还在被 Transformer 的复杂度劝退?来认识一下序列建模的鼻祖 RNN------它的思想正以全新姿态回归大模型舞台中央。
在自然语言处理中,词语的顺序对于理解句子的含义至关重要。虽然词向量能够表示词语的语义,但它本身并不包含词语之间的顺序信息。为了解决这一问题,研究者提出了循环神经网络(RNN)。本文将从核心原理出发,涵盖 PyTorch API 使用、完整实战案例,并深入剖析 RNN 面临的核心挑战,旨在为开发者提供一份系统且深入的技术指南。
一、RNN 核心原理
1.1 为什么需要 RNN?
传统的全连接神经网络要求所有输入彼此独立,无法处理变长的序列数据。例如,在句子"我喜欢吃苹果"中,"吃"和"苹果"之间具有强烈的依赖关系,这种依赖关系无法通过独立建模每个词来捕捉。RNN 引入 循环连接,使得网络能够跨时间步传递信息------这种"记忆"机制让 RNN 天然适合处理文本、语音、时间序列等具有时序依赖的数据。
1.2 基础结构与数学原理
RNN 的核心是一个具有循环连接的隐藏层,它以时间步(time step)为单位依次处理输入序列中的每个 token。在每个时间步,RNN 接收当前 token 的向量和一个时间步的隐藏状态,计算并生成新的隐藏状态,然后将其传递到下一个时间步。
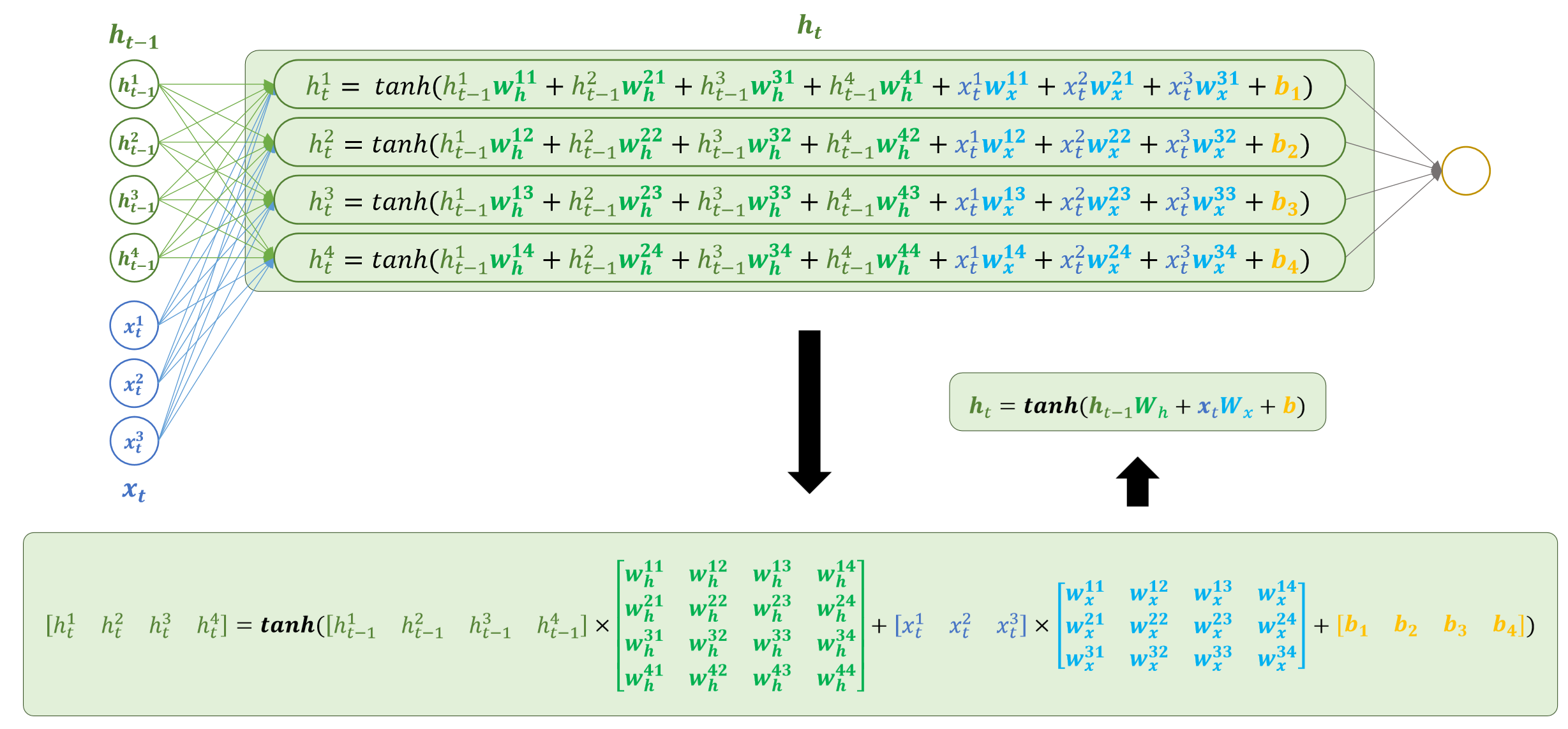
隐藏状态计算公式:
h_t = tanh(x_t · W_x + h_{t-1} · W_h + b)-
x_t
:当前时间步的输入向量(形状为 input_size)
-
h_{t-1}
:上一个时间步的隐藏状态(形状为 hidden_size)
-
W_x
:输入到隐藏的权重矩阵
-
W_h
:隐藏到隐藏的权重矩阵(循环的核心)
-
b
:偏置项
-
tanh
:双曲正切激活函数,输出范围 -1, 1
为什么使用 tanh? tanh 的对称输出范围(关于原点对称)有助于梯度流动,避免激活值偏向同一侧;此外,tanh 的导数比 sigmoid 大(最大值可达 1),一定程度上缓解梯度消失问题。
1.3 时间步展开理解
为了更好地理解 RNN 的信息传递机制,我们可以将循环在时间维度上"展开":
h_1 = tanh(x_1·W_x + h_0·W_h + b)
h_2 = tanh(x_2·W_x + h_1·W_h + b)
h_3 = tanh(x_3·W_x + h_2·W_h + b)
...关键洞察 :RNN 在所有时间步上 共享同一套权重(W_x、W_h 和 b),而不是每个时间步使用独立的权重。这种参数共享使得 RNN 能够处理任意长度的序列,且模型参数量不随序列长度增长,这正是 RNN 的优势所在。
1.4 多层 RNN:从局部模式到抽象语义
为了捕捉更复杂的语言特征,可以将多个 RNN 层按层次堆叠。多层 RNN 的设计核心假设是:
-
底层网络
更容易捕捉局部模式(如词组、短语)
-
高层网络
则能学习更抽象的语义信息(如句子主题或语境)
在结构上,每一层的输出序列会作为下一层的输入序列,最底层 RNN 接收原始输入序列,顶层 RNN 的输出作为最终结果。
1.5 双向 RNN:看到"上下文"
基础 RNN 在每个时间步只输出一个隐藏状态,该状态仅包含来自上文的信息,无法利用当前词之后的下文。这在序列标注任务中是一个明显限制------例如判断"苹果"是一个水果还是公司名称,通常需要依赖下文信息才能准确判断。
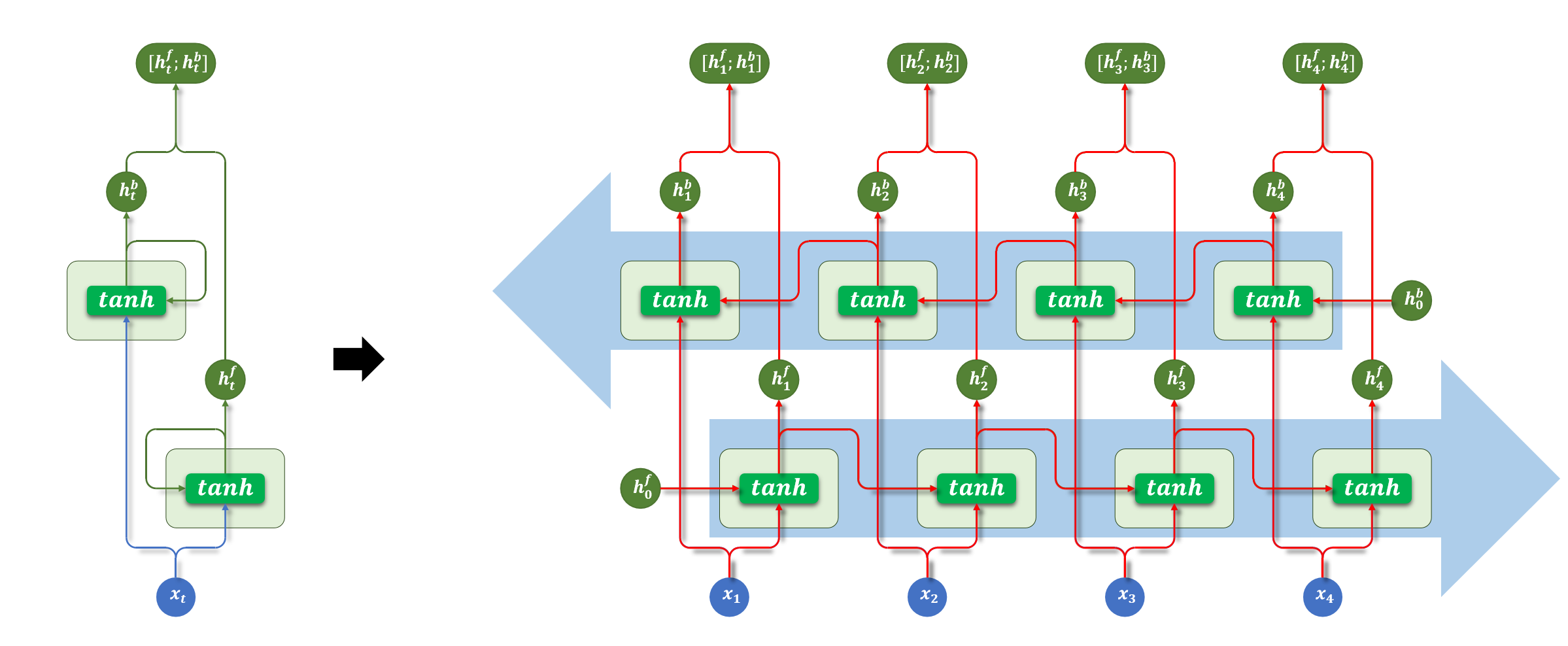
双向 RNN 的解决方案:同时使用两层 RNN:
-
正向 RNN
:按照时间顺序(从前到后)处理序列
-
反向 RNN
:按照逆时间顺序(从后到前)处理序列
每个时间步的输出是正向和反向隐藏状态的组合(通常采用拼接方式)。
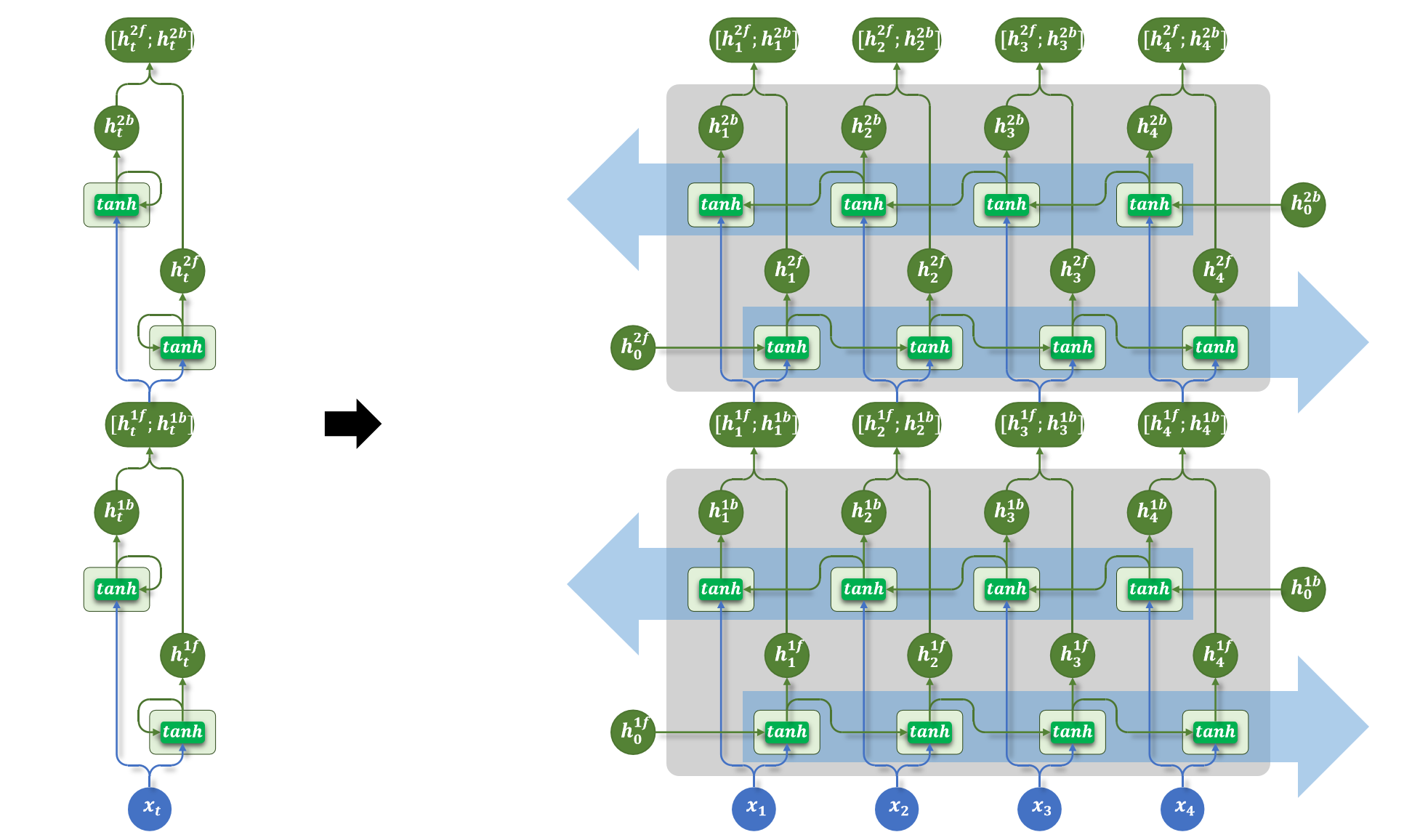
1.6 多层+双向结构
多层结构和双向结构还可组合使用,每层都是一个双向RNN,如下图所示
二、PyTorch RNN API 实战
PyTorch 提供了 torch.nn.RNN 模块用于构建 RNN。我们先通过 API 深入理解其参数和输入输出格式,再进入完整的实战项目。
2.1 核心参数详解
