Note:强化学习(二)
2026 | ming

五. Q学习
5.1 数学理论
蒙特卡洛(MC)方法必须等到整个Episode结束才能更新。而Q学习的核心非常直接------我们能不能走一步看一步? 与其等到终点才知道回报 Gt 是多少,不如在每一步都利用当下的奖励 Rt 和下一步的估计来更新。这就是时序差分(Temporal Difference, TD)学习的精髓。
Q学习不是简单地"提前更新",它实际上在做自举(Bootstrapping)。我们用当前的Q函数估计下一步的最优价值,然后用这个估计来修正现在的估计。
Q学习更新公式:
Q(St,At)←Q(St,At)+αRt+γa′maxQ(St+1,a′)−Q(St,At)
首先, α 是学习率,这很好理解。关键在于方括号里的部分------这被称为TD误差(TD Error):
δt=Rt+γa′maxQ(St+1,a′)−Q(St,At)
这里的直觉是:我们把 Rt+γmaxa′Q(St+1,a′) 看作一个目标值(TD Target) 。它代表"基于当前对下一步的最佳估计,我在状态 St 执行动作 At 应该能得到多少回报"。如果这个目标值比当前的 Q(St,At) 估计要高,我们就把Q值往上调一点;反之则往下调。
这里的 max 操作是Q学习的灵魂,它意味着我们假设在下一步会采取最优动作 ,不管我们实际上下一步准备干什么。这其实就是对最优动作价值函数 q∗ 的直接逼近。
我们再来回看蒙特卡洛的公式:
Q(s,a)←Q(s,a)+αG(n)−Q(s,a)
MC方法的更新是基于实际观测到的完整回报 G(n),而Q学习用 Rt+γmaxa′Q(St+1,a′) 替代了 G(n)。这个替换背后藏着深刻的统计意义:
- 蒙特卡洛 使用的是无偏估计(真实的回报),但方差极大------因为 G(n) 是整条轨迹上所有随机性的累积,路径稍微变一点,数值可能天差地别。
- Q学习 引入了一个基于当前估计的"猜测",这带来了偏差(因为我们的Q值初始可能是错的),但大幅降低了方差------毕竟下一步的估计比整条随机轨迹稳定多了。
我们通常认为,这种用偏差换取方差降低的权衡在实践中往往更划算,特别是在状态空间很大的场景下。而且,随着学习的进行,这个偏差会逐渐消失。
Q学习理论上收敛到最优策略,前提是每个状态-动作对都被无限次访问 。所以我们通常配合 ϵ-贪婪探索:以 ϵ 概率随机选择动作,以 1−ϵ 概率选择当前Q值最大的动作。随着学习进行, ϵ 通常会逐渐衰减。
为了保证收敛,学习率 α 需要满足Robbins-Monro条件(通常取 αt=1/t 或者一个较小的常数)。实践中,前期用较大学习率快速学习,后期调小以稳定收敛,是常见的技巧。
5.2 代码实现
python
from collections import defaultdict
import numpy as np
# -------------------- Q-Learning Agent --------------------
# Q学习智能体类:实现Q-Learning算法的核心逻辑
class QLearningAgent:
"""
Q-Learning智能体
"""
def __init__(self, alpha=0.8, epsilon=0.3, gamma=0.9):
"""
初始化Q学习智能体
参数:
alpha: 学习率(Learning Rate),控制新信息覆盖旧信息的程度
范围通常是0-1,越大学习越快但可能不稳定,越小学习越慢但更稳定
epsilon: 探索率(Exploration Rate),epsilon-greedy策略中的探索概率
范围0-1,越大随机探索越多,越小越依赖已知最优动作
gamma: 折扣因子(Discount Factor),衡量未来奖励的重要性
范围0-1,越接近1越重视长期回报,越接近0越重视即时奖励
"""
self.alpha = alpha # 学习率:每次更新Q值时的步长
self.epsilon = epsilon # 探索概率:随机选择动作的概率(而非选择最优动作)
self.gamma = gamma # 折扣因子:未来奖励的衰减系数
self.action_size = 4 # 动作空间大小:上下左右四个方向(0:上, 1:下, 2:左, 3:右)
# Q表:存储状态-动作值函数 Q(s,a)
# 使用defaultdict自动为未访问过的状态-动作对初始化Q值为0.0
# 键的形式是 (state, action) 元组,值是该状态-动作对的预期累积奖励
self.Q = defaultdict(lambda: 0.0)
def get_action(self, state):
"""
根据当前状态选择动作(epsilon-greedy策略)
参数:
state: 当前环境状态(通常是坐标元组,如 (y, x))
返回:
选择的动作编号(0-3之间的整数)
策略说明:
- 以 epsilon 的概率随机探索(尝试新动作)
- 以 1-epsilon 的概率利用已知信息(选择当前Q值最高的动作)
这种平衡探索与利用的策略称为 epsilon-greedy
"""
# 生成0-1之间的随机数,如果小于epsilon,则进行随机探索
if np.random.rand() < self.epsilon:
# 随机选择一个动作,帮助发现新的、可能更好的策略
return np.random.choice(self.action_size)
else:
# 利用(Exploitation):选择当前Q值最高的动作
# 获取当前状态下所有动作的Q值
qs = [self.Q[state, a] for a in range(self.action_size)]
# np.argmax返回最大值的索引,即最优动作的编号
# int()转换确保返回Python整数而非numpy类型
return int(np.argmax(qs))
def update(self, state, action, reward, next_state, done):
"""
使用Q-Learning算法更新Q表(时序差分学习)
参数:
state: 当前状态(执行动作前的状态)
action: 执行的动作
reward: 执行动作后获得的即时奖励
next_state: 执行动作后到达的下一个状态
done: 布尔值,表示本轮 episode 是否结束(是否到达终止状态)
"""
# 计算下一状态的最大Q值(用于Bootstrap)
if done:
# 如果 episode 结束(到达终止状态),没有未来奖励
# 根据定义,终止状态的V值为0,因此next_max_q设为0
next_max_q = 0.0
else:
# 获取下一状态中所有可能动作的Q值列表
next_qs = [self.Q[next_state, a] for a in range(self.action_size)]
# 选择最大的Q值作为未来累积奖励的估计
next_max_q = max(next_qs)
