第三章:前浪与沉寂------神经网络的史前史
!info
在上一章的结尾我们提到,统计学习走到了它的天花板:特征工程过于依赖人类专家,维度灾难又限制了其发展规模,在跨领域迁移方面能力不足。因此,要想打破这个天花板,就需要发展出一种能让机器自己从原始数据出发学习特征的方法。其实这种想法,早在 1950 年代就已经有人提出来了------但它在接下来三十年里几乎被遗忘,直到一批不肯放弃的人,在最艰难的时刻坚持了下来。
!question
神经网络的想法为什么在诞生后沉寂了三十年?那些年里,真正的障碍是什么?这批坚持者又是怎么度过那段漫长的寒冬的?
3.1、M-P 神经元的诱惑
1943 年,两个人的合作改变了计算机科学的走向,尽管这个影响要等几十年后才会完全显现。
沃伦·麦卡洛克(Warren McCulloch,1898-1969,神经生理学家兼数学家)是一位研究了多年人脑神经结构的精神科医生,其工作风格介于科学家和哲学家之间------他真正的想要解决的问题不是"神经元是怎么工作的",而是想弄清楚"思想是什么,它怎么在物质里发生"。
他的合作者沃尔特·皮茨(Walter Pitts,1923-1969,数学家)的故事,是整个神经网络历史里最令人唏嘘的一个。皮茨出生于底特律工人阶级家庭,从小靠钻研图书馆的书籍躲避继父的暴力。12 岁那年,他花了三天时间读完罗素和怀特海合著的《数学原理》,然后给伯特兰·罗素写信,指出书中的几处错误。罗素回信邀请他来剑桥求学,但皮茨家里没有钱。
15 岁时,他第一次从家中出走。17 岁那年,他来到芝加哥大学图书馆,读到了控制论先驱诺伯特·维纳(Norbert Wiener)关于信息和控制理论的早期手稿,随即找到维纳的地址登门拜访,呈上自己对手稿的数学评注。维纳读后立刻意识到这个少年的非凡才华,并将他引荐给了正在芝加哥大学的麦卡洛克。麦卡洛克当场邀请这个无家可归的少年住进自己的家里,这次的合作由此开始。
这两个人合写的论文------《神经活动内在观念的逻辑演算》(A Logical Calculus of Ideas Immanent in Nervous Activity)------发表在 1943 年的《数理生物物理学公报》(Bulletin of Mathematical Biophysics)上,全文只有 16 页,但信息密度极高:想要读懂它,需要同时精通逻辑学、神经生理学和数学分析,而写它的一个是精神科医生,另一个是 20 岁的流浪少年。
这篇论文的核心思想可以总结为:神经元的激发行为,可以被精确地抽象为逻辑计算。
他们将其描述为,每个神经元接受两类截然不同的输入信号:兴奋性输入 (excitatory)和抑制性输入 (inhibitory)。两者的权力完全不对等:抑制性输入具有绝对否决权 ,只要有任何一个抑制性输入处于活跃状态,无论兴奋性输入多强,神经元都不会激发(输出 0)。在没有活跃抑制性输入的前提下,如果活跃的兴奋性输入数量达到或超过某个固定阈值 θθθ,神经元就激发(输出 1);否则静默。
其中有一个细节值得强调:这个模型的输入是二值化的 (活跃或静默),也没有实数权重 ------每个兴奋性输入的"贡献"是等价的,神经元只是在计数。这和十四年后 Rosenblatt 的感知机(引入了可调的实数权重 W1,W2,⋯W_{1},W_{2}, \cdotsW1,W2,⋯)在机制上是不同的。他们提出的 M-P 神经元更接近真实生物神经元"全或无"(all-or-none)原则的抽象。
这里关键的数学结果在于,通过选择不同的连接方式和阈值,M-P 神经元可以实现基本的逻辑运算:
- AND :两个兴奋性输入,设置阈值 θ=2θ = 2θ=2 ------只有当两个输入都活跃时才激发
- OR :两个兴奋性输入,设置阈值 θ=1θ = 1θ=1------只要有任意一个活跃就激发
- NOT:一个抑制性连接------输入活跃时被否决,输入静默时自然激发
由于任何命题逻辑公式都可以由 AND、OR、NOT 组合表达,因此任意复杂的逻辑推理------在理论上------都可以由 M-P 神经元网络来实现。
这篇论文在当时引发的震动,远超AI圈子。冯·诺依曼 (John von Neumann)在读到论文后深受启发。这为他正构思的计算机体系结构提供了关键的理念支撑------尽管最终他做出了一个与生物原型相反的关键抉择:他设计的计算机采用了集中、同步的中央控制(中央处理器顺序执行指令),而摒弃了大脑分布式、异步、高度冗余的工作方式。但他在 1945 年那份奠定现代计算机架构的 "EDVAC 报告" 中,明确的引用了麦卡洛克-皮茨模型。这标志着一个关键的共识:在 1940 年代顶尖学者的眼中,"计算机如何用电路实现逻辑"与"神经元如何用电信号实现思维",是同一个根本问题在不同物质载体上的呈现。
维纳随后也把这项工作纳入他的控制论(Cybernetics)框架,作为"信息处理机器和生物神经系统之间的统一理论"。1946 年至 1953 年,梅西基金会(Josiah Macy Jr. Foundation)举办了一系列跨学科会议,史称梅西会议(Macy Conferences),专门讨论控制论和神经网络相关的问题。与会者包括维纳、麦卡洛克、冯·诺依曼、信息论创始人克劳德·香农------这是 20 世纪科学史上罕见的一次思想大汇聚。在那个年代,神经网络、控制论、信息论、计算机科学,被视为同一个宏大智识项目的不同侧面。感觉人类即将理解智能的本质,感觉一个新时代就在眼前。
但这段智识上的高光,对皮茨个人来说,以一种令人痛心的方式结束了。1954 年,控制论圈子因为一场复杂的人际纠纷而破裂。维纳与麦卡洛克这一派渐生嫌隙,皮茨夹在中间,两边都是他珍视的人。他对维纳有近乎父子般的情感,这场决裂让他深受打击,开始大量酗酒。据当时认识他的人描述,他烧毁了自己多年的未发表手稿,其中包括一篇被认为具有开创性的博士论文。在 1950 年代末,他几乎完全退出了科学研究的圈子。
1969年,皮茨在困顿中去世,年仅 46 岁。几个月后,麦卡洛克也相继离世。世界上最早的两位"人工神经网络研究者",在神经网络遭遇第一次质疑与寒冬的时刻,安静地退出了历史舞台。他们的论文如同一颗埋入冻土的种子,要借近半个世纪后深度学习的春风,才被重新发掘,赋予它迟来的、完整的历史意义。
但 McCulloch-Pitts 模型的光芒之下,始终横亘着一个根本的局限性:它的一切都是预先设定好的。网络的连接结构是人工设计的,每个神经元的阈值是人工设定的,甚至连哪些输入是"兴奋"、哪些是"抑制",也需要设计者提前指定。M-P 模型证明了"神经元网络能够计算",但它没有回答那个更激动人心的问题:"神经元网络能否自己学会计算?"
