导读 introduction
通过对Claude Code源码的分析,揭示了Rules、MCP、Skills三个概念的底层实现机制。Rules是项目级行为规范,通过messages被动注入;MCP是标准化工具协议,在system和tools中注册并调用外部服务;Skills是可复用提示词,通过tool_use触发后注入指令文本。三者的核心区别在于信息在API请求中的位置不同,而非功能本质...
01 背景
1.1 概念爆炸:学不完的新名词
如果你在用 Claude Code、Cursor 或其他 Coding Agent,你一定经历过这样的感受------
刚弄明白怎么写 Rules 让 Agent 听话,MCP 就火了,一堆人说"MCP 才是未来";MCP 的 Server 还没配明白,Skills 又冒出来了,号称"标准化工作流"。每隔几周就有新概念冒出来,配上各种似是而非的定义,让人焦虑:这些东西之间到底是什么关系?我是不是又落伍了?
1.2 越看越糊涂的"官方定义"
网络上流行的定义往往加剧了混乱:
- "Rules 是项目级的行为规范"
- "MCP 是标准化的工具协议"
- "Skills 是可复用的标准化工作流"
看完这些,你可能和我一样,产生了更多疑问:
-
Rules vs Skills :都说 Skills 的优势是"按需引入",但
.claude/rules/里的条件规则不也能按路径按需生效吗?它们的区别到底在哪? -
MCP vs 内置 Tools:MCP 工具和 Claude Code 自带的 Read、Edit、Bash 这些内置工具,对模型来说有什么不同?为什么需要一套新协议?
-
Skills 的"标准化流程":所谓流程化,是真的像代码一样有 if-else 和循环控制的?还是只是一段写得好的提示词?
1.3 从源码找答案
这些问题靠读文档和博客是答不清楚的,因为它们本质上是实现层面的问题。
恰好 Claude Code 的源码在 GitHub 上泄漏,本文基于 v2.1.88 泄漏源码,从 LLM API 调用层面,拆解 Rules、MCP、Skills 的底层实现。看完源码你会发现,这三个概念远没有网上说的那么玄乎,它们的区别,本质上就是信息在 API 请求中被塞到了不同的位置。
02 前置需要了解的
为了避免阅读本文的读者对一些 Agent 中的流程不够了解,先介绍一下相对重要的知识点。
2.1 Agent 与 LLM API 的交互协议
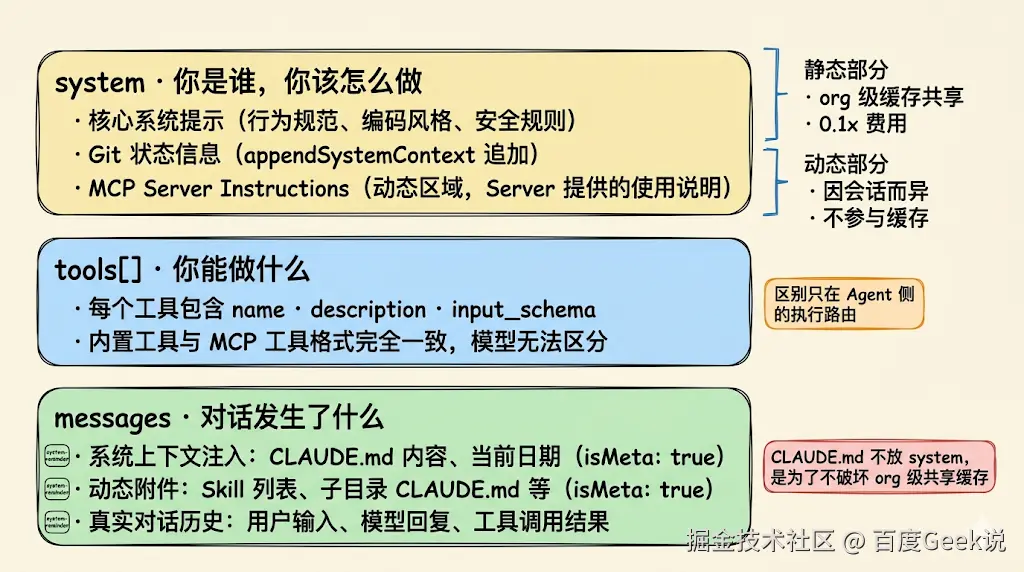
每次 Agent 调用 LLM,本质上就是发一个 HTTP 请求,请求体由三个核心参数组成:
perl
anthropic.messages.create({
system: TextBlockParam[], // 静态角色定义和行为规范
tools: BetaToolUnion[], // 工具定义(name + description + input_schema)
messages: MessageParam[], // 动态对话内容
})2.1.1 system --- "你是谁,你该怎么做"
定义模型的角色和行为规范。在 Claude Code 中,system 包含:
-
核心系统提示(行为规范、编码风格、安全规则等)
