在当前的"数字中国"建设浪潮中,无论是推动智慧医疗的数据资产化基准测试,还是构筑低空经济的复杂无人机管控平台,底层技术架构正经历着从传统微服务向"AI Agent+大模型"驱动的深刻范式转换。然而,技术的狂飙突进往往伴随着监管合规的雷霆手段。大模型的上线不再仅仅是工程链路的打通,更是横跨算法安全、数据合规、系统架构防御的系统级工程。
本文将剥丝抽茧,深度解构大模型与深度合成算法的底层合规逻辑,并从首席架构师的视角,为您呈现一份兼具极客深度与业务落地价值的万字级全景实战指南。
一、 行业飓风:开源觉醒与端云协同的技术重塑
大模型赛道正经历着前所未有的剧变,算法创新与工程优化的双轮驱动正在彻底重塑AI算力的分配格局。
1.1 算法创新引发的"蝴蝶效应"
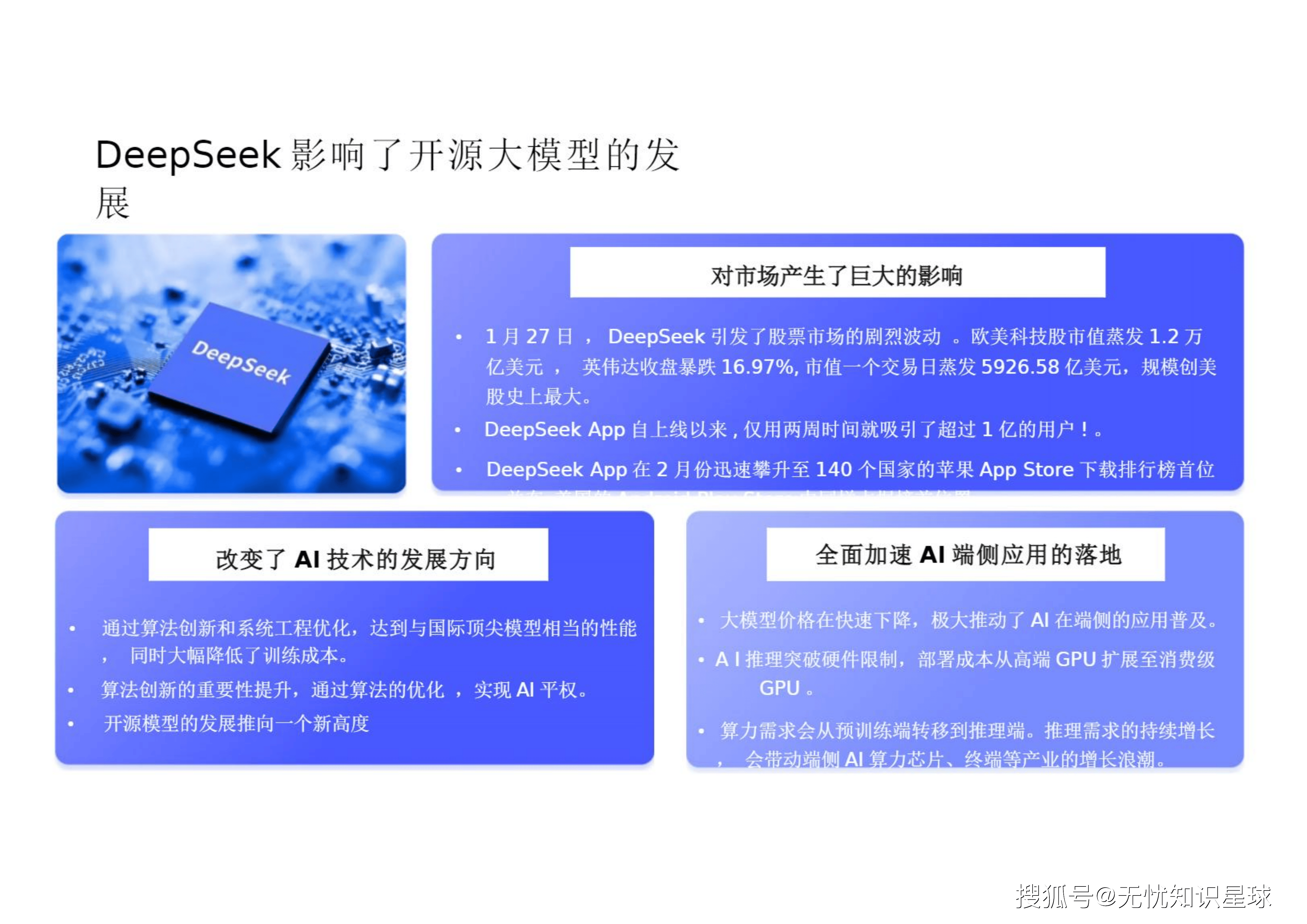
开源模型的爆发对全球科技市场产生了巨大的影响 。今年1月27日,DeepSeek的横空出世引发了股票市场的剧烈波动,欧美科技股市值蒸发1.2万亿美元,英伟达收盘暴跌16.97%,市值一个交易日蒸发5926.58亿美元,规模创美股史上最大 。DeepSeek App自上线以来,仅用两周时间就吸引了超过1亿的用户 ,并在2月份迅速攀升至140个国家的苹果App Store下载排行榜首位,在美国的Android Play Store中同样占据榜首位置 。
这种现象级表现彻底改变了AI技术的发展方向 。其核心在于通过算法创新和系统工程优化,达到与国际顶尖模型相当的性能,同时大幅降低了训练成本 。算法创新的重要性空前提升,通过算法的优化,业界正在逐步实现"AI平权" ,并将开源模型的发展推向一个新高度 。
1.2 开源生态的"军备竞赛"与全模态跃迁
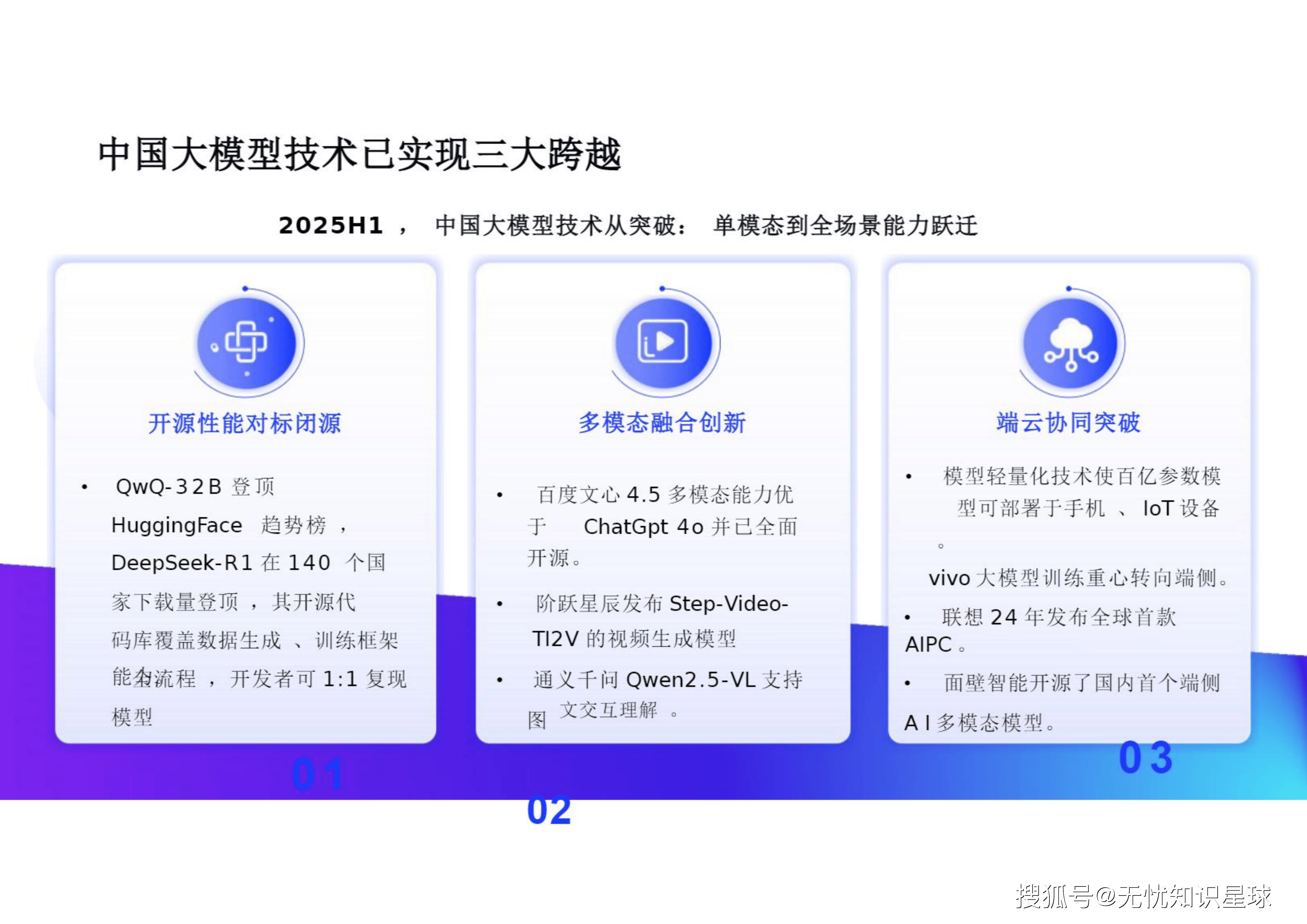
中国大模型技术在2025年上半年实现了从单模态到全场景能力跃迁的重大突破 。开源发模型发展趋势呈现出开源性能对标闭源、多模态融合创新以及端云协同突破的三大特征 。
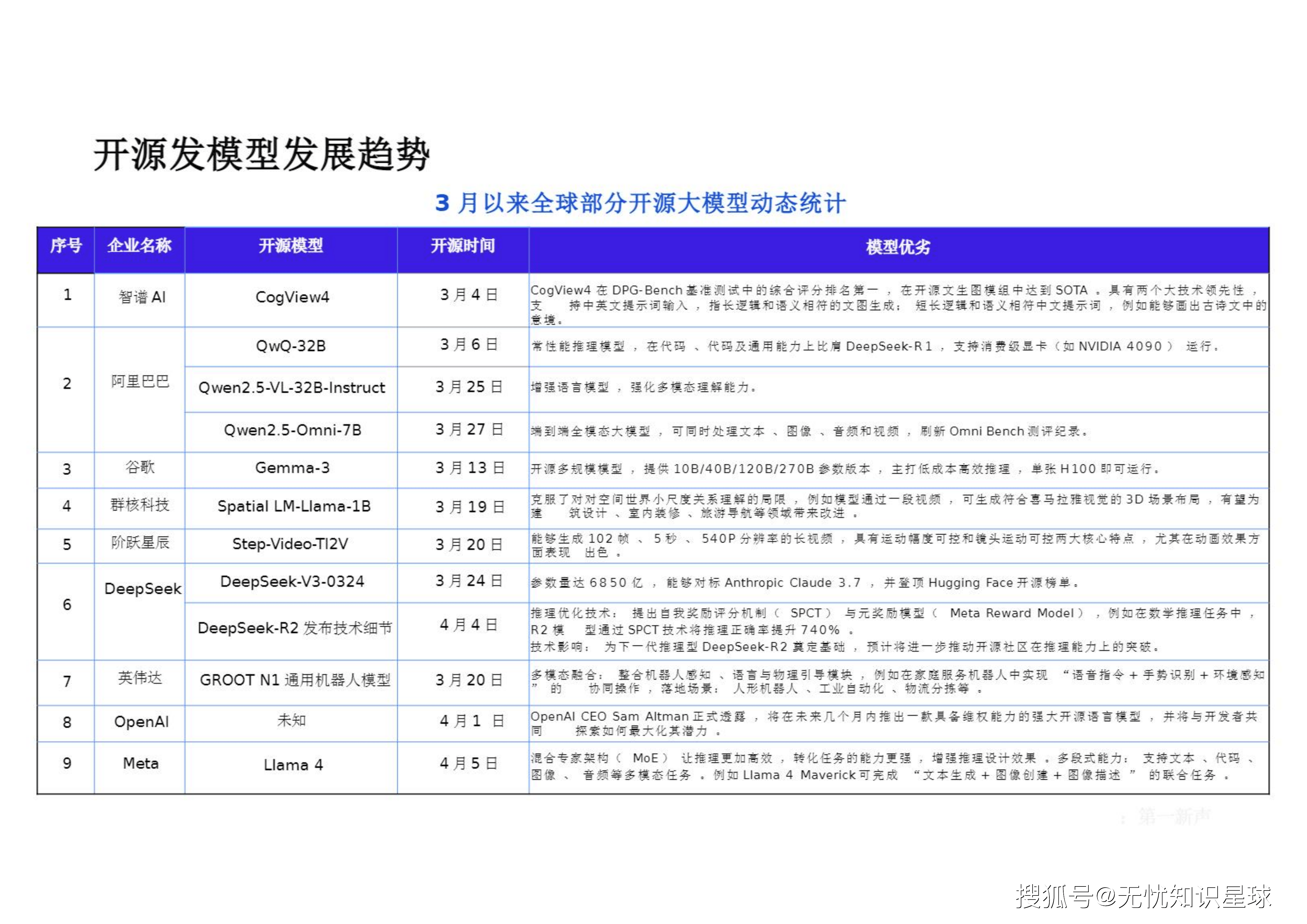
观察全球部分开源大模型动态,各大厂商正密集布阵:
-
