Day 3 编程实战:逻辑回归与金融二分类
实战目标
- 手动实现逻辑回归(梯度下降)
- 理解Sigmoid函数和决策边界
- 构造技术指标特征(RSI、MACD)
- 预测股票次日涨跌
- 评估模型性能(混淆矩阵、AUC、ROC曲线)
1. 导入必要的库
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split, TimeSeriesSplit
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import (
accuracy_score, precision_score, recall_score, f1_score,
confusion_matrix, roc_auc_score, roc_curve, classification_report
)
import warnings
warnings.filterwarnings('ignore')
# 启用LaTeX渲染(如果系统安装了LaTeX)
plt.rcParams['text.usetex'] = False # 设为False避免LaTeX依赖
# 设置中文显示和美化
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
# sns.set_style("whitegrid")2. Sigmoid函数可视化
python
def sigmoid(z):
"""Sigmoid函数"""
return 1 / (1 + np.exp(-z))
def sigmoid_derivative(z):
"""Sigmoid的导数"""
s = sigmoid(z)
return s * (1 - s)
# 生成数据
z = np.linspace(-10, 10, 100)
s = sigmoid(z)
ds = sigmoid_derivative(z)
# 绘图
fig, axes = plt.subplots(1, 2, figsize=(7.5, 2.5))
# Sigmoid函数
axes[0].plot(z, s, 'b-', linewidth=2)
axes[0].axhline(y=0.5, color='r', linestyle='--', alpha=0.5)
axes[0].axvline(x=0, color='r', linestyle='--', alpha=0.5)
axes[0].set_xlabel('$z = β^T x$')
axes[0].set_ylabel('σ(z)')
axes[0].set_title('Sigmoid函数\n将任意实数映射到(0,1)区间')
axes[0].grid(True, alpha=0.3)
# Sigmoid导数
axes[1].plot(z, ds, 'g-', linewidth=2)
axes[1].set_xlabel('z')
axes[1].set_ylabel("σ'(z)")
axes[1].set_title('Sigmoid导数\n最大值在z=0处')
axes[1].grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print("\n关键观察:")
print("- z=0时,σ(0)=0.5,这是决策边界")
print("- |z|很大时,σ(z)接近0或1,但梯度接近0")
print("- 梯度消失:z=±10时,导数几乎为0")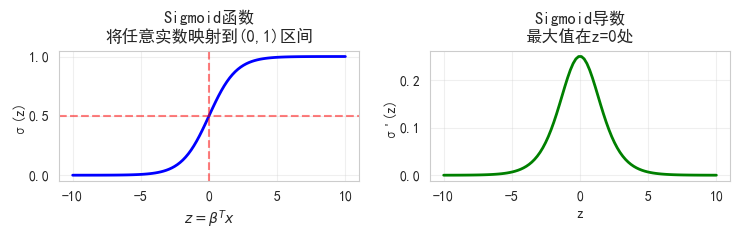
关键观察:
- z=0时,σ(0)=0.5,这是决策边界
- |z|很大时,σ(z)接近0或1,但梯度接近0
- 梯度消失:z=±10时,导数几乎为03. 手搓逻辑回归
python
class LogisticRegressionManual:
"""手动实现逻辑回归(梯度下降)"""
def __init__(self, learning_rate=0.01, n_iterations=1000,
regularization=None, lambda_reg=0.01):
"""
初始化逻辑回归模型
参数:
learning_rate (float): 学习率,控制梯度下降的步长,默认为0.01
n_iterations (int): 迭代次数,控制训练过程的轮数,默认为1000
regularization (str): 正则化类型,可选'l1'(Lasso)、'l2'(Ridge)或None,默认为None
lambda_reg (float): 正则化参数,控制正则化强度,默认为0.01
"""
self.learning_rate = learning_rate # 学习率:控制参数更新的步长
self.n_iterations = n_iterations # 迭代次数:训练的最大轮数
self.regularization = regularization # 正则化类型:防止过拟合的策略
self.lambda_reg = lambda_reg # 正则化参数:控制正则化项的权重
self.weights = None # 权重参数:特征对应的系数,训练后会被赋值
self.bias = None # 偏置项:截距项,训练后会被赋值
self.loss_history = [] # 损失历史:记录每次迭代的损失值,用于监控收敛情况
def sigmoid(self, z):
"""Sigmoid激活函数"""
return 1 / (1 + np.exp(-z))
