作者:来自 Elastic Alexander Marquardt, Honza Král 及 Taylor Roy

学习如何使用 Elasticsearch percolator 来实现搜索治理。在这篇博客中,我们概述了在生产环境中构建受控策略引擎所需的模式,并创建一个可控的检索策略。
更多阅读:
- Elasticsearch:理解 Elasticsearch 中的 Percolator 数据类型及 Percolate 查询
- Elasticsearch:Elasticsearch percolate 查询
刚接触 Elasticsearch?可以参加我们的 Elasticsearch 入门网络研讨会。你也可以开始免费的云试用,或者现在就在本地机器上尝试 Elastic。
这篇文章是对第 3 部分中描述的控制平面架构的技术深入解析,展示如何使用 Elasticsearch percolator 来构建它。文章概述了在生产环境中实现一个确定性的、受治理的策略引擎所需的模式。
从架构到实现
第 3 部分描述了控制平面架构:将反向匹配作为一种查询机制,将匹配与动作分离的策略文档,以及将多个策略组合为单一执行计划的级联转换。这篇文章将深入使用 Elasticsearch 的 percolator 查询来实现这一策略查找功能。
percolator 非常适合用于治理场景,因为它以与控制平面需求完全一致的方式反转了搜索方向。本文将逐步讲解其实现,从 percolator 的作用及其重要性开始,然后深入到索引设计、策略存储、查询时评估以及多策略组合。
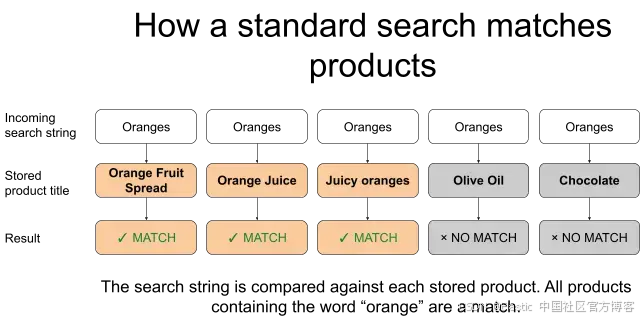
普通搜索是如何工作的
在电商系统中,你可能有几十万甚至上百万个产品文档,这些文档包含 title、category 和 price 等字段。当用户发起搜索时,本质上是在让 Elasticsearch 将用户的搜索字符串与这些产品文档中的一个或多个存储字段进行匹配。
Elasticsearch 的默认分析器(standard analyzer)会将文本转为小写并拆分为 token。例如,搜索 "oranges" 会匹配 "Oranges",因为进行了小写归一化。如果使用包含词干提取的语言分析器,它还可以匹配 "orange",因为两者会被归一化为相同的词干。
例如,下面这个 match 查询会返回 title 字段中包含 "orange" 或 "oranges" 的文档。
POST products/_search
{
"query": {
"match": {
"title": "oranges"
}
}
}因此,对于上述查询,Elasticsearch 会返回 title 字段中匹配 "oranges" 的产品文档,例如 "Orange Fruit Spread"、"Orange Juice"、"Juicy oranges"、"Orange Marmalade" 等等。需要记住的关键点是:Elasticsearch 通常用于将搜索字符串与文档进行比较,并返回与该搜索字符串匹配的文档。
治理问题:在搜索产品之前找到相关策略
正如第 1 到第 3 部分所建立的那样,一个受治理的搜索系统不会直接将用户的搜索字符串发送到产品目录。相反,它首先会检查是否有任何策略适用于该搜索字符串。
一位商品运营人员决定,当有人精确搜索 "oranges" 时,结果应限制在 Oranges 类别,从而排除橙汁、橙子果酱和橙味汽水等内容。这个业务决策被存储为一条策略。当用户输入 "oranges" 时,控制平面需要找到该策略,读取其指令,并相应地调整对产品目录的搜索。为了做到这一点,控制平面需要判断哪些已存储的策略与该搜索字符串相关。
在企业级部署中,可能存在数百甚至数千条这样的策略。通过 if/else 逻辑逐一检查,是第 2 部分中描述的应用层反模式。我们需要一种方式,将所有策略存储在一个索引中,并能够即时找到与给定搜索字符串匹配的策略。这正是 percolator 发挥作用的地方。
反转方向:Percolator
我们之前提到,在普通搜索中,Elasticsearch 通常用于将搜索字符串与文档进行比较,并返回包含该搜索字符串的文档。
Percolator 则反转了这一过程。在 percolator 中,你有一个索引,其中每个文档存储的是一个查询模式,然后将传入的搜索字符串与这些已存储的查询进行匹配,以确定哪些查询模式被触发。
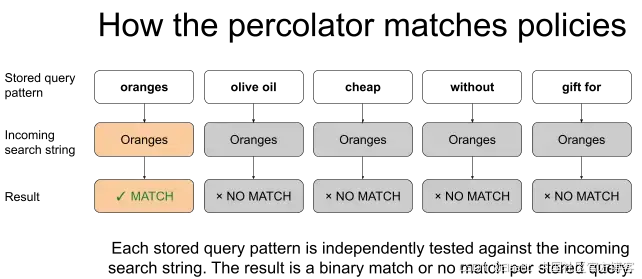