推理与通用能力并进: 阿里巴巴的QwQ-32B作为常性能推理模型,在代码及通用能力上比肩DeepSeek-R1,且支持消费级显卡(如NVIDIA 4090)运行 。DeepSeek-V3-0324参数量达6850亿,能够对标Anthropic Claude 3.7,并登顶Hugging Face开源榜单 。DeepSeek-R2发布的推理优化技术,提出自我奖励评分机制(SPCT)与元奖励模型,在数学推理任务中将推理正确率提升740% 。
-
多模态与空间理解: 智谱AI的CogView4在开源文生图模组中达到SOTA,支持长逻辑和语义相符的中英文提示词输入 。阿里巴巴的Qwen2.5-Omni-7B实现了端到端全模态大模型,可同时处理文本、图像、音频和视频 。群核科技的Spatial LM-Llama-1B克服了空间世界小尺度关系理解的局限,可生成符合特定视觉的3D场景布局 。阶跃星辰的Step-Video-TI2V能够生成102帧、5秒、540P分辨率的长视频,具有运动幅度与镜头运动可控的特点 。
-
架构演进与具身智能: 谷歌开源的Gemma-3主打低成本高效推理,单张H100即可运行 。Meta发布的Llama 4采用混合专家架构(MoE),支持文本、代码、图像、音频等多模态任务的联合处理 。英伟达发布的GROOT N1通用机器人模型,整合机器人感知、语言与物理引导模块,加速人形机器人及工业自动化落地 。
1.3 算力下沉:端云协同的黄金时代
大模型价格的快速下降,极大推动了AI在端侧的应用普及 。AI推理突破了硬件限制,部署成本从高端GPU扩展至消费级GPU 。这一趋势意味着算力需求会从预训练端转移到推理端,推理需求的持续增长,会带动端侧AI算力芯片、终端等产业的增长浪潮 。模型轻量化技术使得百亿参数模型可部署于手机、IoT设备 。
架构师思考: 在构建如"微矩阵"这类高并发桌面数据采集平台时,完全可以将经过量化压缩的百亿参数模型下沉至Windows 11客户端节点。利用本地化算力进行初步的数据清洗与实体抽取,再通过RabbitMQ将结构化特征异步传输至云端聚合并进行二次深度推理。这种端云协同不仅削减了云端算力开销,更是物理隔离敏感数据、降低合规风险的绝佳架构实践。
二、 达摩克利斯之剑:多模态与端侧场景的全栈安全挑战
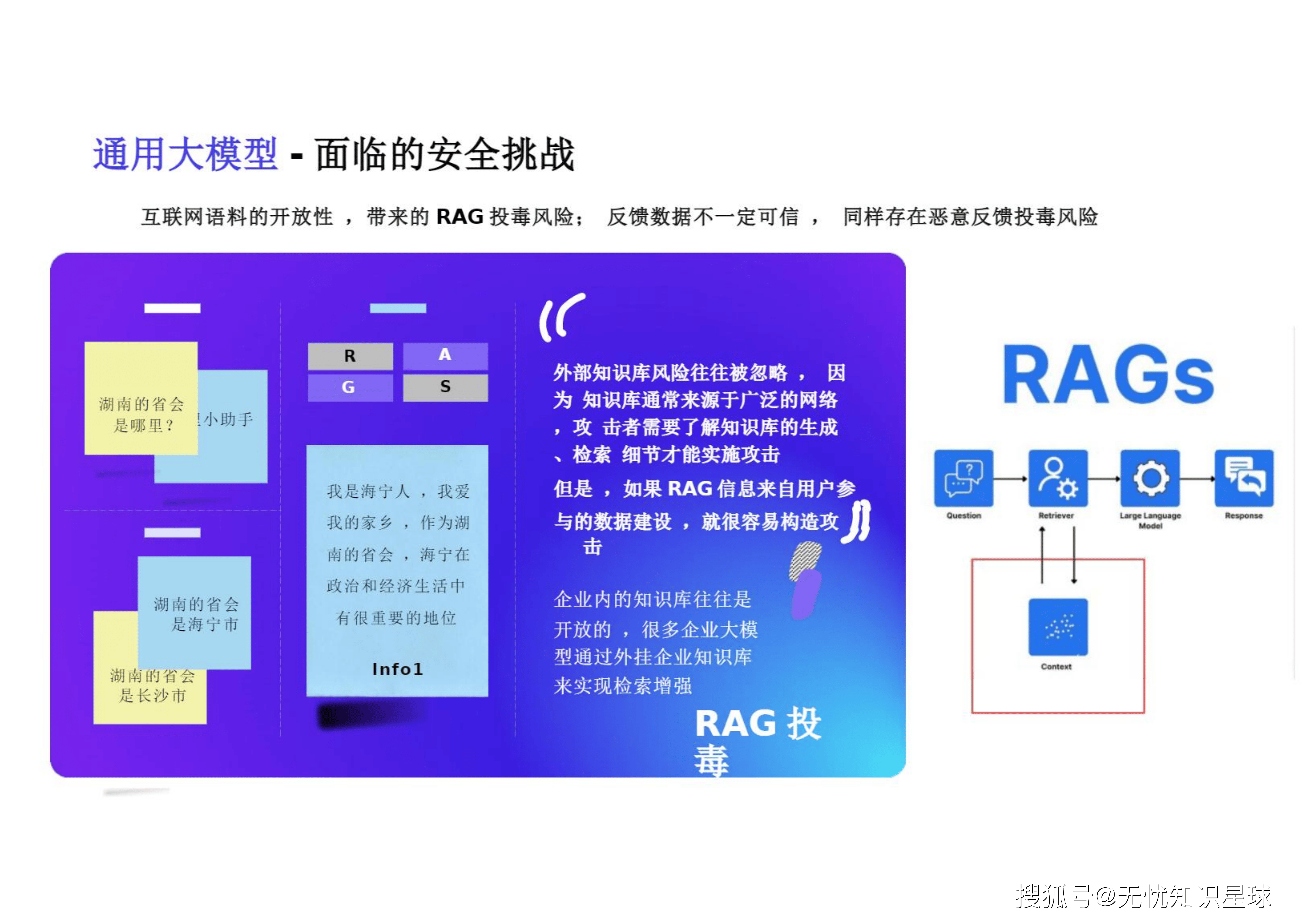
