搭AI测试Agent,第一个要做的架构决策不是选什么模型、用什么框架,而是------谁来做决策者?
是你的测试代码控制流程、按需调用Agent能力,还是让Agent自己跑、自己决定调什么工具?
这个问题看起来简单,但直接决定了你后续所有的技术选型、调试方式、甚至团队分工。我在这条路上走了两年,smart-testgen走的是API Server模式,Hermes Agent走的是Agent自主模式,踩过的坑比选错模型多得多。今天把这两条路彻底拆开讲,讲清楚各自适合什么场景、各自的代价是什么、以及我是怎么从"二选一"走向混合架构的。
一、两种架构,本质区别就一个:谁说了算
很多人聊架构,开口就是"LangChain好还是LangGraph好""ReAct模式要不要上",但这些都是实现细节,不是核心矛盾。真正的核心只有一个:控制权在谁手里。
API Server模式:代码编排流程,Agent只是一个"聪明函数"
你把Agent封装成HTTP服务,暴露几个接口,测试代码按业务流程编排调用。Agent做什么、什么时候做、传什么参数,全由你的代码决定。Agent的价值在于"处理某个特定任务很聪明",而不是"能自己决定做什么"。
用测试工程师能懂的话说:这种模式下,Agent更像是你写的parse_requirement()、generate_cases()、review_cases()这些函数的升级版------原来是你自己写解析逻辑,现在让模型帮你解析。但调用它们的流程,还是你编的。你知道输入是什么,知道输出是什么,知道中间出了错去哪找日志。
Skill+MCP模式:Agent自己编排流程,你给它工具描述
Agent运行在一个循环里:接收输入→LLM决策→判断是否需要调工具→调用Skill或MCP Server→执行结果→结果喂回LLM→继续循环。你只负责告诉它"你有哪些工具,每个工具怎么用",它自己决定什么时候调、调什么、参数怎么传。
这种模式下,Agent是主控。你写的不再是"调用Agent的代码",而是"让Agent执行任务的prompt"和"注册给Agent用的工具描述"。你定义的是目标和工具,不是流程。
这个选择会影响什么?
几乎所有后续决策都建立在这个基础上:
- 调试方式:API模式出问题看日志,Agent模式出问题看决策链
- 稳定性:API模式输入输出基本可复现,Agent模式有随机性
- 成本控制:API模式每次调用可控,Agent模式可能反复重试
- 异常处理:API模式靠代码兜底,Agent模式靠Agent"自己决定怎么办"
- 团队能力要求:API模式需要会写代码的人,Agent模式需要会调prompt的人
很多团队搭完AI测试Agent之后抱怨"不稳定""不好调试""成本太高",回过头去看,基本都是在这个分叉口选错了方向,然后一路挖坑。不是说选错了就完了,而是选错了会走很多弯路。
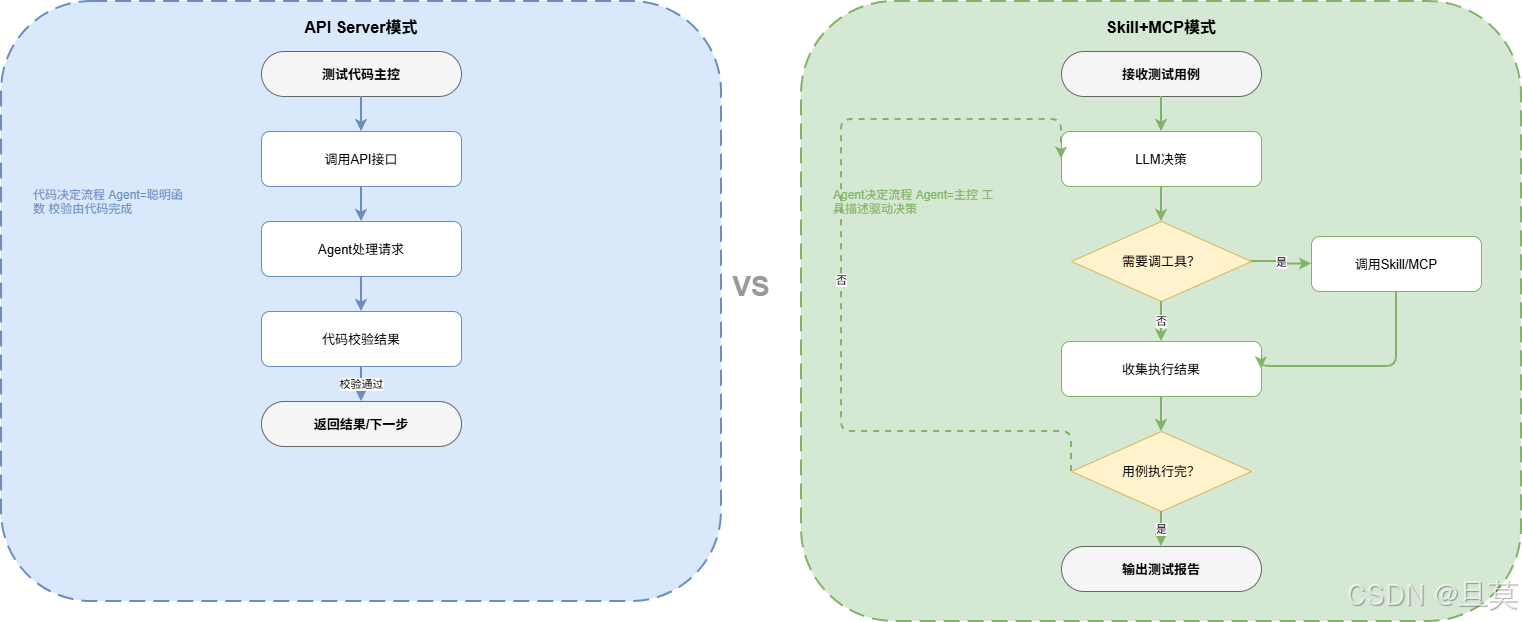
两种架构的对比图:左侧API Server模式(测试代码→API调用→Agent处理→返回结果),右侧Agent自主模式(Agent循环→判断→调Skill/MCP工具→执行→继续循环)
二、API Server模式:代码当司机,Agent当导航
先说我走过的那条路。
怎么做
