上一章节学习了卷积神经网络 的基本原理,本章开始现代卷积神经网络架构的学习,许多现代卷积神经网络的研究都是建立在这一章的基础上的。深度神经网络------将神经网络堆叠在一起,但由于不同的网络架构和超参数选择,这些神经网络的性能会发生很大变化。
首先来看深度学习之前的网络长什么样。
1 深度学习之前的网络
1.1 机器学习
在2000年时,最火的机器学习是核方法(核函数)。
1.1.1 核函数
🍄 在机器学习和数学分析中,核函数(Kernel Function) 是一种极其巧妙的机制。它允许我们在不需要显式进行高维空间变换的情况下,计算两个数据点在++"高维特征空间"++ 中的相似度。
简单来说,核函数是处理非线性可分数据的利器。
1) 核心思想:空间提升(The Kernel Trick)
假设你有一堆散落在桌面上的红蓝豆子,如果它们混杂在一起,你无法用一根直尺(线性分类器)将它们分开。但如果你把桌子一拍,让豆子飞向空中,你可能就能在空中插进一张纸(超平面),完美地把红蓝豆子隔开。
-
低维空间:原始数据,往往是线性不可分的。
-
高维空间 :通过某种映射
,将数据投影到更高维度的空间,使其变得线性可分。
-
核函数的妙处 :直接计算高维映射后的内积,即
2)常见的核函数类型
不同的核函数决定了数据被投影到什么样的"虚拟空间":
| 核函数名称 | 公式 | 特点与应用 |
| 线性核 (Linear) | | 不做映射,直接计算。适用于特征维度极高(如文本分类)的情况。 |
| 多项式核 (Polynomial) | | 适合处理具有阶数关系的特征组合。 |
| 高斯核 (RBF/Gaussian) | | 最常用。它能将数据映射到无限维空间,理论上能拟合任何分布。 |
| Sigmoid 核 | 行为类似于神经网络中的激活函数。 |
|---|
