
导读
无人机巡检已经是电力线路缺陷检测的标配手段,但一个很少被正面讨论的问题是:UAV拍摄的原始图像分辨率高达6000×8000,而主流检测模型的输入只有640×640------绝大多数像素在缩放中被丢弃,微小的绝缘子缺陷特征极易被淹没。
常见的应对方案是滑动窗口切片,但这篇来自中国地质大学(武汉)、清华大学深圳国际研究生院、国网四川省电力公司和上海交通大学的联合工作揭示了一个更深层的问题:"切片策略如果只用在训练端而不同步到推理端,mAP反而会从83.9%暴跌到72.7%"。论文围绕这一发现,提出了数据层(LGOT)、模型层(SDPD-Head)、推理层(ITAT)三层协同的系统级设计方案,基于YOLO11实现了92.9%的mAP@50,同时参数量仅2.17M,GFLOPs较基线降低30.1%。
论文信息
-
标题:Lightweight Insulator Defect Detection in High-Resolution UAV Imagery via System-Level Co-Design
-
作者:Yujie Zhu, Guanhua Chen, Linghao Zhang, Jiajun Zhou, Junwei Kuang, Jiangxiong Zhu
-
机构:中国地质大学(武汉)、清华大学深圳国际研究生院、国网四川省电力公司、上海交通大学
-
发表:Remote Sensing 2026, 18(6), 953
-
日期:2026年3月21日
一、高分辨率UAV图像的尺度失配困境
电力线路的无人机巡检面临一个结构性矛盾:为了在远距离拍摄中捕捉微小缺陷(如绝缘子裂纹、污渍),UAV图像分辨率通常在3648×5472到6000×8000之间;而主流目标检测模型(如YOLO系列)的标准输入仅为640×640。直接缩放意味着原始图像的长边被压缩近10倍,微小缺陷占据的像素从原本就不多变得极难被有效检测。
滑动窗口(Sliding-Window)切片是最直观的解法:将大图切成若干640×640的子图分别检测。但这一做法带来两个问题------一是大量切片落在纯背景区域,产生冗余计算;二是切片边界可能截断目标。
本文的核心贡献不在于提出某个单一的新模块,而是指出了一个被忽视的系统性问题:训练阶段的数据处理方式与推理阶段的输入分布必须对齐,否则即使每个环节单独看都合理,组合后反而会掉点。