|---------------|-------|----------------------------------------|
| 参数名 | 类型 | 说明 |
| input_size | int | 每个时间步输入特征的维度(词向量维度) |
| hidden_size | int | 隐藏状态的维度 |
| num_layers | int | RNN 层数,默认为 1 |
| nonlinearity | str | 激活函数,'tanh'(默认)或 'relu' |
| bias | bool | 是否使用偏置项,默认 True |
| batch_first | bool | 输入张量是否是 (batch, seq, feature),默认 False |
| dropout | float | 除最后一层外,其余层之间的 dropout 概率 |
| bidirectional | bool | 是否为双向 RNN,默认 False |
2.2 输入输出格式
torch.nn.RNN 的前向传播返回两个值:
output, h_n = rnn(input, h_0)-
input
:输入序列,形状为 (seq_len, batch_size, input_size);若 batch_first=True,则为 (batch_size, seq_len, input_size)
-
h_0
:可选,初始隐藏状态,形状为 (num_layers × num_directions, batch_size, hidden_size)
-
output
:最后一层每个时间步的隐藏状态,形状为 (seq_len, batch_size, num_directions × hidden_size);若 batch_first=True,则为 (batch_size, seq_len, num_directions × hidden_size)
-
h_n
:最后一个时间步的隐藏状态,包含每一层的每个方向,形状为 (num_layers × num_directions, batch_size, hidden_size)
2.3 形状变化可视化
单层单向:
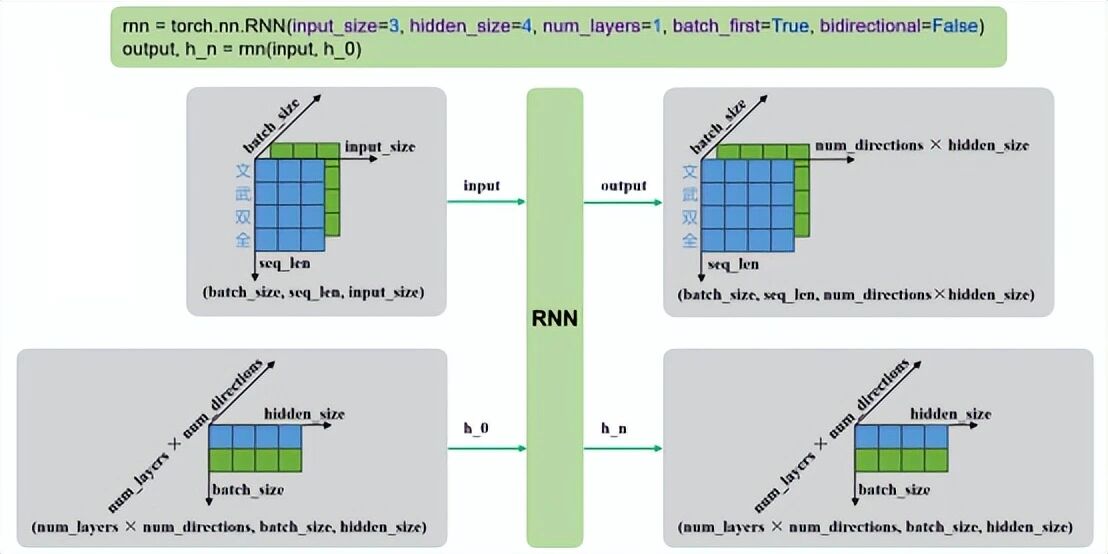
多层单向:
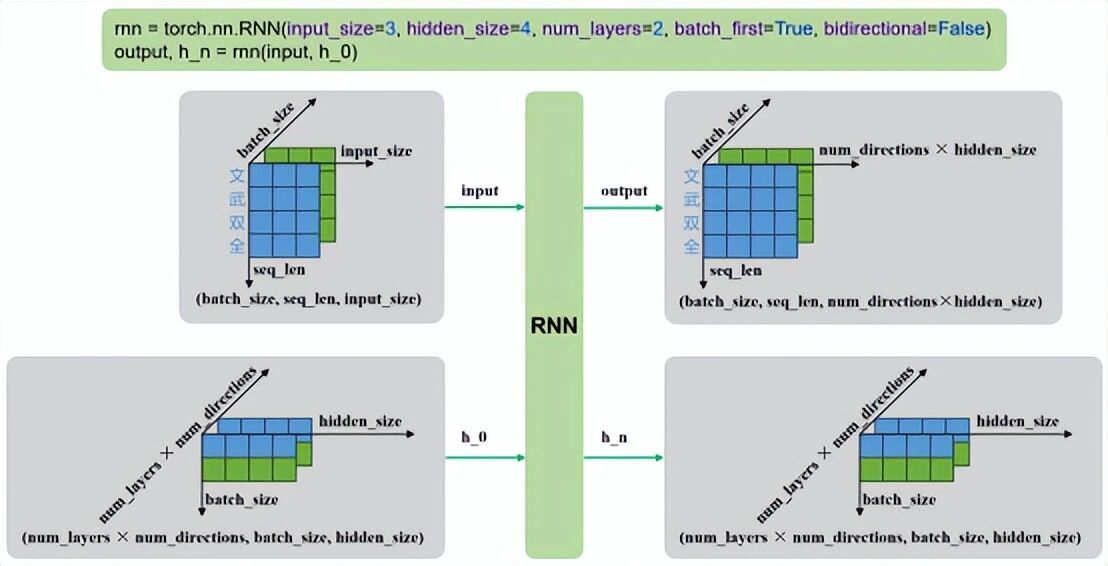
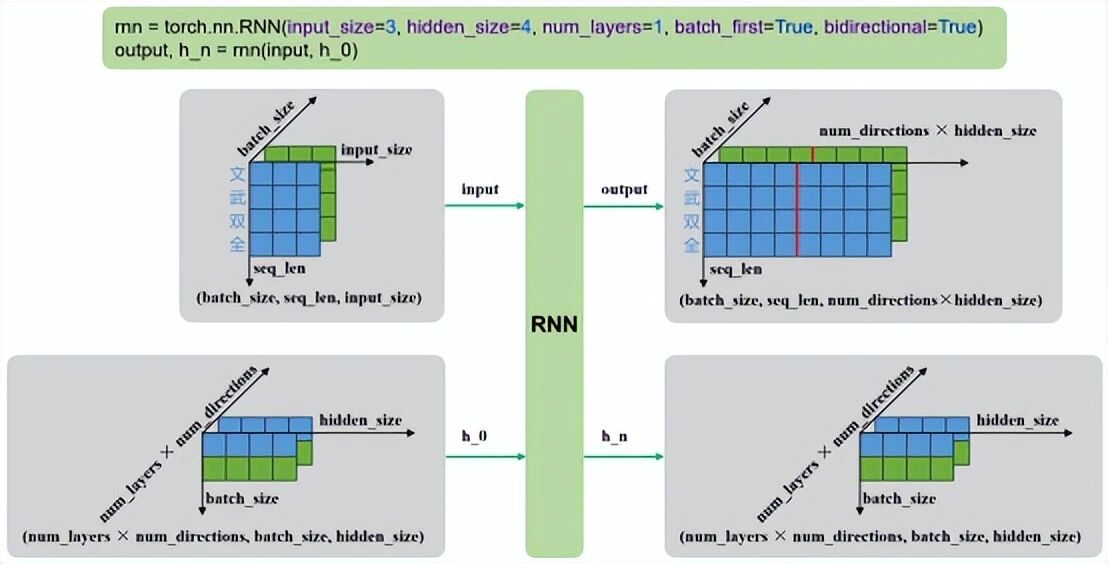
单层双向:
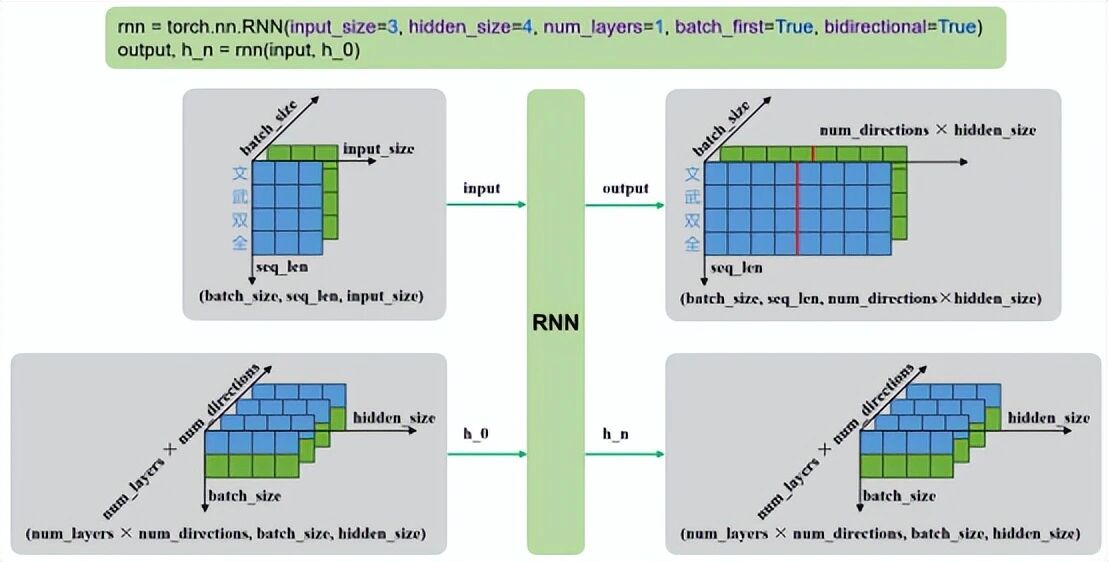
多层双向:
三、完整实战:智能输入法词语联想模型
下面通过一个完整的智能输入法案例,将上述知识串联起来。
3.1 需求说明
根据用户当前已输入的文本内容,预测下一个可能输入的词语,返回概率最高的 5 个候选词供用户选择。例如,输入"自然语言",模型预测 "处理"、"理解"、"的"、"描述"、"生成"。
3.2 数据集处理(preprocess.py)
本任务使用 Hugging Face 上的对话语料库 HundredCV-Chat。原始语料需要经过以下处理:
-
分词
:使用 jieba 分词工具将句子切分为词语序列
-
滑动窗口
:采用滑动窗口方式构建训练样本
-
构造输入输出对
:取窗口内的词语序列作为模型输入,窗口后紧邻的下一个词作为预测目标
-
数据集下载:
https://pan.baidu.com/s/16dszB6-zeUtF_9Inpe0zbg?pwd=5msh
数据预处理
import pandas as pd
import jieba
from sklearn.model_selection import train_test_split # 划分数据集from config import *
构建数据集的函数,传入原始语料和词表 word2id,返回 {'input':[ids], 'target': id}
def build_dataset(sentences, word2id):