def compute_loss(self, y_true, y_pred):
"""计算交叉熵损失"""
# 避免log(0)
eps = 1e-15
y_pred = np.clip(y_pred, eps, 1 - eps)
# 交叉熵损失
loss = -np.mean(y_true * np.log(y_pred) + (1 - y_true) * np.log(1 - y_pred))
# 添加正则化项
if self.regularization == 'l2':
loss += self.lambda_reg * np.sum(self.weights ** 2)
elif self.regularization == 'l1':
loss += self.lambda_reg * np.sum(np.abs(self.weights))
return loss
def fit(self, X, y):
"""训练模型"""
n_samples, n_features = X.shape
# 初始化参数
self.weights = np.zeros(n_features)
self.bias = 0
# 梯度下降
for i in range(self.n_iterations):
# 前向传播
linear_model = np.dot(X, self.weights) + self.bias
y_pred = self.sigmoid(linear_model)
# 计算梯度
dw = (1/n_samples) * np.dot(X.T, (y_pred - y))
db = (1/n_samples) * np.sum(y_pred - y)
# 添加正则化梯度
if self.regularization == 'l2':
dw += 2 * self.lambda_reg * self.weights
elif self.regularization == 'l1':
dw += self.lambda_reg * np.sign(self.weights)
# 更新参数
self.weights -= self.learning_rate * dw
self.bias -= self.learning_rate * db
# 记录损失
loss = self.compute_loss(y, y_pred)
self.loss_history.append(loss)
# 打印进度
if (i+1) % 200 == 0:
print(f"Iteration {i+1}/{self.n_iterations}, Loss: {loss:.4f}")
return self
def predict_proba(self, X):
"""预测概率"""
linear_model = np.dot(X, self.weights) + self.bias
return self.sigmoid(linear_model)
def predict(self, X, threshold=0.5):
"""预测类别"""
proba = self.predict_proba(X)
return (proba >= threshold).astype(int)
# 测试手动实现
print("测试手动实现的逻辑回归...")
# 生成简单数据
np.random.seed(42)
X_test_lr = np.random.randn(200, 2)
y_test_lr = (X_test_lr[:, 0] + X_test_lr[:, 1] > 0).astype(int)
# 训练
lr_manual = LogisticRegressionManual(learning_rate=0.1, n_iterations=1000)
lr_manual.fit(X_test_lr, y_test_lr)
# 评估
y_pred_manual = lr_manual.predict(X_test_lr)
accuracy = accuracy_score(y_test_lr, y_pred_manual)
print(f"\n手动实现准确率: {accuracy:.4f}")
# 对比sklearn
lr_sklearn = LogisticRegression()
lr_sklearn.fit(X_test_lr, y_test_lr)
y_pred_sklearn = lr_sklearn.predict(X_test_lr)
print(f"sklearn准确率: {accuracy_score(y_test_lr, y_pred_sklearn):.4f}")测试手动实现的逻辑回归...
Iteration 200/1000, Loss: 0.2165
Iteration 400/1000, Loss: 0.1625
Iteration 600/1000, Loss: 0.1372
Iteration 800/1000, Loss: 0.1215
Iteration 1000/1000, Loss: 0.1105
手动实现准确率: 1.0000
sklearn准确率: 1.00004. 决策边界可视化
python
def plot_decision_boundary(model, X, y, title="决策边界"):
"""绘制决策边界"""
# 创建网格
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
# 预测网格点
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘图
plt.figure(figsize=(5, 4))
