一、方案概述
AI智能体(AI Agent),通过机器学习、自然语言处理和自动化推理能力,实现防火墙策略的智能化全生命周期管理。本方案详细阐述如何利用OpenClaw AI智能体实现策略的自动发现、智能优化、风险预测和自主修复。
二、系统架构设计
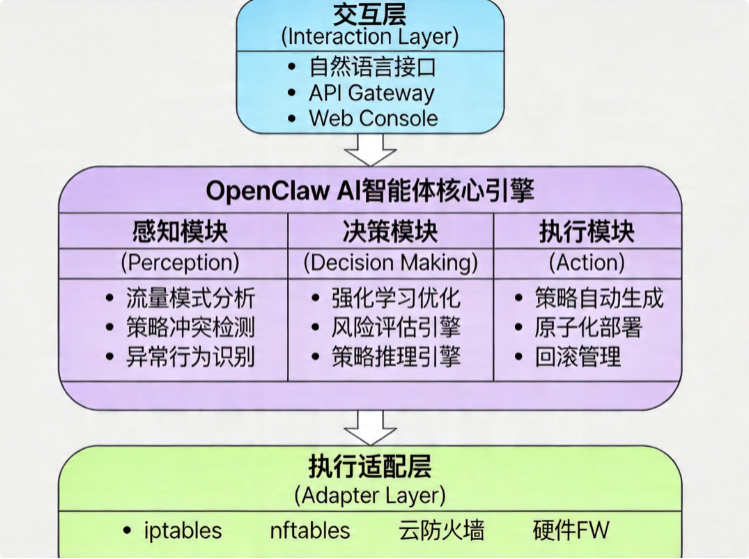
三、核心功能模块实现
3.1 AI智能体核心代码架构
# openclaw_agent.py
import asyncio
import json
from typing import List, Dict, Optional
from dataclasses import dataclass
from datetime import datetime
import numpy as np
from sklearn.ensemble import IsolationForest
import torch
import torch.nn as nn
@dataclass
class FirewallPolicy:
"""防火墙策略数据结构"""
id: str
priority: int
action: str # ALLOW, DENY, DROP
source: List[str]
destination: List[str]
port: List[int]
protocol: str
hit_count: int = 0
last_hit: Optional[datetime] = None
risk_score: float = 0.0
class OpenClawAIAgent:
"""OpenClaw AI智能体核心类"""
def __init__(self, config: Dict):
self.config = config
self.policy_repository = []
self.traffic_patterns = []
# 初始化AI模型
self.anomaly_detector = IsolationForest(
contamination=0.1,
random_state=42
)
self.policy_optimizer = PolicyOptimizationNetwork()
self.nlp_processor = NaturalLanguageProcessor()
async def perceive(self, firewall_logs: List[Dict]) -> Dict:
"""
感知模块:分析防火墙日志,识别模式和异常
"""
# 提取特征
features = self._extract_features(firewall_logs)
# 异常检测
anomalies = self.anomaly_detector.predict(features)
# 流量模式分析
patterns = self._analyze_traffic_patterns(firewall_logs)
# 策略冲突检测
conflicts = self._detect_policy_conflicts()
return {
"anomalies": anomalies,
"patterns": patterns,
"conflicts": conflicts,
"timestamp": datetime.now()
}
def decide(self, perception_result: Dict) -> List[Dict]:
"""
决策模块:基于感知结果制定优化策略
"""
actions = []
# 处理异常流量
if perception_result["anomalies"]:
actions.extend(self._generate_anomaly_response(
perception_result["anomalies"]
))
# 优化冗余策略
if perception_result["patterns"]:
actions.extend(self._optimize_policies(
perception_result["patterns"]
))
# 解决策略冲突
if perception_result["conflicts"]:
actions.extend(self._resolve_conflicts(
perception_result["conflicts"]
))
# 使用强化学习评估动作价值
q_values = self.policy_optimizer.evaluate_actions(actions)
return self._select_best_actions(actions, q_values)
async def execute(self, actions: List[Dict]) -> Dict:
"""
执行模块:原子化部署策略变更
"""
execution_results = []
for action in actions:
try:
# 预验证
validation = await self._validate_action(action)
if not validation["valid"]:
continue
# 创建快照
snapshot_id = await self._create_snapshot()
# 执行变更
result = await self._apply_action(action)
# 验证执行效果
verification = await self._verify_execution(action)
execution_results.append({
"action_id": action["id"],
"status": "success" if verification else "failed",
"snapshot_id": snapshot_id,
"rollback_available": True
})
except Exception as e:
# 自动回滚
await self._rollback(snapshot_id)
execution_results.append({
"action_id": action["id"],
"status": "error",
"error": str(e),
"rolled_back": True
})
return {"results": execution_results}
def _extract_features(self, logs: List[Dict]) -> np.ndarray:
"""提取流量特征用于AI分析"""
features = []
for log in logs:
feature_vector = [
log.get("packet_size", 0),
log.get("frequency", 0),
self._ip_to_numeric(log.get("source_ip", "0.0.0.0")),
self._ip_to_numeric(log.get("dest_ip", "0.0.0.0")),
