智能体与工作流:从「想做一个应用」到「能跑通一条链」
这篇博客用睡前故事 串起两件事:概念上 分清智能体与工作流;操作上 用 Coze 搭画布(大模型 / 循环 / 插件)、发布工作流 ,再 创建对话智能体 把链挂上去并用预览验收;最后对比 Coze 与 Node.js 自研 。配图已上传 OSS(与本地
assets/agent-workflow/*.png同源文件名,便于你用img脚本覆盖更新)。
本文结构(按需跳读)
| 部分 | 内容 |
|---|---|
| 概念与需求 | 智能体、工作流、为何不能一次调模型、串行链、mermaid |
| 设计四步 | 只在脑子里/文档里「生成」草图,不涉及 Coze 点击路径 |
| 实践一 | Coze 工作流画布:节点类型、从「开始」到「结束」的配置与截图 |
| 实践二 | 发布工作流 → 创建智能体 → 编排里 挂工作流 → 预览与 发布智能体(截图) |
| 收尾 | Coze 优缺点、与自研关系、全文小结 |
智能体是什么:不止「和大模型聊一句」
智能体(Agent)在经典定义里,是能感知环境 、做决策 、再行动的系统。落到今天的大模型应用上,可以把它理解成:
以模型为「大脑」之一,再叠上检索、工具调用、业务规则、多模态输出 等能力,按固定或可变策略运转,最终对用户给出一个完整结果单元(而不只是一段即时回复)的那一层产品形态。
用户输入、系统提示词、中间调用的搜索与 TTS 等,都是「环境」与「指导信息」;智能体要做的,是在这些约束下把多步事情办完。
工作流是什么:把能力排成一条(或多条)流水线
智能体里真正承担业务骨架的,是 工作流(Workflow) :把「分析意图 → 查资料 → 写稿 → 润色 → 念出来」这类步骤,变成可执行、可观测、可迭代的节点图。
- 串行工作流:上一步输出是下一步输入,适合故事生成这类主线清晰的任务。
- 并行与分支 :实际业务里常有「同时查多个源」「某步失败则降级」等,图会变复杂;入门阶段先把一条串行链画清楚,价值最大。
一句话:智能体是「产品视角」的说法,工作流是「工程视角」的实现方式。
用「6~8 岁睡前故事」理解:为什么不能只调一次文本模型
假设产品需求是:
- 用户给一个故事主题 ;尽量讲经典民间故事 ,没有经典则围绕主题创作。
- 内容与语言要符合 6~8 岁认知,不「超龄」。
- 最后用亲切的语音把故事念出来。
若只做 chat.completions 一次调用,模型既可能胡编典故 ,又无法引用可靠原文 ,更没有声音。因此这个应用本质上需要多能力组合:
| 能力 | 作用 |
|---|---|
| 搜索 / 检索 | 找到故事原文或参考资料(常与 RAG / 检索增强生成 一起讨论) |
| 写作与润色 | 在检索结果上写草稿,再按儿童口吻改写 |
| 语音合成(TTS) | 把定稿文本变成可播放音频 |
这些能力不会自动长在一起 ,要靠你在产品里编排顺序、约定每步输入输出。这就是工作流要解决的问题。
核心工作流长什么样(串行示例)
把上面的需求压成一条链,可以是:
text
输入主题 → 生成检索 query → 搜索并整理材料 → 撰写草稿 → 语言与风格润色 → 语音合成 → 输出(文本 + 音频)用流程图表示更直观:
实现顺序上的建议 :先在纸上或文档里画出这条链,标清每一步的输入输出数据结构;再决定用 Coze 拖拽,还是用代码(例如 Node.js)写「调度器」。顺序对了,换工具只是换壳。
设计阶段的四步清单(还不打开 Coze 也能做)
你可以把下面四步当作任意业务的模板,先在文档或白板完成;它们回答的是「做什么」,而不是「在 Coze 里点哪个菜单」:
- 定义成功态:用户最终拿到什么?(一段 JSON、一篇带出处的文章、一条语音......)
- 拆能力:需要模型、搜索、数据库、支付、TTS 中的哪几项?哪些可以合并成一步?
- 定依赖与顺序:哪一步必须等上一步结束?哪一步可以并行?失败时是否重试或降级?
