前言
在关于数据库的知识内容中,InnoDB存储引擎默认采用B+树作为索引结构,这是为什么,B+树与B树之间的差异是什么,
关于B树
B树最大的一个核心特点就是:不再限制一个节点只能有两个子节点,而是允许M个子节点(M>2),从而降低树的高度 。
B树查询过程 :
我们以一棵三阶B树来模拟查询过程:
假设我们在上图一棵 3 阶的 B 树中要查找的索引值是 9 的记录那么步骤可以分为以下几步:
- 与根节点的索引(4,8)进行比较,9 大于 8,那么往右边的子节点走;
- 然后该子节点的索引为(10,12),因为 9 小于 10,所以会往该节点的左边子节点走;
- 走到索引为9的节点,然后我们找到了索引值 9 的节点。
我们可以看到:3阶B树查询叶子节点数据时,若树高为3,查询过程会产生3次磁盘I/O操作。
相同节点数量下,平衡二叉树高度更高,会导致磁盘I/O操作增多;因此B树在数据查询时效率更高。
那我们为什么不选择用B树作为存储索引呢?
1.因为B树每个节点都包含了数据(索引+记录),问题就处在了记录上。当用户的记录数据大小远远超过了索引数据,这就导致了需要花费更多磁盘I/O操作次数来读到有用的索引数据。
2.并且,再我们查询数据的同时,非查询数据的记录数据也会从磁盘加载到内存当中,单这些记录我们不需要,这就导致了内存资源的浪费 。
3.用B树来做范围查询时,需要用到中序遍历,这回涉及多个节点的磁盘I/O问题,道中整体速度下降。
B+树
B+树是对B树进行的升级
结构如下图:
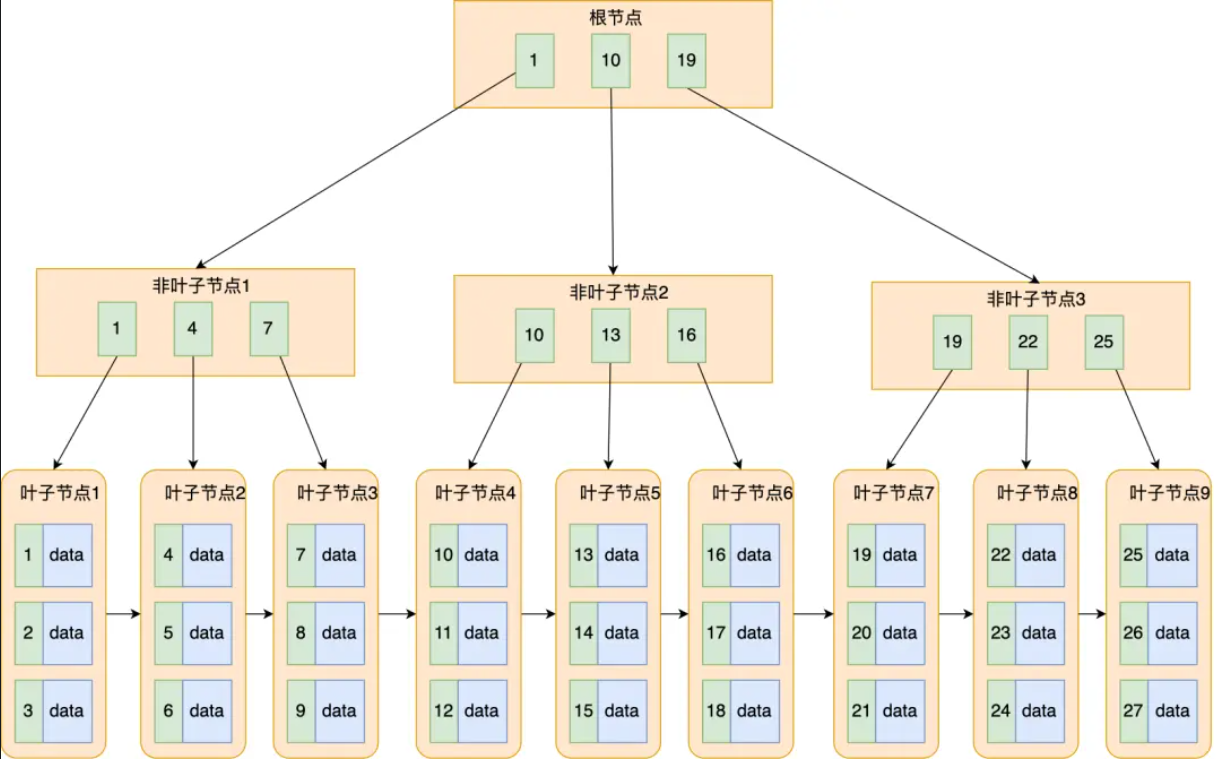
