文章目录
- [【Spring AI 实战】五、RAG 核心原理:为什么需要检索增强生成?](#【Spring AI 实战】五、RAG 核心原理:为什么需要检索增强生成?)
-
- [一、大模型的致命缺陷:知识陈旧 + 幻觉](#一、大模型的致命缺陷:知识陈旧 + 幻觉)
- [二、RAG 的工作原理:先找后答](#二、RAG 的工作原理:先找后答)
-
- [2.1 三个阶段详解](#2.1 三个阶段详解)
- 三、为什么不用微调(Fine-tuning)?
- [四、Spring AI 中 RAG 的模块划分](#四、Spring AI 中 RAG 的模块划分)
-
- [4.1 模块总览](#4.1 模块总览)
- [4.2 典型 RAG 流程在 Spring AI 中的对应实现](#4.2 典型 RAG 流程在 Spring AI 中的对应实现)
- [五、Query 和 Document 的 Embedding 为什么要用同一个模型?](#五、Query 和 Document 的 Embedding 为什么要用同一个模型?)
- [六、Embedding + 相似度搜索的核心原理](#六、Embedding + 相似度搜索的核心原理)
-
- [6.1 什么是 Embedding?](#6.1 什么是 Embedding?)
- [6.2 常见的相似度度量](#6.2 常见的相似度度量)
- [七、RAG 的三大挑战与应对策略](#七、RAG 的三大挑战与应对策略)
-
- [7.1 挑战一:召回质量(Retrieval Quality)](#7.1 挑战一:召回质量(Retrieval Quality))
- [7.2 挑战二:上下文长度限制](#7.2 挑战二:上下文长度限制)
- [7.3 挑战三:多跳推理](#7.3 挑战三:多跳推理)
- [八、RAG vs. Agent:两者是什么关系?](#八、RAG vs. Agent:两者是什么关系?)
- [九、Spring AI RAG 快速体验](#九、Spring AI RAG 快速体验)
-
- [9.1 依赖](#9.1 依赖)
- [9.2 配置](#9.2 配置)
- [9.3 完整代码](#9.3 完整代码)
- 十、本章小结
【Spring AI 实战】五、RAG 核心原理:为什么需要检索增强生成?
大家好,我是冰点,今天我们继续聊SpringAI的基本用法和特性
一、大模型的致命缺陷:知识陈旧 + 幻觉
GPT-4、通义千问、Claude 等大语言模型(LLM)的训练数据有明确的时间截止点。以 GPT-4 为例,其知识截止到 2023 年 12 月左右,而企业的内部知识、实时数据、专有文档更是从未被训练过。这意味着:
- 知识陈旧:无法回答"你们公司去年Q3的营收是多少"这类内部问题。
- 一本正经胡说八道(幻觉):模型会自信满满地编造看似合理但完全错误的答案,这在金融、医疗、法律等高风险场景中是致命的。
- 无法精准引用:直接让模型回答,它无法告诉你"这条结论来自哪篇文档的第几段"。
RAG(Retrieval-Augmented Generation,检索增强生成) 正是为了解决这三大问题而生的。
二、RAG 的工作原理:先找后答
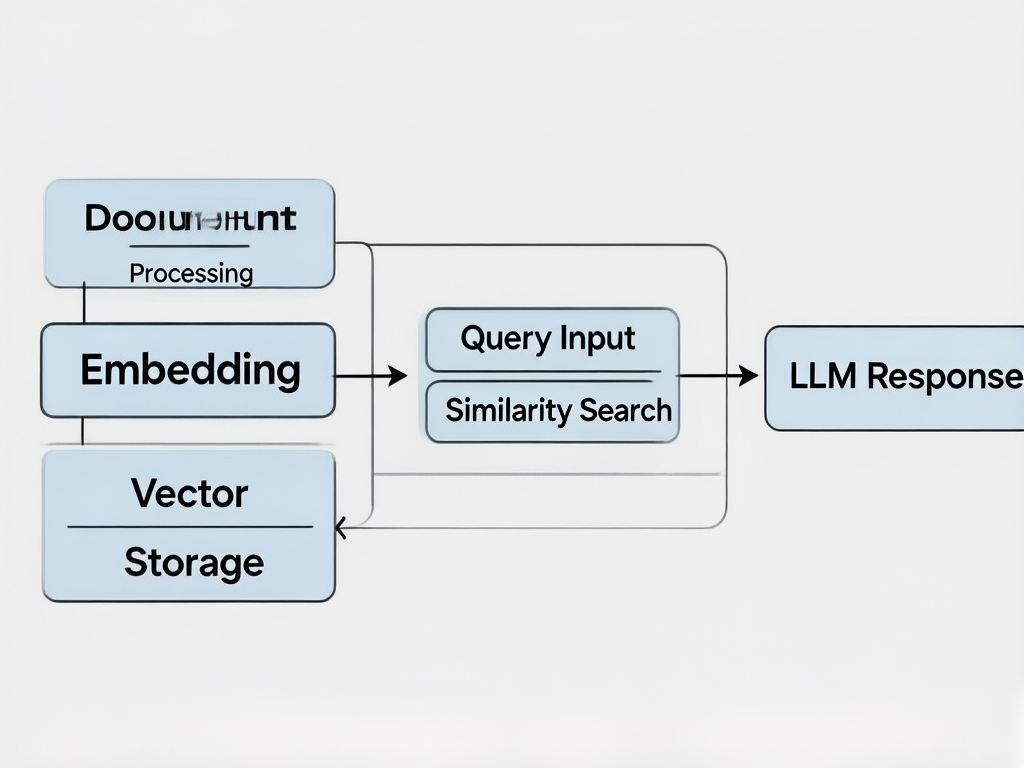
RAG 的核心思想非常直观:在回答之前,先从外部知识库中检索相关内容,再将检索结果作为上下文喂给 LLM 生成答案。
用户提问 → 检索阶段 → 增强阶段 → 生成阶段 → 最终回答
↓
从向量数据库
查询相关文档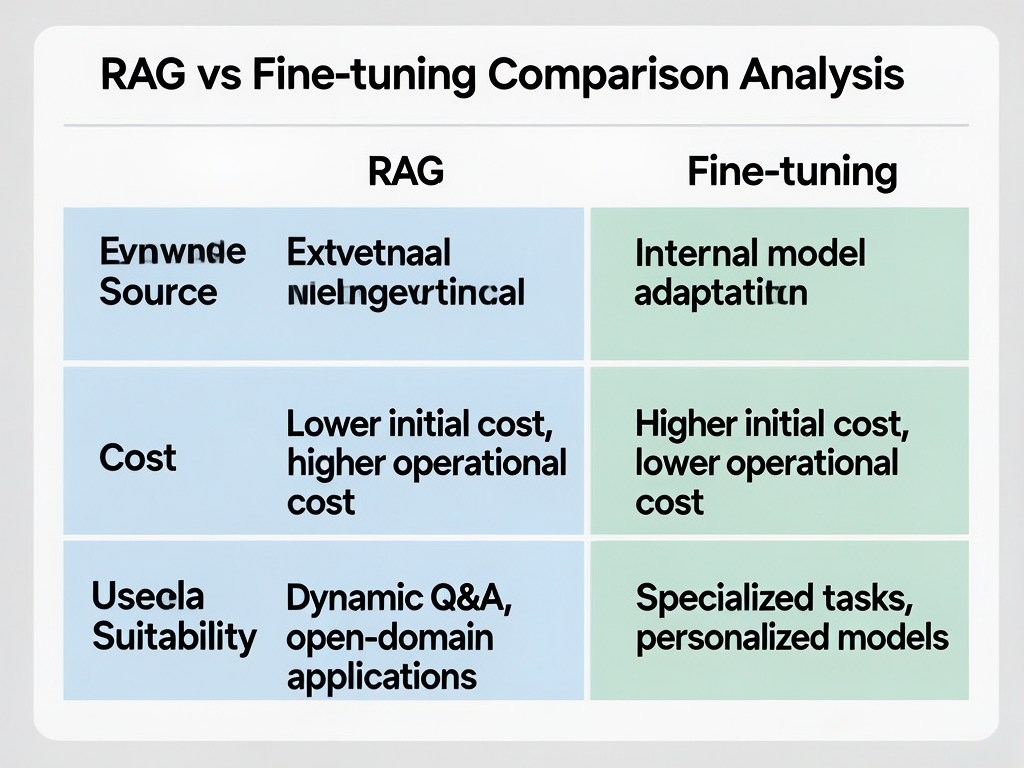
2.1 三个阶段详解
阶段一:检索(Retrieval)
用户问题首先被转换为向量(通过 Embedding 模型),然后在向量数据库中做相似度搜索,找出 Top-K 条最相关的文档片段。
阶段二:增强(Augmentation)
将检索到的文档片段与用户的原始问题组装成一个"扩增 Prompt",格式通常如下:
你是一个助手。根据以下参考资料回答用户的问题。
如果参考资料中没有相关信息,请如实说明,不要编造。
【参考资料】
{retrieved_chunk_1}
{retrieved_chunk_2}
...
{retrieved_chunk_k}
【用户问题】
{user_question}
【回答】阶段三:生成(Generation)
将上述扩增 Prompt 发送给 LLM,LLM 基于真实参考资料生成答案。由于答案的"来源"被明确限定在参考资料中,幻觉问题大幅减少。
三、为什么不用微调(Fine-tuning)?
很多人会问:为什么不直接微调模型,让它学会这些知识?以下是 RAG 相比 Fine-tuning 的核心优势对比:
| 维度 | RAG | Fine-tuning |
|---|---|---|
| 数据时效性 | ✅ 可实时更新知识库,无需重新训练 | ❌ 需要重新微调,周期长 |
| 成本 | ✅ 低(只需存储向量数据) | ❌ 高(GPU 训练成本数万~数百万) |
| 可解释性 | ✅ 可直接引用原始文档来源 | ❌ 模型"权重"不可解释 |
| 幻觉问题 | ✅ 大幅减少,答案有据可查 | ⚠️ 仍有风险 |
| 实时数据 | ✅ 支持动态查询数据库/API | ❌ 只能处理训练时见过的数据 |
| 部署复杂度 | ✅ 只需向量数据库 + LLM API | ❌ 需要管理微调后的模型权重 |
| 适用场景 | 知识库问答、实时数据查询 | 特定领域风格迁移、任务模式学习 |
结论:RAG 是企业级 AI 应用的首选方案,因为它成本低、见效快、可解释性强。
四、Spring AI 中 RAG 的模块划分
Spring AI 将 RAG 能力拆分为以下几个核心模块,每个模块都可以独立使用或组合使用:
4.1 模块总览
Spring AI RAG
├── DocumentReader # 文档读取(PDF/Word/Markdown/HTML...)
├── TextSplitter # 文本分割(按字符/Token/语义)
├── EmbeddingModel # 向量化模型(OpenAI/MiniMax/本地模型)
├── VectorStore # 向量存储(Pinecone/Milvus/Redis/Chroma/Elasticsearch)
├── SimilaritySearch # 相似度检索
├── QueryAugmenter # 查询增强(HyDE/ReAct/重排序)
└── PromptDecorator # Prompt 增强(上下文组装)4.2 典型 RAG 流程在 Spring AI 中的对应实现
java
// Spring AI 中一条完整 RAG 流程的伪代码
Document document = pdfReader.read("report.pdf"); // 1. 读取文档
List<Document> chunks = textSplitter.split(document); // 2. 文本分割
embeddingModel.embed(chunks); // 3. 向量化
vectorStore.store(chunks); // 4. 存入向量库
List<Document> relevant = vectorStore.similaritySearch(query); // 5. 检索
String answer = chatClient.prompt() // 6. 生成
.system("根据以下资料回答:{context}")
.user("问题:" + query + "\n资料:" + relevant)
.call()
.content();五、Query 和 Document 的 Embedding 为什么要用同一个模型?
这是一个常见误区。检索阶段有一个关键原则:
Query(用户问题)的 Embedding 模型必须与 Document(知识库)的 Embedding 模型保持一致。
原因是:Embedding 模型在训练时通常对"查询类文本"和"文档类文本"有不同的偏好。例如,用处理"提问"的模型生成的向量去检索"文档",会因为向量空间不对齐而导致检索质量下降。
Spring AI 提供了 MultiModelEmbedding 接口来解决跨模型检索问题,但生产环境中强烈建议使用统一的 Embedding 模型。
六、Embedding + 相似度搜索的核心原理
6.1 什么是 Embedding?
