如果说过去三年大模型的进化主线是"更大、更快、更聪明",那么从2025年开始,一个被长期忽视的短板正在浮出水面------记忆。
你可能已经感受到了。你和ChatGPT聊了三个月,它依然不记得你的名字。你让一个Agent连续执行十轮任务,它在第六轮就忘了第一轮的结论。你在A平台积累的偏好数据,到了B平台全部归零。大模型可以写诗、写代码、做推理,但它不会"记住"------不会像人一样积累经验、保留偏好、持续进化。
这不是某个产品的bug,而是整个架构的缺陷。
当前的大模型本质上只有两种"记忆":一种是参数记忆(Parametric Memory)------训练时烧进权重里的知识,更新一次就要重新训练;另一种是激活记忆(Activation Memory)------推理时的KV Cache和隐藏状态,对话一结束就消失。RAG(检索增强生成)算是打了个补丁,把外部文档塞进上下文窗口,但它本质上是个"临时工"------没有生命周期管理,没有版本控制,没有跨平台迁移能力。
翻译成人话------大模型现在的记忆系统,就像一台没有硬盘的电脑。CPU很强,内存也够用,但一关机什么都没了。
就在这个关键节点上,2025年5月,来自MemTensor(上海)、上海交通大学、中国人民大学和中国电信研究院的联合团队提出了MemOS------一个专门为大模型设计的"记忆操作系统"。它第一次把记忆提升为大模型的"一等公民资源",像操作系统管理CPU、内存、磁盘一样,统一管理大模型的三种记忆类型。
研究团队由MemTensor的Bo Tang、Hongkang Yang、Feiyu Xiong和上海交通大学的Zhi-Qin John Xu共同通讯,核心成员包括Zhiyu Li、Shichao Song、Hanyu Wang、Simin Niu、Ding Chen等。MemTensor专注于大模型记忆基础设施,上海交通大学在理论建模方面有深厚积累,中国人民大学和中国电信研究院则分别在知识管理和产业落地方面提供支撑。这支团队的组合,恰好覆盖了"理论设计+系统工程+产业验证"三条关键路径。
1. 为什么大模型需要一个"记忆操作系统"
要理解MemOS的价值,先要理解当前大模型记忆系统的四个致命缺陷。
第一,无法建模长期多轮对话状态。你和一个Agent聊了50轮,它在第51轮时对前面的对话一无所知------因为上下文窗口有限,早期信息早就被截断了。
第二,知识更新极其困难。参数记忆是"烧"在权重里的,想更新一条事实(比如"美国总统是谁"),要么重新训练,要么用知识编辑技术逐条修改------成本高、风险大、不可扩展。
第三,用户偏好和Agent工作流无法持久化。你在一个平台上教会了AI你的写作风格,换个平台就得从头来。多Agent协作时,Agent A的发现无法自动传递给Agent B。
第四,"记忆孤岛"问题。不同平台、不同模型、不同会话之间的记忆完全隔离,无法复用、无法迁移。
这四个问题的根源是同一个:当前的大模型架构没有把记忆当作一种可调度、可治理的显式资源。记忆要么藏在权重里(不可见、不可编辑),要么飘在上下文里(用完即弃),要么散落在外部数据库里(缺乏统一管理)。
MemOS的核心主张很简单也很激进------把记忆变成大模型的"一等公民",像操作系统管理进程、文件、网络一样,给记忆建立完整的生命周期管理体系。