-
Git 状态信息(通过
appendSystemContext追加) -
MCP Server 级 instructions(若 Server 提供了使用说明,追加在动态区域中)
system 提示分为静态部分 (可跨用户缓存)和动态部分(因会话而异,不参与缓存共享)。MCP instructions 属于动态部分。
system 的静态部分高度稳定,可利用 Anthropic 的 org 级 Prompt Cache。 同一份静态内容只需计算一次 KV 矩阵,所有用户共享缓存,后续调用仅需 0.1x 费用。CLAUDE.md 等因项目而异的内容不放在 system 里,就是为了不破坏这份共享缓存。
2.1.2 tools --- "你能做什么"
tools 数组定义模型可以调用的工具。每个工具包含 name、description(来自工具的 prompt() 方法输出)、input_schema。模型根据工具描述决定何时调用哪个工具。
内置工具和 MCP 工具在这里的格式完全一致,模型无法区分它们------区别只在 Agent 侧的执行路由。
2.1.3 messages --- "对话发生了什么"
messages 是一个 user/assistant 交替的消息数组,但在 Claude Code 中,它远不只是"对话历史"。实际混合了三种内容:
-
系统上下文注入 (
prependUserContext):CLAUDE.md 内容、当前日期等 -
系统提示上下文 (
appendSystemContext):git 状态等(注入到 system 参数) -
动态附件 (Attachments):Skill 列表、计划模式指令、子目录 CLAUDE.md 等
-
真实对话历史:用户输入、模型回复、工具调用结果
前两类都以 isHidden: true + isMeta: true 注入,用 <system> 标签包裹。isHidden 是客户端侧的 UI 标记,消息仍完整发送给 API,但不会在终端界面中展示给用户。<system> 不是 API 特殊字段,而是 Claude Code 与模型之间的约定格式,系统提示词中会告知模型"被此标签包裹的内容权重等同于系统指令",让模型能区分系统注入的指令和用户真正说的话。
为什么系统上下文不放在
system里?因为 CLAUDE.md 等内容因项目而异,混入 system 会破坏 org 级共享缓存。放在 messages 中,既不影响 system 缓存,又能在会话内轮次间复用。
2.2 tool_use:一切扩展机制的底层基础
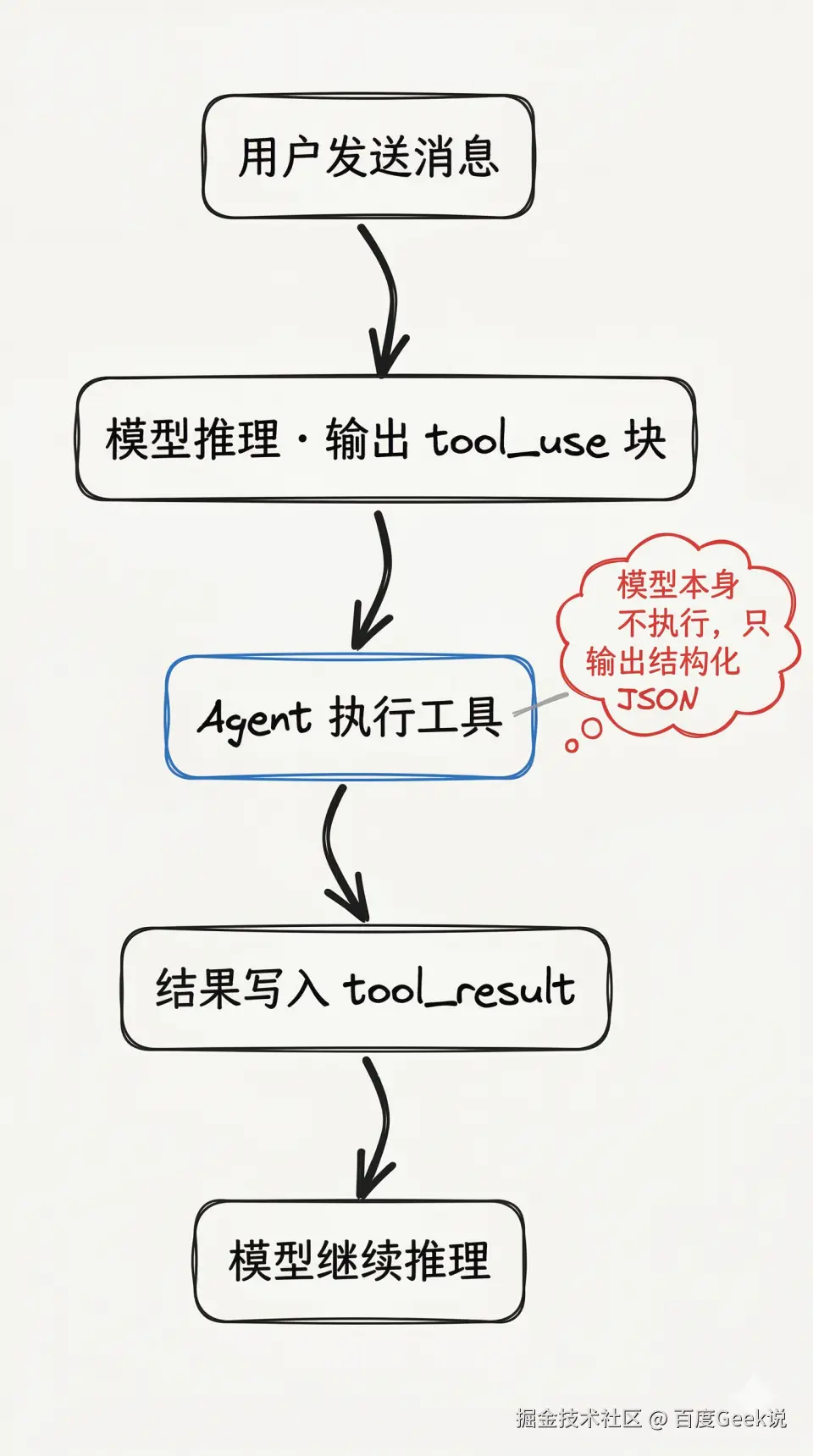
Claude 的工具调用本质上是一个结构化的多轮对话协议:
json
用户消息
↓
模型推理 → 输出 tool_use 块
{ "type": "tool_use", "id": "toolu_xxx", "name": "工具名", "input": { ...参数... } }
↓
调用方(Agent)执行工具
↓
将结果作为 tool_result 追加到对话
{ "type": "tool_result", "tool_use_id": "toolu_xxx", "content": "执行结果" }
