Word2Vec 与 CBOW 算法实战:从词向量到上下文感知
前置知识 :本博客是"迁移学习:让AI站在巨人的肩膀上"系列的延续,聚焦 NLP 领域的词向量技术。
一、语言转换:从文本到数字的桥梁
自然语言处理的第一步,是将人类可读的文字转换为机器可理解的数字。这个过程总结为:
统计语言模型(早期)→ 神经语言模型(现代)→ 预训练词向量(当前主流)1.1 One-Hot 编码及其问题
最朴素的方式是 One-Hot(独热编码),例如"我爱北京天安门":
"我":[1, 0, 0, 0]
"爱":[0, 1, 0, 0]
"北京":[0, 0, 1, 0]
"天安门":[0, 0, 0, 1]存在的问题:
由于参数空间的爆炸式增长,它无法处理(N>3)的数据。没有考虑词与词之间内在的联系性。
当词库有4960个词时,输入维度高达 4 × 4960 = 19840,而向量中大量为0------这便是维度灾难。
1.2 词嵌入(Word Embedding):从高维稀疏到低维稠密
词嵌入的核心思想:
将高维度的词表示转换为低维度的词表示...这个较短的词向量维度是多大呢?一般需要在训练时自己来指定。现在很常见的例如300维。
[0.62, 0.12, 0.01, 0, 0, 0, 0, ..., 0] → 300维稠密向量
[0.1, 0.12, 0.001, 0, 0, 0, 0, ..., 0] → 300维稠密向量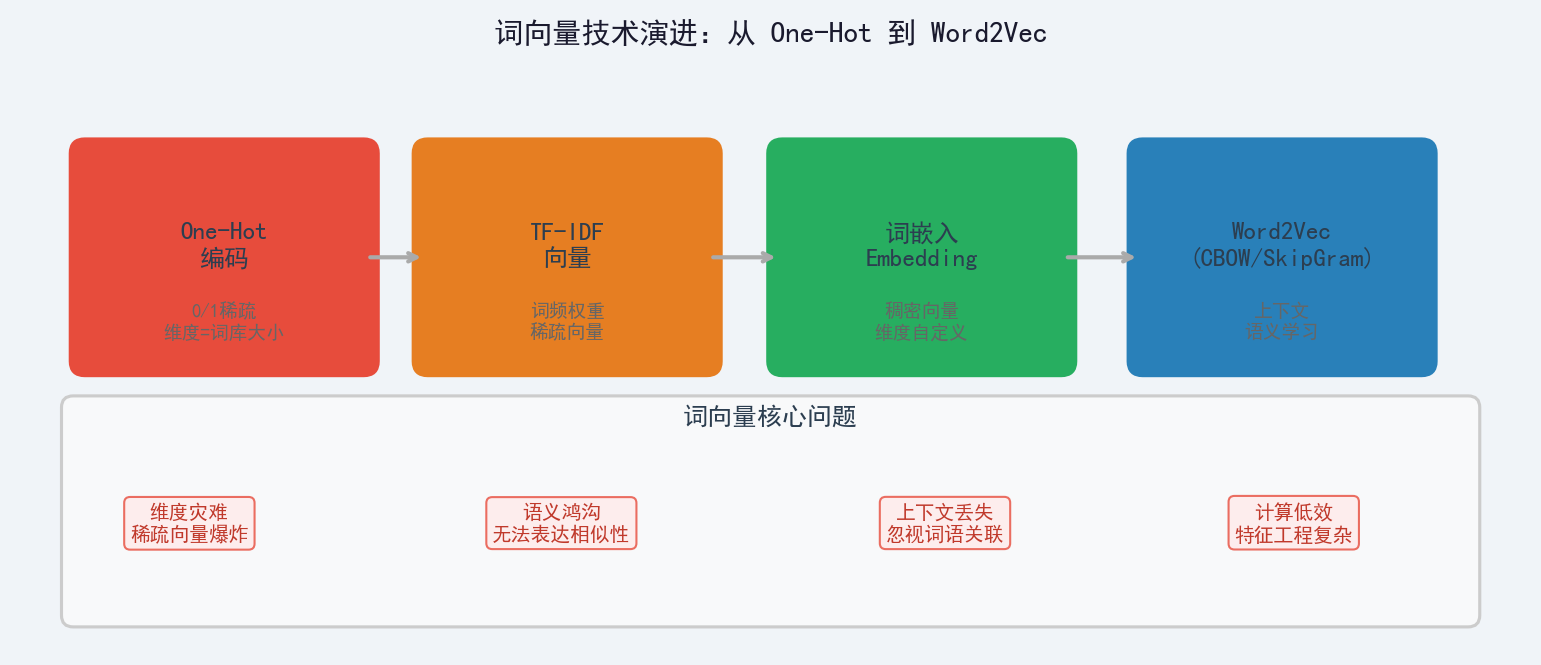
二、Word2Vec 两种模型
Google 的 Tomas Mikolov 等人在2013年提出了 Word2Vec,包含两个互逆的模型:
CBOW(连续词袋模型):
用上下文词汇预测当前词
"我 _ 北京" → 预测"爱"
SkipGram(跳字模型):
用当前词预测上下文词汇
"爱" → 预测"我"和"北京"| 特性 | CBOW | SkipGram |
|---|---|---|
| 预测方向 | 上下文 → 中心词 | 中心词 → 上下文 |
| 训练速度 | 快(多词→单词) | 慢(单词→多词) |
| 效果 | 大词库效果较好 | 小语料、生僻词效果更好 |
| 本博客应用 | 使用 | 原理对比 |
三、CBOW 模型结构详解
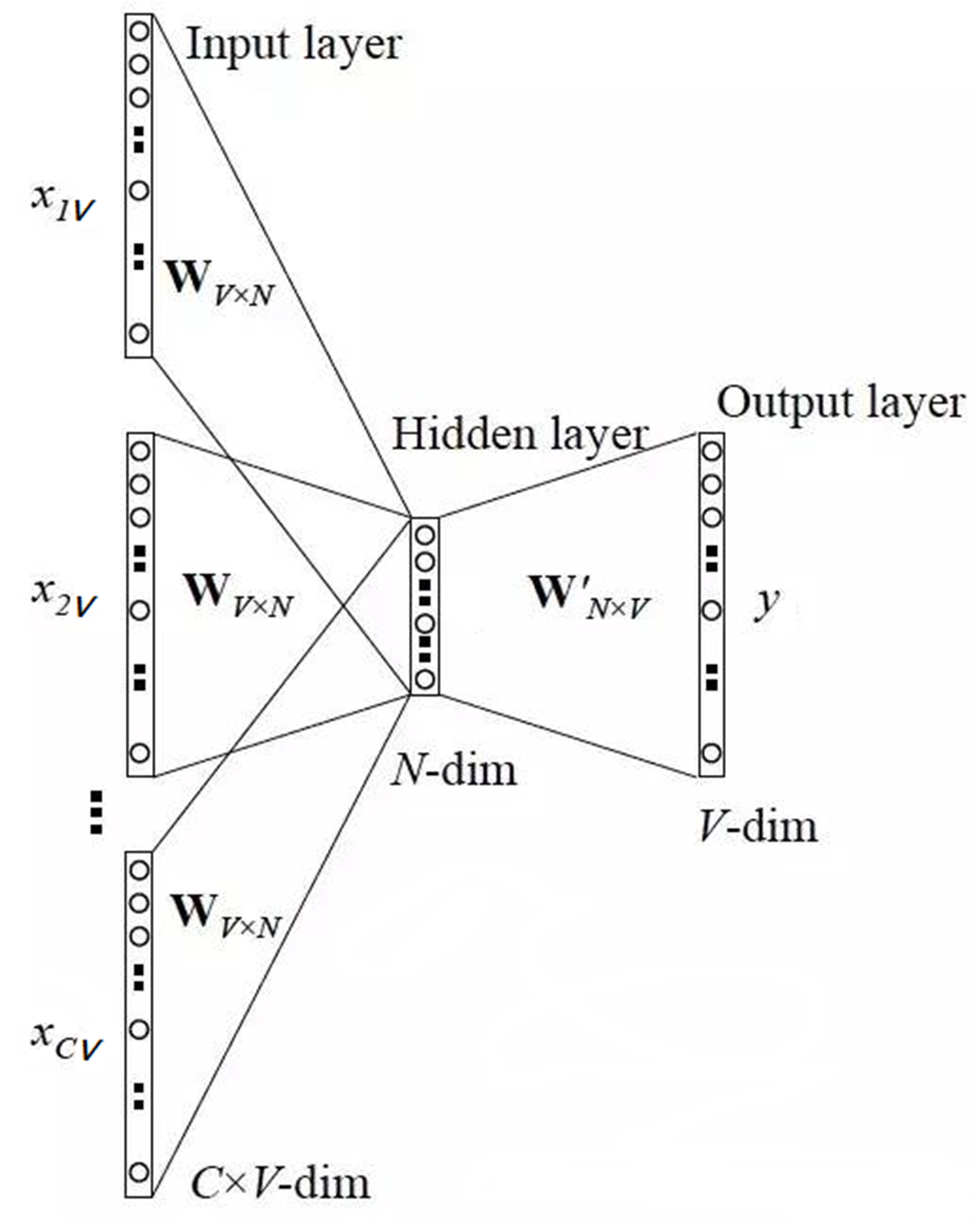
 模型训练最终为了得到嵌入层的嵌入矩阵v*n,v代表词表中词的个数,n代表压缩到n维
模型训练最终为了得到嵌入层的嵌入矩阵v*n,v代表词表中词的个数,n代表压缩到n维
3.1 模型五步流程
第1步:上下文词的 One-Hot 编码输入到输入层
第2步:分别乘以同一个矩阵 WV×N,得到各自的 1×N 向量
第3步:将多个 1×N 向量取平均为一个 1×N 向量
第4步:乘以矩阵 W'V×N,变成一个 1×V 向量
第5步:Softmax 归一化后输出概率向量关键 :CBOW 最终要的是
WV×N嵌入矩阵,训练完成后每一行就是一个词的 N 维向量表示。
3.2 PyTorch 实现解析
python
# ==================== 数据准备 ====================
CONTEXT_SIZE = 2 # 上下文各取2个词(左右各2个)
raw_text = """Morning routines shape our entire day.
