在 AI Agent 时代,数据仓库不再只是"被查询的对象",而是 Agent 可以自主操作、理解、优化的智能基础设施。Hologres AI Plugins 让每一位开发者和 AI Agent 都能安全、高效地驾驭 Hologres。
一、AI Agent 时代,数据仓库需要变
过去,我们用 SQL 手动查库、手动调优、手动排障。DBA 是数据仓库的"翻译官"。
但在 AI Agent 时代,范式变了:
-
Claude Code 在帮你写代码时,需要查看线上表结构;
-
Cursor 在优化 SQL 时,需要读取执行计划;
-
OpenAI Codex 在排查慢查询时,需要分析
hg_query_log。
Agent 不会手动打开 DBeaver,也不会去翻运维文档。它需要的是:
| Agent 需要什么 | 传统方式 | Agent-Ready 方式 |
|---|---|---|
| 查看表结构 | 登录控制台,找到数据库 | hologres schema describe orders |
| 执行 SQL | 打开 SQL 编辑器 | hologres sql run "SELECT ..." |
| 分析执行计划 | 手工 EXPLAIN | hologres sql explain "SELECT ..." |
| 调整参数 | ALTER DATABASE 手写 | hologres guc set param value |
| 创建动态表 | 拼 DDL | hologres dt create -t my_dt --freshness "10 min" -q "..." |
Agent 需要"结构化输入、结构化输出、安全护栏"的 CLI,而不是给人看的 GUI。
这就是 Hologres AI Plugins 解决的问题。
二、整体架构:两层设计,让 Agent 从"能用"到"会用"
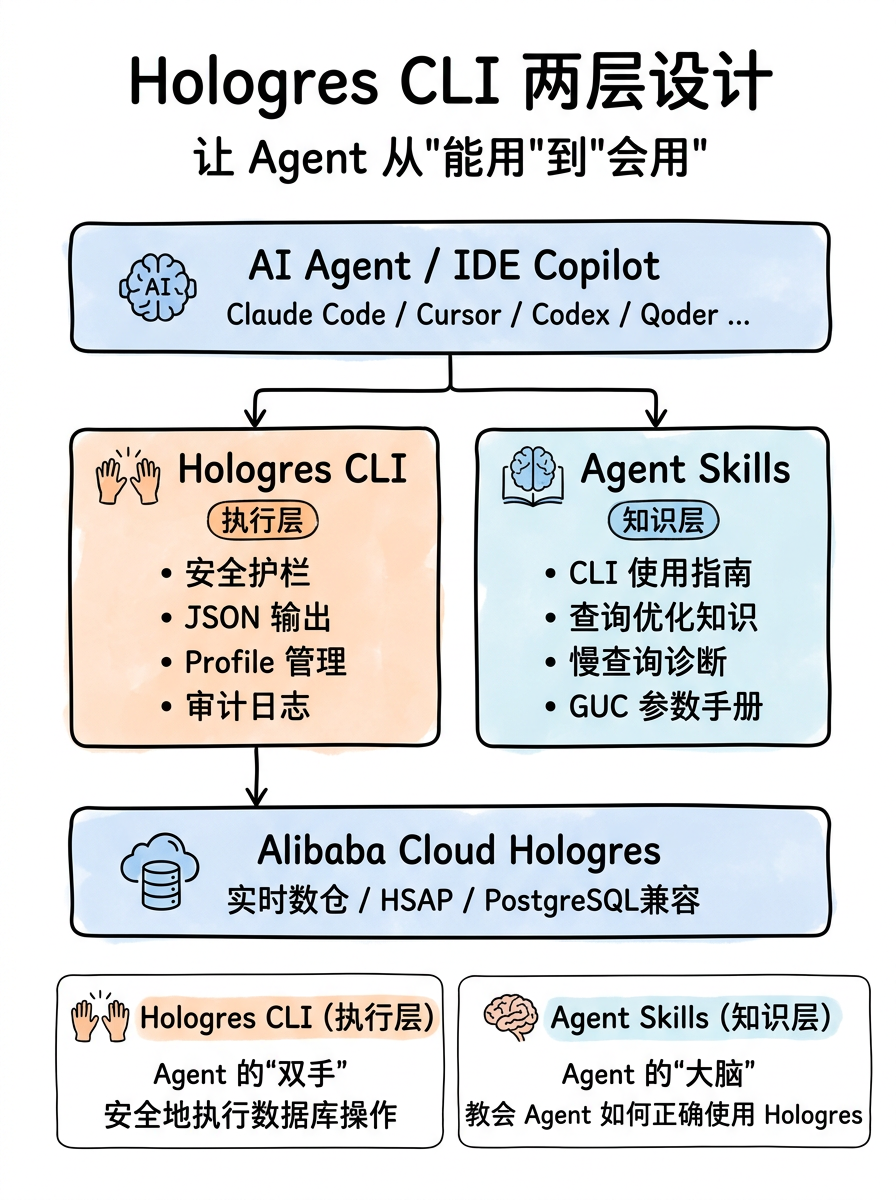
plaintext
┌─────────────────────────────────────────────────────────┐
│ AI Agent / IDE Copilot │
│ (Claude Code / Cursor / Codex / Qoder ...) │
└─────────────────────┬───────────────────────────────────┘
│
┌─────────────┴─────────────┐
│ │
▼ ▼
┌───────────────┐ ┌──────────────────┐
│ Hologres CLI │ │ Agent Skills │
│ (执行层) │ │ (知识层) │
│ │ │ │
│ • 安全护栏 │ │ • CLI 使用指南 │
│ • JSON 输出 │ │ • 查询优化知识 │
│ • Profile 管理│ │ • 慢查询诊断 │
│ • 审计日志 │ │ • GUC 参数手册 │
└───────┬───────┘ └──────────────────┘
│
▼
┌───────────────────────────────────────┐
│ Alibaba Cloud Hologres │
│ (实时数仓 / HSAP / PostgreSQL兼容) │
└───────────────────────────────────────┘-
Hologres CLI(执行层):Agent 的"双手",安全地执行数据库操作
-
Agent Skills(知识层):Agent 的"大脑",教会 Agent 如何正确使用 Hologres。
三、Hologres CLI:为 Agent 设计的安全命令行
3.1 JSON-First:Agent 天然能理解
所有命令默认返回结构化 JSON:
bash
$ hologres status
{
"ok": true,
"data": {
"connected": true,
"version": "Hologres 4.1.0",
"database": "production_db"
}
}AI Agent 看到 "ok": true,就知道操作成功;看到 "ok": false,就能根据 error.code 精准定位问题。不需要正则解析,不需要猜测输出格式。
同时支持 4 种输出格式------JSON / Table / CSV / JSONL------满足不同场景需求:
bash
hologres -f json schema tables # Agent 消费
hologres -f table schema tables # 人类阅读
hologres -f csv schema tables # 数据导出
hologres -f jsonl schema tables # 流式处理3.2 六层安全护栏:让 Agent 不会"闯祸"
在 AI Agent 自主操作数据库时,安全是第一要务。Hologres CLI 内置了六层递进式安全机制,其中前三层构成写操作三层纵深防御体系:
通过
拦截
通过
拦截
通过
拦截