历史在等待 1957 年的一个关键的转折。
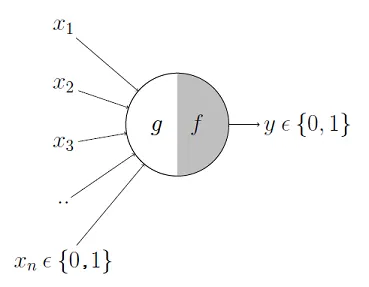
图 3.1:McCulloch-Pitts 神经元模型 ,它可以分为两个部分。第一部分 ggg 接收输入(相当于树突),执行聚合操作;基于聚合后的结果,第二部分 fff 做出决策。
3.2、感知机:罗森布拉特和他的机器
1957 年,弗兰克·罗森布拉特 (Frank Rosenblatt,1928-1971,康奈尔大学神经生物学家)提出了感知机(Perceptron)。
罗森布拉特不只是一个数学家,他是一个有着强烈媒体表演欲的人------而且他有充分的理由表演,因为他相信自己手里握着的,是改变世界的东西。
真实的感知机,是一台名叫 Mark I Perceptron 的物理机器,存放在康奈尔航空实验室。它占满了一整面墙,由 400 个光电管组成的 20×20 像素"视网膜"接收输入,连接到 512 个由电位计代表的权重,每个电位计由步进电机驱动------每当算法更新权重时,你可以听到电机转动的声音和电位计调节的咔哒声。这是一台会"学习"的机器,而且你可以听到它在学习。
1958 年,罗森布拉特在海军资助下为记者举行了一场演示。感知机在演示中学会了区分用不同图案标记的卡片------任务极其简单,但效果令人印象深刻。他向记者宣称,感知机"将最终能够识别人、读书、翻译语言、执行军事任务",并预言在未来几十年内,"感知机将具备意识、能够自我繁殖"。《纽约时报》刊登了这条新闻,将感知机描述为"胚胎型的电子计算机,海军预期它终将能够走路、说话、看见、书写、自我复制,并意识到自身的存在"。美国海军随即大规模资助了这项研究。
感知机的核心创新,不是网络结构(M-P 模型已经有了),而是学习规则。
罗森布拉特提出了一个简单但深刻的规则,今天叫做感知机学习算法:
- 随机初始化权重
- 喂入一个训练样本 xxx,计算输出 y^\hat{y}y^
- 如果 y^\hat{y}y^ 正确(和真实标签 yyy 相同),则不做任何改变
- 如果 y^\hat{y}y^ 错误:
- 如果预测为 0 但应该为 1:把触发了的输入对应的权重增加
- 如果预测为 1 但应该为 0:把触发了的输入对应的权重减少
- 重复,直到所有样本都分类正确
这个规则的直觉非常自然:做对了,什么都不变;做错了,调整导致错误的权重。
更重要的是,罗森布拉特能够证明 这个算法的收敛性------如果数据是线性可分的,感知机学习算法一定能在有限步内找到正确的权重。这个结果叫做感知机收敛定理(Perceptron Convergence Theorem)。
这是机器学习历史上第一个有数学保证的学习算法,在 1950 年代,绝大多数 AI 方法都是工程直觉:调调参数,看看效果。感知机引入了一种新的可能性:机器学习算法可以有理论保证,可以和数学严密性挂钩。这个追求,在后来的 SVM(VC 维理论)和深度学习的理论分析里,以各种形式延续。
1960 年代初,感知机在简单的识别任务上展现出了令人印象深刻的能力:识别简单的字母、区分基本的图形。研究者们兴奋不已,开始尝试把感知机用于更雄心勃勃的任务。康奈尔大学的小组尝试用它识别坦克和树木的航拍图像------据称成功了,但后来有人指出,训练集里所有的坦克照片是在阴天拍的,树木照片是在晴天拍的,感知机可能只是学会了区分光照,而不是车辆形状。这可能也是机器学习历史上最早的"数据集偏差"案例之一。
然而感知机的好景不长,因为 Minsky 要出手了。
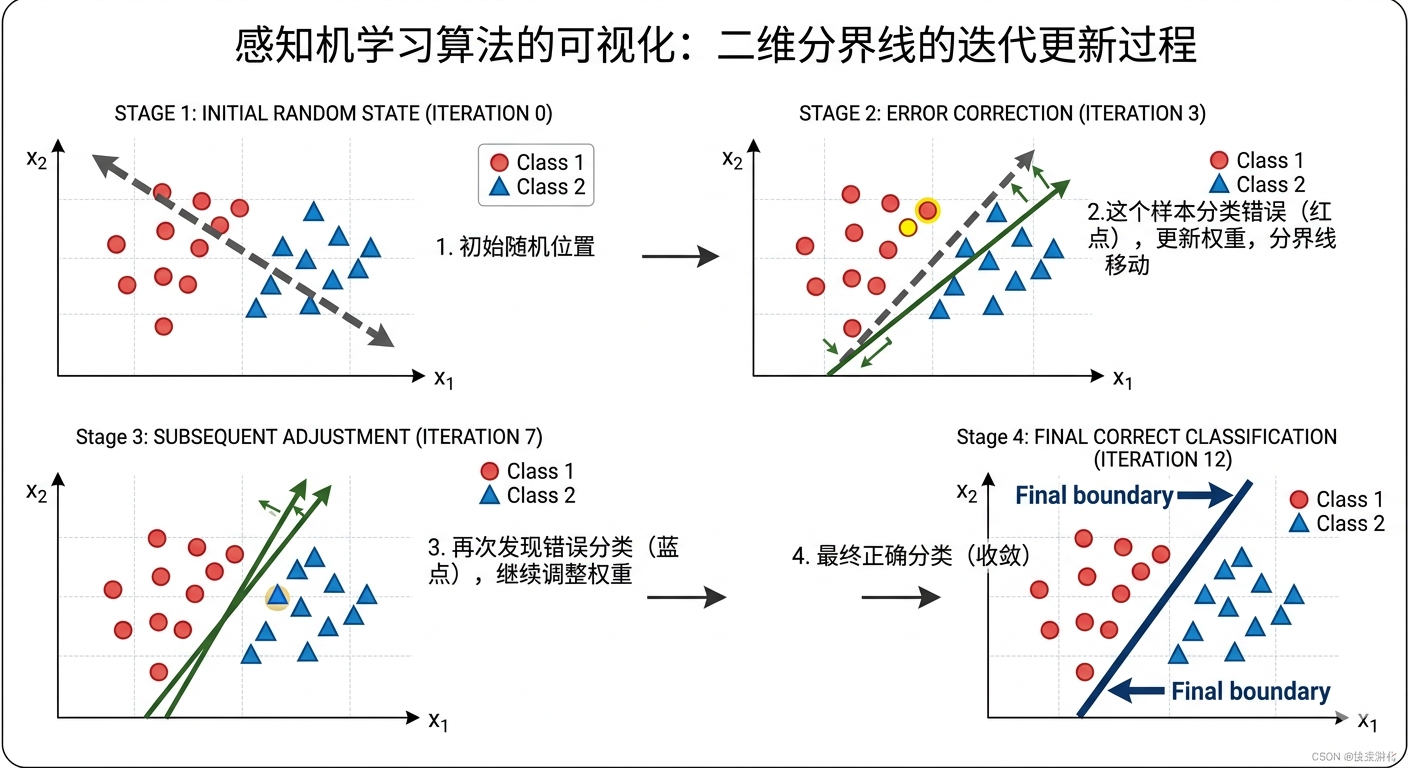
图 3.2:感知机学习算法的可视化
3.3、明斯基的一盆冷水
3.3.1《感知机》:科学史上最具影响力的批评之一
明斯基是 AI 领域的权威------达特茅斯会议的创始人之一,在学术界享有极高的声望。1969 年,他和 Seymour Papert 合著出版了一本书:《感知机》(Perceptrons: An Introduction to Computational Geometry)。在这本书里,感知机遭遇了无情的批判。
在这场批评背后,有一个鲜为人知的背景:明斯基和罗森布拉特,是布朗克斯科学高中(Bronx Science High School)的同届同学,都是 1948 年的毕业生。从中学时代起,这两个人就在互相竞争------都是老师眼中最聪明的学生,都在追问同一个问题:什么是智能?但他们走上了截然不同的路。明斯基相信符号逻辑是智能的本质,罗森布拉特相信统计连接是智能的本质。而这本《感知机》,在某种程度上,是一场延续了二十年的智识之争的终局裁决。
在这本书中,明斯基等人从数学上分析了感知机的能力和局限性,给出的结论鲜明而严厉:
单层感知机只能解决线性可分的问题。
这个结论本身并不是新发现------罗森布拉特的收敛定理已经说明了这一点("如果数据是线性可分的"是一个前提条件)。但 Minsky 和 Papert 用了一个极其具体的例子,把这个局限的严重性展示得触目惊心:
感知机无法解决 XOR(异或)问题。
XOR 是一个极其简单的逻辑运算:只有当两个输入不同时,输出才为 1。
如果把这四个点画在二维坐标上((0,0)→0, (0,1)→1, (1,0)→1, (1,1)→0),你会发现:没有任何一条直线,能把输出为 0 的点和输出为 1 的点分开。
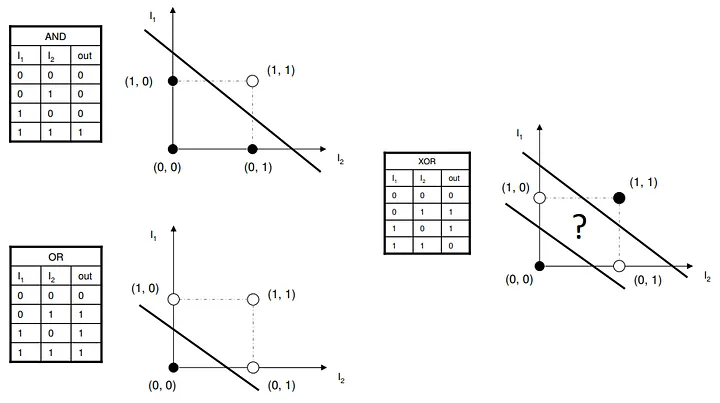
图 3.3:单层感知机只能解决 AND 或 OR 逻辑,无法处理 XOR 问题
Minsky 和 Papert 的论证非常清晰,数学上无懈可击。但他们的书中还有一个更具争议的结论,并用了一个脚注来表达:
"虽然理论上多层感知机(多层网络)可以解决这个问题,但我们认为,多层网络的训练在计算上是不可行的,相关的研究方向是没有前途的。"
