深度学习网络以及基于transformer架构的大模型都可以看做是一个函数,我们把输入传递给函数进行运算,函数的输出就是我们想要的结果。例如我们在使用大模型编程时,我们把需要实现的功能用自然语言描述出来,这就对应函数的输入,
然后模型返回我们所需要的代码实现,这就是函数的输出。问题在于我们需要确定模型给出的答案却是是我们所需要的,在给定的例子中,我们要确保模型给出的代码能正确运行,同时代码实现的结果跟我们所描述的功能要一致。
这使得我们面临一个问题,如何评估模型给出的结果跟预期结果的差异。显然模型给出结果跟预期结果差异越小越好,损失函数的作用就在于基于数学将模型给出结果和预期结果进行量化比较,损失函数的基本逻辑如下:
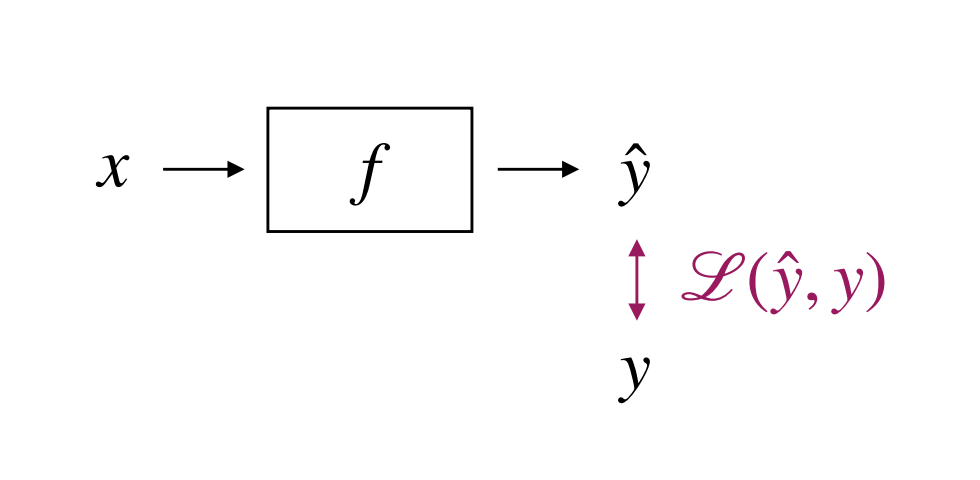
在上图中,f可以看做是对大模型的抽象表述,x就是提供给大模型的问题,y就是模型的输出,y是预期输出,右边的L(y,y)表述的正是使用损失函数来评估模型给的结果跟预期结果的差距,通常我们使用一个数值来表示,数值越小那意味着模型给出的结果越好。下面我们看看在实践中用的最多的损失函数。
在业界目前最常使用的损失函数为:
均方误差(MSE) - 回归
平均绝对误差(MAE) - 回归
交叉熵损失(Cross-Entropy) - 分类,语言模型
二元交叉熵(Binary Cross-Entropy) - 二分类
负对数似然(NLLLoss) - 分类,常与log_softmax结合
KL散度(Kullback-Leibler Divergence) - 分布匹配,知识蒸馏
铰链损失(Hinge Loss) - SVM
CTC损失(Connectionist Temporal Classification) - 序列对齐,语音识别
对比损失(Contrastive Loss, InfoNCE) - 对比学习,如CLIP
三元组损失(Triplet Loss) - 度量学习
这里我们一个个来拆解。首先我们看KL散度,它涉及到一系列概率和数理统计的知识,对于我们专注于工程实践,缺乏足够数学训练的工程师而言并不好理解。一个最直白的论断是:任何人包括大模型能够能够认知的对象必然隐藏着固定规律。问题在于这些规律往往不能使用自然语言或者数学解析式表述出来。例如人的脸或者是猫狗的脸,他们都遵循特定规律,但是我们无法用语言来描述人脸有什么固定的规律,如果要是能直白的描述出来,那么给定一张图片,我们就能使用这些规律一条条的去检验图片以便判断图片中是否包含人脸。
任何有规律的客观世界的对象,都可以使用概率分布来描述。例如统计足够多人的身高,他们的数据分布满足正太分布,我们用代码模拟如下:
py
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
np.random.seed(42)
#模拟成年男性身高分布,通常均值为175cm,差值在10cm左右
mu, sigma=170,10
sample_size=10000 #抽样数量越多,分布越遵守正太分布
heights = np.random.normal(mu, sigma, sample_size)
plt.figure(figsize=(10,6))