# 计算TD目标(Temporal Difference Target)
# 这是基于当前奖励和未来最优估计的总回报预测
target = reward + self.gamma * next_max_q
# 计算TD误差:预测目标与当前估计之间的差异
# 这个误差告诉我们的预测偏离了多少
td_error = target - self.Q[state, action]
# 更新Q值:向目标方向移动一小步(步长由alpha控制)
# 如果alpha=1,则完全替换为target;alpha越小,学习越保守
self.Q[state, action] += self.alpha * td_error
# -------------------- 训练主循环 --------------------
def train_q_learning(env, episodes=1000, max_steps_per_episode=200,
alpha=0.8, epsilon=0.3, gamma=0.9, decay_epsilon=True):
"""
训练Q-Learning智能体的主函数
参数:
env: 环境对象,必须提供 reset() 和 step(action) 接口
reset() 返回初始状态;step() 返回 (next_state, reward, done)
episodes: 训练的总轮数(episode数量),每轮从初始状态到终止状态
max_steps_per_episode: 每轮最大步数限制,防止陷入无限循环
alpha, epsilon, gamma: 智能体超参数,含义同上
decay_epsilon: 是否启用epsilon衰减(逐渐减小探索率)
通常训练初期需要多探索,后期多利用
返回:
训练完成的QLearningAgent实例,包含学习好的Q表
"""
# 创建智能体实例
agent = QLearningAgent(alpha=alpha, epsilon=epsilon, gamma=gamma)
# 保存epsilon的初始值,用于衰减计算
epsilon_start = epsilon
# 设置epsilon的最小值,确保始终保留一点探索能力
epsilon_end = 0.01
# 外层循环:遍历所有训练轮次(episodes)
for ep in range(episodes):
# 重置环境,获取初始状态(通常是起点坐标)
state = env.reset()
# done标记本轮是否结束(如到达目标或掉入陷阱)
done = False
# 步数计数器,用于限制单轮最大步数
steps = 0
# 如果启用epsilon衰减,动态调整探索率
# 策略:随着训练进行,线性地从epsilon_start降到epsilon_end
# 这样前期多探索找策略,后期多利用优化策略
if decay_epsilon:
# 计算当前轮次的epsilon值:随轮次增加而线性减小
# 公式:初始值 * (1 - 当前进度) ,但不低于最小值
agent.epsilon = max(epsilon_end,
epsilon_start * (1.0 - ep / episodes))
# 内层循环:单轮内的交互过程,直到结束或达到最大步数
while not done and steps < max_steps_per_episode:
# 1. 智能体根据当前策略选择动作
action = agent.get_action(state)
# 2. 执行动作,与环境交互,获得反馈
# env.step执行动作并返回:新状态、即时奖励、是否结束
next_state, reward, done = env.step(action)
# 3. 使用Q-Learning算法更新Q表(核心学习步骤)
agent.update(state, action, reward, next_state, done)
# 4. 状态转移:将新状态设为当前状态,继续下一步
state = next_state
steps += 1
# 可选:在这里添加每轮结束时的日志打印,如:
# if ep % 100 == 0:
# print(f"Episode {ep}/{episodes} completed, epsilon={agent.epsilon:.3f}")
# 返回训练完成的智能体,可用于测试或提取策略
return agent
# -------------------- 提取策略地图 --------------------
def extract_policy_map(agent, env):
"""
从训练好的Q表中提取确定性策略,生成可视化的策略地图
参数:
agent: 训练完成的QLearningAgent实例,包含学习好的Q表
env: 环境对象,需要提供 height, width, reward_map 属性
返回:
policy_map: 二维numpy数组,形状为 (height, width)
每个元素代表该位置的最优动作(0-3),-1代表障碍物
"""
# 获取环境的尺寸(假设是网格世界类环境)
height, width = env.height, env.width
# 初始化策略地图,默认值为-1(表示障碍物或不可达区域)
# dtype=int确保存储整数类型的动作编号
policy_map = np.full((height, width), -1, dtype=int)
# 遍历网格中的每一个位置
for y in range(height):
for x in range(width):
# 构造状态标识(假设状态用坐标元组表示)
state = (y, x)
# 检查该位置是否是有效状态(不是障碍物)
# 假设env.reward_map中None表示障碍物(无奖励信息)
if env.reward_map[state] is None:
continue # 跳过障碍物,保持默认值-1
# 获取该状态下所有动作的Q值
qs = [agent.Q[state, a] for a in range(agent.action_size)]
# 选择Q值最高的动作作为该状态的最优策略
best_action = np.argmax(qs)
# 将最优动作填入策略地图
policy_map[y, x] = best_action
return policy_map还是使用3.2小节搭建的网格世界环境来测试Q学习算法,测试代码如下,你可以在自己的设备上运行一下,看看结果如何,这里就不放结果图了。
python
# 1. 创建网格世界环境
env = GridWorld(
height=6,
width=6,
goal_state=(5, 5), # 右下角为目标
start_state=(0, 0), # 左上角为起点
obstacle_ratio=0.1,
trap_ratio=0.25,
)
env.render()
# 2. 训练智能体
print("开始训练...")
