像人一样看
在大模型不断向多模态发展之后,一个看似基础、其实一直没有被真正解决好的问题开始变得越来越重要:模型到底是怎么"看图"的。过去很多视觉语言模型在处理图片时,本质上仍然沿用一种比较机械的方式------先把二维图像切成一块块视觉 token,再按照固定顺序送进模型,常见的就是从左上到右下逐行扫描。这种方法实现简单,但也带来一个明显问题:图片本来是二维结构,而页面理解、文档阅读、表格识别这些任务,往往并不是靠固定顺序就能完成的。人类在看一页复杂文档时,通常不会老老实实按像素顺序扫过去,而是会先注意标题、再看主体、再定位表格、图注和重点区域。DeepSeek 在 2026 年 1 月提出的 DeepSeek-OCR 2,正是试图解决这个问题。它不再满足于"把图像压成 token 交给大模型",而是进一步追问:模型能不能先学会一种更接近人类阅读逻辑的视觉信息组织方式,再去理解内容。
技术概述
这篇论文的核心创新,是一个叫做 DeepEncoder V2 的新编码器。按照论文的说法,它的目标不是简单提取视觉特征,而是能够根据图像语义动态重排视觉 token。作者认为,传统方法把视觉 token 固定成栅格扫描顺序,其实给模型加入了一种并不合理的先验;对于复杂版式图片,这种顺序和人类真正的观察方式并不一致。为了解决这个问题,DeepSeek-OCR 2 把原来类似 CLIP 的视觉编码部分,替换成了一种更接近 LLM 风格的编码结构,同时引入了所谓的 causal flow tokens,并通过专门设计的 attention mask,让视觉 token 保持全局可见,而这些 flow token 则可以逐步、因果式地重新组织视觉信息。最后,送入解码器的不是原始视觉 token,而是已经经过这一步"阅读逻辑重排"的表示。论文甚至把这个思路概括成一个更大的问题:二维图像理解,是否可以拆成两级串联的一维因果推理结构来完成。
技术详解
先用一句人话概括这段:DeepSeek-OCR 2 觉得,问题不只是"模型能不能看懂图片",而是"模型是不是先按合理的顺序去看图片"。 传统方法常常把图片切成很多小块后,按固定顺序一块块送进模型,比如从左上到右下扫过去;但真实文档、表格、公式页、海报这类图片,并不是这样读的。人会先看标题,再看正文,再找表格和关键区域,所以论文想让模型先学会"怎么按语义组织视觉信息",再去输出结果。