3) 核函数的作用
-
避开"维度灾难":如果直接把数据映射到万亿维空间,计算量会爆炸。核函数通过简单的代数运算绕过了这一点。
-
通用性强 :只要一个函数满足🔅 Mercer 定理(正定性),它就可以作为核函数。这意味着我们可以针对特定领域(如蛋白质序列、图论、文本)设计专门的核。
-
非线性能力:让简单的线性模型(如 SVM)拥有了处理复杂非线性问题的能力。
4)应用场景
🎄核函数最著名的应用是在 支持向量机 (SVM) 中,但它也广泛用于:
-
核主成分分析 (Kernel PCA):用于非线性降维。
-
高斯过程 (Gaussian Processes):用于回归和不确定性估计。
-
克里金插值 (Kriging):地质学中的空间数据内插。
1.1.2 SVM 与核函数的关键特性
支持向量机(Support Vector Machine, SVM)是机器学习领域最经典、理论最完备的算法之一。它的核心思想可以用一句话概括:寻找一个能够最宽阔地分隔不同类别样本的超平面。
(机器学习部分的内容,主包自己比较忘记了,之后有时间做一期学习笔记吧)
**A. 特征提取 (Feature Extraction):**在传统机器学习中,特征工程极其繁琐。SVM 通过核函数,可以自动处理复杂的特征转换。它能将低维空间中线性不可分的数据,映射到高维(甚至无限维)的特征空间,从而在更高维度找到一个线性超平面进行分割。
B. 选择核函数来计算相似度 :核函数的本质是计算两个向量在映射后的特征空间中的内积( 内积在数学上代表了两个样本之间的相似度)
C. 凸优化问题 (Convex Optimization):SVM 的目标函数是一个二次规划(QP)问题。
- 优势 :与神经网络不同,凸优化问题具有全局最优解。这意味着只要参数确定,训练出的模型就是在该条件下的理论最优值,不会陷入局部最优。