通过
拦截
Agent 发起操作
第一层:行数限制保护
第二层:连接级只读保护
第三层:写操作显式授权
第四层:危险操作阻断
第五层:Serverless 计算隔离
第六层:Adaptive Execution 防 OOM
Hologres 数据库
LIMIT_REQUIRED
数据库引擎拒绝写入
WRITE_GUARD_ERROR
DANGEROUS_WRITE_BLOCKED
第一层:行数限制保护
bash
# Agent 写了个没有 LIMIT 的 SELECT?自动拦截!
$ hologres sql run "SELECT * FROM orders"
{"ok": false, "error": {"code": "LIMIT_REQUIRED", "message": "Query returns >100 rows, add LIMIT clause"}}Agent 看到 LIMIT_REQUIRED,自动补上 LIMIT 100 重试。零人工干预。
第二层:连接级只读保护------数据库引擎兜底
Hologres CLI 的所有连接默认只读,创建连接后立即执行:
sql
SET default_transaction_read_only = ON;这意味着即使 Agent 绕过了 CLI 层面的所有检查,数据库引擎也会拒绝任何写操作。只有当命令明确需要写入时,CLI 才会创建可写连接(read_only=False)。
bash
# 默认只读连接------数据库引擎直接拒绝
$ hologres sql run "INSERT INTO logs VALUES (1, 'test')"
{"ok": false, "error": {"code": "WRITE_GUARD_ERROR"}}
# 即使直接发送 SQL,连接层也会拦截
# 因为连接本身就是 read_only 的写意图确认方式一览表------只有以下方式才会创建可写连接:
| 写意图确认方式 | 命令 | 连接模式 |
|---|---|---|
--write 标志 |
sql run --write "INSERT ..." |
read_only=False |
--confirm 确认 |
dt drop --confirm, table drop --confirm, table truncate --confirm, |
read_only=False |
非 --dry-run 执行 |
dt create, dt alter |
read_only=False |
| 命令本身即写意图 | guc set / reset,extension create |
read_only=False |
| 无写意图(默认) | 所有查询、所有 list / show / describe 操作 | read_only=True |
plaintext
三层写保护纵深防御:
┌─────────────────────────────────────────────┐
│ Layer 1: 连接层 (数据库引擎) │
│ SET default_transaction_read_only = ON │
│ → 即使所有 CLI 检查被绕过,DB 也拒绝写入 │
├─────────────────────────────────────────────┤
│ Layer 2: CLI 层 (--write 标志) │
│ → sql run 必须显式 --write 才允许写操作 │
├─────────────────────────────────────────────┤
│ Layer 3: 安全层 (危险 SQL 检测) │
│ → DELETE/UPDATE 无 WHERE 直接阻断 │
└─────────────────────────────────────────────┘第三层:写操作显式授权
bash
# 所有 SQL 写操作必须显式加 --write 标志
$ hologres sql run "INSERT INTO logs VALUES (1, 'test')"
{"ok": false, "error": {"code": "WRITE_GUARD_ERROR"}}
# 明确意图后才放行
$ hologres sql run --write "INSERT INTO logs VALUES (1, 'test')"
{"ok": true}第四层:危险操作阻断
bash
# 没有 WHERE 的 DELETE?直接拦截,不商量
$ hologres sql run --write "DELETE FROM users"
{"ok": false, "error": {"code": "DANGEROUS_WRITE_BLOCKED"}}第五层:Serverless 计算隔离------Agent 查询不冲击生产
AI Agent 最大的隐患之一:一条未优化的复杂 SQL 可能瞬间打满实例资源,导致线上业务 failover。
Hologres CLI 默认将所有 Agent 发起的 SQL 路由到 Serverless Computing 资源组执行:
bash
# Agent 执行的每条 SQL,底层自动走 Serverless 资源
$ hologres sql run "SELECT region, SUM(amount) FROM orders GROUP BY region LIMIT 100"
# 内部实际执行:SET hg_computing_resource = 'serverless'; SELECT ...这意味着:
-
生产实例零冲击:Agent 的查询使用独立的 Serverless 算力池,不占用实例本地资源
-
弹性伸缩:复杂查询自动获得更多计算资源,无需人工扩容
-
天然隔离:即使 Agent 连续发起多条重查询,也不会影响在线服务的延迟和稳定性
plaintext
┌──────────────┐ ┌──────────────────────┐
│ AI Agent │────▶│ Hologres CLI │
│ (查询请求) │ │ routing=serverless │
└──────────────┘ └──────────┬───────────┘
│
┌──────────┴───────────┐
│ │
┌─────▼──────┐ ┌────────▼─────────┐
│ Serverless │ │ Local Instance │
│ 算力池 │ │ (在线业务专用) │
│ Agent SQL │ │ 不受 Agent 影响 │
└────────────┘ └──────────────────┘第六层:Adaptive Execution------复杂 SQL 不会 OOM
Agent 生成的 SQL 复杂度不可预测------可能是简单的 SELECT *,也可能是多表 JOIN + 子查询 + 窗口函数。如果用固定的执行策略,轻则浪费资源,重则内存溢出(OOM)导致查询失败。
Hologres CLI 启用 Adaptive Execution Stage 模式,根据 SQL 复杂度智能选择执行策略:
bash
# 内部自动设置自适应执行
# SET hg_experimental_enable_adaptive_execution = on;| SQL 复杂度 | 执行策略 | 效果 |
|---|---|---|
| 简单查询(单表扫描) | 单阶段直接执行 | 低延迟,快速返回 |
| 中等查询(JOIN + 聚合) | 多阶段流水线 | 平衡资源与性能 |
| 复杂查询(多表 JOIN + 窗口函数) | 自适应分阶段 | 中间结果落盘,避免内存溢出 |
核心原理:当优化器检测到某个算子的中间结果可能超过内存阈值时,自动将执行计划拆分为多个 Stage,中间结果通过磁盘 Shuffle 交换,用可控的性能代价换取执行的确定性。
plaintext
Agent SQL ──▶ 优化器评估复杂度
│
┌────────┴────────┐
│ 简单SQL │ 复杂SQL
▼ ▼
单阶段执行 多阶段自适应执行
(内存完成) (中间结果落盘)
│ │
└────────┬────────┘
▼
安全返回结果
(不 OOM)Serverless + Adaptive Execution 的组合拳,让 Agent 的每一条 SQL 都运行在"安全沙箱"中------既不冲击生产实例,也不会因为内存不足而崩溃。这是传统 CLI 工具不具备的 AI-Native 安全能力。
六层护栏设计的核心理念是:Agent 可以自由探索,但不会意外破坏数据,也不会冲击线上稳定性。连接级只读 + CLI 写守卫 + 危险 SQL 阻断,三层纵深防御让写保护"滴水不漏"。
3.3 敏感数据脱敏:自动保护隐私
当 Agent 查询包含敏感字段的数据时,CLI 自动按列名模式识别并脱敏:
| 字段模式 | 原始数据 | 脱敏后 |
|---|---|---|
| phone / mobile | 13812345678 | 138****5678 |
| john@example.com | j***@example.com |
|
| password / token | mysecret123 | ******** |
| id_card / ssn | 110101199001011234 | 110***********1234 |
| bank_card | 6222021234567890 | ************7890 |
Agent 能拿到数据做分析,但不会泄露用户隐私。
3.4 Profile 多环境管理
一条命令切换 dev / staging / prod 环境:
bash
hologres config # 交互式配置向导
hologres --profile prod status # 切换到生产环境
hologres --profile dev schema tables # 开发环境查表Agent 可以根据上下文自动选择环境,像经验丰富的 DBA 一样在多套环境间切换。
3.5 60+ 命令全覆盖
从日常查询到高级管理,覆盖 Hologres 全部核心场景:
plaintext
