作者:来自 Elastic jina.ai

Jina MCP 通过将我们的 API 连接到任意 LLM,简化了 agent 开发,减少了自定义代码,并提升了工作流的可靠性。
我们在之前的一篇文章中向你展示了如何将 Jina AI 的 search 和 reader APIs 与 DeepSeek R1 集成来构建一个深度研究 agent,但要让它正常工作,需要大量的自定义代码和 prompt 工程。在这篇文章中,我们将使用 Model Context Protocol( MCP )来实现相同的功能,它需要更少的自定义代码,并且可以在不同的 LLM 之间移植,但在过程中仍然存在一些需要注意的问题。
为了构建我们的 agent,我们将使用最近发布的 MCP 服务器,它提供了对 Jina Reader、Embeddings 和 Reranker API 的访问,以及 URL 转 markdown、网页搜索、图像搜索和 embeddings/reranker 工具。
Agents 与 Model Context Protocol
最近,关于智能体和智能体人工智能的文章层出不穷,既有对其的高度期待(例如 Gartner 预测,到 2028 年,大约 15% 的日常工作决策将由 AI agent 自主完成),也有质疑(例如 Vortex 认为大多数 agentic AI 的提案缺乏显著价值或投资回报)。
但 agent 到底是什么?一个较好的定义(来自 Chip Huyen,经由 Simon Willison 引用)是:
agent 是 能够规划方法并循环调用工具直到实现目标的 LLM 系统
这也是本文采用的定义。那么 agent 使用的这些工具呢?它们通过 Model Context Protocol 进行连接。该协议最初由 Anthropic 开发,正在成为连接 LLM 与外部工具和数据源的通用语言。这意味着 agent 可以在单个工作流中串联多个工具,从而通过编排一组 API 来实现规划、推理和执行。
 www.anthropic.com/news/model-...
www.anthropic.com/news/model-...
例如,我们可以构建一个价格优化 agent,用于收集竞争对手的产品定价以进行比较和价格优化。然后我们可以为该 agent 配置 Jina AI 的 MCP 服务器、一个 prompt 以及一份竞争对手产品列表,让它生成一份包含抓取数据和来源链接的可执行报告。通过使用额外的 MCP 服务器,agent 还可以将该报告导出为 PDF 格式,通过电子邮件发送给相关人员,将其存储到内部知识库等。
在这篇文章中,我们将使用我们的 MCP 服务器构建三个示例 agent,该服务器提供以下工具:
- primer ------ 获取当前上下文信息,用于本地化和时间感知响应
- read_url ------ 通过 Reader API 从网页中提取干净、结构化的 Markdown 内容(也提供并行版本)
- capture_screenshot_url ------ 通过 Reader API 捕获高质量网页截图
- guess_datetime_url ------ 分析网页的最后更新时间/发布时间,并提供置信度评分
- search_web ------ 通过 Reader API 在全网搜索当前信息和新闻(也提供并行版本)
- search_arxiv ------ 通过 Reader API 搜索 arXiv 仓库中的学术论文和预印本(也提供并行版本)
- search_images ------ 通过 Reader API 在全网搜索图片(类似 Google Images )
- expand_query ------ 基于查询扩展模型通过 Reader API 扩展和重写搜索查询
- sort_by_relevance ------ 通过 Reranker API 按与查询的相关性对文档重新排序
- deduplicate_strings ------ 通过 Embeddings API 和子模优化(submodular optimization)获取语义上唯一的 top-k 字符串
- deduplicate_images ------ 通过 Embeddings API 和子模优化获取语义上唯一的 top-k 图像
我们还需要一个 MCP 客户端( VS Code 搭配 Copilot,因为它免费且使用广泛),以及一个 LLM( Claude Sonnet 4,因为它在我们的测试中表现最好)。
💡
接下来,为了简洁起见,我们将把 MCP 客户端 + LLM + MCP 服务器(们)的组合称为"我们的 agent"。
使用 Jina AI MCP 服务器
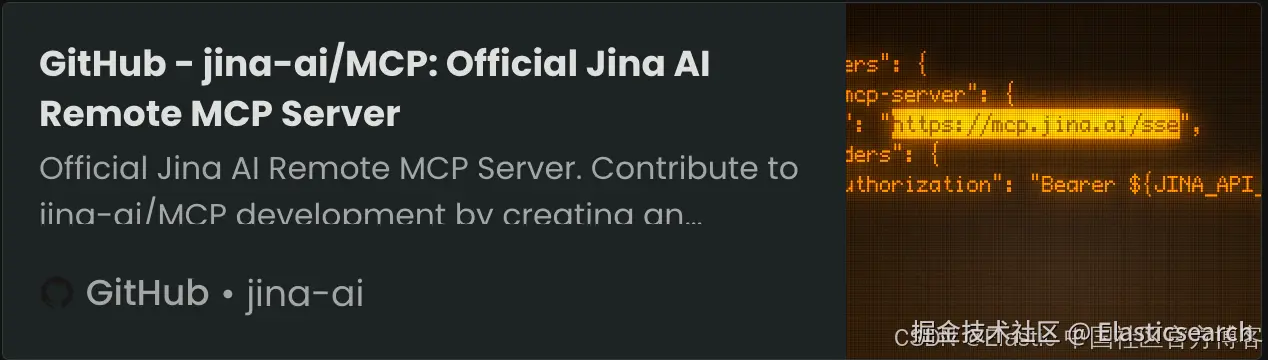
MCP 被描述为一种通用插件系统,支持多个程序,例如 Claude Code、VS Code、Google Gemini CLI,以及 Claude 和 ChatGPT 的桌面前端。连接 MCP 服务器通常只需要编辑你的设置文件并包含以下内容:
bash
`
1. {
2. "mcpServers": {
3. "jina-mcp-server": {
4. "url": "https://mcp.jina.ai/sse",
5. "headers": {
6. "Authorization": "Bearer ${JINA_API_KEY}" // optional
7. }
8. }
9. }
10. }
`AI写代码为了测试 MCP 服务器是否正常工作,我们使用一个简单的 prompt:
css
`
1. Give me a summary of the latest post on jina.ai news in the
2. form of a single verse sea shanty
`AI写代码我们的 agent 执行以下操作:
- 调用 read_url 抓取 jina.ai/news
- 使用查询 " site:jina.ai "Optimizing GGUFs for Decoder-Only Embedding Models" August 2025 " 调用 search_web
- 调用 read_url 抓取该博客文章
- 根据抓取的数据生成一段单节的海员号子(one-verse sea shanty):
markdown
`
1. 🎵 *To the tune of a traditional sea shanty* 🎵
3. **"The GGUF Sailor's Tale"**
5. *Oh, they sailed with their embeddings, three billion strong and true,*
6. *Through quantized waters deep and blue,*
7. *With L4 GPU winds at their back,*
8. *Four thousand tokens per second on their track!*
9. *Heave away, me hearties, strip the vision tower down,*
10. *For GGUF optimizations are the finest ports in town!*
`AI写代码💡
我们的 agent 通常会生成非常长的输出。为了避免在文章中全部展示,我们会将其余内容链接到 GitHub gist。
既然我们已经看到它在实践中可以正常工作,接下来让我们通过构建一些有用的真实世界示例来真正测试它的能力。
示例 1:每日 arXiv 论文摘要
阅读最新的学术论文是我们在 Jina AI 工作的一部分。但从中筛选出真正相关的论文,并提取每篇论文中最重要的信息,是一项相当繁琐的任务。因此,在我们的第一个实验中,我们将这项工作自动化,创建了一个每日精选的最新相关论文摘要。以下是我们使用的 prompt:
sql
`
1. Using only Jina tools, scrape arxiv for the papers about
2. LLMs, reranking, and embeddings published in the past 24
3. hours, then deduplicate and rerank for relevance, outputting
4. the top 10. For each one, scrape the PDF and extract the
5. abstract. Then summarize it and organize the information you
6. gathered into a "daily update". Include a link and publication
7. date for each paper.
`AI写代码💡
我们指定 "仅使用 Jina 工具",因为 VS Code 本身内置了搜索和抓取功能。在没有这些功能的模型中,这一表述可以省略。
我们的 agent:
- 使用查询字符串 large language models LLM、reranking information retrieval、embeddings vector representations、transformer neural networks 和 natural language processing NLP,通过 parallel_search_arxiv 工具搜索相关的 arxiv.org 论文
- 使用 deduplicate_strings 工具去重
- 使用 sort_by_relevance 工具对结果进行重排序,仅输出最相关的前 10 个结果
- 通过 parallel_read_url 获取这些重排序结果对应的 PDF 链接,并分成两批,每批 5 个
- 使用 read_url 工具逐个读取每个链接(共调用 10 次)
- 生成一份详细报告,包括摘要、总结、趋势与洞察、对未来研究的影响、研究空白以及结论
 gist.github.com/alexcg1/9be...
gist.github.com/alexcg1/9be...
我们偶尔会遇到这样的问题:agent 没有将结果限制在过去 24 小时内。再次提示它遵循该指令后,才得到了上面的报告。
示例 2:市场研究 agent
在下一个实验中,我们将让 agent 为一家知名电子游戏公司(名称已隐去)撰写一份竞争情报报告。以下是我们的 prompt:
css
`
1. Create a comprehensive competitive intelligence report for
2. $GAME_COMPANY focusing on their recent activities in retro
3. indie games. Use Jina tools to search for the latest news,
4. press releases, and announcements, then extract clean content
5. from their official communications. Rank all findings by
6. business relevance and remove any duplicate information.
7. Present insights on their strategic direction, product
8. launches, and market positioning changes over the past
9. quarter
`AI写代码我们的 agent:
- 多次循环执行 search_web 和 read_url 以收集研究资料
- 使用 sort_by_relevance 对结果进行重排序,输出前 10 个最相关结果
- 生成一份市场情报报告,包括执行摘要、关键商业动态(按战略重要性排序)、战略决策分析以及其他多个部分

示例 3:法律合规研究
正如我们之前提到的,MCP 的一个有用之处在于我们可以使用多个服务器来获得更复杂的输出。在这个案例中,我们除了使用我们自己的 MCP 服务器之外,还使用了 PDF Reader MCP 服务器,以生成一份关于欧盟和美国当前 AI 法律合规状况的研究报告。我们使用的 prompt 是:
markdown
`
1. Develop a knowledge base section focused on AI legal
2. compliance news and common pitfalls in the EU and USA as of
3. this moment. Report should be aimed at AI startups in EU.
4. Apply Jina MCP tools extensively: perform parallel web
5. searches and URL reads to efficiently extract detailed
6. content, deduplicate semantic overlaps, and rerank to surface
7. the most authoritative information. Cite all sources with
8. URLs and publication or update dates. Organize content
9. clearly and produce a formatted PDF document ready for
10. immediate use.
`AI写代码我们的 agent:
- 对通用信息执行并行搜索操作(使用 parallel_search),查询包括 EU AI Act 2024 compliance requirements startups legal obligations August 2025、USA AI regulation Biden executive order compliance requirements 2024 2025、AI startup legal pitfalls Europe GDPR data protection compliance 2025、AI liability insurance compliance requirements EU USA startups 2024 2025 以及 AI ethics governance framework startups EU USA regulatory updates 2025,每个查询返回 25 个结果。
- 使用 deduplicate_strings 对返回的 URL 进行去重
- 使用 parallel_read_url 读取其中 4 个 URL 的内容
- 再次执行更具体信息的并行搜索,查询包括 AI startup common compliance pitfalls mistakes EU USA 2025、AI liability insurance cybersecurity startup requirements 2025、AI bias discrimination testing requirements EU AI Act compliance startups、AI data protection GDPR violations penalties startups 2025
- 使用 parallel_read_url 再读取 4 个 URL
- 生成 Markdown 格式报告,并将其转换为 18 页 PDF
 gist.github.com/alexcg1/0dd...
gist.github.com/alexcg1/0dd...
我们还需要进行一些额外的 prompt 调整,以改进 PDF 的元数据和格式,并使其更像一份正式报告而不是一份非常长的项目符号列表,但这些内容可以在未来的报告中整合进 prompt。
替代方案
在选择 Claude Sonnet 4 之前,我们尝试了多种支持 tools 的 Ollama 模型,包括 Qwen3:30b、Qwen2.5:7b 和 llama3.3:70b。对于 MCP 客户端,我们最初使用 ollmcp,之后才切换到 VS Code。上述所有模型都以相同方式失败,无论我们如何明确提示工具及其使用方式:当被要求执行一个简单任务(例如获取 Jina AI 的最新博客文章)时,每个模型(无论规模或厂商)都会持续表现出以下行为:
- 进入冗长的推理循环,不断自我怀疑(并消耗 token),直到最终决定直接按指令执行
- 调用 read_url 访问 jina.ai/news
- 检查博客文章标题和摘要
- 完全"幻觉"式地认为自己抓取了最新文章(甚至没有真正对该页面调用 read_url)
- 基于搜索结果的摘要(而非实际页面内容)生成总结
- 在被质疑时,声称自己已严格遵循指令并抓取了页面
Claude、GPT 和 Gemini 系列模型整体表现尚可,但我们很快选择了 Claude Sonnet 4,因为它更积极地使用工具(经常使用并行工具,而不是 GPT-4.1 偏好的串行方式),并生成更长、更结构化的输出。
结论
关于 "agentic AI" 这一概念目前仍存在很多模糊性,但 MCP 正在将其转变为一个更具体、更实用的方向。在我们的经验中,agent 还没有完全达到生产可用的成熟阶段,LLM 仍然是主要短板,但通过一定的引导和实验,已经可以获得不错的结果。也就是说,当 prompt、LLM 和 MCP 服务器三者组合正确时,agent 能够可靠地执行多步骤任务且无需自定义代码------这在之前的模型(如不支持 tools 的 DeepSeek)中是很难实现的,因为那时需要更多手工工程且集成更脆弱。
尽管当前仍存在局限性,但整体发展趋势是积极的。MCP 生态正在快速增长,带来了越来越多的集成和工具,使得 API(如 Jina 的)可以更容易地组合使用,也可以随着新 LLM 的出现灵活替换。随着底层模型能力的提升以及工具生态的成熟,实验性 agent 与生产级 agentic AI 之间的差距正在持续缩小,使得在真实世界应用中构建可靠系统变得越来越可行。