agent = train_q_learning(env, episodes=2000, decay_epsilon=True)
print("训练完成。")
# 3. 提取策略地图
policy_map = extract_policy_map(agent, env)
env.render(policy_map=policy_map)六. Gym 环境
在前面的章节中,我们使用了自定义的"网格世界"环境来演示基础的强化学习算法。但网格世界过于简化,无法体现现代强化学习算法(如深度Q网络、策略梯度等)的真正能力。因此,从本章开始,我们将统一使用 Gymnasium 库------一个由Farama基金会维护的、广泛使用的强化学习环境接口标准。
Gymnasium 是原先 OpenAI Gym 库的继承者,提供了大量经典的环境(如控制任务、Atari游戏、机器人仿真等),并保持了简单一致的API设计。你只需要通过 gym.make() 创建环境,然后调用 reset()、step()、render() 等方法,就能与复杂的环境进行交互。这使得我们能够专注于算法本身,而不必重复编写环境模拟代码。
本笔记将重点使用两个经典环境:CartPole-v1 (倒立摆)和 LunarLander-v3(登月舱)。下面分别进行详细讲解。
官方手册:gymnasium.farama.org
6.1 CartPole-v1
CartPole 是一个经典的控制问题:一个小车可以在水平轨道上左右移动,车上连接着一根竖直的杆子。目标是对小车施加水平力,使得杆子保持直立而不倒下。如图6.1
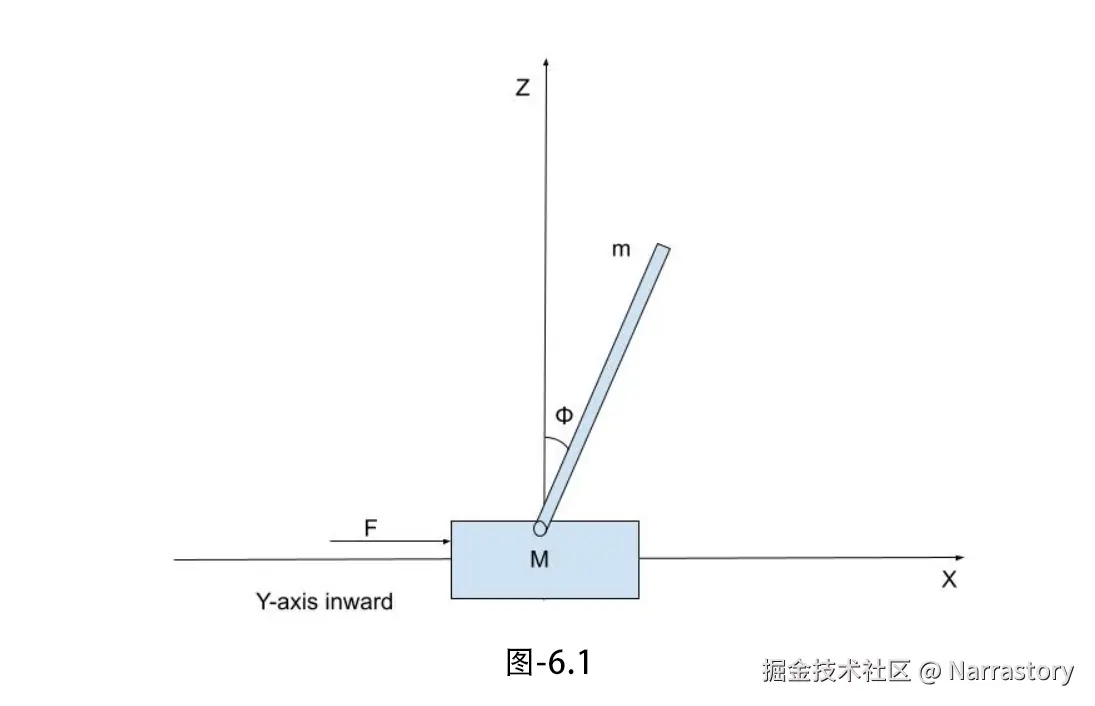
每维持一个时间步(杆子没有倒下),环境就会返回 +1 的奖励。没有额外的负奖励,因此智能体需要尽可能久地保持平衡。
终止条件
一个 episode 会在以下任一情况下结束:
- 杆子角度超出 −12∘,12∘(相对于垂直方向)
- 小车位置超出轨道边界 : x<−4.8 或 x>4.8
- 累计步数达到 500(此时认为任务成功,强制终止)
状态空间
CartPole-v1 的状态是一个 4 维连续向量:
| 索引 | 变量名 | 含义 | 大致范围 |
|---|---|---|---|
| 0 | 小车位置 | 轨道中心为0 | −4.8,4.8 |
| 1 | 小车速度 | 水平速度 | −∞,∞ |
| 2 | 杆子角度 | 垂直方向为0,顺时针为正 | −0.418,0.418 弧度(约 ±24∘,但终止阈值为 ±12∘) |
| 3 | 杆子角速度 | 角度变化率 | −∞,∞ |
动作空间
只有 两个离散动作:
0:向左移动小车1:向右移动小车
代码示例
python
import gymnasium as gym
# 创建环境
env = gym.make('CartPole-v1')
# 重置环境,获得初始状态
state, info = env.reset()
print("初始状态:", state) # 例如 [0.02, 0.01, 0.04, -0.02]
# 查看动作空间
action_space = env.action_space
print("动作空间:", action_space) # Discrete(2)
# 按照自定义概率分布采样一个动作(非均匀采样示例)
import numpy as np
action = env.action_space.sample() # 默认均匀随机采样
# 若想按概率分布采样:np.random.choice([0,1], p=[0.9, 0.1])
action = np.random.choice([0, 1], p=[0.9, 0.1])
# 执行动作
next_state, reward, terminated, truncated, info = env.step(action)
print("下一状态:", next_state)
print("奖励:", reward) # 通常是 1.0
print("是否终止:", terminated) # 杆子倒下或超出边界时为 True
print("是否截断:", truncated) # 达到最大步数(500)时为 True注意 :terminated 表示任务因失败或成功自然结束,truncated 表示因时间限制(步数上限)而强制中断。在训练时通常将两者视为 episode 结束,但它们在算法中(如GAE)可能有不同用途。
python
