一、文件与IO的基本认知
在正式敲下 fopen 之前,我们必须先在脑海中建立起一套系统的关于文件的观念
1. 什么是文件
在大多数人的认知中,文件就是磁盘上的一个 .txt 文档、一张 .jpg 图片或一个 .c 源文件。这被称为文件的狭义理解
但在 Linux 系统的设计哲学认为 "万物皆文件" 。这就是文件的广义理解:
-
磁盘文件:常规意义上的数据存储
-
硬件设备:你的键盘(只能读)、显示器(只能写)、网卡、甚至内存,在 Linux 看来统统都是文件
-
虚拟路径:有些文件并不存在于磁盘,而是在内核内存中虚拟出来的,用于反映系统状态
为什么要这么设计?
对于操作系统来说,无论是向磁盘写数据,还是向显示器刷字符,其核心逻辑都是数据传输。将所有事物抽象为文件,就可以用一套统一的接口来管理所有复杂的硬件
2. 文件操作的本质
我们必须明确一个事实:作为程序员,我们永远无法直接操作硬件
磁盘的盘片如何旋转、磁头如何寻址、电平如何翻转,这些物理层面的细节由驱动程序负责。而内核则严格的保护着这些硬件资源
-
通过接口访问文件:当我们的 C 程序调用 printf 或 fwrite,本质上是向操作系统发起请求:请帮我把这段字符刷新到显示器(或磁盘)上
-
不是直接操作硬件 :为了系统安全和稳定性,用户态程序被禁止直接操作硬件。所有的 IO 操作,最终都必须通过操作系统提供的接口来完成
文件 I/O 的核心机制本质上是进程 与操作系统内核之间关于数据的交互过程
3. 操作系统如何看待文件
当你在程序中打开一个文件时,操作系统并不是只在磁盘上做查找。为了管理这个文件,内核会为其执行两项操作:
-
加载数据:将文件的内容从硬件载入内存缓冲区
-
创建结构 :在内核中创建一个数据结构来描述这个文件
文件 = 属性 + 内容。 每一个被打开的文件都有一个对应的结构体(通常称为 struct_file)。记录了文件的所有元数据:文件的大小、权限、最后修改时间、偏移量等
这就引出了一个关键矛盾:一个进程可以打开成百上千个文件,内核中会有成千上万个 struct_file。那么,进程是如何精准地找到需要操作的那一个呢
这就是我们即将重点介绍的核心概念------文件描述符(File Descriptor,fd)。它相当于一张索引表中的标识符,连接着进程与内核中的文件结构
二、C语言文件IO
1. C文件接口回顾
C 语言通过 FILE 结构体来抽象文件。我们熟悉的 fopen、fclose、fread、fwrite 等函数,实际上是在用户态维护了一层缓冲区(Buffer)
-
w 模式 :如果文件不存在则创建;如果存在,则先清空内容,再从头写入
-
a 模式:追加模式。每次写入都会定位到文件的末尾
-
r 模式:只读模式。如果文件不存在,则打开失败
这些接口属于 C 标准库 。这意味着无论在 Linux 还是 Windows 上运行,代码逻辑是一致的。但它们最终都要调用具体操作系统的系统调用接口(如 Linux 的 open)来实现功能
2. 当前工作目录
在文件操作中,相对路径 是常用的概念。例如执行 fopen("log.txt", "w") 时,文件会被创建在**当前工作目录(CWD)**下
什么是 CWD
每一个进程在启动时,都会记录自己当前所处的路径。这是一个进程级的属性
-
本质:它是内核 task_struct 中的一个属性,记录了进程查找相对路径时的锚点
-
在 Linux 中,你可以通过 /proc/pid/cwd 这个符号链接看到任何运行中进程的工作目录
路径转换
当你提供一个相对路径时,操作系统会自动执行:CWD + 相对路径 = 绝对路径。 这也是为什么我们在写 Shell 时,执行 cd 指令必须使用内建命令去修改父进程的 CWD,否则子进程切换了目录,父进程一动不动,相对路径的指向也就不会改变