- 选承载 :原型期用 Coze 等低代码快速验证;上线前再评估是否迁到 自研编排(数据隐私、细粒度调试、成本结构)。
做到这里,你已经「生成」了智能体的设计稿 。接下来两节是落地 :先在 Coze 里把 工作流画布 跑通,再 发布 并 挂到智能体。
实践一:在 Coze 里搭「睡前故事」工作流(画布)
扣子 Coze 提供了工作流编排 :用节点把大模型、循环、插件等连成图,适合快速验证 「这条链跑不跑得通」。下面配图来自同一套「睡前故事」示例画布,界面以你当前 Coze 版本为准;若菜单文案略有差异,对照节点职责即可。
节点类型与添加路径(和本文截图一致)
在 Coze 工作流画布上点 「添加节点」 时,可按下面方式选类型(不同版本菜单层级可能微调,核心是节点类型要对):
| 画布上的职责 | 添加节点时的选择 | 说明 |
|---|---|---|
| 开始 / 结束 | 无需添加 | 新建工作流后画布默认自带;只需配置入参、出参。 |
| 生成 query、撰写草稿、润色 | 大模型 | 三处都是「大模型」节点,分别改节点标题与提示词、输入输出即可。 |
| 搜索并整理内容(外层) | 循环 | 先加循环 节点,再在循环体内部加搜索用的插件节点。 |
| 循环体内的搜索 | 插件 → 必应搜索 | 每次迭代用当前 query 调必应,把结果汇总给后续大模型。 |
| 语音合成 | 插件 → 搜索文本转语音 | 将润色后的正文交给插件生成音频(插件名以控制台为准)。 |
下文按数据从左到右 的顺序讲配置要点;你在菜单里选对的节点类型,就和「一步步实现」对上了。
画布总览:一条从主题到「文本 + 语音」的链
整体从左到右大致是:开始(默认)→ 生成 query(大模型)→ 搜索并整理内容(循环,循环体内必应搜索)→ 撰写草稿(大模型)→ 润色(大模型)→ 语音合成(插件:搜索文本转语音)→ 结束(默认)。多模态输出在「结束」节点里一次性返回给上层 Bot 或 API。
