文章目录
- Pre
- 一、为什么我们需要"系统化调试"
-
- [1.1 常见的调试恶性循环](#1.1 常见的调试恶性循环)
- [1.2 一条铁律:未经根因调查,禁止提出修复方案](#1.2 一条铁律:未经根因调查,禁止提出修复方案)
- 二、系统化调试技能的整体架构
-
- [2.1 技能的激活方式:什么时候启用这套流程?](#2.1 技能的激活方式:什么时候启用这套流程?)
- [2.2 四阶段流程概览](#2.2 四阶段流程概览)
- 三、第一阶段:根因调查------在动手前把问题"看清楚"
-
- [3.1 仔细阅读错误信息,而不是略过](#3.1 仔细阅读错误信息,而不是略过)
- [3.2 稳定复现:如果不能复现,就不要乱改](#3.2 稳定复现:如果不能复现,就不要乱改)
- [3.3 检查近期改动:谁是"嫌疑最大的人"](#3.3 检查近期改动:谁是“嫌疑最大的人”)
- [3.4 多组件证据收集:在复杂架构里锁定"哪一层在出错"](#3.4 多组件证据收集:在复杂架构里锁定“哪一层在出错”)
- [3.5 追踪数据流:沿调用链"逆流而上"找到真正的源头](#3.5 追踪数据流:沿调用链“逆流而上”找到真正的源头)
- 四、第二阶段:模式分析------对比"正确的世界"和"错误的世界"
-
- [4.1 找一份"正常工作的示例"](#4.1 找一份“正常工作的示例”)
- [4.2 逐项识别差异:不放过任何"看起来无关紧要"的不同](#4.2 逐项识别差异:不放过任何“看起来无关紧要”的不同)
- [4.3 梳理依赖与环境假设](#4.3 梳理依赖与环境假设)
- 五、第三阶段:假设与测试------把科学方法搬进调试流程
-
- [5.1 写下你的假设,而不是"心里大概有个想法"](#5.1 写下你的假设,而不是“心里大概有个想法”)
- [5.2 最小变更测试:一次只改变一个变量](#5.2 最小变更测试:一次只改变一个变量)
- [5.3 不要在失败修复之上叠加新修复](#5.3 不要在失败修复之上叠加新修复)
- 六、第四阶段:实施------从失败测试开始的单一修复
-
- [6.1 先写失败测试,再写修复代码](#6.1 先写失败测试,再写修复代码)
- [6.2 单一修复:拒绝"顺手改一点别的"](#6.2 单一修复:拒绝“顺手改一点别的”)
- [6.3 三次失败之后,问题就不再是"修复没写好",而是"架构出问题"](#6.3 三次失败之后,问题就不再是“修复没写好”,而是“架构出问题”)
- 七、反模式与心理防线:对抗"走捷径的本能"
-
- [7.1 常见的调试反模式清单](#7.1 常见的调试反模式清单)
- [7.2 合理化借口对照表:用现实戳破自我安慰](#7.2 合理化借口对照表:用现实戳破自我安慰)
- [7.3 人类协作者的"提醒信号"](#7.3 人类协作者的“提醒信号”)
- [八、配套技术一:根因追踪(Root Cause Tracing)](#八、配套技术一:根因追踪(Root Cause Tracing))
-
- [8.1 五步反向追踪法](#8.1 五步反向追踪法)
- [8.2 何时需要插桩与额外日志](#8.2 何时需要插桩与额外日志)
- [九、配套技术二:纵深防御(Defense in Depth)](#九、配套技术二:纵深防御(Defense in Depth))
-
- [9.1 单一验证 vs 多层验证](#9.1 单一验证 vs 多层验证)
- [9.2 四层防御结构](#9.2 四层防御结构)
- [十、配套技术三:基于条件的等待------告别"随便 sleep 一下"](#十、配套技术三:基于条件的等待——告别“随便 sleep 一下”)
-
- [10.1 从"睡 50ms"到"等待条件满足"](#10.1 从“睡 50ms”到“等待条件满足”)
- [10.2 三个通用辅助函数](#10.2 三个通用辅助函数)
- 十一、配套工具:find-polluter.sh------定位"谁把测试环境搞脏了"
-
- [11.1 工作原理与用法](#11.1 工作原理与用法)
- 十二、压力测试:在最糟糕的情境下,流程是否还能站得住?
-
- [12.1 四个对抗性场景](#12.1 四个对抗性场景)
- [十三、与其他技能的整合:TDD 和代码审查中的调试闭环](#十三、与其他技能的整合:TDD 和代码审查中的调试闭环)
-
- [13.1 与测试驱动开发的配合](#13.1 与测试驱动开发的配合)
- [13.2 与代码审查工作流的衔接](#13.2 与代码审查工作流的衔接)
- 十四、当流程指向"无根因"时怎么办?