Many people start with a glass of warm water...""".split()
vocab = set(raw_text)
word_to_idx = {word: i for i, word in enumerate(vocab)}
# 构建 (上下文, 目标词) 训练对
for i in range(CONTEXT_SIZE, len(raw_text) - CONTEXT_SIZE):
context = (
[raw_text[i-(2-j)] for j in range(CONTEXT_SIZE)] # 左边2个词
+ [raw_text[i+j+1] for j in range(CONTEXT_SIZE)] # 右边2个词
)
target = raw_text[i] # 中间预测词
data.append((context, target))
python
# ==================== CBOW 模型定义 ====================
class CBOW(nn.Module):
#vocab_size,embedding_dim分别代表词语的数量和词向量的维度
def __init__(self, vocab_size, embedding_dim):
super(CBOW, self).__init__()
#词嵌入层embedding可以用nn.Embedding构建
#是vocab_size*embedding_dim的词嵌入矩阵
self.embedding = nn.Embedding(vocab_size, embedding_dim) # WV×N
self.proj = nn.Linear(embedding_dim, 128) # 隐藏层
self.out = nn.Linear(128, vocab_size) # 输出层
def forward(self, inputs):
# 核心:sum 对 C 个上下文词的嵌入向量求平均
embeds = sum(self.embedding(inputs)).view(1, -1)
out = F.relu(self.proj(embeds))
out = self.out(out)
return F.log_softmax(out, dim=1) # NLLLoss 配套
python
# ==================== 训练过程 ====================
model = CBOW(vocab_size, 10).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
loss_fn = nn.NLLLoss()
model.train()
for epoch in range(200):
for context, target in data:
x_context = make_context_vector(context, word_to_idx).to(device)
y_target = torch.tensor([word_to_idx[target]], dtype=torch.long).to(device)
prediction = model(x_context)
