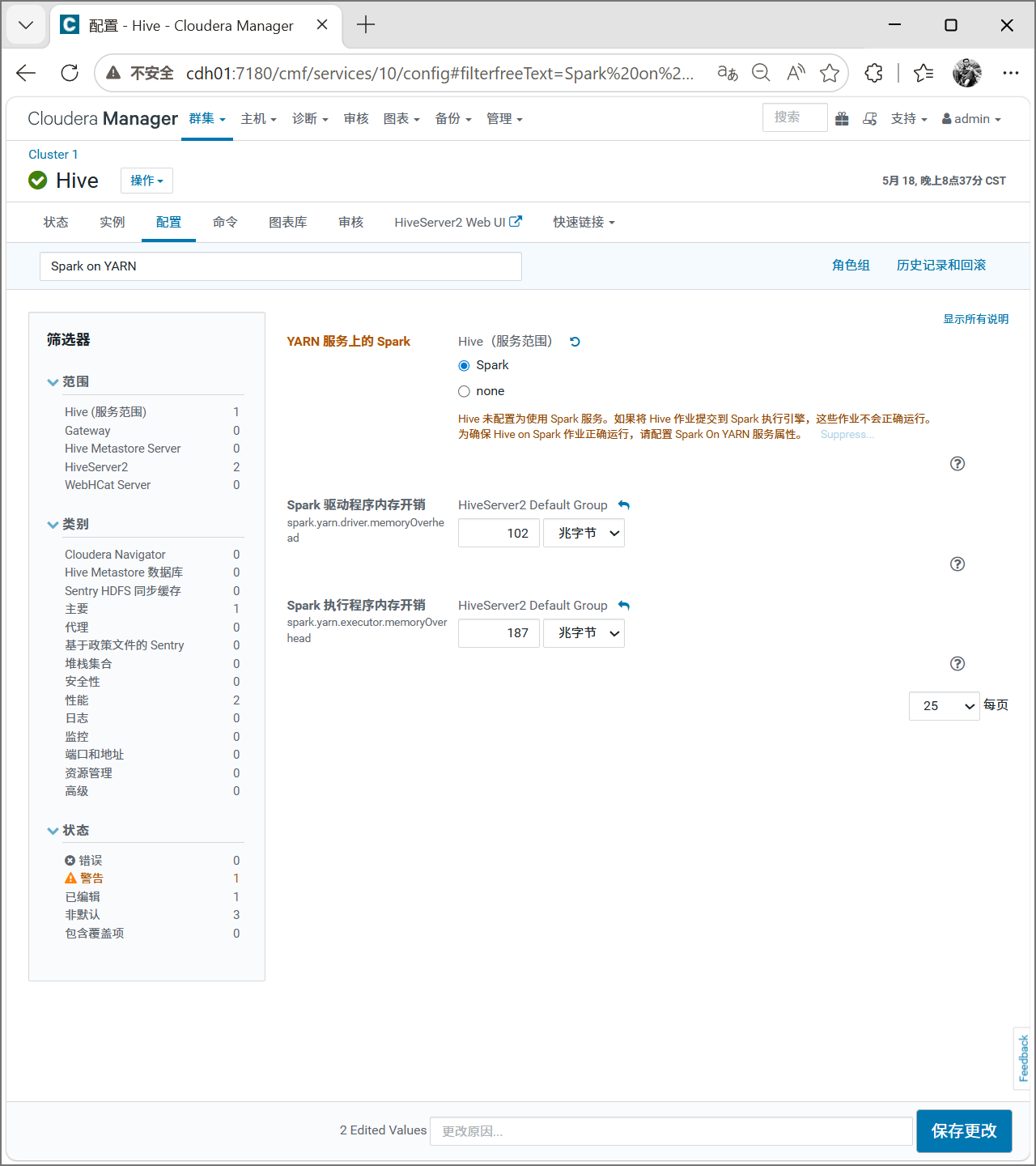
保存更改。
重启配置
出现提示符号需要重启的服务都重启,跟前一章一样。
二、使用Spark处理Hive数据
回到虚拟机,执行以下命令启动spark:
spark-shell \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--executor-cores 1 \
--num-executors 2 \
--conf spark.executor.memoryOverhead=128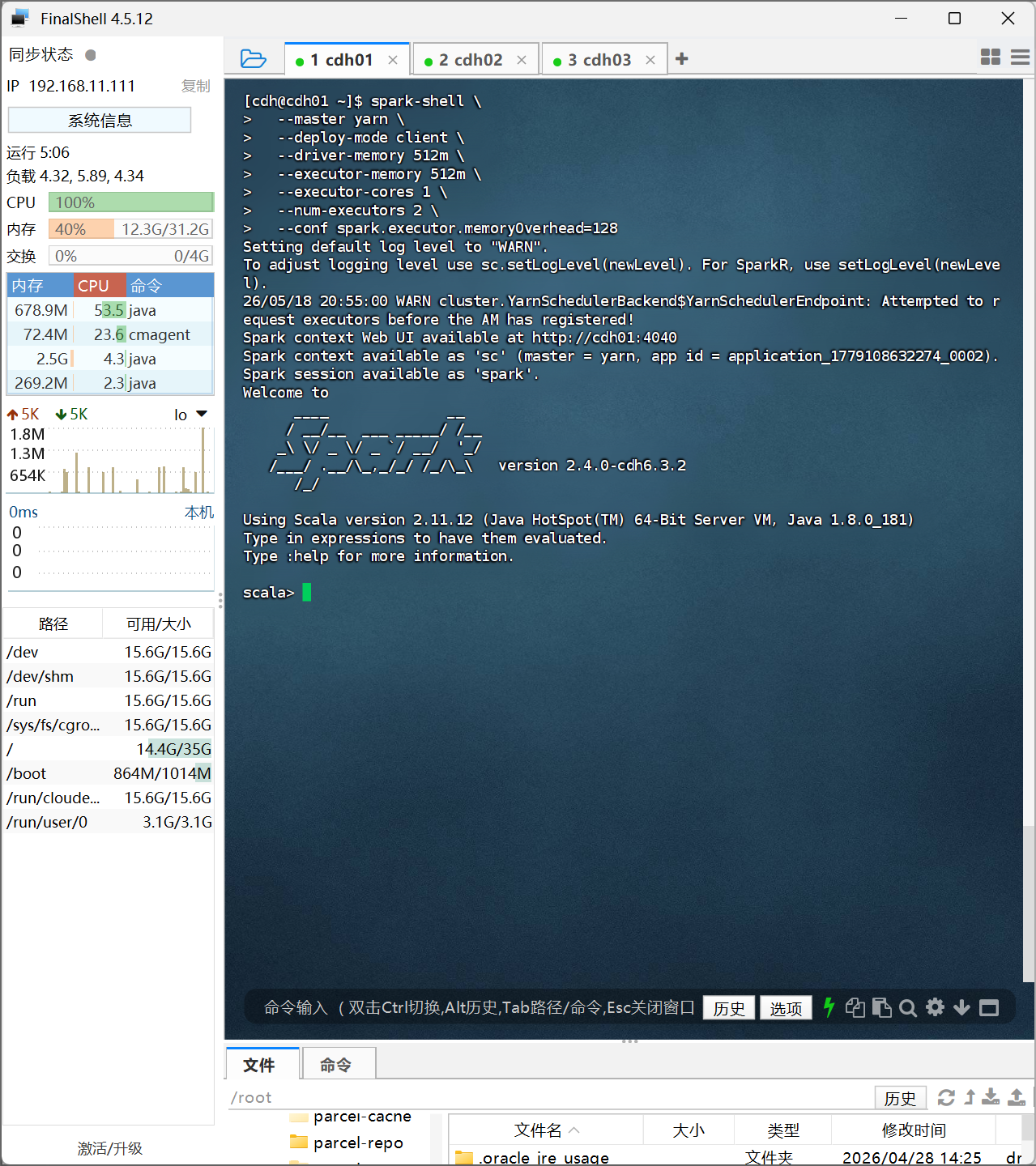
接下来依次执行命令即可:
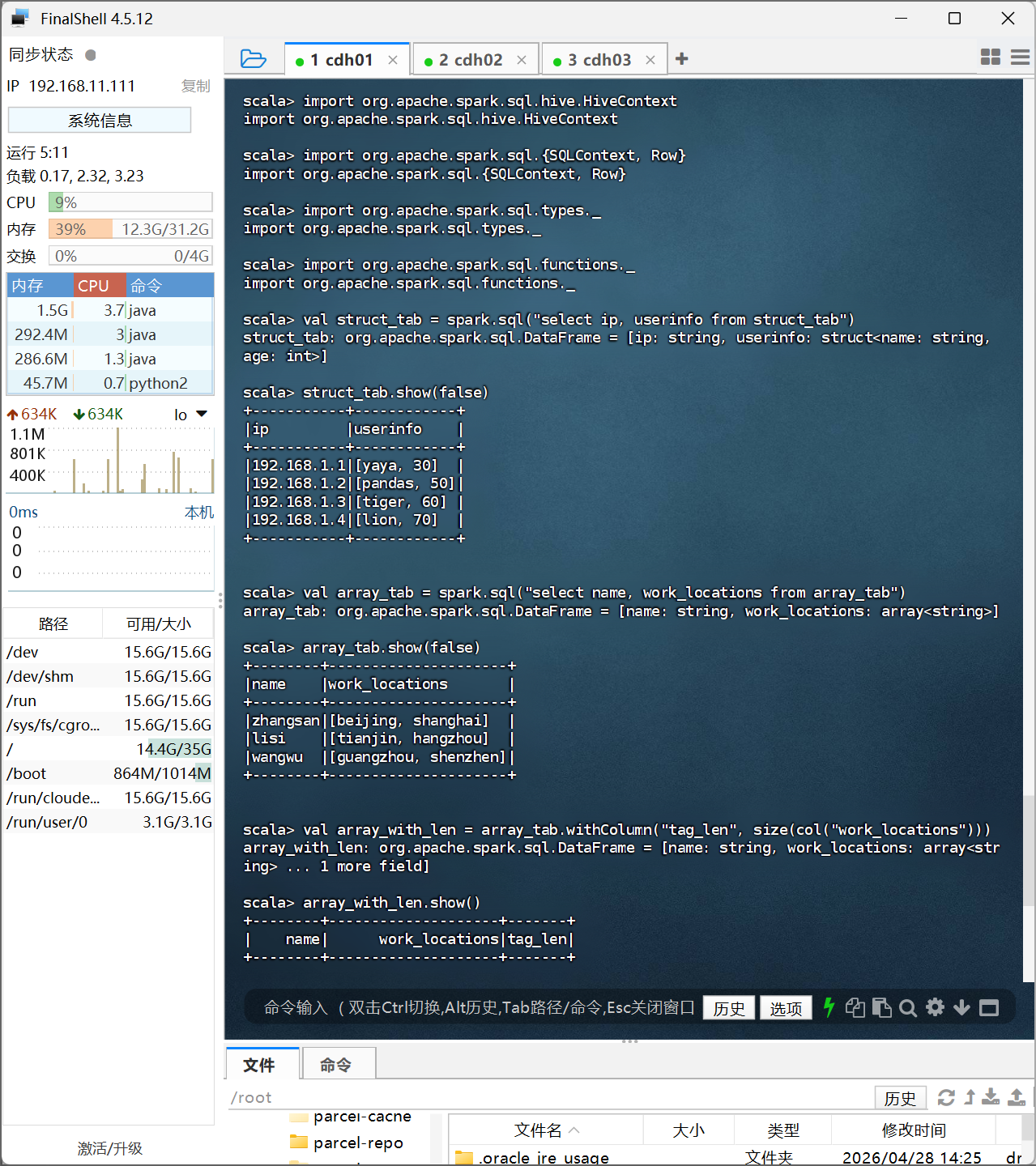
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.sql.{SQLContext, Row}