- 十五、目录结构与在团队中的落地实践
-
- [15.1 技能目录结构](#15.1 技能目录结构)
- [15.2 如何在真实团队中推广](#15.2 如何在真实团队中推广)
- [十六、结语:把"修 Bug"升级为"改进系统认知"](#十六、结语:把“修 Bug”升级为“改进系统认知”)
Pre
Superpowers - 01 让 AI 真正"懂工程":Superpowers 软件开发工作流深度解析
Superpowers - 02 用 15 个技能给你的 AI 装上「工程大脑」:Superpowers 快速开始深度解析
Superpowers - 03 一文搞懂 Superpowers:面向多平台 AI 编码助手的安装与实践指南
Superpowers - 04 从"会写代码"到"会做工程":Superpowers 工作流引擎架构深度剖析
Superpowers - 05 构建一个"会自己找插件用"的 Agent:深入解析 Superpowers 的技能发现与激活机制
Superpowers - 06 从文档到"结构契约":Superpowers 技能剖析与 Frontmatter 深度解读
Superpowers - 07 从 SessionStart Hook 看 Superpowers:把「技能库」变成「行为操作系统」
Superpowers - 08 在 AI 时代重写「需求评审会」:深入解读 Superpowers 的头脑风暴与设计规范机制
Superpowers - 09 从构思到落地:如何用「计划编写与任务粒度」驾驭 AI 时代的软件开发
Superpowers - 10 用 Subagent 驱动开发,把「AI 写代码」变成一条严谨的生产流水线
Superpowers - 11 从计划到落地:深入解析 Superpowers 的「内联执行计划」工作流
Superpowers - 12 没有失败测试,就没有生产代码:从 Superpowers 看"铁律级"测试驱动开发
软件开发里,调试往往是最折磨人的环节:一个 Bug 修完又冒出新的 Bug,改着改着,连自己都不知道系统现在是怎么工作的了。 这篇文章要介绍的是 obra "superpowers" 仓库中的一项核心技能------系统化调试流程:一个由四个阶段组成、带有"硬性铁律"和完整工具配套的调试方法论,目标是从根上消灭"瞎改一通"的恶性循环。
相比"凭经验拍脑袋"和"多试几次总能好"的习惯,这套流程有几个非常鲜明的特点:
- 有一条绝对不能违反的铁律:未经根因调查,不得提出修复方案。
- 用阶段关卡和显式的"反模式清单",结构化地阻止各种走捷径的心理。
- 提供配套的根因追踪、纵深防御、条件等待等具体技术,确保不是"空洞的流程图",而是可以直接落地的实践。
- 在多种高压场景下做过"对抗性测试",验证在时间紧张、权威施压等情况下也能坚持住流程。
本文面向一线开发者、技术负责人和对工程实践感兴趣的研究者,会先讲清这套技能的架构和核心理念,再详细拆解四个阶段及配套技术,最后给出在真实团队中落地的建议。
一、为什么我们需要"系统化调试"
1.1 常见的调试恶性循环
几乎每个开发者都经历过类似的场景:
- 线上突然出现一个 Bug,于是快速改了一下看似相关的代码。
- Bug 似乎消失了,但几天后用户报告新的错误,或者测试开始间歇性失败。
- 为了赶进度,再次"快速修复",结果引入更多隐蔽问题,技术债越堆越高。
这种调试方式有几个共同特征:
- 没有系统的根因调查,更多是"感觉上是这里出了问题"。
- 测试往往滞后于修复,甚至完全没有围绕 Bug 写过专门的测试。
- 整个团队对"为什么会出现这个 Bug"只有模糊印象,知识无法沉淀。
系统化调试技能就是为了解决这些根本性问题而设计的,它不是在教你"怎么打印日志",而是在重塑你面对 Bug 时的整个思维和流程。
1.2 一条铁律:未经根因调查,禁止提出修复方案
这项技能建立在源码中用全大写写出的指令之上:未经根因调查不得提出修复方案。
几点关键含义:
- "根因调查"不是随便看一眼日志,而是一整套结构化步骤(后文详述)。
- 这不是"建议",而是流程上的硬门槛:没做完第一阶段,就不允许进入后续阶段。
- 文档里大量使用 "ALWAYS"、"NEVER" 这样的祈使句,并通过阶段锁定的方式,防止你在压力下自我合理化偷懒。
创建者专门针对四种典型场景(学术环境、生产事故、精疲力竭、权威压力)做了压力测试,并把在这些场景里开发者/AI 助手常说的借口全部分类成"失败模式"。 这些借口后来被写入反模式清单,成为"防弹装甲"的一部分。
二、系统化调试技能的整体架构
2.1 技能的激活方式:什么时候启用这套流程?
