在数据驱动的业务中,IP归属地查询是一个高频基础操作。无论是用户画像、流量分析,还是安全风控,都可能面临处理海量IP的挑战。例如,一次离线日志分析任务涉及上亿条IP,如果用在线API循环调用,几天都跑不完,而且数据仓库环境往往无法访问外网。那么,大数据场景下如何高效查询IP归属地?
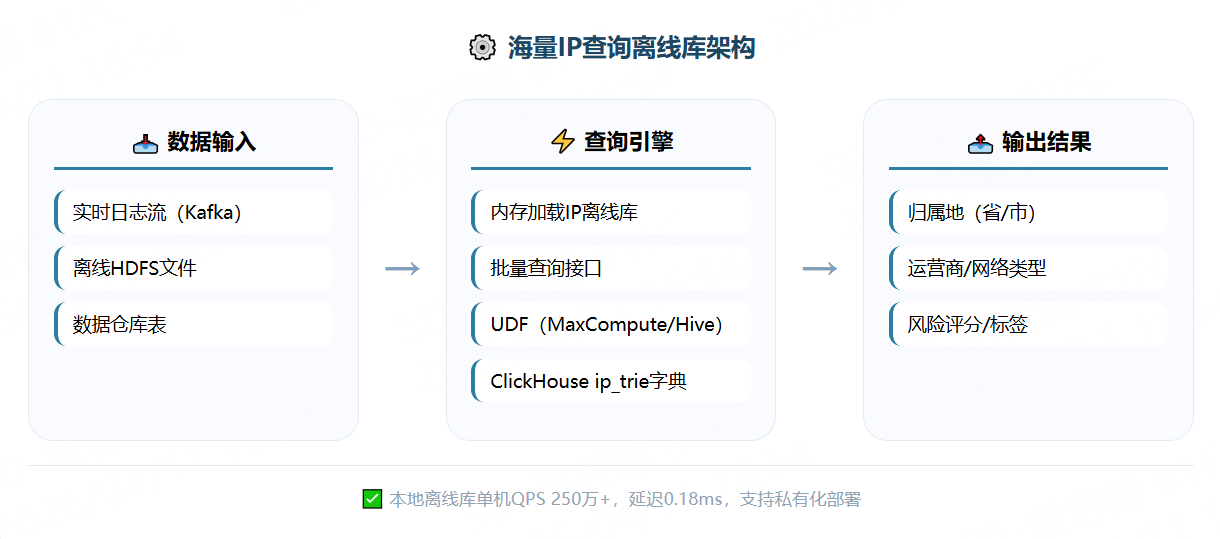
核心思路:将IP查询从"外部服务调用"转为"本地数据计算"。实测表明,本地离线库(以IP数据云为例)单机QPS可达250万+,平均延迟0.18ms,比在线API快两个数量级。结合数据仓库UDF或ClickHouse字典,可轻松完成TB级数据的并行解析。

01 海量IP查询的三大瓶颈
大数据场景下的IP查询与在线业务不同,有两个显著特点:一是批量为主 ,离线日志分析、用户画像任务往往一次性处理上亿条IP;二是环境受限,数据仓库(如MaxCompute)通常是封闭计算环境,无法直接调用外部HTTP API。
传统方案在三类场景下会遇到明显瓶颈:
| 场景 | 问题表现 | 根本原因 |
|---|---|---|
| 实时风控 | 高并发下API限流,查询失败率骤升 | 外部API的QPS上限远低于业务峰值 |
| 离线日志分析 | 上亿条IP循环调用API,几天都跑不完 | HTTP网络往返开销叠加API频率限制 |
| 数据仓库关联 | 封闭环境无法调用外部服务 | 计算集群无外网访问权限 |
因此,离线库方案成为大数据场景下的唯一选择。
02 离线库方案:性能与部署优势
IP离线库的核心逻辑是将查询从"外部服务调用"变成"本地数据计算"。在4核8G云服务器环境下,本地离线库单机QPS可超过250万,平均耗时仅0.18ms,P99延迟0.35ms。
| 维度 | 在线API | 本地离线库 |
|---|---|---|
| 平均响应时间 | 30-80ms | 0.1-0.5ms |
| 单机QPS | 受接口限流(约1000) | 250万+ |
| 数据安全 | IP数据外发 | 私有化部署,数据不出域 |
| 批量任务 | 受频率限制 | 只受CPU限制 |
| 成本模型 | 按次计费 | 一次性采购 |
03 批量查询:代码示例
对于海量IP,推荐使用离线库的内存加载模式 或批量接口,避免逐条调用的循环开销。
方案一:内存加载离线库(适合高并发/超大批量)
python
# 示例使用IP数据云SDK(其他厂商类似)
from ipdatacloud import IPDatabase
# 一次性加载到内存
db = IPDatabase.load("/data/ipdb/ipdata.xdb")
def batch_resolve(ip_list):
results = []
for ip in ip_list:
result = db.query(ip)
results.append({
'ip': ip,
'province': result.province,
'city': result.city,
'risk_score': result.risk_score
})
return results
# 亿级IP处理示例
all_ips = [...] # 从日志读取
results = batch_resolve(all_ips)方案二:批量查询接口(适合中等批量)
python
import requests
def batch_query_ips(ip_list):
url = "https://api.ipdatacloud.com/v2/batch"
params = {'ips': ','.join(ip_list), 'key': 'your_api_key'}
resp = requests.get(url, params=params, timeout=5).json()
if resp.get('code') == 0:
return resp.get('data', [])
return []