# 一个简单的交互循环
env = gym.make('CartPole-v1')
state, _ = env.reset()
done = False
total_reward = 0
while not done:
action = env.action_space.sample() # 随机策略
next_state, reward, terminated, truncated, _ = env.step(action)
total_reward += reward
done = terminated or truncated
print(f"Episode 结束,总奖励: {total_reward}")
env.close()6.2 LunarLander-v3
LunarLander 是一个经典的火箭着陆问题:你需要控制登月舱在月球表面着陆。登月舱拥有主引擎和两个侧向姿态引擎,目标是将它安全地降落在两面旗帜之间的着陆平台上。如图6.2
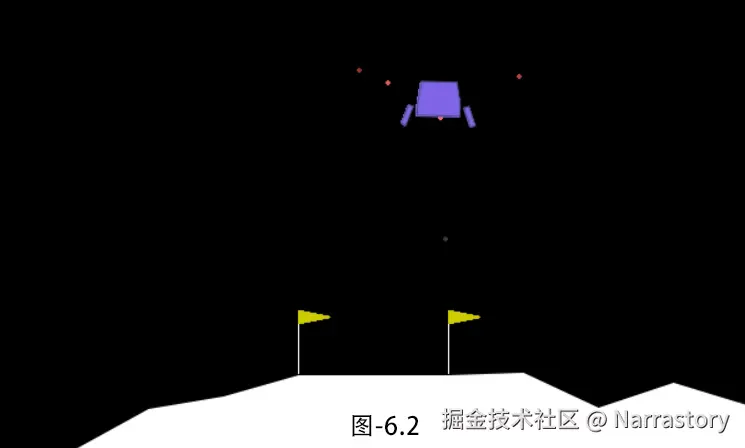
这个环境比 CartPole 复杂得多,更接近真实世界的控制问题,非常适合测试算法的鲁棒性和精细控制能力。
动作空间
LunarLander-v3 默认提供 4 个离散动作:
| 动作 | 含义 |
|---|---|
| 0 | 不执行任何操作 |
| 1 | 启动左侧姿态引擎(产生向右的推力) |
| 2 | 启动主引擎(产生向上的推力) |
| 3 | 启动右侧姿态引擎(产生向左的推力) |
状态空间
状态是一个 8 维向量,包含位置、速度、角度及触地信息:
| 索引 | 变量 | 含义 |
|---|---|---|
| 0 | x | 登月舱的水平坐标 |
| 1 | y | 登月舱的垂直坐标 |
| 2 | vx | 水平速度 |
| 3 | vy | 垂直速度 |
| 4 | θ | 角度(倾斜程度) |
| 5 | ω | 角速度 |
| 6 | 左腿接触 | 布尔值(0或1),左腿是否接触地面 |
| 7 | 右腿接触 | 布尔值(0或1),右腿是否接触地面 |
奖励机制
每一步都会根据当前状态计算奖励,最终累积奖励决定了着陆的好坏。奖励分为正向和负向两部分:
正向奖励
- 靠近着陆平台中心时,获得 距离奖励(随距离减小而增加)
- 移动速度越慢,奖励越高
- 每条腿接触地面时:+10 分
- 安全着陆(两条腿同时着地且垂直速度适中):额外 +100 分
负向惩罚
- 远离着陆平台:惩罚增加
- 速度越快,惩罚越大
- 倾斜角度越大,惩罚越大
- 使用左侧或右侧姿态引擎:每帧 -0.03 分
- 使用主引擎:每帧 -0.3 分(鼓励高效使用燃料)
- 坠毁(主体接触月面或撞到侧面):额外 -100 分
终止条件
一个 episode 在以下任一情况下结束:
- 登月舱 主体接触月面(坠毁)
- 登月舱 超出视口范围 ( x>1 或 x<−1 或 y 超出上下界)
- 登月舱 进入休眠状态(速度几乎为零且长时间无碰撞,通常被视为安全着陆)
成功标准
通常认为 单局得分 ≥ 200 分 即为成功解决该任务(例如在 DQN 论文中的标准)。
创建环境的高级参数
gym.make() 支持许多配置参数,可以改变任务的难度和环境特性:
python
import gymnasium as gym
env = gym.make(
"LunarLander-v3",
continuous=False, # False=离散动作,True=连续动作(此时动作空间为Box)
gravity=-10.0, # 重力常数(范围 -12.0 到 0.0),负值表示向下
enable_wind=False, # 是否启用随机风力
wind_power=15.0, # 最大水平风力强度(推荐 0.0 ~ 20.0)
turbulence_power=1.5, # 最大旋转风力强度(推荐 0.0 ~ 2.0)
render_mode="human", # 可视化模式:None, "human", "rgb_array"
)提示 :开启 enable_wind=True 会极大增加难度,适合测试算法的鲁棒性。
python
# 基本使用示例
env = gym.make("LunarLander-v3")
state, info = env.reset()
total_reward = 0
done = False
while not done:
action = env.action_space.sample() # 随机动作(效果很差)