2. 大模型记忆研究的三个阶段
大模型的记忆能力并非一夜之间成为焦点。论文梳理了这条演进脉络,分为三个清晰的阶段------
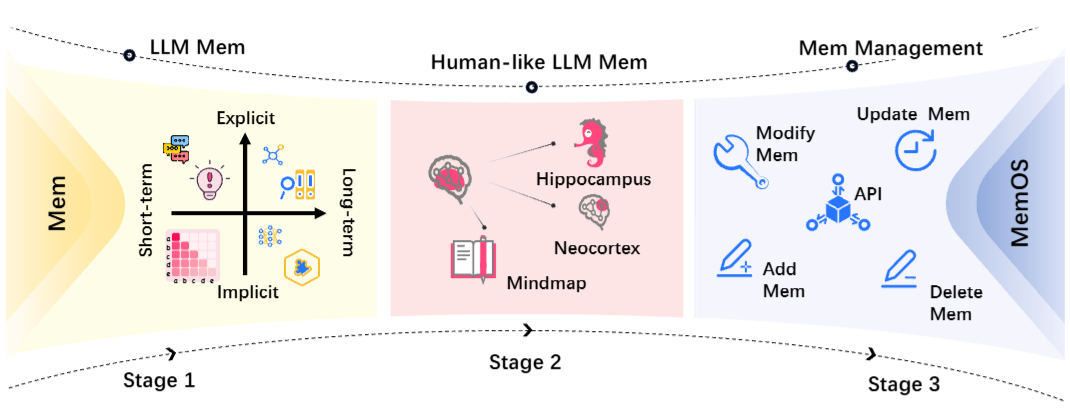
图1
图1:大模型记忆的三阶段演进。从左到右依次是"记忆定义与探索"(区分隐式/显式、短期/长期)、"类人记忆涌现"(海马体启发的HippoRAG、个性化建模的Second-Me)、"系统化记忆管理"(EasyEdit、Mem0、Letta等工具),最终指向MemOS的统一记忆操作系统。
第一阶段是"记忆定义与探索"。研究者开始区分参数记忆和非参数记忆、短期记忆和长期记忆。隐式短期记忆(KV Cache、隐藏状态)负责推理时的上下文连续性;显式短期记忆(Prompt拼接)受限于上下文窗口长度;显式长期记忆(外部检索)开始采用图、树等结构化格式来提升检索效率。知识编辑技术(如ROME、AlphaEdit)则尝试对参数记忆进行定向修改。
第二阶段是"类人记忆的涌现"。HippoRAG借鉴海马体的记忆巩固机制,Memory³引入显式记忆模块,Second-Me支持行为连续性和个性化记忆建模。这些系统开始展现出类似人类记忆的结构和行为模式------但它们各自为战,缺乏统一的管理框架。
第三阶段是"系统化记忆管理"。EasyEdit、Mem0等工具包支持显式记忆操作,Letta(原MemGPT)实现了分页上下文管理和模块化调用。但这些系统仍然缺少统一调度、生命周期治理和跨角色记忆融合的能力。
三个阶段,一条清晰的脉络:从"定义记忆是什么"到"模仿人类记忆"再到"管理记忆"。MemOS正是在第三阶段的基础上,向前迈出了关键一步------从"工具"升级为"操作系统"。
3. 三种记忆的统一:参数、激活、明文
MemOS的第一个核心设计是把大模型的记忆统一为三种类型,并建立它们之间的转换路径。
参数记忆(Parametric Memory)是通过预训练或微调编码进模型权重的长期知识。它藏在前馈层和注意力层里,推理时不需要外部检索就能参与生成。这是模型的"本能"------零样本生成和基础语言理解都依赖它。在MemOS中,参数记忆不仅包括基础语言能力,还支持通过可插拔的LoRA模块注入领域知识(比如法律、医疗),实现模块化的知识组合和复用。
激活记忆(Activation Memory)是推理过程中产生的瞬时认知状态------隐藏层激活、注意力权重、KV Cache。它在上下文感知、指令对齐和行为调控中起关键作用。MemOS把激活记忆当作"工作记忆"层,支持动态调度。更重要的是,频繁访问的激活状态(比如某个KV Cache模式)可以被转化为半结构化片段或参数模块------让短期记忆"沉淀"为长期记忆。
明文记忆(Plaintext Memory)是从外部来源检索的显式知识------文档、知识图谱、Prompt模板。它的核心优势是可编辑、可共享、可治理。在MemOS中,明文记忆支持版本控制、访问权限管理和调用追踪,是知识治理的基础。
这三种记忆不是孤立的。MemOS建立了它们之间的转换路径:
-
明文→激活:频繁访问的明文记忆被转化为激活模板,减少重复解码的开销
-
明文/激活→参数:稳定、可复用的知识被蒸馏进参数结构,提升推理效率
-
参数→明文:不常用或过时的参数知识被外化为可编辑的明文,保持灵活性
