哈喽朋友们,今天上班滕总又遇到了问题,为什么他加了几段代码以后,ETL脚本(HiveSQL)就跑不动了?
需求场景就不赘述了,单从技术角度分析。
我问他ApplicationID是多少?他说没看到,直接报code1了。我看下日志是Tez报错了,代码都没提交到Yarn
Tez报错内容是:Dag submit failed due to Java heap space
很显然是Tez内存溢出了,我在想是代码太复杂了它优化不了执行计划?
然后用explain想看下执行计划,结果执行计划都卡的打不出来。
然后从ETL的上一个版本开始一块一块断点刷执行计划,定位到具体代码块以后发现,是一大段union all导致的
试过过滤空值,没什么效果。
最后发现是大量重复扫描表,果断换了写法,注释大量union all 关联条件收敛到on 后面 用 or 区分,执行计划能打出来了,问题解决了。
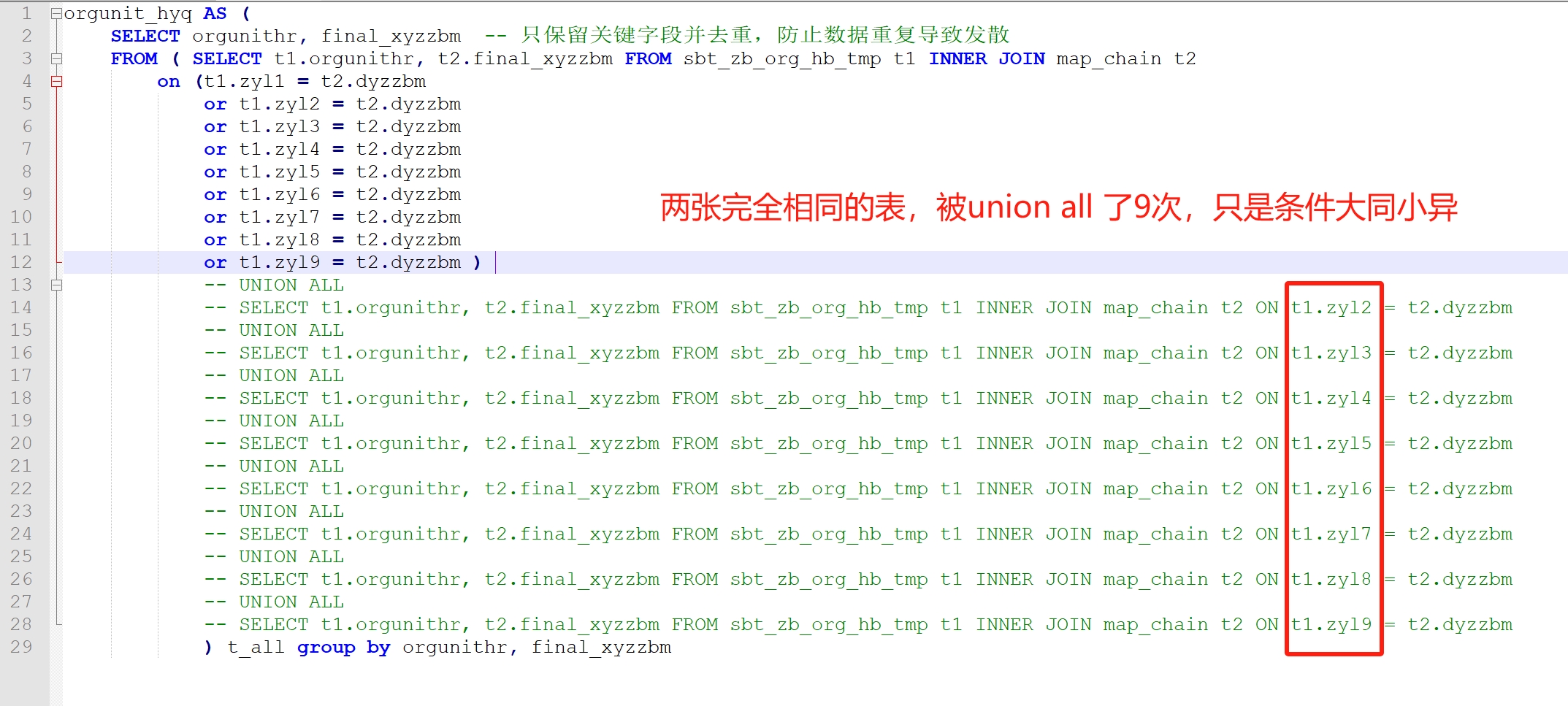
结语:这是一个处理复杂组织合并问题是遇到的一个多层次关联案例。正常写法确实直接union all 的话逻辑看上去会更清晰,考虑下分布式计算引擎的特点就不会这样写了,减少表扫描的次数确实给Tez减负了,扫一次就行。