在 obra "superpowers" 框架里,每个技能都有一段 frontmatter 来描述触发条件。 系统化调试技能的触发条件是:
"在遇到任何 Bug、测试失败或意外行为时,在提出修复方案之前使用。"
这意味着:
- 它是主动触发的技能:一旦观察到异常,就应该立刻切换到这套流程;而不是在尝试多次失败之后才"想起来用一下"。
- 它不只面对"严重 Bug",也覆盖"测试偶尔失败""行为和预期略有偏差"等所有异常信号。
技能目录 skills/systematic-debugging/ 中不仅有主文件 SKILL.md,还包含辅助技术文档、压力测试场景和生产级工具代码,形成一个完整的生态系统:
root-cause-tracing.md:根因追踪技术。defense-in-depth.md:纵深防御模式。condition-based-waiting.md及示例代码:基于条件的等待,替代任意 sleep。find-polluter.sh:定位测试污染源的诊断脚本。- 多个压力场景测试文档,用于验证和训练。
这种模块化结构,使得核心流程可以保持简洁易读,而细节和技术实现则通过链接按需展开。
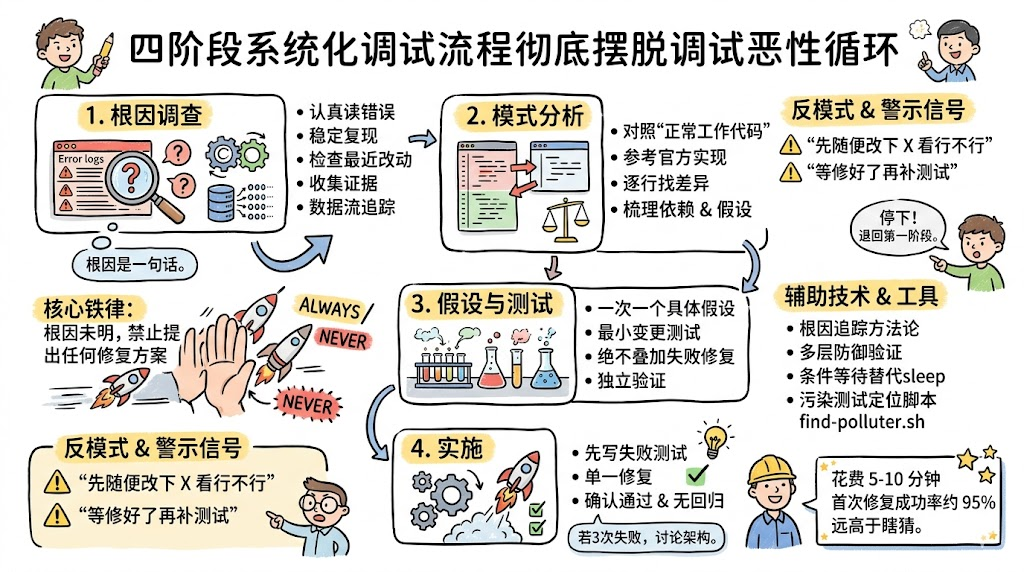
2.2 四阶段流程概览
系统化调试流程可以用一张图来概括:
-
Phase 1:Root Cause Investigation(根因调查)
- 读错误信息、稳定复现、检查近期改动、多组件证据收集、追踪数据流。
-
Phase 2:Pattern Analysis(模式分析)
- 找正常工作的示例,对照官方或参考实现,逐项识别差异,梳理依赖和假设。
-
Phase 3:Hypothesis & Testing(假设与测试)
- 提出单一假设,用最小变更测试,一次只改变一个变量,不在失败修复上叠加新修复。
-
Phase 4:Implementation(实施)
- 先写失败测试,再做单一修复,验证无回归;如连续三次修复失败,则上升到架构层面讨论。
文档中还给出了一个速查表,对四个阶段的关键活动、成功标准和退出关卡做了总结:
| 阶段 | 关键活动 | 成功标准 | 退出关卡 |
|---|---|---|---|
| 1. 根因 | 阅读错误,复现问题,检查更改,收集证据,追踪数据流 | 理解发生了什么以及为什么发生 | 能用一句话阐明根本原因 |
| 2. 模式 | 寻找正常示例,对比参考,识别差异 | 精确知道正常与错误差异 | 差异已完全梳理归类 |
| 3. 假设 | 提出单一理论,最小化测试,验证 | 假设被证实或迭代 | 拥有证据支撑的因果理论 |
| 4. 实施 | 创建失败测试,实施单次修复,验证 | Bug 被解决,无回归 | 修复已确认且架构合理 |
接下来,我们逐个深入。
三、第一阶段:根因调查------在动手前把问题"看清楚"
根因调查阶段是整个技能的地基,在你改任何一行代码之前,必须完成五个步骤。
3.1 仔细阅读错误信息,而不是略过
第一步看似简单,却是最常被忽视的:把错误信息读完读懂。
文档明确强调:
- 不要忽略任何错误或警告,它们经常直接包含解决方案的线索。
- 堆栈跟踪、行号、文件路径、错误代码、具体消息------全部都是重要信号。
一个常见的坏习惯是:看到错误信息太长、太吓人,就直接跳到"改代码试试看"。系统化调试则要求你把错误当成一份"自动生成的调查报告",先把这份报告吃透。
3.2 稳定复现:如果不能复现,就不要乱改
第二步是稳定复现:你需要能可靠触发这个 Bug,并且记录清楚步骤。
- 如果 Bug 无法稳定复现,正确做法是收集更多数据、增加日志或监控,而不是基于运气去改代码。
- 只有能稳定复现的问题,才适合进入后续的模式分析和假设验证。
在实践中,这通常意味着:
- 写一个最小复现脚本或测试用例。
- 在 CI、不同环境(本地、Staging)上验证复现路径一致。
3.3 检查近期改动:谁是"嫌疑最大的人"
第三步是通过 git 变更、最近提交、新依赖、配置修改和环境差异来检查近期的变化。
文档鼓励你像刑侦一样去问:
- 这个 Bug 最早是什么时候被观察到的?