总之,SVM 是一套理论严谨(漂亮的定理)、计算高效(凸优化)、处理非线性能力强(核函数相似度计算)的机器学习方案。 尽管现在大模型非常火热,但在处理结构化小样本数据、或者对模型解释性有极高要求的场景下,核方法依然是研究者和工程师手中的重要工具。
1.2 几何学
早期的CNN主要用于图像相关任务,属于计算机视觉领域。在2000年时期,计算机视觉关注结合几何学完成任务,核心思想 是:从多视角图像中提取特征,通过描述其几何信息(比如多个相机对于同一物体的相对位置估计)恢复其几何结构。
可以在模型中建模引入(非)凸优化的函数,从而可能得到一些漂亮的定理,不错的效果。
1.3 特征工程
在计算机视觉领域,早期更重要的是特征工程。若直接把图像的像素信息丢到模型当中,往往效果很差,需要针对任务做特征处理才会得到比较好的结果。
在机器学习中,特征工程(Feature Engineering) 有一句名言:"数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。"
简单来说,特征工程就是利用领域知识从原始数据中提取特征,并将这些特征转化为能让模型更好理解的格式的过程。
在特征工程和计算机视觉领域,SIFT 和 SURF 是两座绕不开的里程碑。它们属于局部特征描述子(Local Feature Descriptors) ,核心任务是在图像中寻找那些*"即便图像旋转、放大、缩小或亮度改变也能被识别出来"*的关键点。
1.4 Hardware
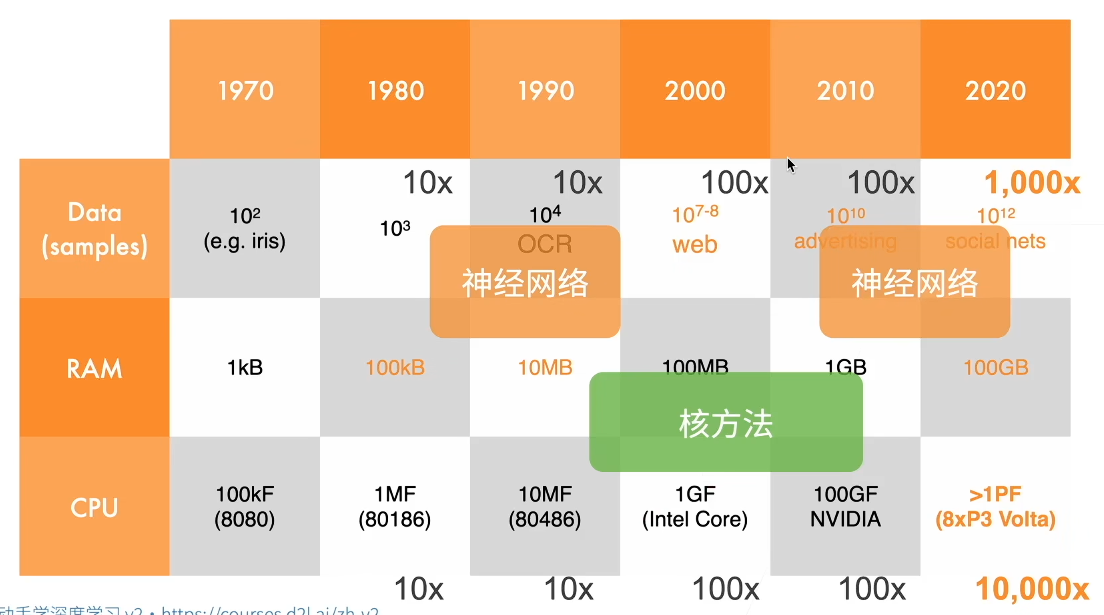
下面的这张图非常直观地展示了硬件计算能力、数据规模与机器学习算法流行趋势之间的演进关系。
从 1970 年到 2020 年:数据量增长了 100 亿倍;RAM增长了1亿倍;算力增长了 10 万倍。