log.get("port", 0),
log.get("protocol_code", 0)
]
features.append(feature_vector)
return np.array(features)
def _analyze_traffic_patterns(self, logs: List[Dict]) -> List[Dict]:
"""分析流量模式,识别冗余策略"""
patterns = {}
for log in logs:
key = f"{log['source']}-{log['destination']}-{log['port']}"
if key not in patterns:
patterns[key] = {
"hit_count": 0,
"last_seen": None,
"policy_id": log.get("matched_policy")
}
patterns[key]["hit_count"] += 1
patterns[key]["last_seen"] = datetime.now()
# 识别低使用率策略
unused_policies = [
{"policy_id": v["policy_id"], "hits": v["hit_count"]}
for v in patterns.values()
if v["hit_count"] < 10
]
return unused_policies
class PolicyOptimizationNetwork(nn.Module):
"""基于深度学习的策略优化网络"""
def __init__(self):
super().__init__()
self.network = nn.Sequential(
nn.Linear(10, 64),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.network(x)
def evaluate_actions(self, actions: List[Dict]) -> List[float]:
"""评估每个动作的Q值"""
# 将动作转换为特征向量
features = torch.tensor([self._action_to_features(a) for a in actions])
with torch.no_grad():
q_values = self.forward(features)
return q_values.squeeze().tolist()3.2 自然语言策略生成
# natural_language_processor.py
import spacy
from typing import Dict
class NaturalLanguageProcessor:
"""自然语言处理模块:将人类语言转换为防火墙策略"""
def __init__(self):
self.nlp = spacy.load("zh_core_web_sm")
self.action_map = {
"允许": "ALLOW",
"禁止": "DENY",
"拒绝": "DROP",
"permit": "ALLOW",
"deny": "DENY"
}
def parse_to_policy(self, text: str) -> Dict:
"""
将自然语言转换为策略规则
示例输入:
"允许192.168.1.0/24网段访问80和443端口"
输出:
{
"action": "ALLOW",
"source": ["192.168.1.0/24"],
"port": [80, 443],
"protocol": "TCP"
}
"""
doc = self.nlp(text)
policy = {
"action": "DENY",
"source": [],
"destination": [],
"port": [],
"protocol": "TCP",
"description": text
}
# 提取动作
for token in doc:
if token.text in self.action_map:
policy["action"] = self.action_map[token.text]
# 提取IP地址(简化版)
import re
ips = re.findall(r'\b\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}(?:/\d{1,2})?\b', text)
if ips:
policy["source"] = ips[:1]
if len(ips) > 1:
policy["destination"] = ips[1:2]
# 提取端口号
ports = re.findall(r'\b(?:端口|port)\s*(\d+)', text)
if not ports:
ports = re.findall(r'\b(\d{2,5})\b', text)
policy["port"] = [int(p) for p in ports[:5]]
return policy
# 使用示例
nlp = NaturalLanguageProcessor()
policy = nlp.parse_to_policy("允许10.0.0.0/8访问服务器192.168.1.100的8080端口")
print(json.dumps(policy, indent=2, ensure_ascii=False))3.3 智能策略优化引擎
# policy_optimizer.py
from typing import List, Set
import ipaddress
class IntelligentPolicyOptimizer:
"""智能策略优化:合并、去重、优化规则"""
def optimize(self, policies: List[FirewallPolicy]) -> List[FirewallPolicy]:
"""执行策略优化"""
optimized = []
# 1. 删除冗余策略
policies = self._remove_redundant(policies)
# 2. 合并相似策略
policies = self._merge_similar(policies)
# 3. 重新排序优化
policies = self._optimize_order(policies)
return policies
def _remove_redundant(self, policies: List[FirewallPolicy]) -> List[FirewallPolicy]:
"""删除被完全覆盖的冗余策略"""
non_redundant = []
for i, policy in enumerate(policies):
is_redundant = False
for j, other in enumerate(policies):
if i == j:
continue
if self._is_subset(policy, other):
is_redundant = True