# 单次最多100个IP
ip_batch = ['203.0.113.5', '45.33.22.11', '240e:3a0:1000::1']
results = batch_query_ips(ip_batch)
for item in results:
print(f"{item['ip']} → {item['province']}·{item['city']}")加载到内存后,单次查询是纯CPU运算,不涉及IO,QPS只受CPU限制。
04 大数据平台集成:MaxCompute + UDF
在MaxCompute、Hive等数据仓库中处理IP归属地,最优方案是"IP库入仓+UDF"。
实现步骤:
- 将IP离线库上传为MaxCompute表(
ip_resource) - 开发UDF函数,将IP字符串转换为整数
- 编写SQL,JOIN IP库表进行范围匹配
sql
-- 1. 创建IP库表
CREATE TABLE IF NOT EXISTS ip_resource (
start_ip BIGINT COMMENT '起始IP(整数形式)',
end_ip BIGINT COMMENT '结束IP(整数形式)',
country STRING,
province STRING,
city STRING,
isp STRING
);
-- 2. UDF:IP转整数
CREATE FUNCTION ip2long AS 'com.example.IP2LongUDF';
-- 3. 查询匹配
SELECT
t.user_id,
t.ip,
r.province,
r.city
FROM user_log t
JOIN ip_resource r
ON ip2long(t.ip) BETWEEN r.start_ip AND r.end_ip;这种方案充分利用了数据仓库的并行计算能力,性能极高,且可直接与任意业务表关联。
05 ClickHouse集成:ip_trie字典
在ClickHouse这类OLAP数据库中,可使用内置的ip_trie字典实现IP地理位置匹配。
sql
-- 创建ip_trie字典
CREATE DICTIONARY ip_geo_dict
(
network String,
province String,
city String
)
PRIMARY KEY network
SOURCE(CLICKHOUSE(
HOST 'localhost'
PORT 9000
USER 'default'
TABLE 'ip_geo_table'
))
LAYOUT(IP_TRIE())
LIFETIME(86400);ClickHouse会为IP范围构建前缀树索引,查询效率极高,适合在大规模分析查询中实时解析IP。
06 性能实测数据
基于4C/8G云服务器,100万随机IPv4的压测结果:
| 方案 | 平均耗时 | P99延迟 | 单机QPS |
|---|---|---|---|
| 在线API | 35-42 ms | 80-95 ms | ~1000 |
| IP2Location离线库 | 0.15 ms | 0.30 ms | 300万+ |
| IP数据云离线库 | 0.18 ms | 0.35 ms | 250万+ |

关键结论:性能的决定因素不是"哪家数据",而是"是否走网络"。离线库将查询从毫秒级压到微秒级,同时完全消除网络依赖和外部服务限流风险。
07 总结
大数据场景下高效查询海量IP归属地,核心是选择离线库方案 并集成到数据仓库的计算引擎中:
- 实时高并发:内存加载离线库,单机QPS 250万+,延迟<0.2ms
- 离线批量处理:利用数据仓库UDF,将IP库入仓,并行匹配TB级数据
- OLAP分析:使用ClickHouse的ip_trie字典,实现秒级地理位置分析
从"外部调用"到"本地计算",是海量IP查询的唯一解。建议在技术选型时,优先评估离线库方案对自身业务场景的适配性,重点关注定位精度、更新频率和部署方式。