loss = loss_fn(prediction, y_target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
python
# ==================== 推理与词向量提取 ====================
model.eval()
context_vector = make_context_vector(['people', 'usually', 'with', 'colleagues'], word_to_idx)
pred = model(context_vector)
max_idx = pred.argmax(1).item()
print("预测词:", idx_to_word[max_idx])
# 提取训练好的词向量(最终产物)
W = model.embedding.weight.cpu().detach().numpy() # shape: (vocab_size, embedding_dim)四、CBOW vs TF-IDF:六维度深度对比
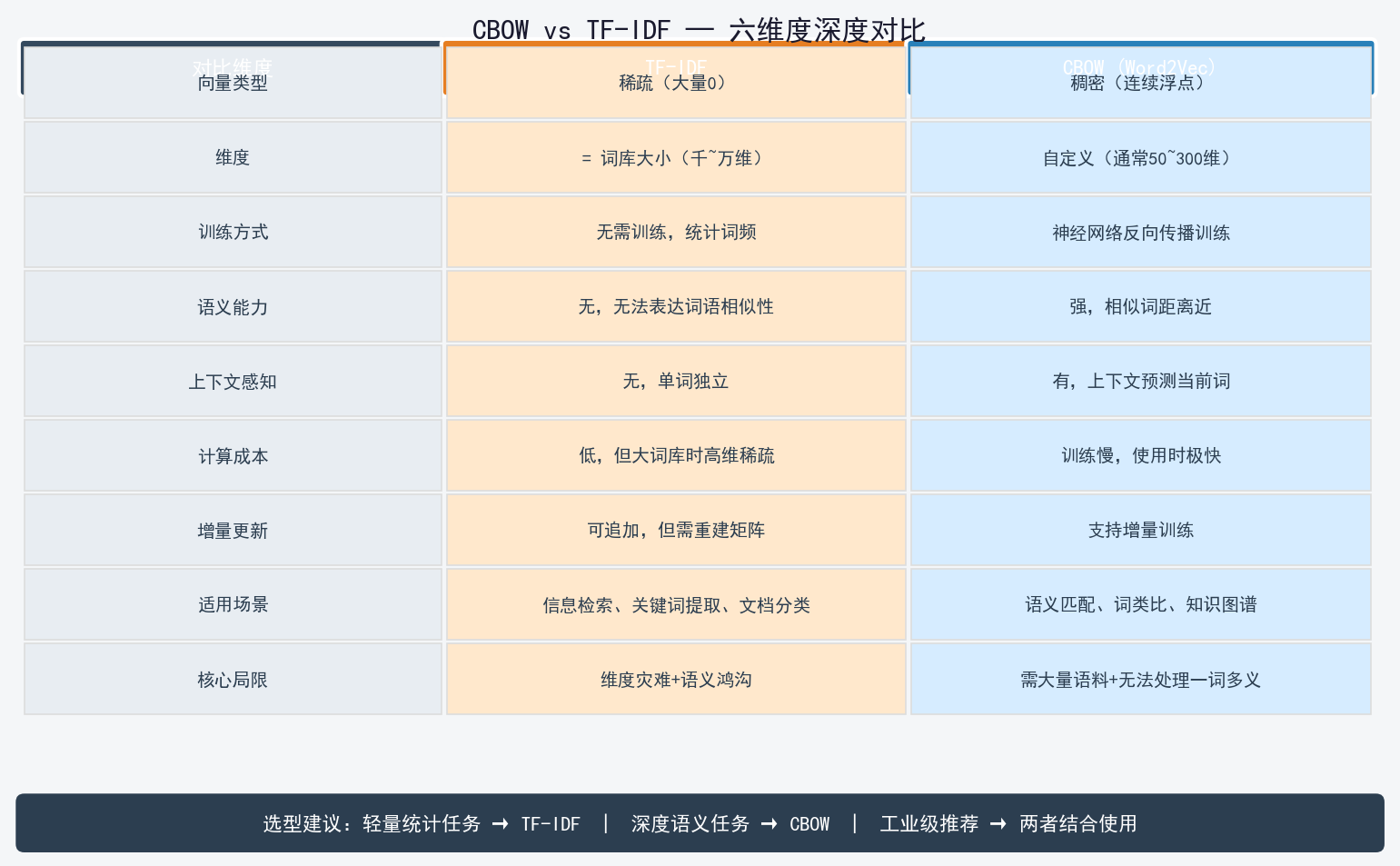
| 对比维度 | TF-IDF | CBOW (Word2Vec) |
|---|---|---|
| 向量类型 | 稀疏(大量0) | 稠密(连续浮点) |
| 维度 | = 词库大小(千~万维) | 自定义(通常50~300维) |
| 训练方式 | 无需训练,统计词频 | 神经网络反向传播训练 |
| 语义能力 | 无,无法表达词语相似性 | 强,相似词距离近 |
| 上下文感知 | 无,单词独立 | 有,上下文预测当前词 |