1. 新建工作流
进入 Coze 控制台 → 工作空间 → 资源库 → 新建 工作流 ,例如命名为 bedtime_story,描述写清「给 6~8 岁孩子讲睡前故事」。进入画布后,「开始」与「结束」是默认节点,不必在「添加节点」里再选一次;后面所有节点都是从「开始」往后串、最后收进「结束」。
「开始」节点 :声明工作流对外的入参。示例里只暴露一个字符串 input (故事主题),后续大模型节点通过模板变量 {{input}} 引用。
2. 第一个大模型节点:从主题到「检索 query」
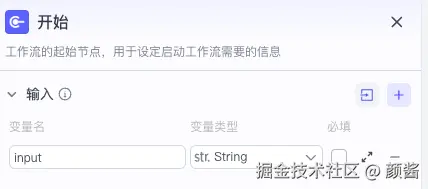
添加节点 → 大模型 ,将节点标题改为「生成 query」(名称可自定)。用于:根据用户输入分析意图 ,并输出一组搜索用 query (后续由循环消费)。
系统提示词可围绕「目标 + 分析方法 + 任务」来写,例如(节选思路):
- 若主题是常见民间故事名,则生成便于检索原文的 query;
- 否则结合文化背景生成能搜到参考资料的 query;
- 明确输出格式要求(如字符串数组)。
用户提示词里使用 Coze 的模板变量,把「开始」节点的输入接进来,例如:
text
{{input}}双花括号中的名字需与开始节点 里定义的输入字段名一致(默认常为 input)。
输出变量建议配置两个(示例命名):
| 输出名 | 类型 | 含义 |
|---|---|---|
querys |
字符串数组 | 多条检索 query |
intent |
字符串 | 对用户意图的简短概括 |
这里 intent 未必被后续节点消费,但让模型多输出一个「对自己有用」的字段 ,往往能起到链式思考(chain-of-thought)外显 的效果,有助于提高 querys 质量------这是很多工作流里的小技巧。