InnoDB使用B+树的一些特点:
- B+树的叶子节点之间是使用双向链表进行连接,好处是既能向右遍历,也能向左遍历。
- B+树节点内容是数据页,数据页里存放了用户的记录以及各种信息,每个数据页默认大小是16kb。
B+树与B树的区别(面试回答)
B树也是多叉平衡树,和B+树最大的区别时数据存储位置:
- B树每个节点都存储完整信息,B+树只有叶子节点存储树,非叶子节点存储key和指针。意味着B+树的非叶子节点更小,一页能装更多索引项,树更矮
- B+树叶子节点用链表串起来,范围查找直接顺序扫描。B树做范围查找要不断回到上层节点再往下查找,IO次数多。
- B树有可能再非叶子节点就找到数据直接返回,查询时间不稳定。B+树必须查到叶子节点,时间稳定可预期。
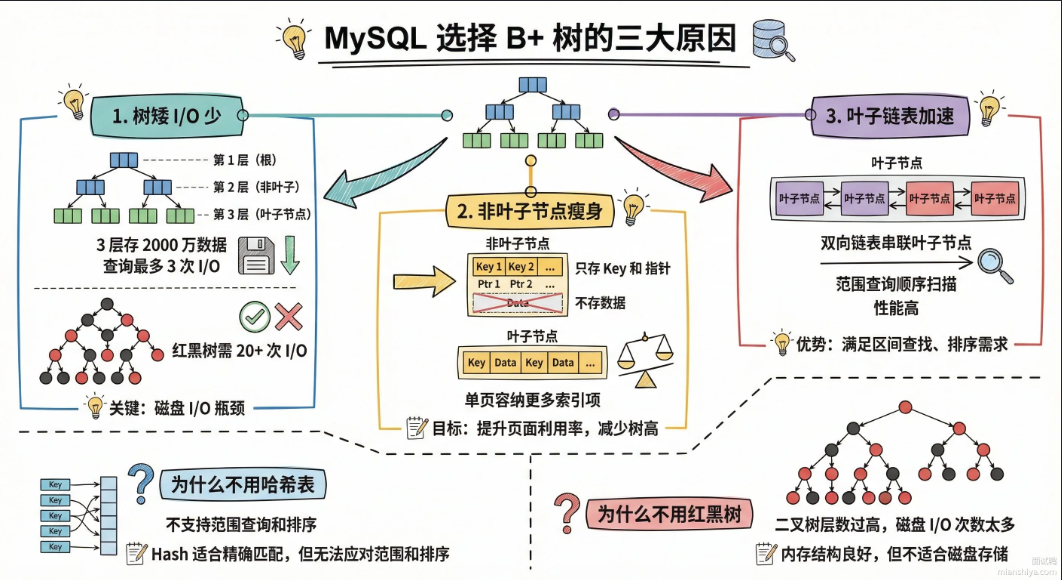
总结
回到开头的问题,为什么InnoDB存储索引使用B+树呢:
核心原因就一个:磁盘IO次数最少 。数据库的数据存在磁盘上,磁盘随机读写比内存慢10万倍。
B+树的三点特性:
- 树矮。B+树是多叉树,一个节点能存几百上千给key。3层的B+树就能存两千多万跳数据,查任何一条最多3次磁盘IO。红黑树是二叉树,存同样的数据量要20多层。
- 非叶子节点只存key和指针,不存数据。一个16kb的页能塞进更多索引项,内存里能缓存更多索引,命中率高,磁盘访问少。
- 叶子节点用双向链表串起来。范围查询时,定位到起点后顺着链表往后扫就行,不用再会根节点重新查找,顺序IO比随机IO快太多。