对于治理而言,"已存储的查询模式"就是策略。每条策略都包含一个模式,用来描述它应该匹配哪类搜索字符串。例如,搜索字符串是否精确匹配 "oranges",或者是否包含 "olive oil"。传入的字符串是用户的搜索文本,在查询时到达,需要与所有已存储的策略模式进行匹配。这一点在相关 PRISM 视频的 4:09 处有说明。
逐步说明:一次 "oranges" 搜索如何找到对应策略
策略
一位商品运营人员创建了一条策略:当用户搜索内容完全等于 "oranges" 且没有其他词时进行匹配。一旦 percolator 命中,该文档的其余部分会包含控制平面用于构建产品查询的规则;在这个例子中,其中一条规则是将结果限制(过滤)在 Fruits 类别中。
{
"percolator": {
"match_phrase": { "query": "START oranges END" }
},
"rule_type": "filter",
"rule_args": {
"filters": [
{
"field": "categories",
"values": ["Fruits"],
"mode": "hard_filter",
"on_conflict": "soft_boost",
"on_conflict_boost_weight": 1.0
}
]
},
"priority": 0,
"enabled": true
}percolator 字段包含定义该策略何时触发的匹配模式。在这个例子中,它匹配短语 "START oranges END"。rule_type 和 rule_args 字段定义了当策略被触发时应该执行的操作。START 和 END 标记是边界标记,我们稍后会进行解释。
你可以在相关 PRISM 视频 2:52 处的 PRISM Studio UI 中看到策略是如何编写的。
用户发起搜索
一位购物者在搜索框中输入 "oranges"。
控制平面检查匹配策略
在搜索产品目录之前,控制平面会拦截用户的搜索字符串,为其添加边界标记,并将其发送给 percolator:
POST policies/_search
{
"query": {
"percolate": {
"field": "percolator",
"document": {
"query": "START oranges END"
}
}
}
}字符串 "START oranges END" 会与所有已存储的策略模式进行匹配。在内部,Elasticsearch 会运行这些已存储的策略模式来检查该字符串,并返回所有匹配的策略。这就是 percolator 的工作方式。用户的搜索字符串会与所有已存储的策略模式进行比对,并返回所有匹配项。没有 if/else 链式判断,也没有顺序遍历执行;索引负责完成匹配。
控制平面应用策略
控制平面读取已匹配策略的动作。上述策略指示控制平面将结果限制在 Fruits 类别。随后,控制平面基于产品目录构建最终的 Elasticsearch 查询如下:
POST products/_search
{
"query": {
"bool": {
"must": [
{ "match": { "title": "oranges" } }
],
"filter": [
{ "terms": { "categories": ["Fruits"] } }
]
}
}
}用户搜索了 "oranges"。产品目录接收到一个被限制在 Fruits 类别中的 "oranges" 查询。由于这个约束,orange juice、orange marmalade 和 orange soda 都被排除。
为什么 "orange marmalade" 不会触发 "oranges" 策略
假设另一个用户搜索 "orange marmalade"。控制平面会对该字符串进行封装并执行 percolation:"START orange marmalade END"。而 "oranges" 策略的模式是 match_phrase:"START oranges END"。该策略不会匹配,因此不会被应用,结果也不会被限制在 Fruits 类别。
这正是 START 和 END 边界标记的作用。如果没有这些标记,一个匹配 "oranges" 的策略可能会错误触发在 "orange marmalade" 这样的查询上。通过将用户搜索字符串包裹在 START 和 END 中,并在策略模式中包含这些标记,我们确保该策略只在 "oranges" 是完整搜索字符串(没有其他词)时才触发。这同时符合购物者和商品运营人员的意图。
第二个策略:"olive oil" 在词干化字段上的匹配