# 1. 将所有句子进行分词、id化
sentences_id = [ [ word2id.get(token, 0) for token in jieba.lcut(sentence) ] for sentence in sentences ]# 2. 构建input和target组成的dataset dataset = [] # 字典构成的列表 [{'input':[ids], 'target': id},{}] # 遍历所有句子的id列表 for sentence_id_list in sentences_id: # 遍历每一个id for i in range(len(sentence_id_list) - SEQ_LEN): # 每5个构成一个input,后面的是target input = sentence_id_list[i:i+SEQ_LEN] target = sentence_id_list[i+SEQ_LEN] dataset.append({'input': input, 'target': target}) return datasetdef preprocess():
print("-------开始数据预处理...-------")# 1. 读取JSON文件,得到DataFrame;并做随机抽样 df = pd.read_json(RAW_DATA_DIR / RAW_DATA_FILE, lines=True, orient='records').sample(frac=0.1) # 2. 提取所有对话句子,并做清洗 sentences = [] # 遍历所有组对话 for dialog in df['dialog']: # 遍历本组对话中的每一句,并做处理 for sentence in dialog: sentences.append(sentence.split(':')[1]) print(sentences[0]) print(len(sentences)) # 3. 对原始语料做划分 train_sentences, test_sentences = train_test_split(sentences, test_size=0.2) # 4. 针对训练集分词,构建词表 vocab_set = set() # 利用集合做token去重 for sentence in train_sentences: vocab_set.update(jieba.lcut(sentence)) # 转换成列表(词表,id2word),并处理未登录词 vocab_list = [UNK_TOKEN] + list(vocab_set) word2id = { word : id for id, word in enumerate(vocab_list) } print("词表大小:", len(vocab_list)) # 5. 保存词表到文件 with open(MODEL_DIR/VOCAB_FILE, 'w', encoding='utf-8') as f: f.write('\n'.join(vocab_list)) # 6. 构建数据集 train_dataset = build_dataset(train_sentences, word2id) test_dataset = build_dataset(test_sentences, word2id) # 7. 保存数据集到文件 pd.DataFrame(train_dataset).to_json(PROCESSED_DATA_DIR/TRAIN_DATA_FILE, orient='records', lines=True) pd.DataFrame(test_dataset).to_json(PROCESSED_DATA_DIR/TEST_DATA_FILE, orient='records', lines=True) print("-------数据预处理完成-------")if name == 'main':
preprocess()
3.3 自定义分词器(tokenizer.py)
import jieba
from tqdm import tqdm
jieba.setLogLevel(jieba.logging.WARNING)
class JiebaTokenizer:
"""
基于 jieba 的分词器,用于分词、编码和词表管理。
核心功能:分词 → 构建词表 → 文本编码(token → index) → 解码(index → token)
"""
unk_token = '<unk>' # 未知词占位符
@staticmethod