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
val struct_tab = spark.sql("select ip, userinfo from struct_tab")
struct_tab.show(false)
val array_tab = spark.sql("select name, work_locations from array_tab")
array_tab.show(false)
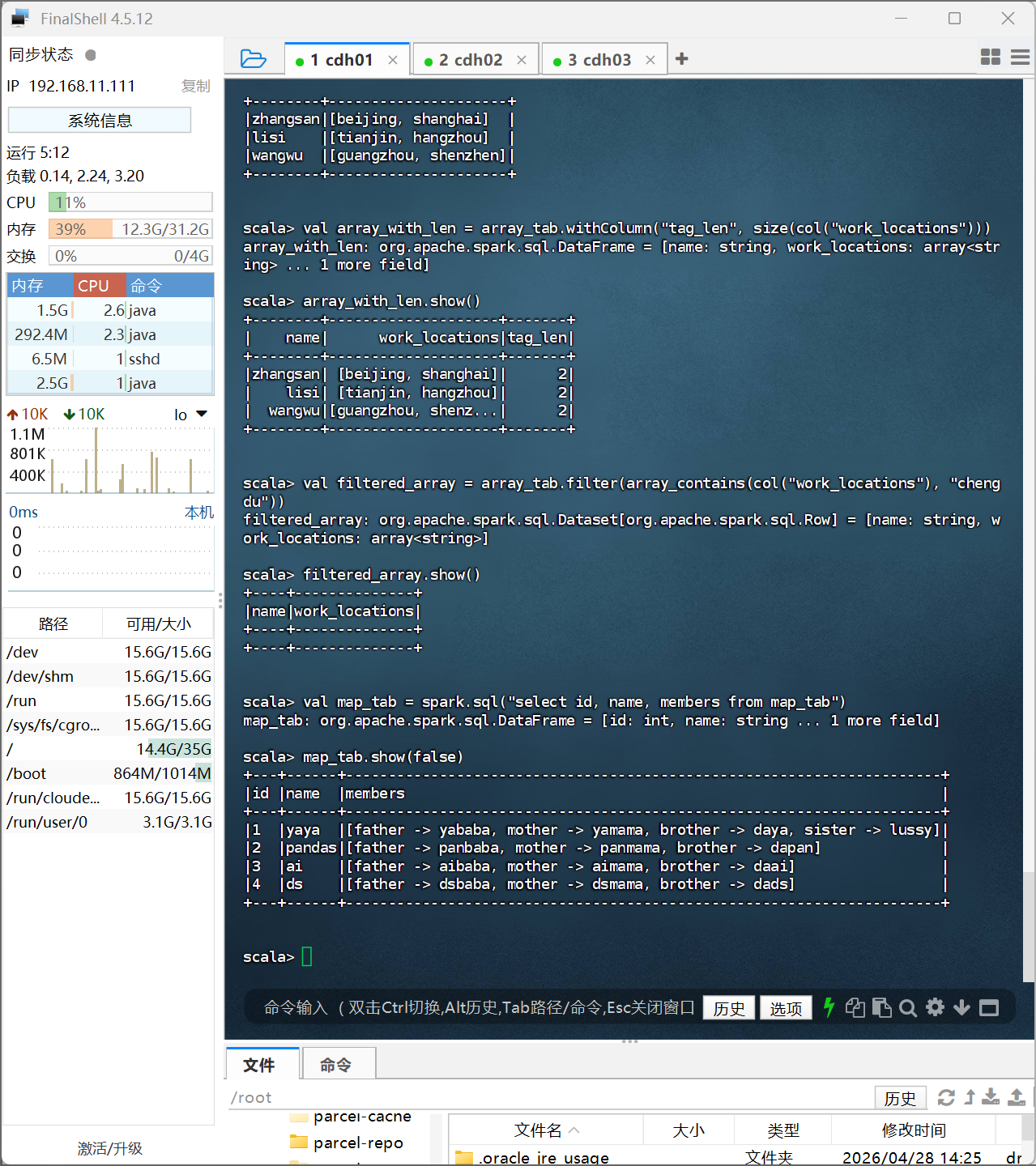
val res1=array_tab.withColumn("tag_len", size(col("work_locations")))
res1.show()
val map_tab = spark.sql("select id, name,members from map_tab")
map_tab.show(false)