plt.contourf(xx, yy, Z, alpha=0.3, cmap='RdYlBu')
plt.scatter(X[y==0, 0], X[y==0, 1], c='green', label='下跌', alpha=0.6, edgecolors='k')
plt.scatter(X[y==1, 0], X[y==1, 1], c='red', label='上涨', alpha=0.6, edgecolors='k')
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.title(title)
plt.legend()
plt.colorbar()
plt.show()
# 使用sklearn模型绘制决策边界
plot_decision_boundary(lr_sklearn, X_test_lr, y_test_lr, "逻辑回归决策边界(线性)")
print("观察: 逻辑回归产生线性决策边界")
# 非线性决策边界示例
from sklearn.preprocessing import PolynomialFeatures
# 添加多项式特征
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(X_test_lr)
# 训练多项式逻辑回归
lr_poly = LogisticRegression()
lr_poly.fit(X_poly, y_test_lr)
print("\n多项式特征可以产生非线性决策边界")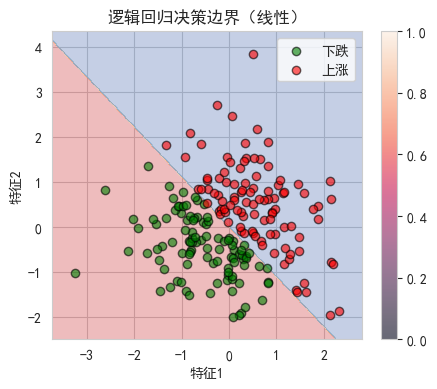
观察: 逻辑回归产生线性决策边界
多项式特征可以产生非线性决策边界5. 技术指标计算函数
5.1 RSI计算
python
def calculate_rsi(prices, period=14):
"""
计算相对强弱指标(RSI)
参数:
- prices: 价格序列
- period: 计算周期(通常14天)
返回:
- RSI值(0-100)
"""
# 计算价格变化
delta = prices.diff()
# 分离涨跌
gain = delta.where(delta > 0, 0)
loss = -delta.where(delta < 0, 0)
# 计算平均涨跌幅
avg_gain = gain.rolling(window=period).mean()
avg_loss = loss.rolling(window=period).mean()
# 计算RS和RSI
rs = avg_gain / avg_loss
rsi = 100 - (100 / (1 + rs))
return rsi
# 测试RSI
df = pd.read_csv(r"E:\AppData\quant_trade\klines\20260413\600125.SH.csv")
test_prices = df["close"].sort_index(ascending=False).reset_index(drop=True)
test_rsi = calculate_rsi(test_prices)
plt.figure(figsize=(6, 3))
plt.plot(test_rsi)
plt.axhline(y=70, color='r', linestyle='--', label='超买线(70)')
plt.axhline(y=30, color='g', linestyle='--', label='超卖线(30)')
plt.fill_between(range(len(test_rsi)), 70, test_rsi, where=(test_rsi>70), color='red', alpha=0.3)
plt.fill_between(range(len(test_rsi)), test_rsi, 30, where=(test_rsi<30), color='green', alpha=0.3)
plt.xlabel('时间')
plt.ylabel('RSI')
plt.title('RSI指标示例')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()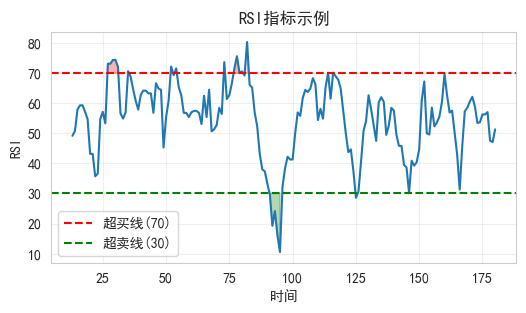
5.2 MACD计算
python
def calculate_macd(prices, fast=12, slow=26, signal=9):
"""
计算MACD指标
参数:
- prices: 价格序列
- fast: 快线周期
- slow: 慢线周期
- signal: 信号线周期
返回:
- macd: MACD线
- signal_line: 信号线
- histogram: MACD柱
"""
# 计算EMA
ema_fast = prices.ewm(span=fast, adjust=False).mean()
ema_slow = prices.ewm(span=slow, adjust=False).mean()
# MACD线
macd = ema_fast - ema_slow
# 信号线
signal_line = macd.ewm(span=signal, adjust=False).mean()
# MACD柱
histogram = macd - signal_line
return macd, signal_line, histogram
# 测试MACD
test_macd, test_signal, test_hist = calculate_macd(test_prices)