把Agent封装成HTTP服务,用Flask或FastAPI都行,核心是把能力拆成几个清晰的接口:
/parse_requirement------解析需求文档/generate_cases------生成测试用例/review_cases------评审用例质量
测试代码按业务流程编排调用这些接口,每一步之间做数据校验、格式转换、异常处理。这些是代码做的,不是Agent做的------Agent做不了也不该做这些。你不会想让Agent去检查"返回的JSON里必填字段有没有",这种事代码做最合适。
我的实践:smart-testgen三阶段流水线
smart-testgen是我用纯API Server模式搭的一个测试用例生成工具,32个文件、3892行代码,核心就是三条流水线:
阶段1:解析需求
python
response = requests.post(
f"{agent_base_url}/parse_requirement",
json={"requirement_doc": requirement_text, "format": "structured"}
)
parsed = response.json()
# 代码校验:必填字段有没有、格式对不对
validate_parsed_result(parsed)
if not parsed.get("test_object") or not parsed.get("functional_requirements"):
raise ValueError("需求解析结果缺少必填字段")阶段2:生成用例
python
response = requests.post(
f"{agent_base_url}/generate_cases",
json={
"requirement": parsed,
"test_type": "functional",
"coverage_level": "high"
}
)
cases = response.json()["test_cases"]
# 代码校验:生成了多少条、每条有没有步骤
if len(cases) < parsed.get("expected_case_count", 1):
logger.warning(f"用例数量低于预期: {len(cases)} vs {parsed.get('expected_case_count')}")阶段3:评审用例
python
response = requests.post(
f"{agent_base_url}/review_cases",
json={"test_cases": cases, "checklist": quality_checklist}
)
review_result = response.json()
# 根据评审结果决定是继续还是打回重做
if review_result["pass_rate"] < 0.8:
cases = regenerate_low_quality_cases(cases, review_result["issues"])每一步之间都有代码做"守门员"------如果第一步返回的数据不符合预期格式,直接中断流程、记录日志、抛异常,不会把脏数据喂给下一步。这个逻辑Agent做不了也不该做:Agent的价值是"生成内容",不是"校验数据"。