三、pyspark处理文本数据
点击以下网址进入下载页面选择ml-100k.zip进行下载
https://files.grouplens.org/datasets/movielens/
下载并解压好后我们进入Hue服务
然后创建hdfs的movie目录将文件u.data导入到该目录下
移动到左上角的三条杠那里,点击文件
右上角新建目录。
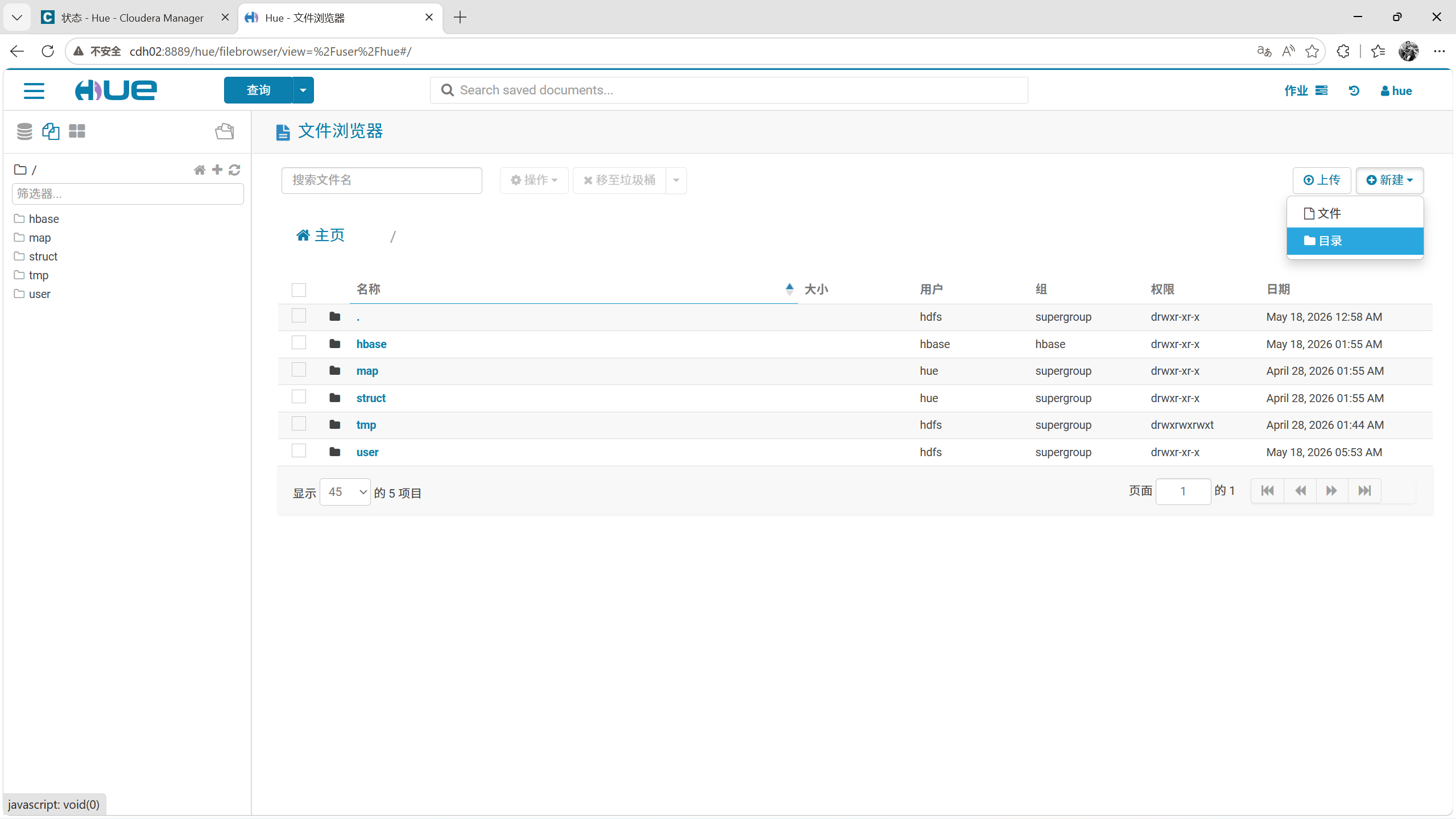
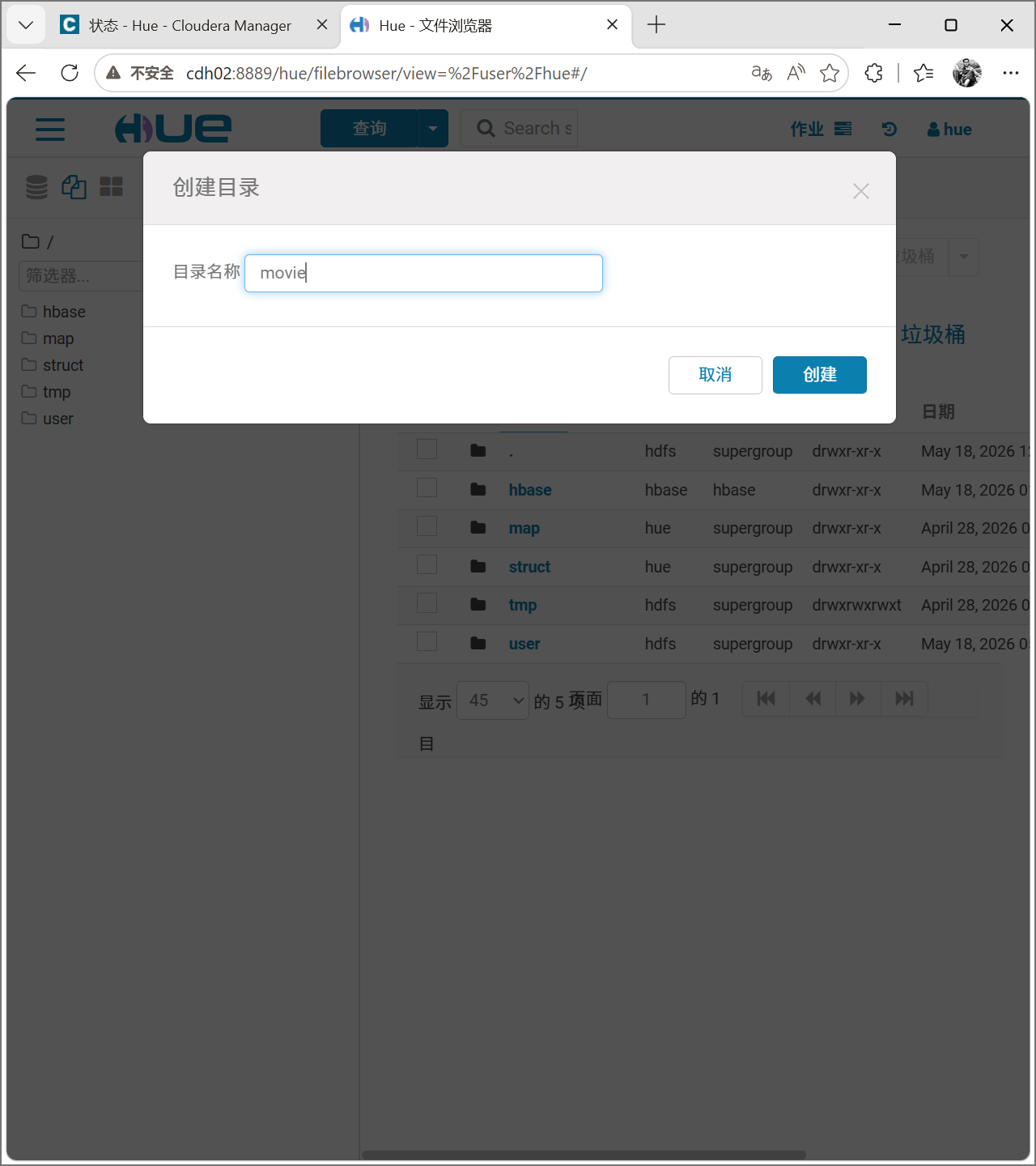
进入movie目录,点击加号上传文件。
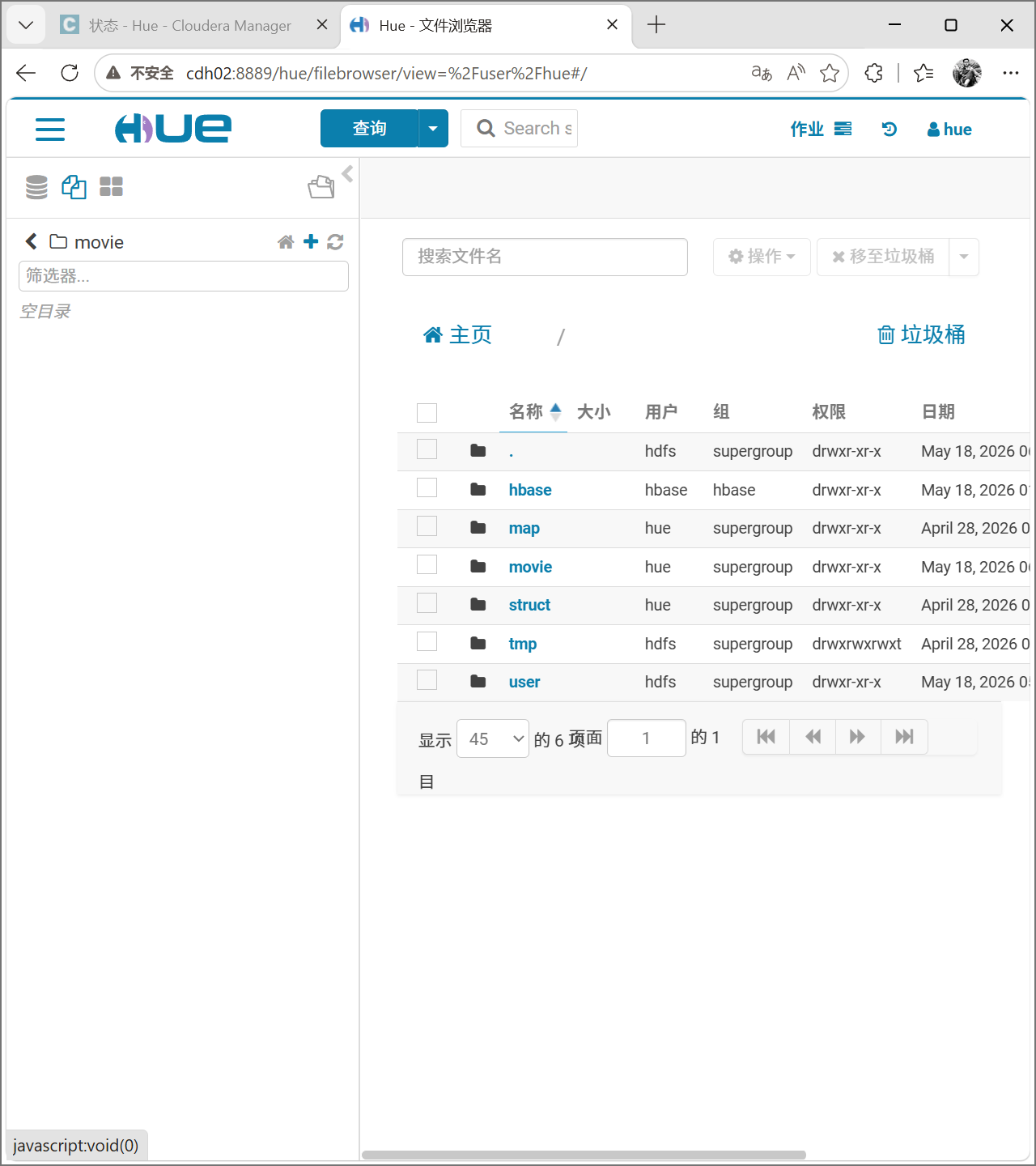
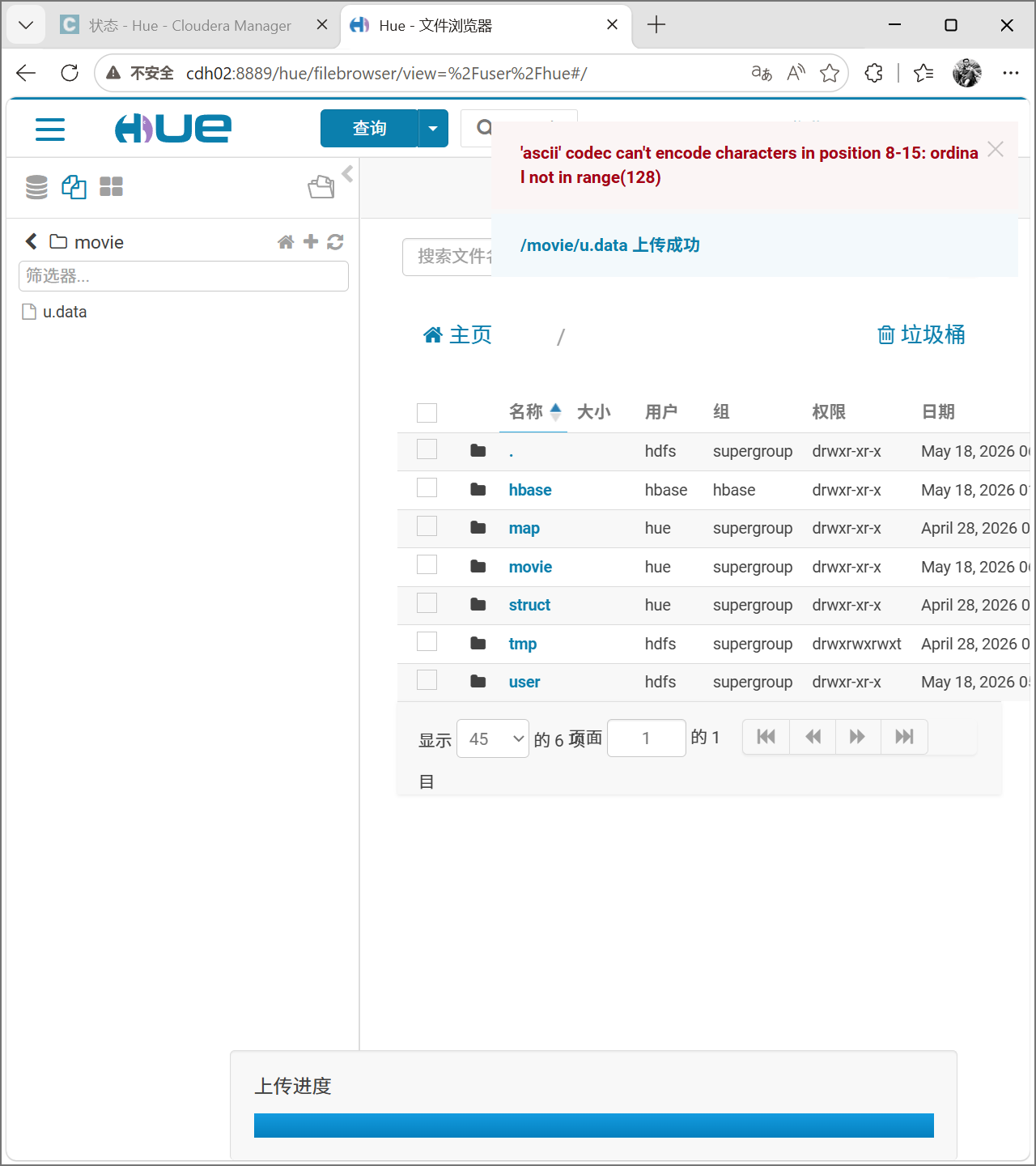
找到解压的文件并上传,可以直接拖拽,我这里为了演示采用加号上传。
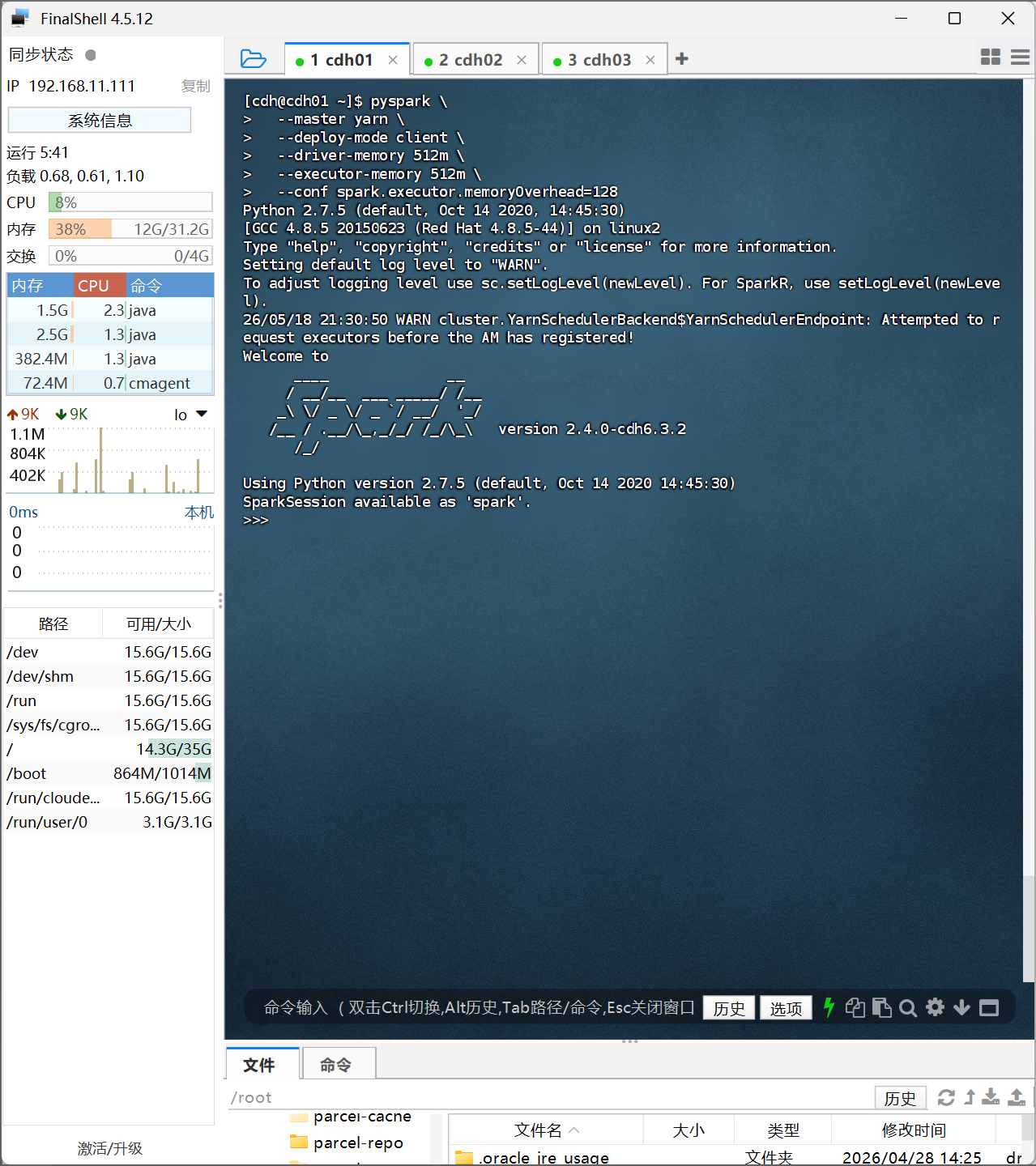