def tokenize(sentence):
"""对句子进行分词,调用 jieba 进行中文分词"""
return jieba.lcut(sentence)
@classmethod
def build_vocab(cls, sentences, vocab_file):
"""
从句子列表构建词表并保存到文件。
:param sentences: 句子列表(原始文本)
:param vocab_file: 保存词表的文件路径
"""
unique_words = set()
for sentence in tqdm(sentences, desc='分词'):
# 收集所有出现的词语
for word in cls.tokenize(sentence):
unique_words.add(word)
# <unk> 放在首位,便于索引处理
vocab_list = [cls.unk_token] + list(unique_words)
# 保存词表,每行一个词语
with open(vocab_file, 'w', encoding='utf-8') as f:
for word in vocab_list:
f.write(word + '\n')
@classmethod
def from_vocab(cls, vocab_file):
"""从文件加载已构建的词表"""
with open(vocab_file, 'r', encoding='utf-8') as f:
vocab_list = [line.strip() for line in f.readlines()]
return cls(vocab_list)
def __init__(self, vocab_list):
self.vocab_list = vocab_list
self.vocab_size = len(vocab_list)
# 建立词 → 索引 和 索引 → 词 的双向映射
self.word2index = {word: idx for idx, word in enumerate(vocab_list)}
self.index2word = {idx: word for idx, word in enumerate(vocab_list)}
self.unk_token_index = self.word2index[self.unk_token]
def encode(self, sentence):
"""
将句子编码为索引列表。
未知词自动映射到 <unk> 索引。
"""
tokens = self.tokenize(sentence)
return [self.word2index.get(token, self.unk_token_index) for token in tokens]3.4 自定义数据集(dataset.py)
import torch
from torch.utils.data import Dataset, DataLoader
import pandas as pd
import config
class InputMethodDataset(Dataset):
"""
输入法数据集类,用于加载 JSONL 格式的预处理数据并生成 PyTorch 张量。
数据文件格式:每行为 {"input": [词索引列表], "target": 目标词索引}
"""
def __init__(self, file_path):
# pandas 读取 JSONL 文件,每行是一个 JSON 对象
self.data = pd.read_json(file_path, lines=True).to_dict(orient='records')
def __len__(self):
return len(self.data)
def __getitem__(self, index):
# 返回输入张量和目标张量,类型为 torch.long(用于索引嵌入)
input_tensor = torch.tensor(self.data[index]['input'], dtype=torch.long)
target_tensor = torch.tensor(self.data[index]['target'], dtype=torch.long)