| 计算成本 | 低,但大词库时高维稀疏 | 训练慢,使用时极快 |
4.1 核心差异的本质
TF-IDF:词在文档中出现多少次 → 反映"这个词对这个文档重不重要"
CBOW:词在什么上下文中出现 → 反映"这个词和其他词有什么关系"4.2 选型建议
轻量统计任务 (关键词提取、文档分类)→ TF-IDF
深度语义任务 (语义匹配、词类比、知识图谱)→ CBOW
工业级推荐 → 两者结合使用
五、CBOW 优缺点总结与扩展方向
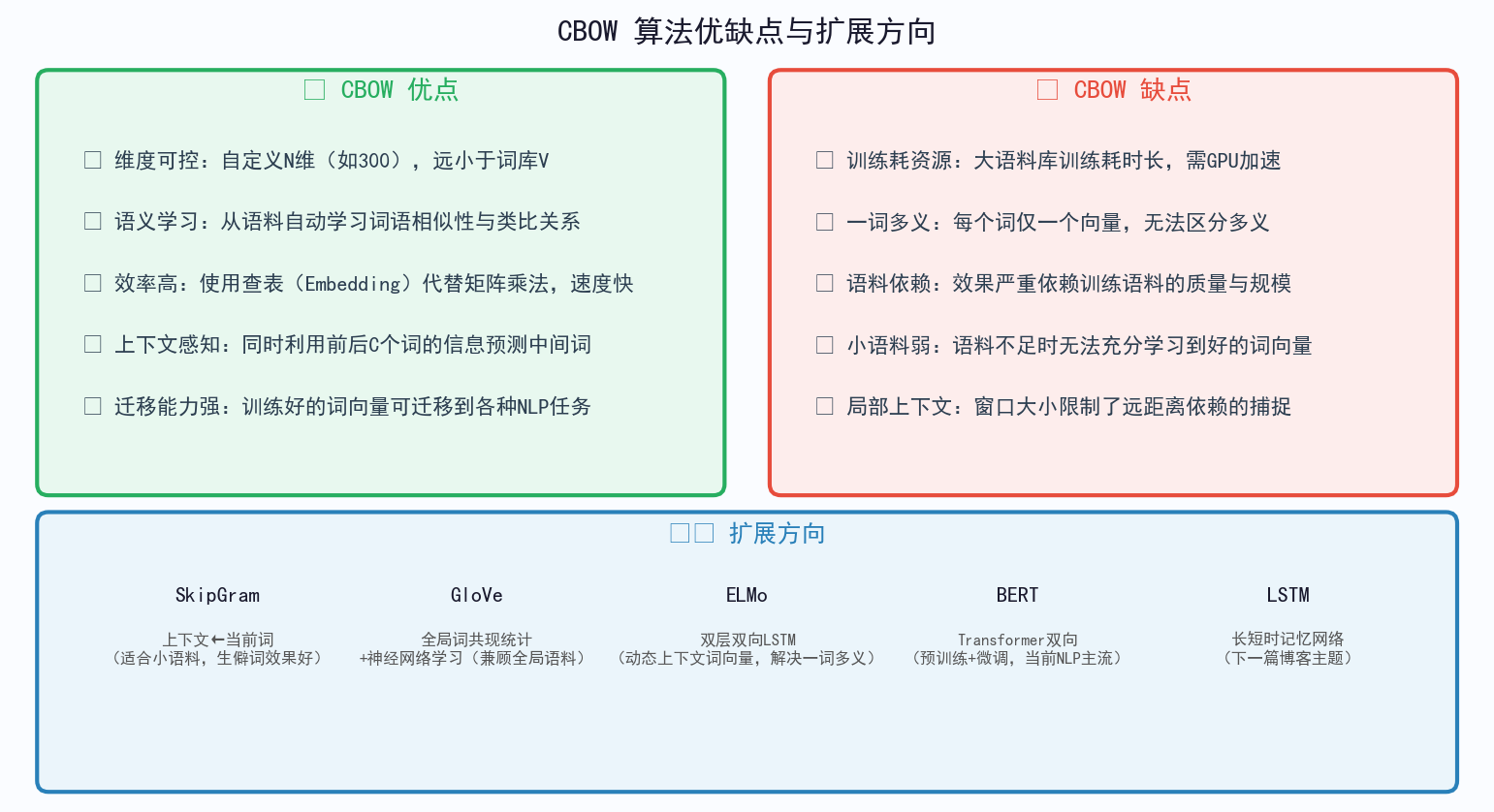
5.1 优点
| 优点 | 说明 |
|---|---|
| 维度可控 | 自定义 N 维(如300),远小于词库 V |
| 语义学习 | 从语料自动学习词语相似性与类比关系 |
| 效率高 | 使用查表(Embedding)代替矩阵乘法 |
| 上下文感知 | 同时利用前后 C 个词的信息预测中间词 |
| 迁移能力强 | 训练好的词向量可迁移到各种 NLP 任务 |
5.2 缺点
| 缺点 | 说明 |
|---|---|
| 训练耗资源 | 大语料库训练耗时长,需 GPU 加速 |
| 一词多义 | 每个词仅一个向量,无法区分多义 |
| 语料依赖 | 效果严重依赖训练语料的质量与规模 |
| 小语料弱 | 语料不足时无法充分学习到好的词向量 |
| 局部上下文 | 窗口大小限制了远距离依赖的捕捉 |
六、扩展方向:从 Word2Vec 到现代预训练模型
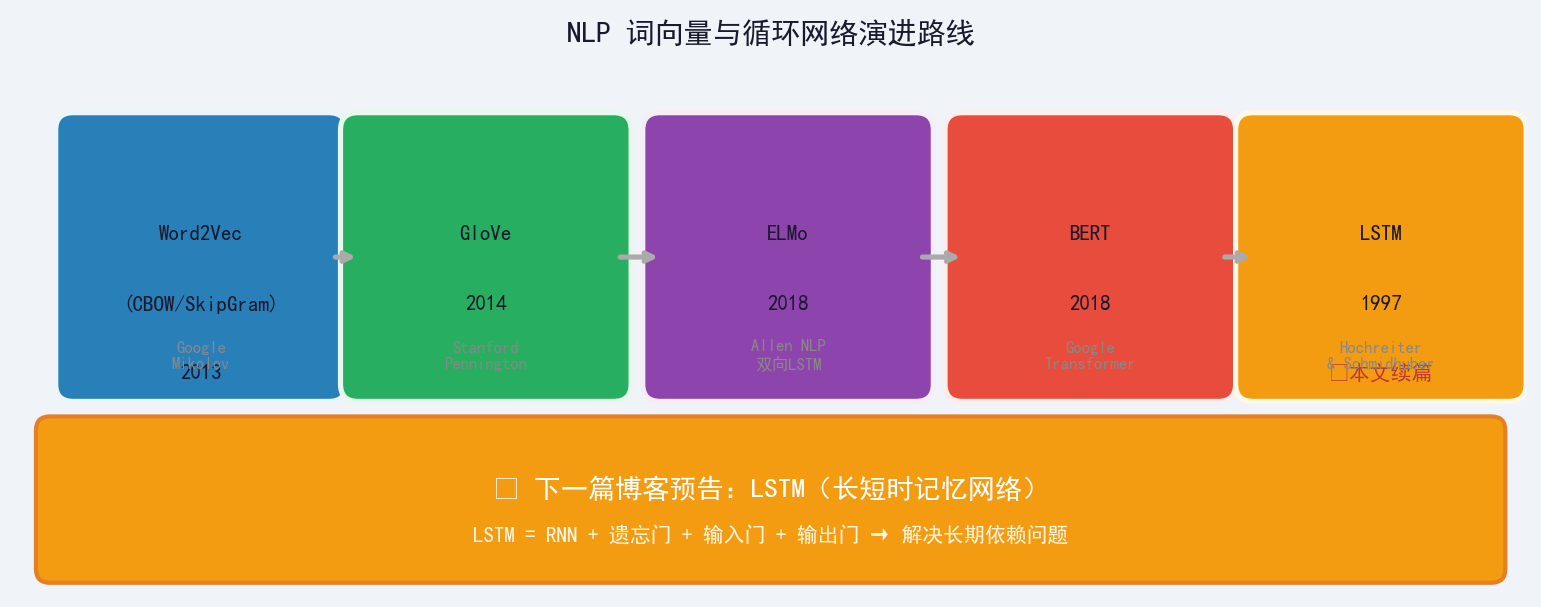
| 模型 | 年份 | 核心改进 |
|---|---|---|
| SkipGram | 2013 | CBOW 的逆过程,适合小语料和生僻词 |