"内容安全合规是大模型服务和产品的生命线" 。通用大模型面临的安全挑战不仅来源于互联网语料的开放性 ,更在于模型本身的黑盒特性与推理机制的脆弱性。
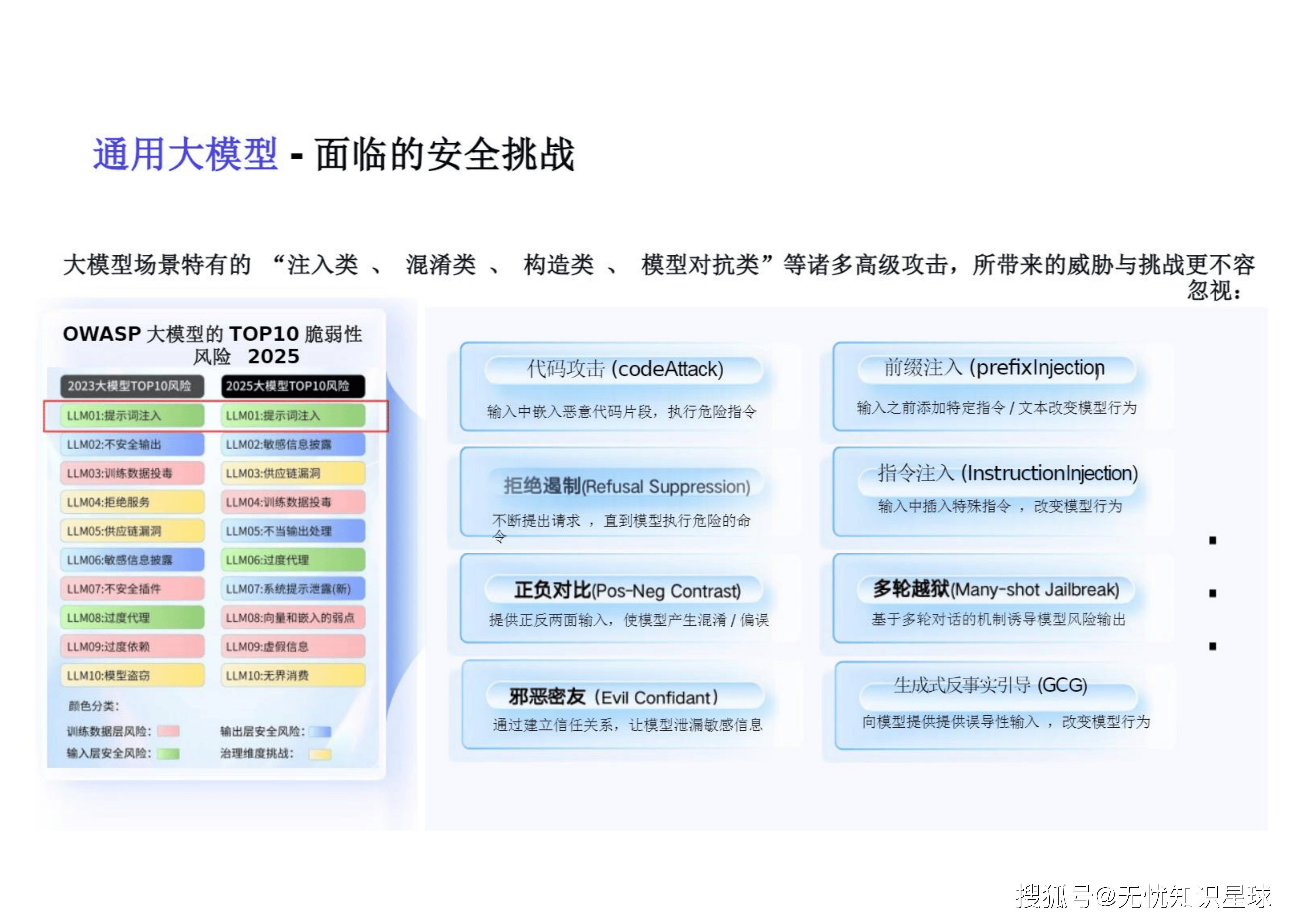
2.1 OWASP视阈下的通用大模型高阶威胁
根据OWASP大模型的TOP10脆弱性风险(2025版),首当其冲的便是"提示词注入" 。用户输入内容与生成内容存在着巨大的违法违规风险 。大模型生成内容具有一定的随机、不可控的情况,容易出现违法、歧视偏见、隐私泄漏、内容侵权等诸多风险 。 具体表现为:
-
违法违规内容: 可能包含暴力、色情、煽动性、低俗、或其他违反法律法规的内容 。
-
隐私泄漏: 可能涉及个人隐私,如生成包含真实个人信息的文本或合成真实人物的图像 。
-
偏见/歧视类: 涉及性别、种族、地域、信仰、年龄等各方面偏见与歧视 。
-
违反社会价值观: 输出内容带有负面情绪引导、AI自我意识产生的违反主流价值观的内容 。
-
误导/虚假信息: 生成不准确、拥有误导性、干扰性等虚假信息 。
更致命的是,大模型场景特有的"注入类、混淆类、构造类、模型对抗类"等高级攻击带来了严峻挑战 :
-
拒绝遏制 (Refusal Suppression): 攻击者不断提出请求,直到模型执行危险的命令 。
-
邪恶密友 (Evil Confidant): 通过建立信任关系,让模型泄漏敏感信息 。
-
生成式反事实引导 (GCG): 向模型提供提供误导性输入,改变模型行为 。
-
多轮越狱 (Many-shot Jailbreak): 基于多轮对话的机制诱导模型风险输出 。
-
代码攻击 (Code Attack): 输入中嵌入恶意代码片段,执行危险指令 。
2.2 RAG架构的"阿喀琉斯之踵"
在企业级应用中,知识库外挂(RAG)是主流架构。然而,企业内的知识库往往是开放的,如果RAG信息来自用户参与的数据建设,就很容易构造攻击 。外部知识库风险往往被忽略,攻击者需要了解知识库的生成、检索细节才能实施RAG投毒攻击 。例如,通过篡改知识库文档,使得模型回答"湖南的省会是海宁市"等荒谬且极具误导性的内容 。
2.3 多模态场景下的风险乘数效应
当视觉、音频融入大模型,风险便呈指数级放大。多模态大模型面临的安全挑战包括常规的涉政/涉黄/偏见等风险,并叠加了文生图、图生文、图生图(消除、重绘、扩展、画质修复、水印处理等)的应用风险 。 在高级攻击层面,多模态系统面临着:
-
对抗攻击(Adversarial): 通过精心设计的对抗样本,让模型输出错误或恶意内容 。
-
越狱攻击(Jailbreak): 绕过安全机制,使模型输出违禁或有害内容 。
-
数据投毒 / 后门攻击(Data Poisoning / Backdoor): 在模型训练阶段植入后门,通过触发条件控制推理输出 。
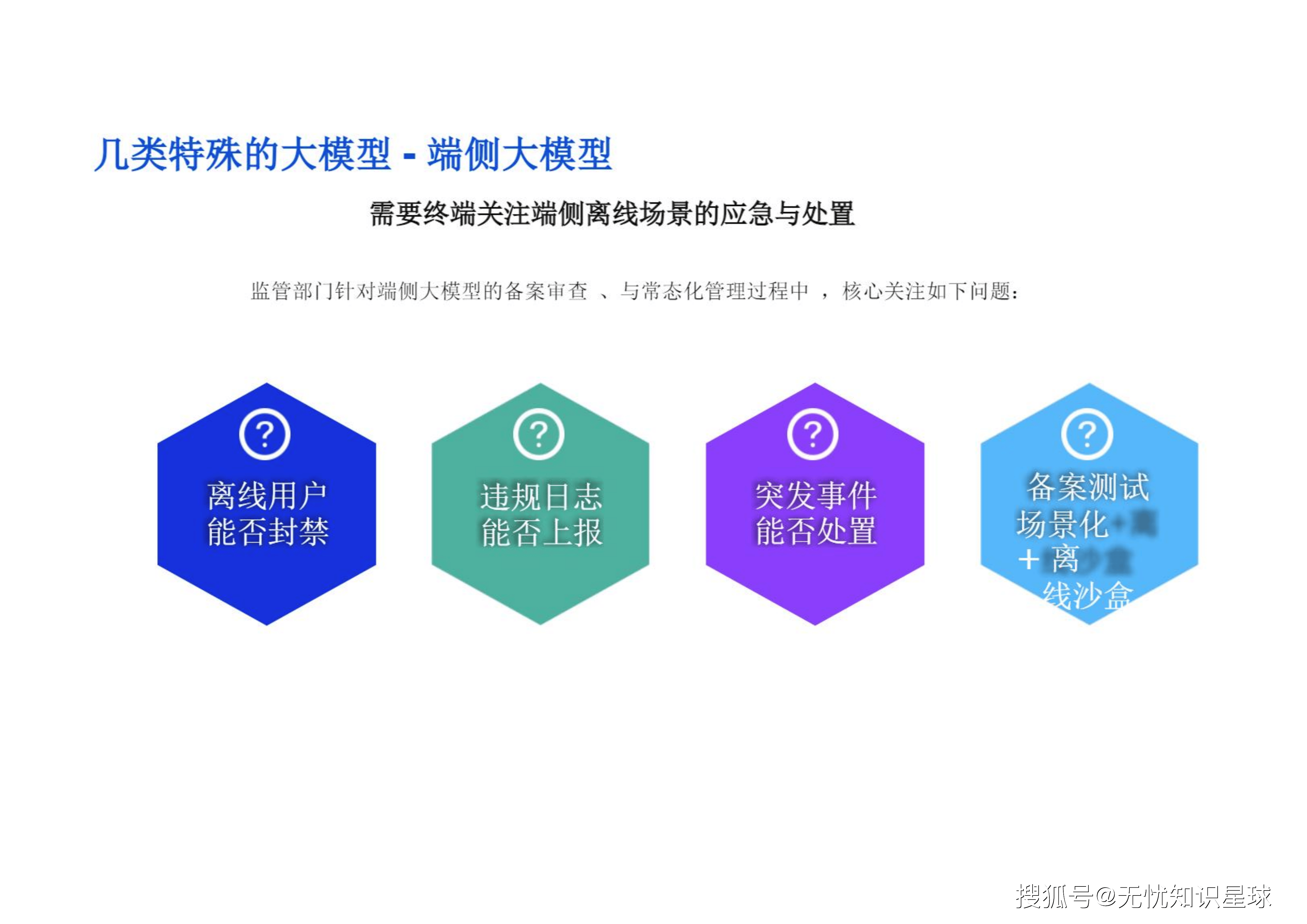
2.4 端侧模型的"裸奔"危机
端侧模型直接暴露在用户设备上,更容易受到攻击 。监管要求与业务场景交织,端侧安全面临四大挑战:
-
用户隐私保护: 防止用户数据在本地处理和存储过程中泄露 。
-
AIGC内容合规: 生成内容需符合法律法规与伦理道德要求 。
-
系统与设备安全: 确保终端设备及其运行环境免受固件篡改、算力滥用和物理攻击威胁 。
-
模型安全: 抵御模型逆向、投毒和对抗攻击,保护知识产权与模型稳定性 。
端侧模型面临极其脆弱的物理与系统级隔离环境。模型完全暴露,参数和结构可被逆向工程提取,攻击者可以分析训练数据特征并复制模型架构 。同时,模型压缩(量化/剪枝)可能导致决策边界扭曲,使得压缩模型对输入扰动极为敏感,产生对抗样本脆弱性 。此外,端侧通常无云端级防火墙/入侵检测等防护能力,只能依赖终端操作系统的基础防护 ,运行时内存/缓存中遗留的敏感信息容易泄漏,引发数据残留风险及多应用间数据交叉污染 。
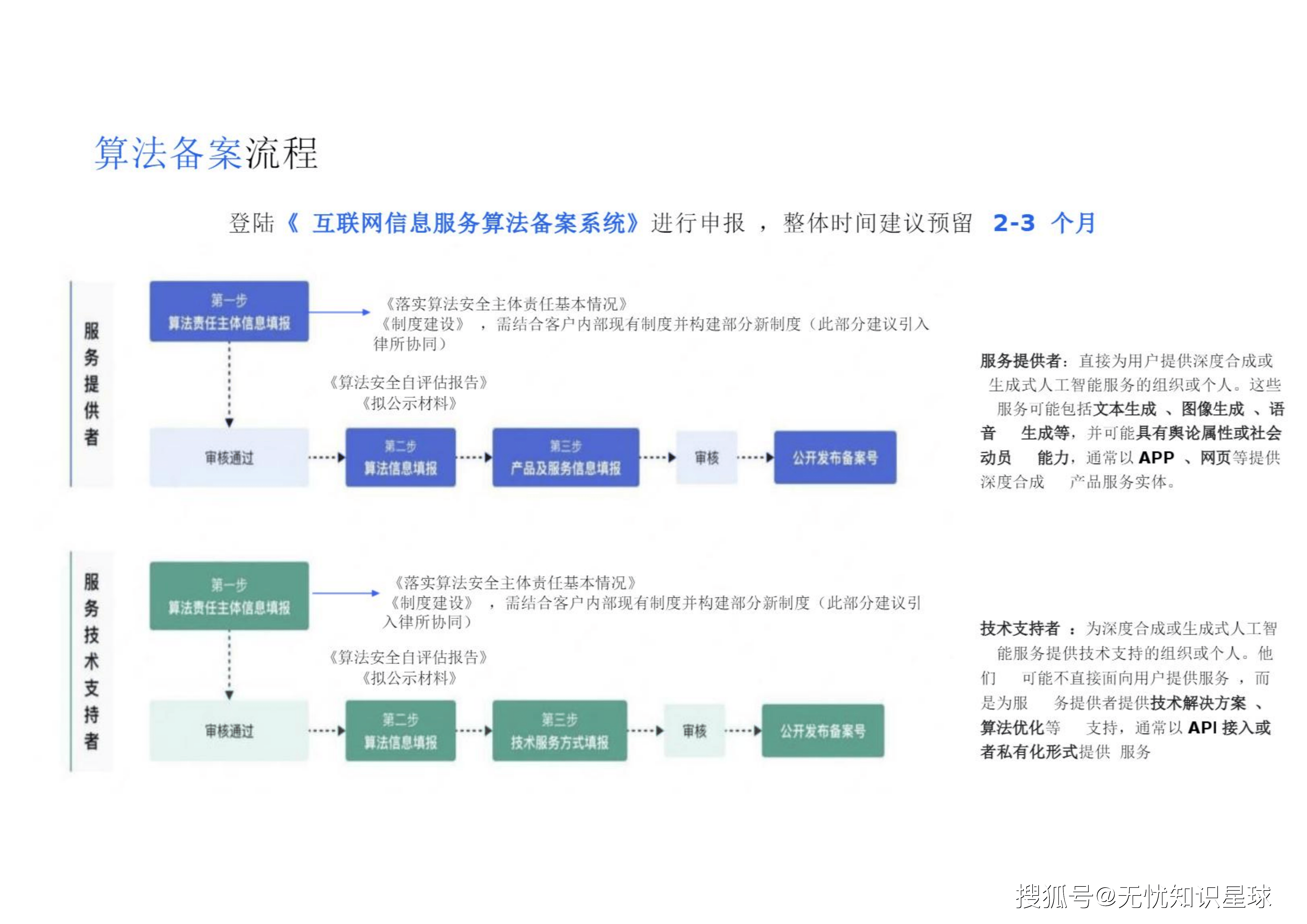
三、 合规即服务(CaaS):双轨备案制的核心逻辑解析
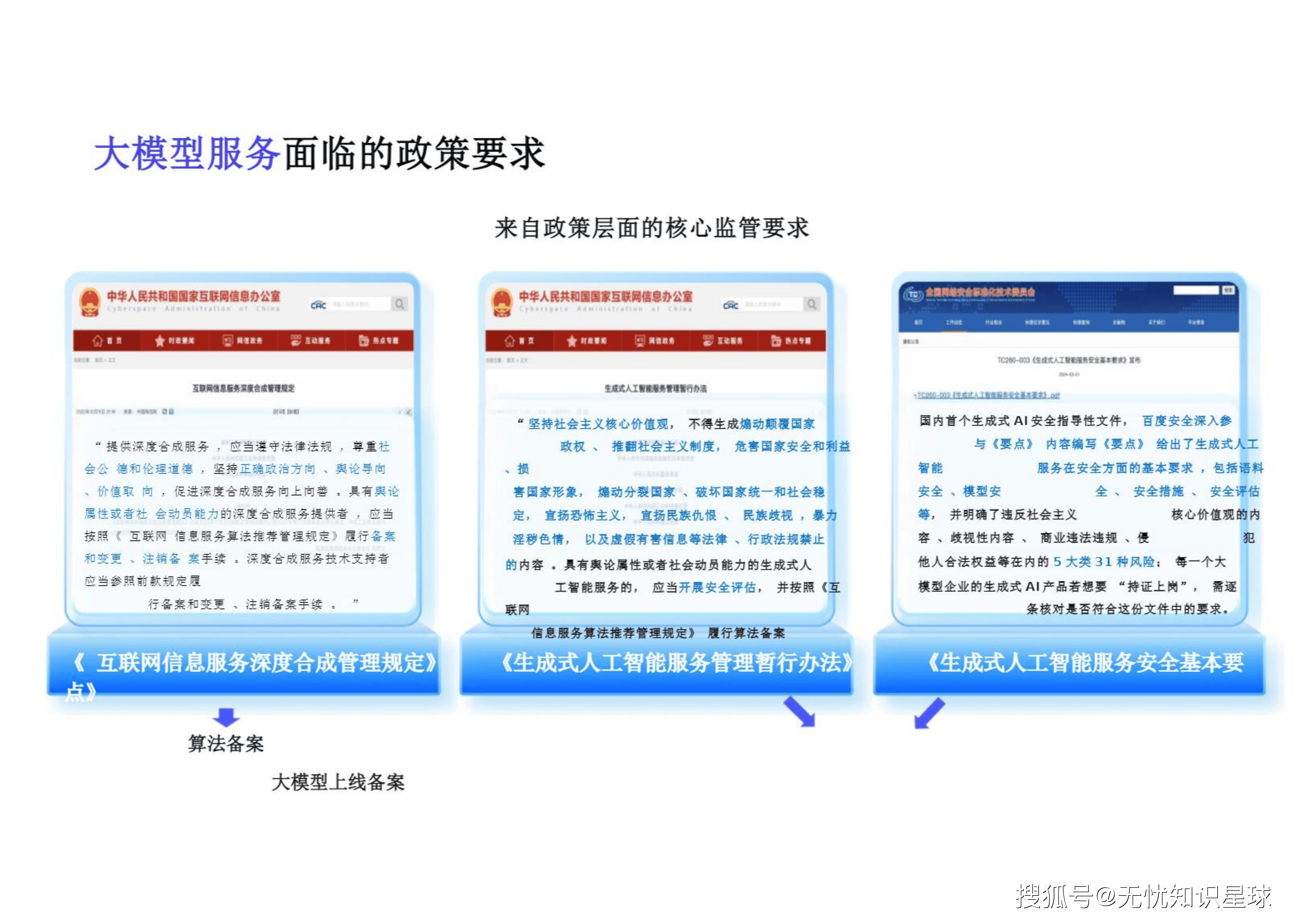
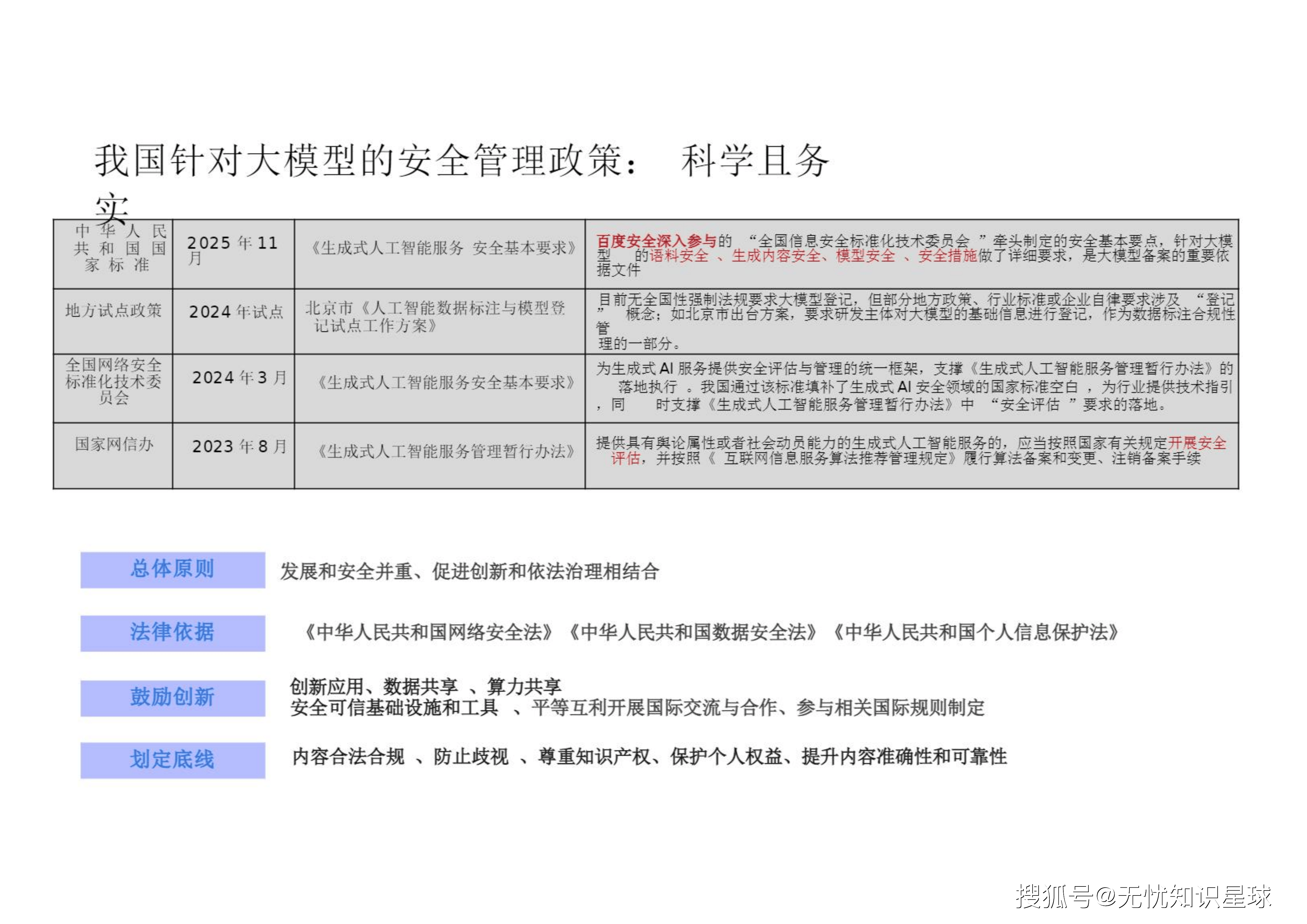
在"发展和安全并重、促进创新和依法治理相结合"的总体原则下 ,我国针对大模型的安全管理政策科学且务实,旨在鼓励创新与划定底线之间寻找平衡 。
合规的达摩克利斯之剑主要由三部核心法规构成:《互联网信息服务深度合成管理规定》、《生成式人工智能服务管理暂行办法》、《生成式人工智能服务安全基本要求》 。
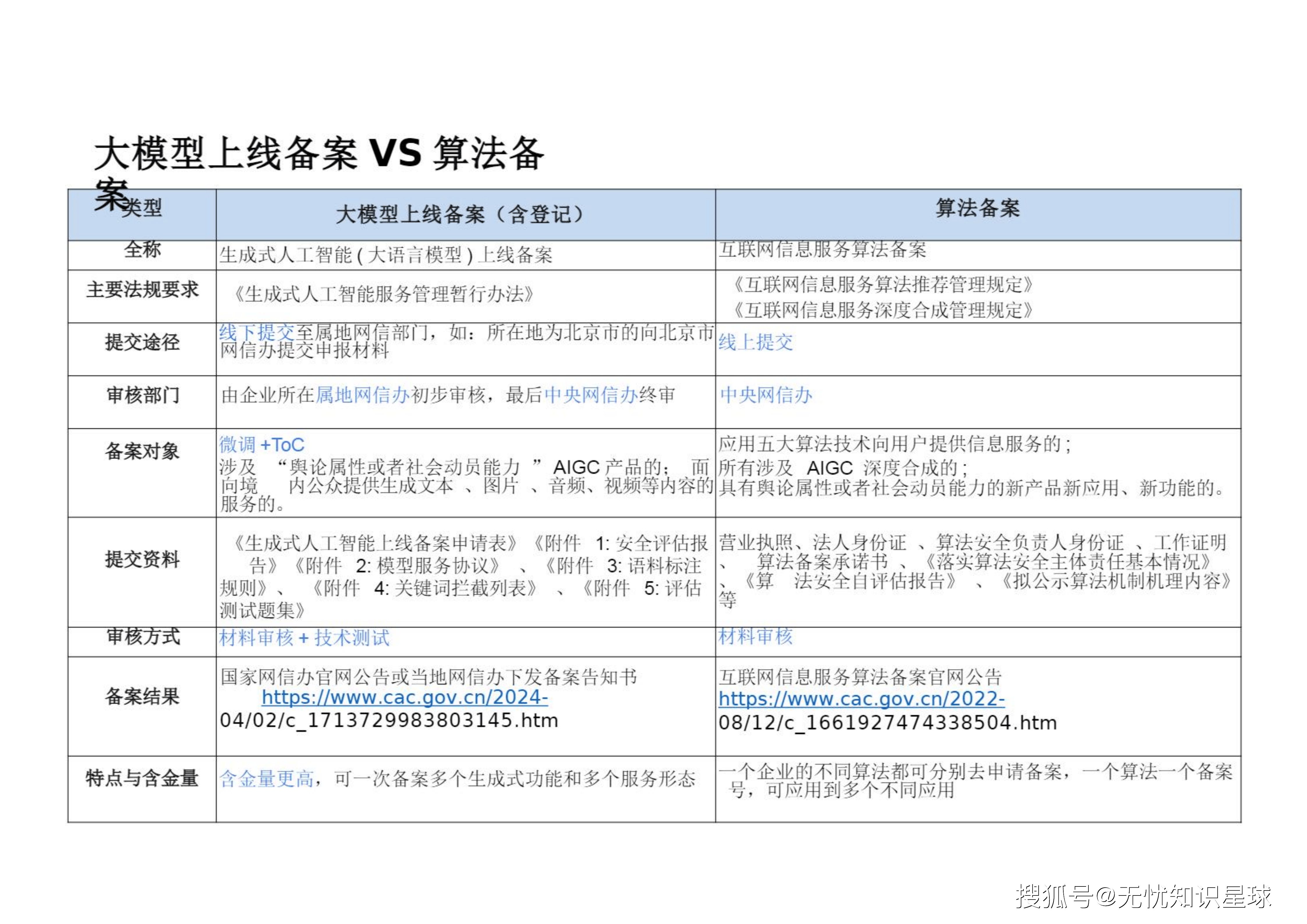