这就像人类大脑的记忆巩固过程------短期记忆中反复出现的重要信息会被"写入"长期记忆,而长期不用的知识会逐渐变得模糊、需要外部提示才能唤起。MemOS把这个过程工程化了。论文用一个医疗场景把这三种记忆的关系展示得非常直观------
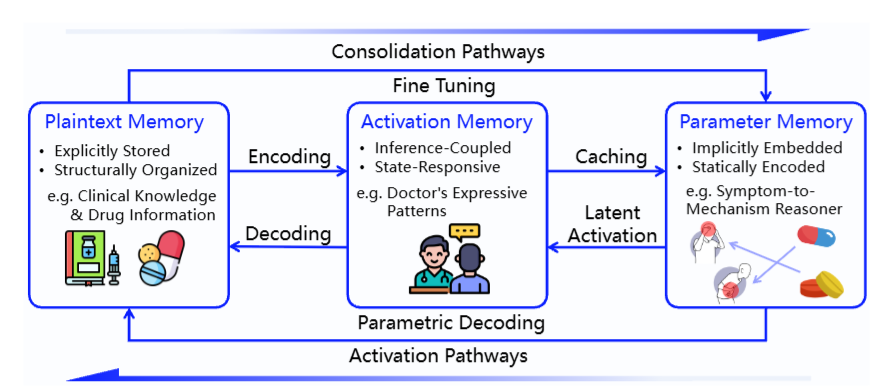
图2
图2:三种记忆之间的转换路径。临床知识和药物信息属于明文记忆(显式存储),医生的表达模式属于激活记忆(推理时动态生成),症状到机制的推理能力属于参数记忆(训练时编码进权重)。三者通过编码、缓存、潜在激活、解码、微调等路径相互转换,形成一个统一、可控、可进化的记忆空间。
这张图的关键信息是:三种记忆不是三个独立的"抽屉",而是一个可以相互流动的连续体。
4. MemCube:记忆的"标准集装箱"
三种记忆形态各异------参数是张量,激活是中间状态,明文是文本。如何用一个统一的抽象来管理它们?
MemOS的答案是MemCube(记忆立方体)------一个标准化的记忆封装单元。
MemCube的设计思路很像集装箱对全球物流的意义。在集装箱出现之前,货物形态各异------散装粮食、桶装石油、箱装电器------每种都需要不同的装卸方式。集装箱用一个标准化的"盒子"把所有货物统一封装,让装卸、运输、仓储都可以用同一套流程。MemCube对记忆做的事情完全一样。
每个MemCube包含两部分:语义载荷(Payload)和结构化元数据(Metadata)。
语义载荷是记忆的"内容"本身。它可以是一段明文("你是一个气候政策领域的助手")、一个激活状态张量(注入到第12层的偏置向量)、或一个参数补丁(某个MLP层的LoRA低秩增量)。三种类型,同一个接口。
元数据分为三类:
第一类是描述性元数据------时间戳、来源签名(用户输入还是推理输出)、语义类型(用户偏好、任务提示、领域知识)。这是记忆的"身份证"。
第二类是治理属性------访问权限、生命周期策略(存活时间或基于频率的衰减)、优先级、合规机制(敏感标签、水印、访问日志)。这是记忆的"安全锁"。
第三类是行为指标------访问频率、上下文相关性、版本谱系。这些运行时指标自动采集,用于驱动动态调度和跨类型转换。比如,一条明文记忆被频繁访问,系统会自动将其转化为激活模板以减少解码开销;一条稳定复用的知识会被蒸馏进参数结构以提升推理效率。
具体长什么样?论文给出了MemCube的完整结构------
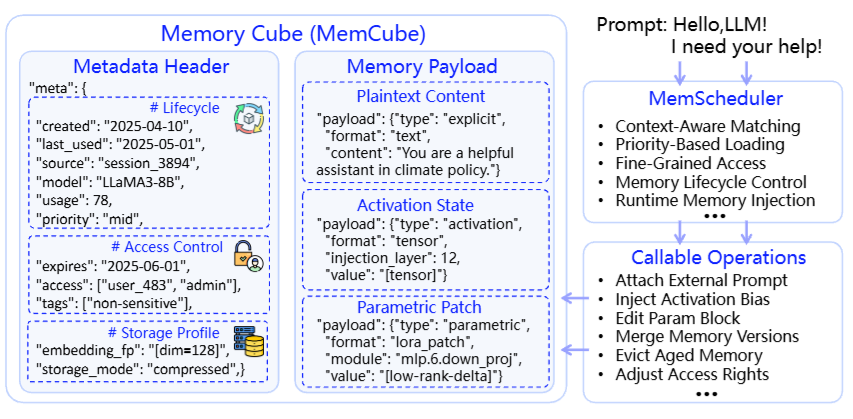
图3
图3(:MemCube的结构。左侧是元数据头(创建时间、最后使用时间、来源会话、关联模型、使用次数、优先级、过期时间、访问权限、敏感标签、嵌入指纹、存储模式),中间是三种语义载荷(明文内容、激活状态张量、LoRA参数补丁),右侧是MemScheduler可执行的操作列表。一个MemCube就是MemOS中最小的记忆执行单元。
这意味着什么?意味着不管记忆是一段文本、一个KV Cache还是一组LoRA权重,系统都可以用同一套机制来追踪、调度、融合、迁移。MemCube让记忆从"散装货物"变成了"标准集装箱"。
5. 三层架构:接口层、操作层、基础设施层
MemOS采用模块化的三层架构,形成一个闭环的记忆治理框架。