Schema 管理 ─── schema tables / describe / dump / size
Table 管理 ─── table list / create / show / properties / drop / truncate
View 管理 ─── view list / show
SQL 执行 ─── sql run / explain
数据导入导出 ─── data export / import / count
动态表生命周期 ─── dt create / list / show / ddl / lineage / refresh / alter / drop
GUC 参数管理 ─── guc show / set / reset / list
扩展管理 ─── extension list / create
实例信息 ─── instance / warehouse / status四、Agent Skills:教 AI 成为 Hologres 专家
CLI 解决了"能操作"的问题,但 Agent 还需要"会操作"------知道什么时候用什么命令,知道如何优化查询,知道如何诊断问题。
这就是 Agent Skills 的价值。
4.1 技能全景图
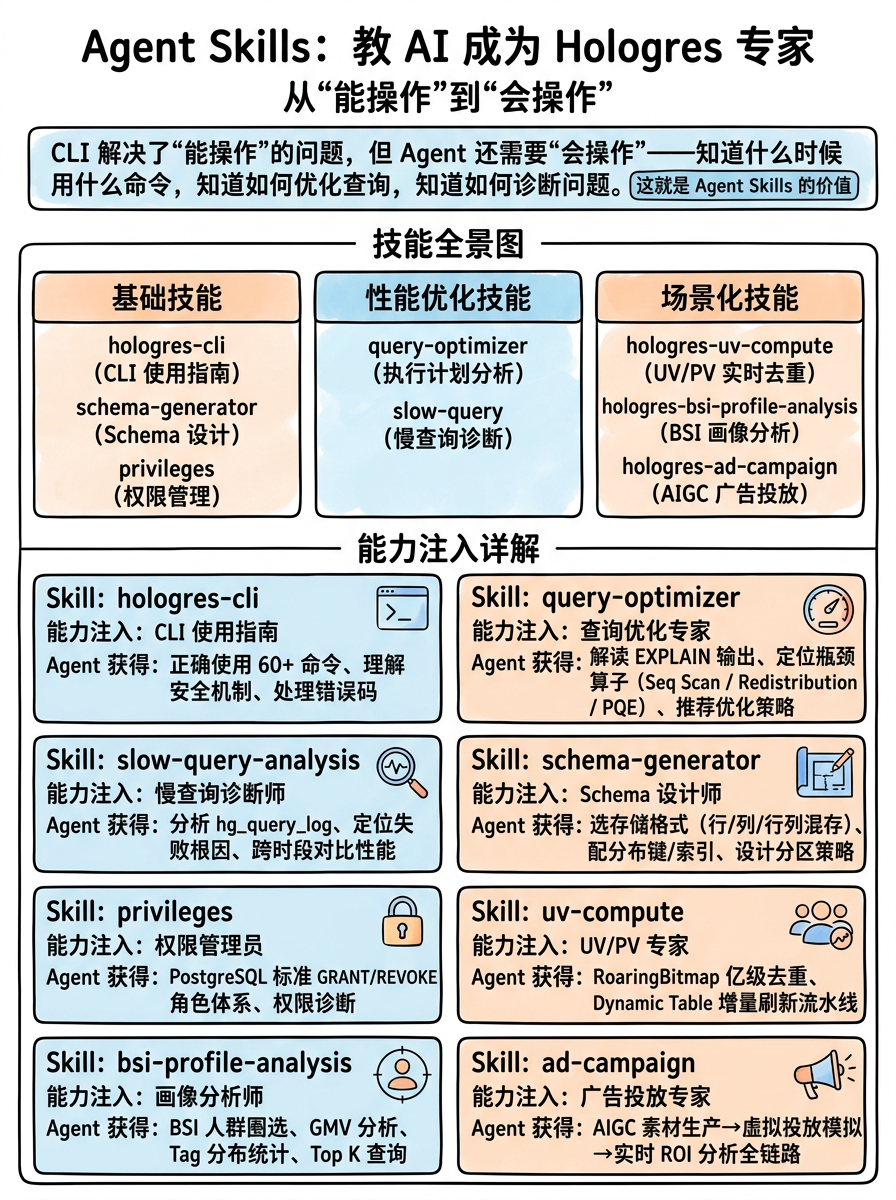
plaintext
┌─────────────────────────────────────────────────────────────────────────┐
│ Agent Skills (知识层) │
├─────────────────┬──────────────────┬────────────────────────────────────┤
│ 基础技能 │ 性能优化技能 │ 场景化技能 │
│ │ │ │
│ hologres-cli │ query-optimizer │ hologres-uv-compute │
│ (CLI 使用指南) │ (执行计划分析) │ (UV/PV 实时去重) │
│ │ │ │
│ schema-generator│ slow-query │ hologres-bsi-profile-analysis │
│ (Schema 设计) │ (慢查询诊断) │ (BSI 画像分析) │
│ │ │ │
│ privileges │ │ hologres-ad-campaign │
│ (权限管理) │ │ (AIGC 广告投放) │
└─────────────────┴──────────────────┴────────────────────────────────────┘| Skill | 能力注入 | Agent 获得什么 |
|---|---|---|
| hologres-cli | CLI 使用指南 | 正确使用 60+ 命令、理解安全机制、处理错误码 |
| query-optimizer | 查询优化专家 | 解读 EXPLAIN 输出、定位瓶颈算子(Seq Scan / Redistribution / PQE)、推荐优化策略 |
| slow-query-analysis | 慢查询诊断师 | 分析 hg_query_log、定位失败根因、跨时段对比性能 |
| schema-generator | Schema 设计师 | 选存储格式(行/列/行列混存)、配分布键/索引、设计分区策略 |
| privileges | 权限管理员 | PostgreSQL 标准 GRANT/REVOKE、角色体系、权限诊断 |
| uv-compute | UV/PV 专家 | RoaringBitmap 亿级去重、Dynamic Table 增量刷新流水线 |
| bsi-profile-analysis | 画像分析师 | BSI 人群圈选、GMV 分析、Tag 分布统计、Top K 查询 |
| ad-campaign | 广告投放专家 | AIGC 素材生产→虚拟投放模拟→实时 ROI 分析全链路 |
4.2 查询优化三大技能包
教会 Agent
正确操作
教会 Agent
分析执行计划
教会 Agent
诊断慢查询
执行命令
安全访问
AI Agent
hologres-cli
CLI 使用指南
query-optimizer
查询优化专家
slow-query-analysis
慢查询诊断师
Hologres CLI
Hologres
技能一:hologres-cli ------ CLI 使用指南
教 Agent 正确使用 60+ 条命令,理解安全机制,处理错误码。Agent 看完这个 Skill,就知道:
-
查询大表要加 LIMIT
-
写操作要加 --write
-
DROP 操作默认是 dry-run,需要 --confirm
技能二:hologres-query-optimizer ------ 查询优化专家
把 Hologres 执行计划的解读经验浓缩成 AI 可消费的知识:
plaintext
Agent 分析流程:
1. 执行 EXPLAIN ANALYZE
2. 看 ADVICE 段获取系统建议
3. 识别瓶颈算子(Seq Scan?Redistribution?)