并不是所有策略都需要精确字符串匹配。"olive oil" 策略是在词干化字段上匹配,因此即使存在轻微的词形变化,它也会触发:
{
"percolator": {
"bool": {
"should": [
{ "match_phrase": { "query.stemmed": "START olive oil END" } }
]
}
},
"rule_type": "filter",
"rule_args": {
"filters": [
{
"field": "categories",
"values": ["Olive oils"],
"mode": "hard_filter",
"on_conflict": "soft_boost",
"on_conflict_boost_weight": 1.0
}
]
},
"priority": 300,
"enabled": true
}该策略的模式不是在 query 字段上匹配,而是在 query.stemmed 字段上匹配。当用户的搜索字符串到达时,它会同时存储在两个字段中:query 字段(原始文本)以及 query.stemmed 字段(使用词干分析器处理后的文本,该分析器会将词语还原为词干,例如 "olives" 和 "olive" 都会被还原为同一个词干,"oils" 和 "oil" 也是如此)。该策略的模式会在词干化后的字符串上进行匹配,因此即使存在轻微的词形变化也会触发。
START 和 END 边界标记同样作用于 stemmed 字段,从而确保该策略只在 "olive oil" 是完整搜索字符串时触发,而不会在它出现在更长查询的一部分时触发。
本文其余部分将介绍使其具备生产可用性的实现细节:支持两种匹配模式的索引 mapping、如何通过高亮驱动短语移除与已消费短语追踪,以及多个冲突策略如何组合成单一执行计划。
策略索引 mapping
策略索引需要一个 percolator 字段来存储已定义的查询模式,以及一个文本字段,用于镜像 percolator 将要匹配的输入搜索字符串结构。下面的 mapping 是简化版本以便理解。在生产环境中会更加复杂,例如使用自定义分析器来处理边界标记、可变模式匹配(例如识别 "under $4" 中的货币值)以及其他类型的文本分析。
PUT policies
{
"mappings": {
"properties": {
"percolator": {
"type": "percolator"
},
"query": {
"type": "text",
"fields": {
"stemmed": {
"type": "text",
"analyzer": "stemming"
}
}
},
"rule_type": { "type": "keyword" },
"rule_args": { "type": "object", "enabled": false },
"priority": { "type": "integer" },
"enabled": { "type": "boolean" }
}
}
}该索引被命名为 policies,因为每个文档都代表一个完整的受治理策略,正如第 2 部分所定义的那样。这包括匹配条件、动作、优先级以及元数据。rule_type 和 rule_args 字段包含策略的动作部分,即控制平面在构建针对产品目录执行查询时所使用的指令。
query 字段是 percolator 用来匹配的字符串,它有两个版本:精确版本和词干化版本。当用户的搜索字符串到达时,它会被放入这个字段对应的临时内存索引中。在 query 上匹配的策略会看到原始精确字符串;在 query.stemmed 上匹配的策略则会看到词干化后的版本。
带高亮、过滤和排序的 percolation
上述简单示例展示的是最小化的 percolation 请求。在实际应用中,控制平面会加入高亮功能、过滤掉已禁用的策略,并按照优先级进行排序:
POST policies/_search
{
"query": {
"bool": {
"must": [
{
"percolate": {
"field": "percolator",
"document": {
"query": "START olive oil END"
}
}
},
{
"term": { "enabled": true }
}
]
}
},
"highlight": {
"fields": {
"query": {
"matched_fields": ["query.stemmed"]
}
}
},
"sort": [