- 在80-90年代,当时的算力(10MF)和内存(10MB)刚好能支撑小型卷积神经网络处理低分辨率图像;
- 到了2000 年代初,数据量增长较快(Web 时代),但内存和算力还不足以训练深层神经网络。核方法(如 SVM)具有严谨的数学理论,且在中小规模数据集 上表现极佳,计算效率在当时的硬件上更具优势;
- 2012 年 AlexNet 之后,GPU(图中的 NVIDIA 100GF)开始大规模应用。当数据量达到
🐼技术流派的更迭不仅仅是算法优劣的竞争,本质上是算法对硬件利用效率的博弈。 核方法在资源有限时更优雅,而神经网络在资源充足时更强大。
目前的深度学习本质上是**"大数据+大算力**"的堆叠。
本章学习的每一个模型都曾一度占据主导地位,其中许多模型都是ImageNet竞赛的优胜者。
2 深度学习网络 AlexNet
2.1 ImageNet 了解
ImageNet是计算机视觉(Computer Vision)历史上最具影响力的项目之一,是推动现代深度学习爆发式发展的核心燃料。ImageNet 是由斯坦福大学教授李飞飞及其团队在2009年推出的一个大型可视化数据库,其设计初衷是模拟人类认知世界的方式------通过海量的数据来学习。
虽然ImageNet数据库非常庞大,但人们提它时,通常是指其衍生的ILSVRC(ImageNet Large Scale Visual Recognition Challenge)比赛,主要包括图像分类、目标检测 和 图像分割任务。
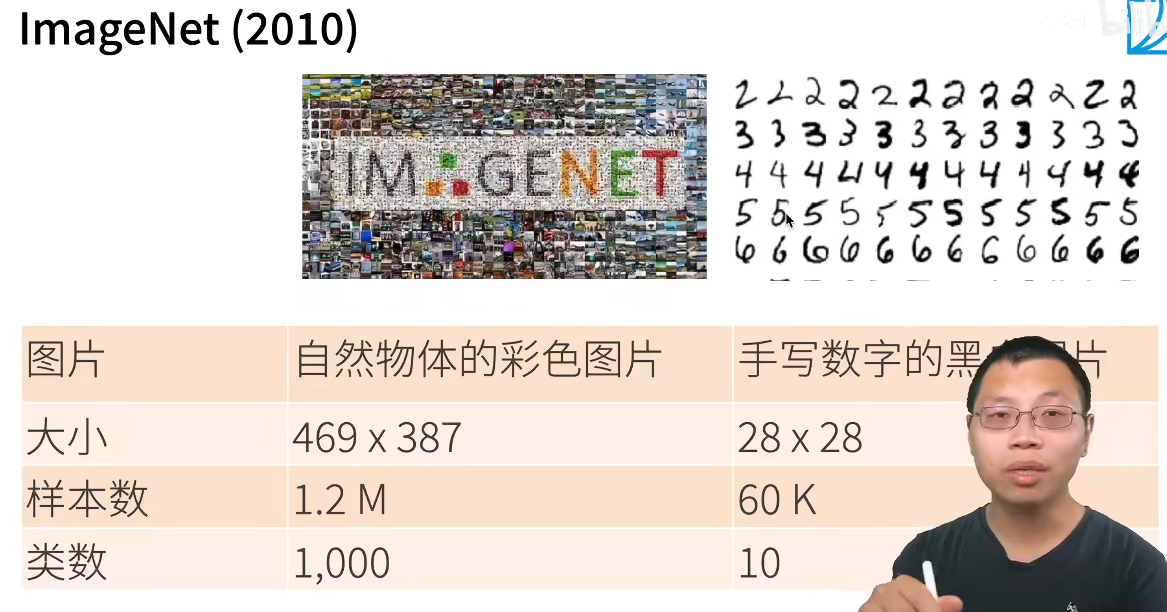
IamgeNet的出现引发了三次重大变革:
- 算法的突破:在2012年的比赛中,☀️AlexNet以绝对优势夺冠,这标志着CNN正式统治了计算机视觉领域,开启这一轮深度学习的热潮,因此2012年也成为深度学习元年。
- **算力的证明:**训练如此庞大的数据集需要极高的计算能力,直接推动了GPU在AI领域的应用。
- 范式的转移:在ImageNet之前,学界普遍认为"算法"最重要。而ImageNet证明了海量、高质量的数据与复杂的模型同等重要。
| 年份 | 冠军模型 | Top-5 错误率 | 备注 |
|---|---|---|---|
| 2010 | Lin et al. | 28.2% | 传统机器学习方法 |
| 2012 | AlexNet | 16.4% | 深度学习元年 |
| 2014 | VGG / GoogLeNet | 6.7% | 网络深度大幅增加 |
| 2015 | ResNet | 3.5% | 超越人类识别水平 (人类约 5.1%) |
2.2 AlexNet
1) 关键技术
AlexNet 的成功不仅仅是因为网络变"深"了,更重要的是它引入了多项关键技术,解决了深层网络训练难、过拟合以及计算量大的问题。
下面是关键技术:
1) 激活函数:Sigmoid→ReLU
++解决了梯度消失问题++,使得网络收敛速度比使用饱和激活函数(如 Sigmoid)快了约 6 倍。
2) 局部响应归一化 (LRN)虽然现在的网络更多使用 Batch Normalization,但 AlexNet 当时提出了 LRN (Local Response Normalization)。它模拟了生物神经元的"侧抑制"机制,++对局部神经元的活动进行竞争++,从而增强了模型的泛化能力。
3) 数据增强 (Data Augmentation)
为了防止过拟合,AlexNet 采用了两种数据增强方式:
随机裁剪与翻转 :将
颜色抖动:通过 PCA(主成分分析)改变图像颜色通道的强度,增加光照变化对模型的鲁棒性。
4) Dropout 层