↓
继续下一轮模型推理模型本身不"执行"任何工具 ,它只是输出一段结构化 JSON,真正的执行发生在调用方(即 Claude Code 客户端)。理解了这一点,就能理解为什么 Rules、MCP、Skills 虽然表现形式完全不同,但底层都构建在同一套 tool_use 协议之上。
03 实现细节
3.1 Rules(CLAUDE.md)的实现
3.1.1 Rules 是什么
Rules 就是 CLAUDE.md 文件 (以及 .claude/rules/*.md 规则文件)。它们是用自然语言写的指令文本,告诉模型"在这个项目中你应该遵循什么规范"。
3.1.2 文件发现机制
Claude Code 从多个位置按优先级加载 Rules(源码中对应 getMemoryFiles 函数)。实际加载逻辑是从项目根到 CWD 逐层处理 ,每层内部按 CLAUDE.md → .claude/CLAUDE.md → .claude/rules/*.md → CLAUDE.local.md 的顺序收集,后加载的覆盖先加载的。主要来源包括:
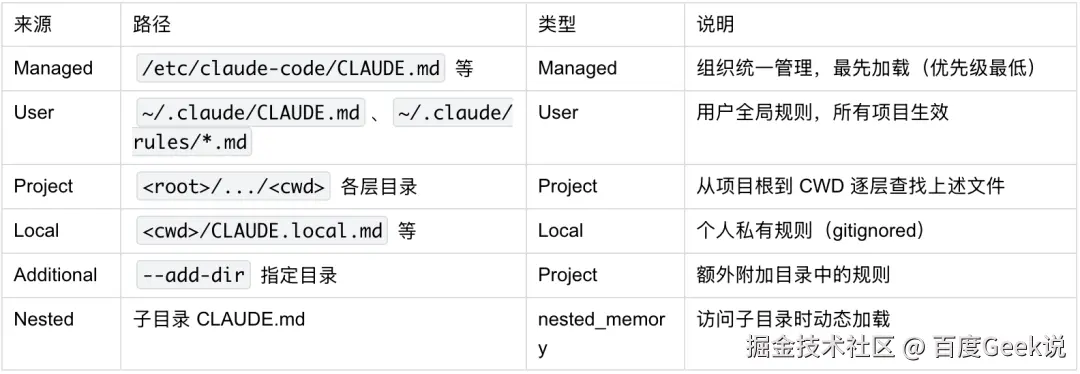
单个 CLAUDE.md 文件建议不超过 40,000 字符,超出会触发诊断警告⚠️。
3.1.3 内容处理流程
每个文件经过 processMemoryFile 处理:
css
读取文件
↓
解析 frontmatter(提取 paths 等条件匹配字段)
↓
移除 HTML 注释
↓
处理 @include 引用(最大递归深度 5 层)
↓
条件规则匹配(.claude/rules/*.md 中 paths 字段匹配当前文件路径)
↓
格式化输出条件规则是一个值得注意的特性。在 .claude/rules/ 下的规则文件可以通过 frontmatter 中的 paths 字段指定生效范围:
yaml
---
paths:
- "src/components/**/*.tsx"
- "src/hooks/**/*.ts"
---
在 React 组件中始终使用函数式组件和 hooks。这意味着这条规则只在模型处理匹配路径的文件时才会被注入。
3.1.4 注入方式:进入 messages,而非 system
格式化后的 Rules 内容通过 prependUserContext() 注入到 messages 的最前面 ,包裹在 <system-reminder> 标签中,以 role: "user" + isMeta: true 的形式存在------isMeta 是客户端 UI 标记,消息本身仍完整发送给 API,但不会在终端中展示给用户。
注入时还会带上一个强制指令头:
"Codebase and user instructions are shown below. Be sure to adhere to these instructions. IMPORTANT: These instructions OVERRIDE any default behavior and you MUST follow them exactly as written."
核心洞察:Rules 不走 ****tool_use**** 协议。 它既不是工具,也不需要模型主动调用。它是被动注入到每次 API 调用的上下文中,模型在推理时自然会"看到"并遵循这些规则。