return input_tensor, target_tensor
def get_dataloader(train=True):
"""获取 DataLoader,支持训练集和测试集的自动切换"""
file_name = config.TRAIN_DATA_FILE if train else config.TEST_DATA_FILE
dataset = InputMethodDataset(config.PROCESSED_DATA_DIR / file_name)
return DataLoader(dataset, batch_size=config.BATCH_SIZE, shuffle=train)3.5 模型定义(model.py)
import torch
from torch import nn
import config
class InputMethodModel(nn.Module):
"""
输入法预测模型,基于 RNN 的序列模型。
模型结构:Embedding → RNN → Linear
"""
def __init__(self, vocab_size):
super().__init__()
# 嵌入层:将 token 索引(0~vocab_size-1)映射为稠密向量
# 输入: (batch_size, seq_len) → 输出: (batch_size, seq_len, embedding_dim)
self.embedding = nn.Embedding(
num_embeddings=vocab_size,
embedding_dim=config.EMBEDDING_DIM
)
# RNN 层:处理序列数据,提取上下文特征
# batch_first=True 表示输入形状为 (batch_size, seq_len, input_size)
self.rnn = nn.RNN(
input_size=config.EMBEDDING_DIM,
hidden_size=config.HIDDEN_SIZE,
batch_first=True
)
# 全连接层:将 RNN 最后一个时间步的隐藏状态映射到词表大小的概率分布
self.linear = nn.Linear(
in_features=config.HIDDEN_SIZE,
out_features=vocab_size
)
def forward(self, x):
"""
前向传播。
:param x: 输入张量,形状 (batch_size, seq_len),每个元素是词索引
:return: 模型输出,形状 (batch_size, vocab_size),每个样本对应词表上的概率分布
"""
# 1. 嵌入层:索引 → 词向量
embed = self.embedding(x) # (batch_size, seq_len, embedding_dim)
# 2. RNN 处理:提取序列的上下文特征
# output: (batch_size, seq_len, hidden_size) --- 每个时间步的隐藏状态
# _: 最后一个时间步的隐藏状态(本例中未使用)
output, _ = self.rnn(embed) # (batch_size, seq_len, hidden_size)
# 3. 取最后一个时间步的输出进行分类
# 为什么取最后一个时间步?因为对于"下一个词预测"任务,最后一个时间步的隐藏状态
# 已经编码了整个输入序列的信息,最适合用于预测下一个词。
result = self.linear(output[:, -1, :]) # (batch_size, vocab_size)
return result模型结构示意图:
输入 (batch_size, seq_len)
│
▼
[Embedding] 词索引 → 词向量
│
▼ (batch_size, seq_len, embedding_dim)
[RNN] 处理序列上下文
│
▼ (batch_size, seq_len, hidden_size)
取最后一个时间步 output[:, -1, :]
│
▼ (batch_size, hidden_size)
[Linear] 映射到词表大小
│