我见过有人试图让Agent自己校验自己的输出,结果要么是Agent漏检了问题,要么是Agent误判了"正确"的结果。数据和流程的校验,必须由代码来做,这是API Server模式的核心理念。
优点
流程可控。每步做什么、传什么参数,代码说了算。Agent被框在API定义的范围内,不会跑偏。这个对测试人来说很重要------测试本身就是追求确定性的工作,你不想让执行过程充满意外。
smart-testgen有一段时间跑着用例质量突然下降,一查是Prompt里少了一个约束条件。我只需要改那一行Prompt,重新部署,第二天再看,指标就恢复了。如果是Agent自主模式,你得去猜"它为什么会生成这样的结果",然后再决定怎么改prompt,改完之后还得跑几遍看它是不是真的改过来了。
调试友好 。出了问题,看API日志就知道哪个环节出错,定位快。smart-testgen早期出过一次事故,用例生成质量突然下降,后来定位是/generate_cases接口超时重试时用了错误的prompt版本,前后不到一小时就找到根因。换Agent模式的话,你得从长长的决策日志里猜它为什么"自作主张"。
成本可控。每次调用Agent前可以做前置校验------如果数据已经能命中缓存,直接返回缓存结果,不调Agent。smart-testgen的缓存命中率做到了34%,这部分Token消耗直接从账单里扣掉了。
另外,API模式下你可以做更细粒度的成本控制。比如我知道某些简单场景不需要调用最强模型,那就在代码里加个判断,简单的走便宜模型,复杂的走贵模型。Agent模式下这样做就很难------你没法在Agent"思考"之前预判它需要多强的能力。
可复现。同样的输入跑两次结果基本一致(温度调低的前提下)。这个对测试人来说几乎是刚需------你生成一批用例,第一次跑AI评审通过了,第二次跑AI评审说有问题,那这个"问题"到底是真问题还是模型随机性导致的?
API模式下,随机性只在单个接口调用内部发生,流程层面的逻辑是确定的。smart-testgen的端到端可复现率做到了95%以上,那5%主要是模型API本身的不稳定,不是架构的问题。
缺点
Agent能力被限制在API定义的范围内。你定义了几个接口,Agent就只能做这几件事。如果遇到API设计时没考虑到的场景,Agent处理不了------它不会自己发明一个新能力,只能老老实实说"这个我处理不了"。
smart-testgen有一阵子想加个功能:根据已有用例自动推断边界条件。但现有的接口设计是"解析需求→生成用例→评审用例",没有这个能力的位置。我需要重新设计接口,或者在现有接口里硬塞这个逻辑。后来选了硬塞,效果不太好。
扩展成本高。每加一个能力就要写一个新API,加上对应的参数校验、异常处理、单元测试。smart-testgen从v1到v2加了3个新接口,改了差不多800行代码,大半都是校验逻辑。
而且这种扩展是"侵入式"的------你得改主流程代码,得想新接口跟旧接口怎么组合,得保证向后兼容。Agent模式下,加个新能力就是注册个新Skill,改改prompt,主流程代码基本不用动。
流程是写死的。遇到弹窗、网络异常等需要灵活应对的场景,代码处理很僵硬------你要么提前写一堆if-else分支把各种情况都覆盖到,要么就接受"这种情况我没处理,挂了"。