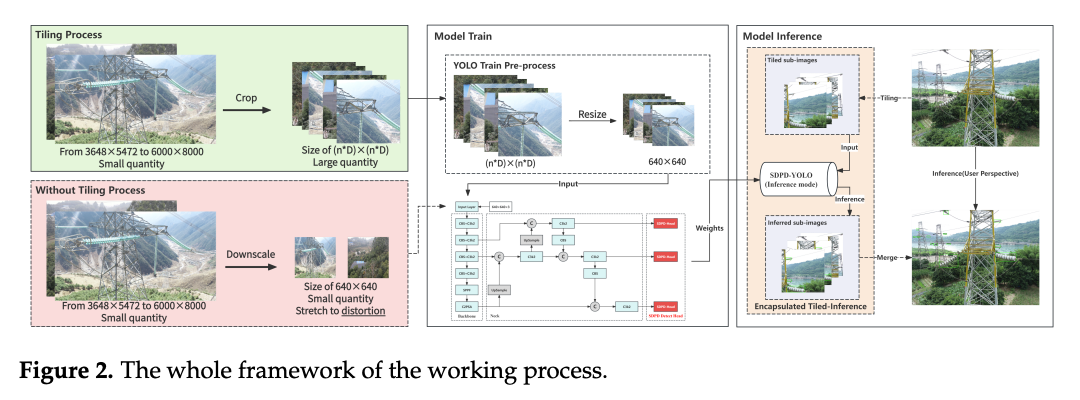
二、三层协同框架:LGOT + SDPD-Head + ITAT
论文提出的方案基于YOLO11,由三个层面的设计协同构成。
图片来源于原论文
数据层:LGOT(Label-Guided Optimal Tiling)
LGOT是一种离线切片策略,核心思想是利用标注框信息指导切片位置的选择 。具体而言,论文提出了Corner Optimal Cover(COC)策略:以每个标注框的四个角点为锚点生成候选切片,然后选择覆盖标注框数量最多的切片方案。
与滑动窗口相比,LGOT的优势在于:切片集中于有目标的区域,减少纯背景切片的冗余。论文在验证集上的对比结果如下:
| 切片策略 | 验证集 mAP@50(%) |
|---|---|
| Sliding-Window | 82.7 |
| Random Tiling | 84.0 |
| LGOT(本文) | 86.5 |
LGOT较滑动窗口提升+3.8%,较随机切片提升+2.5%。
切片后,论文的训练集从原始图像扩展为4717张子图,按7:2:1划分为训练集、验证集和测试集。数据集包含3类缺陷:G-Insulator Broken (玻璃绝缘子破损,83→96张切片)、G-Insulator Dirty (玻璃绝缘子污渍,383→464张)、P-Insulator Dirty(瓷绝缘子污渍,410→869张)。由于G-Insulator Broken样本稀少,论文对其做了4倍数据增强(色调、饱和度、亮度、噪声)。
模型层:SDPD-Head(Semi-Decoupled Prior-Driven Detection Head)
在检测头设计上,论文采用了半解耦 结构,与YOLO11的完全解耦头不同。分类和回归各有一个3×3**深度可分离卷积(DWConv)**分支提取特征,但最终通过concat后共用一个1×1卷积层生成预测输出。这种设计在保留分类与回归的特征差异化的同时,减少了参数冗余。
此外,SDPD-Head引入了进化算法生成的锚框先验(anchor priors),为微小目标提供稳定的空间尺度参考。论文指出,对于绝缘子缺陷这类尺度变化相对可控的目标,先验锚框比完全无锚(anchor-free)方案更能提供有效的回归起点。