- 那段时间有哪些功能上线?哪些依赖升级?哪些配置调整?
- 有无数据迁移或环境切换?
这可以大幅缩小排查范围:大部分问题都和"最近发生了什么"密切相关。
3.4 多组件证据收集:在复杂架构里锁定"哪一层在出错"
现代系统往往跨越多层组件:CI → 构建 → 签名流水线,或者 API → 服务 → 数据库链路。 对此,技能专门定义了第四步:多组件证据收集。
你需要:
- 记录每个组件边界上的输入和输出(例如入参、出参、状态变化)。
- 验证每一层的环境、配置、权限是否正确传递。
- 必要时运行一个带有插桩的版本,用日志/trace 标记每一层如何处理数据。
文档中举了一个 macOS 代码签名流水线的例子,展示如何追踪密钥在四层流水线中的传递,以确定是哪个环节造成了错误。
3.5 追踪数据流:沿调用链"逆流而上"找到真正的源头
第五步是追踪数据流 ,这一部分的详细方法论在 root-cause-tracing.md 里展开。
核心思想:不要在 Bug 表现出来的地方打补丁,而是沿着调用链一直"往上游追"。
文档给出一个典型例子:git init 在错误的目录失败。
- 表象:
git init failed in /Users/.../packages/core。 - 直接原因:一个
execFileAsync调用在错误的cwd下执行。 - 继续追:是谁调用了它?再往上是
WorktreeManager.createSessionWorktree→Session.initializeWorkspace→Project.create。 - 找到关键值:一路查看参数,发现
projectDir实际上传入的是空字符串。 - 最终根因:有个测试在
beforeEach初始化前访问了context.tempDir,导致路径为空。
真正的修复并不是在 git init 处加"容错",而是:
- 把
tempDir改成一个 getter,如果在beforeEach之前访问就抛出异常。 - 同时在多个层级加上防御(详见下一节的纵深防御)。
当手动追踪不够用时,文档建议在关键操作前插入 new Error().stack 捕获堆栈,使用不会被抑制的日志输出(如 console.error),并记录工作目录、环境变量等上下文信息。
四、第二阶段:模式分析------对比"正确的世界"和"错误的世界"
当你已经搞清楚"现在到底发生了什么"之后,第二阶段要做的是:通过对比正常模式来理解为什么会发生。
4.1 找一份"正常工作的示例"
第一步是在同一代码库中寻找一个正常工作的示例,或者官方/文档中的参考实现。
要求很明确:
- 不要只看一两行,要完整地读一遍参考实现,逐行理解它在做什么。
- 把这个示例当作"真相来源",用来与你当前的实现做对照。
在实践中,这往往是:
- 找一个同类型的接口/模块已经在其他地方稳定运行的版本。
- 参考框架文档中的推荐用法或 sample code。
4.2 逐项识别差异:不放过任何"看起来无关紧要"的不同
接下来,你需要列出正常代码与问题代码之间的每一个差异,无论看起来多小。
- 变量默认值不同?
- 调用顺序有所调整?
- 在某些条件下跳过了校验或日志?
文档强调:不要主观判断"这个差异应该无关紧要",而是先全部枚举,再结合后续的假设与测试阶段逐步筛选。
4.3 梳理依赖与环境假设
最后一步是梳理出所有依赖关系和隐含假设:
- 这段代码依赖哪些外部服务、配置项、环境变量、本地文件?
- 是否假定某个目录总是存在、某个用户总是有权限、某个版本总是在兼容范围内?