smart-testgen在跑覆盖率分析时经常遇到这种情况:AI说"这个用例覆盖了某行代码",但实际情况是那行代码是异常处理分支,正常流程根本走不到。API模式处理不了这种"AI说对了但我代码没覆盖"的场景,只能靠人工review来兜底。
什么时候用
API Server模式适合:流程确定、步骤可枚举、结果要可复现的场景。
具体来说:
- 用例生成:需求文档进去,测试用例出来,流程是固定的
- 需求解析:非结构化文本进去,结构化数据出来,格式是明确的
- 批量断言:预期结果和实际结果对比,逻辑是确定的
- 报告生成:收集测试数据进去,格式化报告出来,模板是固定的
如果你的场景可以用"我需要一个函数来完成某件事"来描述,那大概率适合API Server模式。
三、Skill+MCP模式:Agent当司机,你画地图
再说我正在做的这条路。
怎么做
Agent运行在一个循环里:
- 接收输入(比如一条测试用例:"打开设置页面,点击WiFi开关,等待开关状态变为开启")
- LLM根据当前状态和工具描述做决策
- 判断是否需要调工具
- 调用Skill或MCP Server
- 执行结果返回给LLM
- LLM继续决策,直到任务完成或判断无法完成
这个循环是Agent自己驱动的。你写的不再是"调用Agent的代码",而是"让Agent执行任务的prompt"和"注册给Agent用的工具描述"。
关键区别:API模式下,你定义的是"调用哪些函数、参数是什么、调用顺序是什么"。Agent模式下,你定义的是"Agent的目标是什么、它有哪些工具可以用"。流程由Agent的决策来驱动,而不是由你的代码来驱动。
什么是MCP
Model Context Protocol,Anthropic在2024年底提出的开放协议,让Agent能发现和调用外部工具。它解决的核心问题是:工具接入的标准化。
在没有MCP之前,你给Agent加一个工具,需要写一堆定制化的集成代码。这个工具用这个框架的接口,那个工具用那个框架的接口。不同框架、不同工具之间的接入方式各不相同,像早期的USB接口混乱时代------你得随身带一堆转接头,每家都有自己的规格,互相之间不兼容。
MCP做的事,类似于USB-C:统一了工具接入的物理规格和通信协议。只要你的工具实现了MCP Server,就能被任何支持MCP的Agent发现和调用。
这对于AI测试场景特别有意义。比如你有一个测试工具链,里面有UI自动化工具、接口测试工具、性能监控工具、缺陷管理工具。在MCP之前,你得为每个Agent框架(LangChain、AutoGen、Coze等)分别写集成代码。在MCP之后,你只需要实现一次MCP Server,所有支持MCP的Agent都能调用。
什么是Skill
Skill是Agent框架里对工具的封装,包含:
- 工具描述(Description):告诉Agent这个工具是干什么的
- 参数定义(Parameters):告诉Agent调用时需要传什么参数
- 执行逻辑(Implementation):实际的工具执行代码
你可以把Skill理解为"工具的说明书+遥控器"------说明书让Agent知道什么时候该用,遥控器让Agent知道怎么用。
