Hive的安装部署
安装MySQL数据库(在hadoop01节点上)
(1) 在线安装MySQL
使用root用户登录hadoop01节点,执行以下命令:
bash
# 切换到root用户
sudo -i
# 在线安装MySQL
apt install mysql-server -y(2) 启动MySQL服务
bash
# 启动MySQL服务
systemctl start mysql
#如果你想, 设置MySQL开机自启
systemctl enable mysql
(3) 设置MySQL root用户密码
1) 无密码登录MySQL
bash
mysql -u root -p
# 出现密码提示时直接按Enter键
2) 设置root用户密码
在MySQL客户端中执行:
sql
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'root';
FLUSH PRIVILEGES;
exit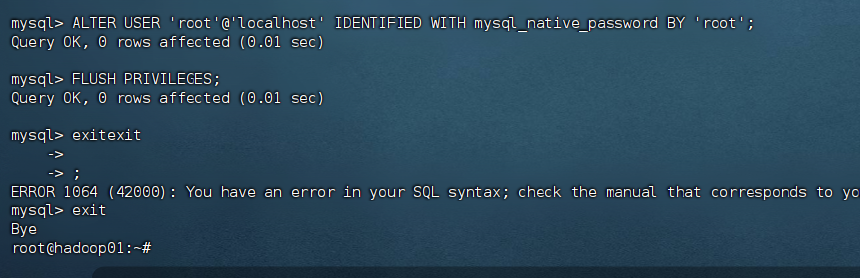
3) 有密码登录MySQL验证
bash
mysql -u root -p
# 输入密码:root
(4) 创建Hive账户
在MySQL客户端中执行:
sql
CREATE USER 'hive'@'%' IDENTIFIED BY 'hive';2) 授予Hive用户权限
sql
-- 赋予所有数据库的所有权限
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%' WITH GRANT OPTION;
-- 确保 hive 用户允许从任何主机连接
CREATE USER IF NOT EXISTS 'hive'@'%' IDENTIFIED BY 'hive';
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;
-- 刷新权限
FLUSH PRIVILEGES;
3) 验证Hive用户登录
bash
#密码为hive
mysql -h hadoop01 -u hive -p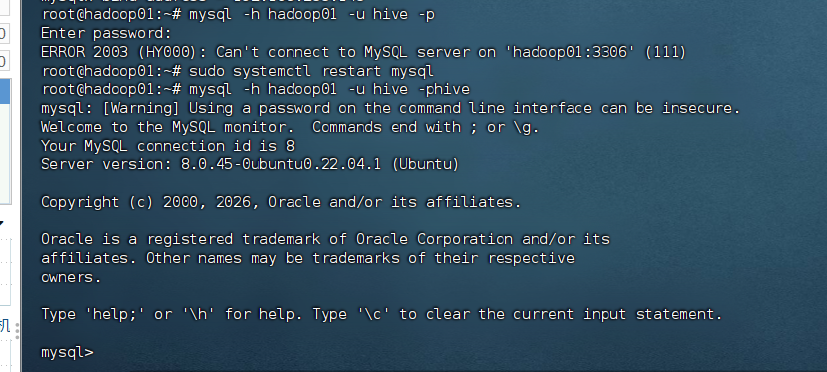
遇到问题了,hive连接不上

bash
# 修改 bind-address 为正确的 IP
sudo sed -i 's/bind-address.*=.*/bind-address = 192.168.255.145/' /etc/mysql/mysql.conf.d/mysqld.cnf
# 验证修改
sudo grep bind-address /etc/mysql/mysql.conf.d/mysqld.cnf
sudo systemctl restart mysql
安装Hive
(1) 下载Hive
切换到hadoop用户:
bash
su hadoop
cd /home/hadoop/app从官网下载或使用本书配套资源中的Hive安装包:
bash
# 如果使用wget下载
wget http://archive.apache.org/dist/hive/hive-2.3.7/apache-hive-2.3.7-bin.tar.gz(2) 解压Hive并创建软链接
bash
# 解压Hive安装包
tar -zxvf apache-hive-2.3.7-bin.tar.gz
# 创建软链接
ln -s apache-hive-2.3.7-bin hive
(3) 配置Hive环境变量