联调小技巧 :开发时可以把该节点输出直接连到 结束 节点,在结束节点里配置要暴露的变量,先验证「query 生成」是否稳定,再往下接搜索与写作。
下图可见:模型 选用「豆包·2.0·pro」等;输入 绑定「开始 → input」;输出 解析为 JSON 字段(如 intent、querys 数组),供下一节点消费。
3. 循环 + 必应搜索:对多条 query 逐个检索
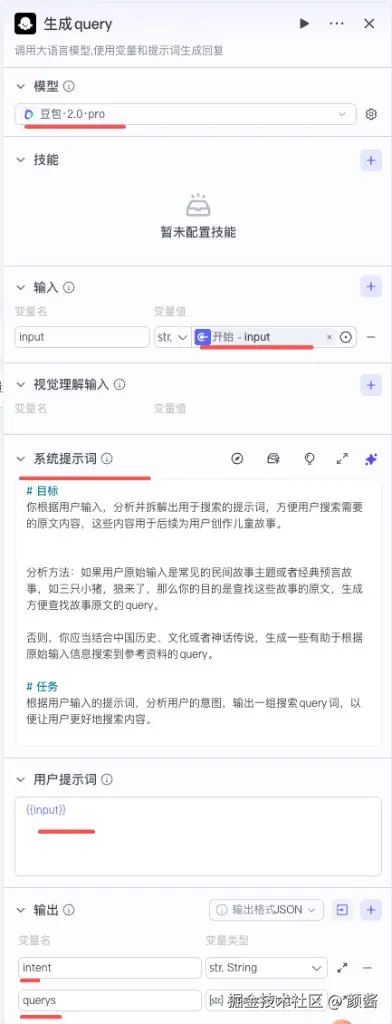
因为 querys 是数组,在「生成 query」后面 添加节点 → 循环;外层循环节点标题可写成「搜索并整理内容」一类,便于读图。
- 循环类型 :选「使用数组循环」;循环数组 绑定上一大模型节点的
querys。 - 循环体内部 :再点 添加节点 → 插件 → 必应搜索 (或你工作区里可用的等价联网搜索插件)。每次迭代把当前元素映射为搜索的
query,count控制条数;输出里的data等字段供循环汇总。 - 输出映射 :界面上常有经验顺序------先在循环体里把「必应搜索」节点接好、跑通,再回来配置循环节点对外的输出数组(否则没有可引用的中间结果)。
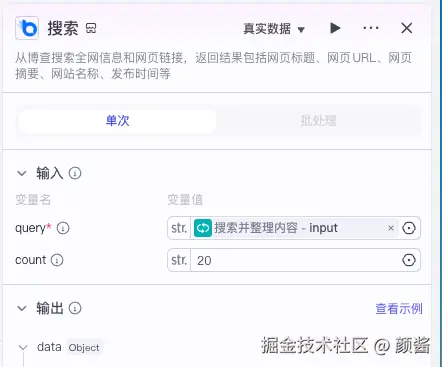
若不需要循环内的临时中间变量,可在 Coze 里按界面提示精简变量,避免图越来越乱。
4. 撰写草稿 → 润色(大模型)→ 语音合成(插件)→ 结束(默认)
在循环之后,把整理后的检索结果 交给两个连续的大模型节点做「写稿 + 润色」,最后用插件出音。
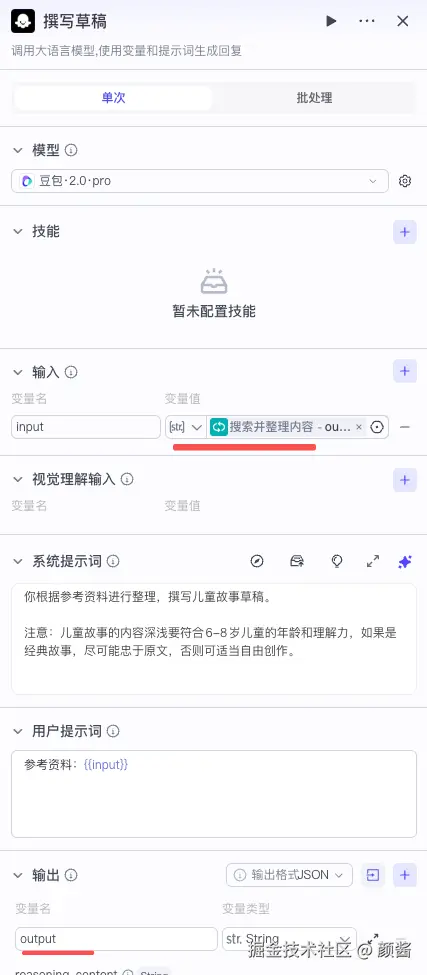
撰写草稿 :添加节点 → 大模型 。输入侧接入「搜索并整理内容」汇总后的材料;系统提示词约束「6~8 岁、经典尽量忠于原文」等;用户提示词用模板 参考资料:{{input}} 把变量喂进模型;输出 output (及可选 reasoning_content)供下一步使用。
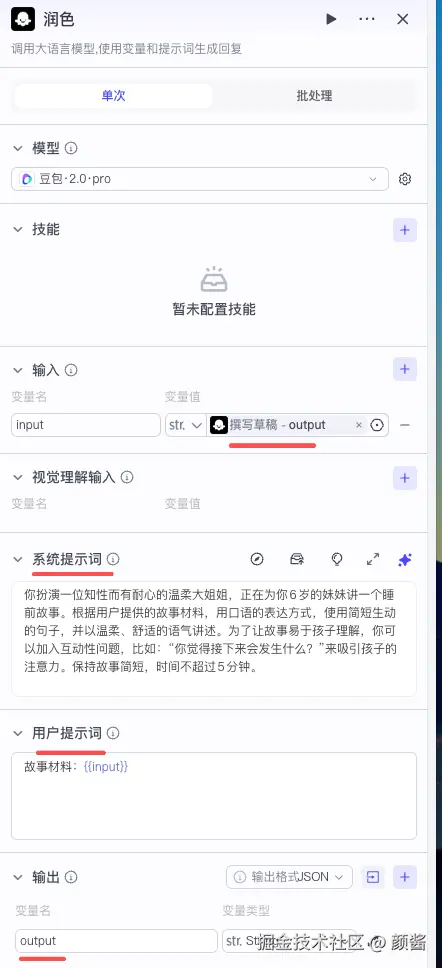
润色 :同样 添加节点 → 大模型 。输入接 撰写草稿 → output ;系统提示词切换为「温柔大姐姐给妹妹讲睡前故事」等人设;用户侧 故事材料:{{input}} ;输出仍为字符串 output。
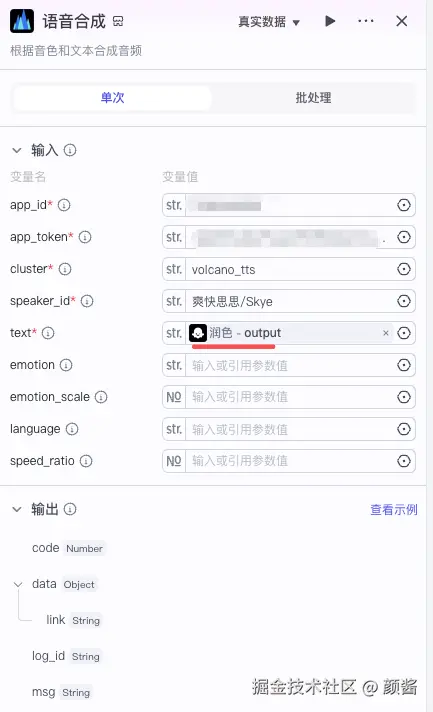
语音合成 :添加节点 → 插件 → 搜索文本转语音 (若控制台插件名称有细微差别,以实际列表为准)。将正文字段绑定 润色 → output ;并按插件面板填写音色、cluster(如 volcano_tts )、app_id / app_token 等;输出里常见 link 指向生成音频 URL。
结束 :使用画布默认的「结束」节点 即可;在配置里选 「返回变量」 :例如 text 映射润色后的正文,audio 映射语音合成返回的 link(或平台等价字段),这样上层一次拿到「可读文本 + 可播音频」。
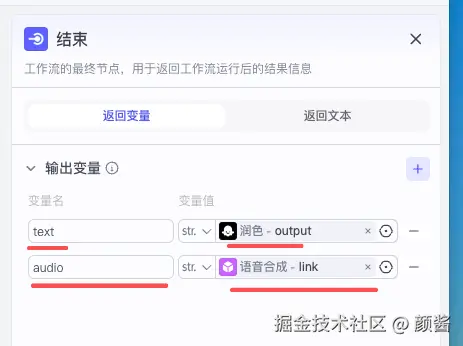
每一段的输入输出变量名 要与前后节点对齐;逻辑顺序应与上文「核心工作流」示意图一致------你在 Coze 里是在「画图实现」同一张设计稿。
实践二:发布工作流,并挂到「对话智能体」
画布上的 工作流 解决「一条链怎么跑 」;智能体(Bot) 解决「用户怎么对话触发这条链 」。建议顺序:试运行并发布工作流 → 在资源库 创建智能体 → 编排 → 技能 → 工作流 里添加已发布的工作流 → 预览与调试 验证触发与入参 → 发布智能体。