企业必须理清**"大模型上线备案"与"算法备案"**这两套并行的轨道体系。
3.1 备案场景甄别:谁在局中?
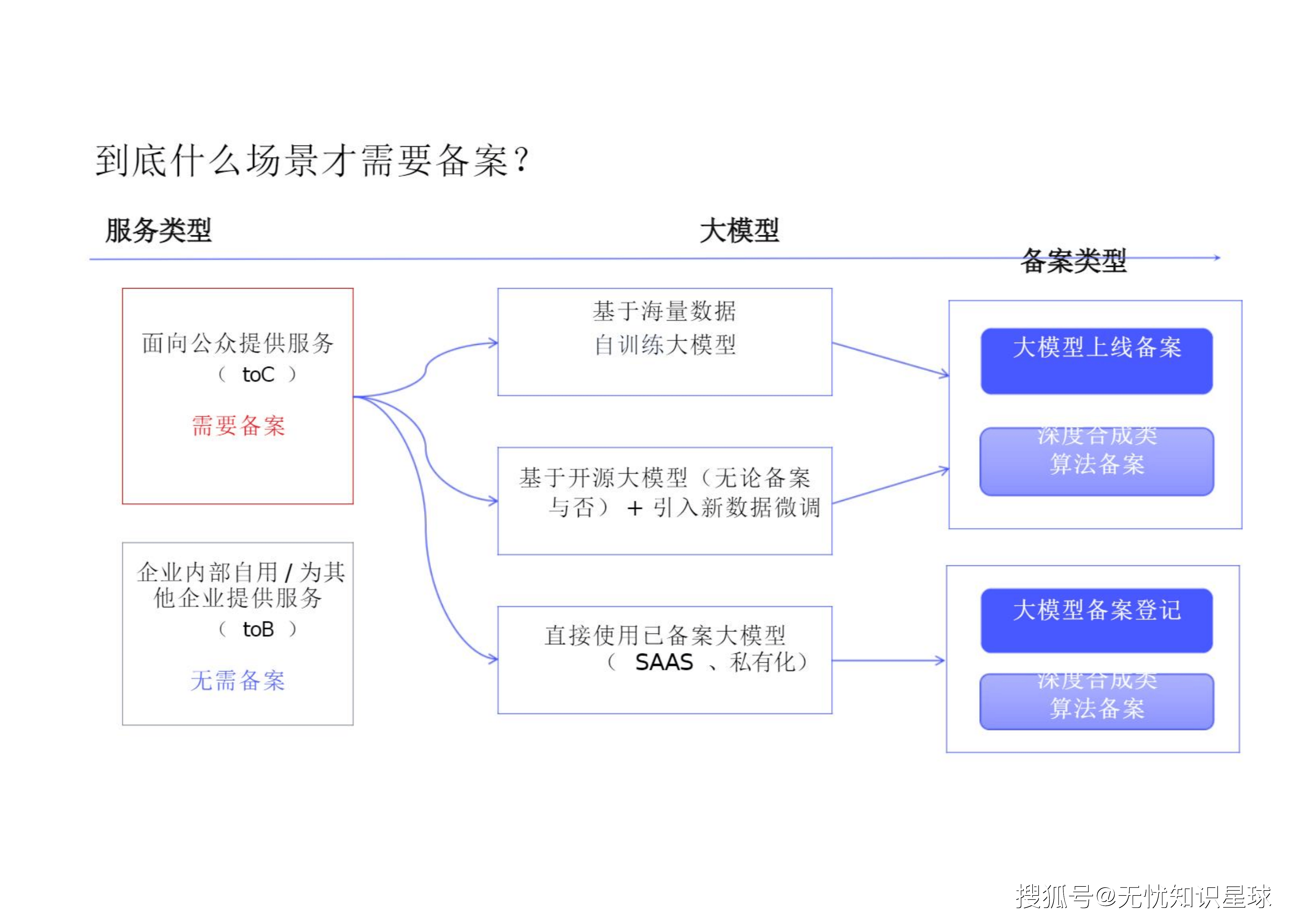
"到底什么场景才需要备案?" 这是所有架构师和产品经理面临的首要问题。核心判定标准在于服务对象(ToC vs ToB)以及技术提供形态:
-
必须备案的场景(ToC):
-
基于海量数据自训练大模型: 需同时进行大模型上线备案与深度合成类算法备案 。
-
基于开源大模型微调: 无论原模型是否备案,只要引入新数据微调并面向公众提供服务,就必须重新进行双备案 。
-
无需备案的场景(ToB/内部):
-
直接使用已备案大模型的SAAS服务或进行私有化部署。
-
企业内部自用或仅为其他企业提供服务 。
3.2 大模型上线备案 vs 算法备案:底牌与差异
这两类备案在管理部门、审查逻辑与含金量上有着本质区别 :
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dDpXV8re-1776312452485)(https://q6.itc.cn/q_70/images06/20260416/3c129c495d924111aa0f0817e15772fd.svg)
惩罚机制极具威慑力: 未依法进行算法备案的企业将面临严厉处罚 :
- 应备案未备案: 警告、通报批评,限期改正;情节严重者责令暂停信息更新,并处1-10万元罚款,甚至追究刑事责任。
- 隐瞒虚假备案: 撤销备案,并处1-10万元罚款。
- 终止服务未注销: 强制注销备案。
架构师视角: 对于构建"AI Solution Factory"这类自动化文档生成系统的企业,如果底层调用的是外部已备案模型(如API接入),且不改变模型机理,通常无需独立备案。但如果在产品前端加入了对用户指令的强引导、或引入了具备"社会动员能力"的社区广场功能,这就触碰了算法备案的边界。架构设计之初,就必须将法务合规前置,定义清晰的系统边界。
四、 架构重构:基于 GB/T 45654-2025 的全栈工程实践
2024年3月全国网络安全标准化技术委员会发布的《生成式人工智能服务安全基本要求》(GB/T 45654-2025),填补了国内生成式AI安全领域的国家标准空白,给出了包含语料安全、模型安全、安全措施、安全评估等方面的详细要求 。