编辑hadoop用户的bashrc文件:
bash
vim ~/.bashrc在文件末尾添加以下内容:
bash
export HIVE_HOME=/home/hadoop/app/hive
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$PATH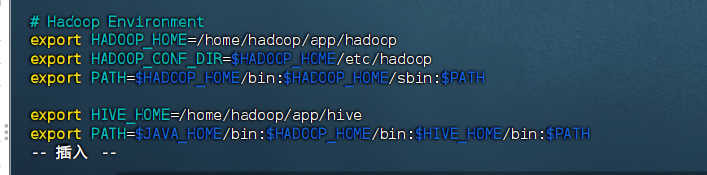
使配置生效:
bash
source ~/.bashrc
(4) 配置hive-site.xml
bash
cd $HIVE_HOME/conf
cp hive-default.xml.template hive-site.xml编辑hive-site.xml文件,修改以下配置:
1) 配置MySQL连接驱动
xml
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>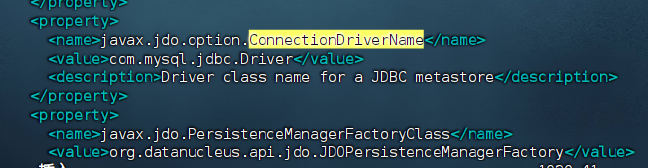
2) 修改MySQL连接URL
xml
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
3) 配置数据库用户名和密码
xml
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
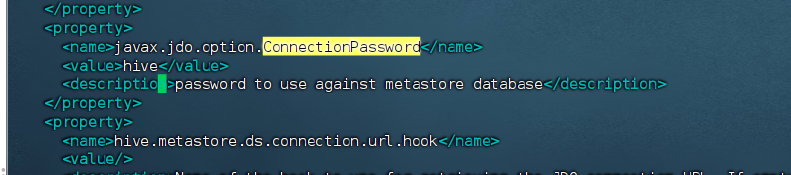
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>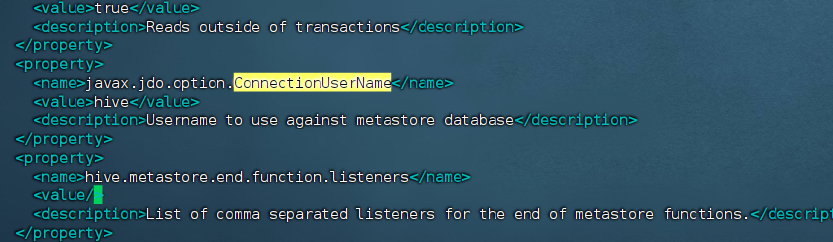
4) 添加Hive数据目录
xml
<property>
<name>hive.querylog.location</name>
<value>/home/hadoop/app/hive/iotmp</value>
<description>Location of Hive run time structured log file</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hadoop/app/hive/iotmp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hadoop/app/hive/iotmp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
需要删除的代码块
xml
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>mine</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>APP</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;create=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
<description>Driver class name for a JDBC metastore</description>
</property>把临时目录改了
xml
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
<description>...</description>