plt.figure(figsize=(8, 4))
plt.subplot(2, 1, 1)
plt.plot(test_prices, label='价格')
plt.title('价格序列')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(2, 1, 2)
plt.plot(test_macd, label='MACD线', linewidth=2)
plt.plot(test_signal, label='信号线', linewidth=2)
plt.bar(range(len(test_hist)), test_hist, label='MACD柱', alpha=0.3)
plt.axhline(y=0, color='k', linestyle='-', alpha=0.3)
plt.xlabel('时间')
plt.ylabel('MACD')
plt.title('MACD指标')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()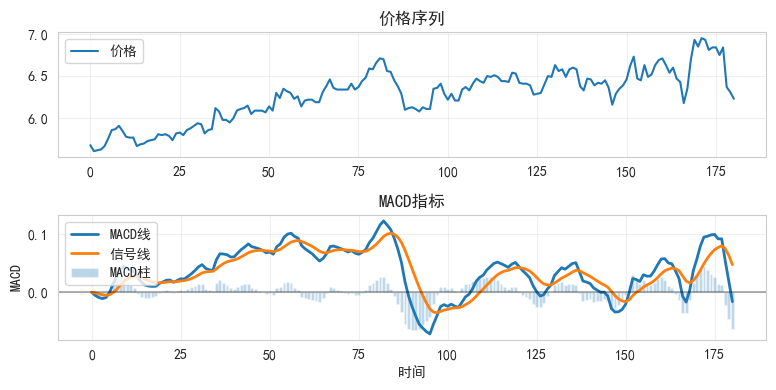
6. 金融数据获取与特征工程
6.1 加载股票数据
python
df = pd.read_csv(r"E:\AppData\quant_trade\klines\20260413\600125.SH.csv",
usecols =["trade_date", "close", "vol"],
parse_dates=["trade_date"]).sort_values(by="trade_date").reset_index(drop=True)
# 计算收益率
df['return'] = df['close'].pct_change()
# 计算技术指标
df['rsi'] = calculate_rsi(df['close'], period=14)
macd, signal, hist = calculate_macd(df['close'])
df['macd'] = macd
df['macd_signal'] = signal
df['macd_hist'] = hist
# 添加其他常用指标
df['ma_5'] = df['close'].rolling(5).mean()
df['ma_20'] = df['close'].rolling(20).mean()
df['volume_ma'] = df['vol'].rolling(10).mean()
df['volatility'] = df['return'].rolling(20).std()
# 目标变量:次日是否上涨
df['target'] = (df['return'].shift(-1) > 0).astype(int)
# 删除缺失值
df = df.dropna()
print(f"数据形状: {df.shape}")
print(f"数据时间范围: {df['trade_date'].min()} 到 {df['trade_date'].max()}")
df.head()数据形状: (161, 13)
数据时间范围: 2025-08-11 00:00:00 到 2026-04-13 00:00:00| | trade_date | close | vol | return | rsi | macd | macd_signal | macd_hist | ma_5 | ma_20 | volume_ma | volatility | target |
| 20 | 2025-08-11 | 5.80 | 159327.18 | -0.001721 | 43.181818 | 0.018009 | 0.016650 | 0.001359 | 5.766 | 5.7495 | 126233.852 | 0.008881 | 1 |
| 21 | 2025-08-12 | 5.81 | 113282.27 | 0.001724 | 43.181818 | 0.020812 | 0.017482 | 0.003330 | 5.782 | 5.7595 | 123793.412 | 0.008302 | 0 |
| 22 | 2025-08-13 | 5.79 | 151760.00 | -0.003442 | 35.714286 | 0.021175 | 0.018221 | 0.002955 | 5.792 | 5.7680 | 125513.412 | 0.008384 | 0 |
| 23 | 2025-08-14 | 5.74 | 138247.09 | -0.008636 | 36.585366 | 0.017230 | 0.018023 | -0.000792 | 5.790 | 5.7735 | 122786.921 | 0.008685 | 1 |
| 24 | 2025-08-15 | 5.82 | 216365.40 | 0.013937 | 54.761905 | 0.020325 | 0.018483 | 0.001842 | 5.792 | 5.7810 | 133923.742 | 0.009064 | 1 |
|---|
6.2 特征选择与准备
python
# 选择特征
feature_cols = [
'return', # 当日收益率
'rsi', # RSI指标
'macd', # MACD线
'macd_signal', # MACD信号线
'macd_hist', # MACD柱