next_state, reward, terminated, truncated, _ = env.step(action)
total_reward += reward
done = terminated or truncated
print(f"Episode 结束,总奖励: {total_reward}")
env.close()七. 神经网络Q学习
7.1 理论
基础的Q学习有一个明显的局限------之前的Q学习依赖于一个"Q字典"(本质是表格存储),把每个状态-动作对的Q值都记下来,更新时直接查找和修改。在网格世界中这种方法还尚可,但实际场景中,状态空间往往庞大到难以想象,比如Atari游戏的像素状态、机器人控制的连续状态,此时表格存储根本无法实现,甚至连"遍历所有状态-动作对"都做不到。
这时候,我们自然会想到:能不能用一个函数来近似这个Q字典?而在深度学习时代,最强大的函数近似器无疑是神经网络------这就是神经网络Q学习的核心思路。我们通常不再关心每个状态的具体Q值,而是关心一个函数: Qθ(s,a),其中 θ 是神经网络的权重。训练的目标是让这个函数的输出尽可能接近真实的长期回报。
在基础Q学习中,要估计的是动作价值函数 q(s,a),也就是在状态 s下执行动作 a的期望累积回报。表格Q学习中,我们用 Q(s,a)这个表格项来直接存储这个估计值;而神经网络Q学习中,我们用一个神经网络 Qθ(s,a)来近似这个函数,其中 θ是神经网络的参数。
这个神经网络的结构其实很直观,如图7.1,通常使用下面那种神经网络。
- 输入:当前状态 s(可以是离散状态的编码,也可以是连续状态的特征向量,比如游戏像素的扁平化向量、机器人的位置和速度);
- 输出:当前状态 s下,每个可能动作 a对应的Q值 Qθ(s,a)(如果动作是离散的,输出维度等于动作数;如果是连续动作,会有相应的适配,但这里我们聚焦离散动作)。
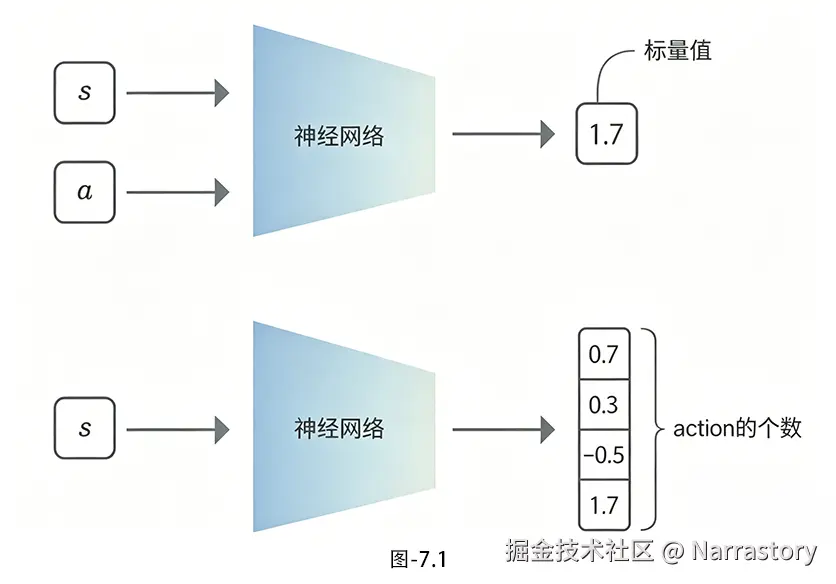
简单来说,之前我们查Q表格找 Q(s,a),现在我们把状态 s输入神经网络,直接输出所有动作的Q值------神经网络就相当于一个"可学习的Q字典",既能处理庞大的状态空间,还能泛化到未见过的状态(这是表格Q学习完全做不到的)。如图7.2,我们想让神经网络预测值尽量靠近标签,但是标签本身又是由神经网络预测值组成,这就是自举。
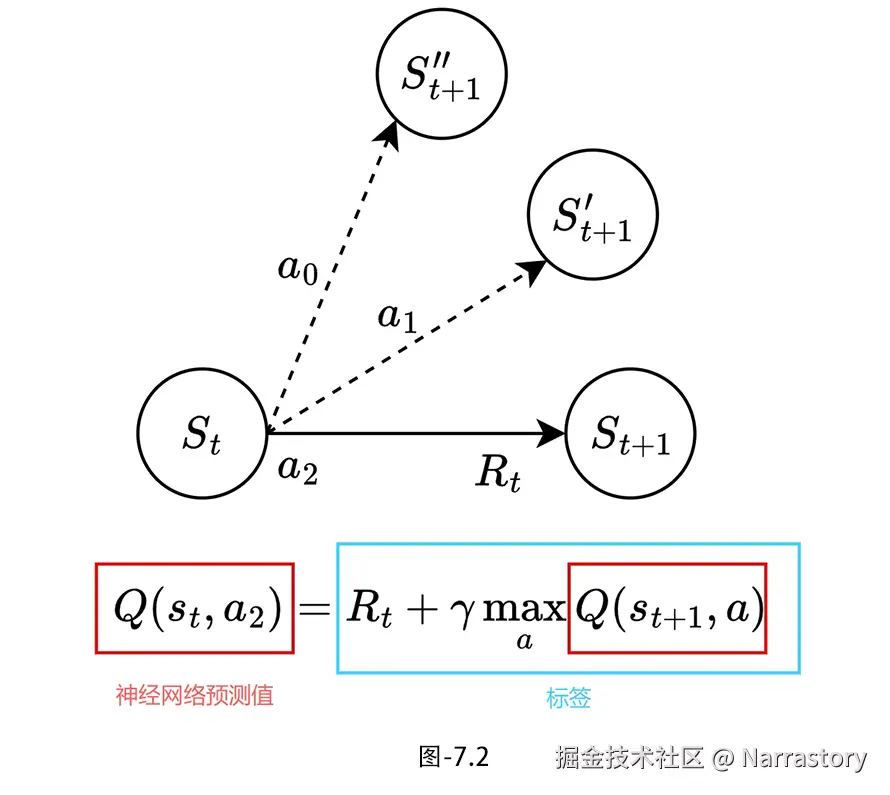
注意: 基础Q学习本身就有不稳定的趋势,而加入神经网络后,这种不稳定性会变得更加明显。
核心原因有两个:
- 自举带来的"误差传递":我们用 Qθ(s′,a′)计算目标 y,但 Qθ(s′,a′)本身就是神经网络的估计值,可能存在偏差;而我们又用这个带偏差的目标去更新神经网络,导致偏差不断传递、累积,甚至发散。
- 数据相关性与参数更新的耦合:在训练过程中,我们通常是按轨迹顺序采样数据( st,at,rt,st+1),这些数据之间存在很强的相关性(比如连续的状态是相关的);而神经网络的梯度下降需要独立同分布的数据,这种相关性会导致参数更新震荡,难以收敛。
7.2 代码实现
下面就用PyTorch实现一个最朴素的神经网络Q学习,并且在CartPole-v1上进行一个简单的测试。
先引入必要库
python
"""
神经网络Q学习 (Naive Neural Q-Learning) on CartPole-v1
======================================================
环境:CartPole-v1 (gymnasium)
状态:4维连续向量 (小车位置, 速度, 杆角度, 角速度)
动作:2个离散动作 (0: 左推, 1: 右推)
"""
import gymnasium as gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
from collections import deque我们用一个小型全连接网络来近似Q函数。输入是4维状态,输出是2个动作分别对应的Q值。网络结构很简单:两个隐藏层,每层128个神经元,ReLU激活。麻雀虽小,但足以应付CartPole这类任务。
python
# -------------------- 1. 定义Q网络 --------------------
class QNetwork(nn.Module):
"""
输入:
state: 形状为 (batch_size, 4) 或 (4,) 的张量
输出:
Q值: 形状为 (batch_size, action_dim) 或 (action_dim,) 的张量,
每个元素代表在给定状态下执行对应动作的期望累积奖励。
"""
def __init__(self, state_dim=4, action_dim=2, hidden_dim=128):
super().__init__()
# 使用 Sequential 容器构建三层线性变换 + ReLU 激活
self.net = nn.Sequential(
nn.Linear(state_dim, hidden_dim), # 第一隐藏层: 4 -> 128
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim), # 第二隐藏层: 128 -> 128
nn.ReLU(),
nn.Linear(hidden_dim, action_dim) # 输出层: 128 -> 2 (每个动作的Q值)
)
def forward(self, state):
"""
前向传播。注意:这里不做 softmax 或 argmax,
因为我们最终要回归到TD目标值,需要原始的Q值输出。
"""
return self.net(state)这里我们采用最经典的 ϵ‑贪婪策略:以概率 ϵ 随机选择一个动作(探索),否则选择当前Q网络认为最优的动作(利用)。为了让训练过程更稳定,epsilon 会随着训练回合数逐渐衰减。
python
# -------------------- 2. ε-贪婪策略 --------------------
def select_action(q_net, state, epsilon):
"""
参数:
q_net: Q网络模型
state: numpy数组,形状为 (4,)
epsilon: 当前探索概率,取值范围 [0, 1]
返回:
action: 选择的动作 (0 或 1)
"""
# 生成一个随机数,若小于 epsilon 则随机探索
if np.random.random() < epsilon:
return np.random.randint(2) # CartPole 的动作空间为 {0, 1}
else:
# 将 numpy 状态转换为 torch 张量,并增加 batch 维度 (1, 4)
state_tensor = torch.FloatTensor(state).unsqueeze(0)
# 禁用梯度计算,仅进行推理,加快速度且节省内存
with torch.no_grad():
q_values = q_net(state_tensor)
# 返回 Q 值最大的动作索引
return torch.argmax(q_values, dim=1).item()我们会在每个时间步收集一条转移 (s,a,r,s′),然后立刻用它来更新Q网络。更新的目标值(TD目标)按照Q学习的经典公式计算:
target=r+γa′maxQ(s′,a′;θ)
如果下一步是终止状态,则没有后续Q值,目标值就等于即时奖励 r。损失函数采用均方误差(MSE),对网络输出 Q(s,a;θ) 与目标值之间的差距进行惩罚。
python
# -------------------- 3. 训练主循环 --------------------
def train_naive_qlearning(env_name="CartPole-v1",
num_episodes=500,
gamma=0.99,
lr=1e-3,
epsilon_start=1.0,
epsilon_end=0.01,
epsilon_decay=0.995):
"""
参数:
env_name: Gym 环境名称
num_episodes: 训练的总回合数
gamma: 折扣因子,控制未来奖励的重要性
lr: Adam 优化器的学习率
epsilon_start: 初始探索率
epsilon_end: 最小探索率
epsilon_decay: 每个回合后 epsilon 的衰减因子
"""
env = gym.make(env_name)
state_dim = env.observation_space.shape[0] # 4
action_dim = env.action_space.n # 2
# 初始化 Q 网络与优化器
q_net = QNetwork(state_dim, action_dim)
optimizer = optim.Adam(q_net.parameters(), lr=lr)