▼ (batch_size, vocab_size)
Softmax(CrossEntropyLoss 内置)3.6 训练流程(train.py)
import time
import torch
from torch import nn
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm
from dataset import get_dataloader
from model import InputMethodModel
from tokenizer import JiebaTokenizer
import config
def train_one_epoch(model, dataloader, loss_function, optimizer, device):
"""
训练一个 epoch。
"""
total_loss = 0
model.train() # 设置为训练模式(启用 dropout、BatchNorm 等)
for inputs, targets in tqdm(dataloader, desc='训练'):
# 将数据移到 GPU/CPU
inputs, targets = inputs.to(device), targets.to(device)
# 清零梯度(避免累加)
optimizer.zero_grad()
# 前向传播
outputs = model(inputs) # (batch_size, vocab_size)
# 计算损失:CrossEntropyLoss 自动执行 Softmax + NLLLoss
loss = loss_function(outputs, targets)
# 反向传播
loss.backward()
# 更新参数
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss / len(dataloader)
return avg_loss
def train():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print('设备:', device)
# 获取 DataLoader
dataloader = get_dataloader(train=True)
# 加载分词器和模型
tokenizer = JiebaTokenizer.from_vocab(config.MODEL_DIR / 'vocab.txt')
model = InputMethodModel(vocab_size=tokenizer.vocab_size).to(device)
# 损失函数:交叉熵损失,适用于多分类任务
loss_function = nn.CrossEntropyLoss()
# 优化器:Adam 结合了 Momentum 和 RMSProp,自适应学习率
optimizer = torch.optim.Adam(model.parameters(), lr=config.LEARNING_RATE)
# TensorBoard 日志记录
writer = SummaryWriter(log_dir=config.LOG_DIR / time.strftime('%Y-%m-%d_%H-%M-%S'))
best_loss = float('inf')
for epoch in range(1, config.EPOCHS + 1):
print(f'========== Epoch: {epoch} ===========')
avg_loss = train_one_epoch(model, dataloader, loss_function, optimizer, device)
print(f'Loss: {avg_loss:.4f}')
writer.add_scalar('Loss/train', avg_loss, epoch)
# 保存最优模型(基于 loss 判断)
if avg_loss < best_loss:
best_loss = avg_loss
torch.save(model.state_dict(), config.MODELS_DIR / 'model.pt')
print('模型保存成功!')