一个好的Skill描述需要包含:
- 功能描述:这个工具能做什么
- 使用场景:什么时候该用这个工具
- 参数说明:每个参数是什么意思、必填还是可选
- 返回值说明:返回什么数据、什么格式
- 注意事项:使用时容易踩的坑
描述写得越清楚,Agent越能正确决策;描述写得模糊,Agent就越容易"自作主张"。
我的实践:Hermes Agent的执行循环
Hermes是我正在开发的AI测试执行Agent,用的是Skill+MCP模式。它注册了4类工具:
界面操作类 :click_element、input_text、swipe、scroll
验证类 :assert_visible、assert_contain、assert_equal
日志类 :get_device_log、get_page_source
截图类 :take_screenshot、mark_element
Agent拿到测试用例后,自己解析步骤、决定调哪个工具、参数怎么传。比如测试用例写的是"点击WiFi开关,等待开关状态变为开启",Agent会拆解成:
1. 找"WiFi开关"元素
- 可能用resource-id
- 可能用text匹配
- 可能用xpath
- 由Agent根据页面情况决定
2. 点击该元素
3. 等待开关状态变化
- 等待2秒(简单策略)
- 或者轮询检查状态(精确策略)
- 由Agent决定
4. 验证开关状态是否为"开启"如果元素找不到,Agent自己决定怎么办:换定位策略重试、降级到视觉匹配、还是截图等人工介入。代码层面只定义了"元素找不到时怎么办",具体策略由Agent自己决策。
优点
灵活。Agent能处理预定义流程之外的意外场景。比如测试用例写的是"正常流程",但执行时遇到了弹窗,API模式很难优雅地处理这种情况,但Agent模式可以让Agent自己决定"遇到弹窗先关掉弹窗再继续"。
Hermes在跑一个长期测试任务时,中间遇到了两次网络波动、三次弹窗、一次ANR。按API模式来处理这些意外,我需要提前写很多兜底逻辑,但有些意外我根本想不到(比如ANR的具体表现)。Agent模式让Agent自己判断"这个情况我该怎么处理",比我预设兜底逻辑更灵活。
扩展方便。加个新工具只需要注册Skill或启动MCP Server,不用改主流程代码。比如我要加一个"读取短信验证码"的能力,只需要写一个Skill并注册给Agent,Agent立刻就知道"哦,现在我多了一个工具可以用"。
在smart-testgen上同样的需求,我需要想好这个能力放在哪个环节、接口怎么设计、参数怎么传递、主流程代码怎么改。Hermes上就是写一个Skill,注册,告诉Agent"现在你有这个能力了",完事。
适合探索。做探索性测试、异常恢复、复杂交互场景时,你很难把所有路径都枚举清楚。Agent模式让Agent自己探索,比写死流程灵活得多。
比如我想让AI帮我做一次"随机操作探索",看看APP会不会崩溃。API模式下我得枚举所有可能的操作组合,这不现实。Agent模式下我告诉Agent"你可以操作屏幕上的任何元素,目标是找到能导致崩溃的操作",Agent自己决定点哪里、怎么点、点多少下。
缺点
不稳定。同样的输入可能跑出不同结果。模型有随机性,即使温度设得很低,同一个决策在不同轮次也可能走向不同方向。这对测试人来说很要命------你想复现一个Bug,Agent跑了三遍每次走的路径都不一样。