4. 对症下药(加索引?改分布键?调 GUC?)Agent 知道 rows=1000 意味着统计信息缺失要跑 ANALYZE;知道 Redistribution 意味着分布键不匹配要调整 distribution_key;知道 ExecuteExternalSQL 意味着走了 PQE 需要改写 SQL。
技能三:hologres-slow-query-analysis ------ 慢查询诊断师
基于 hologres.hg_query_log 系统表的诊断工作流:
-
找出最耗 CPU 的查询模式
-
定位失败查询的错误根因
-
分析查询各阶段(优化 / 启动 / 执行)的时间分布
-
跨时段对比(今天 vs 昨天同时段)
4.3 一键安装,支持 8 大 AI 工具
bash
# 一条命令安装到你的 AI 工具
uvx hologres-agent-skills交互式安装器支持 8 大主流 AI 开发工具:
PyPI: hologres-agent-skills
uvx hologres-agent-skills
交互式安装器
Claude Code
.claude/skills
Cursor
.cursor/skills
OpenAI Codex
.agents/skills
Qoder
.qoder/skills
GitHub Copilot
.github/skills
Trae
.trae/skills
OpenClaw
~/.openclaw/skills
OpenCode
.opencode/skills
选择工具、选择技能包、一键安装。Skills 文件自动复制到对应工具的 skills 目录。
五、AI Function:SQL 原生驱动 AIGC 内容生产
Hologres CLI 首创数据仓库原生 AI 创作能力------用 SQL 调用大模型生成文本、图片、视频,配合 Volume 存储实现全链路资产管理:
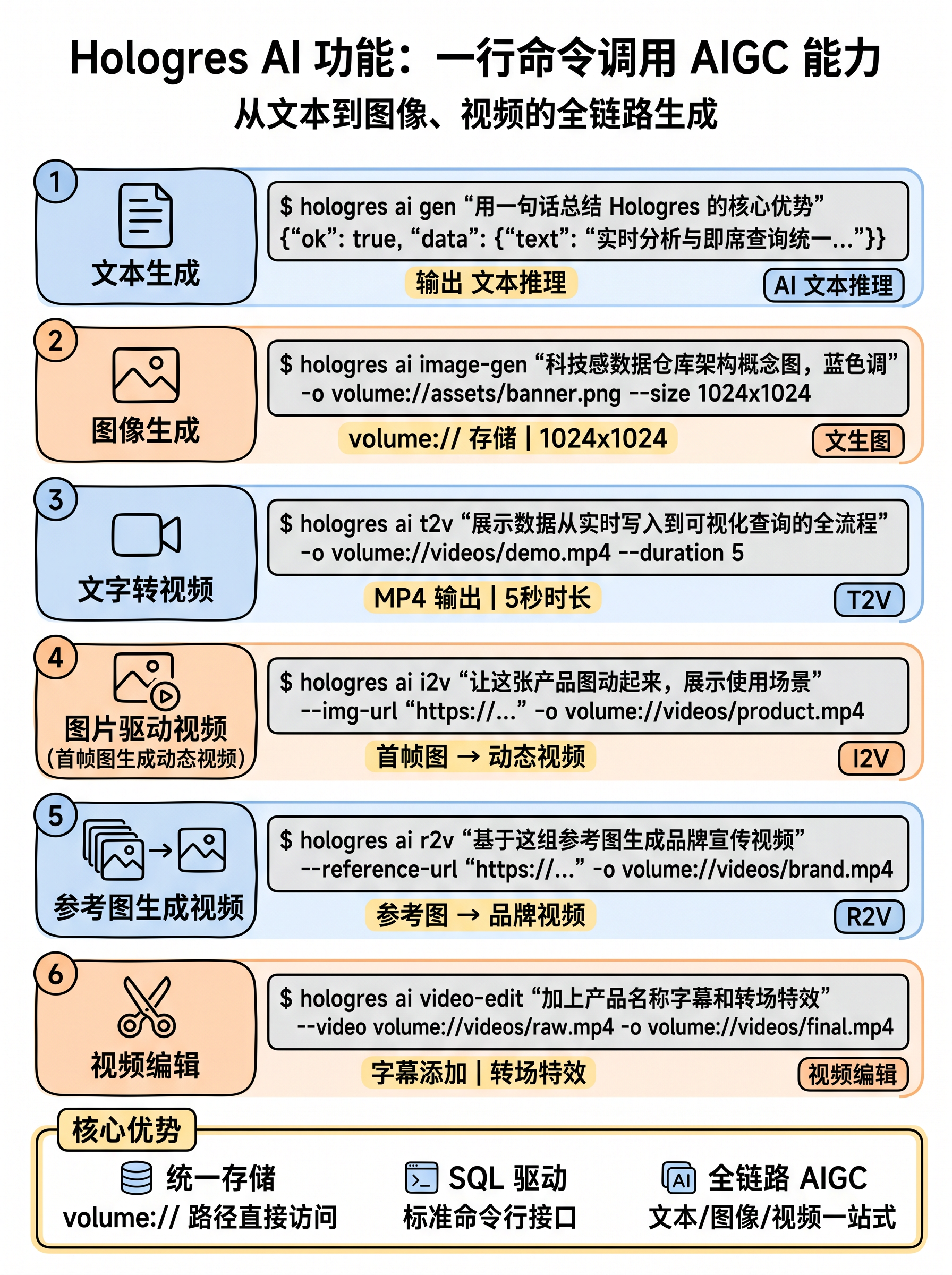
bash
# 注册模型到holo
hologres model create --name qwen3 --type qwen3.6-plus --api-key <api_key>
hologres model create --name qwen-image2 --type qwen-image-2.0-pro --api-key <api_key>
hologres model create --name happyhorse-t2v --type happyhorse-1.0-t2v --api-key <api_key>
hologres model create --name happyhorse-i2v --type happyhorse-1.0-i2v --api-key <api_key>
hologres model create --name happyhorse-r2v --type happyhorse-1.0-r2v --api-key <api_key>
hologres model create --name happyhorse-video-edit --type happyhorse-1.0-video-edit --api-key <api_key>
# 文本生成
$ hologres ai gen "用一句话总结 Hologres 的核心优势" --model qwen3
{"ok": true, "data": {"text": "实时分析与即席查询统一,行列混存兼顾事务与分析..."}}
# 图像生成到 Volume 存储
$ hologres ai image-gen "科技感数据仓库架构概念图,蓝色调" \