count,bins,patches=plt.hist(heights,bins=50,density=True,alpha=0.6,color='skyblue',edgecolor='black',label='body height')
#绘制曲线
x=np.linspace(mu-4*sigma, mu+4*sigma, 1000)
pdf=norm.pdf(x,mu,sigma)
plt.plot(x, pdf,'r-',linewidth=2,label=f'simulate normal distribution N({mu},{sigma}^2)')
plt.axvline(mu, color='green', linestyle='--', linewidth=1.5, label=f'average={mu} cm')
plt.title('average height simulation', fontsize=14)
plt.xlabel('height(cm)')
plt.ylabel('probability distrubition')
plt.legend()
plt.grid(alpha=0.3)
plt.show()上面代码运行后所得结果如下:
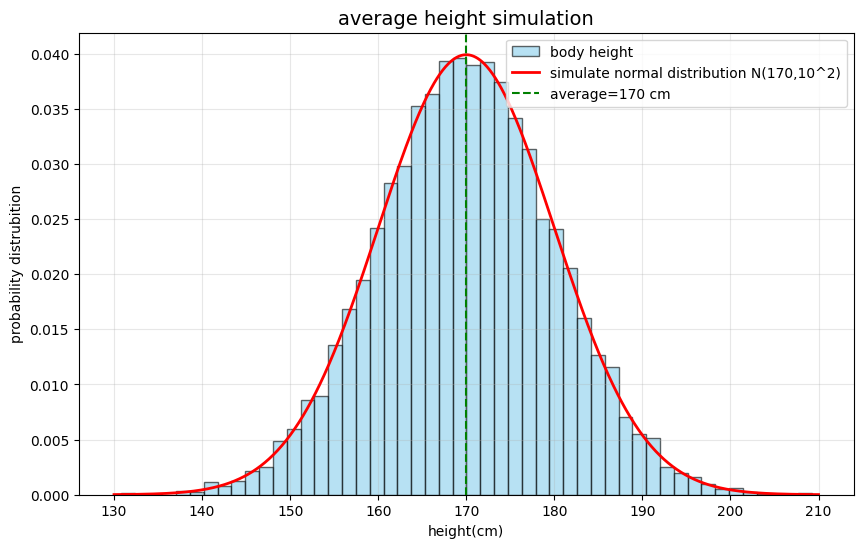
上面代码的逻辑并不重要,重要的是图形中的红色钟形曲线,它的特色是越靠近中间线的例子越多,越往两边两个极端延伸时,采样例子越少。这个规律能够适应现实世界很多情况,例如智商分数,人群的血压等。当然客观世界也有很多情况不会满足正太分布,例如个人收入,股票收益,城市人口规模等。当然很多情况下,我们并不知道实物的概率分布规律细节,例如我们就不知道人脸的规律分布,但是从数学上可以证明,我们可以使用多个正太分布的组合来模拟真实分布,然后使用KL散度来判断模拟的效果。
首先我们给出KL 散度的计算公式:
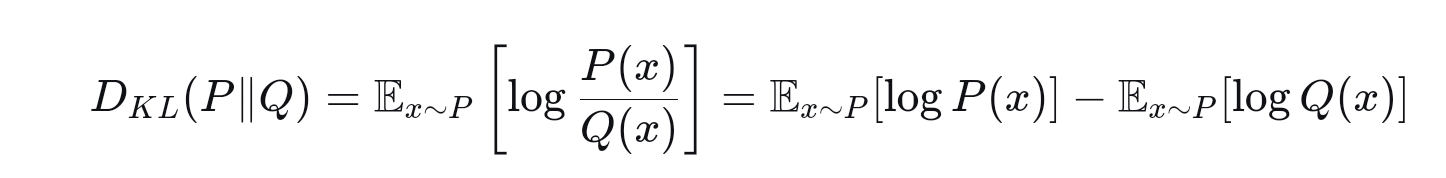
一开始看到上面公式时,我有一点想不通,那就是既然真实分布P我们不知道,那么怎么计算:
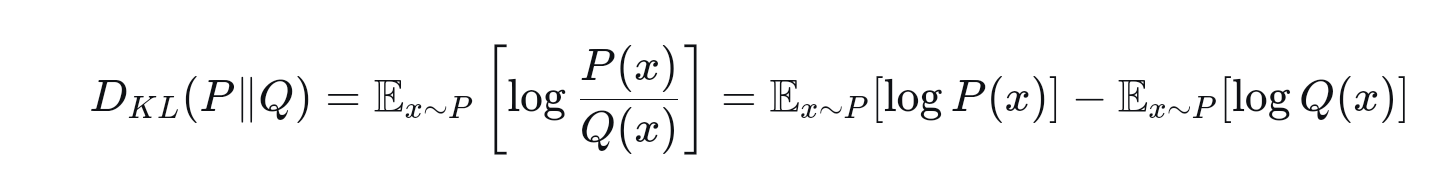
经过一段时间的搜索和琢磨后才明白,上面公式表示的是变量的"数学期望",而"数学期望"本质上是一个常数,实际上就是考虑这个变量所有可能得取值后,将取值乘以它的概率再加总。那么在上面公式中如果后面部分是常数,那么在实际运用时就不用考虑它,如果公式的取值越小就表明我们使用的函数Q对真实分布P的模拟效果就越好,那么我们只要计算第一部分,保证它取值越小就越好,而第一部分可以直接计算如下,它也叫交叉熵:
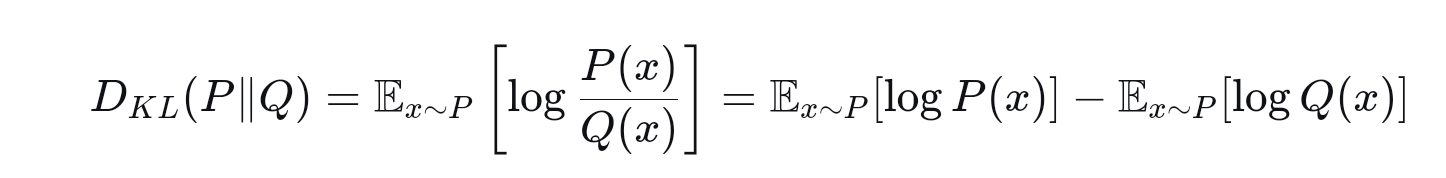
其中的X_i对应的就是训练数据,或者是真实分布P产生的采样数据。我们举个具体例子来说明KL散度的使用。我们使用指数分布来模拟真实分布P:
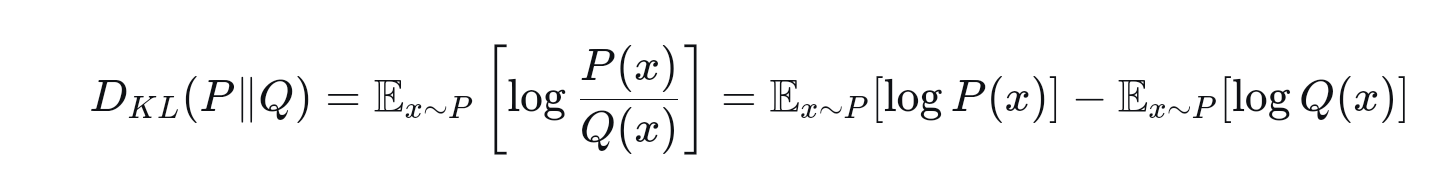
然后我们使用两个正太分布函数的组合来模拟它,然后使用三个正太分布函数来模拟它,后者的模拟效果更好,因此针对后者的KL散度值就比前者更小,我们看具体实现代码:
py
import numpy as np
