市面上99%的IP归属地文章,都在回答"怎么查""为什么不准""用什么工具查"。但几乎没有人回答那个最关键的问题------查完了,然后呢?
查IP归属地从来不是终点。风控团队要决定"拦不拦",电商运营要决定"券发不发",内容团队要决定"内容推不推",广告投放要决定"流量认不认"。本文用5步决策清单,帮你把归属地结果变成可执行的业务动作。
IP地址查询在金融风控中通常承担"低成本、低延迟的第一层信号"角色,用于快速识别异常地域、代理网络和潜在欺诈流量。但要把它变成稳定可控的线上能力,需要先明确一个事实:你查到的结果是"出口网络画像",不等同于"用户真实地理位置"。
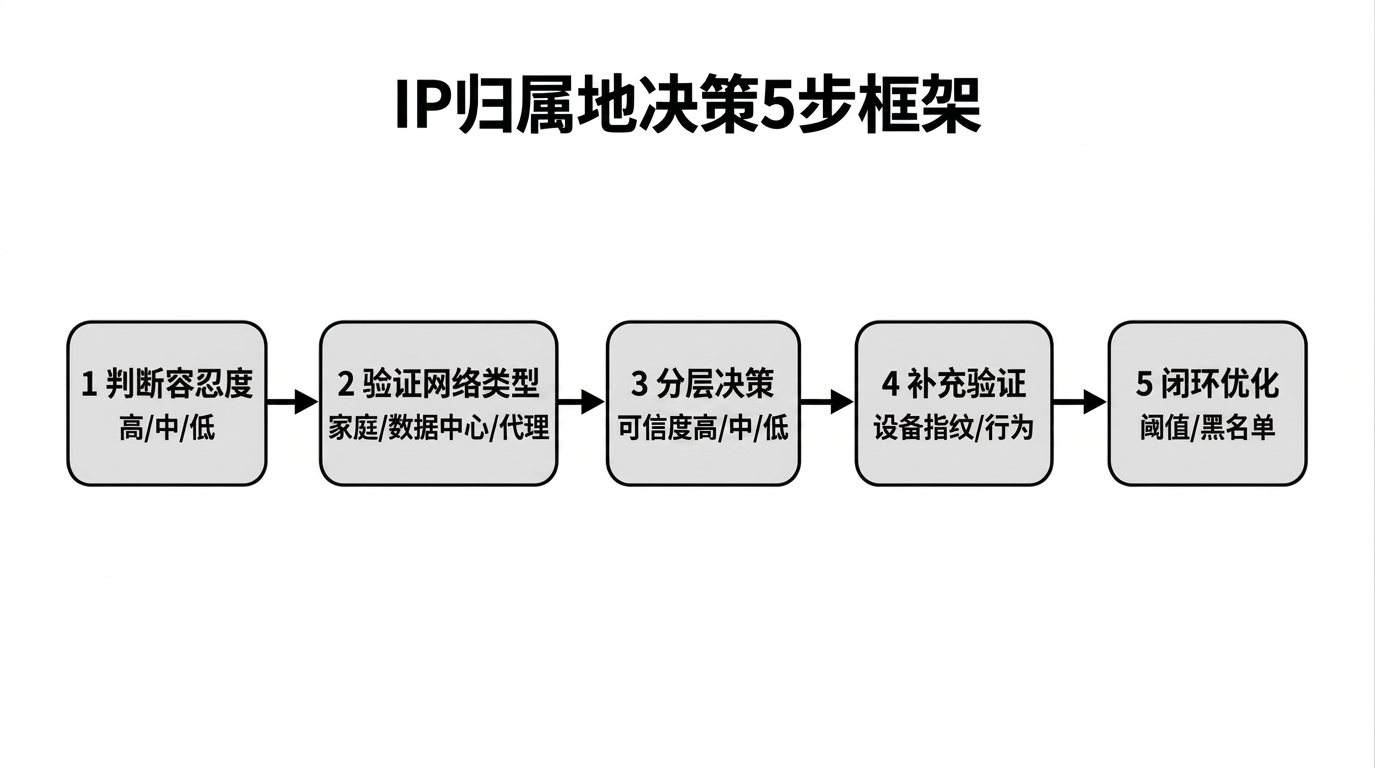 5步决策流程图,从判断容忍度到闭环优化,IP归属地业务应用框架
5步决策流程图,从判断容忍度到闭环优化,IP归属地业务应用框架
第1步:判断场景容忍度------你的业务能接受多大偏差?