试运行与发布工作流
在 bedtime_story (或你的工作流名)编辑页里先 试运行 ,确认「开始 → ... → 结束」整条链无报错后,使用平台提供的 发布 (或「上线」类)能力,把工作流变为 已发布 状态。只有发布后,智能体侧「添加工作流」列表里才容易稳定搜到它(具体按钮名称以 Coze 当前版本为准)。
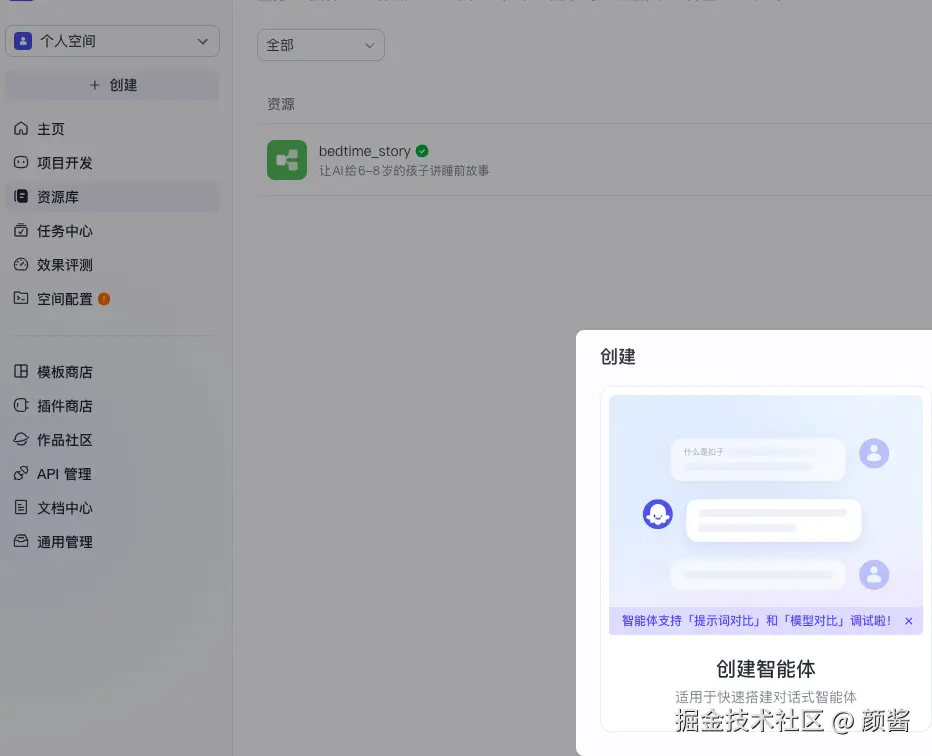
在资源库创建智能体
进入 工作空间 → 资源库 ,右上角 「+ 创建」 ,选择 「创建智能体」(适用于对话式智能体)。
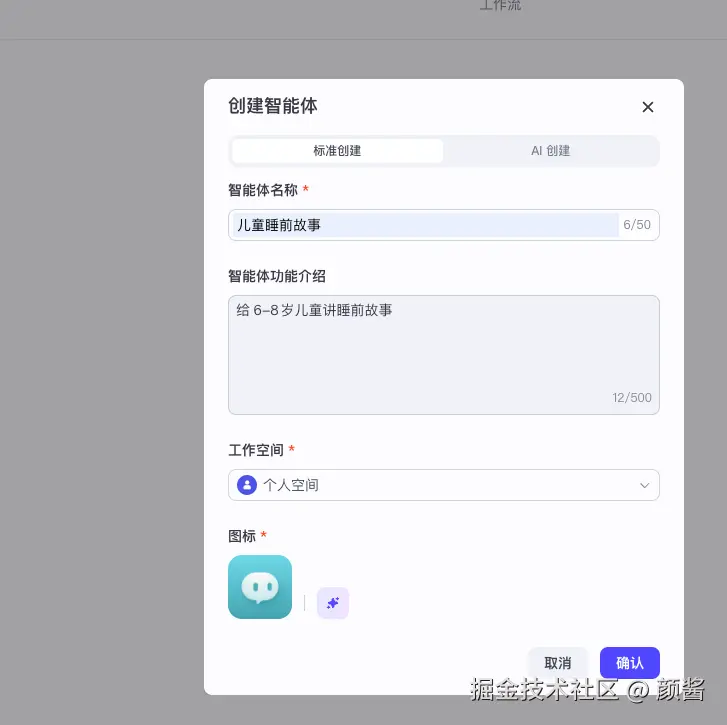
填写名片并确认
在弹窗里选 标准创建 (或你需要的创建方式),填写 智能体名称 、功能介绍 、工作空间 、图标 等。示例中与睡前故事一致:儿童睡前故事 / 给 6-8 岁儿童讲睡前故事 等。点 确认 进入编排页。
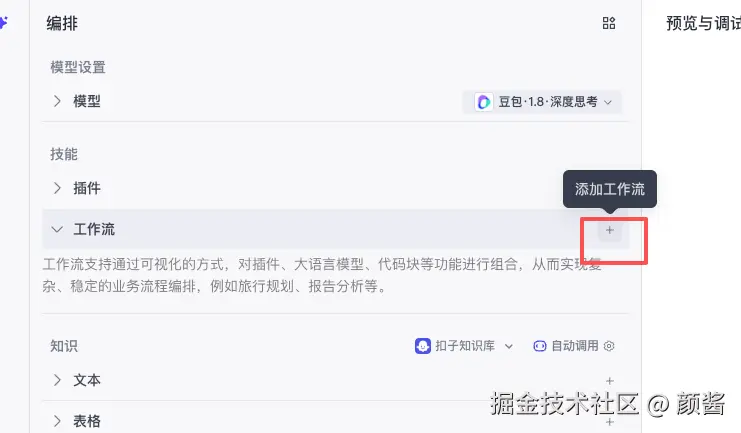
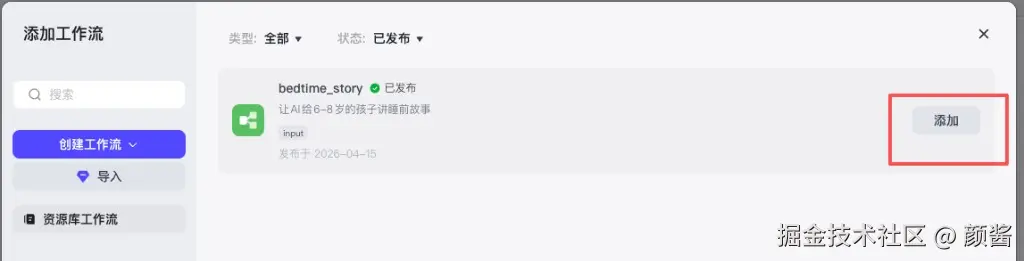
编排里挂载工作流技能
打开 编排 ,在 技能 区域找到 工作流 一行,点击右侧 「+」 (提示为 添加工作流 )。在列表中选中已发布的 bedtime_story ,点 添加 ,把它挂到当前智能体上。这样用户发一句自然语言时,智能体才会按策略去 调用 你刚编排好的那条链。
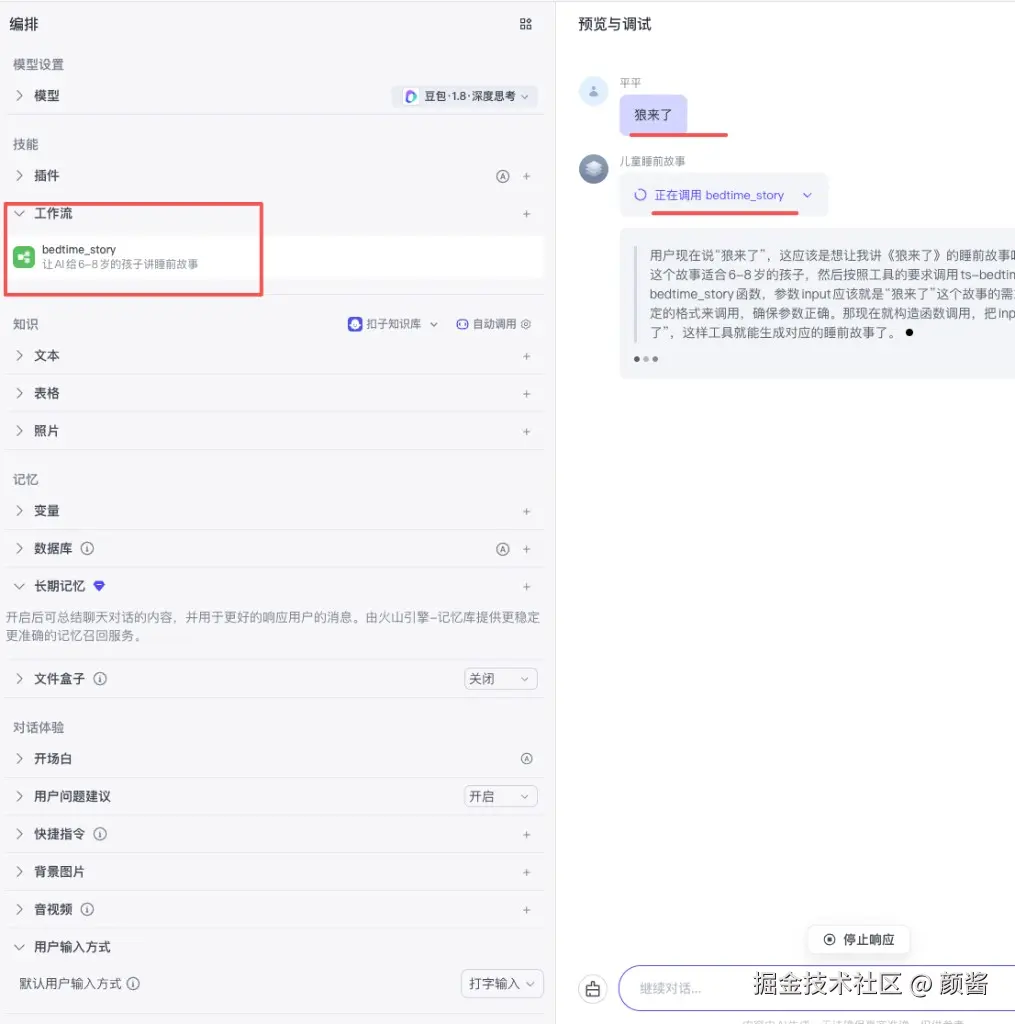
预览调试并发布智能体
右侧 预览与调试 里直接输入用户会说的主题(例如 「狼来了」 )。若编排正确,应能看到 正在调用 bedtime_story 一类状态,并走完整条工作流(含你结束的 text / audio 等返回)。确认满意后,再在平台里 发布智能体,对外分享或接入渠道。