import matplotlib.pyplot as plt
# ==================== 1. 真实分布:指数分布 (λ=1) ====================
def true_pdf(x):
# 向量化:x >= 0 时返回 exp(-x),否则返回 0
return np.where(x >= 0, np.exp(-x), 0.0)
# 采样函数
def sample_from_true(n_samples):
return np.random.exponential(scale=1.0, size=n_samples) # scale = 1/λ
# ==================== 2. 高斯分布函数 ====================
def gaussian_pdf(x, mu, sigma):
return (1 / (sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma) ** 2)
def mixture_pdf(x, weights, mus, sigmas):
pdf = np.zeros_like(x)
for w, mu, s in zip(weights, mus, sigmas):
pdf += w * gaussian_pdf(x, mu, s)
return pdf
# ==================== 3. 计算交叉熵(负对数似然)====================
def cross_entropy(samples, weights, mus, sigmas):
"""计算样本上的平均负对数似然: - (1/N) * sum(log Q(x_i))"""
log_lik = 0.0
for x in samples:
qx = mixture_pdf(np.array([x]), weights, mus, sigmas)[0]
log_lik += np.log(qx + 1e-12) # 避免 log(0)
return -log_lik / len(samples)
# ==================== 4. 设置随机种子,保证可重复 ====================
np.random.seed(42)
n_samples = 10000
samples = sample_from_true(n_samples)
# ==================== 5. 手动指定两个高斯混合的参数 ====================
weights2 = [0.6, 0.4]
mus2 = [0.5, 2.0]
sigmas2 = [0.8, 1.2]
# ==================== 6. 手动指定三个高斯混合的参数 ====================
weights3 = [0.5, 0.3, 0.2]
mus3 = [0.2, 1.2, 2.8]
sigmas3 = [0.4, 0.7, 1.0]
# ==================== 7. 计算交叉熵 ====================
ce2 = cross_entropy(samples, weights2, mus2, sigmas2)