这里最先要懂的词是 编码器(encoder) 和 解码器(decoder) 。你可以把它们理解成两道工序:编码器负责"看图、提取信息、整理信息",解码器负责"根据整理好的信息,把答案写出来"。这篇论文整体上仍然沿用 DeepSeek-OCR 原来的 encoder-decoder 架构,只是把原来的编码器升级成了 DeepEncoder V2。也就是说,这篇文章的创新重点不在"最后怎么生成文字",而在"前面如何把图片读明白"。
接下来是 visual token(视觉 token)。你可以把它理解成"图片被切碎后得到的一小块一小块的信息单元"。就像大语言模型把一句话切成 token 来处理,视觉模型也会把一张图拆成很多局部块,再把每一块变成向量表示。论文里先用一个 vision tokenizer 把图像变成视觉 token,这一步本质上就是把原始图片转成模型能算的"视觉小块序列"。
问题出在:图片本来是二维的,但模型最后往往要按一维序列处理它。 一旦变成序列,就得有先后顺序。传统做法通常采用 raster-scan order(栅格扫描顺序),也就是从左到右、从上到下,像打印机或屏幕刷新那样依次处理。这个顺序在普通自然图片里未必特别糟,但在文档、表格、票据、复杂排版页面里,经常并不符合真实阅读逻辑。比如你看一张带标题、图注、表格和脚注的页面,并不会机械地沿像素顺序扫,而是按内容结构跳着看。论文认为,传统视觉语言模型把视觉 token 固定成这种扫描顺序,相当于提前塞给模型一个不太合理的假设。
这里的 先验(prior),你可以简单理解成"模型在正式理解内容之前,被强行规定好的一种默认规则"。这篇论文批评的"顺序先验"就是:还没真正理解图片含义,就先规定这些视觉 token 必须按左上到右下排列。问题在于,这种排列方式更多来自坐标,不来自语义。对于 OCR 来说,真正重要的常常不是"这块在第几行第几列",而是"这块和标题、表格、正文谁先谁后、彼此是什么关系"。
然后是 CLIP 。你现在不用把它理解得太复杂,直接把它看成一种很经典的图文对齐视觉模型就够了。论文中提到,旧版 DeepEncoder 里,vision tokenizer 后面接的是一个 CLIP ViT 模块,用来做视觉知识压缩;而 DeepEncoder V2 把这一块改造成了更像大语言模型的结构。这里所谓 LLM-style architecture(LLM 风格结构),不是说它变成了普通文本模型,而是说它借用了大语言模型特别擅长的那套"按序列做推理和信息组织"的方式,来处理视觉 token。