具体的
prependUserContext()源码还原见 \[Claude Code 架构解析:从 Skill 调用到 Prompt Cache]
3.1.5 子目录 Rules 的动态加载
当模型在对话过程中访问了某个子目录的文件,Claude Code 会检查该子目录是否有 CLAUDE.md。如果有,会通过 nested_memory attachment 动态注入:
javascript
// nested_memory attachment 处理
case "nested_memory":
return [createMessage({
content: `Contents of ${attachment.content.path}:\n\n${attachment.content.content}`,
isMeta: true
})];这实现了 Rules 的按需加载------只有当模型实际接触到某个子目录时,该目录的规则才会被加载进来。
3.2 MCP Tools 的实现
3.2.1 MCP 是什么
MCP(Model Context Protocol)是一个标准化协议,让 Claude Code 能调用外部服务提供的工具。它是 tool_use 最直接的应用------模型触发后,客户端向外部 MCP Server 进程发起 RPC 调用,拿到真实结果。
3.2.2 配置与连接
MCP 服务器定义在 ~/.claude.json(user scope)或项目根目录的 .mcp.json(project scope)中,常见传输方式:
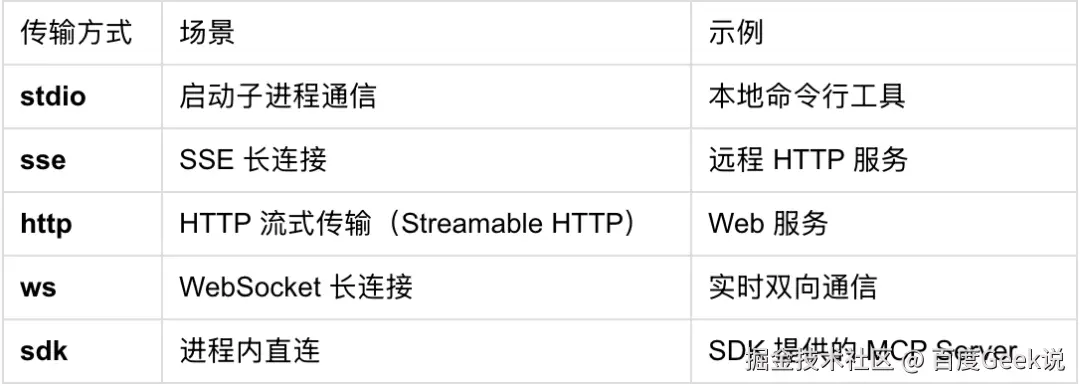
连接建立后,Claude Code 通过 MCP SDK 与 Server 完成 initialize 握手。这一步不仅获取工具列表,还会拿到 Server 返回的 instructions 字段------一个可选的 Server 级使用说明,后面会看到它的去向。
3.2.3 MCP 在 API 请求中占据两个位置
MCP 不只是注册在 ****tools[]**** 里,它还在 ****system**** 中有一席之地。
位置一:tools\[\] --- 工具定义
每个 MCP 工具通过 toolToAPISchema() 转换为 tools[] 格式,命名遵循 mcp__<serverName>__<toolName> 模式:
javascript
// toolToAPISchema 核心逻辑
async function toolToAPISchema(tool, options) {
return {
name: tool.name, // 如 "mcp__github__create_issue"
description: await tool.prompt(), // 工具描述 → tools[].description
input_schema: tool.inputJSONSchema // 参数 schema
};
}这部分和内置工具的注册方式完全一致,模型通过工具描述决定何时调用。
位置二:system --- Server 级 instructions