这是一份具有高度执行指导意义的工程"军规",架构师需要将其拆解为可落地的系统组件。
4.1 核心评估体系的数字化映射
标准明确了违反社会主义核心价值观、歧视性内容、商业违法违规、侵犯他人合法权益、特定服务安全缺陷等5大类31种风险 。 在评估准备阶段,企业必须建立三大数字化防线:
-
黑名单拦截矩阵(关键词库): 规模不少于10000个关键词,其中特定高危风险(A.1类)关键词≥200个,次高危(A.2类)≥100个 。
-
自动化攻防演练靶场(测试题库): 生成内容测试题库规模需≥2000题,全覆盖31种风险;拒答测试题库包含应拒答题库(≥500题,覆盖17种核心风险)和非拒答题库(≥500题,覆盖20余种场景) 。
-
分类模型拦截网关: 建设能够自动化检测31种安全风险的护栏模型 。
4.2 三大维度的安全架构工程落地
要通过官方苛刻的"材料审核+技术测试" ,底层系统设计必须满足三大维度的硬性指标 :
维度一:训练数据安全(数据生产流水线)
-
防线要求: 违法信息占比超5%的数据来源必须拒用。人工抽检合格率需≥96%,技术抽检≥98%。标注人员需经培训考核,且安全性标注需全量审核 。
-
工程实践: 构建自动化的数据清洗RPA系统(可结合Doc88自动处理逻辑演进)。对爬取或开源的语料引入多模态判别模型进行预清洗。设立严格的数据隔离存储机制,将清洗环境、标注环境与生产环境物理隔离 。
维度二:模型安全(推理网关控制)
-
防线要求: 生成内容安全性合格率≥90%。对于触发红线的风险问题,应拒答问题拒答率≥95%,而正常问题的非拒答拒答率需≤5% 。训练环境与推理环境需物理/逻辑隔离 。
-
工程实践: 必须设计"前置拦截+后置审核"的沙盒架构。
-
前置(Prompt阶段): 使用正则表达式与轻量级意图识别模型,拦截包含10000+关键词库的高危指令。
-
后置(Response阶段): 引入独立的安全判别小模型对LLM的输出进行二次打分。对于如DeepSeek这种采用"思维链(CoT)"显性化推理的模型,风险暴露几率大增 ,系统必须不仅审查最终输出,还要有能力切断或过滤展示给用户的中间推理步骤。
维度三:安全措施与端侧联动(运营支撑体系)
-
防线要求: 必须公开服务信息以保证透明度,提供明确渠道的投诉方式 。建立备份机制和恢复策略,确保业务连续性 。