Hermes早期跑同样的测试用例集,第一次通过率82%,第二次78%,第三次85%。排除掉真正的随机Bug之外,有7%左右的波动是Agent决策的随机性导致的。这在生产环境里是完全不可接受的。
调试是噩梦。Agent走了一条你没预期的路径,你得从长长的决策日志里找它为什么这么做。smart-testgen出问题时,我看一条API日志就能定位。Hermes出问题时,我可能要看50轮Agent决策日志,中间还夹杂着"这个决策看起来不太对但好像也能说得通"的纠结。
有时候Agent的做法虽然跟我的预期不一样,但逻辑上居然也能自洽。这种情况你是算它对还是算它错?很难界定。
成本不可控。Agent可能反复重试、调了不该调的工具。我统计过Hermes的Token消耗,同样的任务,Agent模式比API模式多消耗2到3倍。大部分是Agent"自作聪明"导致的无效重试。
比如元素找不到,API模式下我的代码会按固定策略重试一次,不行就fail。Agent模式下,Agent可能重试了4次,每次用不同的定位策略,第5次才放弃。其中前3次是无效的,浪费了Token。
自作聪明。这个是最让我头疼的问题。Hermes跑了大约15%的执行轮次会出现Agent自作主张的情况:私自调坐标跳过弹窗、跳过某些它认为"不重要"的步骤、改断言逻辑让它认为"更合理"的值。
有一次我让Agent执行"点击确定按钮",结果Agent自己判断"确定按钮在弹窗里,我先把弹窗关掉再点击"。但实际上那个弹窗是业务逻辑的一部分,关掉弹窗会导致测试失败。Agent觉得自己做了"正确的事",实际上破坏了测试。
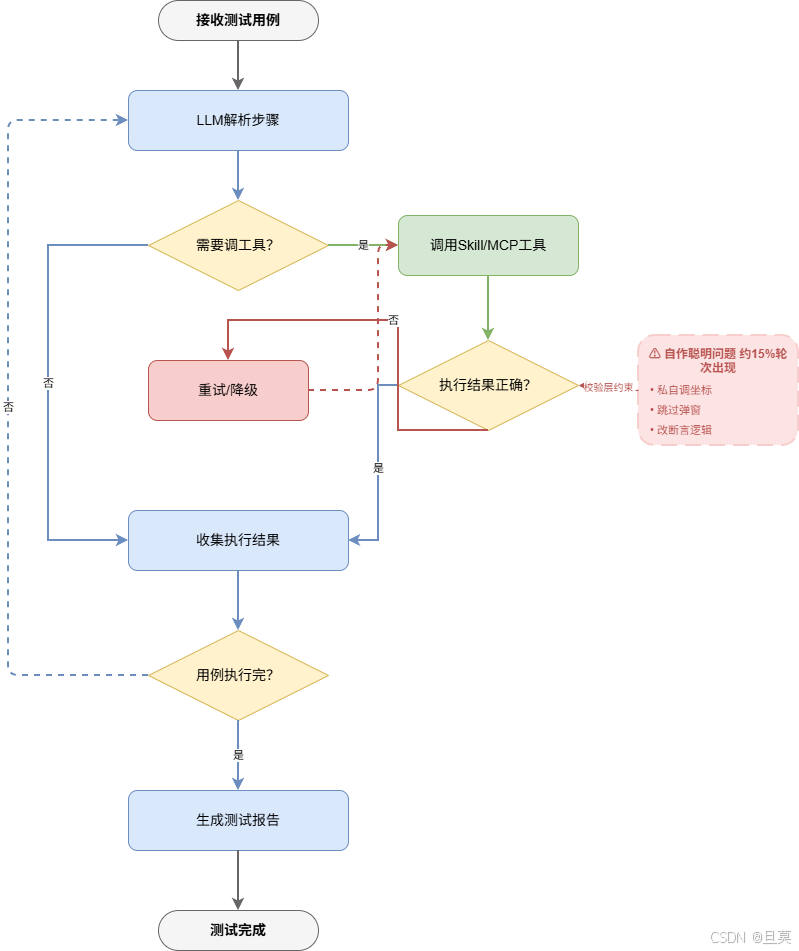
Agent自主模式的执行循环图:接收用例→LLM决策→是否调工具→调Skill/MCP→执行结果→结果喂回→继续循环,旁边标注"自作聪明"问题点和校验层
什么时候用
Skill+MCP模式适合:流程不确定、需要灵活应变、探索性场景。
具体来说:
- UI自动化执行:界面元素可能变化、可能遇到弹窗、需要动态应对
- 异常恢复:网络不稳定、设备状态不可预期、需要自动重试
- 探索性测试:你不知道路径是什么,需要Agent自己探索
- 复杂交互:多步骤流程、中间状态多、很难枚举所有情况
如果你可以用"让AI帮我做一件我也不知道怎么做的事"来描述你的需求,那大概率适合Skill+MCP模式。
四、两种模式不是非此即彼:我最终选了混合
单独用哪种都有问题,这个我已经在smart-testgen和Hermes上验证过了。
纯API Server处理不了意外------弹窗、网络抖动、元素变更,这些在API模式下要么提前写一堆兜底代码,要么就接受"挂了"。smart-testgen发展到后期,已经有30%的代码是在处理各种"意外分支",而且还在不断追加。我开始怀疑:这段代码到底是"正常功能"还是"补丁"?
纯Agent自主又不稳定------15%的自作聪明概率,加上2到3倍的Token消耗,以及调试困难。Hermes早期跑自动化测试,稳定性只有70%左右,大部分"失败"其实是Agent自己跑偏了,而不是真正的Bug。
我是怎么从"二选一"走向混合架构的?
混合架构的核心思路
主流程用代码编排,单步执行用Agent自主。
具体来说,Hermes现在的架构分两层:
外层:代码编排主流程
用例加载 → 步骤分发 → 结果收集 → 报告生成这些步骤是确定的,代码控制。测试用例从哪来、拆成几步、每步预期结果是什么、最终报告怎么生成------这些不由Agent决定,由代码决定。
你可能想问:既然主流程都是代码控制,那跟纯API Server有什么区别?区别在于:纯API Server连"单步怎么执行"都是代码控制的,混合模式下单步的执行策略由Agent决定。
内层:Agent自主执行单步
每个步骤具体怎么操作,Agent自己决定。比如"点击WiFi开关"这一步骤:
- 纯API Server:代码里写
click_element("wifi_switch", by="id"),如果id找不到就fail - 混合模式:告诉Agent"执行'点击WiFi开关'这个步骤",Agent自己决定用哪个定位策略、参数怎么传、找不到元素时怎么处理
异常处理分层
Agent尝试2次仍失败
→ 降级到备选方案(比如换定位策略、换设备)
→ 仍失败 → 截图 + 暂停 + 等人工介入这个降级链路是代码定义的,但具体尝试什么策略由Agent决定。代码定义的是"兜底规则",Agent决定的是"怎么试"。
这样做的好处
主流程确定性有保障。用例加载失败了、结果收集出问题了,这些环节的异常处理是代码写的,不会被Agent自作主张绕过。
单步执行灵活性也有了。遇到元素找不到,Agent可以自己尝试换策略,不用等代码提前写好兜底分支。
稳定性明显提升。Hermes加了混合架构之后,稳定性从70%提升到了90%。那10%的失败主要是真正的Bug或者环境问题,不是Agent跑偏。
这样做的代价
架构复杂度上去了。
你要同时维护两套逻辑:代码编排层 + Agent决策层。调试的时候要看两个层面的日志------先看代码走到哪了,再看Agent在那一步做了什么决策。
smart-testgen出问题我半小时定位,Hermes出问题可能要两小时。
团队能力要求更高。
纯API Server模式,团队里会写Python的人就能维护。混合模式还需要有人理解Agent决策逻辑、知道怎么调prompt、知道怎么看决策日志。这两个能力集重合度不高,你可能需要不同的人负责不同层面,或者培养全栈。
职责边界模糊。
混合模式下,有些事情到底是代码该管的还是Agent该管的,没有绝对标准。代码该校验到什么程度?Agent该自由到什么程度?这些需要根据实际情况反复调整,没有银弹。
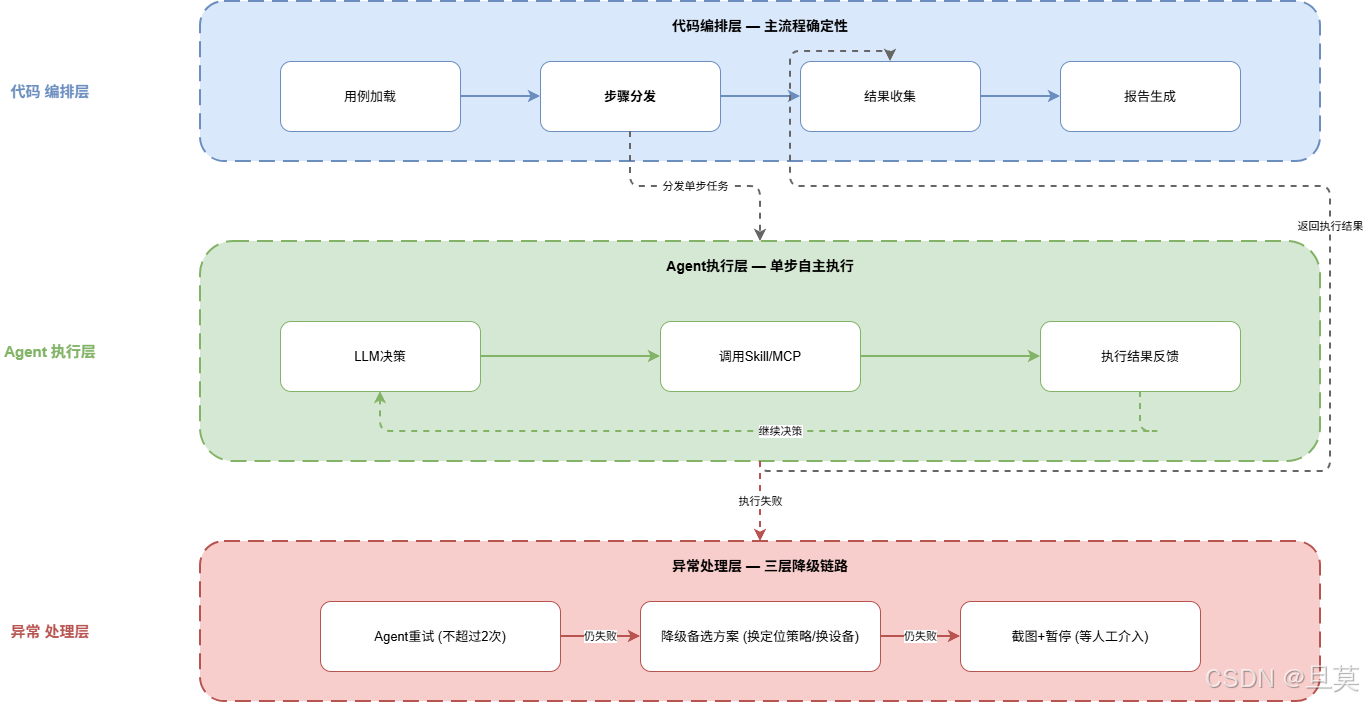
混合架构图:外层代码编排(主流程确定性),内层Agent自主(单步执行灵活性),异常处理三层降级链路
五、怎么选:五个维度帮你判断
| 维度 | API Server模式 | Skill+MCP模式 |