break
if not is_redundant:
non_redundant.append(policy)
return non_redundant
def _merge_similar(self, policies: List[FirewallPolicy]) -> List[FirewallPolicy]:
"""合并具有相同动作和协议的策略"""
merged = []
processed = set()
for i, policy in enumerate(policies):
if i in processed:
continue
merge_group = [policy]
processed.add(i)
for j, other in enumerate(policies):
if j in processed:
continue
if self._can_merge(policy, other):
merge_group.append(other)
processed.add(j)
# 执行合并
merged_policy = self._do_merge(merge_group)
merged.append(merged_policy)
return merged
def _can_merge(self, p1: FirewallPolicy, p2: FirewallPolicy) -> bool:
"""判断两个策略是否可以合并"""
return (p1.action == p2.action and
p1.protocol == p2.protocol and
self._are_adjacent(p1.source, p2.source) and
self._are_adjacent(p1.destination, p2.destination))
def _are_adjacent(self, list1: List[str], list2: List[str]) -> bool:
"""检查两个地址列表是否可以合并"""
# 简化实现:检查是否有重叠或相邻
return True # 实际实现需要更复杂的IP地址计算
# 可视化优化效果
def visualize_optimization(before: List, after: List):
"""可视化策略优化效果"""
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 优化前
axes[0].bar(range(len(before)), [p.hit_count for p in before])
axes[0].set_title(f"优化前: {len(before)}条规则")
axes[0].set_xlabel("规则索引")
axes[0].set_ylabel("命中次数")
# 优化后
axes[1].bar(range(len(after)), [p.hit_count for p in after])
axes[1].set_title(f"优化后: {len(after)}条规则")
axes[1].set_xlabel("规则索引")
axes[1].set_ylabel("命中次数")
plt.tight_layout()
plt.savefig("policy_optimization.png")
plt.show()四、完整工作流示例
# main_workflow.py
async def openclaw_management_workflow():
"""OpenClaw完整管理流程"""
# 1. 初始化AI智能体
config = {
"learning_rate": 0.001,
"anomaly_threshold": 0.7,
"optimization_interval": 3600
}
agent = OpenClawAIAgent(config)
# 2. 从自然语言创建策略
nlp = NaturalLanguageProcessor()
user_request = "允许办公网10.0.0.0/8访问生产服务器192.168.1.0/24的HTTPS服务"
new_policy = nlp.parse_to_policy(user_request)
# 3. 感知当前状态
firewall_logs = await collect_firewall_logs()
perception = await agent.perceive(firewall_logs)
print(f"检测到{len(perception['anomalies'])}个异常")
print(f"发现{len(perception['conflicts'])}个策略冲突")
# 4. 智能决策
actions = agent.decide(perception)
# 5. 执行优化
results = await agent.execute(actions)
# 6. 生成报告
report = generate_optimization_report(results)
print(report)
# 运行工作流
if __name__ == "__main__":
asyncio.run(openclaw_management_workflow())五、监控与可视化
# monitoring_dashboard.py
import plotly.graph_objects as go
from plotly.subplots import make_subplots
def create_openclaw_dashboard(metrics: Dict):
"""创建OpenClaw监控仪表盘"""
fig = make_subplots(
rows=2, cols=2,
subplot_titles=("策略命中率", "AI决策准确率",
"异常检测趋势", "策略优化效果")
)
# 策略命中率
fig.add_trace(
go.Scatter(x=metrics["timestamps"], y=metrics["hit_rates"],
name="命中率"),
row=1, col=1
)
# AI决策准确率
fig.add_trace(
go.Bar(x=metrics["models"], y=metrics["accuracies"],
name="准确率"),
row=1, col=2
)
fig.update_layout(height=800, title_text="OpenClaw AI智能体监控面板")
fig.write_html("openclaw_dashboard.html")六、方案优势总结
- 智能化决策:基于机器学习自动识别异常流量和冗余策略
- 自然语言交互:运维人员可用自然语言描述策略需求
- 自主学习优化:通过强化学习持续优化策略配置
- 原子化执行:确保策略变更的原子性和可回滚性
- 实时感知:持续监控流量模式,主动发现安全隐患
本方案通过AI智能体实现了防火墙策略的全生命周期智能管理,将传统的手动配置转变为自动化、智能化的管理模式,大幅提升安全运维效率和准确性。