'ma_5', # 5日均线
'ma_20', # 20日均线
'volume_ma', # 成交量均线
'volatility' # 波动率
]
# 检查特征相关性
correlation_matrix = df[feature_cols + ['target']].corr()
plt.figure(figsize=(6, 5))
sns.heatmap(correlation_matrix, annot=True, fmt='.2f', cmap='coolwarm',
center=0, square=True)
plt.title('特征相关性矩阵')
plt.tight_layout()
plt.show()
# 查看特征与目标的相关性
target_corr = correlation_matrix['target'].drop('target').sort_values(ascending=False)
print("\n特征与目标的相关性:")
print(target_corr)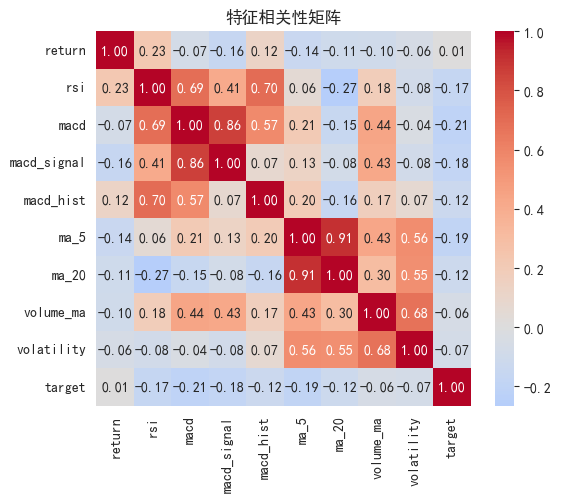
特征与目标的相关性:
return 0.008254
volume_ma -0.056885
volatility -0.073198
ma_20 -0.116996
macd_hist -0.123097
rsi -0.168707
macd_signal -0.176575
ma_5 -0.189182
macd -0.208347
Name: target, dtype: float647. 模型训练与评估
7.1 数据划分(时间序列)
python
# 按时间顺序划分
split_idx = int(len(df) * 0.7)
train_df = df[:split_idx]
test_df = df[split_idx:]
X_train = train_df[feature_cols]
y_train = train_df['target']
X_test = test_df[feature_cols]
y_test = test_df['target']
print(f"训练集: {len(train_df)} 样本 ({train_df['trade_date'].min()} 到 {train_df['trade_date'].max()})")
print(f"测试集: {len(test_df)} 样本 ({test_df['trade_date'].min()} 到 {test_df['trade_date'].max()})")
# 特征标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)训练集: 112 样本 (2025-08-11 00:00:00 到 2026-01-23 00:00:00)
测试集: 49 样本 (2026-01-26 00:00:00 到 2026-04-13 00:00:00)7.2 训练不同正则化的逻辑回归
python
# 创建不同配置的模型
models = {
'无正则化': LogisticRegression(penalty=None, solver='lbfgs', max_iter=1000),
'L2正则化 (C=1)': LogisticRegression(penalty='l2', C=1.0, max_iter=1000),
'L2正则化 (C=0.1)': LogisticRegression(penalty='l2', C=0.1, max_iter=1000),
'L1正则化 (C=1)': LogisticRegression(penalty='l1', solver='saga', C=1.0, max_iter=1000),
}
# 训练和评估
results = []
for name, model in models.items():
# 训练
model.fit(X_train_scaled, y_train)
# 预测
y_pred = model.predict(X_test_scaled)
y_pred_proba = model.predict_proba(X_test_scaled)[:, 1]
# 计算指标
results.append({
'Model': name,
'Accuracy': accuracy_score(y_test, y_pred),
'Precision': precision_score(y_test, y_pred),
'Recall': recall_score(y_test, y_pred),
'F1': f1_score(y_test, y_pred),
'AUC': roc_auc_score(y_test, y_pred_proba)
})
results_df = pd.DataFrame(results)
# print(results_df.to_string(index=False))
results_df.set_index(["Model"])| | Accuracy | Precision | Recall | F1 | AUC |
| Model | | | | | |
| 无正则化 | 0.591837 | 0.560000 | 0.608696 | 0.583333 | 0.610368 |
| L2正则化 (C=1) | 0.591837 | 0.666667 | 0.260870 | 0.375000 | 0.677258 |
| L2正则化 (C=0.1) | 0.571429 | 1.000000 | 0.086957 | 0.160000 | 0.673913 |