从参数量来看,SDPD-Head的计算公式约为2×C_in×K²+C_in×C_out,远少于YOLO11原始Head的参数量。最终模型参数仅2.17M,GFLOPs为4.7,较YOLO11基线分别降低19.2%和30.1%。
推理层:ITAT(Inference-Time Adaptive Tiling)
ITAT解决的是推理阶段的关键问题:如何在不知道标注信息的情况下,避免对全图做滑动窗口式的穷举切片。
ITAT采用两阶段策略 :第一阶段用一个缩小版的SDPD-YOLO粗检测器对缩放后的全图做快速推理,提出候选ROI(Region of Interest)区域;第二阶段仅在这些ROI区域内做高分辨率切片推理。为了防止ROI裁切时截断目标边缘特征,ITAT引入了自适应边缘扩展因子α,根据目标尺度动态调整ROI边界。
这一设计避免了全图滑动窗口的冗余计算,将推理开销集中在真正可能存在缺陷的区域。
三、训练-推理尺度对齐:一个被忽视的系统性问题
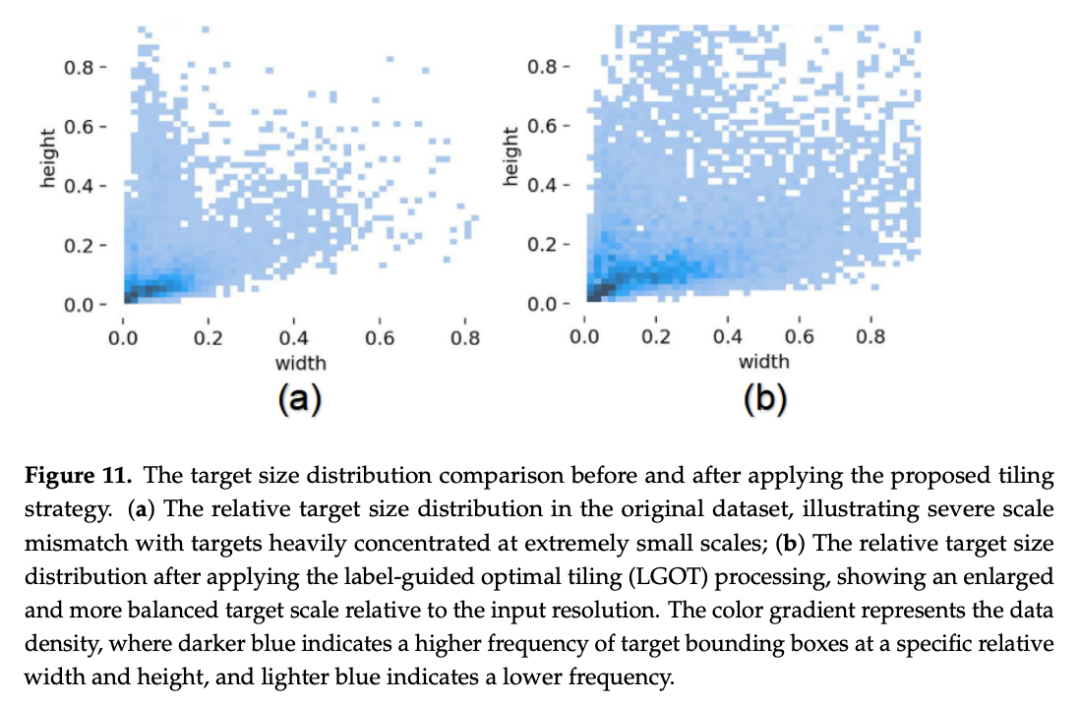
本文最值得关注的发现来自消融实验。论文在不同训练集与推理策略的组合下测试了模型表现:
| 训练集 | 推理策略 | mAP@50(%) |
|---|---|---|
| 原始数据集 | 标准推理 | 83.9 |
| LGOT数据集 | 标准推理 | 72.7 |
| LGOT数据集 | ITAT推理 | 86.0 |
LGOT单独使用时,mAP从83.9%暴跌至72.7%,下降了11.2个百分点。
原因在于:LGOT切片后的训练图像是高分辨率的局部放大图,模型在训练阶段学到的是放大后的缺陷特征分布;而标准推理时输入的是将原始大图缩放到640×640的全图,缺陷在这一尺度下极难被有效表征。训练和推理的空间尺度分布严重失配,导致模型无法将训练中学到的特征迁移到推理场景。
只有当LGOT与ITAT协同使用------训练时用LGOT切片放大目标,推理时用ITAT在高分辨率ROI上做切片检测------训练与推理的输入分布才能对齐,mAP才回升到86.0%。
这一发现的意义在于:在高分辨率图像检测场景中,数据预处理策略不能只考虑训练端,必须与推理端形成闭环。
图片来源于原论文
四、消融实验:各模块的独立与协同贡献
论文通过逐步叠加模块的方式展示了完整框架的效果。在YOLO11n基线上:
-
YOLO11n基线(原始数据+标准推理):mAP@50 = 83.9%