if __name__ == '__main__':
train()3.7 预测实现(predict.py)
import torch
from model import InputMethodModel
from tokenizer import JiebaTokenizer
import config
def predict_batch(input_tensor, model):
"""
对一个 batch 的输入进行预测,返回每个样本 top-5 的索引列表。
"""
model.eval() # 设置为评估模式(禁用 dropout)
with torch.no_grad(): # 禁用梯度计算,节省内存
output = model(input_tensor) # (batch_size, vocab_size)
# 取概率最高的 5 个索引(torch.topk 返回 (values, indices))
predict_ids = torch.topk(output, k=5, dim=-1).indices # (batch_size, 5)
return predict_ids.tolist()
def predict(text, model, tokenizer, device):
"""对单条文本进行预测,返回 top-5 词汇列表"""
# 编码文本为 token 索引列表
input_ids = tokenizer.encode(text)
# 转换为张量并增加 batch 维度
input_tensor = torch.tensor([input_ids], dtype=torch.long, device=device)
# 获取 top-5 索引
top_k_ids = predict_batch(input_tensor, model)[0]
# 索引映射回词语
return [tokenizer.index2word[idx] for idx in top_k_ids]
def run_predict():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载分词器和模型
tokenizer = JiebaTokenizer.from_vocab(config.MODEL_DIR / 'vocab.txt')
model = InputMethodModel(vocab_size=tokenizer.vocab_size).to(device)
model.load_state_dict(torch.load(config.MODELS_DIR / 'model.pt', map_location=device))
print('请输入词语:(输入 q 或者 quit 退出系统)')
text = ''
while True:
user_input = input('> ')
if user_input in ['q', 'quit']:
print('感谢使用!')
break
if not user_input:
print('请输入词语!')
continue
text += user_input
print('历史输入:', text)
topk_tokens = predict(text, model, tokenizer, device)
print('预测结果:', topk_tokens)
if __name__ == '__main__':
run_predict()交互示例:
请输入词语:(输入 q 或者 quit 退出系统)
> 我们
历史输入: 我们
预测结果: ['可以', '团队', '也', '都', '公司']
> 团队
历史输入: 我们团队
预测结果: ['的', '合作', '也', '正在', '开发']
> 正在
历史输入: 我们团队正在
预测结果: ['开发', '研究', '研发', '优化', '做']
> 研发
历史输入: 我们团队正在研发
预测结果: ['一个', '一款', '下一代', '智能', '智能家居']3.8 模型评估(evaluate.py)
import torch
from tqdm import tqdm
from tokenizer import JiebaTokenizer
import config
from model import InputMethodModel
from dataset import get_dataloader
from predict import predict_batch
def evaluate(model, dataloader, device):
"""
评估模型,返回 Top-1 准确率和 Top-5 准确率。
"""
total_count = 0
top1_correct = 0
topk_correct = 0
model.eval()
for inputs, targets in tqdm(dataloader, desc='评估'):
inputs = inputs.to(device)
targets = targets.tolist() # 转换为 Python 列表
predicted_ids = predict_batch(inputs, model)
for pred, target in zip(predicted_ids, targets):
if pred[0] == target: # 预测的第一候选是否正确
top1_correct += 1
if target in pred: # 目标是否在 top-5 内
topk_correct += 1
total_count += 1
top1_acc = top1_correct / total_count
topk_acc = topk_correct / total_count
return top1_acc, topk_acc
def run_evaluate():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
tokenizer = JiebaTokenizer.from_vocab(config.MODEL_DIR / 'vocab.txt')
model = InputMethodModel(vocab_size=tokenizer.vocab_size).to(device)
model.load_state_dict(torch.load(config.MODELS_DIR / 'model.pt', map_location=device))
dataloader = get_dataloader(train=False)
top1_acc, topk_acc = evaluate(model, dataloader, device)
print("====== 评估结果 =======")
print(f"Top-1 准确率: {top1_acc:.4f}")
print(f"Top-5 准确率: {topk_acc:.4f}")
if __name__ == '__main__':
run_evaluate()输出结果:
评估: 100%|██████████| 1332/1332 [00:01<00:00, 1270.68it/s]
====== 评估结果 =======
Top-1 准确率: 0.2958
Top-5 准确率: 0.53433.9 配置文件(config.py)
from pathlib import Path
# 项目根目录
ROOT_DIR = Path(__file__).parent
# 数据路径
RAW_DATA_DIR = ROOT_DIR / 'data' / 'raw'
PROCESSED_DATA_DIR = ROOT_DIR / 'data' / 'processed'