这个脚注,成了科学史上影响最深远的"误判"之一。
他们低估了一件事:算法的创新能够从根本上改变可行性的边界。 他们对"计算不可行"的判断,建立在当时已知的训练方法(梯度下降在随机初始化的多层网络上效果极差)和当时的硬件上。但他们无法预见:十五年后会出现可以高效利用 GPU 的训练框架,二十年后会有 CUDA,二十六年后会有 ImageNet。技术的"可行性边界"不是固定的------它随着每一个工具、每一个数据集、每一个算法技巧的出现而移动。
3.3.2 寒冬的来临
《感知机》出版后的效果是立竿见影的,而且超出了大多数人的想象。
由于 Minsky 在学术界的权威地位,这本书几乎成了一纸判决书。政府资金开始从神经网络研究撤离。学术期刊开始拒绝神经网络相关的论文。研究生们被导师劝告:"不要做神经网络,这是个死路"。
仅仅几年内,神经网络研究从一个热门方向变成了一个禁区。
罗森布拉特没有活着看到这场争论的结果。1971 年 7 月 11 日,在他 43 岁生日那天,他在马里兰州切萨皮克湾驾船时意外溺水身亡。他的感知机理论,在他去世后沉寂了整整二十年,才随着深度学习的崛起被彻底证明。历史有时候以这种残酷的方式运作:最终正确的人,未必能看到自己被证明正确的那一天。
Minsky 和 Papert 判断的是"多层网络的训练不可行",但他们没有证明多层网络理论上也不可行。XOR 不能被单层网络解决,到底能不能被多层网络解决呢?答案显然是肯定的------只要在中间加一层隐藏层,就可以把 XOR 问题解决。
但要训练一个多层网络,就需要一个算法来告诉我们:每一层的权重应该如何调整,才能让整个网络的输出趋向正确?
3.4、反向传播的发现与重新发现
3.4.1 一个想法,多个源头
科学史上有一个有趣的现象:重要的思想往往会被独立地多次发现,因为一旦时机成熟,这个想法就仿佛"悬在天空中",等待着被摘下来。
反向传播(Backpropagation)就是这样的一个思想。
1960 年代 :控制理论领域的研究者,包括 Henry Kelley (1960)和 Stuart Dreyfus(1962),在优化控制系统时,发展出了通过链式法则反向传播梯度的数学方法。但这些工作在 AI 圈子里几乎没有引起注意。
1970 年 :芬兰数学家 Seppo Linnainmaa 在他的硕士论文里,详细描述了反向自动微分(Reverse Mode Automatic Differentiation)------这在数学上等价于反向传播。但这篇论文写的是数值计算,没有被 AI 研究者读到。
1974 年 :Paul Werbos 在他的哈佛博士论文里,明确地把反向传播应用到了神经网络的训练上。他写出了完整的推导,清晰地展示了如何通过链式法则计算每一层权重相对于损失函数的梯度,进而更新权重。
但 Werbos 的论文发表在 1974 年------神经网络寒冬最寒冷的时候。《感知机》出版才五年,资金已经撤走,研究者已经离场,他的工作几乎没有被任何人注意到。他后来在采访中描述了这段经历:他的导师告诉他,把神经网络写进博士论文是"职业自杀"。他坚持写了,但这篇论文在十年内几乎没有人引用。
这是历史的一种反讽:在最需要这个算法的年代,没有人相信神经网络值得研究;而等到人们重新相信神经网络的时候,这个算法已经被独立地重新发明了多次。
真正让反向传播复活的,是 1986 年的那篇论文。
3.4.2 1986 年:终于被听到的声音
大卫·鲁梅尔哈特 (David Rumelhart,1942-2011,加州大学圣地亚哥分校认知科学家)、杰弗里·辛顿 和 罗纳德·威廉姆斯(Ronald Williams,1955-,东北大学计算机科学家)在 1986 年发表了一篇论文:《通过反向传播误差来学习表示》(Learning Representations by Back-propagating Errors),发表在《自然》(Nature)杂志上。这个发表渠道本身就是一个信号------《Nature》是一个综合科学期刊,计算机科学论文很少在那里发表,作者们相信这不只是 AI 内部的一个技术进展,而是足以引起整个科学界关注的发现。
这篇论文做了几件关键的事:
一、清晰地阐明了反向传播算法。 虽然这个算法之前已经被发现过,但从未以这么清晰、可操作的形式被呈现。Rumelhart 等人的论文用的语言和符号,让 AI 研究者能够立刻理解和实现。
二、展示了多层网络能够学习"有意义的内部表示"。 这是论文中最重要的实验。他们证明,当一个多层网络被训练来完成某种任务时,隐藏层的神经元会自发地组织成有意义的特征表示------模型不只是"记住"了训练数据,而是发现了数据中的结构。
三、用 XOR 问题直接回应了 Minsky 的批评。 他们展示了多层网络(即使只有一个隐藏层)可以轻松解决 XOR------而且用反向传播可以学习到正确的权重,不需要人工设定。
在所有展示的实验里,最令人印象深刻的是一个家族关系推理任务(后来被称为"家谱实验")。他们构造了两个虚构家族的关系树,让网络学会回答"如果 Arthur 是 Colin 的父亲,那么 Arthur 的妻子是谁"这类问题。训练完成后,他们分析了网络隐藏层的激活模式,发现网络自发地学会了用一组神经元编码"这个人的国籍",用另一组编码"这个人所在的家族代际"------这些内部表示,没有人告诉网络应该用,而是网络自己从关系数据中发现的。模型自己发现了概念,这是当时最有说服力的证据之一。
3.4.3 反向传播:链式法则的威力
反向传播的数学核心,是微积分中的链式法则(Chain Rule)。
想象一个多层神经网络:输入层 → 隐藏层 1 → 隐藏层 2 → 输出层。
网络做出一个预测,我们计算出这个预测和正确答案的差距(损失函数)。现在我们想知道:要减小这个差距,每一个权重应该怎么调整?