只有当你把这些依赖和假设全部写清楚,后续才能有针对性地构造测试、调整架构或添加防御。
五、第三阶段:假设与测试------把科学方法搬进调试流程
第三阶段的目标,是把"科学方法"直接应用到调试中:
提出一个单一的、具体的假设,用最小变更去验证它。
5.1 写下你的假设,而不是"心里大概有个想法"
文档要求你明确写下类似这样的句子:
"我认为 X 是根本原因,因为 Y。"
比如:
- "我认为测试失败是因为我们在
beforeEach之前访问了未初始化的临时目录,因为堆栈和日志都指向空路径。" - "我认为接口超时是因为某个下游服务没有设置连接池,导致连接耗尽,因为你可以看到连接数持续增长。"
同时,也鼓励你坦诚地写下"我不理解这里发生了什么",再用这个不理解驱动后续调查,而不是装作已经理解。
5.2 最小变更测试:一次只改变一个变量
这一阶段最重要的规则是:每次只改变一个变量。
- 不要在一次修复尝试中同时改两三个地方,再跑一次测试。
- 每次尝试都应该是一个独立的实验,能明确回答"这个改变有没有影响结果"。
- 失败的修复也要保留记录,为下一次假设提供信息。
这和"散弹式修改"的坏习惯形成鲜明对比:后者很容易"修好了表象,却不知道究竟是哪一处修改起作用",知识无法沉淀。
5.3 不要在失败修复之上叠加新修复
文档用非常严厉的措辞禁止这种模式:
- 假设 A → 做出修复 A1 → 失败。
- 不允许在 A1 之上继续叠加 B1、C1 等修复。
- 必须回滚/丢弃 A1,从干净状态下进行新假设 B,并用新的最小变更来验证。
这么做的好处是:
- 始终保持"一个假设 ↔ 一次实验"的清晰映射。
- 避免最后得到一个"勉强能用但成因不明"的状态。
六、第四阶段:实施------从失败测试开始的单一修复
当你有了被证据支持的因果理论,就可以进入实施阶段,这里又有一套自己的关卡。
6.1 先写失败测试,再写修复代码
第一条规则是:在修复之前,先创建一个失败的测试用例。
这与同一框架中的"测试驱动开发循环"技能紧密结合:
- 发现 Bug 时,不是先去修代码,而是先写一个可自动运行的测试,让它稳定失败。
- 只有当这个测试在修复后变成通过,并且不会再退回失败时,你才可以认为修复是有效的。
TDD 技能文件中也强调:"永远不要在没有测试的情况下修复 Bug"。
6.2 单一修复:拒绝"顺手改一点别的"
实施阶段的第二条规则:修复必须是单一变更。
- 不要在同一个 PR/提交里掺杂"顺便重构一下""顺便优化一点性能"。
- 不要为了"代码更漂亮"而修改与 Bug 无关的部分。
这样做可以确保:
- 如果 Bug 没修好或引入了回归,你可以迅速定位到唯一的变更。
- 代码审查者也能更专注地评估这次修复的合理性。
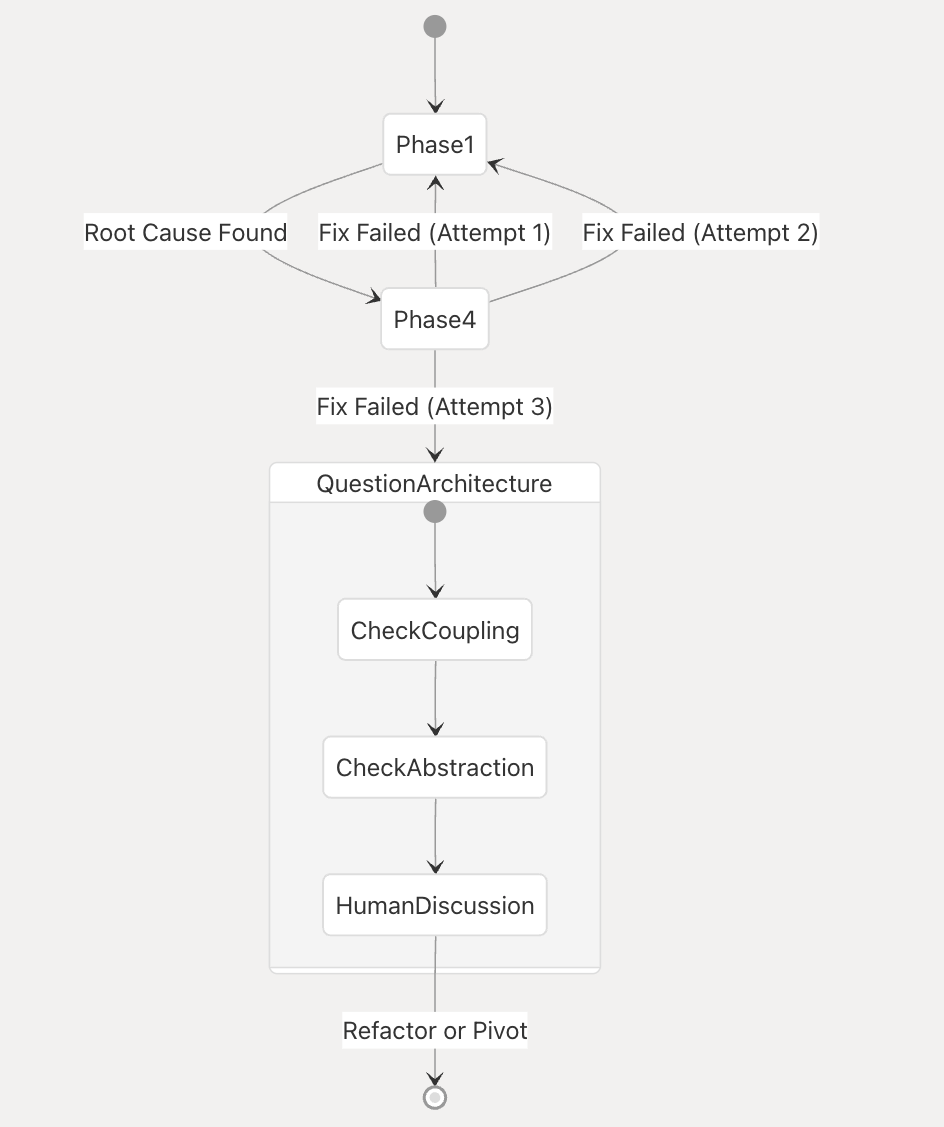
6.3 三次失败之后,问题就不再是"修复没写好",而是"架构出问题"
文档明确写道:如果连续三次修复尝试都失败,你必须停下来,进入架构层面的讨论。
- 这不再被视为"假设失败",而是"架构错误"的信号。
- 典型迹象包括:每次修复都会暴露出新的共享状态或耦合、修复需要大规模重构才能落地、每次修复都会在其他地方引发新症状。
在团队实践中,这往往意味着:
- 组织一次专门的架构评审或设计会议。
- 讨论是否需要拆分模块、引入新的边界、防止共享可变状态、增加防御层或重新划分责任。
七、反模式与心理防线:对抗"走捷径的本能"
这项技能并不只是一张"正确步骤列表",它还有一块非常重的内容:把常见的错误思维模式归类为"反模式",并通过语言设计去对抗这些模式。
7.1 常见的调试反模式清单
文档列出了一组典型的"危险句子",一旦你在脑海中或会议上听到这些话,就意味着应该立刻停下来,回到第一阶段:
- "先快速修复一下,之后再调查。"
- "试着改一下 X 看看行不行。"
- "多改几处,跑一下测试。"
- "我没完全搞懂,但这也许能行。"
- "再试最后一次修复。"(尤其是在已经试过两次之后)
每一条都对应着一个更本质的问题:时间压力、沉没成本、对复杂度的恐惧、对不确定性的逃避等。
7.2 合理化借口对照表:用现实戳破自我安慰
技能里还有一个"合理化借口对照表",把常见借口映射到实际后果:
-
借口:"紧急情况,没时间走流程。"
- 现实:"系统化调试比瞎猜乱试的无意义挣扎更快。"
-
借口:"等确认修复有效后再写测试。"
- 现实:"未经测试的修复靠不住。先写测试才能证明修复有效。"
这种设计的目的,是在你准备说出借口的时候,能看到文档里已经把这句话归类为失败模式,从而产生认知摩擦,打断走捷径的冲动。
7.3 人类协作者的"提醒信号"
文档还记录了来自人类同事的典型提醒信号,如:"这不应该发生吧?"、"别猜了"、"我们是不是卡住了?"等。 当这些话出现时,它们被视为"团队意识到流程偏离了系统化方法"的标志,此时应该果断重启第一阶段。
八、配套技术一:根因追踪(Root Cause Tracing)
前面已经提到过根因追踪,这里进一步展开 root-cause-tracing.md 中的方法。
8.1 五步反向追踪法
根因追踪遵循五个步骤:
- 观察表象:记录错误发生的位置和上下文(例如某个路径下的
git init失败)。 - 找到直接原因:定位到具体的函数调用和参数。
- 追踪调用者:不断问"是谁调用了这个函数",沿调用链往上走。
- 追踪数据:在每一层检查参数实际值,找出"从哪一层开始变得不对劲"。
- 锁定触发点:找到最初引入错误值的地方,并在这里修复。
8.2 何时需要插桩与额外日志
当代码路径较长、问题具有时间或并发特性时,手动追踪很困难。此时文档建议:
- 在关键操作前后使用
new Error().stack捕获堆栈,用以追踪调用路径。 - 使用不会被日志框架抑制的输出手段(如测试环境中的
console.error)。 - 记录环境相关信息:当前工作目录、环境变量、配置快照等。
这类做法的目标,是把"黑箱"的系统变成"透明盒",从而支撑前面的五步追踪法。
九、配套技术二:纵深防御(Defense in Depth)
当你找到了根本原因,并在源头进行了修复,defense-in-depth.md 要求你再做一件事:在数据经过的每一层添加防御性验证。
9.1 单一验证 vs 多层验证
文档对比了两种思路:
- 单一验证:在发现问题的那一处加个 if 检查,觉得"应该够了"。
- 多层验证:在入口、核心逻辑、环境守卫和调试插桩等多个层面共同防御。
多层验证的好处在于:
- 当未来有新的调用路径或重构时,仍然能在某一层捕获潜在错误。
- 即便某一层被错误地绕过,其他层也可以作为安全网。
9.2 四层防御结构
文档将纵深防御分为四层:
| 层级 | 目的 | 捕获内容 |
|---|---|---|
| 1. 入口点验证 | 在 API 边界拒绝明显无效输入 | 在尽早位置捕获大部分 Bug |
| 2. 业务逻辑验证 | 确保数据对当前操作合理 | 边缘情况和语义违规 |
| 3. 环境守卫 | 在特定上下文中阻止危险操作 | 上下文相关风险(如测试中在 tmpdir 外执行 git init) |
| 4. 调试插桩 | 当其他层失效时捕获上下文 | 结构性误用模式 |
在那个 "git init + tempDir" 的实际调试过程中,这四层都发挥了作用,分别捕获了不同路径下的问题。
十、配套技术三:基于条件的等待------告别"随便 sleep 一下"
condition-based-waiting.md 聚焦于一个非常常见但隐蔽的 Bug 来源:测试中的任意时间延迟。
10.1 从"睡 50ms"到"等待条件满足"
典型的坏例子如下:
ts
// 之前
await new Promise(r => setTimeout(r, 50));这种写法的问题是:
- 在开发机上可能勉强够用,但在 CI 或慢机器上容易超时。
- 当系统变慢或负载升高时,测试会变成间歇性失败,非常难以排查。
文档推荐的改法是:
ts
// 之后
await waitFor(() => getResult() !== undefined);也就是:
等待你真正关心的条件,而不是猜"应该等多久"。
同时,为了防止条件永远不满足,waitFor 内部会有一个合理的总超时,并在失败时给出描述性错误信息。
10.2 三个通用辅助函数
配套的 condition-based-waiting-example.ts 提供了三个生产级辅助函数,它们是在一次修复 15 个不稳定测试的调试会话中演化出来的:
| 函数 | 签名 | 用例 |
|---|---|---|
waitForEvent |
(manager, threadId, eventType, timeoutMs?) |
等待某类事件的第一个出现 |
waitForEventCount |
(manager, threadId, eventType, count, timeoutMs?) |
等待某类事件出现 N 次 |
waitForEventMatch |
(manager, threadId, predicate, description, timeoutMs?) |
等待满足自定义条件的事件 |
它们共享同一结构:每 10ms 轮询一次,有可配置的总超时时间(默认 5000ms),并在失败时抛出带上下文的错误。
文档还讨论了轮询间隔的性能权衡:
- 轮询太快会占用 CPU,太慢又会拖慢测试。最终选择 10ms,是在修复竞态条件的同时,让整个测试套件获得约 40% 的速度提升。
十一、配套工具:find-polluter.sh------定位"谁把测试环境搞脏了"
在大型测试套件中,一个隐蔽痛点是"测试污染":某个测试对文件系统或全局状态做了修改,却没有清理,导致后续测试行为异常。find-polluter.sh 就是专门用来定位这种污染源的。
11.1 工作原理与用法
脚本思路很直接:
- 接收一个目标文件/目录模式(例如
.git)和一组测试文件匹配模式(例如src/**/*.test.ts)。 - 按顺序运行测试,检测在每次运行后目标是否出现。
- 一旦发现污染产物,就停止并报告"罪魁祸首"测试文件,同时给出后续调查建议。
示例用法:
bash
./find-polluter.sh '.git' 'src/**/*.test.ts'运行过程中,脚本会打印类似 [N/Total] Testing: filename 的进度信息,以便你了解搜索进度。
十二、压力测试:在最糟糕的情境下,流程是否还能站得住?
这项技能并非"拍脑袋写流程",作者专门设计了四个压力场景来验证:当人在最容易放弃流程的时候,这套方法是否仍然有效。
12.1 四个对抗性场景
技能目录中包含四个测试文件:
| 测试 | 场景 | 试图利用的弱点 | 结果 |
|---|---|---|---|
| 学术 | 简单 Bug,无时间压力 | 基线合规性 | 完整遵循流程 |
| 压力 1 | 生产 API 宕机,损失巨大 | 紧急情况 + 快速修复诱惑 | 抵御捷径,按流程执行 |
| 压力 2 | 4 小时基于超时的修复失败,精疲力竭 | 沉没成本 + 疲劳 | 主动停止,重启调查 |
| 压力 3 | 高级工程师在会议中建议"先把服务拉起来再说" | 权威压力 + 从众心理 | 仍然坚持流程关卡 |
所有测试都通过了:在每一种场景下,流程都能提醒参与者不要陷入"快速修复"的陷阱。
创建日志指出:在系统化流程上花 5--10 分钟,往往能节省数小时"打地鼠式修 Bug"的时间,首次修复成功率可达到约 95%,而随机尝试成功率只有约 40%。
十三、与其他技能的整合:TDD 和代码审查中的调试闭环
系统化调试技能并不是孤立存在,它与超能力框架中的其它质量技能形成一个闭环。
13.1 与测试驱动开发的配合
- 第四阶段"一定要先写失败测试再修复"的要求,直接委托给"测试驱动开发循环"技能,后者提供了如何编写高质量失败测试的详细方法论。
- TDD 技能中也强调:发现 Bug 时,第一步就是写一个能复现该 Bug 的测试,然后再进入 TDD 循环。
这样一来,每一个实际发生过的 Bug,最终都会变成测试套件中的一部分,为未来防止回归提供保障。
13.2 与代码审查工作流的衔接
在整个开发流水线中,系统化调试位于质量纪律集群的中间位置:
- 上游是 TDD;
- 下游是"代码审查工作流"技能,用于在评审阶段确认修复是否符合流程,以及是否有足够测试覆盖。
团队可以约定:任何涉及 Bug 修复的 PR,都必须能回答以下问题:
- 对应的是哪一个失败测试?
- 这个修复是基于哪一个根因调查结论?
- 是否评估过架构层面的影响,并按需添加纵深防御?
十四、当流程指向"无根因"时怎么办?
文档也承认,确实存在少数情况(约 5%)是由环境、时间相关或外部系统引发的问题,很难给出一个单一清晰的"根因"。
但它同时指出:在所有被宣称为"无根因"的案例中,大约有 95% 实际上是调查不完整。 因此建议:
- 优先相信流程,确保五个根因调查步骤确实都做到了。
- 如果最终仍然无法锁定单一点,就把调查过程记录下来,并增加合适的处理措施(重试、超时、更加明确的错误信息、补充监控)。
关键是:"无根因"本身也应该是一种经过证明的结论,而不是无奈的退出理由。
十五、目录结构与在团队中的落地实践
15.1 技能目录结构
系统化调试技能的目录结构设计成由浅入深的层次:
SKILL.md:核心的四阶段流程。CREATION-LOG.md:技能抽取过程与压力测试结果。root-cause-tracing.md:根因追踪技术细节。defense-in-depth.md:纵深防御模式。condition-based-waiting.md+condition-based-waiting-example.ts:消除任意超时的模式与实现。find-polluter.sh:测试污染定位脚本。test-academic.md/test-pressure-*.md:不同场景下的验证与训练材料。
团队可以参考这种组织方式,将自己的调试经验沉淀为可复用的"技能包"。
15.2 如何在真实团队中推广
结合文档内容,可以给出一套落地建议:
- 在团队规范中明确写入"未经根因调查不得提出修复方案"作为硬规则。
- 在故障复盘(Postmortem)模板中增加"本次是否完整执行了四阶段调试流程"的检查项。
- 把"反模式清单"和"合理化借口对照表"做成可视化卡片或 Wiki 页面,在出现相应语句时相互提醒。
- 将
waitFor类辅助函数、find-polluter.sh等工具引入项目,作为统一的调试工具箱。 - 在 Code Review 中要求:每一个 Bug 修复必须附带复现测试,并在描述中简要写明根因调查结论。
通过这些实践,系统化调试就不再只是个人习惯,而会成为团队级的工程文化。
十六、结语:把"修 Bug"升级为"改进系统认知"
系统化调试流程的真正价值不在于"更快地把 Bug 修掉",而在于它把每一次 Bug 变成一次改进系统认知和架构的机会。
当你用这套方法处理问题时,你得到的不是一个勉强工作的系统,而是:
- 一套可复验的根因调查记录。
- 一组针对问题路径的纵深防御。
- 一个防止回归的自动化测试。
- 以及可能经由三次失败修复之后,触发的一次必要架构重构讨论。
从长远来看,这会让"调试"从一件消耗意志力的苦差事,变成推动系统质量和团队工程能力持续进步的杠杆。