接下来回到虚拟机,启动PySpark(YARN模式)
pyspark \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--conf spark.executor.memoryOverhead=128
然后依次执行:
from pyspark.sql import SparkSession, functions as F
from pyspark.sql.types import *
ss = SparkSession.builder.getOrCreate()
sc = ss.sparkContext
# 读取 HDFS 上的文件
rdd = sc.textFile('/movie')
# 解析数据(注意分隔符是 \t)
rdd_map = rdd.map(lambda x: x.split('\t')).map(lambda arr: (arr[0], arr[1], int(arr[2]), arr[3]))
# 定义 schema
schema = StructType([
StructField("user_id", StringType()),
StructField("movie_id", StringType()),
StructField("score", IntegerType()),
StructField("date_time", StringType())
])
df = rdd_map.toDF(schema)
df.show(5)
# 1. 每个用户的平均分
df.groupBy("user_id").agg(F.avg("score").alias("avg_score")).show()
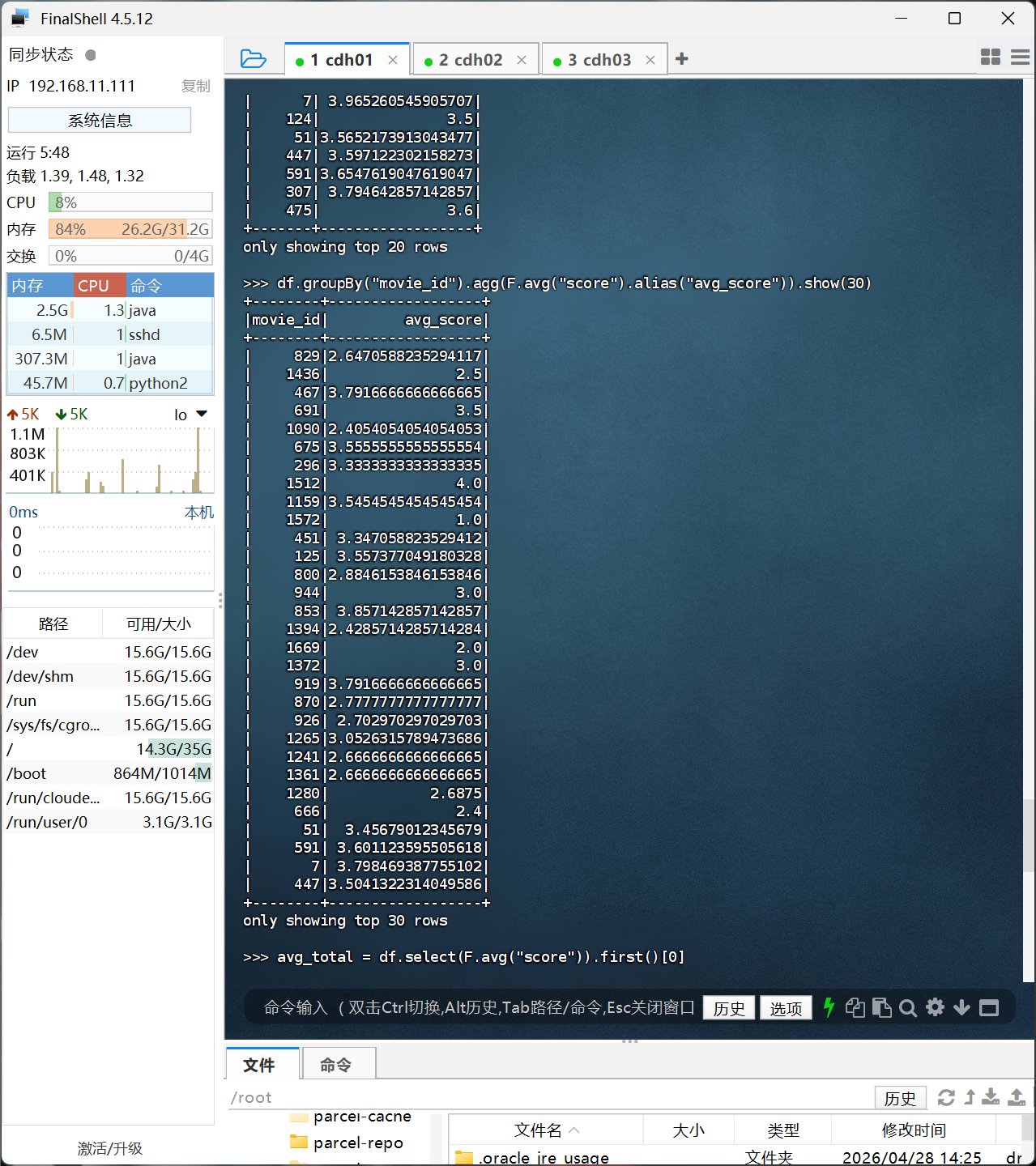
# 2. 每个电影的平均分
df.groupBy("movie_id").agg(F.avg("score").alias("avg_score")).show(30)
# 3. 查询大于平均分的电影数量
avg_total = df.select(F.avg("score")).first()[0]
movie_avg = df.groupBy("movie_id").agg(F.avg("score").alias("avg_score"))
high_movies = movie_avg.filter(movie_avg["avg_score"] > avg_total)
print("大于平均分的电影数量:", high_movies.count())
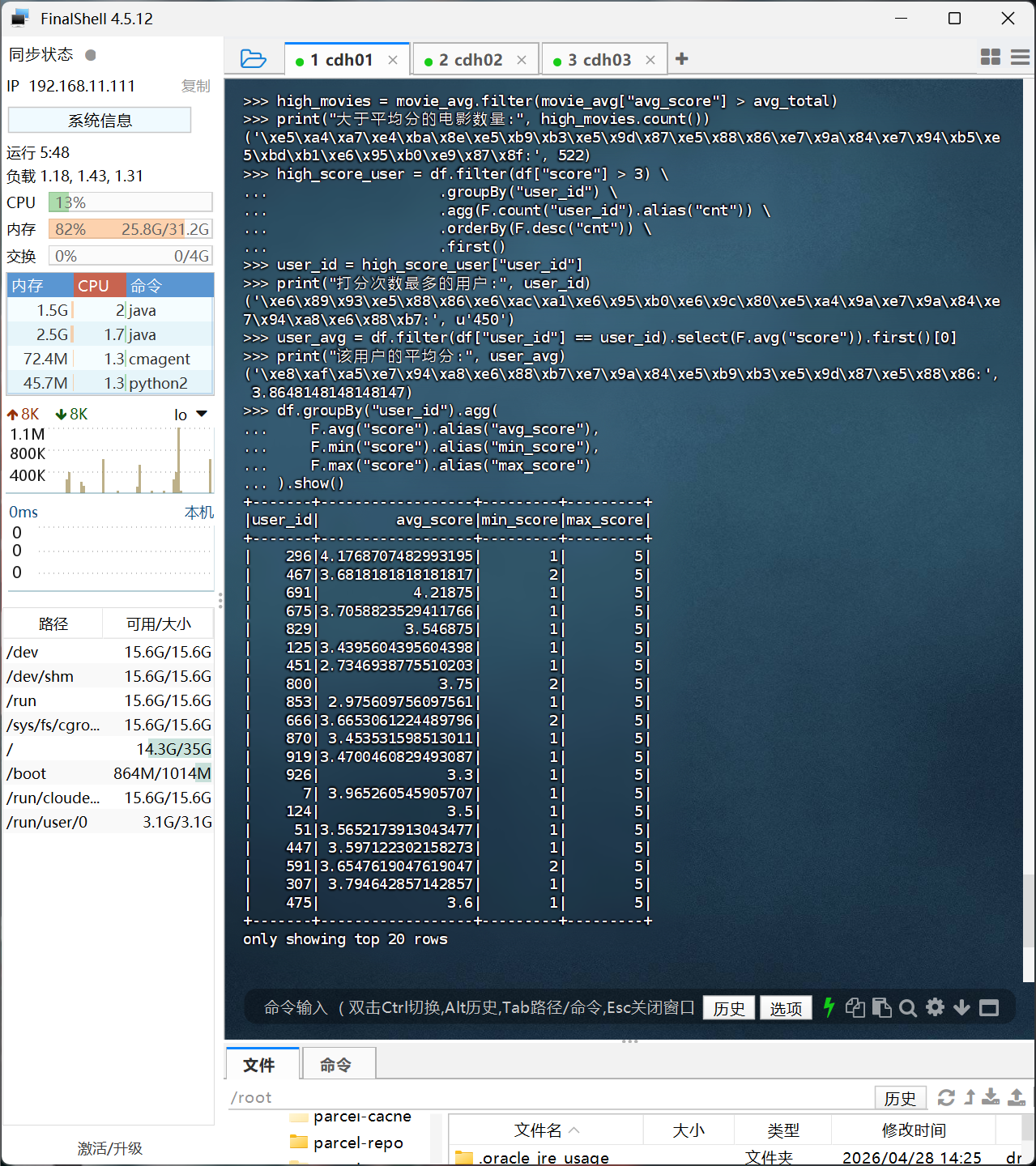
# 4. 高分电影(>3)打分次数最多的用户,及其平均分
high_score_user = df.filter(df["score"] > 3) \
.groupBy("user_id") \
.agg(F.count("user_id").alias("cnt")) \
.orderBy(F.desc("cnt")) \
.first()
user_id = high_score_user["user_id"]
print("打分次数最多的用户:", user_id)
user_avg = df.filter(df["user_id"] == user_id).select(F.avg("score")).first()[0]
print("该用户的平均分:", user_avg)
# 5. 每个用户的平均分、最低分、最高分
df.groupBy("user_id").agg(
F.avg("score").alias("avg_score"),
F.min("score").alias("min_score"),
F.max("score").alias("max_score")
).show()
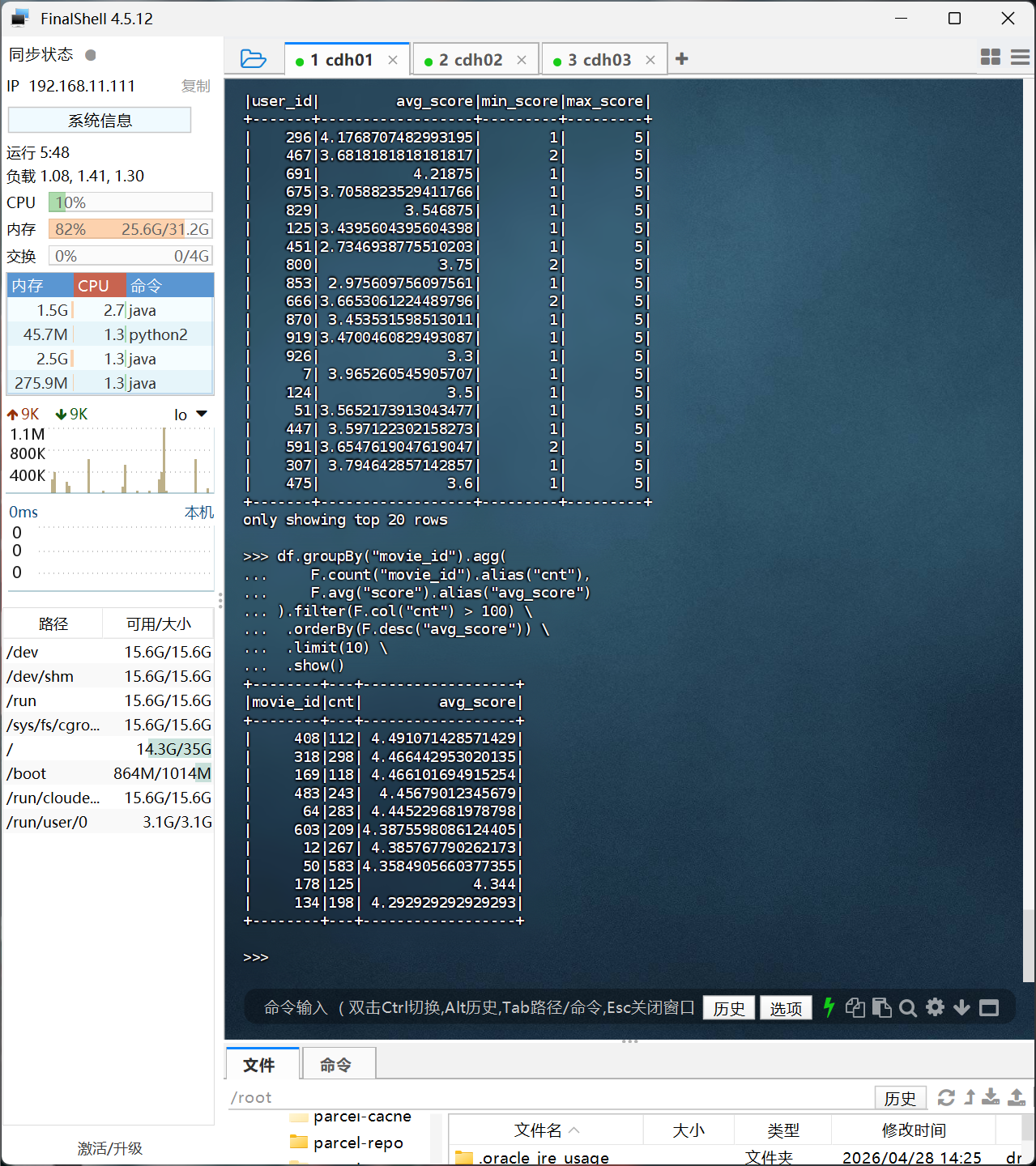