# 模型和日志路径
MODELS_DIR = ROOT_DIR / 'models'
LOG_DIR = ROOT_DIR / 'logs'
# 训练参数
SEQ_LEN = 5 # 输入序列长度
BATCH_SIZE = 64 # 批大小
EMBEDDING_DIM = 128 # 词嵌入维度
HIDDEN_SIZE = 256 # RNN 隐藏层维度
LEARNING_RATE = 0.001 # 学习率
EPOCHS = 10 # 训练轮数3.10 运行说明与项目结构
完整项目结构:
input_method/
├── config.py # 配置文件
├── tokenizer.py # 分词器和词表管理
├── dataset.py # 数据集和 DataLoader
├── model.py # RNN 模型定义
├── train.py # 训练脚本
├── predict.py # 预测交互脚本
├── preprocess.py # 数据集处理脚本
├── evaluate.py # 评估脚本
├── data/
│ ├── raw/ # 原始数据
│ └── processed/ # 预处理后的数据(含 vocab.txt)
├── models/ # 保存训练好的模型
└── logs/ # TensorBoard 日志运行步骤:
-
数据集处理
:python preprocess.py
-
构建词表
(运行一次即可):python tokenizer.py --build
-
预处理数据
:运行数据预处理脚本生成 indexed_train.json 和 indexed_test.json
-
训练模型
:python train.py
-
评估模型
:python evaluate.py
-
交互预测
:python predict.py
3.11 完整代码下载(包含数据集)
**代码下载地址:**https://pan.baidu.com/s/1QoffF4qUMZVcU2_MqH5YHg?pwd=395d
3.12 训练技巧与超参数调优
在实际训练中,以下技巧有助于提升模型性能:
-
学习率调度
:使用 torch.optim.lr_scheduler 进行学习率衰减(如 StepLR、ReduceLROnPlateau),帮助模型更好地收敛
-
梯度裁剪(Gradient Clipping)
:在 loss.backward() 后调用 torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0),有效防止梯度爆炸
-
早停(Early Stopping)
:当验证集 loss 连续多个 epoch 不再下降时提前终止训练,防止过拟合
-
Dropout 调节
:适当增加 dropout 率(如 0.3~0.5)提高泛化能力
-
词表大小控制
:根据数据集规模合理设置词表大小(如 2 万~5 万),低频词归入 <unk> 处理
四、RNN 的核心挑战:梯度消失与梯度爆炸
尽管 RNN 在序列建模中展现了强大的能力,但它在处理长序列时面临严重的长期依赖建模困难。以下从数学角度深入剖析这一问题的成因。
4.1 问题描述
在训练 RNN 时,采用的是 时间反向传播(BPTT) 方法。在反向传播过程中,梯度需要在每个时间步上不断链式传递。当输入序列较长时,早期时间步的梯度经过多次链式乘法后会指数级衰减或增长,导致模型难以学习长期依赖。
4.2 数学推导
根据计算图,总梯度可以表示为:
∂l/∂W_h = ∂l/∂h_t·∂h_t/∂W_h + ∂l/∂h_{t-1}·∂h_{t-1}/∂W_h + ... + ∂l/∂h_1·∂h_1/∂W_h展开早期时间步的某一条路径:
∂l/∂h_1·∂h_1/∂W_h = ∂l/∂h_t · (∂h_t/∂h_{t-1}) · (∂h_{t-1}/∂h_{t-2}) · ... · (∂h_2/∂h_1) · ∂h_1/∂W_h由于 h_t = tanh(x_t·W_x + h_{t-1}·W_h + b),令 u_t = x_t·W_x + h_{t-1}·W_h + b,则:
∂h_t/∂h_{t-1} = ∂h_t/∂u_t · ∂u_t/∂h_{t-1} = tanh'(u_t) · W_h因此,早期路径的完整表达式为:
∂l/∂h_1·∂h_1/∂W_h = ∂l/∂h_t · [tanh'(u_t)·W_h] · [tanh'(u_{t-1})·W_h] · ... · [tanh'(u_2)·W_h] · ∂h_1/∂W_h这里出现了很多 tanh'(u_t)·W_h 的连乘,其中 tanh'(u_t) 的值域是 0, 1。
4.3 梯度消失
若 W_h 也小于 1,那么经过多次连乘后,早期路径的梯度值会指数级衰减并迅速接近 0。由于早期时间步的梯度几乎为 0,总梯度 ∂l/∂W_h 几乎只受最近时间步的影响------这意味着模型只能学到短期依赖,而无法有效利用早期的上下文信息。
以语言模型为例,当需要根据句首信息预测句尾单词时,梯度消失会使模型无法有效利用早期的上下文信息。
4.4 梯度爆炸
相反,若 W_h 大到使 tanh'(u_t)·W_h > 1,那么经过多次连乘后,早期路径的梯度会指数级增长。梯度爆炸会导致参数更新极不稳定,甚至使训练完全失败------极端情况下,过大的梯度会使权重值超出计算机的数值表示范围,出现 NaN(非数字)错误。
4.5 解决方案演进
梯度裁剪:通过设置梯度上限来控制爆炸问题。例如,若梯度的 L2 范数超过阈值,则按比例缩放梯度。这是一种工程上的补救措施,但不能从根本上解决网络结构本身的问题。
LSTM / GRU :通过引入门控机制(遗忘门、输入门、输出门),使用加法更新而非连乘,给出近似常数误差流,能够较好地保存长期信息,从而缓解梯度消失问题。
门控机制的核心优势:传统 RNN 的梯度传播涉及矩阵与激活导数的连乘,而 LSTM 在细胞状态路径上主要是门值的元素级乘法,这些门可以通过学习设置为接近 1,从而保留长期梯度。在实践中,常把遗忘门的偏置初始化为正值(如 1 或 2),使模型初始时倾向于"记住"信息,有助于长期记忆的学习。
Transformer:通过自注意力机制彻底革新序列建模范式,以并行计算和直接访问任意位置信息的能力,超越了 RNN 的串行处理限制。
五、总结与展望
5.1 学习价值
尽管 RNN 已在许多场景中被 Transformer 取代,但它依然具有重要的学习价值:
-
基础概念建立
:RNN 的"循环建模上下文"思想是理解 LSTM、GRU 等改进模型的基础
-
计算效率对比
:RNN 推理时具有 O(1) 的常数级显存占用,而 Transformer 的注意力机制随序列长度呈 O(N²) 增长
-
架构成熟度
:RNN 及其变体在时序预测、资源受限场景中仍有广泛应用价值
-
工业级应用
:在实际生产环境中,RNN 因其轻量级和低延迟特性,在手机输入法、嵌入式设备等场景中仍被广泛使用
5.2 未来趋势
有意思的是,RNN 的思想正在以新的形式回归。为了突破 Transformer O(N²) 的计算瓶颈,业界正朝着混合架构方向演进------以 Olmo Hybrid 为例,通过在 Transformer 中融入线性 RNN 层,在 MMLU 基准上达到相同精度仅需 49% 的训练数据,实现了约 2 倍的数据效率提升。此外,Mamba、RetNet 等新兴架构将 RNN 的低推理成本优势与 Transformer 的并行训练优势相结合,成为下一代大模型架构的重要探索方向。
核心启示 :理解 RNN,不仅仅是为了掌握一项历史技术,更是为了理解序列建模的本质------信息如何在时间维度上传递与衰减。这个底层问题至今仍是所有序列模型面临的挑战,无论是最早的 RNN、后来的 LSTM/GRU、还是当下的 Transformer 和 SSM,都在以不同的方式回答同一个问题:如何在计算效率和建模能力之间找到最佳平衡?