-
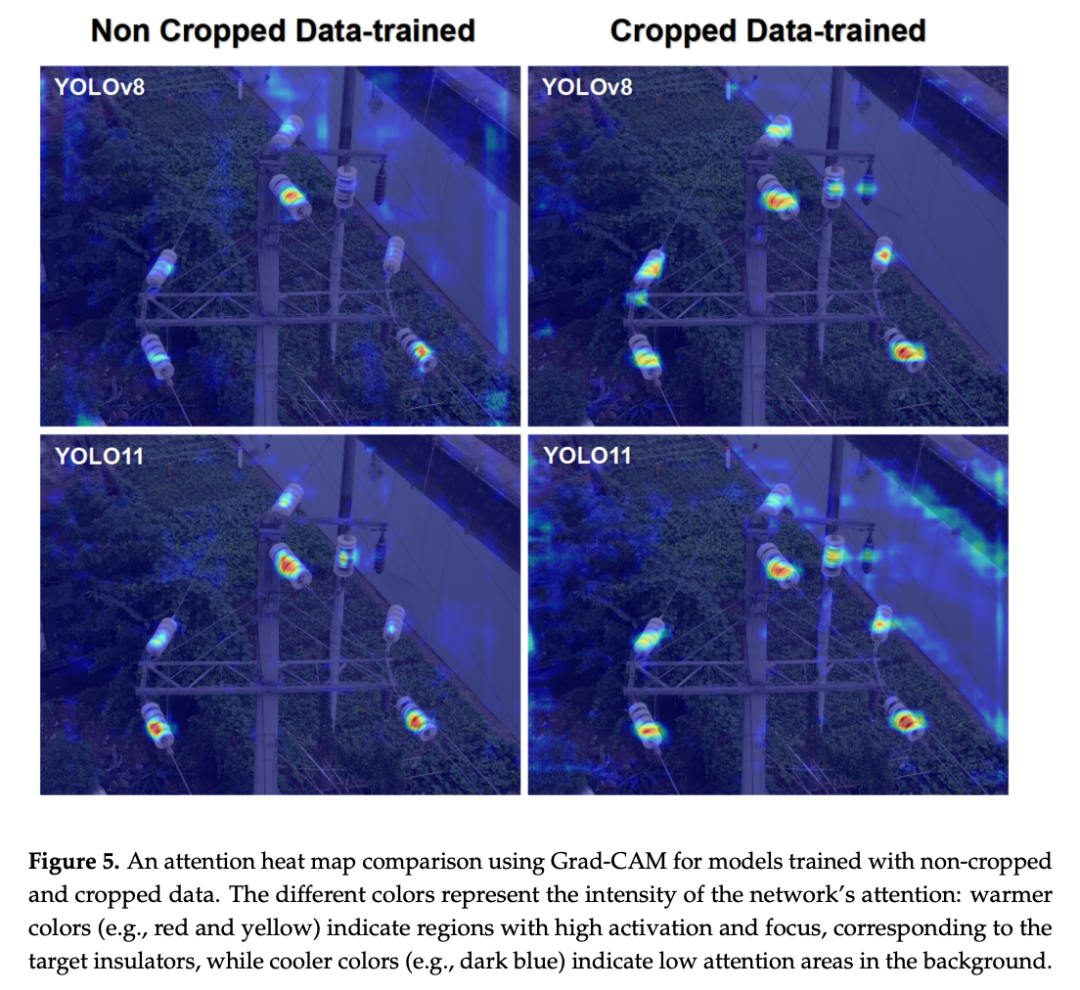
替换为SDPD-Head后:参数量降至2.17M(较基线降低19.2%),GFLOPs降至4.7(较基线降低30.1%),模型更轻量
-
叠加LGOT+ITAT后:mAP@50提升至86.0%
-
完整框架最终在测试集上达到mAP@50 = 92.9%
论文还与多个检测模型进行了对比,包括YOLOv8、YOLOv10、YOLO11以及RT-DETR等,完整框架在mAP@50上取得了领先结果,同时保持了较低的参数量和计算开销。
切片策略的对比实验(见第二节表格)同样表明,LGOT在mAP上较滑动窗口(+3.8%)和随机切片(+2.5%)有稳定优势,验证了标注引导的切片选择在信息密度上的收益。
训练配置方面,论文使用Windows 11系统,RTX 4090 GPU,Xeon W3-2525 CPU,128GB内存,PyTorch v2.4.1,训练200 epochs,batch size为32,输入尺寸640×640,使用AdamW优化器和Mosaic数据增强,损失函数保持YOLO11默认设置。
图片来源于原论文
五、总结与思考
本文的核心贡献是提出了一个数据层-模型层-推理层三层协同的系统级设计框架,用于解决高分辨率UAV图像中微小绝缘子缺陷的检测问题。最终在实际电力巡检数据上实现了mAP@50 = 92.9%,参数量2.17M,GFLOPs仅4.7。
论文在Limitations中指出了当前框架的几个局限:
**1. ITAT的两阶段设计增加了部署复杂度。**ITAT依赖预训练的轻量粗检测器进行ROI筛选,虽然在稀疏目标场景下显著提升了推理效率,但也向部署管线中引入了额外组件,系统复杂度高于端到端的单模型方案。
**2. 缺少实际嵌入式平台的物理验证。**论文在理论计算量(GFLOPs)和参数量上实现了显著压缩,但尚未在实际嵌入式或边缘设备上进行运行时效率、推理延迟和功耗的物理测试。将算法层面的轻量化优势转化为实际边缘部署性能,是论文明确指出的下一步工作方向。
**3. 框架具备跨类别泛化的潜力。**论文指出,LGOT和ITAT的核心策略旨在解决通用的尺度失配问题,不依赖于特定材质属性,因此框架有望迁移到复合绝缘子及其他微观缺陷检测场景。后续计划将数据集扩展到更广泛的电力传输组件以验证这一泛化能力。