从输出层开始,我们很容易计算出:输出层的权重变化,如何影响损失函数。这是直接的微分。
然后,通过链式法则,我们可以把这个影响"往回传":
- 输出层权重 → 对损失的影响
- 隐藏层 2 权重 → 通过改变隐藏层 2 的输出 → 改变输出层的输入 → 影响损失
- 隐藏层 1 权重 → 通过改变隐藏层 1 的输出 → 改变隐藏层 2 的输入 → 改变隐藏层 2 的输出 → 改变输出层的输入 → 影响损失
每一步都是链式法则的应用:∂Loss∂w1=∂Loss∂y2⋅∂y2∂h1⋅∂h1∂w1\frac{\partial Loss}{\partial w_1} = \frac{\partial Loss}{\partial y_2} \cdot \frac{\partial y_2}{\partial h_1} \cdot \frac{\partial h_1}{\partial w_1}∂w1∂Loss=∂y2∂Loss⋅∂h1∂y2⋅∂w1∂h1
这个过程从输出往输入方向反向进行------这就是"反向传播"名字的来源。
而这里的关键在于:这个计算可以高效地递归完成。每一层的梯度,可以用前一层(更靠近输出的层)已经计算好的梯度来表达。从输出层开始,依次往回算,每层的计算量和该层的权重数量成正比。整个网络的梯度计算,时间复杂度和前向传播(计算输出)基本相同。
这就是反向传播的工程美妙之处:它把"训练多层网络"这个看似极其复杂的问题,变成了一个高效、可并行、可自动化的算法。
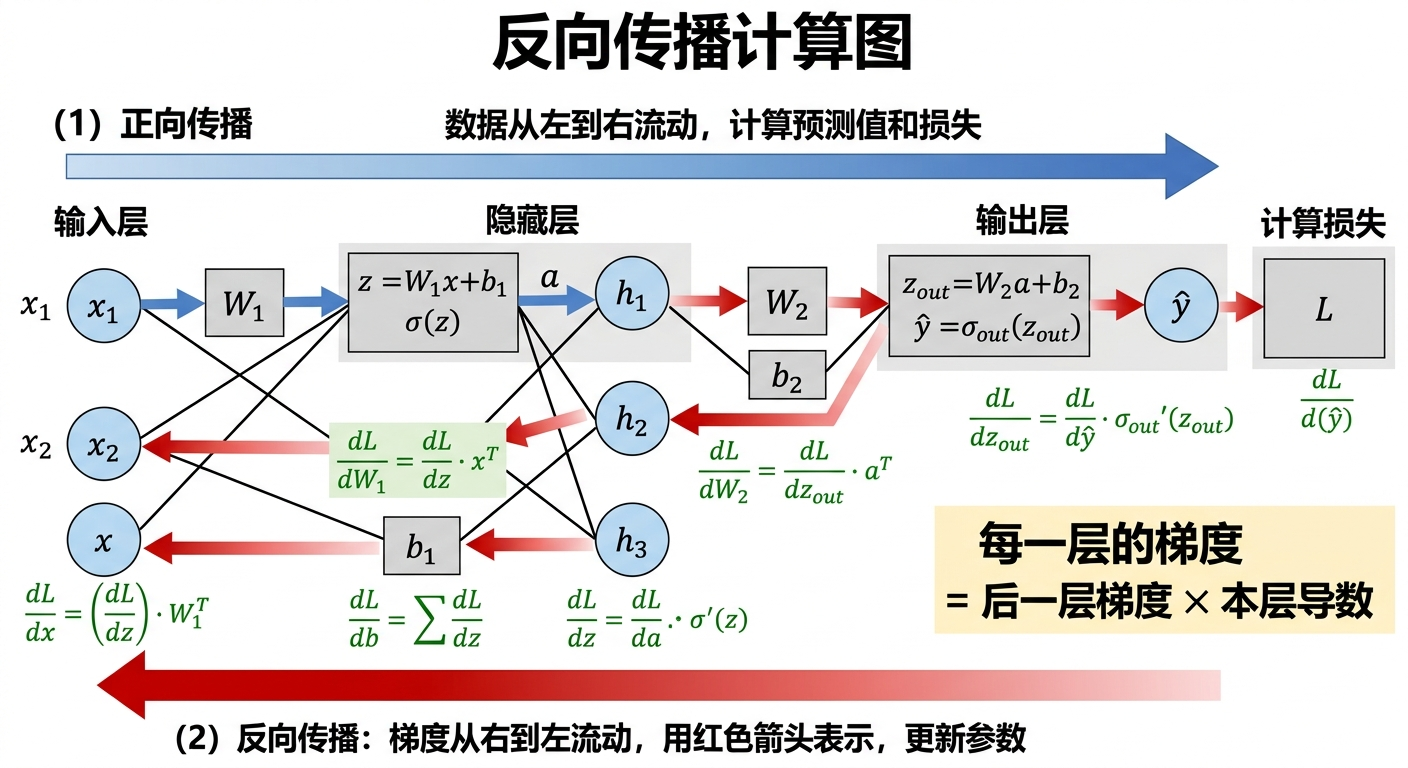
图 3.4:反向传播的计算图
3.5、反向传播之后为什么还不够
3.5.1 1986 年之后的期待与失望
Rumelhart 等人的论文发表之后,神经网络研究确实迎来了一次复兴。1980 年代末到 1990 年代初,有大量研究者开始尝试用多层网络解决各种问题。
但结果让人沮丧。
多层神经网络在很多任务上的表现,依然不如 SVM。有时候甚至不如简单的统计方法。
为什么有了反向传播,神经网络还是不行?
答案不是一个,而是多个紧密相连的问题。
3.5.2 障碍一:梯度消失(Vanishing Gradients)
这是反向传播最根本的技术难题,由 Sepp Hochreiter 在 1991 年的硕士论文中首次深入分析(Hochreiter 是 Schmidhuber 的学生)。
问题的来源,是 1980-1990 年代神经网络标配的激活函数------Sigmoid 函数:
σ(x)=11+e−x\sigma(x) = \frac{1}{1 + e^{-x}}σ(x)=1+e−x1
!tip
激活函数的核心目的是为模型引入解决非线性问题的能力,如果没有激活函数,多层网络在在数学上可以表达为,输出=W3(W2(W1⋅输入+b1)+b2)+b3\text{输出} = W_3(W_2(W_1 \cdot \text{输入} + b_1) + b_2) + b_3输出=W3(W2(W1⋅输入+b1)+b2)+b3而这本质上与单层神经网络并无区别,因为上式可以简化为:输出=W总⋅输入+b总\text{输出} = W_{\text{总}} \cdot \text{输入} + b_{\text{总}}输出=W总⋅输入+b总其中 W总=W3⋅W2⋅W1W_{\text{总}}=W_{3}\cdot W_{2} \cdot W_{1}W总=W3⋅W2⋅W1,引入激活函数的多层网络,其表达式为:y^=f(L)∘f(L−1)∘⋯∘f(1)(x){\hat{y}} = f^{(L)} \circ f^{(L-1)} \circ \cdots \circ f^{(1)}({x})y^=f(L)∘f(L−1)∘⋯∘f(1)(x) 其中 f(l)(h)=σ(W(l)h+b(l))f^{(l)}({h}) = \sigma({W}^{(l)}{h} + {b}^{(l)})f(l)(h)=σ(W(l)h+b(l))这里的 σ\sigmaσ 就是最著名的 sigmoid 激活函数符号。
Sigmoid 函数把任何实数压缩到 (0, 1) 的区间内,形状是一条 S 形曲线。它的导数有一个关键的数学性质:在 x 远离 0 的区域,导数接近于 0。
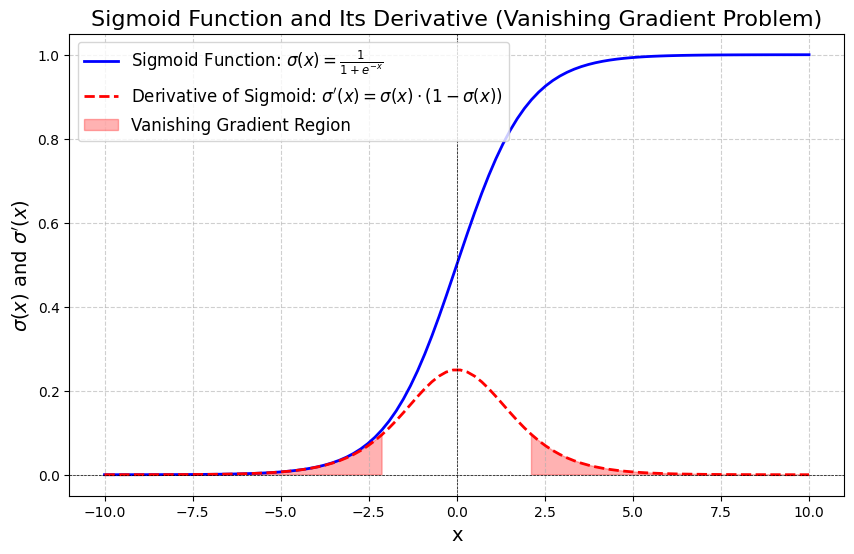
图 3.5:sigmoid 激活函数、其导函数以及梯度消失区间
具体来说,Sigmoid 函数的导数最大值是 0.25(在 x=0x=0x=0 时),在 ∣x∣>2|x| > 2∣x∣>2 时导数就已经非常小了。
这在反向传播中是致命的。反向传播的梯度计算是乘法链:
∂Loss∂w1=∂Loss∂yn⋅∂yn∂yn−1⋅...⋅∂y2∂y1⋅∂y1∂w1\frac{\partial Loss}{\partial w_1} = \frac{\partial Loss}{\partial y_n} \cdot \frac{\partial y_n}{\partial y_{n-1}} \cdot \ldots \cdot \frac{\partial y_2}{\partial y_1} \cdot \frac{\partial y_1}{\partial w_1}∂w1∂Loss=∂yn∂Loss⋅∂yn−1∂yn⋅...⋅∂y1∂y2⋅∂w1∂y1
如果每一层的导数都是一个小于 1 的数(比如 Sigmoid 导数的最大值是 0.25),那么把 10 层的导数乘起来:0.2510≈0.0000010.25^{10} \approx 0.0000010.2510≈0.000001。把 20 层的导数乘起来:0.2520≈10−120.25^{20} \approx 10^{-12}0.2520≈10−12。
这个数字如此之小,以至于浮点数精度都无法表示它。
其导致的结果是:越靠近输入层的权重,收到的梯度信号越微弱,甚至为零。这些层的权重几乎不更新------网络实际上只在最后几层学习,前面的层静止不动。
这就像一个很长的传话游戏:10 个人依次传递一条信息,每次传递都有损耗。第 10 个人能清楚地纠正自己的偏差,但这个纠正传到第 1 个人时,已经衰减到几乎为零。你不能告诉第 1 个人他需要怎么改------即使他有问题,也无法被告知。