loss_fn = nn.MSELoss() # 均方误差损失,将 Q(s,a) 回归到 TD 目标
episode_rewards = [] # 记录每个回合的总奖励,用于绘图
epsilon = epsilon_start
for episode in range(num_episodes):
state, info = env.reset()
done = False
total_reward = 0
while not done:
# --- 步骤 1: 与环境交互,收集转移 ---
action = select_action(q_net, state, epsilon)
next_state, reward, terminated, truncated, info = env.step(action)
done = terminated or truncated
# --- 步骤 2: 构造 TD 目标值 ---
# 将 numpy 数组转为 torch 张量,并增加 batch 维度 (1, dim)
state_tensor = torch.FloatTensor(state).unsqueeze(0)
next_state_tensor = torch.FloatTensor(next_state).unsqueeze(0)
with torch.no_grad():
# 当前状态-动作对的 Q 值 (用于后续计算损失)
current_q = q_net(state_tensor)[0, action]
# 计算 TD 目标值: r + γ * max_{a'} Q(s', a')
if done:
target = reward
else:
next_q = q_net(next_state_tensor) # shape: (1, 2)
max_next_q = torch.max(next_q).item() # 下一个状态的最大 Q 值
target = reward + gamma * max_next_q
# --- 步骤 3: 计算损失并更新网络参数 ---
# 注意:我们只关心执行动作 a 对应的 Q 值,但为了利用 PyTorch 的自动求导,
# 我们仍然对网络输出的所有 Q 值进行一次前向传播,然后只取出对应动作的那个值计算损失。
q_values = q_net(state_tensor) # 再次前向计算 (因为后续需要梯度)
predicted_q = q_values[0, action] # 当前网络给出的 Q(s, a)
# 目标值需要包装成张量,并保证与 predicted_q 在同一设备与数据类型
loss = loss_fn(predicted_q, torch.tensor(target, dtype=torch.float32))
# 标准的三步更新流程
optimizer.zero_grad()
loss.backward()
optimizer.step()
# --- 步骤 4: 转移到下一个状态 ---
state = next_state
total_reward += reward
# 回合结束后的记录与 epsilon 衰减
episode_rewards.append(total_reward)
epsilon = max(epsilon_end, epsilon * epsilon_decay)
# 每 50 回合打印一次平均奖励,方便观察训练进度
if (episode + 1) % 50 == 0:
avg_reward = np.mean(episode_rewards[-50:])
print(f"Episode {episode+1:3d} | Avg Reward (last 50): {avg_reward:.2f} | Epsilon: {epsilon:.3f}")
env.close()
return episode_rewards万事俱备,我们在主程序中设置好随机种子以保证可复现性,然后启动训练。训练结束后,用 Matplotlib 绘制每个回合的总奖励曲线,并叠加一条滑动平均线以便观察趋势。
python
# -------------------- 4. 运行并绘图 --------------------
if __name__ == "__main__":
# 固定随机种子,方便结果复现
np.random.seed(42)
torch.manual_seed(42)
print("开始训练朴素神经网络Q学习 (CartPole-v1)...")