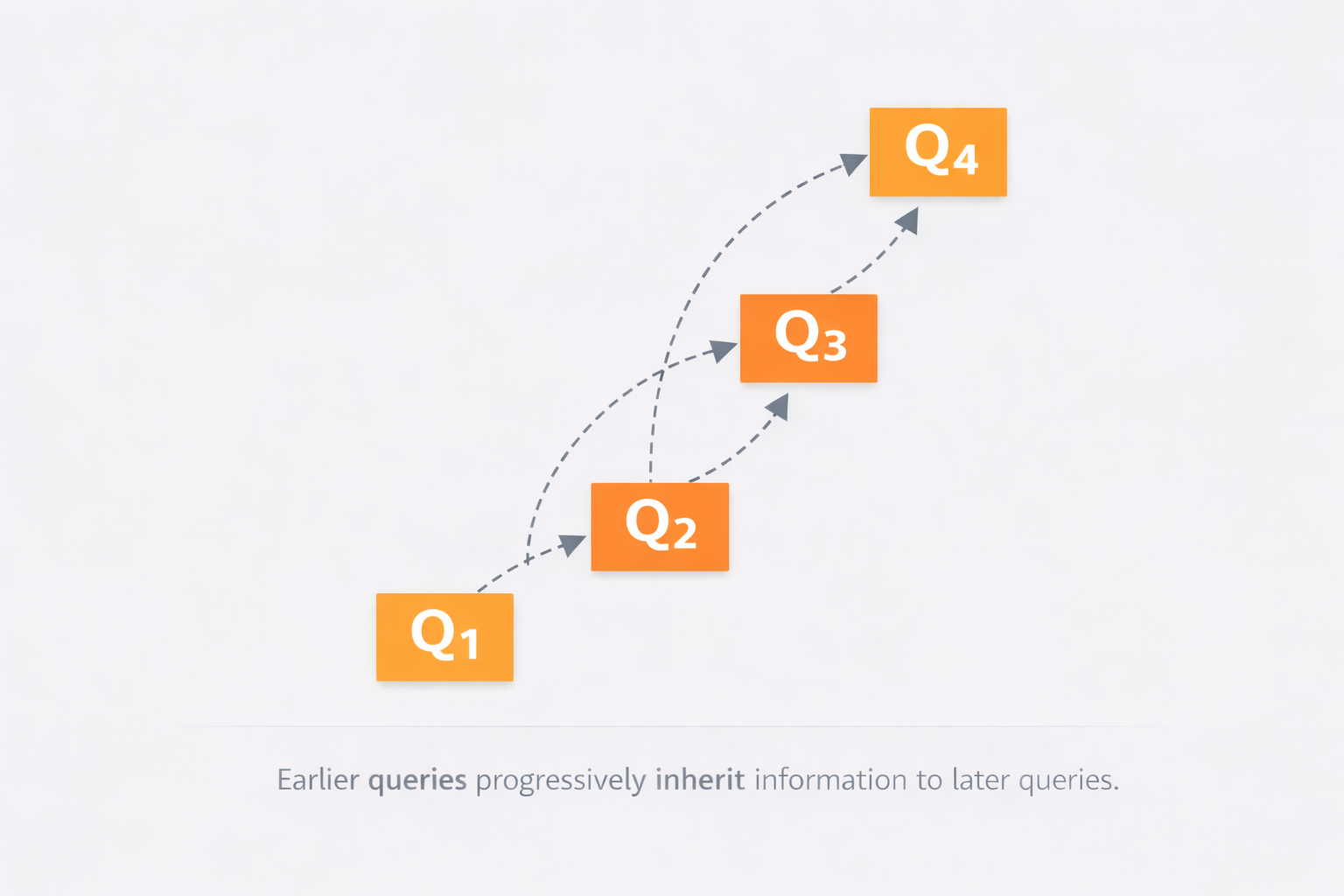
最关键的新东西叫 causal flow queries / causal flow tokens。这个名字看着吓人,其实你可以把它理解成一批"专门负责重新整理视觉信息的查询位"。论文做法不是直接把原始视觉 token 一股脑送给后面的语言模型,而是在视觉 token 后面再接上一串可学习的 query token。每个 query token 都可以去看所有视觉 token,还可以参考前面已经处理过的 query token,于是它们就像一支按步骤推进的整理队伍:前面的 query 先提炼一部分视觉信息,后面的 query 再在前面基础上继续组织和重排,最后形成一套更符合语义顺序的表示。论文明确写到,这些 query 的数量和视觉 token 数量保持一致,而且最后真正送进 LLM decoder 的,不是原始视觉 token,而是这些 causal query 的输出。
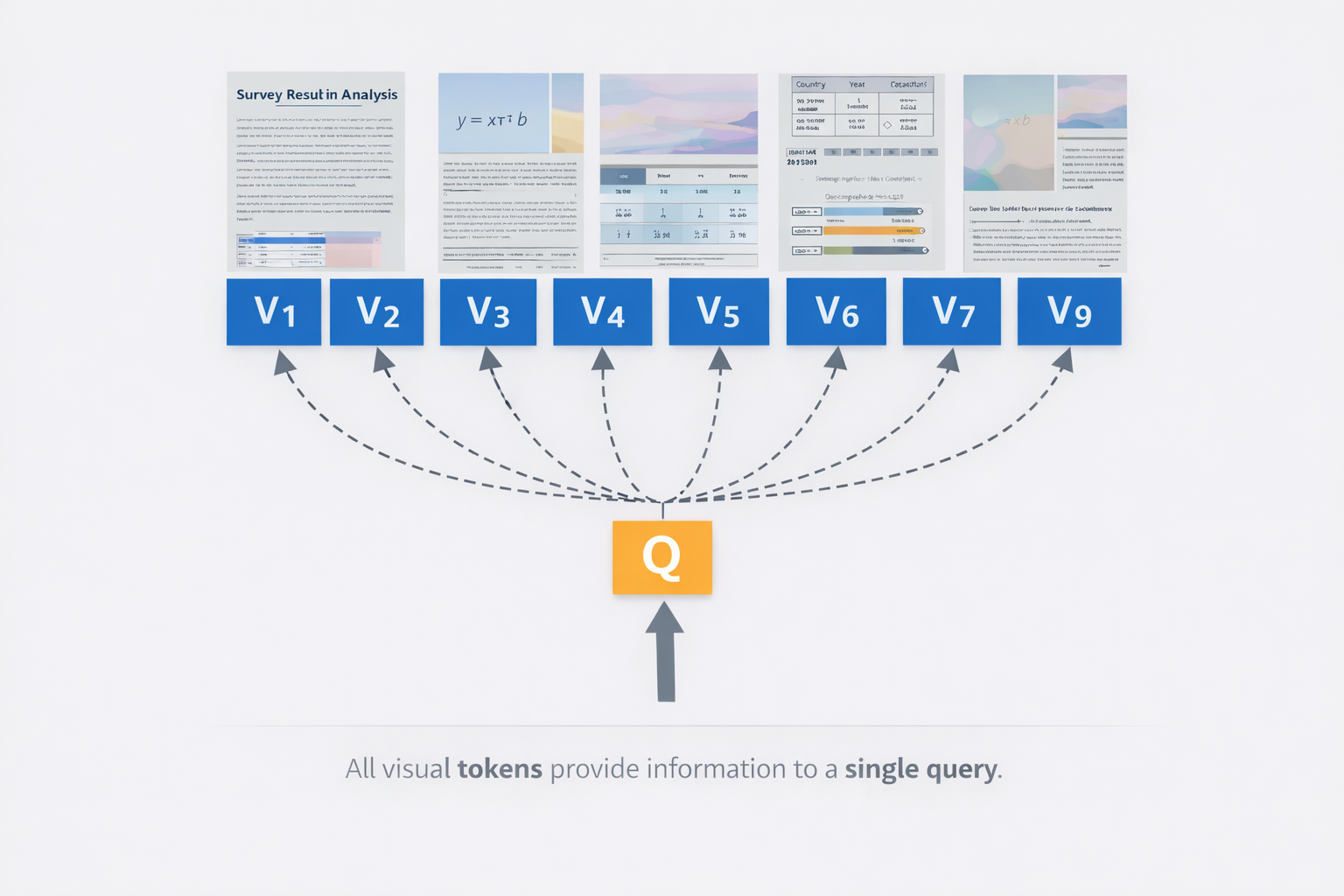
这里的 causal(因果式) 也别按哲学理解,放在模型里,它更接近"有先后依赖关系"。也就是后一个 token 只能看前面的,不能偷看后面的。这和大语言模型逐词生成文本很像:当前词只能基于前文预测,不能提前知道后文。论文借用这个机制,不是为了生成句子,而是为了让视觉信息的整理过程也变成"前一步影响后一步"的链式推进。这样模型就不只是平铺地看见所有图块,而是在逐步建立一种阅读流。
再解释 attention mask(注意力掩码) 。你可以把它理解成"谁允许看谁的规则表"。在 Transformer 里,不是所有 token 都一定能互相看见,attention mask 决定了信息流怎么走。论文这里设计了两块区域:原始视觉 token 那一边用 bidirectional attention(双向注意力) ,意思是视觉 token 彼此都能互相看见,方便保留完整的全局图像信息;而 causal flow token 那一边用 causal attention(因果注意力、下三角掩码),意思是每个 flow token 只能看前面的 flow token,不能看后面的。把这两个规则拼起来后,效果就是:模型一边保留"整张图全局可见"的能力,一边又能让 query token 以顺序推进的方式去整理视觉信息。