与「实践一」的关系 :工作流 = 可复用的业务链;智能体 = 对话壳 + 默认模型 + 挂载的一条或多条工作流 。先发布链,再把链挂到 Bot 上,用预览验证「用户一句话 → 工作流入参 input」是否对齐。
Coze 工作流的优缺点:适合当「哪一级」
优点
- 快:复杂分支、流式输出、插件生态都能较快搭出可演示版本。
- 省成本 :适合创业者、团队做原型验证与需求对齐。
- 可视化:非纯研发也能参与讨论「第几步该干什么」。
局限
- 平台绑定 :流程与数据多在 Coze 侧,对强隐私、强合规、专有部署的场景要慎重。
- 节点内部偏黑盒:要做极致的数据结构优化、细粒度耗时分析时,不如代码透明。
因此常见节奏是:Coze 验证工作流是否合理 → 定型后用 Node.js(或其它后端) 把同一条 DAG 写成可维护的服务(与本仓库 server.js 编排多厂商 API 的思路一致)。理解「工作流原理」之后,换承载并不神秘。
小结:从草图到可对话的一条龙
- 先定义成功态与边界(对应上文「设计四步」前两条):用户拿什么结果、年龄与体裁等约束。
- 再画工作流(设计四步后两条 + mermaid):拆能力、定顺序、选承载。
- 实践一:Coze 画布:「大模型 → 循环 + 必应 → 大模型 ×2 → 搜索文本转语音」,开始/结束用默认节点。
- 实践二:上架 :发布工作流 → 创建智能体 → 编排 → 技能 → 工作流 挂载 → 预览 → 发布智能体。
- 再决定要不要自研 :原型通过后,用 Node.js 等复刻同一条 DAG(见本仓库
server.js一类编排)。
智能体不是「多调几次模型」的代名词,而是**「多步能力 + 清晰编排」**的产物;设计稿 → 工作流画布 → 对话壳挂载 走完,就是从想法到可演示产品的完整一程。