先问自己一个问题:我查IP归属地是为了什么?不同场景对误差的容忍度差异极大:
| 场景 | 容忍度 | 策略建议 |
|---|---|---|
| 内容本地化/语言切换 | 高 | 国家/省份级即可,用户在上海IP显示杭州,不影响他看中文内容 |
| 广告地域投放 | 中 | 大促时广州用户看到深圳优惠券,可能放弃下单。需控制城市级准确率≥95% |
| 金融风控/登录校验 | 低 | 误判"异地登录"可能导致用户流失。需结合网络类型、设备指纹交叉验证 |
| 物流配送/区域限制 | 极低 | 将杭州订单分配至上海仓库,直接导致配送时效超标 |
金融反欺诈场景对IP精准度要求最高,城市级准确率需达到98%以上,部分场景要求街道级定位。如果城市级准确率从90%提升到98%,在日均1亿次请求的广告场景中,年浪费预算可从1825万元降至365万元。
第2步:验证网络类型------家庭宽带IP ≠ 真实用户IP
IP归属地查询的结果,需要结合"网络类型"才能准确解读。IP数据云提供network_type字段,可区分家庭宽带、数据中心、企业专线、移动网络。
典型误判场景:
-
一个IP定位在"上海",但
network_type显示为"企业专线",那它的用户可能在苏州分公司办公。 -
一个IP定位在"北京",但
network_type显示为"数据中心",那它大概率不是真实用户,建议拦截。
在金融风控中,不要将"数据中心/企业专线"一概等同于高风险。更合理的做法是把"网络类型"作为分流条件,叠加账号、设备与历史行为信号后再决策。
第3步:分层决策------用"三级处置法"代替"一刀切"
 三级处置法分层决策图,绿色放行黄色二次验证红色拦截,基于IP类型和风险评分
三级处置法分层决策图,绿色放行黄色二次验证红色拦截,基于IP类型和风险评分
根据IP风险等级和误差可信度,将决策分为三级:
-
绿色(可信度高):IP类型为家庭宽带 + 风险评分<50分 + 与用户历史行为一致 → 直接放行/推送内容
-
黄色(可信度中等):IP类型为移动网络 + 风险评分50-75分 → 触发二次验证(滑块/短信)/推送前弹窗确认
-
红色(可信度低):IP类型为数据中心/代理 + 风险评分>75分 → 拦截/不推送/标记为异常
风控决策优先使用国家/省级粒度,城市级可用于弱信号(触发验证),不建议作为强拦截依据。
第4步:补充验证------当IP信号不足时,用哪些信号佐证?
仅靠归属地城市做决策是不够的。以下是通过IP数据云API获取network_type(网络类型)和risk_score(风险评分),并自动输出的决策建议:
import requests
def ip_decision(user_ip, scene="register"):
"""基于ipdatacloud.com的API的归属地决策函数"""
url = "https://api.ipdatacloud.com/v2/query"
params = {"ip": user_ip, "key": "YOUR_API_KEY", "risk": "true"}
try:
resp = requests.get(url, params=params, timeout=2)
data = resp.json()
if data.get('code') != 200:
return "allow"
result = data['data']
location = result.get('location', {})
network = result.get('network', {})
risk = result.get('risk', {})
city = location.get('city', '')
network_type = network.get('网络类型', '')
risk_score = risk.get('总分', 0)
is_proxy = risk.get('是否代理', '否')
# 支付场景:最严格
if scene == "payment":
if is_proxy == '是' or risk_score > 70:
return "block"
if risk_score > 50:
return "verify"
return "allow"
# 领券场景:中等严格
if scene == "coupon":
if is_proxy == '是' or risk_score > 80:
return "block"
if risk_score > 60:
return "verify"
return "allow"
# 注册场景:较宽松
if network_type == '数据中心' or is_proxy == '是':
return "block"
if risk_score > 80:
return "block"
if risk_score > 60:
return "verify"
return "allow"
except Exception:
return "allow"代码说明:
-
业务场景:不同业务环节对风险的容忍度不同。支付场景资金安全优先(严格),注册场景用户转化优先(宽松),领券场景介于两者之间
-
为什么这样设计 :
network_type可区分家庭宽带、数据中心、企业专线等网络类型;risk_score提供0-100分动态评分,两者组合使用,可覆盖大部分风控决策场景 -
降级策略:API超时或异常时默认放行,避免因检测服务故障导致正常用户流失
IP归属地只是一个信号,不要把它当成全部答案。当归属地信息存疑时,引入以下信号辅助判断:
-
设备指纹:同一设备是否曾关联过其他IP?IP频繁变化但设备不变,可能是出差;设备也频繁变化,才是高风险。
-
行为特征:访问频率、停留时间是否符合真人?凌晨3点的批量注册请求,即使IP归属地正常,也值得怀疑。
-
账号历史:用户过去常登录的城市是什么?IP地理一致性校验是平台判断"你是不是真的在当地"的重要依据之一。
将"代理类型+异常变化"组合使用,而不是只看"是否代理"。对高价值操作(改密、绑卡、提现)提高验证强度,对低价值操作做分层处理。
第5步:闭环优化------把"决策结果"反馈回风控系统
决策不是终点,而是优化的起点。每次决策的结果都应该反馈回风控系统:
-
校准决策阈值:如果误判率持续偏高,说明阈值设置需要调整
-
沉淀黑名单:被确认欺诈的IP永久标记
-
优化场景化规则:不同场景积累不同的决策经验
IP数据云的数据保持每日更新,可确保黑名单时效性。IP信息能以极低成本筛掉70%以上的异常流量与高风险行为。
总结:查归属地是起点,做出正确的业务决策才是终点
IP归属地查询的价值,不在于"查到",而在于"用对"。5步决策清单的核心逻辑是:先判断场景容忍度,再验证网络类型可信度,然后分层决策,信号不足时补充验证,最后闭环优化。
IP数据不是万能钥匙,而是智能决策的"第一道滤网"。它不能替代手机号或设备指纹,但能以极低成本筛掉大部分异常流量。