-o volume://assets/output/ --size 1024x1024 --model qwen-image2
# 文字转视频
$ hologres ai t2v "展示数据从实时写入到可视化查询的全流程" \
-o volume://videos/output/ --duration 5 --model happyhorse-t2v
# 图片驱动视频(首帧图生成动态视频)
$ hologres ai i2v "让这张产品图动起来,展示使用场景" \
--img-url volume://videos/firstframe.png \
-o volume://videos/output/ --model happyhorse-i2v
# 参考图生成视频
$ hologres ai r2v "基于这组参考图生成品牌宣传视频" \
--reference-url volume://videos/liubei.png \
-o volume://videos/output/ --model happyhorse-r2v
# 视频编辑
$ hologres ai video-edit "加上产品名称字幕和转场特效" \
--video volume://videos/raw.mp4 -o volume://videos/output/ \
--model happyhorse-video-editVolume 存储管理------Agent 的 AIGC 资产仓库:
bash
hologres volume create my-assets --endpoint oss-cn-hangzhou.aliyuncs.com ...
hologres volume upload-file --volume my-assets --local-file ./logo.png --target-file brand/logo.png
hologres volume list-files --volume my-assets --prefix brand/
hologres volume view volume://my-assets/brand/logo.png # 下载并打开预览模型管理
bash
# List所有支持的模型
hologres model catalog [--task T] [--search S]
# List hologres中注册的模型
hologres model list [--task T] [--model-type T] [--search S]
# 将一个支持的模型注册到hologres中
hologres model create --name qwen3 --type qwen3.6-plus --api-key <api_key>
# 从hologres删除一个注册的模型
hologres model delete qwen3 --confirm六、动态表全生命周期管理:AI 时代的实时数据编排
Hologres 动态表(Dynamic Table)是实时数仓的核心能力。在 AI Agent 时代,创建动态表不再需要手写复杂的 DDL------用自然语言告诉 Agent 你想要什么,Agent 会自动生成并执行。
postgresql
用户:"帮我基于 orders 表建一个按区域汇总的实时销售看板,5 分钟刷新一次"
Agent 思考链:
1. hologres schema describe orders → 理解源表结构
(region VARCHAR, amount DECIMAL, ds DATE, ...)