接口层(Interface Layer)是系统的入口。它的核心组件是MemReader------负责解析自然语言请求,识别记忆相关意图,并调用标准化的Memory API。接口层提供三类关键API:Provenance API(标注记忆来源)、Update API(更新记忆内容)、LogQuery API(查询使用痕迹)。所有操作都封装在MemCube结构中,受MemGovernance的访问控制管理。
更值得关注的是Pipeline机制。MemOS引入了流水线式的操作链------每个Pipeline节点通过MemCube传递上下文、状态和中间输出,支持事务控制、可定制拓扑和DAG调度。开发者可以构建"查询→更新→归档"这样的常见操作模式,在多模型协作场景中复用。
操作层(Operation Layer)是中央控制器,编排三个核心组件:
MemScheduler------记忆调度器。根据用户级、任务级或组织级上下文,动态选择参数、激活或明文记忆。支持可插拔的调度策略:LRU(最近最少使用)、语义相似度匹配、标签匹配等。
MemLifecycle------生命周期管理器。把记忆的生命周期建模为状态机,支持版本回滚和冻结机制,确保可审计性和时间一致性。这就像Git对代码做的事情------每次记忆更新都有版本记录,出了问题可以回滚。
MemOperator------记忆操作器。通过标签系统、图结构和多层分区来组织记忆,支持结构化搜索和语义搜索的混合查询。检索结果会回传给MemScheduler来决定激活路径,频繁访问的记忆条目会被缓存到中间层以优化性能。
基础设施层(Infrastructure Layer)负责记忆的合规、存储和流通。
MemGovernance------治理引擎。执行访问权限、生命周期策略和审计追踪,确保多用户环境下的安全和可问责。
MemVault------记忆仓库。管理多样化的记忆存储库,提供跨异构存储后端的统一访问。
MemLoader/MemDumper------记忆迁移工具。支持跨平台、跨Agent的结构化记忆迁移,同时保持上下文完整性。
MemStore------记忆商店。支持记忆单元的开放发布和订阅,实现多模型知识共享和协作执行。
这三层如何协同工作?论文的架构全景图把整个流程串了起来------

图4
图4:MemOS架构全景图。从顶部的用户/Agent/Pipeline入口,经过Memory API解析,进入MemScheduler调度和MemOperator组织,再到底层的MemVault存储、MemGovernance治理和MemStore发布------所有环节通过MemCube统一串联,形成端到端的记忆生命周期闭环。
6. 执行流程:一条记忆从输入到复用的完整旅程
一个典型的MemOS执行流程是这样的:
用户发出一个Prompt(比如"我的狗需要帮助!")。MemReader解析这条请求,识别出记忆相关意图,生成一个结构化的Memory API调用。这个调用启动一条Pipeline,上下文和状态通过MemCube单元传递。
MemScheduler根据访问模式和调度策略,选择相关的记忆------可能是参数记忆(模型对宠物护理的基础知识)、激活记忆(之前对话中的上下文状态)、或明文记忆(用户之前存储的宠物信息)。被选中的记忆单元被注入推理上下文。