这不只是训练慢的问题,而是网络根本上无法从数据中提取深层特征------因为深层特征来自前面的层,而那些层的权重无法被更新。深度网络在名义上是"深"的,但实际上只有最后两三层在学习。
3.5.3 障碍二:计算资源的匮乏
反向传播的计算量,和网络的规模成正比。
1980-1990 年代的计算机,速度大约是今天的个人电脑的百万分之一量级。在那个年代,训练一个有几万个参数的网络,需要几天到几周的时间。训练一个有几百万参数的网络,在计算量上基本不可行。
而真实世界的问题------比如从 ImageNet 这种规模(1000 类、每类数千张图)的数据集中学习图像识别------需要的网络参数量级是数千万到数亿。
在计算资源不足的情况下,研究者只能做小网络、用小数据。小网络的表达能力有限,很难解决复杂问题。小数据导致过拟合。这两个问题叠加在一起,让神经网络的实际效果很难令人满意。
这不是算法问题,而是基础设施问题------但在那个时代,没有任何明显的解决方案。CPU 每年的性能提升大约是 50%(摩尔定律),但要把神经网络的训练时间从几周缩短到几小时,需要的性能提升是几个数量级,不是几十个百分点。
有一种潜在的解决方案,直到 2000 年代初才被意识到:图形处理器(GPU)。GPU 最初是为了加速游戏中的图形渲染设计的------它们擅长的事情,恰好是大规模的矩阵乘法运算,而这也是神经网络训练的核心计算。
3.5.4 障碍三:数据的稀缺
统计学习时代,数据量是一个普遍的瓶颈,但对于特征工程比较好的方法(如 SVM),这个问题相对好处理------精心设计的特征可以有效压缩信息,让有限的数据发挥更大的作用。
但对于神经网络,尤其是深度多层网络,数据量的需求远高于统计学习方法。深度网络有大量的参数,而这些参数基本上是需要通过数据来约束。
1980-1990 年代,这样规模的数据集根本不存在。即使是当时规模最大的公开数据集,也只有几万到几十万个样本。
更严重的是,标注数据(有人工标签的数据)的获取尤其困难和昂贵。每张图片需要人来标注"这是猫",每条语音需要人来转录成文字。在互联网普及之前,大规模数据标注是一个几乎不可完成的任务。1990 年代最有名的图像数据集之一,MNIST,包含 7 万张手写数字图片------这在当时已经是一个很大的数据集了,但它只有 10 个类别,真实世界的视觉识别任务通常需要识别上千个类别,需要的数据量是 MNIST 的几个数量级以上。
这几个障碍------梯度消失、计算资源不足、数据稀缺------基本上共同构成了神经网络在 1990 年代无法起飞的根本原因。
3.5.5 工程师的处境:调参即玄学
这三个障碍从学术的角度说清楚是容易的。但它们落到实际的工程操作上,是什么感受呢?
试着还原一下 1990 年代,一个研究者决定训练一个五层神经网络的经历。
第一关:初始化权重 。没有 Xavier 初始化(2010 年才出现),没有 He 初始化(2015 年才出现)。教材上说"从均匀分布随机取一个小数",于是从 (−0.5,0.5)(-0.5, 0.5)(−0.5,0.5) 均匀随机初始化。但这个看似合理的做法,对 Sigmoid 网络来说往往不够。初始权重稍大,Sigmoid 在正向传播时就进入饱和区,梯度从第一步起就几乎为零;初始权重过小,激活值全部压缩到接近 0.5 的平坦区,也产生不了有效的梯度。怎样才算"合适"的初始化?当时没有系统的理论,研究者们凭直觉和积累的经验,各有各的秘方。
第二关:选学习率 。梯度消失造成的另一个工程难题是:不同层的梯度大小相差悬殊。输出层的梯度可能是 0.01,而第一层的梯度在经过多层 Sigmoid 的乘法链之后,可能已经萎缩到 10−810^{-8}10−8。用同一个全局学习率,若调大了,输出层的权重更新剧烈,训练不稳定;若调小了,前层权重几乎静止不动,相当于只在训练一个两层网络。2014 年出现的 Adam 优化器可以为每个参数自适应地调整学习率,但那是多年之后的事。1990 年代,研究者大多只有固定学习率的 SGD。
第三关:漫长的等待。用 1990 年代的 CPU,在几千个样本上训练一个五层网络,需要几天的时间。也许三天之后,损失函数没有明显下降。然后呢?是学习率太小?是初始化不好导致了梯度消失?是网络太深所以前层没有学到任何东西?是数据太少所以过拟合?还是根本思路有问题?
没有合适的、可以实时监测每层梯度分布的工具(例如 2015 年的 TensorBoard),没有成熟的诊断框架。你只能修改一个超参数,再等三天。这种过程,更接近于民间经验的积累,而不是可复现的工程科学。
这就是为什么当时的大多数从业者把 SVM 视为更可靠的选择:超参数少,有明确的理论保证,在小数据上性能稳定,训练速度快。"可调可控"比"理论上更强大"更实用------至少在条件成熟之前是如此。
研究者们在 1990 年代的处境,很像一个设计了完美发动机但没有燃料、也没有诊断仪器的工程师:方向是对的,但缺少让方向变成现实的条件,而且每次失败都难以定位原因。
3.6、漫长的等待:坚守者的故事
3.6.1 Hinton 的不放弃
1980 年代,当大多数 AI 研究者都转向 SVM 和统计学习的时候,有几个人却选择了坚守神经网络这条路线。
Geoffrey Hinton 是其中最重要的一个。
Hinton 出生于英国,有一段不寻常的学术历程:他先学了实验心理学,然后转向了 AI------因为他相信,理解人类的认知过程和构建人工智能是同一件事。他读博士时,导师对他的神经网络研究不感兴趣,所以他基本上是自学的。
Hinton 在整个 1990 年代做的不只是"坚持",他在坚持的过程中持续在研究真实的问题。这些问题最终都成了深度学习革命的重要组成部分:
- 如何无监督地训练网络? 如果有标签数据很少,能不能先用大量无标签数据预训练,再微调?这个问题促使他研究玻尔兹曼机 (Boltzmann Machine)和亥姆霍兹机(Helmholtz Machine)------一类能同时学习"如何识别"和"如何生成"的生成模型。虽然这些模型在 1990 年代难以有效训练,但它们为后来的生成式 AI 打下了概念基础。
- 权重初始化和激活函数的问题:随机初始化真的是最好的吗?有没有更聪明的方式让深度网络从一开始就处于更容易训练的状态?