论文还特别强调,这套结构可以看成 two-stage cascade causal reasoning(两级串联的一维因果推理)。第一层发生在编码器里:它先通过这些 causal queries,把二维图像中的视觉块重新组织成更有语义顺序的一维序列。第二层发生在后面的语言解码器里:语言模型再沿着这个已经整理好的序列,按自回归方式一步步输出文字结果。你可以把它理解成:第一层先解决"怎么读图",第二层再解决"怎么说出来"。作者想表达的是,二维图像理解未必一定要靠一个显式二维推理器,也许可以拆成两段一维、但有逻辑链条的处理过程来完成。
测试结果
从实验结果看,DeepSeek-OCR 2 的提升并不只是"换了个结构,分数稍微高一点"。论文选用的主测试集是 OmniDocBench v1.5,这是一套专门评估文档解析能力的基准,包含 1355 页中英文文档,覆盖学术论文、教材、杂志、报纸、研究报告、考试卷等 9 大类型。它测的不只是"字认得准不准",还会分别考察普通文本、表格、公式以及阅读顺序这些更接近真实文档理解的问题。也就是说,这个测试集更像是在问模型:你到底有没有把一整页文档真正读明白,而不只是看见了一些字。
在这个基准上,DeepSeek-OCR 2 的综合得分达到 91.09%,相比上一代 DeepSeek-OCR 的 87.36% 有明显提升。更重要的是,论文里最值得注意的不是总分,而是几个更具体的指标。这里反复出现的 Edit Distance,可以简单理解成"模型输出离标准答案还差多少修改步数",数值越低,说明越接近正确结果。比如 TextEdit 测的是普通文字内容的提取质量,数值从 0.073 降到 0.048,说明正文识别更准了;TableEdit 测的是表格内容和结构的还原质量,从 0.123 降到 0.096,说明表格被读乱、列行关系错位的情况减少了;FormulaEdit 则对应公式识别,虽然论文这一段没有重点展开,但它也从 0.236 降到 0.198。最能体现这篇论文核心思想的,是 R-order Edit,也就是阅读顺序误差,它只看文本块之间的顺序,不把表格和图片算进去;这个指标从 0.085 降到 0.057,说明 DeepSeek-OCR 2 在"先读哪里、后读哪里、哪些段落该连在一起"这件事上做得更好了。最后的 OverallEdit 可以看成整页文档解析的综合误差,它从 0.129 降到 0.100,说明整体页面理解能力确实提升了,而不只是某一个局部模块碰巧变强。