| GloVe | 2014 | 全局词共现统计 + 神经网络,兼顾全局语料 |
| ELMo | 2018 | 双层双向 LSTM,动态上下文词向量(解决一词多义) |
| BERT | 2018 | Transformer 双向编码器,当前 NLP 预训练主流 |
| LSTM | 1997 | 长短时记忆网络,解决 RNN 长期依赖问题 |
七、总结与下篇预告
本篇核心知识点
CBOW 模型:
输入:上下文 C 个词的 One-Hot → 嵌入层(查表)
处理:C 个向量求平均 → 隐藏层(ReLU)→ 输出层(Softmax)
输出:概率最大的词 → 反向传播更新 WV×N 嵌入矩阵
产物:词向量矩阵 W,可用于下游 NLP 任务
CBOW vs TF-IDF:
TF-IDF = 词频统计 = 无语义
CBOW = 神经网络 = 有语义
两者互补,工业级任务可结合使用下篇预告:RNN 循环神经网络之 LSTM 网络
"LSTM(长短时记忆网络)是一种 RNN 特殊的类型,可以学习长期依赖信息。大部分与 RNN 模型相同,但它们用了不同的函数来计算隐状态。"
下篇将深入讲解:
- RNN 的长期依赖问题:梯度消失导致远距离信息丢失
- LSTM 三种门结构:遗忘门、输入门、输出门的工作原理
- LSTM vs 标准 RNN:为什么 LSTM 能"记住重要的,忘记无关紧要的"
- PyTorch LSTM 实战:如何用 LSTM 处理文本分类任务
系列导航
- 上一篇:迁移学习:让AI站在巨人的肩膀上
- 本篇:Word2Vec 与 CBOW 算法实战
- 下篇:RNN 循环神经网络之 LSTM 网络