在系统提示词的构建过程中,getMcpInstructions() 会将所有已连接 Server 的 instructions 拼接进 system 的动态区域(位于缓存边界标记之后):
javascript
// getMcpInstructions(源码路径:src/constants/prompts.ts)
function getMcpInstructions(mcpClients) {
const clientsWithInstructions = mcpClients
.filter(c => c.type === "connected")
.filter(c => c.instructions); // 只取有 instructions 的 Server
if (clientsWithInstructions.length === 0) return null;
return `
# MCP Server Instructions
The following MCP servers have provided instructions for how to use their tools and resources:
${clientsWithInstructions.map(c => `## ${c.name}\n${c.instructions}`).join("\n\n")}
`;
}当 feature gate
isMcpInstructionsDeltaEnabled()开启时,MCP instructions 会改走 attachment 注入而非 system,以避免 Server 连接/断开破坏 prompt 缓存。
MCP Server 可以通过 initialize 响应的 instructions 字段,向模型传达整个 Server 级别的使用指南,比如"优先使用 search 工具而非 list 工具"、"所有日期参数必须用 ISO 格式"等。这些指导信息是全局性的,不是针对单个工具的。
tools[].description 描述的是"这个工具做什么、参数是什么",system 中的 instructions 描述的是"如何正确地使用这个 Server 的工具集"。一个是单工具说明书,一个是整体使用手册。
3.2.4 执行流程
MCP 工具的调用是真正的函数调用:
arduino
模型输出 tool_use: { name: "mcp__github__create_issue", input: {...} }
↓
Claude Code 识别 mcp__ 前缀,路由到对应 MCP Client
↓
MCP Client 发送 JSON-RPC 请求到 MCP Server 进程
↓
MCP Server 执行实际操作(如调用 GitHub API)
↓
返回真实结果
↓
tool_result.content = MCP Server 的真实输出
↓
模型读取结果,继续推理MCP 是名副其实的"远程过程调用"。 工具做真实的事情,结果回传给模型。tool_result 里装的是外部世界的真实数据。
3.2.5 MCP 祛魅:很多场景下一条 Bash 就够了
理解了源码实现后,一个自然的问题浮出水面:模型已经有 Bash 工具了,为什么还需要 MCP?