# 6. 被评分超过100次的电影,平均分 TOP10
df.groupBy("movie_id").agg(
F.count("movie_id").alias("cnt"),
F.avg("score").alias("avg_score")
).filter(F.col("cnt") > 100) \
.orderBy(F.desc("avg_score")) \
.limit(10) \
.show()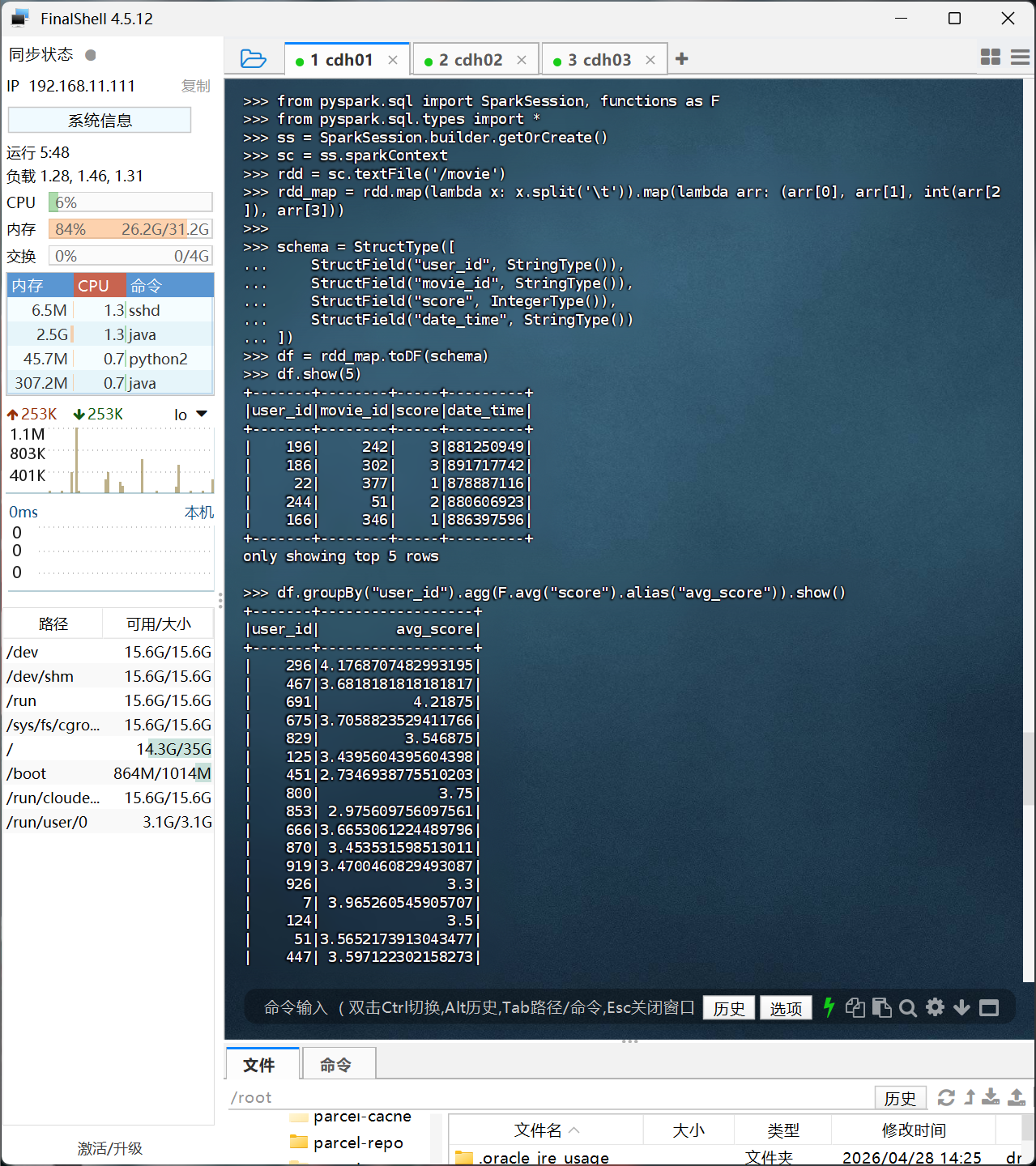
如果觉得一行一行执行太麻烦可以将所有代码打包成.py文件,然后使用spark-submit提交:
spark-submit \
--master yarn \
--deploy-mode client \
--driver-memory 512m \
--executor-memory 512m \
--conf spark.executor.memoryOverhead=128 \
your_job.py这里就不演示了。