2. 根据用户意图,自动生成 CLI 命令:
hologres dt create -t region_sales_realtime \
--freshness "5 minutes" \
--refresh-mode incremental \
--computing-resource serverless \
-q "SELECT region, ds,
SUM(amount) AS total_amount,
COUNT(*) AS order_count,
AVG(amount) AS avg_amount
FROM orders GROUP BY region, ds" \
--dry-run
3. 先 --dry-run 预览 SQL → 展示给用户确认
4. 确认后去掉 --dry-run 正式创建
5. hologres dt show region_sales_realtime → 确认创建成功用户全程只说了一句话,Agent 完成了:理解表结构 → 设计聚合逻辑 → 选择刷新策略 → 安全预览 → 执行创建。
创建之后,Agent 同样可以自然语言管理整个生命周期:
bash
# "看看这个动态表的数据来源" → Agent 执行:
hologres dt lineage region_sales_realtime
# "刷新频率改成 1 分钟" → Agent 执行:
hologres dt alter region_sales_realtime --freshness "1 minute"
# "这个表不需要了" → Agent 执行(默认 dry-run,安全优先):
hologres dt drop region_sales_realtime # 只预览 SQL
hologres dt drop region_sales_realtime --confirm # 用户确认后真正执行Agent 可以根据业务需求,自主创建、调整、监控实时数据管道------而用户只需要用自然语言描述需求。
--dry-run
--confirm
dt create
创建动态表
dt list / show
查看状态
dt lineage
血缘分析
dt storage / state-size
存储监控
dt alter
调整属性
dt refresh
手动刷新
dt drop
安全删除
预览 SQL
真正执行
七、GUC 参数管理:数据库调优的"旋钮"
27 个常用 Hologres 参数,分类管理,--help 即查即用:
bash
$ hologres guc --help
Known Hologres GUC Parameters:
[Auto Analyze]
hg_enable_start_auto_analyze_worker
default=on 开启 Auto Analyze (V1.1+)
[Query Optimization]
optimizer_join_order
default=exhaustive Join 顺序策略 (exhaustive/query/greedy)
[Timeout & Connection]
statement_timeout
default=8h 活跃 Query 超时时间
...
bash
# 查看当前值
hologres guc show statement_timeout
# 数据库级持久化设置
hologres guc set statement_timeout '5min'
# 重置为默认值
hologres guc reset statement_timeout
# 查看所有参数当前值
hologres guc list八、端到端场景:Agent 如何用 Hologres 解决真实问题
场景一:Agent 自动排查线上慢查询
用户:线上数据库有点慢
hologres status
确认连接正常
hologres sql run
查询 hg_query_log 近 10 分钟
发现 3 条慢查询
hologres sql explain
分析执行计划
发现全表扫描
hologres guc show
检查 auto_analyze 配置
给出建议:
添加 clustering_key + ANALYZE
plaintext
用户:"线上数据库有点慢,帮我看看什么情况"
Agent 思考链:
1. hologres status → 确认连接正常
2. hologres sql run "SELECT status, duration, query::char(60)
FROM hologres.hg_query_log
WHERE query_start >= now() - interval '10 min'
ORDER BY duration DESC LIMIT 20"
→ 找到 3 条慢查询
3. hologres sql explain "SELECT ..." → 发现全表扫描
4. hologres guc show hg_enable_start_auto_analyze_worker → 确认 auto analyze 已开启
5. 给出建议:添加 clustering_key + 跑 ANALYZE场景二:Agent 完成 AIGC 广告全流程
plaintext
用户:"帮我为新品做一波小红书投放素材"
Agent 执行链(ad-campaign Skill 指导):
1. hologres ai image-gen "小红书风格,清新自然,新品展示" -o volume://creative/xhs1.png
2. hologres ai t2v "15秒种草短视频,展示产品使用场景" -o volume://creative/video1.mp4
3. hologres sql run --write "INSERT INTO ad_materials ..." # 素材入库
4. hologres dt create -t campaign_roi_realtime \
--freshness "1 minute" -q "SELECT channel, SUM(cost), SUM(conversion) ..."
→ 创建实时 ROI 监控看板
5. 基于 ROI 数据给出预算分配建议场景三:Agent 设计亿级 UV 实时去重
plaintext
用户:"我们有 5 亿用户,需要实时统计每天各频道 UV"
Agent 执行链(uv-compute Skill 指导):
1. 根据 Skill 知识,选择 RoaringBitmap + Dynamic Table 方案
2. hologres table create --name uid_mapping ... --dry-run # UID 字典编码表
3. hologres table create --name channel_bitmap ... --dry-run # Bitmap 基表
4. hologres dt create -t channel_uv_realtime \
--freshness "1 minute" --refresh-mode incremental \
-q "SELECT channel, ds, RB_BUILD_AGG(uid_int) AS uv_bitmap FROM ..."
5. 验证查询:hologres sql run "SELECT channel, RB_CARDINALITY(uv_bitmap) FROM ..."