对模型来说,调 mcp__github__list_issues 和执行 gh issue list 拿到的结果没有本质区别------都是 tool_result 里的一段文本。但 MCP 多了一个 Server 进程、一层 JSON-RPC 通信、一套配置和维护成本。实际使用中,查 GitHub 用 gh,读数据库用 psql,调 API 用 curl,大量 MCP Server 做的事一条命令就能替代。
那 MCP 真正不可替代的场景是什么?
-
持久化连接和状态管理:Bash 每次是新进程没有状态。数据库连接池、WebSocket 长连接、跨调用共享认证 session,MCP Server 作为常驻进程可以做到
-
复杂操作的原子封装:把 5 步 Bash 命令封装成一次 MCP 调用,减少模型拼长命令出错的概率
-
权限隔离和安全约束:Bash "什么都能干",MCP Server 可以限制模型只执行预定义操作
MCP 的价值不在于"能调用外部系统"(Bash 也能),而在于"以更安全、更可靠的方式调用外部系统"。
3.3 Skills 的实现
3.3.1 Skills 是什么
Skills 是可复用的 Markdown 提示词文件(SKILL.md),定义了一套结构化的工作指令。它同样通过 tool_use 触发,但执行逻辑与 MCP 截然不同。
3.3.2 文件发现
Skills 从以下位置扫描发现:

3.3.3 Skill 列表注入
模型怎么知道有哪些 Skill 可用?通过 skill_listing attachment 注入到 messages 中:
php
// skill_listing attachment 处理
case "skill_listing": {
return [createMessage({
content: `The following skills are available for use with the Skill tool:\n\n${attachment.content}`,
isMeta: true
})];
}Skill 列表有严格的 token 预算 :仅占上下文窗口的 1%(默认 8000 字符),每个 Skill 描述最多 250 字符。当 Skill 数量过多时,描述会被截断甚至移除。这是为了避免 Skill 列表挤占对话空间。
同时,Skill 工具的 description 中包含一条强制触发指令(BLOCKING REQUIREMENT):
"When a skill matches the user's request, this is a BLOCKING REQUIREMENT: invoke the relevant Skill tool BEFORE generating any other response about the task"
这条指令确保模型看到匹配的 Skill 时,必须先调用工具,不能直接回答。
3.3.4 执行流程:提示词注入,不是函数调用
当模型调用 Skill 工具时,默认走 Inline 模式:
css
模型输出 tool_use: { name: "Skill", input: { skill: "commit", args: "" } }
↓
Claude Code 读取本地 SKILL.md 提示词文本
↓
将提示词内容包装为 isMeta: true 的 user 消息,注入到对话历史中
↓
tool_result 仅返回一个标签:"Launching skill: commit"
↓
下一轮 API 调用时,对话历史中已包含完整的 Skill 指令
↓
模型读到指令后,按步骤调用工具(Read、Edit、Bash 等)执行任务3.3.5 Inline 模式 vs Fork 模式
Skills 有两种执行模式,Inline 是默认模式 ,Fork 需要 Skill 配置文件中显式设置 context: 'fork' 才会触发:
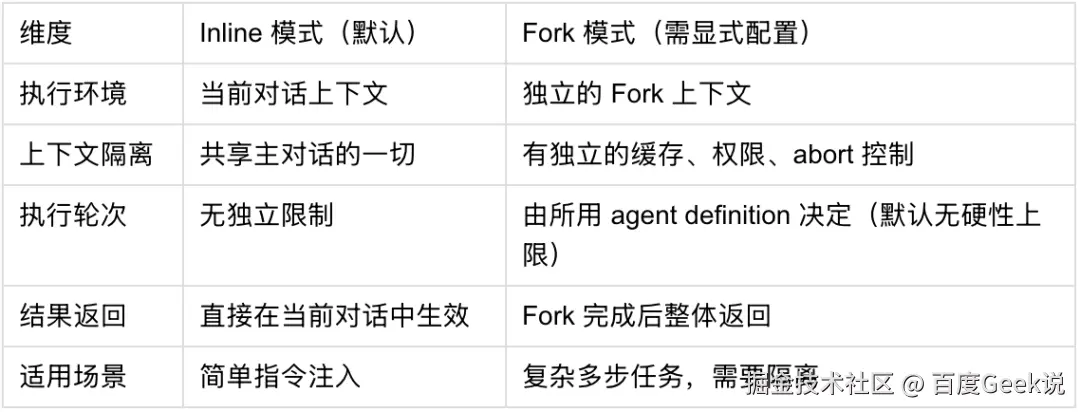
Fork 的隔离性意味着 Skill 内部的文件缓存、权限拒绝记录、abort 控制都是独立的,不会污染主对话上下文。
核心洞察:Skills 是"提示词注入"机制,不是函数调用。 tool_use 只是触发器,真正的"能力"来自被注入的 Markdown 指令文本。模型读到指令后,按指令一步步执行,利用已有的工具(Read、Edit、Bash 等)完成任务。
04 总结
4.1 三者的核心对比
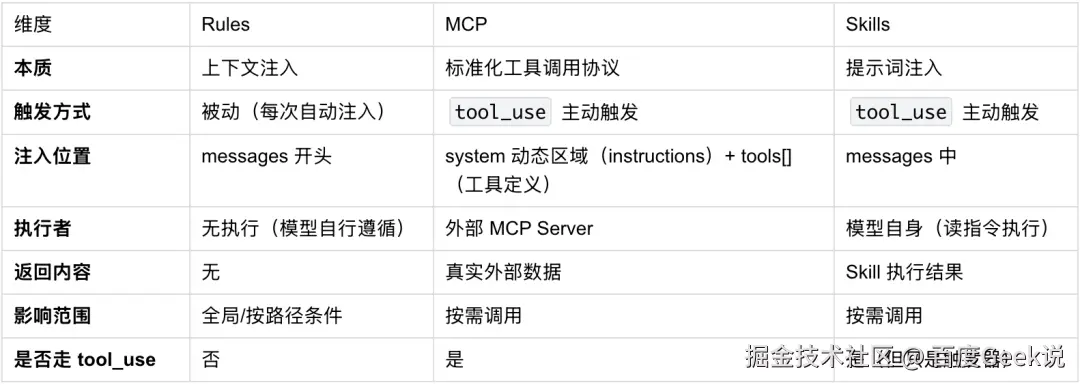
4.2 一张图理解全貌

4.3 回答开头的三个问题
Q1:Rules 和 Skills 都支持按需引入,区别在哪?
先说结论:区别没有想象中大。 从源码看,Skills 执行后注入的就是一段 Markdown 提示词,和你手动把一段 Rules 文本贴进对话框,对模型来说没有本质区别------都是 messages 里的一段 role: "user" 文本。
真正的区别只有两点工程实现上的差异:
-
触发方式 :Rules 每次 API 调用自动注入,Skills 需要模型判断后主动调用
tool_use(或用户手动/skill-name触发) -
执行隔离:Skills 可配置在 Fork 上下文中运行,拥有独立的缓存、权限跟踪和 abort 控制;Rules 没有这层隔离
但现实中,第一点反而成了 Skills 的痛点。模型判断"是否需要调用 Skill"依赖的是 skill_listing 中最多 250 字符的描述加上 whenToUse 字段------这点信息经常不够模型做出正确判断 。这就是为什么很多人发现 LLM 不会自动触发 Skill,最终还是靠手动 /commit、/review-pr 来调用。
想想这意味着什么:如果你每次都是手动触发,那 Skills 的完整调用链路是这样的:
bash
你输入 /commit
→ Claude Code 查找对应 SKILL.md
→ 包装为 tool_use 调用
→ 读取 Markdown 文本
→ 注入到 messages 中
→ 模型读到这段文本,按指令执行而你手动用 @commit-rules.md 引用一个同等内容的 Rules 文件,效果是:
css
你输入 @commit-rules.md + "帮我提交代码"
→ Claude Code 读取文件内容
→ 作为 FileAttachment 注入到 messages 中
→ 模型读到这段文本,按规范执行两者最终模型看到的都是一段自然语言指令,没有本质区别。 Skills 多绕的那几步(tool_use → 读文件 → 注入),本质上只是提供了额外的工程便利。如果你每次都是手动 /commit,那和直接 @commit-rules.md 效果几乎一样。
那 Skills 真正有价值的场景是什么?关键在于手动引用 Rules 替代不了的三个点:
1. 模型自主触发------用户只需表达意图
当 Skill 的 description/whenToUse 写得足够精准,模型能自动识别场景并触发,用户不需要知道这个 Skill 的存在。差距在单步场景不明显,但在多步骤组合任务时就凸显了:
sql
用户:"帮我完成这个 feature,包括写代码、写测试、提交"
手动引用方式:
@coding-rules.md @test-rules.md @commit-rules.md
→ 用户需要知道有哪些规则、叫什么名字、在哪里
Skill 自动触发:
→ 模型识别任务,依次自动调用 coding / test / commit skill
→ 用户只说了目标,工具选择完全交给模型Skills 还支持嵌套调用(Skill 内部再触发其他 Skill),可以用一个"主 Skill"编排多个子 Skill,形成完整的多步工作流入口。
注意:自动触发能力的上限取决于 Skill 描述的质量,而不是 Skill 数量。描述模糊或触发时机不清晰的 Skill,模型大概率不会自动识别,最终还是要靠手动 /skill-name 触发------此时就和手动引用 Rules 没有区别了。
2. 可发现、可分发------团队协作的标准化入口
Skill 有名字、注册在系统里,可以通过 /skills 浏览,可以打包进插件发布给团队。Rules 文件路径是私人知识,Skill 是"被组织管理的知识"。当你需要把一套工作流标准化并推广给不了解内部实现的团队成员时,Skill 是更合适的载体------用户只需记住 /commit,不需要知道背后引用了哪些规则文件。
3. Fork 模式的独立执行生命周期------这是手动引用 Rules 做不到的
配置 context: 'fork' 后,Skill 在独立 Agent 上下文中运行:执行过程中所有的 tool_use/tool_result 不会写入主对话,主对话保持干净;有独立的 abort 控制和权限跟踪,不会影响主流程。长流程多步任务特别适合 Fork 模式。
Q2:MCP 和 LLM 内置 Tools 的区别在哪?
对模型来说没有区别。 tools[] 里格式一样,调用方式一样。区别纯粹在 Agent 侧的执行路由:内置 Tools 本地执行,MCP Tools 转发到外部 Server。
如上文 2.5 所述,大多数简单场景 Bash 就能替代 MCP。MCP 真正的价值在持久化连接、原子封装和权限隔离三个点上。另外 MCP 的 Server 级 instructions 注入到 system 中理论上能提供工具集使用指南,但现实中大多数 Server 作者根本没写这个可选字段。
Q3:Skills 的标准化流程是"代码层面的流程化"吗?
不是。 源码里没有任何代码逻辑来控制 Skill 的执行步骤。所谓"标准化工作流",就是一段写得比较结构化的 Markdown------"Step 1 做什么,Step 2 做什么"。模型读到后自行理解、自行执行,完全靠模型的指令遵循能力。
这意味着:
-
Skill 的质量 = 提示词的质量
-
Skill 的"流程保障"= 模型的指令遵循率
-
同一个 Skill,换一个弱一点的模型,流程可能就乱了
从这个角度看,写一个好的 Skill 和写一段好的 Rules,需要的能力是一样的------都是提示词工程。
4.4 实际使用建议
基于源码分析和实际使用经验,给出一些落地建议:
什么时候用 Rules:
-
项目级的编码规范、技术栈约定、代码风格要求
-
文本短(几百字以内),每次注入不心疼 token
-
需要"始终生效"的指令,不依赖模型判断是否需要
什么时候用 Skills:
-
指令文本较长(几百行级别),不适合每次注入
-
有明确的触发时机(用户主动
/commit、/review-pr) -
需要执行隔离(Fork 模式能让任务在独立上下文中运行,不污染主对话)
什么时候用 MCP:
-
需要持久化连接/状态管理的场景(数据库连接池、认证 session)
-
复杂多步操作需要原子封装,减少模型拼命令出错的概率
-
需要权限隔离,不想给模型一个万能的 Bash
-
如果只是简单的 CLI 操作(
gh、curl、psql),直接让模型用 Bash,别折腾 MCP
一个现实提醒: 不要迷信 Skills 的自动触发。源码中 Skill 列表的 token 预算只有上下文的 1%,每个描述最多 250 字符。如果你的 Skill 描述写得不够精准,或者用户意图不够明确,模型大概率不会自动触发。把核心 Skill 的快捷命令告诉团队成员,让他们手动调用,比指望模型自动识别靠谱得多。 MCP 同理------在引入之前先想想,Bash 能不能直接搞定。
参考源码:
claude-code-source-code
v2.1.88(泄漏源码)