| L1正则化 (C=1) | 0.530612 | 0.500000 | 0.130435 | 0.206897 | 0.688963 |
|---|
7.3 混淆矩阵可视化
python
# 选择最佳模型(这里用L2 C=1)
best_model = LogisticRegression(penalty='l2', C=1.0, max_iter=1000)
best_model.fit(X_train_scaled, y_train)
y_pred_best = best_model.predict(X_test_scaled)
# 混淆矩阵
cm = confusion_matrix(y_test, y_pred_best)
plt.figure(figsize=(4, 3))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=['预测下跌', '预测上涨'],
yticklabels=['实际下跌', '实际上涨'])
plt.title('混淆矩阵 - 股票涨跌预测')
plt.ylabel('真实标签')
plt.xlabel('预测标签')
plt.show()
# 计算并显示详细指标
print("\n分类报告:")
print(classification_report(y_test, y_pred_best, target_names=['下跌', '上涨']))
# 解释混淆矩阵
tn, fp, fn, tp = cm.ravel()
print(f"\n详细解读:")
print(f"- 正确预测下跌: {tn} 次")
print(f"- 正确预测上涨: {tp} 次")
print(f"- 误报(预测涨实际跌): {fp} 次")
print(f"- 漏报(预测跌实际涨): {fn} 次")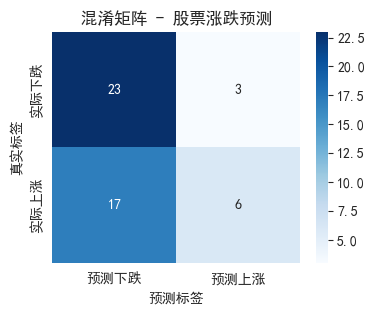
分类报告:
precision recall f1-score support
下跌 0.57 0.88 0.70 26
上涨 0.67 0.26 0.38 23
accuracy 0.59 49
macro avg 0.62 0.57 0.54 49
weighted avg 0.62 0.59 0.55 49
详细解读:
-
正确预测下跌: 23 次
-
正确预测上涨: 6 次
-
误报(预测涨实际跌): 3 次
-
漏报(预测跌实际涨): 17 次
7.4 ROC曲线与AUC
python
# 获取预测概率
y_pred_proba = best_model.predict_proba(X_test_scaled)[:, 1]
# 计算ROC曲线
fpr, tpr, thresholds = roc_curve(y_test, y_pred_proba)
auc = roc_auc_score(y_test, y_pred_proba)
# 绘制ROC曲线
plt.figure(figsize=(5, 4))
plt.plot(fpr, tpr, linewidth=2, label=f'逻辑回归 (AUC = {auc:.4f})')
plt.plot([0, 1], [0, 1], 'k--', linewidth=1, label='随机分类器 (AUC=0.5)')
plt.fill_between(fpr, tpr, alpha=0.2)
# 标记最优阈值
optimal_idx = np.argmax(tpr - fpr)
optimal_threshold = thresholds[optimal_idx]
plt.scatter(fpr[optimal_idx], tpr[optimal_idx], c='red', s=100,
label=f'最优阈值 = {optimal_threshold:.3f}')
plt.xlabel('假阳性率 (False Positive Rate)', fontsize=12)
plt.ylabel('真阳性率 (True Positive Rate)', fontsize=12)
plt.title('ROC曲线 - 股票涨跌预测', fontsize=14)
plt.legend(loc='lower right')
plt.grid(True, alpha=0.3)
plt.show()
print(f"AUC值: {auc:.4f}")
print(f"AUC解读: ", end="")
if auc >= 0.8:
print("优秀")
elif auc >= 0.7:
print("良好")
elif auc >= 0.6:
print("一般")
else:
print("较差")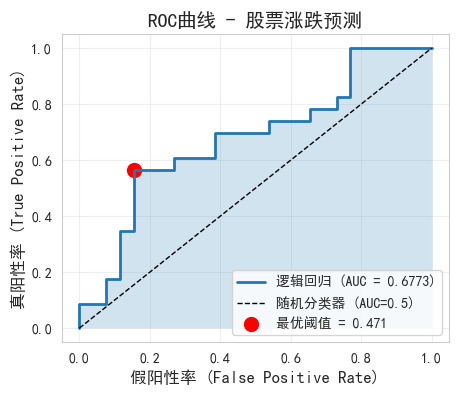
AUC值: 0.6773
AUC解读: 一般8. 阈值优化与策略应用
8.1 不同阈值下的性能对比
python
# 测试不同阈值
thresholds_test = np.arange(0.1, 0.9, 0.05)
precision_scores = []
recall_scores = []
f1_scores = []
for threshold in thresholds_test:
y_pred_thresh = (y_pred_proba >= threshold).astype(int)
precision_scores.append(precision_score(y_test, y_pred_thresh, zero_division=0))