MemOperator对记忆进行语义和结构化组织,MemLifecycle管理状态转换。归档的记忆被持久化到MemVault,由MemGovernance管理,并可以上传到MemStore供其他Agent下载使用。Agent之间的记忆迁移由MemLoader/MemDumper支持。
整个过程形成一个闭环------从输入到激活、转换、存储、复用------由声明式策略驱动,通过MemCube抽象执行。
论文用一个具体的例子展示了这条路径------
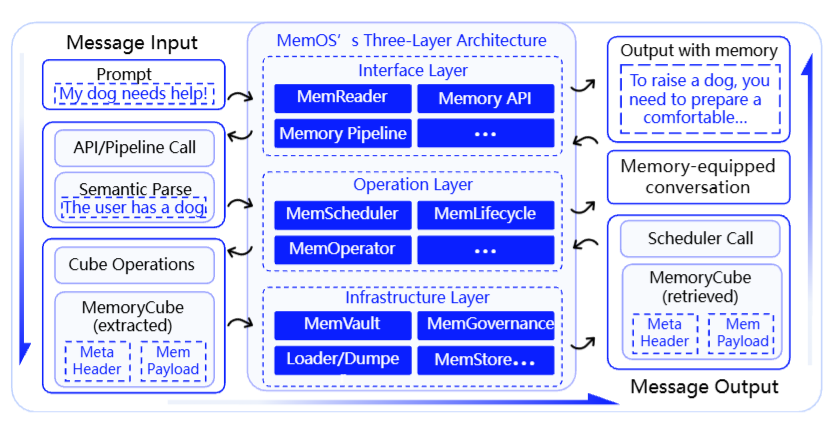
图5
图5:MemOS的记忆I/O路径实例。用户输入"My dog needs help!",MemReader语义解析出"用户有一只狗",MemScheduler检索到相关记忆("养狗需要准备舒适的..."),注入推理上下文后生成带记忆的回复。每个阶段都通过MemCube结构执行,实现可追踪的记忆生命周期管理。
7. Mem-training:Scaling Law的下一个变量
论文提出了一个大胆的判断------大模型能力进化的下一个飞跃,将来自记忆系统的引入。
过去的Scaling Law经历了两个阶段。Pre-training Scaling(2023年之前):更多数据+更大模型=更强能力,GPT-3.5/GPT-4是这个阶段的代表。Post-training Scaling(2024-2025):通过对齐、微调和强化学习在后训练阶段提升能力,GPT-O1/DeepSeek-R1是这个阶段的代表。
但Post-training Scaling正在遭遇双重瓶颈:性能增益递减和工程复杂度递增。
MemOS提出的"Mem-training Scaling"是第三条曲线------通过持续建模和调度记忆,让大模型在使用过程中不断积累经验、适应变化、迭代优化。学习和推理不再是分离的两个阶段,而是统一的、记忆驱动的过程。
论文用一张图把这个判断说得很清楚------
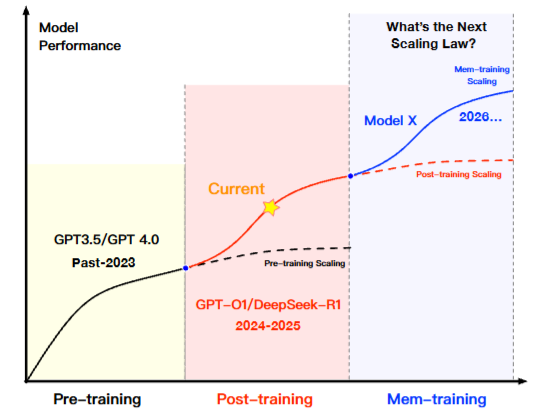
图6
图6:模型能力进化的三条Scaling曲线。Pre-training Scaling(2023年之前,代表:GPT-3.5/GPT-4)、Post-training Scaling(2024-2025,代表:GPT-O1/DeepSeek-R1)、Mem-training Scaling(论文预测2026年起)。每条曲线都有自己的天花板,而Mem-training被定位为突破Post-training瓶颈的下一个范式。从今天的时间点回看,这个预测正在逐步兑现。
这不是空想。当一个模型能够把用户偏好沉淀为参数记忆、把高频操作模式缓存为激活记忆、把领域知识结构化为明文记忆------并且这三种记忆可以跨会话、跨平台、跨Agent流转------它就不再是一个"无状态的生成器",而是一个"有记忆的智能体"。
8. MemOS vs 已有方案:从补丁到操作系统
把MemOS放在已有方案的版图中,它的定位非常清晰。
RAG(检索增强生成)是目前最主流的外部记忆方案。它的优势是简单直接------把相关文档检索出来塞进上下文窗口。但RAG本质上是个"临时补丁":没有记忆的生命周期管理(文档更新了怎么办?),没有跨类型融合(参数知识和检索知识冲突了怎么办?),没有治理机制(谁能访问哪些记忆?)。