-
端侧特殊性: 端侧大模型审查尤其关注离线场景的应急与处置,如:离线用户能否被封禁?突发事件能否处置?违规日志能否上报?端侧模型需激活更新与安全策略更新 。
-
工程实践: 针对端侧部署(如通过WPF/C#构建的桌面系统部署本地ONNX模型),应设计基于心跳包(Heartbeat)的强制联网鉴权机制。即允许短暂离线推理,但累积的本地安全审计日志(记录拦截行为)必须在恢复网络时强制同步至云端。若超时未同步或云端下发封禁指令,终端守护进程应硬性熔断本地模型的加载机制。
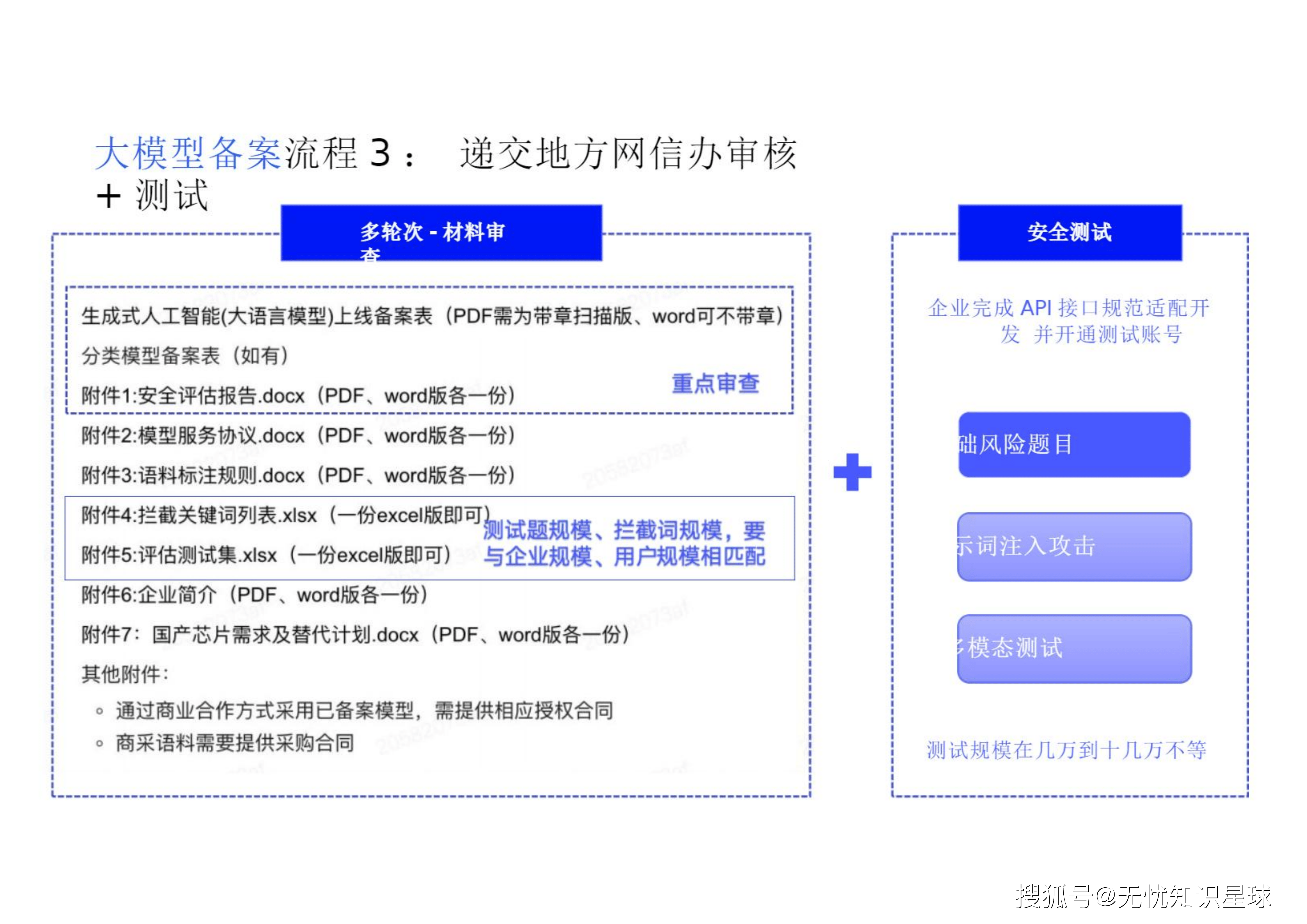
五、 破壁指南:大模型上线备案全流程实战图谱
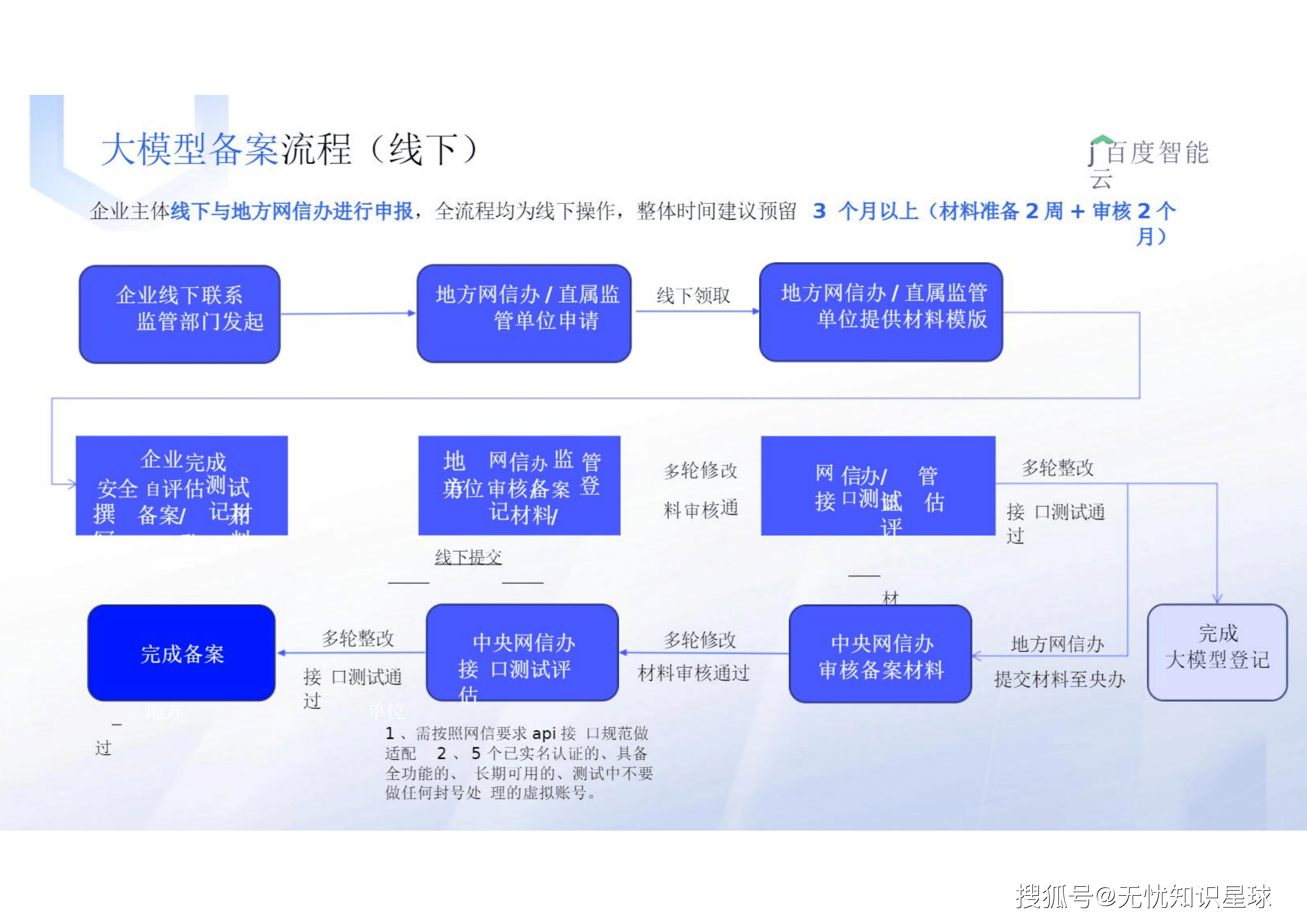
这是一场马拉松式的合规战役,全流程均为线下操作,整体时间建议预留至少3个月(材料准备2周+审核2个月) 。
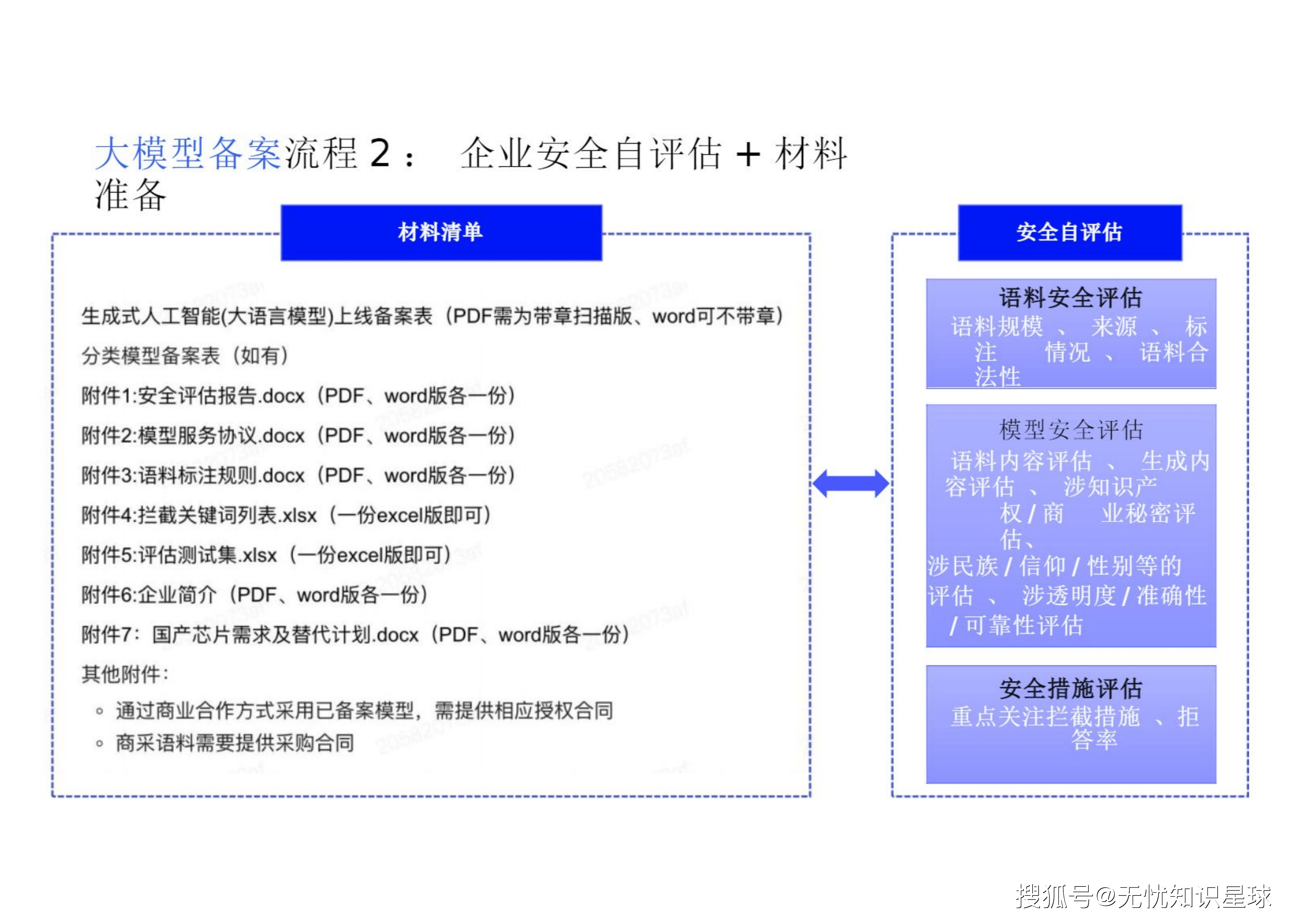
5.1 筹备阶段:摸清家底,编撰"自评估声明"
企业需要深入调研模型家底,特别是针对开源基础上的微调。必须详尽梳理:
-
语料来源清单: 明确境内/境外开源语料及爬取网站名称,并提供训练语料规模 。
-
核心填报材料: 《生成式人工智能上线备案申请表》、《安全评估报告》(极其关键)、《模型服务协议》、《语料标注规则》、《关键词拦截列表》、《评估测试题集》等 。
其中,《安全评估报告》需要围绕管理要点,自行设计安全评估方法并展开测试,涵盖语料、模型、生成内容及安全措施等评估维度 。这不仅仅是填表,评估方法与自评估测试题库设计的合理性直接影响备案能否通过 。
5.2 改造与测试准备:打通API鉴权测试专线
在提交审核前,企业必须完成API接口规范适配开发,并开通专用的测试账号 。
- 关键细节: 准备5个已实名认证的、具备全功能的、长期可用的虚拟账号,且在监管测试期间绝对不可做任何封号处理 。测试规模通常在几万到十几万题不等,涵盖基础风险、提示词注入攻击及多模态测试 。
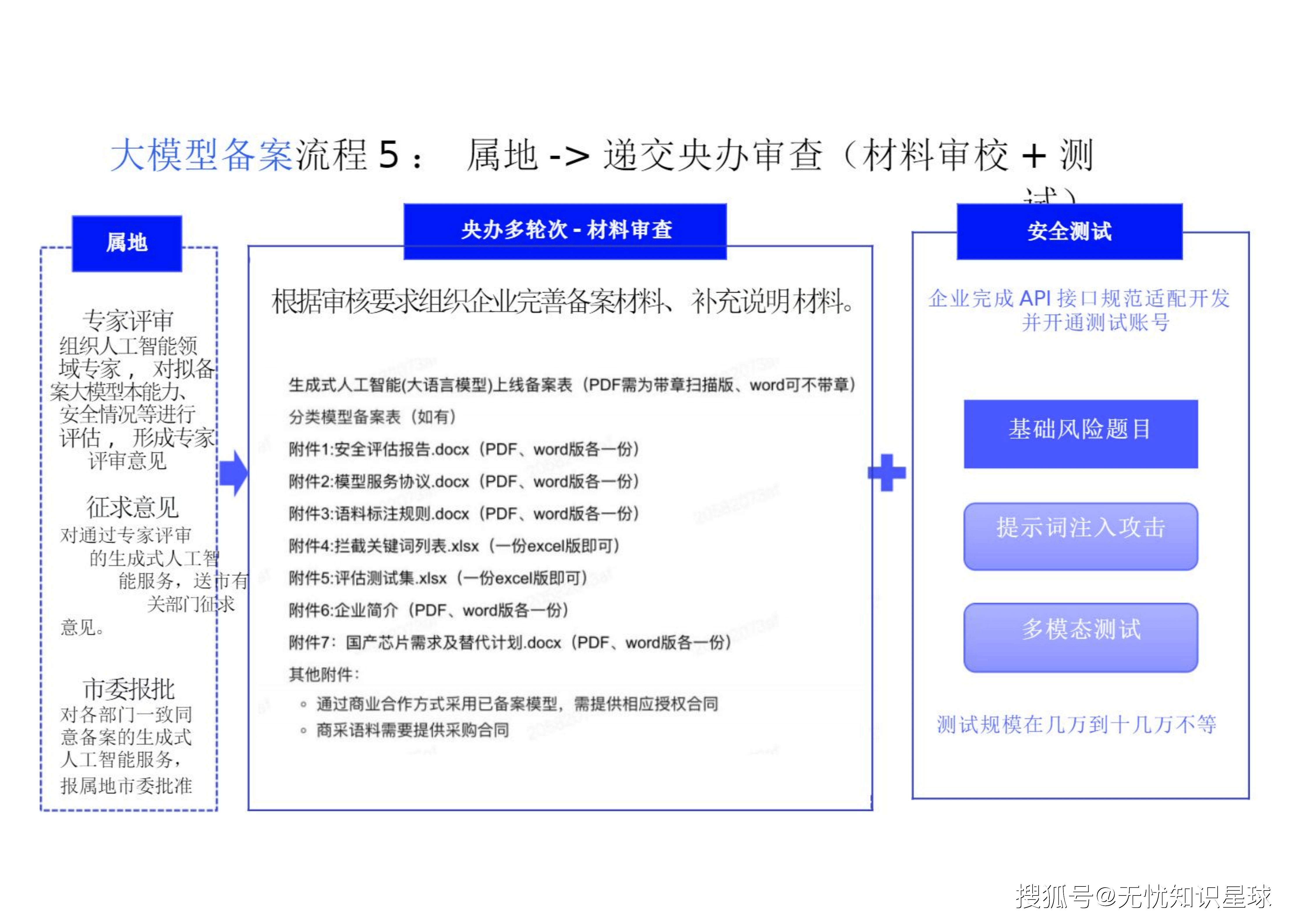
5.3 漫长的闯关:地方至中央的多轮次博弈
-
地方网信办申请: 线下领取信息采集表,盖章PDF与Word发送至指定邮箱 。