ce3 = cross_entropy(samples, weights3, mus3, sigmas3)
print(f"两个高斯混合的交叉熵 = {ce2:.4f}")
print(f"三个高斯混合的交叉熵 = {ce3:.4f}")
# ==================== 8. 绘图对比 ====================
x_plot = np.linspace(0, 6, 1000)
true_vals = true_pdf(x_plot)
q2_vals = mixture_pdf(x_plot, weights2, mus2, sigmas2)
q3_vals = mixture_pdf(x_plot, weights3, mus3, sigmas3)
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(x_plot, true_vals, 'b-', linewidth=2, label='True Exponential')
plt.plot(x_plot, q2_vals, 'r--', linewidth=2, label=f'2-Gaussian (CE={ce2:.3f})')
plt.fill_between(x_plot, true_vals, alpha=0.2, color='blue')
plt.fill_between(x_plot, q2_vals, alpha=0.2, color='red')
plt.title('Fitting with 2 Gaussians')
plt.xlabel('x')
plt.ylabel('Density')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(x_plot, true_vals, 'b-', linewidth=2, label='True Exponential')
plt.plot(x_plot, q3_vals, 'g--', linewidth=2, label=f'3-Gaussian (CE={ce3:.3f})')
plt.fill_between(x_plot, true_vals, alpha=0.2, color='blue')
plt.fill_between(x_plot, q3_vals, alpha=0.2, color='green')
plt.title('Fitting with 3 Gaussians')
plt.xlabel('x')
plt.ylabel('Density')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()上面代码执行后结果如下:
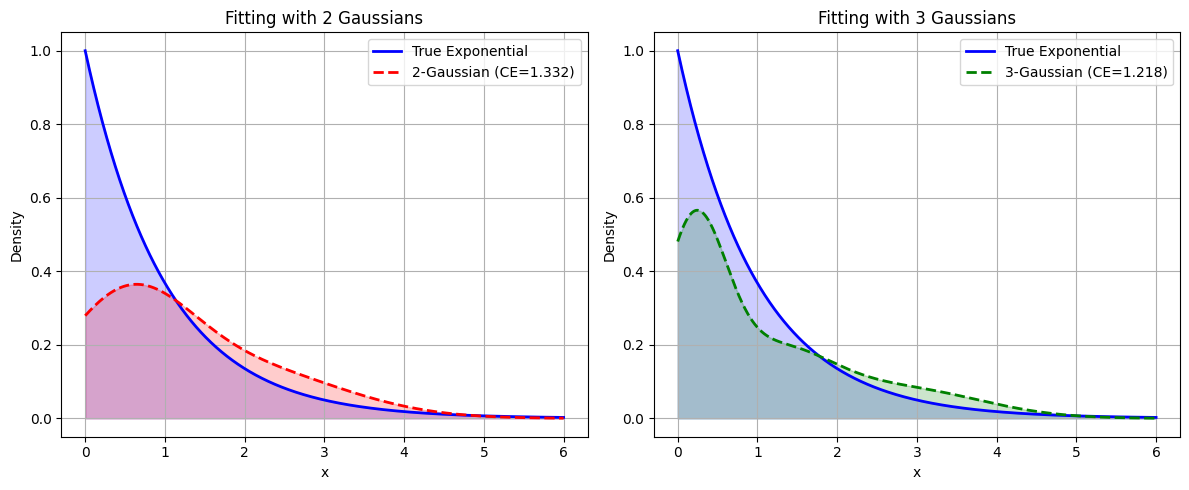
根据上面结果可以看到,三个正太分布函数组合在一起对指数分布的模拟效果好于两个正太分布函数的组合,同时三个正太函数组合计算出来的交叉熵数值小于两个正太函数组合对应的交叉熵,由此说明前者对指数函数的模拟比后者效果更好。KL散度作为损失函数常用于大模型的知识蒸馏中。