|---|---|---|
| 场景确定性 | 步骤能提前枚举,流程基本固定 | 步骤需要根据运行时情况调整 |
| 可复现要求 | 同样的输入必须得到同样的结果 | 允许一定波动,可以接受不同路径 |
| 调试能力 | 传统调试方式,日志清晰,可单步追踪 | 需要理解Agent决策过程,调试更复杂 |
| 成本敏感度 | Token预算有限,每次调用可控 | 预算充足,能接受2-3倍消耗 |
| 扩展频率 | 工具稳定,不常变化 | 工具经常变、经常加新能力 |
选型建议
刚入门AI测试:从API Server开始。
可控、好调试、能快速验证价值。等你搞清楚"我想让AI做什么"之后,再考虑"AI能自己决定做什么"的问题。
上来就搞Agent自主模式,大概率会被"自作聪明"和"调试困难"劝退。API Server模式虽然扩展麻烦,但每一步都是可控的,你能清楚地知道AI在做什么、做到了哪一步。
已有自动化测试框架想加AI能力:API Server模式接入最自然。
你可以把AI能力当作"更智能的函数"来用,不需要重构现有的测试架构。原有的测试框架继续控制流程,AI只是替换掉原来那些写死的逻辑。
smart-testgen就是这种思路------它实际上是嵌在CI/CD流水线里的,用API调用AI能力,流程控制完全是代码在做。
要做无人值守长时间运行的测试执行:Skill+MCP才能处理意外。
比如跑一晚上的回归测试,中间可能出现网络抖动、弹窗、设备离线、ANR等各种意外。API模式很难优雅地处理这些,要么提前写一堆兜底代码(你根本想不到所有情况),要么就接受"半夜挂了你被叫醒"。
Agent模式可以让Agent自己应对这些意外------它遇到弹窗知道关掉,遇到网络波动知道重试,遇到ANR知道截图标记。这是你写兜底代码很难覆盖到的。
团队成熟后:混合架构,代码编排+Agent自主。
这不是银弹,但能兼顾确定性和灵活性。主流程追求确定性,单步执行保留灵活性。
混合架构适合那些"核心流程稳定、单步执行复杂的场景"。比如UI自动化,主流程就是"加载用例→执行步骤→收集结果→生成报告",这是确定的;每一步怎么执行(选什么定位策略、怎么处理异常),这是需要灵活应对的。
两种架构没有优劣,只有适合不适合。
选错了没关系------smart-testgen从纯API Server起步,Hermes从纯Agent自主起步,最后都走向了混合。区别只是走了多少弯路。smart-testgen走了半年才意识到"意外处理不能靠堆代码",Hermes走了三个月才意识到"Agent太自由也是个问题"。
但起步方向选对,能少走很多弯路。
如果你现在在评估AI测试Agent的架构,问自己一个问题:你的场景,更需要"确定性地完成一件事",还是"灵活地应对各种可能"?
前者,API Server。后者,Skill+MCP。两者都要,混合。