Hinton 也面临着职业上的压力。在神经网络最不受欢迎的 1990 年代,写关于神经网络的论文很难发表,申请神经网络方向的资金很难成功,招收对神经网络感兴趣的学生也很难------因为学生要考虑找工作。
在整个 1990 年代,他组织了一个规模很小、几乎不公开的工作坊,专门邀请神经网络方向的研究者。不是为了发表什么大发现,而是为了让这些散落在各地的人知道:还有其他人在做同样的事,你不是一个人在孤独地坚守一件傻事。在一个方向被主流宣告死亡的年代,这种团体感本身,就是一种维持下去的力量。
他在接受采访时曾经描述过那段时期的感受:
"我知道我们的方向是对的,但我不知道什么时候才能证明这一点。有时候我想,也许我要在退休之前都无法看到这一天。"
3.6.2 LeCun 和卷积网络
Yann LeCun 是另一个在神经网络寒冬期间做出了重要贡献的人。
LeCun 来自法国,在 Hinton 的指导下完成了博士后研究,然后加入了 AT&T 贝尔实验室。他的工作重点是把神经网络用于手写数字识别------一个有实际商业需求的问题(自动读取支票上的金额)。
1989 年,LeCun 发表了卷积神经网络(Convolutional Neural Network,CNN)的早期形式。他的核心洞察是:对于图像识别,可以用专门设计的、利用图像空间结构的网络架构(卷积核)来替代全连接层,大幅减少参数量,同时提升对平移和变形的鲁棒性。
1998 年,他发表了完整版的 LeNet-5------一个可以高精度识别手写邮政编码的卷积网络,被部署到了美国邮政系统中,每天自动读取大量信件上的邮编。据估计,到 1990 年代末,美国大约 10% 的支票是用 LeCun 的系统读取的。这是最早的商业化深度学习应用之一------不是实验室里的演示,而是真实运行在真实邮件里的系统。
但在 1990 年代末,LeNet-5 的影响力非常有限。它在邮政编码识别上的成功,被研究界解读为"在一个特定的小问题上有效",而不是"深度学习是一种通用的有效方法"。
SVM 在那个时代的文本分类和其他图像分类问题上,效果往往不比 CNN 差,甚至更好------而且 SVM 有理论保证,CNN 没有。事后看,这种比较在某种程度上是不公平的:1990 年代用于比较的数据集规模太小,正好处于 SVM 最擅长的范围(小数据、有限类别),CNN 的优势需要在更大规模的任务上才能显现。但 1990 年代的研究者没有机会做那个更大的实验,因为更大的数据集还不存在。
3.6.3 Bengio 的第三极
如果说 Hinton 是深度学习的哲学奠基人,LeCun 是工程实践的先驱,那么约书亚·本吉奥(Yoshua Bengio,1964-,蒙特利尔大学教授)则是深度学习在自然语言理解方向上的拓荒者。
本吉奥在 1990 年代就开始研究如何用神经网络处理序列数据------语言模型、机器翻译、语音识别。这是一个比图像识别更难的领域,因为语言里的依存关系是长程的(一个词的意义可能取决于几十个词之前的上下文),而当时的循环神经网络在长序列上训练时梯度消失问题尤其严重。
本吉奥在 2003 年发表的论文《语言模型的神经网络方法》(A Neural Probabilistic Language Model),引入了词嵌入(Word Embedding)的核心思想------用连续向量表示词语,让语义相近的词在向量空间里也彼此接近。这个思想在十年后成了整个 NLP 领域的基础,但在 2003 年,它没有能够翻起多大的浪潮。

图 3.6:左起,Bengio,Hinton,LeCun
这就是那个时代三个坚守者的共同处境:做出了真实的、重要的进展,但无法让大多数人停下来认真看一眼。2006 年之后,Hinton、LeCun、Bengio 三人,形成了深度学习的"三角形"------三个城市,三种研究风格,彼此知道对方在做什么,偶尔协作,共同成为这个领域在漫长黑暗时期的核心。2018 年,三人共同获得图灵奖,被称为"深度学习的教父们"(Godfathers of Deep Learning)。
这就是 1990 年代到 2000 年代初的状态:一小批坚守者,在做出了真实的进展,但这些进展无法让他们在与 SVM 的竞争中占据明显优势。大多数研究者认为,他们不过是在一个没有前途的方向上浪费时间。
3.7、2006 年:转折点的预兆
3.7.1 深度置信网络
2006 年,Geoffrey Hinton、Simon Osindero 和 Yee-Whye Teh 在《科学》杂志上发表了一篇论文:《深度置信网络的快速学习算法》(A Fast Learning Algorithm for Deep Belief Nets)。这篇论文提出了一种新的训练深度网络的策略:逐层预训练(Layer-wise Pre-training)。
想法是这样的:直接端到端地训练深度网络,梯度消失会让前面的层无法更新。但如果我们先逐层地无监督地预训练每一层------让每一层学会对输入进行一种有意义的表示------然后把这些预训练好的层叠起来,再进行监督微调,结果可能会好很多。
Hinton 的直觉是:预训练阶段给了每一层一个好的初始值,让反向传播在微调时不需要从随机噪声开始学习,大大缓解了梯度消失的问题。这本质上是一种"分而治之"的策略------不要同时训练所有层,先让每一层单独学好自己的表示,再一起微调。
这个方法在当时的计算条件下,确实让深度网络的训练变得更稳定了。Hinton 的论文展示了一个有若干隐藏层的深度网络,在手写数字识别(MNIST)上达到了 1.25% 的错误率------略低于当时最好的 SVM 结果(大约 1.4%)。这是神经网络在二十年后第一次明确地在一个标准测试上超过 SVM。
这篇论文在学术界引发了相对克制的兴奋------因为它依然是在一个有限的问题上展示的,MNIST 被认为是一个"太简单"的基准,很多人仍然持怀疑态度。但对于 Hinton 实验室的人来说,这是一个具体的证据:方向是对的,下一步是更大的数据、更多的算力。
与此同时,2006 年前后,一件深刻影响整个 AI 历史的基础设施变化正在悄悄发生。
3.7.2 NVIDIA 的意外礼物
GPU,俗称显卡,在 1990 年代末到 2000 年代,随着 PC 游戏产业的爆发,变得越来越强大和越来越廉价。GPU 的设计目标是加速 3D 游戏的图形渲染------它需要并行地处理大量三角面片的坐标变换和光照计算,这些运算的本质是大规模矩阵乘法。
神经网络训练的核心计算,也是大规模矩阵乘法。
2006-2007 年,Hinton 的学生 Ruslan Salakhutdinov 和 Bryan Graham 开始尝试用 GPU 训练神经网络。结果令他们吃惊:速度提升了 10-50 倍 。同期,斯坦福大学的 吴恩达(Andrew Ng) 也开始系统地把 GPU 用于深度学习训练,发现了类似的加速效果。
这个发现的意义,不只是"训练速度更快"。它意味着:
- 以前需要几周的实验,现在几天甚至几小时就能完成
- 可以训练更大的网络------因为计算资源的瓶颈被部分解除
- 可以在更多数据上训练------因为时间不再是不可克服的约束
GPU 成了神经网络革命的隐性推手。这不是一个 AI 研究者的发明,而是游戏产业发展的副产品------一个在历史上屡见不鲜的规律:一个领域的基础设施革新,往往在完全意想不到的地方开花。
2007 年到 2011 年,Hinton 实验室开始系统地用 GPU 训练深度网络,探索什么样的架构在什么样的数据上能有多深、多好。这五年是一个低调的准备期:论文数量不多,轰动效应不大,但每一年都有新的实验结果累积,每一年深度网络能处理的问题都稍微复杂了一点。Hinton 的学生 亚历克斯·克里泽夫斯基(Alex Krizhevsky)在这段时间里开始构建一个比以往任何网络都深、都宽的卷积网络架构,利用两块 GPU 的并行训练能力,把网络推到了此前根本无法训练的规模。2012 年,这个网络参加了 ImageNet 竞赛,用一个令所有人震惊的结果,宣告了深度学习时代的正式到来。
3.8、数据、算力、算法,缺一不可
当我们回顾这段历史往事的时候,一个问题自然地浮现出来:既然方向是对的,为什么没有更早发生?