rewards = train_naive_qlearning(num_episodes=500)
# 绘制学习曲线
plt.figure(figsize=(10, 5))
plt.plot(rewards, alpha=0.6, label='Episode Reward')
# 计算滑动平均(窗口大小 20),让曲线更平滑
window = 20
smoothed = np.convolve(rewards, np.ones(window)/window, mode='valid')
plt.plot(range(window-1, len(rewards)), smoothed,
color='red', linewidth=2, label=f'{window}-Episode Moving Avg')
plt.xlabel('Episode')
plt.ylabel('Total Reward')
plt.title('Naive Neural Q-Learning on CartPole-v1')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()执行这段代码后,控制台会输出类似下面的信息(具体数值可能因随机性略有差异):
python
开始训练朴素神经网络Q学习 (CartPole-v1)...
Episode 50 | Avg Reward (last 50): 21.02 | Epsilon: 0.778
Episode 100 | Avg Reward (last 50): 33.74 | Epsilon: 0.606
Episode 150 | Avg Reward (last 50): 51.02 | Epsilon: 0.471
Episode 200 | Avg Reward (last 50): 82.06 | Epsilon: 0.367
Episode 250 | Avg Reward (last 50): 130.34 | Epsilon: 0.286
Episode 300 | Avg Reward (last 50): 226.64 | Epsilon: 0.222
Episode 350 | Avg Reward (last 50): 283.24 | Epsilon: 0.173
Episode 400 | Avg Reward (last 50): 340.40 | Epsilon: 0.135
Episode 450 | Avg Reward (last 50): 267.60 | Epsilon: 0.105
Episode 500 | Avg Reward (last 50): 361.74 | Epsilon: 0.082对应的奖励曲线如图7.3所示。
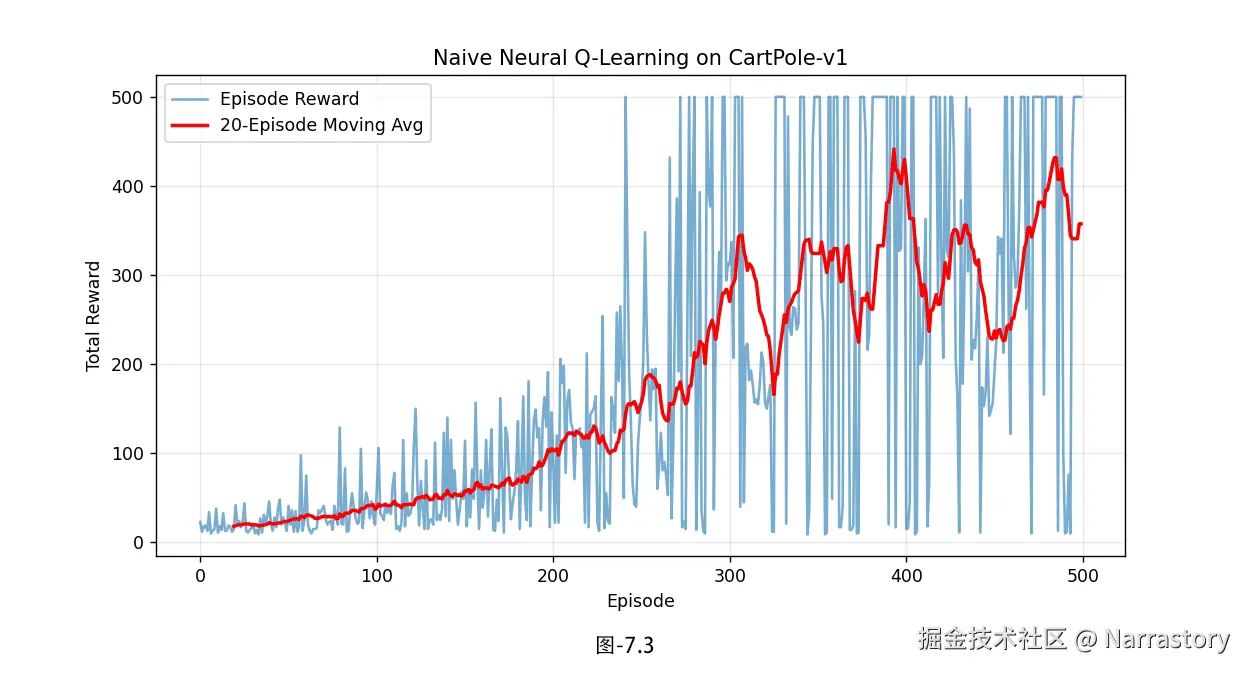
从图7.3中我们可以明显看到,虽然平均奖励整体呈上升趋势(说明智能体的确在进步),但单回合奖励的波动非常大------有时能达到满分的500(CartPole-v1的默认上限),但紧接着就暴跌到几十甚至更低,过一段时间又慢慢爬回去。这种"刚学会又忘记"的现象,正是朴素Q学习在使用神经网络近似时暴露出的经典问题。因此,虽然朴素神经网络Q学习在理论上正确,但在实践中几乎无法稳定地解决稍微复杂一点的任务。
END~