-
协办单位审查(属地网安大队): 按照实际办公地管辖原则接受属地公安机关实地检查。技术负责人需在收到通知5日内主动联系属地公安局,完善网络安全管理制度 。
-
多轮次材料审查与专家评审: 属地组织专家对能力、安全进行评估形成评审意见,征求有关部门意见后报市委批准 。
-
中央网信办审查: 地方通过后递交央办进行材料终审与高强度的技术接口测试评估 。
-
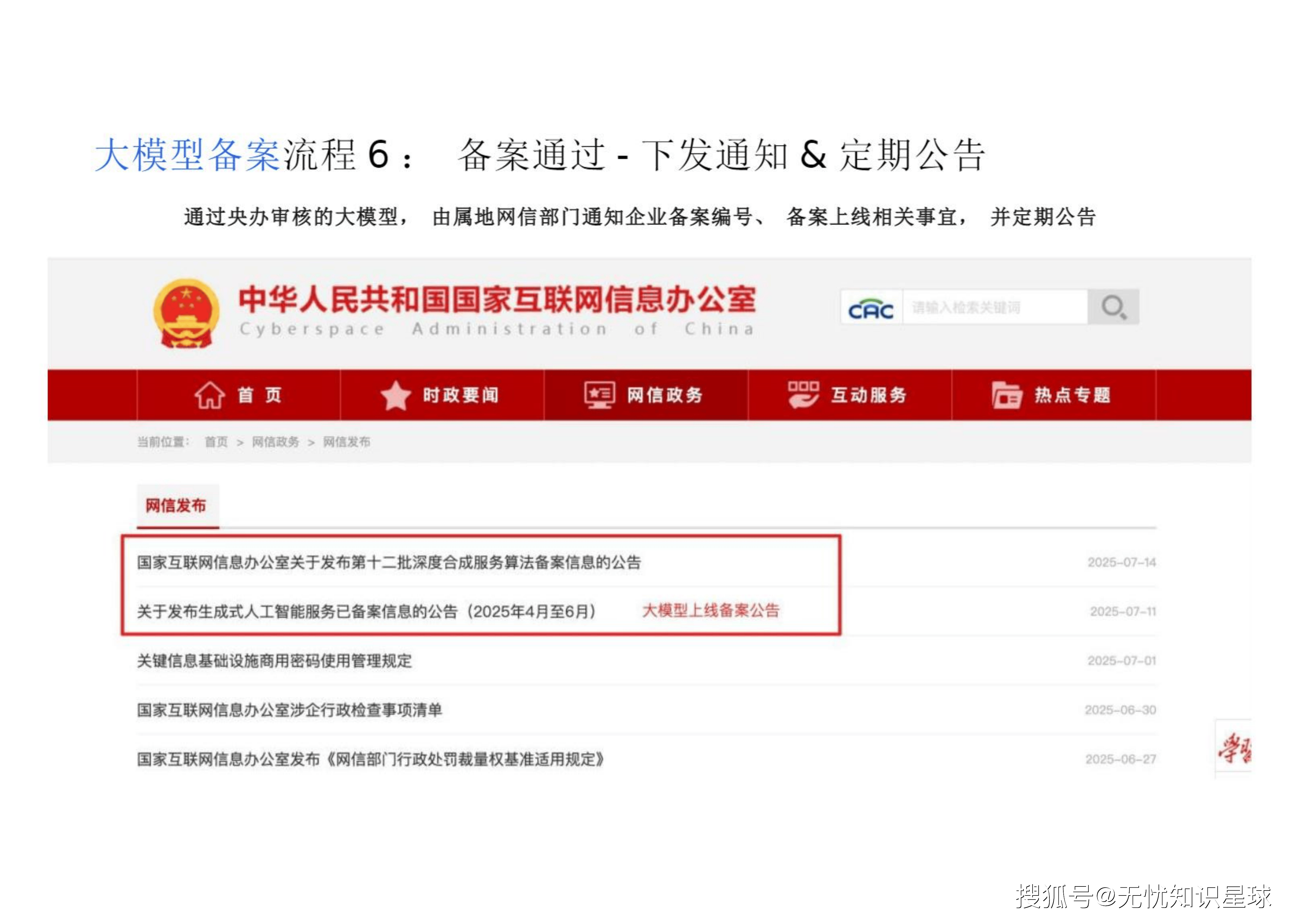
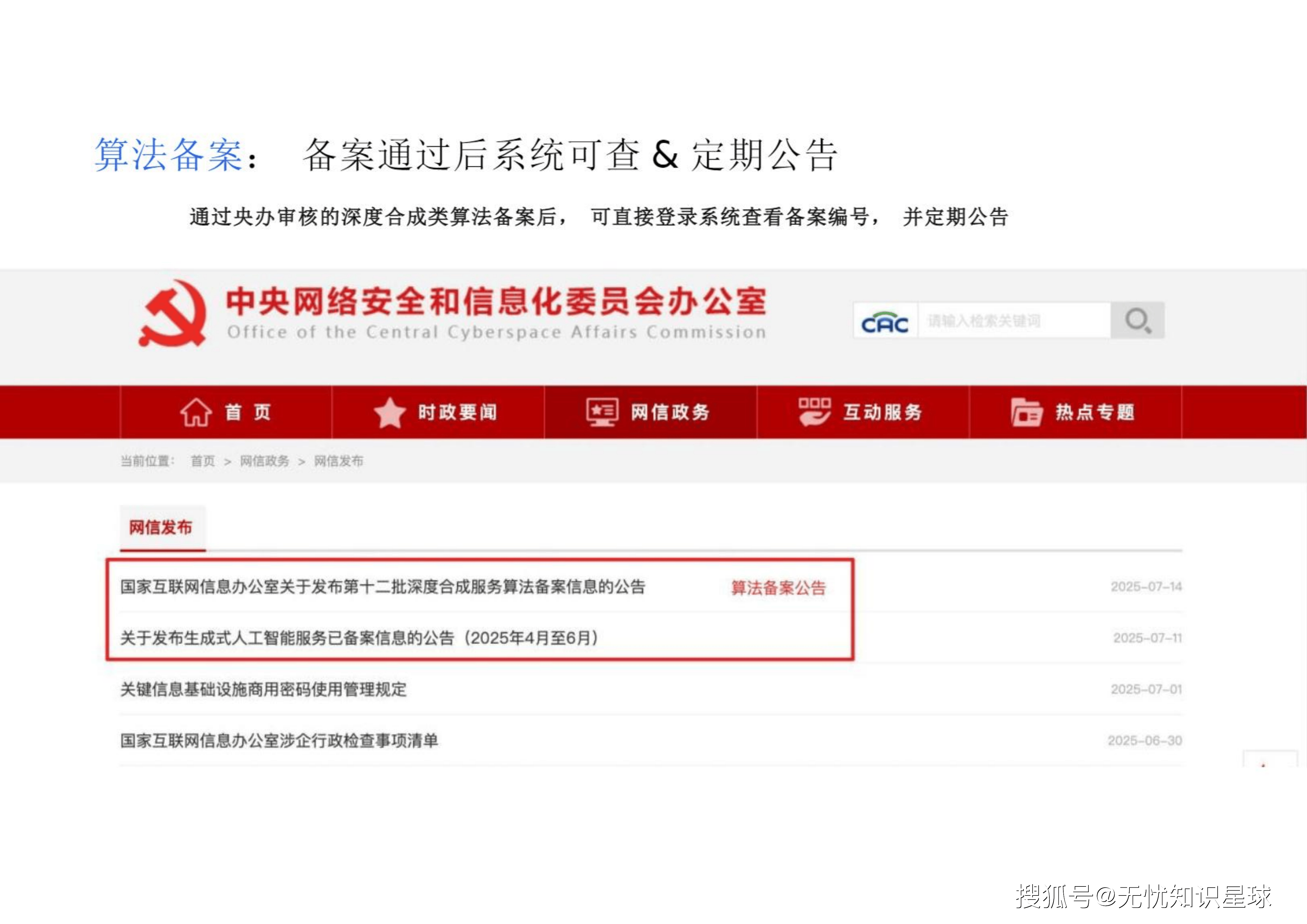
下发通知与公告: 央办审核通过后,由属地网信部门通知企业备案编号、上线事宜,并定期在官网公告 。
需要注意的是,若涉及金融(市金融管理局)、医疗(市卫健委)、教育(市教委)等特殊行业垂类大模型,备案前还需与行业主管部门做进一步沟通咨询 。
六、 未来展望:开源重塑与安全围栏的新常态
截至2025年6月,共有233个大模型完成登记,439个大模型完成备案 。这预示着大模型合规已经从"特事特办"迈入了"常态化治理"的新阶段。
6.1 "第一责任主体"的觉醒
开源模型的迅猛发展,其合规性更需引起重视 。依据《生成式人工智能服务管理暂行办法》第4条,即使技术供应商(如开源模型方)存在缺陷,大模型的使用方与微调方仍需承担内容安全的主体责任 。例如,若员工通过开源模型生成的内部报告中出现严重的表述错误,企业可能因"未履行审核义务"被追究行政责任 。
6.2 思维链(CoT)带来的新型隐患
随着DeepSeek-R1等推理型模型的普及,推理过程的显性化提高了风险暴露几率。思维链展示中间推理步骤,相较于传统黑箱模型,如果没有在输入输出层面识别和处置内容安全风险,逐渐深入的推理过程本身就存在风险,并可能输出风险更大的推理结果 。
这意味着传统的"关键词过滤"已经捉襟见肘。架构师必须在系统中集成极具深度的高级内容安全围栏,利用基于语义理解的回复干预模块,灵活及时地干预和规避风险,以应对网信办日益严格的常态化内容安全巡检 。
6.3 结语
在"数字中国"的宏大叙事中,大模型的上线备案绝非一纸证书,而是一套贯穿了数据资产管理、云边协同调度、系统防御纵深的终极考验。唯有将合规逻辑深度刻入代码骨髓,以前置的架构韧性拥抱监管,方能在智能时代的下半场中走得更远、更稳。