答案是:数据、算力、算法,这三个条件需要同时成熟,缺一不可。
3.8.1 条件一:数据
2009 年,李飞飞 (Fei-Fei Li,1976-,斯坦福大学教授)和她在斯坦福大学的团队,历时三年,发布了 ImageNet 数据集:这份数据集中包含 1400 万张图片,20000 个类别,全部带有人工标注。
这个数据集的规模,在此之前是完全不存在的。它的出现,不是因为有什么技术突破,而是因为有人相信"大规模标注数据对于训练视觉系统是必要的",并且用了极大的工程努力把它做出来。
李飞飞在推动这个项目时,遭到了很多来自同行的质疑:很多计算机视觉研究者认为,算法才是最重要的,数据只是工具,不值得花如此大的精力去收集和标注。李飞飞的判断恰好相反:视觉系统需要在海量、多样化的图像上训练,才能学到足够泛化的特征,算法上的精妙无法弥补数据的不足。ImageNet 的图片,通过亚马逊的众包平台 Mechanical Turk 进行标注,花了三年时间,雇用了来自 167 个国家的标注工人。这是一场数据工程运动,不是一次算法研究。
从 2010 年起,ImageNet 举办年度竞赛(ILSVRC),让不同的算法在同一数据集上比拼图像分类准确率。这个竞赛成了整个视觉识别领域的基准。
3.8.2 条件二:算力
GPU 为什么天然适合神经网络训练?答案在于两者的核心计算结构几乎完全一样:矩阵乘法。3D 游戏里渲染一帧画面,需要把屏幕上的数十万个三角形同时做坐标变换和光照计算------这是大量相互独立的乘法和加法操作,用 GPU 的数千个并行核心同时处理,速度远超只有几十个核心的 CPU。神经网络前向传播和反向传播里的核心操作,也是大规模矩阵乘法(每一层的权重矩阵乘以激活向量)。这两件事恰好是同一类计算------GPU 因为游戏需求而变得强大,然后意外地成了深度学习的完美加速器。
NVIDIA 在 2007 年推出了 CUDA(Compute Unified Device Architecture),一套让程序员可以直接在 GPU 上编程的工具,大大降低了使用 GPU 做通用计算的门槛。在 CUDA 出现之前,要用 GPU 做神经网络训练,需要把计算伪装成图形渲染任务来绕过 GPU 的图形专用接口------这是一种痛苦的黑客手段。CUDA 让这件事变得直接可行。
3.8.3 条件三:算法
梯度消失问题需要新的解决方案。这里的关键不是一个单一的突破,而是三个算法技巧的叠加------每个单独看都很简单,但三者合在一起,让深度网络的训练从"不稳定的黑艺术"变成了"可复现的工程"。
ReLU------一个简单到令人尴尬的答案
解决梯度消失的方法,事后看来简单到令人难以置信:换一个激活函数。
Vinod Nair (文诺德·纳尔,谷歌 Brain 研究员)和 Hinton 在 2010 年正式推广了 ReLU(Rectified Linear Unit,修正线性单元),它的数学形式极其简洁:
f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x)
正数原样输出,负数输出零。就这样。
为什么这个改动从根本上解决了梯度消失?关键在于导数:Sigmoid 在 ∣x∣>2|x| > 2∣x∣>2 的区域导数趋近于零;而 ReLU 在 x>0x > 0x>0 时导数恒为 1 。在反向传播的梯度乘法链中,ReLU 层不会压缩梯度。10 层 ReLU 网络,梯度能原样从输出层传递到第一层;而同样深度的 Sigmoid 网络,梯度早已衰减到 0.2510≈10−60.25^{10} \approx 10^{-6}0.2510≈10−6,浮点数几乎表示不了。
ReLU 并不是 2010 年才被发明------类似的分段线性函数在工程数学里早就存在。它迟迟没有被采用,一个原因是研究者认为"不光滑"的激活函数会让优化变得困难(在 x=0x=0x=0 处不可微),另一个原因是 Sigmoid 的 S 形曲线有"神经元激发概率"的生物学解释,显得更"合理"。直到实验证明,ReLU 不只是更容易训练,还通常能达到更好的最终精度,大家才放弃了对数学美感的执念。
ReLU 也有一个工程问题需要注意:死亡 ReLU(Dying ReLU)。如果某个神经元接收到的输入长期为负,它的输出和梯度都是零,相当于永久"死了",不论后续如何训练都不会再被更新。这催生了 Leaky ReLU(负半轴保留一个小斜率)和 He 初始化等配套方案,在 AlexNet 之后的几年里被逐一完善。
Xavier 初始化------解决训练之前的问题
有了 ReLU 之后,权重初始化的问题依然存在。如果初始权重不合适,训练从第一步就陷入糟糕的状态,后续再怎么调整也很难恢复。
Xavier Glorot(塞维尔·格洛特,谷歌 Brain 研究员)和 Yoshua Bengio 在 2010 年系统分析了这个问题。他们发现:随机初始化的权重,会导致信号在经过多层网络时方差剧烈变化------有时越来越大(梯度爆炸的前兆),有时越来越小(梯度消失的另一个来源)。
Xavier 初始化的核心思想是:让每一层激活值的方差在前向和反向传播中都尽量保持稳定。具体来说,权重从以下范围均匀采样:
W∼U(−6nin+nout,6nin+nout)W \sim \mathcal{U}\left(-\sqrt{\frac{6}{n_{in} + n_{out}}}, \sqrt{\frac{6}{n_{in} + n_{out}}}\right)W∼U(−nin+nout6 ,nin+nout6 )
其中 ninn_{in}nin 是该层的输入维度,noutn_{out}nout 是输出维度。直觉上:输入越多,每个权重应该越小,以防止输出方差被放大;输入越少,权重可以稍大,以防止信号消失。这是一种用方差分析倒推出来的"在方差上保持平衡"的初始化策略。
这个方法对实践者的效果是立竿见影的:用 Xavier 初始化的网络,从训练第一步起,各层的激活分布就处于合理范围,梯度能正常传播,训练过程也比过去要稳定得多。
Dropout------向随机性学习鲁棒
过拟合一直是深度学习的顽疾。网络参数越多,对训练数据的拟合能力越强,但泛化越差。在数据有限的年代,这个问题尤其严峻。
Hinton 和他的学生尼提什·斯里瓦斯塔瓦 (Nitish Srivastava,多伦多大学)在 2012 年提出了 Dropout:在每一次训练步骤里,随机"关闭"(将输出置零)一定比例(通常是 50%)的神经元,只用剩下的神经元计算这次的梯度更新。下一步,再随机选择另一组神经元关闭。
理解 Dropout 有一个好类比:一个团队如果知道每次都只有一半成员会到场,而且到场的是哪一半完全随机,那么每个成员就必须学会独立完成任务,不能依赖固定的"搭档"。Dropout 让每个神经元无法依赖特定的其他神经元,而是被迫学习更鲁棒、更独立的特征表示------从网络层面看,这相当于在每次训练时隐式地训练了指数级数量的不同"子网络",最终的预测是这些子网络的集成。
在测试时,所有神经元都参与(不进行 Dropout),但权重乘以保留概率作为补偿。实验证明,加入 Dropout 之后,AlexNet 的错误率显著下降,这个技巧后来成了深度学习工具箱里最常用的正则化手段之一。
3.9、边界与局限:这段历史能教给我们什么
3.9.1 历史的节律
神经网络的史前史,有一个鲜明的节律:
兴奋 → 冷水 → 沉寂 → 坚守 → 条件成熟 → 爆发
感知机引发了第一次兴奋。Minsky 的书泼了冷水。神经网络沉寂了将近二十年。Rumelhart 的反向传播带来了第二次复兴,但遭遇了梯度消失和计算瓶颈。SVM 的崛起带来了第二次冷水。神经网络进入了更漫长的沉寂。Hinton 等人坚守了下来。
然后,三个条件------数据、算力、算法------在大约 2009-2012 年同时成熟了。
3.9.2 寒冬的教训:什么样的"失败"是致命的
这段历史里有一个值得细想的问题:Minsky 和 Papert 的判断,是错误的吗?