Mem0是一个生产级的长期记忆工具包,支持可扩展的记忆存储和检索。但它主要处理明文记忆,缺乏对参数记忆和激活记忆的统一管理。
Letta(原MemGPT)把操作系统的分页思想引入上下文管理,实现了模块化调用。但它仍然局限于上下文层面的记忆操作,没有建立跨记忆类型的统一调度和生命周期治理。
EasyEdit专注于知识编辑------对参数记忆进行定向修改。但它是"手术刀"式的工具,不是系统级的记忆管理框架。
换句话说,RAG太浅(只处理明文检索),Mem0太窄(只管明文记忆),Letta太局限(只做上下文分页),EasyEdit太专(只改参数知识)。四条路线都没有真正触及"统一记忆管理"这个核心问题。
MemOS的定位正是在这四者之上建立一个统一的操作系统层------把参数、激活、明文三种记忆纳入同一个管理框架,提供标准化的封装(MemCube)、统一的调度(MemScheduler)、完整的生命周期管理(MemLifecycle)和严格的治理机制(MemGovernance)。
9. 未来方向:记忆商店、自进化记忆块、跨模型共享
论文在结尾描绘了三个值得关注的未来方向。
第一,跨LLM记忆共享。不同基础模型之间共享参数记忆和激活记忆,实现模块复用和协作知识迁移。为此,团队计划扩展Memory Interchange Protocol(MIP)------定义标准格式、兼容性规则和信任机制,用于跨模型/跨应用的记忆传输。这就像USB协议让不同设备可以互联互通------MIP要让不同模型的记忆可以互相"插拔"。
第二,自进化MemBlock。开发能够基于使用反馈进行自我优化、重构和进化的记忆单元,减少人工维护和监督的需求。记忆不再是静态的数据,而是能够"自我生长"的活性模块。
第三,可扩展的记忆商店(Memory Marketplace)。建立去中心化的记忆交换机制,支持资产级交易、协作更新和分布式进化。想象一下------一个医疗领域的专家记忆模块,可以在记忆商店中发布、定价、被其他Agent购买和使用。这不是科幻,而是MemOS架构自然延伸出的商业模式。
10. 从"生成"到"记住":大模型的下一个范式跃迁
MemOS的意义远不止一个技术系统。
它代表的是一种根本性的思路转变:大模型不应该只是"理解世界"的工具,而应该是能够"积累经验、保留记忆、持续进化"的智能体。过去几年,我们一直在让模型变得更大、更快、更聪明------但我们忽略了一个最基本的问题:一个没有记忆的系统,不管多聪明,都无法真正"成长"。
MemOS在2025年5月发布时还是一个原型系统(Short Version),论文没有给出大规模的实验验证数据。它的三层架构在工程落地时必然面临性能、一致性和安全性的多重挑战。跨模型记忆共享的语义对齐问题、记忆商店的信任机制设计、自进化记忆的可控性------每一个都是硬骨头。
但它提出了一个正确的问题,并给出了一个结构清晰的回答框架。
如果说Pre-training让大模型学会了"理解语言",Post-training让大模型学会了"遵循指令",那么Mem-training要让大模型学会的是"记住、适应、进化"。
MemOS不是终点,但它可能是通向"有记忆的AGI"的第一张架构蓝图。