recall_scores.append(recall_score(y_test, y_pred_thresh, zero_division=0))
f1_scores.append(f1_score(y_test, y_pred_thresh, zero_division=0))
# 可视化
plt.figure(figsize=(5, 3))
plt.plot(thresholds_test, precision_scores, 'o-', label='精确率 (Precision)', linewidth=2)
plt.plot(thresholds_test, recall_scores, 's-', label='召回率 (Recall)', linewidth=2)
plt.plot(thresholds_test, f1_scores, '^-', label='F1分数', linewidth=2)
plt.xlabel('决策阈值')
plt.ylabel('分数')
plt.title('不同阈值下的模型性能')
plt.legend()
plt.grid(True, alpha=0.3)
plt.axvline(x=0.5, color='red', linestyle='--', alpha=0.5, label='默认阈值=0.5')
plt.legend()
plt.show()
# 找到最佳F1阈值
best_f1_idx = np.argmax(f1_scores)
best_f1_threshold = thresholds_test[best_f1_idx]
print(f"最佳F1阈值: {best_f1_threshold:.3f}")
print(f"此时精确率: {precision_scores[best_f1_idx]:.4f}")
print(f"此时召回率: {recall_scores[best_f1_idx]:.4f}")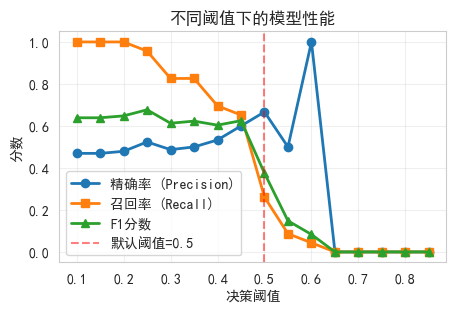
最佳F1阈值: 0.250
此时精确率: 0.5238
此时召回率: 0.95658.2 简单交易策略模拟
python
# 基于预测概率构建交易信号
def backtest_strategy(probabilities, prices, threshold=0.5, transaction_cost=0.001):
"""
简单回测策略:当预测上涨概率 > threshold时买入并持有1天
参数:
- probabilities: 预测的上涨概率
- prices: 价格序列
- threshold: 决策阈值
- transaction_cost: 交易成本(滑点+手续费)
"""
# 生成交易信号
signals = (probabilities > threshold).astype(int)
# 将 signals 转换为 Series,索引与 prices 保持一致
signals = pd.Series(signals, index=prices.index)
# 计算策略收益
returns = prices.pct_change().shift(-1) # 次日收益
strategy_returns = signals * returns
# 扣除交易成本(每次交易时)
trade_indicators = (signals != signals.shift(1)).astype(int)
strategy_returns -= trade_indicators * transaction_cost
# 计算累计收益
strategy_cumulative = (1 + strategy_returns).cumprod()
buy_hold_cumulative = (1 + returns).cumprod()
# 计算绩效指标
sharpe_ratio = strategy_returns.mean() / strategy_returns.std() * np.sqrt(252)
max_drawdown = (strategy_cumulative / strategy_cumulative.cummax() - 1).min()
return strategy_cumulative, buy_hold_cumulative, sharpe_ratio, max_drawdown
# 执行回测
test_prices = test_df['close']
strategy_cum, bh_cum, sharpe, mdd = backtest_strategy(
y_pred_proba, test_prices, threshold=0.6
)
# 可视化回测结果
plt.figure(figsize=(6, 3))
plt.plot(strategy_cum, label=f'策略收益 (夏普={sharpe:.2f})', linewidth=2)
plt.plot(bh_cum, label='买入持有', linewidth=2, alpha=0.7)
plt.xlabel('交易日期')
plt.ylabel('累计收益')
plt.title('策略回测表现')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
print(f"策略年化夏普比率: {sharpe:.4f}")
print(f"最大回撤: {mdd:.4%}")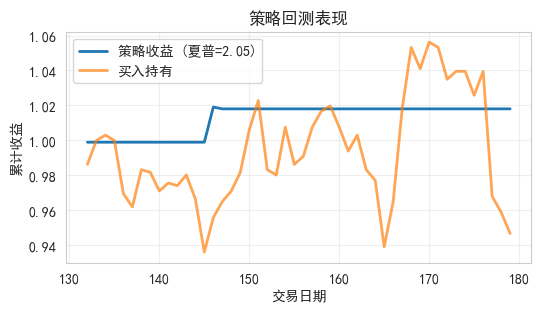
策略年化夏普比率: 2.0540
最大回撤: -0.1000%9. 特征重要性分析
逻辑回归系数解释
python
# 获取特征系数
coefficients = best_model.coef_[0]
feature_importance = pd.DataFrame({
'Feature': feature_cols,
'Coefficient': coefficients,
'Abs_Coefficient': np.abs(coefficients)
}).sort_values('Abs_Coefficient', ascending=False)
# 可视化
plt.figure(figsize=(5, 3))
plt.barh(feature_importance['Feature'], feature_importance['Coefficient'])
plt.xlabel('系数值')
plt.ylabel('特征')
plt.title('逻辑回归特征重要性\n(正系数促进上涨预测,负系数促进下跌预测)')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print("\n特征重要性排序:")
print(feature_importance.to_string(index=False))
# 解释
print("\n系数解读:")
print("- 正系数: 该特征值越大,预测上涨的概率越高")
print("- 负系数: 该特征值越大,预测下跌的概率越高")
print("- |系数|越大: 该特征对预测的影响越大")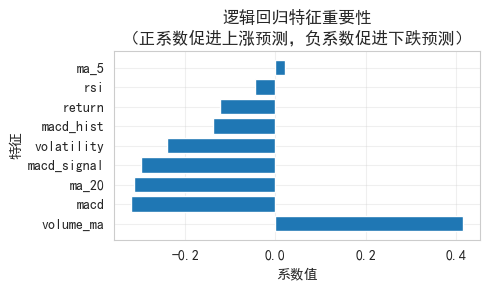
特征重要性排序:
Feature Coefficient Abs_Coefficient
volume_ma 0.416180 0.416180
macd -0.319852 0.319852
ma_20 -0.312888 0.312888
macd_signal -0.298601 0.298601
volatility -0.240392 0.240392
macd_hist -0.138321 0.138321
return -0.123296 0.123296
rsi -0.045864 0.045864
ma_5 0.022027 0.022027
系数解读:
- 正系数: 该特征值越大,预测上涨的概率越高
- 负系数: 该特征值越大,预测下跌的概率越高
- |系数|越大: 该特征对预测的影响越大10. 模型优化与交叉验证
网格搜索找最佳参数
python
from sklearn.model_selection import GridSearchCV
# 定义参数网格
param_grid = {
'C': [0.001, 0.01, 0.1, 1, 10, 100], # 正则化强度
'penalty': ['l1', 'l2'],
'solver': ['saga'] # 支持l1和l2
}
# 时间序列交叉验证
tscv = TimeSeriesSplit(n_splits=5)
# 网格搜索
lr_grid = LogisticRegression(max_iter=1000, random_state=42)
grid_search = GridSearchCV(lr_grid, param_grid, cv=tscv, scoring='roc_auc', n_jobs=-1)
grid_search.fit(X_train_scaled, y_train)
print("最佳参数:")
print(grid_search.best_params_)
print(f"\n最佳CV AUC: {grid_search.best_score_:.4f}")
# 使用最佳模型
best_cv_model = grid_search.best_estimator_
y_pred_cv = best_cv_model.predict(X_test_scaled)
y_pred_proba_cv = best_cv_model.predict_proba(X_test_scaled)[:, 1]
print(f"\n测试集AUC: {roc_auc_score(y_test, y_pred_proba_cv):.4f}")
print(f"测试集准确率: {accuracy_score(y_test, y_pred_cv):.4f}")最佳参数:
{'C': 10, 'penalty': 'l2', 'solver': 'saga'}
最佳CV AUC: 0.6629
测试集AUC: 0.6304
测试集准确率: 0.632711. 今日总结与练习
核心要点回顾
逻辑回归基础:
- 通过Sigmoid函数将线性输出转换为概率
- 决策边界是线性的
- 使用交叉熵损失函数
技术指标:
- RSI: 动量指标,超买超卖判断
- MACD: 趋势跟踪指标
模型评估:
- 混淆矩阵:直观展示预测结果
- ROC/AUC:评价排序能力
- 精确率vs召回率:根据策略目标选择
量化应用:
- 阈值调整可以适应不同风险偏好
- 概率输出可用于仓位管理
- 需要警惕过拟合
今日练习
python
# 练习1:修改技术指标参数(如RSI周期、MACD参数),观察对模型性能的影响
# 练习2:尝试不同的决策阈值,找到最适合你风险偏好的阈值
# 练习3:添加更多技术指标(如布林带、KDJ),看是否能提升AUC
# 练习4:使用实际股票数据(通过yfinance)替换模拟数据思考题
- 为什么在量化交易中AUC比准确率更适合作为评估指标?
- 如何根据策略目标选择精确率和召回率的平衡点?
- 逻辑回归的线性决策边界在什么情况下会成为限制?