{ "priority": { "order": "desc" } }
]
}高亮配置使用 "query" 作为字段键,并在 matched_fields 中使用 "query.stemmed"。这告诉 Elasticsearch 的统一高亮器(unified highlighter)在返回高亮结果时基于父字段 query,但同时在判断哪些 token 需要高亮时,也考虑来自 query.stemmed 子字段的匹配结果。这使得即使某个策略是在 stemmed 字段上匹配,也能在原始文本上生成准确的高亮范围,而控制平面正需要这些信息来进行短语移除和已消费短语追踪。
enabled: true 过滤条件确保已禁用的策略会被跳过。按 priority 排序则保证高优先级策略优先返回,使控制平面能够按正确顺序执行级联转换。highlight 字段是最关键的补充;它可以精确指出用户搜索字符串中哪些词触发了每个匹配。
对于 "olive oil" 搜索,其响应可能如下所示:
{
"hits": {
"hits": [
{
"_id": "en_2c3021c8",
"_source": {
"rule_type": "filter",
"rule_args": {
"filters": [
{
"field": "categories",
"values": ["Olive oils"],
"mode": "hard_filter",
"on_conflict": "soft_boost",
"on_conflict_boost_weight": 1.0
}
]
},
"priority": 300
},
"highlight": {
"query": ["<em>START olive oil END</em>"]
}
}
]
}
}为什么高亮很重要
注意响应中的高亮:"START olive oil END"。Elasticsearch 在告诉我们,正是用户搜索字符串中的哪些词触发了该策略的匹配。这不仅仅是展示效果,高亮元数据驱动了两个关键的下游行为:
短语移除。某些策略需要在构建产品目录查询之前,将匹配到的文本从搜索字符串中移除。例如,一个匹配 "cheap" 的策略会移除该词,并将其转换为价格过滤条件。高亮可以精确标识该策略匹配的是搜索字符串中的哪一段,因此系统知道应该移除哪一部分。
已消费短语追踪 。正如第 3 部分所描述,当多个策略匹配同一个搜索字符串时,高优先级策略可能会移除低优先级策略也匹配到的词。通过将每个策略的高亮结果与当前(不断变化的)搜索字符串进行对比,系统可以识别某个短语已被"消费",并跳过低优先级策略。这避免了重复处理,并确保行为的确定性。
你可以在这篇文章中了解更多关于高亮机制的内容。
从 percolation 到执行计划
percolator 返回的是一组匹配的策略。但正如第 3 部分所描述的,查找只是故事的一半,另一半是将这些匹配组合成一个一致的执行计划。下面是一个具体查询的示例。
完整示例:"Cheap chocolate" 在圣诞活动期间
假设系统中有两条激活策略:"Cheap chocolate" 策略(优先级 210)和 "Christmas chocolates" 策略(优先级 300),两者在第 3 部分中都有详细描述。
1)步骤 1:Percolate 。用户搜索 "cheap chocolate"。控制平面将其封装为 "START cheap chocolate END",并发送给 percolator。两个策略匹配:
"Cheap chocolate" 策略通过短语 "cheap chocolate" 匹配;
"Christmas chocolates" 策略通过 stemmed 字段匹配 "chocolate"。
2)步骤 2:按优先级排序。percolator 返回两个策略,并按优先级降序排序。首先处理 "Christmas chocolates"(300),然后是 "Cheap chocolate"(210)。
2)步骤 3:应用级联转换 。这对应第 3 部分中的初始状态 → Policy A → state' → Policy B → state'' → 执行计划模型。
优先级 300 的 "Christmas chocolates" 策略首先应用:
- 添加类别硬过滤:Christmas foods and drinks、Christmas sweets
- 添加价格过滤:低于 $7
- 添加类别软提升:Advent calendars(3x)
接着优先级 210 的 "Cheap chocolate" 策略在修改后的状态上应用:
- 尝试添加类别硬过滤:Chocolates、Milk chocolates;但由于 Christmas 策略已设置该字段且 on_conflict: override,因此被覆盖并丢弃
- 尝试添加价格过滤:2,但 Christmas 策略设置 on_conflict: restrict,且 2 比 7 更严格,因此 2 生效
- 移除搜索词 "cheap"
3)步骤 4:构建 Elasticsearch 查询。控制平面将执行计划组装为一个针对产品目录的 Elasticsearch 查询:
POST products/_search
{
"query": {
"function_score": {
"query": {
"bool": {
"must": [
{ "match": { "title": "chocolate" } }
],
"filter": [
{ "terms": { "categories": ["Christmas foods and drinks", "Christmas sweets"] } },
{ "range": { "price": { "lt": 2 } } }
]
}
},
"functions": [
{
"weight": 1
},
{
"filter": { "terms": { "categories": ["Advent calendars"] } },
"weight": 3
}
],
"score_mode": "sum",
"boost_mode": "multiply"
}
}
}原始搜索字符串是 "cheap chocolate"。最终到达产品目录的查询是一个经过治理的、具备意图感知的检索计划:词语 "cheap" 已被消耗并转换为价格约束,结果被限制在圣诞季节性类别中,Advent calendar 产品获得排名提升,并且价格上限采用了来自低优先级策略中更严格的值。每一次转换都是确定性的、可追踪的、可解释的。
关于这些乘数如何与基础 BM25 分数交互的快速说明,可以参考相关 PRISM 视频 8:45 处,其中简要讨论了乘法式提升(multiplicative boosts)。
为什么这种方式具备可扩展性?
percolator 在这个用例中之所以高效,是因为存在结构上的不对称性:一个企业级电商系统可能有数百万个产品,但只有数百或数千条治理策略。percolator 只是在将单个传入的搜索字符串与这组已存储的策略模式进行匹配,而不是扫描整个产品目录。其成本与策略数量成正比,并且 Elasticsearch 通过内部优化(例如对已存储查询模式进行索引、对布尔逻辑进行短路处理)来保持匹配效率。
新增一条策略,只需要索引一条新文档;禁用策略,只需要更新一个字段;无需代码修改、无需部署、无需重启。
从查找到受治理的检索
percolator 提供了快速的反向匹配原语,使第 3 部分中的控制平面架构能够在规模上落地。策略作为数据被存储并建立索引,并被高效地与传入的搜索字符串进行匹配。控制平面通过第 3 部分中描述的级联转换和按字段冲突解决机制,将匹配到的策略组合成一个受治理的执行计划。随后,检索引擎在产品目录上执行该执行计划。
最终结果是一个系统:商品运营人员可以在不接触应用代码的情况下编写新策略,在代表性查询上进行测试,将其发布到生产环境,并立即看到效果。percolator 使策略查找变得快速;控制平面使策略组合变得确定性;而受治理的工作流则让整个过程变得安全。
本系列下一篇
本系列的下一篇文章将把受治理的控制平面扩展到新的领域。它将介绍一个多层级搜索架构,解释如何在保持稳定分页和 facets 的同时,协调严格检索、宽松检索和语义检索。
将受治理的电商搜索付诸实践
本文中描述的基于 percolator 的控制平面 ------ 从索引 mapping、边界标记,到基于高亮的短语追踪,再到级联策略组合 ------ 由 Elastic Services Engineering 构建,作为可复用的电商搜索加速方案的一部分。文中的每一个查询示例和策略结构都来自经过企业级产品目录验证的真实系统。
如果你想在 Elasticsearch 上实现一个受治理的、基于策略的控制平面,Elastic Services 可以帮助你更快实现。联系 Elastic 专业服务团队。
加入讨论
对搜索治理、检索策略或电商搜索架构有疑问?欢迎加入更广泛的 Elastic 社区讨论。
原文:https://www.elastic.co/search-labs/blog/elasticsearch-percolator-search-governance