→ 亚秒级返回亿级 UV场景四:Agent 设计高性能 Schema
plaintext
用户:"帮我设计一张订单表,日增 1 亿行,主要按时间范围查询"
Agent 执行链(schema-generator Skill 指导):
1. 分析查询模式 → 时间范围查询 → 列存 + 按日分区
2. hologres table create \
--name orders \
--columns "order_id BIGINT, user_id BIGINT, amount DECIMAL, region TEXT, order_time TIMESTAMPTZ" \
--distribution-key order_id \
--clustering-key order_time \
--orientation column \
--partition-by "LIST(ds)" \
--time-column order_time \
--dry-run
3. 预览 DDL → 解释设计决策:
- 列存:适合分析型查询
- clustering_key=order_time:时间范围查询加速
- distribution_key=order_id:均匀分布
- 按日分区:lifecycle 管理 + 查询裁剪
4. 用户确认后创建场景五:Agent 自动创建实时报表
plaintext
用户:"帮我建一个实时区域销售看板,每 5 分钟刷新"
Agent 思考链:
1. hologres schema describe orders → 确认源表结构
2. hologres dt create -t region_sales_rt
--freshness "5 minutes"
--refresh-mode incremental
--computing-resource serverless
-q "SELECT region, ds, SUM(amount) AS total, COUNT(*) AS cnt
FROM orders GROUP BY region, ds"
--dry-run → 预览 SQL
3. 确认无误后去掉 --dry-run 执行
4. hologres dt show region_sales_rt → 确认创建成功场景六:Agent 自动优化查询性能
plaintext
用户:"这个 SQL 跑了 30 秒,帮我优化"
Agent 思考链:
1. hologres sql explain "..." → 读取执行计划
2. 识别 Redistribution 算子 → 分布键不匹配
3. hologres table properties orders → 查看当前 distribution_key
4. 建议修改分布键 或 调整 GUC
5. hologres guc set optimizer_force_multistage_agg on --scope session
6. 重新 explain 验证效果九、为什么 Hologres AI Plugins 是 Agent-Friendly 的第一选择
| 维度 | Hologres AI Plugins | 传统 CLI / GUI | MCP 方案 |
|---|---|---|---|
| Agent 可解析 | JSON-First + 结构化错误码 | 自由文本,需正则 | JSON-RPC,但无领域语义 |
| 安全深度 | 6 层护栏(连接只读 + 计算隔离 + OOM 防护) | 最多参数校验 | 无安全层 |
| 凭据安全 | Fernet 加密 + 文件权限 0600 | 明文 / 环境变量 | 无 |
| 隐私保护 | 自动脱敏(手机/邮箱/身份证/银行卡) | 无 | 无 |
| 知识注入 | 8 个深度 Skill,覆盖优化/诊断/设计/画像/投放 | 无 | 无 |
| AIGC 原生 | SQL 驱动文生图/文生视频 + Volume 管理 | 无 | 需对接外部服务 |
| 可观测 | Skill 级追踪 + 审计日志 | 黑盒 | 部分 |
| 工具覆盖 | 8 大 AI IDE 一键集成 | 手动配置 | 单工具绑定 |
| 命令完整度 | 60+ 命令,16 大资源组 | 基础 CRUD | 有限工具集 |
| 动态表 | 完整 V3.1 生命周期(10+ 子命令) | 手写 DDL | --- |
| 一键安装 | `curl ... | sh或pip install` |
多步安装 |
| 测试保障 | 1100+ 单元测试 | --- | --- |
| 开源 | Apache 2.0,完全开源 | 闭源 | 部分开源 |
十、为什么选 Hologres + AI Plugins
| 能力 | Hologres AI Plugins | 传统 CLI / GUI |
|---|---|---|
| AI 可解析 | JSON-First,结构化错误码 | 自由文本,需正则解析 |
| 安全机制 | 五层护栏 + 自动脱敏 | 依赖人工判断 |
| 计算隔离 | 默认 Serverless,不冲击生产 | 共享实例资源,存在风险 |
| 内存安全 | Adaptive Execution,复杂 SQL 不 OOM | 固定策略,大查询可能崩溃 |
| 知识注入 | Agent Skills 自动加载 | 人工翻文档 |
| 工具链 | 8 大 AI 工具一键集成 | 手动配置 |
| 动态表 | 完整 V3.1 生命周期 | 手写 DDL |
| 参数调优 | 27 个参数分类管理 | 记忆力 + 文档 |
| 审计追踪 | 全量操作日志 | 无 |
十一、快速上手
Hologres CLI 体验方式如下:
方式一:一键安装脚本(推荐)
自动检测环境、安装 uv、配置 PATH、安装 CLI:
bash
curl -sSf https://raw.githubusercontent.com/aliyun/hologres-ai-plugins/master/hologres-cli/install.sh | sh安装完成后重新加载 shell:
bash
source ~/.bashrc # bash 用户
source ~/.zshrc # zsh 用户方式二:pip 安装
bash
pip install hologres-cli方式三:uv 安装
bash
uv tool install hologres-cli方式四:开发安装(从源码)
bash
git clone https://github.com/aliyun/hologres-ai-plugins.git
cd hologres-ai-plugins/hologres-cli
pip install -e ".[dev]"验证安装
bash
hologres --versionHologres agent Skills 体验方式如下:
方式一:通过 uvx 安装(推荐)
bash
# 无需预安装,直接运行
uvx hologres-agent-skills方式二:通过 pip 安装
bash
pip install hologres-agent-skills
hologres-agent-skills方式三:通过 源码安装
postgresql
cd hologres-ai-plugins/agent-skills
uv sync
uv run hologres-agent-skills安装器会引导你完成以下交互流程
-
选择工具 --- 选择要安装技能的 AI 编程工具
-
确认路径 --- 确认安装目录
-
选择技能 --- 勾选一个或多个技能
-
完成 --- 技能文件被拷贝到对应工具的技能目录
十二、写在最后
AI Agent 时代,数据仓库的价值不在于它存了多少数据,而在于 AI 能多快、多安全、多智能地使用这些数据。
Hologres AI Plugins 做的事情很简单:
让 Hologres 成为 AI Agent 最顺手的数据仓库。
当你的 Agent 需要查数据 ------ 它有安全的 CLI; 当你的 Agent 需要懂数据库 ------ 它有专业的 Skills; 当你的 Agent 需要调性能 ------ 它有完整的诊断链路。
从 pip install 到 Agent 自主排障,中间只有一个 hologres config 的距离。
这就是 Agent-Ready。
项目完全开源,欢迎 Star 和贡献: