非结构化数据检索:全文本索引与底层 OCR 解析
在企业日常运作中,数据存储的最终目的在于随时被准确调用。然而,随着文件共享服务器(NAS)中积累了数以百万计的 PDF、Word 文档以及扫描件,员工在日常办公中面临的最大阻力,已经从"存储空间不足"降级为最基本的"找不到文件"。
当用户通过 Windows 资源管理器连接到网络映射磁盘,并在右上角搜索框中输入关键字时,往往需要面对长达数十分钟的进度条,甚至遭遇系统无响应。这种检索瘫痪并非硬盘损坏,而是底层协议机制与文件结构导致的必然结果。威联通(QNAP)通过在存储节点本地部署 Qsirch 全文本搜索引擎,将"搜索"这一计算动作从前端电脑转移至后端服务器,重构了底层的文件寻址逻辑。
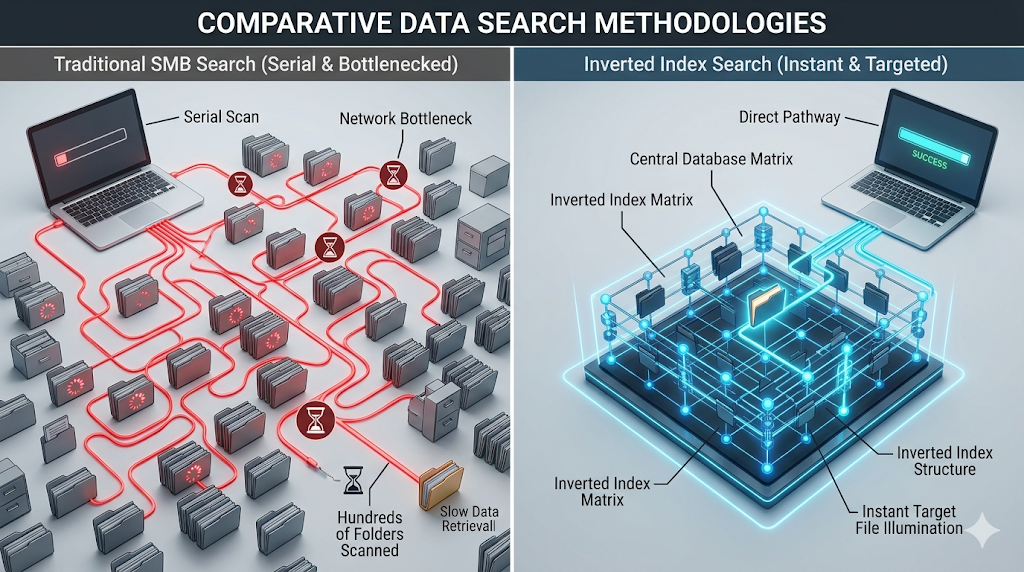
一、 物理阻碍:SMB 协议下的串行搜索困境
理解传统搜索为什么慢,需要剖析 SMB/CIFS 网络文件协议的底层逻辑。
当用户在 Windows 中搜索网络磁盘时,前端电脑的 CPU 会向 NAS 发出指令,通过局域网"串行"打开每一个文件夹,读取文件名称。如果勾选了"包含文件内容",前端电脑甚至需要通过网络将每一个文档拉取到本地内存中进行拆解比对。
- 高昂的网络开销:在包含 100 万个文件的存储池中,这种拉网式的串行扫描会产生海量的网络 I/O 请求包。它不仅极度消耗前端电脑的算力,还会导致局域网带宽被微小的数据封包阻塞,最终表现为搜索进度条的彻底停滞。
二、 Qsirch 倒排索引:将算力收敛于本地
为了打破前端搜索的网络瓶颈,威联通 Qsirch 引擎放弃了实时扫描,转而采用类似 Google 或 Elasticsearch 核心引擎的**倒排索引(Inverted Index)**技术。
-
本地索引库(Index Database):当文件初次落盘或发生修改时,运行在威联通系统内核中的 Qsirch 服务会直接调用 NAS 自身的 CPU 与内存,在后台静默解析文件内容。它将文档拆解为无数个独立的词汇(Token),并建立一张"词汇 -> 文件物理位置"的映射表(即倒排索引库)。
-
毫秒级查询:当用户在 Qsirch 界面(Web 端或手机端)输入搜索词时,系统不再去遍历物理硬盘上的文件结构,而是直接在事先建立好的高维索引库中执行内存级别的布尔比对(Boolean Matching)。这种机制将耗时数十分钟的网络 I/O,转化为延迟仅在几十毫秒内的本地数据库查询,查询速度与文件总数完全脱钩。
三、 本地 OCR 引擎:扫描件与图像的文本剥离
在法务或财务部门,大量的核心数据并非以可编辑的 Word 或 Excel 存在,而是以扫描版 PDF、传真图片(TIFF/JPEG)的形式固化。传统的文本搜索引擎对这类纯像素图像完全无能为力。
威联通 Qsirch 引擎在底层内嵌了 OCR(光学字符识别) 模块。
-
像素转文本的后台推断:当一张包含文字的扫描图片存入 NAS 时,后台的 OCR 引擎会自动启动。它利用 CPU 的向量指令集,对图像中的像素阵列进行形态学分析,将其推断、还原为可供检索的字符串,并将这些提取出的不可见文本注入到该图片的元数据(Metadata)索引中。
-
数据主权的零妥协:目前许多应用依赖调用公有云 API(如百度云或阿里云 OCR)来识别图片文字,但这会导致企业内部的敏感合同或报表流出物理网闸。Qsirch 的 OCR 推理过程 100% 在威联通本地 CPU/内存中离线完成,确保了在实现"图片内文字秒搜"的同时,核心业务数据不发生任何外部流转。
四、 多维元数据过滤:缩小检索漏斗
在命中了数千个包含关键字的搜索结果后,如何帮助用户进行二次降维,是搜索引擎可用性的关键。
Qsirch 在建立索引时,不仅提取正文内容,还会深度抽离文件的原生元数据。 例如,针对摄影或设计团队,系统会解析 RAW 或 JPEG 图像的 EXIF 数据。用户可以不输入任何关键字,直接通过左侧的过滤面板,勾选"相机品牌:Sony"、"焦距:50mm"或"光圈:f/1.8"等硬件级属性。结合修改时间、文件大小或作者信息的交叉过滤,系统能够在海量的搜索结果中建立一个多维度的漏斗,快速收敛目标文件的物理坐标。
五、 总结
将"搜索"从操作系统的附加功能,升格为独立的底层数据库服务,是解决海量非结构化数据寻址的唯一工程路径。威联通 Qsirch 通过引入本地倒排索引机制,截断了传统 SMB 搜索造成的网络 I/O 风暴;并通过内嵌的离线 OCR 引擎,唤醒了沉睡的图像与扫描件数据。对于任何每天需要与海量历史文档打交道的企业部门而言,这项微观的功能重构,直接消除了员工在数据检索环节面临的系统性时间损耗。