3. 实战:实现简单cat
为了加深对 C 接口的理解,我们用它们来实现一个最基础的工具------cat。它的逻辑非常简单:打开文件 -> 读取内容 -> 输出到屏幕(标准输出) -> 关闭文件
代码实现:mycat.c
cpp
#include <stdio.h>
int main(int argc, char* argv[])
{
// 参数检查:必须提供文件名
if (argc != 2) {
printf("Usage: %s <filename>\n", argv[0]);
return 1;
}
// 只读方式打开文件
FILE* file = fopen(argv[1], "r");
if (file == NULL) {
perror("fopen");
return 1;
}
// 从文件读取内容到缓冲区
char buf[1024];
while(1) {
int s = fread(buf, 1, sizeof(buf), file);
if (s > 0) {
buf[s] = 0;
printf("%s", buf);
}
if (feof(file))
break;
}
// 关闭文件
fclose(file);
return 0;
}当执行 ./mycat test.txt 时:
-
进程启动,确定了其 CWD
-
fopen 拿着 test.txt 在 CWD 下寻找文件
-
数据从磁盘被内核读入,经过内核缓冲区,拷贝到 C 标准库的 FILE 缓冲区,最后打印在你的显示器上
C 语言的 IO 接口设计精妙之处在于通过 FILE 结构体封装了底层实现细节。但作为系统级开发者,我们需要深入理解其内部机制
值得思考的是:FILE 结构体究竟封装了哪些关键信息?此外,stdin、stdout 和 stderr 这三个标准流为何在程序启动时自动开启?
三、系统调用IO
当标准 C 库的功能无法满足需求时,我们就需要直接与内核进行交互。在这个层面,不再有 FILE* 这样的高级抽象,只剩下最原始、最直接的系统调用
1. 标准输入输出
在 C 语言中,我们习惯将 stdin、stdout 和 stderr 称为"标准流"。但在 Linux 的世界里,为了维持"万物皆文件"的统一性,它们被彻底文件化了:
-
stdin (标准输入) :通常对应键盘
-
stdout (标准输出) :通常对应显示器
-
stderr (标准错误) :同样对应显示器,但它通常用于输出警告和报错信息,以便与正常输出区分开
本质逻辑: 当你运行一个进程时,操作系统会自动为该进程打开这三个文件。虽然在 C 语言层面它们是 FILE* 指针,但在内核层面,它们分别对应着三个极小的整数索引:0、1、2。这正是我们稍后要谈到的文件描述符
2. 系统调用接口
理解 IO 架构的关键在于:C 库函数并不直接执行操作,而是扮演着高级调度者的角色
核心接口对比
在 Linux 中,每一个 C 库 IO 函数都有一个对应的系统调用接口
| 操作 | C 库函数 (User Level) | 系统调用 (Kernel Level) |
|---|---|---|
| 打开 | fopen | open |
| 写入 | fwrite / fputs / fprintf | write |
| 读取 | fread / fgets / fscanf | read |
| 关闭 | fclose | close |
为什么 C 库函数要封装系统调用?
你可能会问:既然最终都要调 write,为什么不直接写 write,非要用 fwrite?
-
跨平台性:fopen 在 Windows 和 Linux 下的代码是一样的,但底层的系统调用完全不同(Linux 用 open,Windows 用 CreateFile)。C 库帮我们屏蔽了平台的差异
-
效率提升 :系统调用的开销很大。C 库在用户层增加了一个缓冲区。当你调用 fwrite 时,数据可能先存在内存里,攒够了一大波才调用一次 write 批量送往内核。这种操作极大提升了 IO 效率
总结:层级关系
如果我们把整个 IO 流程画成一张示意图,它的层级是极其严密的:
用户应用程序
C 标准库

3. 函数详解
在 Linux 中,操作文件的核心系统调用主要有四个:open、write、read 和 close
1. open
open 不仅负责打开文件,还负责在文件不存在时创建它
-
函数原型:
cppint open(const char *pathname, int flags); int open(const char *pathname, int flags, mode_t mode); -
常用参数 flags(通过位图/位掩码传递):
-
O_RDONLY:只读打开
-
O_WRONLY:只写打开
-
O_RDWR:读写打开
-
O_CREAT:若文件不存在则创建(此时必须传第三个参数 mode)
-
O_TRUNC:打开的同时清空文件(类似 C 的 "w" 模式)
-
O_APPEND:追加写入(类似 C 的 "a" 模式)
-
-
参数 mode:创建文件时的初始权限(如 0664)
-
返回值 :成功返回一个最小的未被占用的文件描述符,失败返回 -1
2. write:向内核递交数据
-
函数原型:
cppssize_t write(int fd, const void *buf, size_t count); -
参数:fd 是目标文件的描述符,buf 是待写数据的缓冲区,count 是期望写入的字节数
-
返回值:实际写入的字节数
3. read:从内核索取数据
-
函数原型:
cppssize_t read(int fd, void *buf, size_t count); -
参数:从 fd 中读取最多 count 字节的数据到 buf 中
-
返回值:实际读到的字节数。如果返回 0,表示读到了文件末尾
4. close:释放文件资源
-
函数原型:
cppint close(int fd); -
返回值:成功返回 0,失败返回 -1
具体使用
下面的代码演示了如何使用系统调用实现:创建/打开文件、写入字符串、再重新读取内容
cpp
int main() {
// 1. 打开文件:只写 | 创建 | 清空
// 权限设为 0664 (rw-rw-r--)
int fd = open("log.txt", O_WRONLY | O_CREAT | O_TRUNC, 0664);
if (fd < 0) {
perror("open");
return 1;
}
// 2. 写入数据
const char *msg = "Hello Linux\n";
write(fd, msg, strlen(msg));
// 关闭当前写入的 fd
close(fd);
// 3. 重新以只读方式打开
fd = open("log.txt", O_RDONLY);
if (fd < 0) {
perror("open");
return 1;
}
// 4. 读取内容
char buffer[1024];
ssize_t n = read(fd, buffer, sizeof(buffer) - 1);
if (n > 0) {
buffer[n] = '\0'; // 系统调用不负责加 \0,需要手动添加
printf("Read: %s", buffer);
}
close(fd);
return 0;
}四、文件描述符
通过上一节对系统调用的介绍可以看出,fd 实际上只是一个简单的整数值,而非复杂对象。这个被称为文件描述符的整数,正是理解 Linux I/O 机制的关键所在
1. 什么是文件描述符
本质:数组下标
在 Linux 内核中,每个进程都有一个管理文件的结构体 files_struct,里面维护着一个名为 fd_array 的指针数组
-
文件描述符就是一个非负整数,本质上是这个数组的下标
-
数组的每个元素都指向一个 struct file 结构体
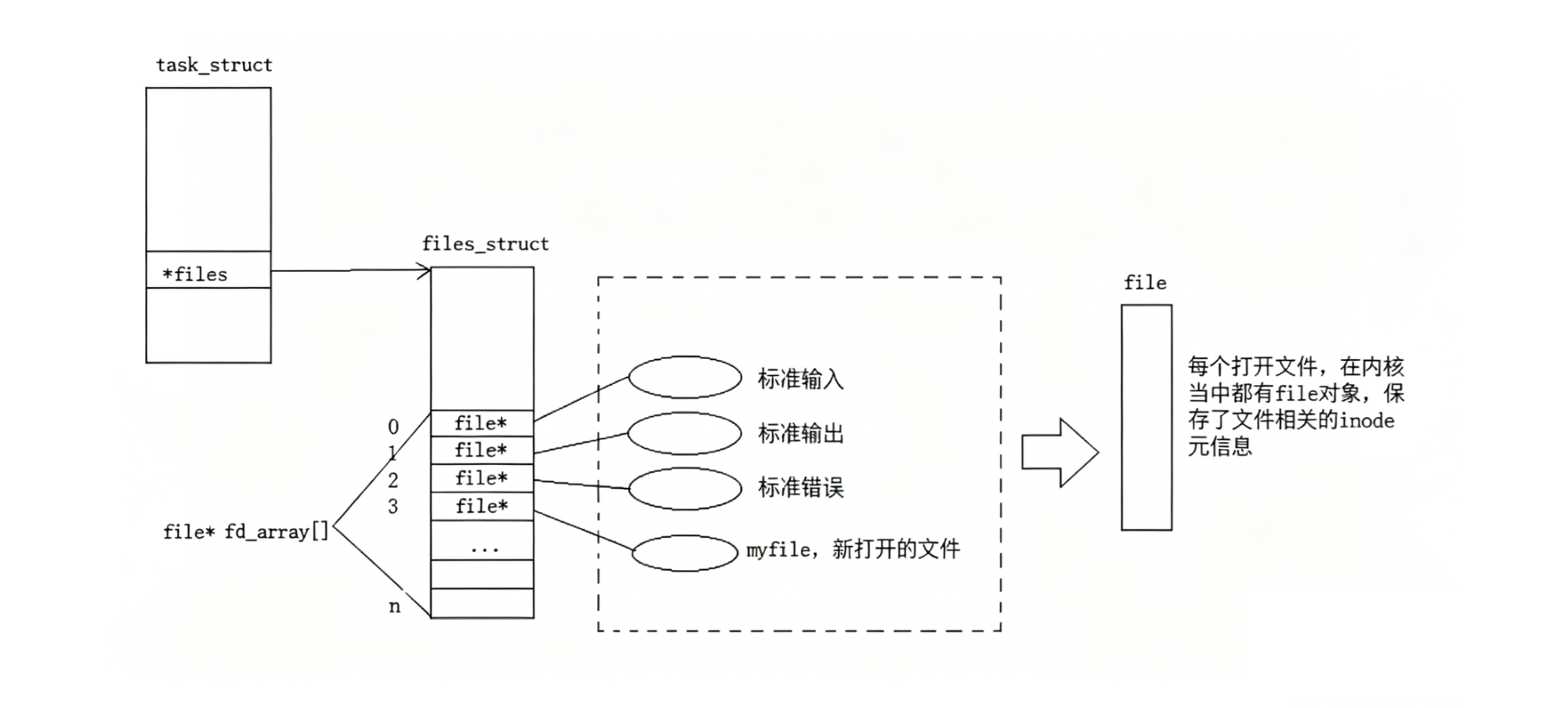
调用 read(3, ...) 时,内核的逻辑非常直接:
-
找到当前进程的 fd_array
-
取出下标为 3 的元素
-
顺着指针找到对应的 struct file 对象
-
对该文件进行操作
默认打开的描述符
为什么我们在代码里打开第一个文件,返回的通常是 3?因为 0, 1, 2 已经被操作系统预占了:
| fd | 符号常量 (C 库) | 对应设备 |
|---|---|---|
| 0 | stdin | 标准输入 |
| 1 | stdout | 标准输出 |
| 2 | stderr | 标准错误 |
2. 文件描述符分配规则
内核在给新文件分配 fd 时,遵循最小未使用原则
分配逻辑
-
从下标 0 遍历 fd_array 数组
-
找到第一个数值最小且当前未被占用的槽位
-
将新文件的 struct file 地址填进去
-
返回这个下标给用户
示例演示
为了验证这个规则,我们可以做个有趣的实验:
-
场景 A:
-
0, 1, 2 默认被占用
-
open("log.txt") -> 分配 3
-
-
场景 B:
-
我们手动调用 close(0)(关闭标准输入)
-
此时,下标 0 变为空
-
立即调用 open("data.txt") ,按照规则,新文件的 fd 将会是 0
-
cpp
int main() {
close(0); // 关掉 0
int fd = open("test.txt", O_WRONLY | O_CREAT, 0664);
printf("New fd: %d\n", fd); // 输出将会是 0
return 0;
}五、内核视角
从内核源码层面深度解析 Linux IO 机制,其核心在于揭示进程如何通过文件描述符这一关键桥梁,实现与硬件资源的高效交互
在 3.10 内核中,这三个结构体构成了从用户态引用到内核态实体的完整映射链路。我们可以将其逻辑拆解为:进程持有表、表内含指针、指针向文件
1. struct task_struct
源码位置: include/linux/sched.h
task_struct 是进程控制块。在内核眼中,一个进程就是一个 task_struct 结构体。为了让进程能和文件产生关联,它内部包含了一个关键指针 files_struct *files
当进程调用 open 或 read 时,内核首先要看的就是当前运行进程里的这个 files 指针
2. struct files_struct
源码位置: include/linux/fdtable.h
该结构体作为文件描述符的核心管理单元,负责管理当前进程打开的所有文件
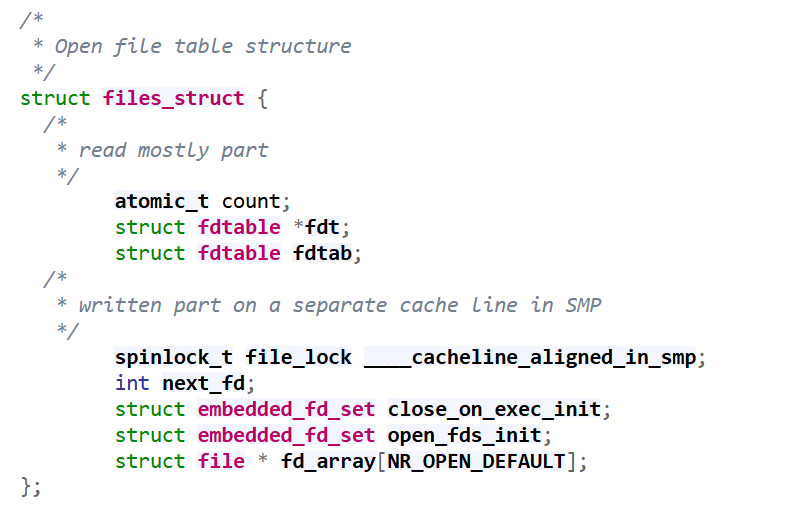
-
fd_array是一个指针数组,数组的下标就是我们常说的 文件描述符
-
每一个数组元素都指向一个 struct file 结构体
-
默认情况下,NR_OPEN_DEFAULT 通常是 32 或 64。如果进程打开的文件超过这个数,内核会动态分配更大的数组
3. struct file
源码位置: include/linux/fs.h
这是 IO 机制中最核心的对象。每当一个文件被 open 一次,内核就会创建一个 struct file
注意: 如果两个进程同时打开同一个文件,或者一个进程打开同一个文件两次,内核会创建两个 struct file

三者关系
当我们调用 read(fd, buf, size) 时,内核底层的追踪路径如下:
-
获取当前进程的 task_struct 指针
-
顺着 task_struct->files 找到 files_struct
-
以 fd 为下标,在 files_struct->fd_arrayfd 中找到对应的 struct file *
-
通过 struct file->f_op->read 调用该文件特有的读取函数
-
根据 struct file->f_pos 确定从文件的哪个位置开始读取
以下是内核结构的关系图
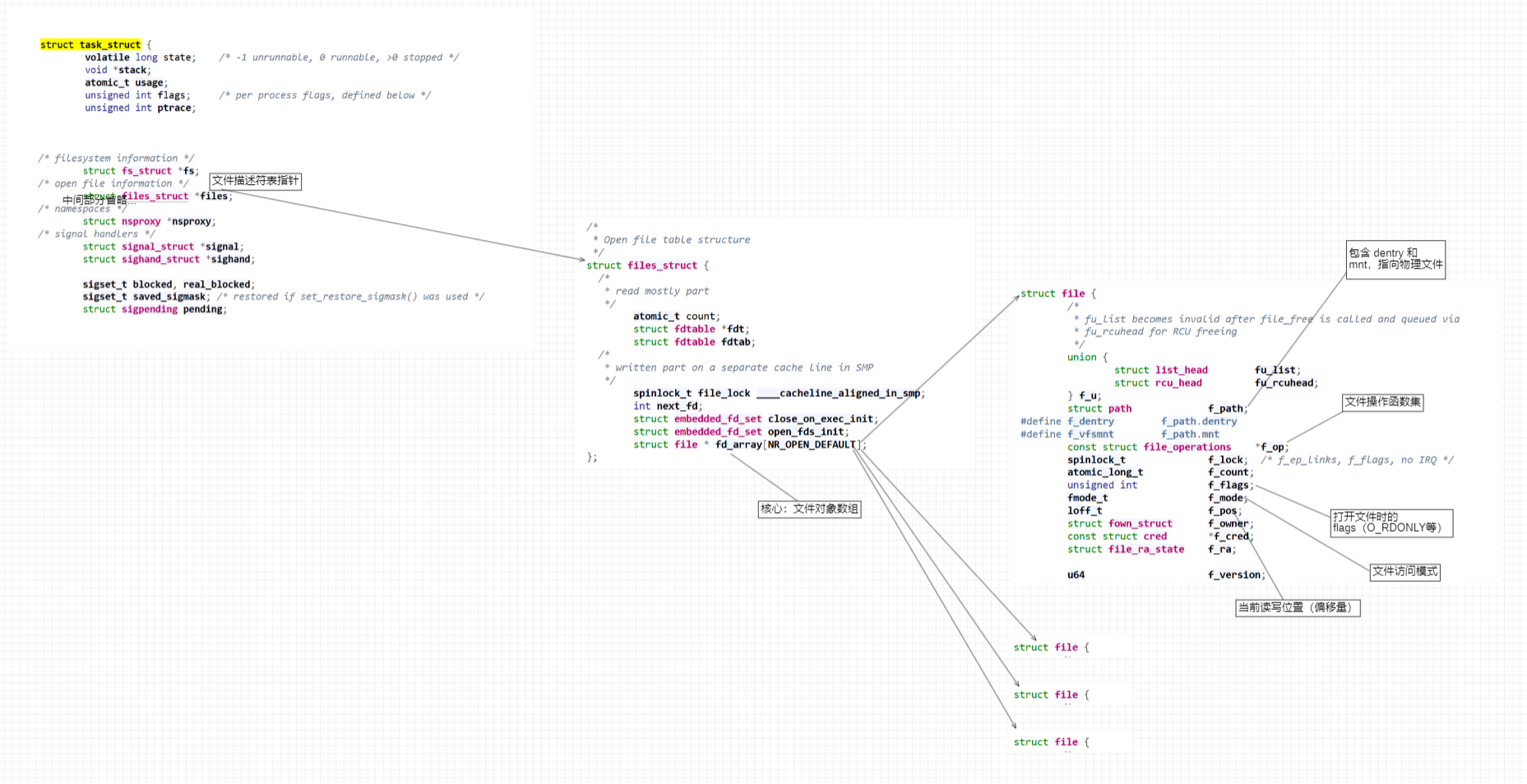
总结
综上所述,从 C 语言的文件接口到系统调用,再到文件描述符与内核中的数据结构,我们逐步揭示了文件操作背后的完整路径。表面上看,程序只是通过 fopen、fread 等接口进行读写,但在更底层,这些操作最终都会转化为系统调用,并通过文件描述符定位到内核中的具体文件对象
在下一篇中,我们将进一步基于文件描述符展开,探讨重定向机制以及如何在 Shell 中实现输入输出的控制,使文件IO从理解原理走向实际应用