这组结果还有一个很关键的背景:DeepSeek-OCR 2 的提升并不是靠"让模型看更多图像块"硬堆出来的。论文专门对比了 visual token 的上限,也就是模型最多能用多少视觉小块去表示一页图像。DeepSeek-OCR 使用的是 1156 个视觉 token,而 DeepSeek-OCR 2 是 1120 个,预算并没有变得更宽松,反而略紧一些。换句话说,它不是靠"看得更多"赢的,而更像是靠"看得更有条理"赢的。论文还把它和 Gemini-3 Pro、Seed-1.8 放在同一张表里比较,说明作者想强调的是:在相近视觉预算下,DeepSeek-OCR 2 的文档解析误差更低。
除了实验室里的 benchmark,论文还给了两组更贴近实际部署的数据。一组是线上用户上传图片的 OCR 日志,另一组是批量处理 PDF、为大模型生成训练数据的生产流水线。因为真实生产环境里通常拿不到标准答案,所以这里没法像 benchmark 一样直接算准确率,论文就改用 repetition rate,也就是"重复生成、重复抄写、输出啰嗦打转"的比例,作为最容易观测的质量信号。结果显示,DeepSeek-OCR 2 在线上图片日志中的重复率从 6.25% 降到 4.17%,在 PDF 数据生产中的重复率从 3.69% 降到 2.88%。这说明它不仅在论文测试集上更强,在实际使用时也更不容易出现那种 OCR 模型常见的"同一句重复、段落粘连、结构混乱"的问题。
所以,这篇论文最有说服力的地方,不是总分涨了多少,而是它在"阅读顺序、表格结构、整页解析质量"这些真正体现文档理解能力的指标上都更稳定地变好了,而且这种提升并不是靠增加视觉 token 硬堆出来的。
TO SUM UP
总的来看,DeepSeek-OCR 2 的意义,不在于它单纯证明了 OCR 还能继续涨分,而在于它提醒人们:多模态模型的难点,未必只在"识别能力"本身,也可能在"信息组织方式"上。对于复杂文档而言,真正接近人类阅读的,不是机械地扫过所有像素,而是先建立结构、再理解内容、最后输出结果。DeepSeek-OCR 2 正是在这个方向上往前推进了一步。它让我们看到,未来更强的视觉语言模型,也许不只是拥有更大的参数和更长的上下文,而是会越来越重视"如何读取"这件事本身。从这个角度看,这篇论文讨论的已经不只是 OCR,而是在探索多模态模型是否能够像人一样,更有条理地理解二维世界。