从数学上看,他们的判断没有错:单层感知机确实无法解 XOR。他们对多层网络训练不可行的担忧,在 1969 年也是合理的------当时确实没有有效的训练算法和足够的计算资源。
把"当前条件下不可行"理解成了"根本不可行"。虽然他们的书写的是数学证明,也没有盖棺定论,但他们的话被读者解读成了对整个方向的否定判决,而不是对特定约束条件下可行性的分析。
在知识边界不清晰的领域,权威的声音有特殊的分量------不只是说服同行,还会影响资金流向、研究生的选题、审稿人的标准。Minsky 的书是一次以科学名义进行的资源重新分配,而这次重新分配把一个正确的方向打入了冷宫二十年。
这个教训今天仍然有意义:当一个权威声音说"某方向没有前途"时,要区分"它没有数学前途"(需要严格证明)和"它在当前条件下效果不好"(只是暂时的工程问题)。
3.9.3 技术思想的时机性
正确的思想往往需要等待周边条件的成熟才能爆发。
神经网络的核心思想(多层非线性变换 + 通过反向传播从数据中学习特征层次)在 1986 年就已经完整了。但它需要等到 26 年后,才在数据和算力的配合下,真正展示出潜力。这 26 年里,这个思想不是错的,但从另外的角度来看,或许是超前于它所处的时代。
这种"超前于时代"的模式,在技术史上反复出现。Babbage 的机械差分机(1820 年代)在概念上是完全正确的,但 19 世纪的制造精度无法支撑它的实现。遗传学的孟德尔定律(1865 年)等待了三十五年才被重新发现,因为当时没有染色体的概念来解释机制。图神经网络的早期想法(1990 年代末)等待了近二十年,才随着计算图优化工具和大规模图数据的出现而爆发。
对一个 AI 从业者来说,这个模式也许会给我们带来一些不一样的启发:在评估一个方向时,要区分两种情况------思想本身有缺陷 (即使条件成熟,也难以走通),和思想正确但条件未成熟 (则它需要等待,直到条件到来)。前一种的失败是彻底的,后一种的"失败"只是暂时的沉寂。判断一个方向属于哪一种,是 AI 研究中最难也最有价值的判断力。
3.10、知识自检
读完本章,你应该能做到:
- 解释 McCulloch-Pitts 神经元模型的核心思想,以及它和生物神经元的对应关系
- 描述感知机学习算法,并用几何语言解释感知机在线性可分问题上为什么一定收敛
- 解释 XOR 问题为什么单层感知机无法解决,多层网络为什么可以
- 用链式法则的直觉解释反向传播是怎么工作的
- 说出梯度消失问题的成因(Sigmoid 的饱和区),以及它如何阻碍了深度网络的训练
- 描述 1990 年代神经网络无法起飞的三个原因(梯度消失、计算资源、数据),并解释这三者为什么"缺一不可"
- 说明 2006 年 Hinton 的深度置信网络论文做了什么,以及 GPU 如何成为神经网络革命的隐性推手
- 解释 ReLU 为什么比 Sigmoid 更适合深度网络,以及"死亡 ReLU"问题是什么
- 说出 1990 年代训练神经网络的实际工程挑战(调参难、诊断难、计算慢),以及这些挑战如何被 2010-2012 年的算法进步解决
3.11、常见误解
❌ "反向传播是 Hinton 1986 年发明的"
✅ 实际上:反向传播的核心思想------通过链式法则反向计算梯度------被多次独立发现,最早可以追溯到 1960 年代(Kelley, Dreyfus)。Paul Werbos 在 1974 年已经将其明确应用于神经网络训练。Rumelhart 等人 1986 年的贡献是:以清晰可操作的方式呈现这个算法,并展示了它让多层网络学习"有意义表示"的能力,推动了这个想法的广泛传播。
❌ "Minsky 的《感知机》证明了神经网络不可能解决复杂问题"✅ 实际上:Minsky 和 Papert 证明的是单层感知机有根本性的局限(只能解线性可分问题)。他们没有证明、也无法证明多层网络有类似的局限。他们对"多层网络训练不可行"的判断,是基于当时已知的训练方法和计算资源做出的工程判断,而不是数学证明。事实上,多层网络(深度学习)后来证明了是解决复杂问题的最有效路径之一。
❌ "梯度消失问题只在非常深的网络中存在"✅ 实际上:对于 Sigmoid 激活函数,梯度消失在只有 5-10 层的网络中就已经相当严重了。Sigmoid 导数的最大值是 0.25,10 层的乘积是 0.2510≈10−60.25^{10} \approx 10^{-6}0.2510≈10−6,这已经让最前面的层几乎无法更新。这就是为什么即使有反向传播,1990 年代研究者也很难训练出真正"深"的有效网络的原因。
❌ "GPU 用于深度学习是专门设计的"✅ 实际上:GPU 是为了加速 3D 游戏图形渲染而设计的,深度学习只是利用了 GPU 并行矩阵运算能力的"意外收获"。NVIDIA 起初并没有预见到自家的 GPU 会成为 AI 革命的基础设施,直到 2010 年代才系统地针对深度学习优化硬件(NVIDIA Tesla/A100 系列)。这是技术史上一个典型的"意外用途改变历史"的案例。这也提醒我们:有时候,改变一个领域的关键突破,不来自这个领域内部,而来自一个完全不同的行业为了完全不同的目的发展出来的工具。
❌ "权重初始化只是随便选个小随机数就行,这不是真正的技术问题"✅ 实际上:权重初始化是深度学习工程中的核心挑战之一,在 Xavier 初始化(2010)之前,这个问题没有系统的解决方案。初始化太大,Sigmoid 网络立刻饱和,梯度从第一步就消失;初始化太小,信号在前向传播时衰减到零,同样没有梯度可以反传。Xavier/Glorot 初始化、He 初始化(针对 ReLU 的改进版),是让深度网络"从合理状态出发"的必要前提,与学习率、批归一化等并列为深度学习的工程基础设施。
❌ "深度学习在 2012 年突然从零开始出现"✅ 实际上:2012 年 AlexNet 的成功,建立在数十年的积累上:McCulloch-Pitts 模型(1943)、感知机(1957)、反向传播(1974/1986)、LeNet(1989/1998)、逐层预训练(2006)、ReLU/Dropout(2010-2012)、ImageNet 数据集(2009)、GPU 编程(CUDA, 2007)。它是条件成熟之后的爆发,而不是无中生有的奇迹。
本章关键词
| 词汇 | 简明定义 |
|---|---|
| McCulloch-Pitts 神经元 | 1943 年提出的人工神经元模型,将生物神经元抽象为加权求和+阈值判断的数学操作 |
| 感知机(Perceptron) | Rosenblatt 1957 年提出的单层线性分类器,包含自动学习权重的感知机学习算法 |
| 感知机收敛定理 | 若训练数据线性可分,感知机学习算法一定能在有限步内找到正确分类的权重 |
| 反向传播(Backpropagation) | 通过链式法则从输出层向输入层反向计算每层梯度的算法,是训练多层神经网络的基础 |
| 梯度消失(Vanishing Gradient) | 在深度网络中,梯度从输出层向输入层传播时指数衰减,导致前层权重无法有效更新的现象 |
| Sigmoid 函数 | 一种将实数映射到(0,1)的S形激活函数,1980-1990年代的标准选择,导数有饱和区是梯度消失的主要原因 |
| 逐层预训练(Layer-wise Pre-training) | Hinton 2006 年提出的训练深度网络的策略:先无监督地逐层预训练,再监督微调 |
| ReLU(Rectified Linear Unit) | f(x)=max(0,x)f(x) = \max(0, x)f(x)=max(0,x),正区间导数恒为1,从根本上解决梯度消失问题的激活函数 |
| ImageNet | 李飞飞主导构建的大规模图像数据集(1400万张图,20000类),深度学习革命的关键数据基础设施 |
| GPU(图形处理器) | 为图形渲染设计的并行计算硬件,因矩阵运算能力强,意外成为深度学习训练的关键加速器 |
| ReLU(修正线性单元) | f(x)=max(0,x)f(x)=\max(0,x)f(x)=max(0,x),正区间导数恒为 1,从根本上解决梯度消失的激活函数,2010 年起取代 Sigmoid 成为深度学习的标准选择 |
| Xavier 初始化 | Glorot 和 Bengio 2010 年提出的权重初始化策略,通过保持各层激活方差稳定,解决深度网络训练开始时的信号衰减问题 |
| Dropout | Hinton 等人 2012 年提出的正则化技术,训练时随机关闭部分神经元,防止过拟合,显著提升深度网络的泛化能力 |
延伸阅读
- 必读 :Rumelhart, D.E., Hinton, G.E., & Williams, R.J.(1986). "Learning Representations by Back-propagating Errors." Nature, 323, 533-536. 反向传播在神经网络领域的奠基性论文,虽然数学较密,但引言和结论部分非常值得读
- 推荐 :Minsky, M., & Papert, S.(1969). Perceptrons. 有争议的经典之作,理解它的论证和局限,是理解神经网络历史的必要背景
- 推荐 :Hochreiter, S., & Schmidhuber, J.(1997). "Long Short-Term Memory." Neural Computation, 9(8). 梯度消失问题的详细分析,以及 LSTM 的解决方案------第六章会详细展开,但这里值得提前了解背景
- 推荐 :Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R.(2014). "Dropout: A Simple Way to Prevent Neural Networks from Overfitting." JMLR. 解决过拟合问题的重要论文
- 深入 :LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P.(1998). "Gradient-Based Learning Applied to Document Recognition." Proceedings of the IEEE. LeNet 的完整论文,深度学习用于真实应用的早期里程碑
- 深入 :Hinton, G.E., Osindero, S., & Teh, Y.W.(2006). "A Fast Learning Algorithm for Deep Belief Nets." Neural Computation. 逐层预训练的原始论文,深度学习复兴的起点
!tip
下一章预告:我们已经看到了所有的"前菜"------神经网络的思想、反向传播的工具、逐层预训练的策略。2012 年,当数据、算力、算法三个条件同时成熟时,一个叫 AlexNet 的网络在 ImageNet 竞赛上将错误率从 26% 降到了 15%。这不仅仅是一个数字的变化,而是整个 AI 领域的地震时刻。下一章:深度学习革命。