</property>改成自己的临时目录:
xml
<property>
<name>hive.exec.scratchdir</name>
<!-- 改为你已创建的 /home/hadoop/app/hive/iotmp -->
<value>/home/hadoop/app/hive/iotmp</value>
<description>...</description>
</property>
把{...}里面的说清楚
改成:
xml
<property>
<name>hive.exec.local.scratchdir</name>
<!-- 原配置:${system:java.io.tmpdir}/${system:user.name} -->
<value>/home/hadoop/app/hive/iotmp</value> <!-- 替换为具体路径 -->
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<!-- 原配置:${system:java.io.tmpdir}/${hive.session.id}_resources -->
<value>/home/hadoop/app/hive/iotmp/${hive.session.id}_resources</value> <!-- 替换前缀 -->
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
以及:
xml
<property>
<name>hive.querylog.location</name>
<!-- 原配置:${system:java.io.tmpdir}/${system:user.name} -->
<value>/home/hadoop/app/hive/iotmp</value> <!-- 替换为具体路径 -->
<description>Location of Hive run time structured log file</description>
</property>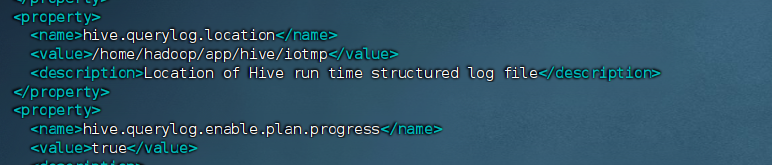
xml
<property>
<name>hive.server2.logging.operation.log.location</name>
<!-- 原配置:${system:java.io.tmpdir}/${system:user.name}/operation_logs -->
<value>/home/hadoop/app/hive/iotmp/operation_logs</value> <!-- 替换为具体路径 -->
<description>...</description>
</property>
验证 XML 是否正确
(5) 添加MySQL驱动包
下载mysql-connector-java-8.0.33 .jar驱动包,在hive的lib目录下
https://downloads.mysql.com/archives/c-j/
(6) 创建Hive临时目录
bash
mkdir -p /home/hadoop/app/hive/iotmp(7) 初始化Hive元数据库
先启动好hdfs,yarn,mysql
bash
cd /home/hadoop/app/hive
schematool -dbType mysql -initSchema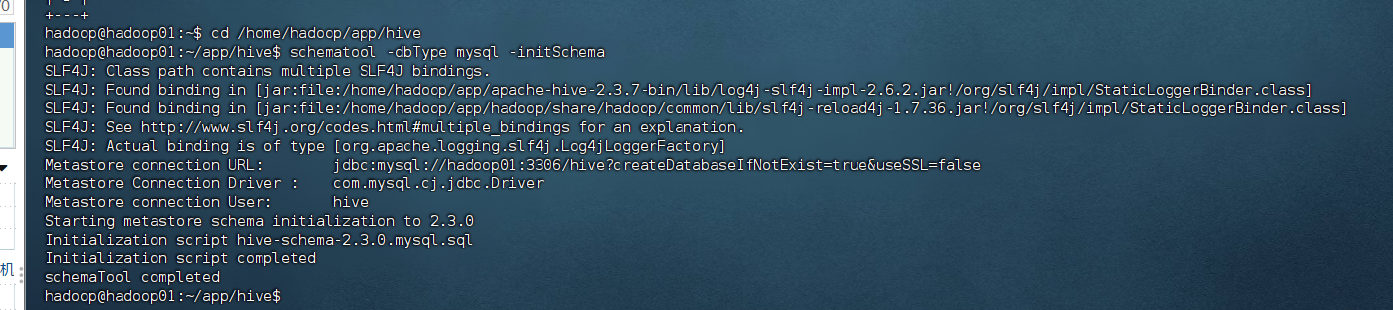
启动和验证Hive
(1) 启动Hive
bash
# 确保Hadoop集群已启动,也就是zookeeper,hdfs,yarn
cd /home/hadoop/app/zookeeper/bin
./zkServer.sh start
start-dfs.sh
start-yarn.sh
# 启动Hive
hive
(2) 验证Hive安装
在Hive命令行中执行:
sql
-- 显示数据库
show databases;
-- 创建测试表
create table test(id int, name string);
-- 查看表
show tables;
-- 插入数据
insert into test values(1, 'test');
-- 查询数据
select * from test;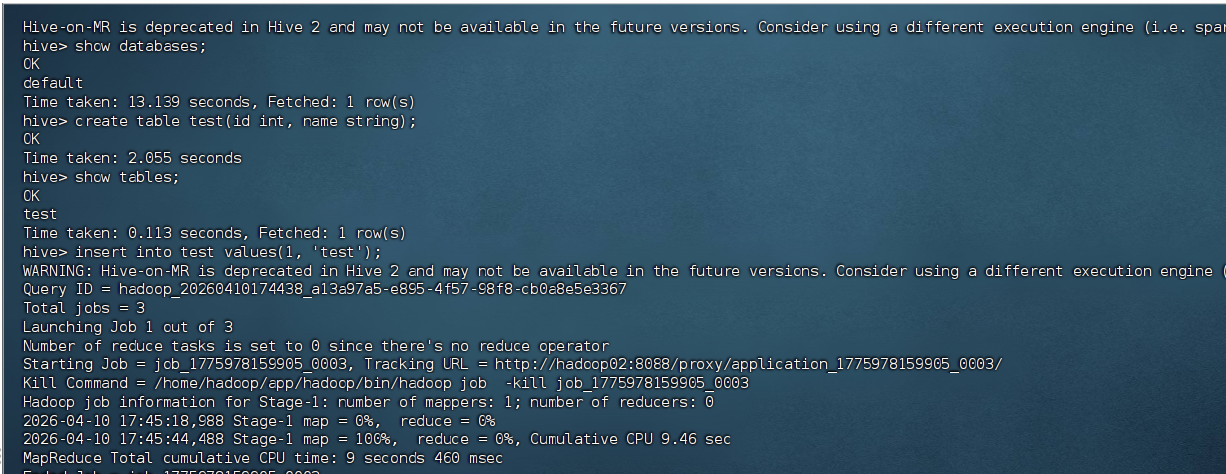
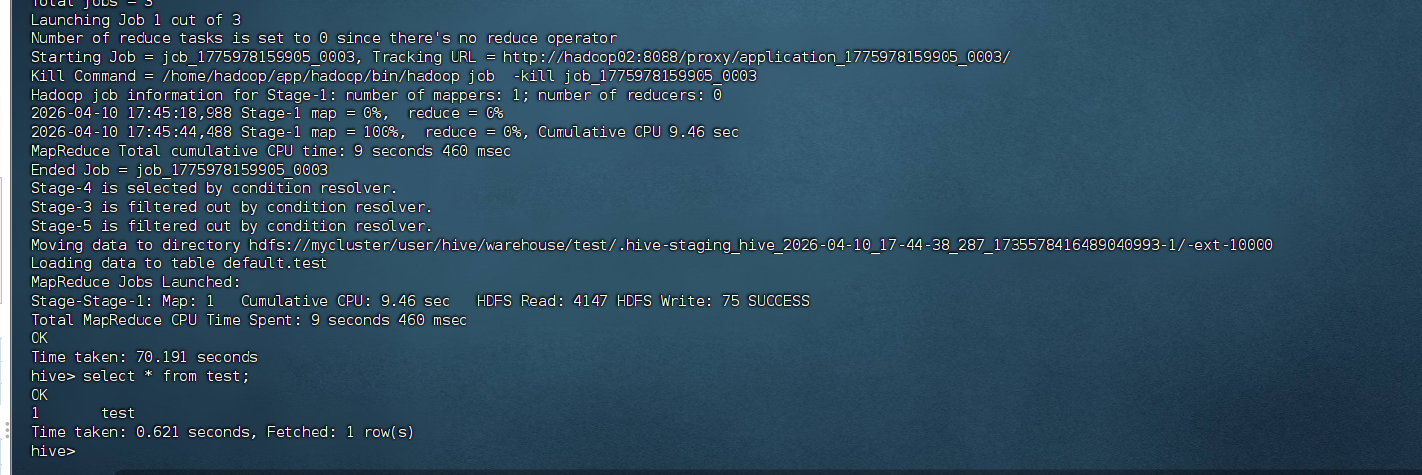
故障排除
常见问题1:MySQL连接失败
解决方案:
- 检查MySQL服务是否启动:
service mysqld status - 检查MySQL用户权限:确保hive用户有远程登录权限
- 检查防火墙设置:
systemctl stop firewalld
常见问题2:HDFS权限问题
解决方案:
- 在Hadoop的core-site.xml中添加:
xml
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>常见问题3:元数据库初始化失败
解决方案:
- 删除MySQL中的hive数据库:
mysql -u root -p -e "DROP DATABASE hive" - 重新初始化:
schematool -dbType mysql -initSchema
WordCount 实验
7.1 准备数据文件
bash
# 创建数据目录
# sudo mkdir -p /opt/hive/data
# 如果提示权限不足,可以用sudo,或改成/home/hadoop/data
# 这里建议改成hadoop用户有权限的目录,避免权限问题
mkdir -p /home/hadoop/hive_data
# 创建单词文件
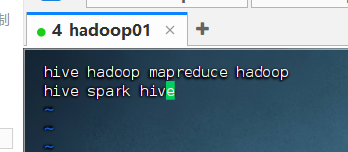
vim /home/hadoop/hive_data/words.txt输入以下内容:
plain
hive hadoop mapreduce hadoop
hive spark hive
7.2 在 Hive 中创建表并加载数据
进入 Hive 命令行后:
sql
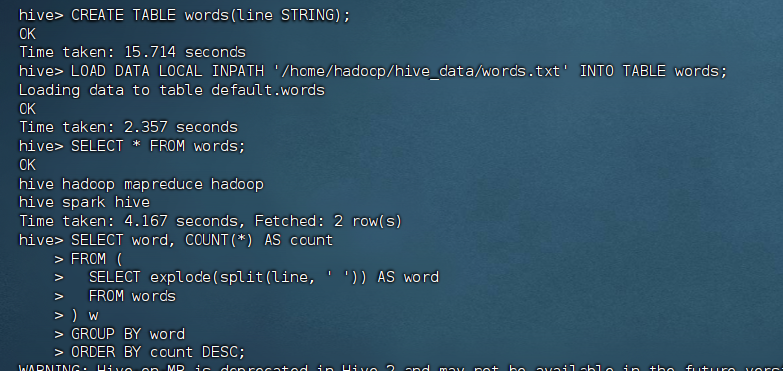
CREATE TABLE words(line STRING);
LOAD DATA LOCAL INPATH '/home/hadoop/hive_data/words.txt' INTO TABLE words;7.3 执行 WordCount
sql
SELECT * FROM words;
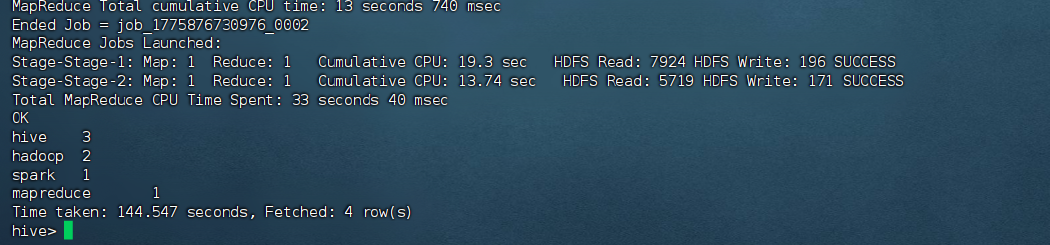
SELECT word, COUNT(*) AS count
FROM (
SELECT explode(split(line, ' ')) AS word
FROM words
) w
GROUP BY word
ORDER BY count DESC;