Embedding 是将文本映射为一个高维向量(例如 1536 维)的过程。语义相近的文本在向量空间中距离更近。
"如何申请退款" → [0.12, -0.34, 0.78, ...] ←→ "退款流程是什么" (余弦相似度: 0.91)
"如何申请退款" → [0.12, -0.34, 0.78, ...] ←→ "今天天气怎么样" (余弦相似度: 0.12)6.2 常见的相似度度量
| 度量方式 | 公式 | 特点 | 适用场景 |
|---|---|---|---|
| 余弦相似度 | cos(θ) = A·B/( | A | |
| 欧氏距离 | √Σ(Ai-Bi)² | 直观,几何意义清晰 | 密集体数据 |
| 点积 | A·B | 计算快,与向量模长相关 | 对长度敏感的排序 |
七、RAG 的三大挑战与应对策略
7.1 挑战一:召回质量(Retrieval Quality)
问题:检索到的文档和用户问题"语义相近但实际不相关",导致回答跑偏。
Spring AI 解决方案:
- 使用 ReRanker(重排序模型) 对初步召回结果重新打分排序
- 使用 HyDE(Hypothetical Document Embeddings) 让模型先生成一个"假设答案"再检索
- 使用 Query Expansion 将用户问题拆分为多个子问题分别检索
7.2 挑战二:上下文长度限制
问题:LLM 有上下文长度限制(如 GPT-3.5 是 16K tokens),无法一次性塞入所有检索结果。
Spring AI 解决方案:
- 精确控制
SimilaritySearchOptions.topK参数限制返回数量 - 使用
ContextualCompression压缩冗余内容 - 使用
SummaryTransformer对检索结果做摘要再喂给 LLM
7.3 挑战三:多跳推理
问题:有些问题需要综合多份文档才能回答(如"对比A公司2023年和2024年的营收增长")。
Spring AI 解决方案:
- 使用 Agent 做多步推理和工具调用
- 使用 Query Decomposition 将复杂问题拆解为多个简单问题
八、RAG vs. Agent:两者是什么关系?
这是另一个常见混淆。
┌─────────────────────────────────────────────┐
│ Agent │
│ ┌──────────┐ ┌──────────┐ ┌───────┐ │
│ │ Planning │ → │ Memory │ → │ Tools │ │
│ └──────────┘ └──────────┘ └───────┘ │
│ ↑ │
│ ┌───────┴───────┐ │
│ │ RAG │ ← Agent 的 │
│ │ (工具之一) │ 知识库工具 │
│ └───────────────┘ │
└─────────────────────────────────────────────┘关系:RAG 是 Agent 能力体系中的重要"工具"之一,但 Agent 不等于 RAG。Agent 还需要规划(Planning)、记忆(Memory)、工具调用(Tools)等能力。
九、Spring AI RAG 快速体验
以下是一个极简版 RAG 演示,只需 30 行代码即可跑通完整流程:
9.1 依赖
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId>
</dependency>9.2 配置
yaml
spring:
ai:
openai:
api-key: ${OPENAI_API_KEY}
embedding:
openai:
options:
model: text-embedding-3-small9.3 完整代码
java
@RestController
@RequestMapping("/rag")
public class RagController {
private final VectorStore vectorStore;
private final ChatClient chatClient;
public RagController(VectorStore vectorStore, ChatClient chatClient) {
this.vectorStore = vectorStore;
this.chatClient = chatClient;
}
// 初始化知识库(启动时执行一次)
@PostConstruct
public void initKnowledgeBase() {
String content = """
退货政策:自收到商品之日起7天内可以申请退货,
15天内可以申请换货。定制商品不支持无理由退货。
""";
Document doc = new Document(content);
vectorStore.add(List.of(doc));
}
// RAG 问答接口
@GetMapping("/ask")
public String ask(@RequestParam String question) {
// 1. 检索相关文档
List<Document> docs = vectorStore.similaritySearch(question);
// 2. 组装 Prompt
String context = docs.stream()
.map(Document::getContent)
.collect(Collectors.joining("\n"));
String prompt = """
根据以下退货政策回答用户问题。如果政策中没有相关信息,
请回答"抱歉,我没有找到相关信息"。
【退货政策】
%s
【用户问题】
%s
""".formatted(context, question);
// 3. 生成回答
return chatClient.prompt()
.user(prompt)
.call()
.content();
}
}十、本章小结
| 知识点 | 核心要点 |
|---|---|
| RAG 定义 | 检索 → 增强 → 生成,先找后答 |
| 核心价值 | 解决知识陈旧、幻觉、无法引用来源三大问题 |
| vs Fine-tuning | RAG 成本低、实时、可解释;Fine-tuning 适合风格迁移 |
| Embedding | 文本→高维向量,语义相近→向量空间距离近 |
| Spring AI 模块 | DocumentReader / TextSplitter / EmbeddingModel / VectorStore |
| 三大挑战 | 召回质量、上下文长度、多跳推理 |
| RAG vs Agent | RAG 是 Agent 的知识工具之一,不是全部 |
下一篇预告:《六、文档 ETL 实战:PDF/Word/Markdown 解析与文本分割》------ 详细介绍 Spring AI 中如何将各类文档解析为结构化文本,以及如何做好文本分割策略。
📌 系列导航
📎 示例说明:本文以原理讲解和 RAG 心智模型为主,建议与第六至第八篇配套阅读。