在全连接层中,AlexNet 以 0.5 的概率随机将神经元的输出置为 0。
- 这迫使模型*++学习更鲁棒的特征++*,减少了神经元之间的共适应性,是缓解大型网络过拟合的关键。
5) 多GPU并行训练
当时的单块 GPU(如 GTX 580,仅 3GB 显存)无法容纳整个模型。AlexNet 将模型切分到两块 GPU 上并行计算,这也是为什么其网络架构图常呈现"上下两路"的原因。
( 🐶🐶🐶太太太太太太牛了~~~~~~~~~~)
2) 网络架构
原始论文:《ImageNet Classification with Deep Convolutional Neural Networks》https://proceedings.neurips.cc/paper_files/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
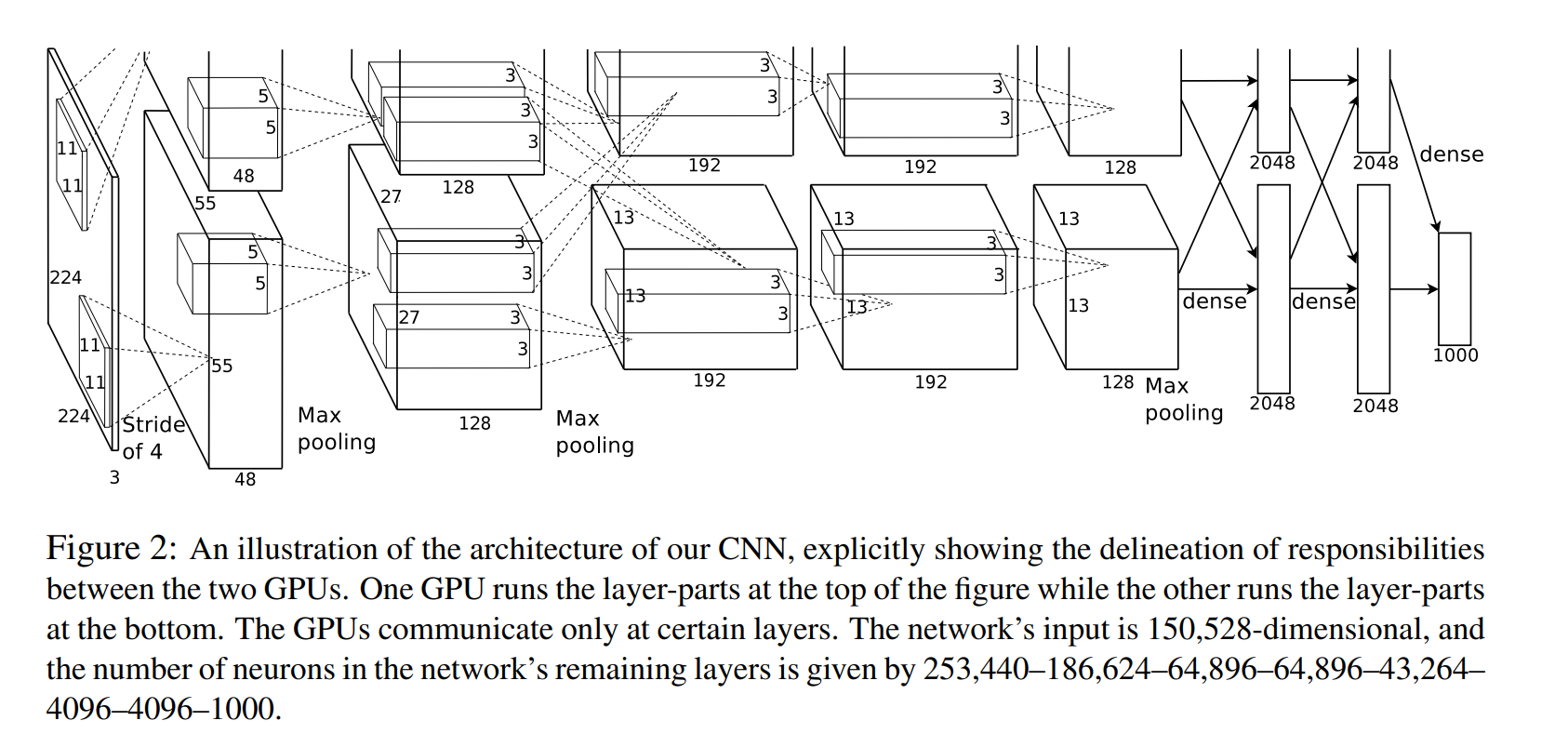
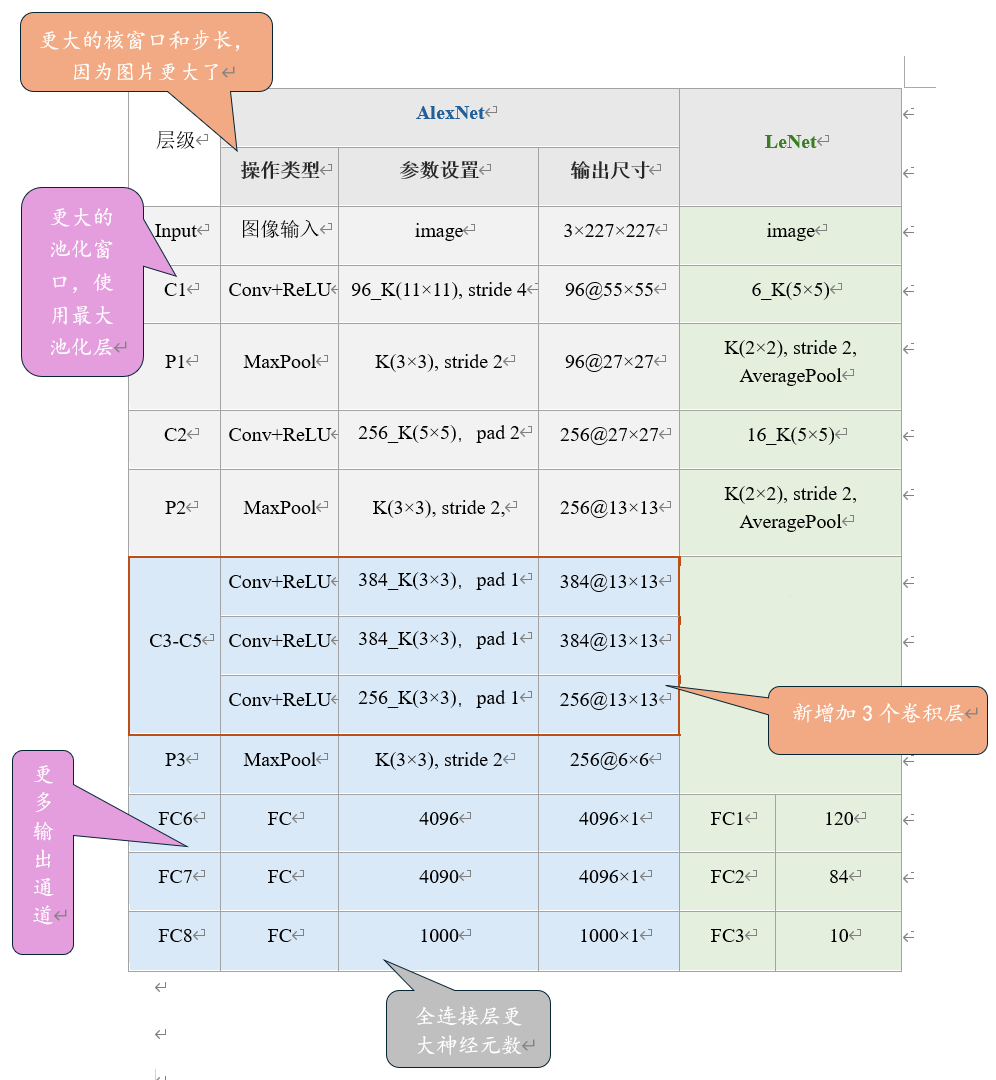
这里结合LeNet的网络架构进行分析。(~~~还是word的表格好用~~~)
从架构来看,可是说AlexNet是一个胖胖的高高的LeNet版本
原文中的输入是3×224×224,但在实际计算第一层的时候发现根本除不尽,为了让卷积核能够滑动,系统通常会自动进行非对称的 Padding(填充) 。大部分深度学习教材和代码实现(如 Caffe 原始版本)会将输入视为,这里以输入(3×227×227)为例:
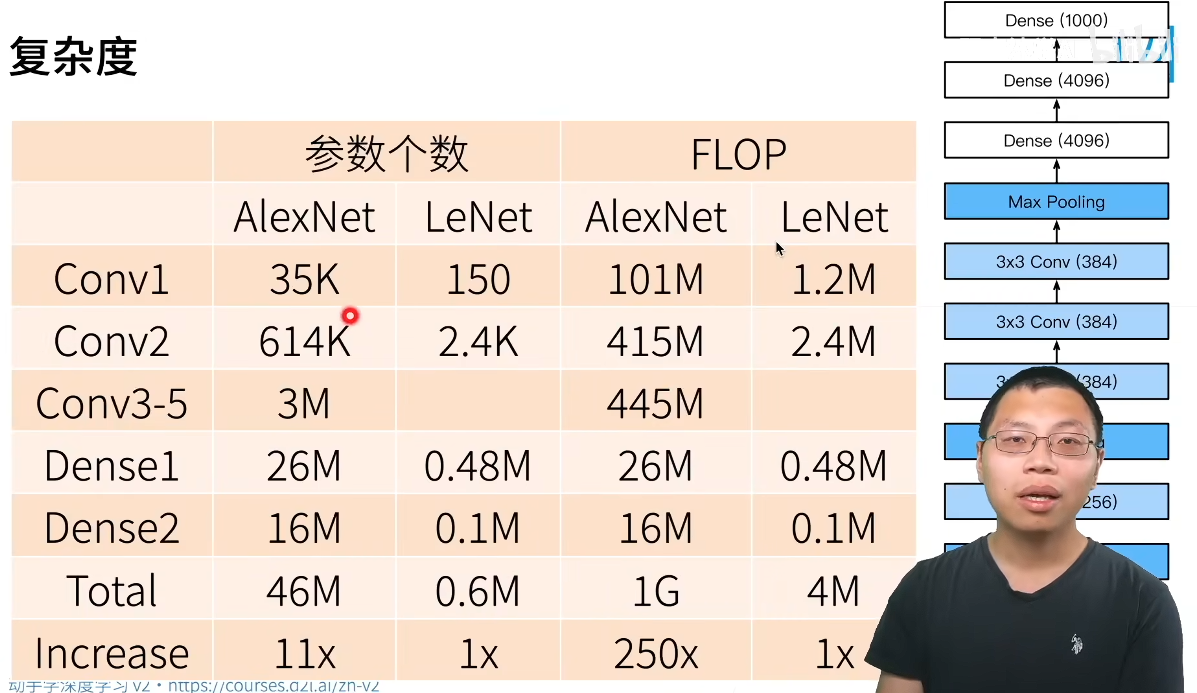
3) 复杂度分析
// 以AlexNet的Conv1为例:
**a)参数个数:**96×11×11×3=35K;
b)FLOP(浮点运算次数)
特征图的宽度/高度计算:
计算单个输出点的计算量(感受野 × 输入通道):
计算总的输出点数(输出宽×高×输出通道):
计算总FLOP:
这与图片中的 101M 非常接近。产生微小差异的原因通常有以下几点:
- 输入尺寸定义不同 :有些实现可能使用 227×227227×227 作为输入,这会导致输出尺寸变为 55×5555×55 (计算方式略有不同),进而影响总数。
- FLOPs 定义不同 :有时计算 FLOPs 时不包含偏置加法,或者将乘加运算视为一次操作,这都会导致结果略有出入。
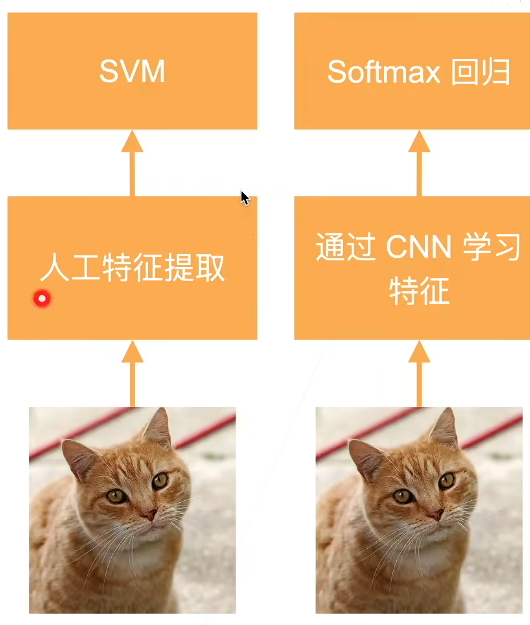
4) 现代深度学习与传统机器视觉的区别
(1) 传统机器视觉(以SVM为例)
在 AlexNet 出现之前,图像分类通常遵循这个流程:
a. 人工特征提取:
科学家们需要凭借经验设计算法(如 SIFT, HOG, LBP)来捕捉边缘、角点或颜色直方图;痛点:特征的设计非常耗时且极具挑战性,而且这些特征往往是"死"的,无法针对特定任务自动调整。
b. 浅层分类器:
随后将提取出的特征向量被输入到支持向量机(SVM)或随机森林中进行分类。**然而,**模型只能学习到表层关系,面对自然界中光照、角度、遮挡等复杂变化时,泛化能力较弱。
(2) 现代深度学习
不再需要人工设计特征,卷积神经网络(CNN)会自动从原始像素中通过一层层的卷积核学习。可以理解为:其告诉计算机"猫长什么样",不如给它看一百万张猫的照片,让它自己总结特征。
总结
AlexNet 相较于LeNet 更深更壮(10x个参数,260x计算复杂度),并在框架中引入丢弃法、使用ReLU、最大池化层、数据增强等关键技术,在2012年ImageNet竞赛中脱颖而出,标志着现代深度神经网络的革命性前进。
(哇,这一章太长了,但是很精彩~,代码下一节来写吧)