前面我已经介绍过数据清洗,主要是先把原始的 CSV 或 Excel 文件整理成结构清晰、字段规范、可以继续分析的数据。数据清洗完成之后,下一步通常就是把数据入库成表,再基于表去做统计分析。尤其是在千万级数据场景下,真正的难点是在 本地电脑里面,进行数据入库,如何稳定、快速地完成大表统计。
关于千万级数据清洗的可以看我专栏的其它文章。
在实际业务里,很多需求并不是单纯查看明细,而是要进一步看总量、分组结果、趋势变化、排行情况,甚至是多个表之间的关联分析。数据量一旦上来,如果继续依赖手工透视、临时脚本或者现写 SQL,不仅效率低,而且很容易在统计口径、字段关联和分析逻辑上出错。
这篇文章就介绍如何将表格文件进行入库到本地数据库成表,然后通过自然语言提示词完成千万级数据场景下的单表统计和多表统计分析。
本地数据库引擎这里采用的不是传统 MySQL 那种更偏行式的存储处理方式,而是基于列式存储来做分析计算。对于统计分析这类场景,列式存储在聚合、分组、筛选、排序等操作上通常更有优势,尤其适合大批量数据的分析型查询。也正因为如此,在千万级数据表统计场景下,整体查询性能会更高,很多统计任务都可以做到秒级返回结果。
一、什么是表统计智能体
"表统计智能体"本质上可以理解为一个自然语言驱动的数据表分析助手。对已经准备好的表进行分析、汇总和结构化输出。通过入库后,用户只需要围绕"我想统计什么""按什么维度分析""多个表之间怎么关联"来写提示词,系统就可以自动理解需求并生成对应的统计逻辑。
和传统做法相比,它最大的特点同样不是"功能多",而是"表达更接近业务语言"。你不需要先写 select 、 group by 、 join 、 having 、 order by ,也不需要提前想好 SQL 结构,只需要把分析目标说清楚,比如"按部门统计人数""按日期统计销售额趋势""把订单表和退款表关联起来看退款率""按员工和月份统计工资总额",系统就能自动完成相应的统计分析。
表统计适合解决什么问题
在数据处理链路里,表统计更适合处理下面这几类问题。
1. 单表基础统计
这是最常见的一类场景。也就是围绕一张已经整理好的表,做汇总、分组、排序和排行分析。
例如你可以输入下面这些提示词:
-
统计表总数。
-
按"部门"分组,统计每个部门的人数。
-
按"城市"分组,统计销售额总和,并按销售额从高到低排序。
-
统计"退款金额"大于100的订单数量。
-
按"班组"分组,统计平均工资,并取前10个班组。
这些需求本质上都属于单表统计,只不过统计口径、分组字段和排序方式不同。
2. 单表复杂分析
有些需求虽然还是单表,但不再只是简单计数或求和,而是带有更多分析意图。比如同比、环比、占比、分组内排行、Top N、结构占比等。
例如:
-
按"日期"统计每天销售额,并按日期升序输出。
-
按"部门"分组,统计人数,并计算每个部门人数占总人数的比例。
-
按"员工"分组,统计每个人的总业绩,并取前20名。
-
按"月份"分组,统计收入总额,并按月份输出趋势。
-
按"水果"分组,统计销售额总和,并计算每种水果销售额占总销售额的比例。
这类需求的重点已经不只是"得到结果",而是得到一个更适合继续看趋势、做比较、看结构的统计结果表。
3. 多表关联统计
这类场景比单表更进一步。数据不是只在一张表里,而是已经分散在多张表中,比如订单表、退款表、员工表、工资表、考勤表、商品表、库存表等。此时就不只是简单分组统计,而是需要先把多个表按业务关系关联起来,再做分析。
例如:
-
将订单表和退款表按订单ID关联,统计每个商品的退款率。
-
将员工表和工资表按员工ID关联,统计每个部门的平均工资。
-
将销售表和库存表按SKU编码关联,统计高销量但低库存的商品。
-
将招聘表和入职表按候选人ID关联,统计每个招聘渠道的最终入职转化率。
-
将客户表和订单表按客户ID关联,统计不同客户等级的复购情况。
这类需求如果手工写 SQL,往往容易卡在关联键、统计口径和聚合层级上;而自然语言驱动的表统计,更适合让业务人员直接描述目标。
4. 模糊统计目标分析
这是一个很有价值、也很适合实际业务的场景。很多用户在做数据分析时,并不是一开始就能准确说出"按什么字段分组、统计哪个指标、排序规则是什么",而是只有一个相对模糊的业务目标。比如他知道自己想看"哪个品牌卖得最好""哪些客户最有价值""哪个渠道效果最好",但并不一定能立即拆解成标准 SQL 或完整统计口径。
这时候,用户不需要先把统计逻辑想得特别清楚,只需要先描述自己的分析目标,系统会去理解这类模糊提示词背后的统计意图,再自动收口成对应的分析任务。这也是表统计工具一个很重要的亮点。
例如:
-
按品牌分析,找出销量最高与最赚钱的品牌。
-
分析一下哪些客户最值得重点运营。
-
看看哪个渠道带来的订单最多,而且退款率最低。
-
帮我找出表现最好的销售员和拖后腿的销售员。
-
分析一下哪些商品卖得多,但利润并不高。
这类需求的价值在于,它更接近真实业务表达,而不是技术实现表达。用户不一定要先知道该写 group by 、 sum 、 avg 、 order by ,只需要先说清楚"想看什么业务结果",系统再把它转换成更具体的统计分析逻辑。
三、解决方案
传统的数据统计方案,通常依赖 SQL、Python、BI 工具或者 Excel 数据透视表。对于小数据量、临时分析来说,这些方案并不是不能用;但当数据量和分析复杂度一起上升后,真正麻烦的往往不是"有没有工具",而是"这个分析逻辑能不能快速写对、稳定跑完"。
特别是在大数据量表场景下,很多统计需求都需要先经历几步:先把原始文件清洗好,再入库成表,最后基于表来做分析。如果每一步都要人工切换工具、手工写逻辑,不仅耗时,而且非常容易在字段名、统计口径、筛选条件、分组层级上出错。
通过我们的自动化AI工作流,可以直接将原始表格文件的清洗,入库,表统计配置成链路同时执行得到结果。
下面我们通过一个统计的案例来分析。
案例:电商用户增长与转化分析
首先已经通过数据清洗生成了下面相关表,如图:
各表的列信息和部分数据如下。
访问行为表:
| 访问ID | 访客ID | 访问时间 | 访问渠道 | 设备类型 | 页面类型 | 是否新访客 | 关联用户ID |
|---|---|---|---|---|---|---|---|
| VISIT00001 | VISITOR00001 | 2026/1/6 22:51 | 自然搜索 | Android | 商品详情页 | 否 | USER00001 |
| VISIT00002 | VISITOR00012 | 2026/3/2 5:08 | 首页推荐 | iPhone | 类目页 | 是 | |
| VISIT00003 | VISITOR00023 | 2026/1/17 1:32 | 直播间 | PC | 首页 | 否 | USER00023 |
| VISIT00004 | VISITOR00034 | 2026/1/17 8:17 | 直播间 | iPhone | 直播间页 | 否 | USER00034 |
加购表:
| 加购ID | 用户ID | 商品ID | 商品名称 | 加购时间 | 商品数量 | 来源渠道 |
|---|---|---|---|---|---|---|
| CART00001 | USER00001 | SKU0005 | 库尔勒香梨 | 2026/2/21 8:47 | 2 | 自然搜索 |
| CART00002 | USER00008 | SKU0003 | 云南蓝莓 | 2026/1/6 8:35 | 3 | 社群分享 |
下单表:
| 订单号 | 用户ID | 商品ID | 商品名称 | 下单时间 | 商品数量 | 订单金额 | 订单渠道 | 订单状态 | 是否首单 |
|---|---|---|---|---|---|---|---|---|---|
| ORDER00001 | USER00001 | SKU0011 | 佳沛奇异果 | 2026/3/3 14:12 | 4 | 357.42 | 广告投放 | 已支付 | 是 |
| ORDER00002 | USER00010 | SKU0011 | 佳沛奇异果 | 2026/2/14 15:21 | 2 | 164.5 | 自然搜索 | 已支付 | 是 |
| ORDER00003 | USER00019 | SKU0004 | 泰国金枕榴莲 | 2026/1/15 17:57 | 3 | 120.41 | 直播间 | 已支付 | 是 |
用户表:
| 用户ID | 访客ID | 注册时间 | 注册渠道 | 设备类型 | 省份 | 城市 | 是否会员 |
|---|---|---|---|---|---|---|---|
| USER00001 | VISITOR00001 | 2026/2/7 12:52 | 自然搜索 | PC | 江苏 | 成都 | 是 |
| USER00002 | VISITOR00002 | 2026/1/4 16:50 | 社群分享 | PC | 山东 | 广州 | 否 |
| USER00003 | VISITOR00003 | 2026/3/9 13:07 | 社群分享 | PC | 河南 | 苏州 | 是 |
支付表:
| 支付单号 | 订单号 | 用户ID | 支付时间 | 支付金额 | 支付方式 | 支付状态 |
|---|---|---|---|---|---|---|
| PAY00001 | ORDER00001 | USER00001 | 2026/3/3 15:03 | 357.42 | 银行卡 | 支付成功 |
| PAY00002 | ORDER00002 | USER00010 | 2026/2/14 15:47 | 164.5 | 银行卡 | 支付成功 |
| PAY00003 | ORDER00003 | USER00019 | 2026/1/15 20:21 | 120.41 | 支付宝 | 支付成功 |
根据上面5个表格进行下面20个指标数据分析:
- 注册转化概览 :帮我看看最近一周来了多少人访问,有多少人最后注册成用户了,注册转化怎么样。
2.渠道拉新效果 :我想知道各个访问渠道带来了多少访客、多少注册用户,哪个渠道拉新效果最好。
3.设备转化对比 :帮我看一下不同设备来的用户,注册效果有什么差别,哪个设备的转化更高。
4.地域转化分布 :看看各个省份、城市的访客数、注册用户数和下单用户数,哪里转化最好。
5.渠道加购转化 :帮我分析一下从访问到加购的转化情况,哪些渠道的人更容易先把商品加进购物车。
6.注册下单转化 :我想知道注册用户里面,有多少人最后下单了,下单转化率高不高。
7.加购下单分析 :帮我看看加购的人最后有多少下单了,哪些商品加购多但下单少。
8.商品成交效率 :看一下不同商品从被加购到被下单的转化情况,哪些商品最容易成交。
9.渠道支付意愿 :帮我看各个渠道带来的下单人数和支付人数,哪个渠道付钱最爽快。
10.支付转化漏斗:我想知道支付转化率怎么样,就是下单的人里面最后真正付钱的人有多少。
- 首单来源分析 :帮我看看哪些用户是第一次下单,首单用户主要来自哪些渠道。
12.会员价值对比 :看一下会员和非会员的下单转化、支付转化有什么差别,会员值不值得继续做。
13.复购行为分析 :帮我分析一下复购情况,哪些用户买过一次以后还会继续买,复购率高不高。
14.渠道客户质量 :我想知道不同渠道带来的用户,后面谁更容易复购,哪个渠道客户质量最好。
15.城市消费价值 :帮我看看不同城市的用户下单金额和支付金额,哪里用户更值钱。
16.拉新与转化商品 :看一下哪些商品最能带来新用户下单,哪些商品更容易让用户直接付钱。
17.趋势波动监控 :帮我按时间看一下注册、加购、下单、支付的变化趋势,最近是不是哪里掉下来了。
18.渠道流失诊断 :我想看看访问很多但注册很少的渠道有哪些,帮我找出问题比较大的渠道。
19.商品流失诊断 :帮我找出加购很多但最后不下单的商品,看看是不是这些商品转化有问题。
20.全链路漏斗分析:给我整体看一下从访问、注册、加购、下单到支付这一整条链路,每一步掉了多少人。
上面每一个统计指标就输出一张新的表格。
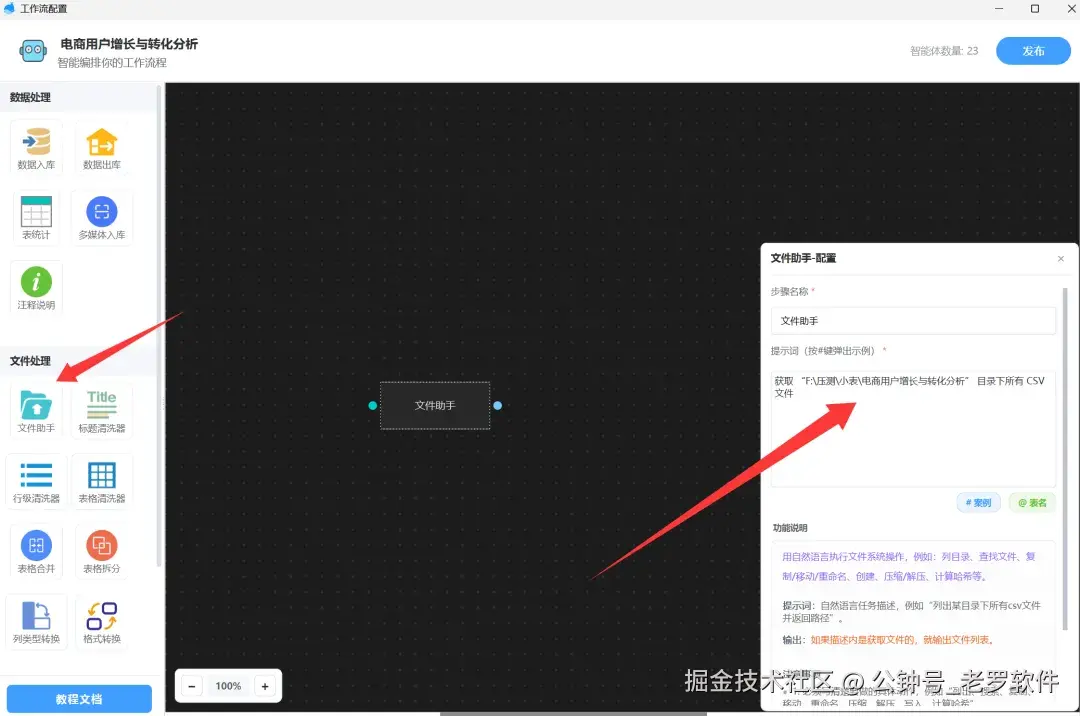
首先打开 DT-Bot 工作流,配置一个"文件助手"智能体节点,用来获取 CSV 或 Excel 文件,作为后续表统计的输入来源,如下图所示:
点击下面获取到这个软件:
这个 "文件助手" 可以获取一个文件,也可以获取目录下的多个文件。 多个文件就可以后面对多个文件批量进行清洗。
配置好文件助手,我们就获取到了原文件了,数据清洗我们就省略不讲了, 然后我们在直接挂一个"数据入库"的智能体节点,如图:
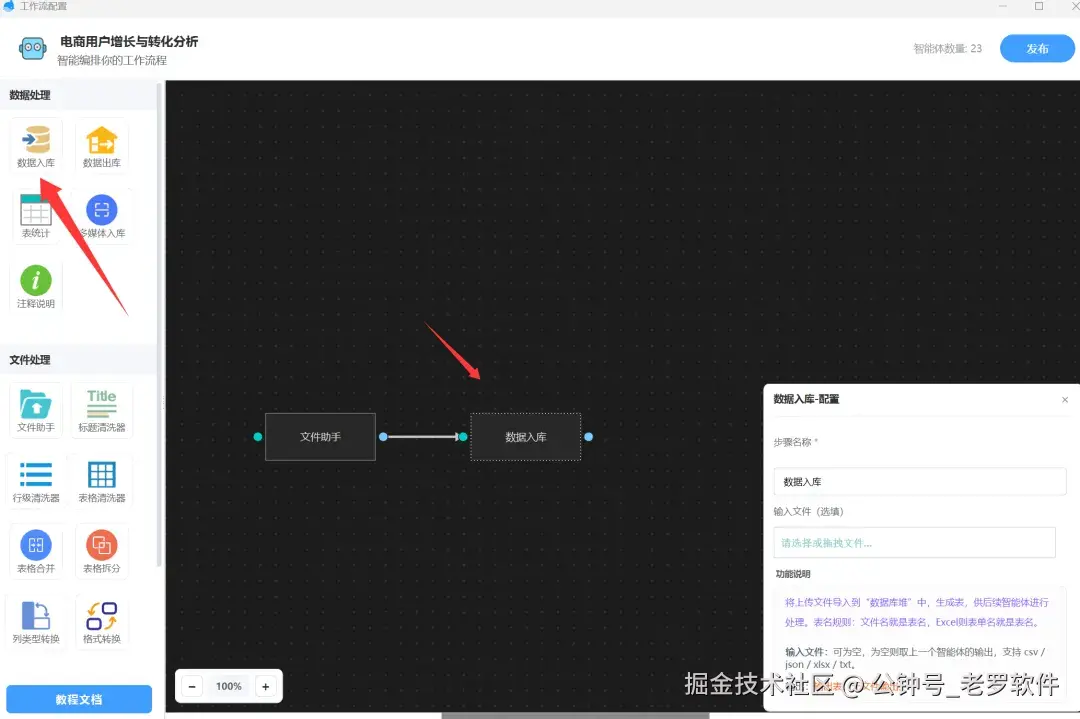
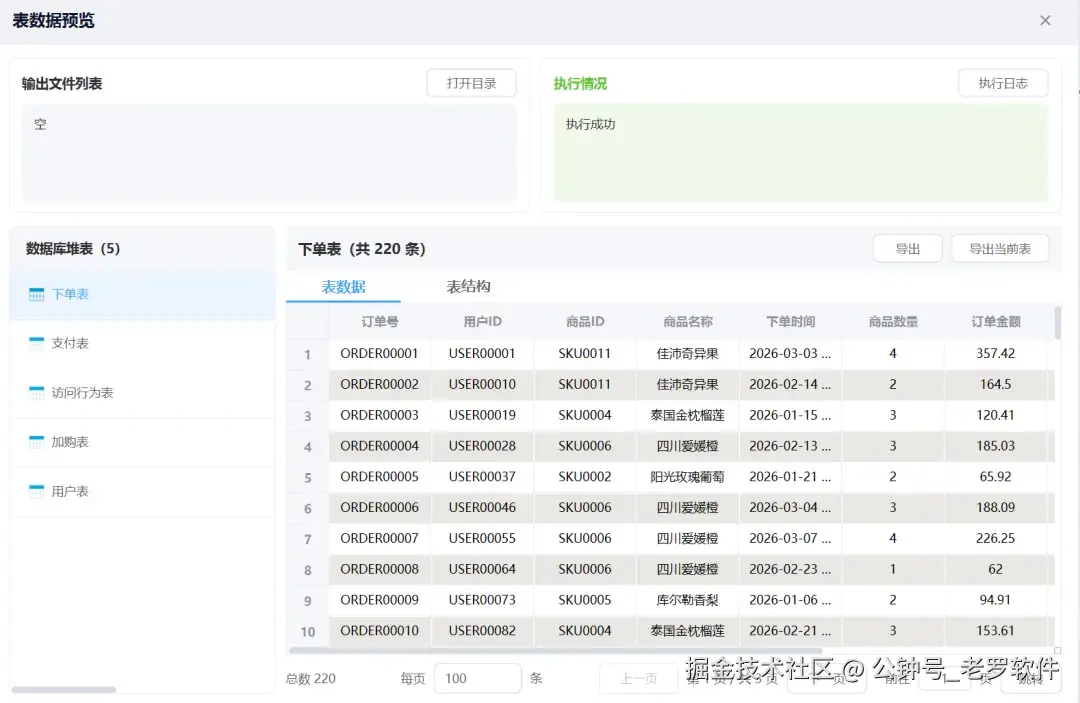
为什么要先进行入库,因为原始表格是不可以进行关联分析的,我通过入库统一检测列格式,创建表,将数据入库到表里面。数据入库不需要配置任何参数,都是AI自动处理数据类型。入库后,我们可以预览数据库的表数据,如图:
我们还可以查看每一个表的表结构,如图:
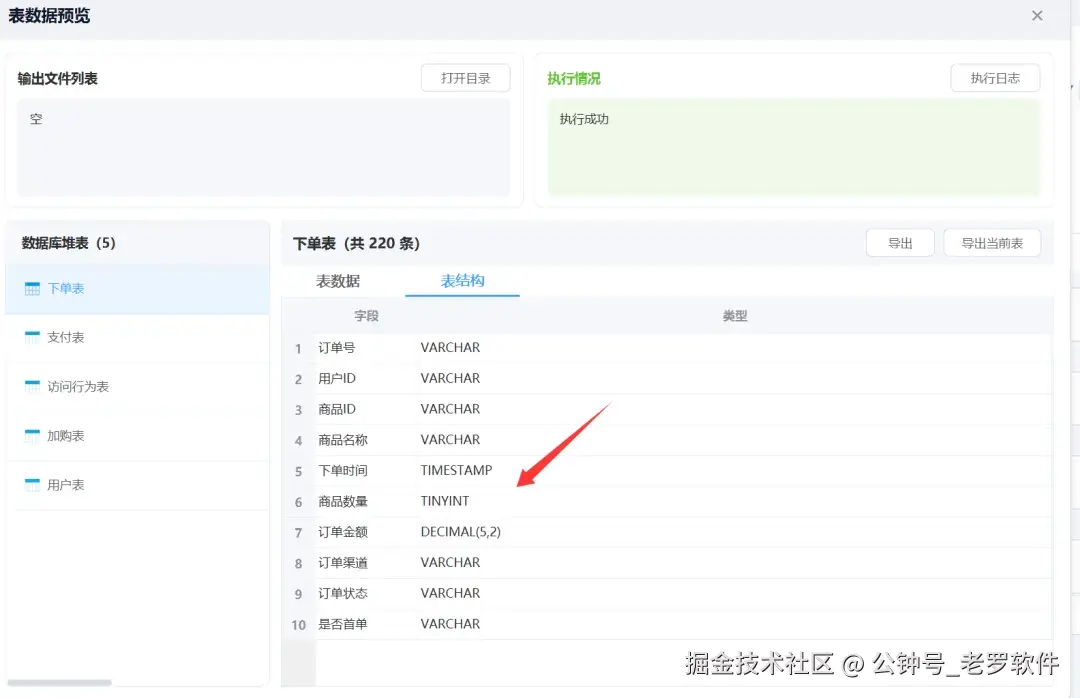
入库后,我们就只需要配置表统计节点就可以了。因为你要统计20个指标,所以要配置20个表统计节点,如图:
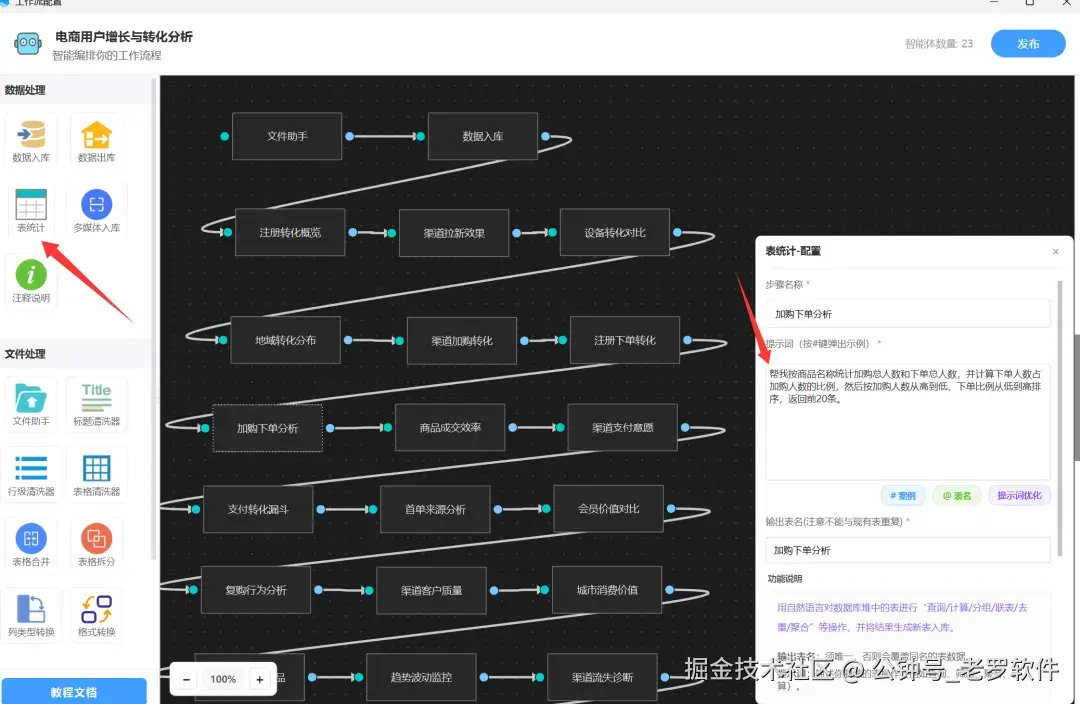
每个节点的关键参数:
-
提示词: 就是你统计的描述。(如果没有显示指明从哪些表进行统计,AI会自动帮你选表)
-
输出表名: 必填的,统计结果会生成一张新表,然后放到数据库里面,供后续继续使用。表名不能重复,否则就会覆盖。
统计节点配置完成后,我们最后添加一个数据出库,将统计结果生成文件,如图:
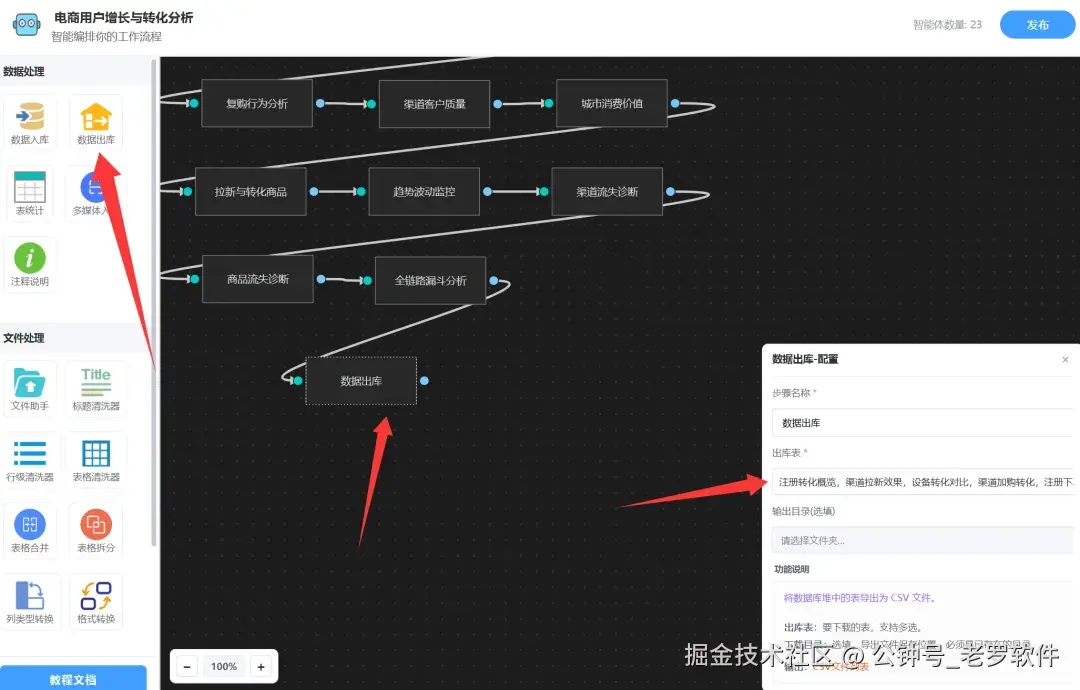
数据出库填一个 出库表的参数, 如果填* 就是所有表,可以下拉选择要下载的表。
工作流配置完成后,点击发布,然后开始执行工作流,打开目录就可以拿到生成的结果文件,下面是预览结果:
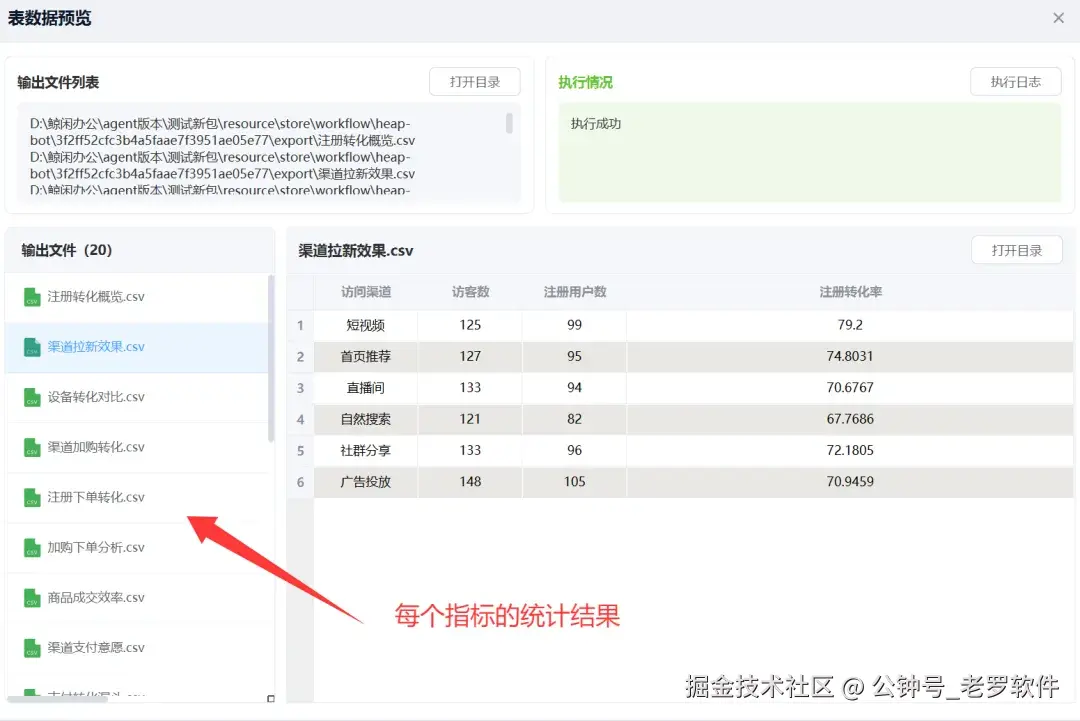
生成的统计表文件:
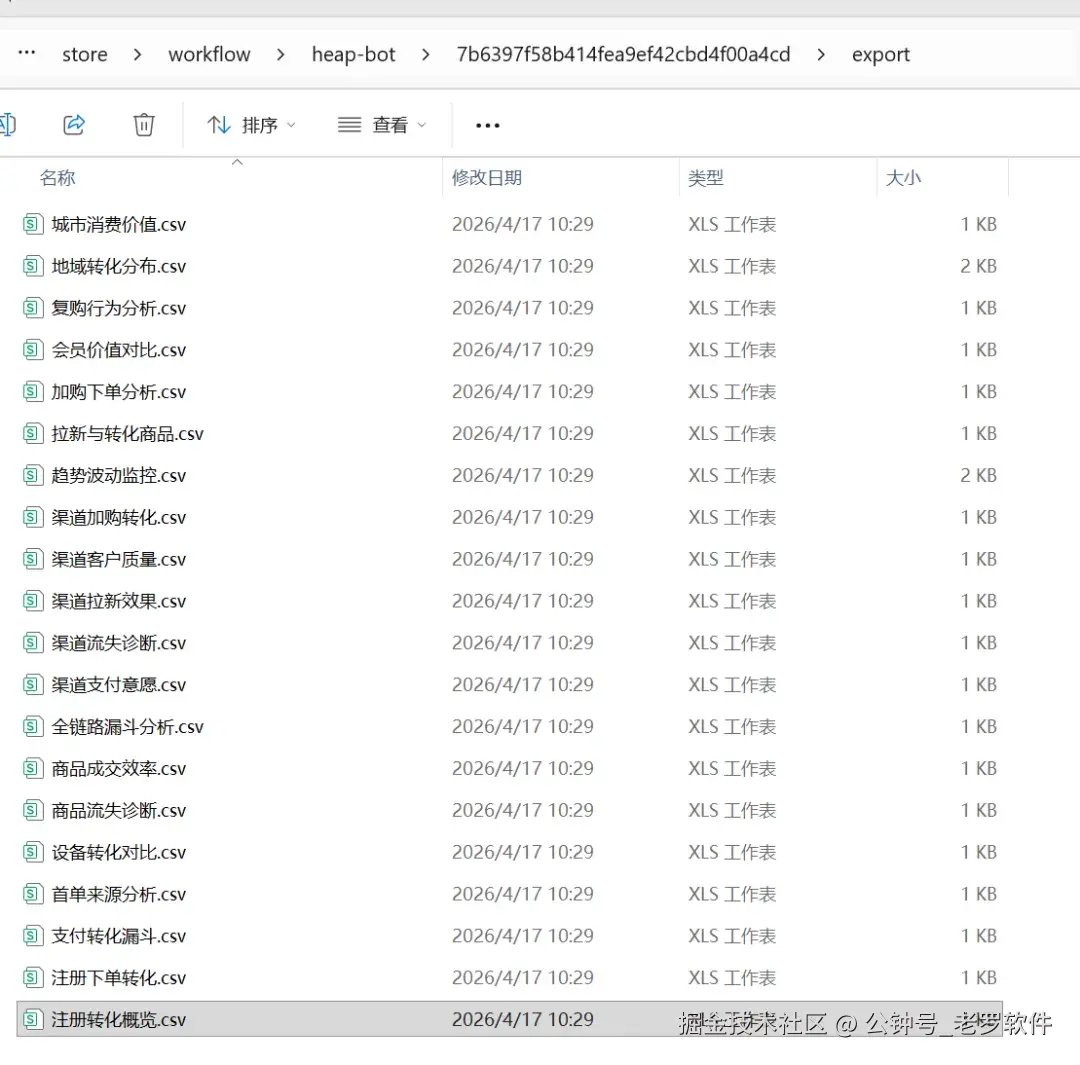
我们来抽取几个查看结果是否准确。
渠道拉新效果
渠道拉新效果:我想知道各个访问渠道带来了多少访客、多少注册用户,哪个渠道拉新效果最好。
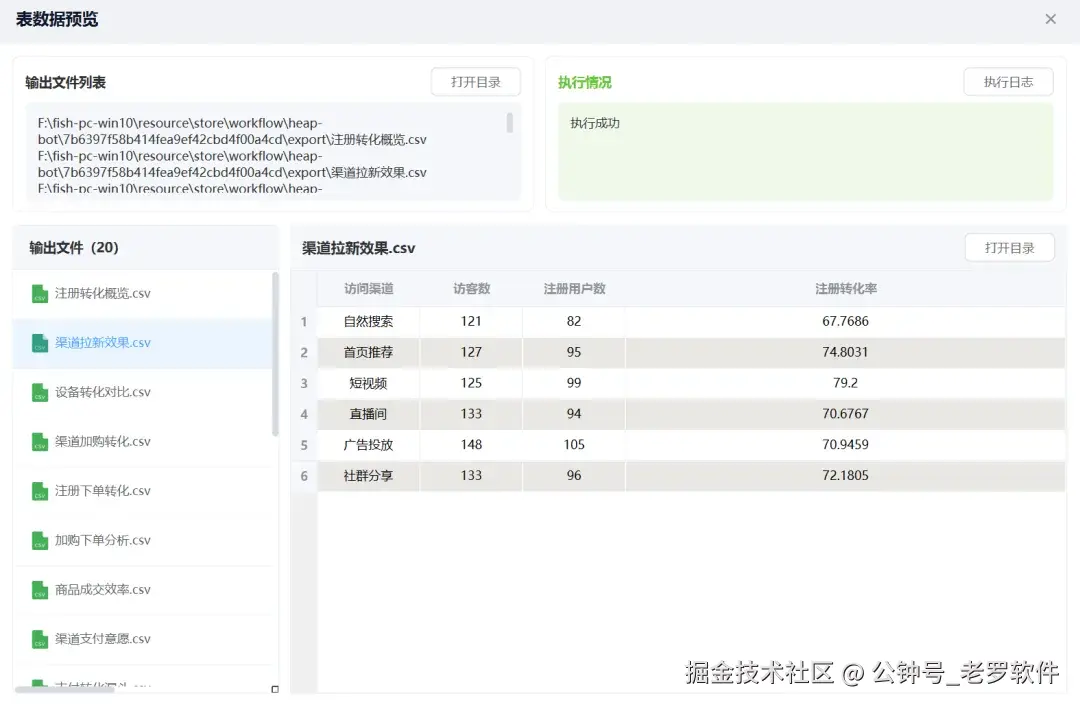
拉新与转化商品
拉新与转化商品:看一下哪些商品最能带来新用户下单,哪些商品更容易让用户直接付钱。
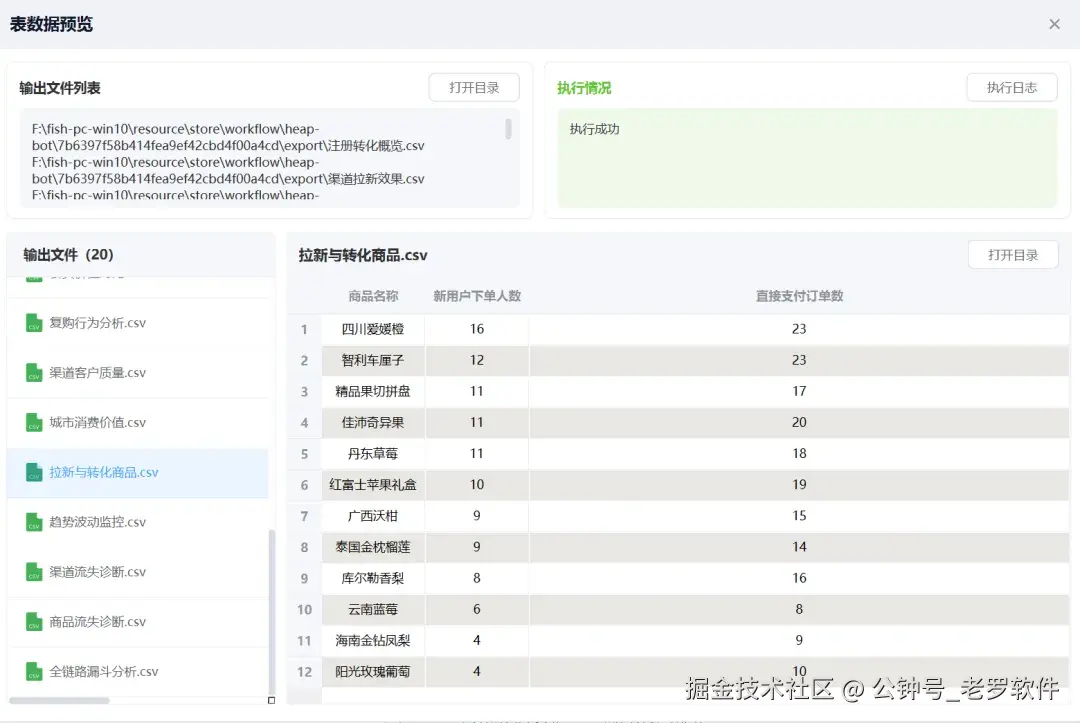
趋势波动监控
趋势波动监控:帮我按时间看一下注册、加购、下单、支付的变化趋势,最近是不是哪里掉下来了。
四、结果回溯
当我们通过 AI 来做报表分析时,一个非常重要的问题是: 用户需要知道自己的提示词到底让系统做了什么。 这就涉及结果回溯能力。表统计智能体不仅会输出最终的统计结果,还可以回溯本次分析对应的结果 SQL,以及整个统计分析的步骤说明,帮助用户看清楚这次分析到底是如何完成的。
比如上面案例的"渠道拉新效果" 指标回溯,如图:
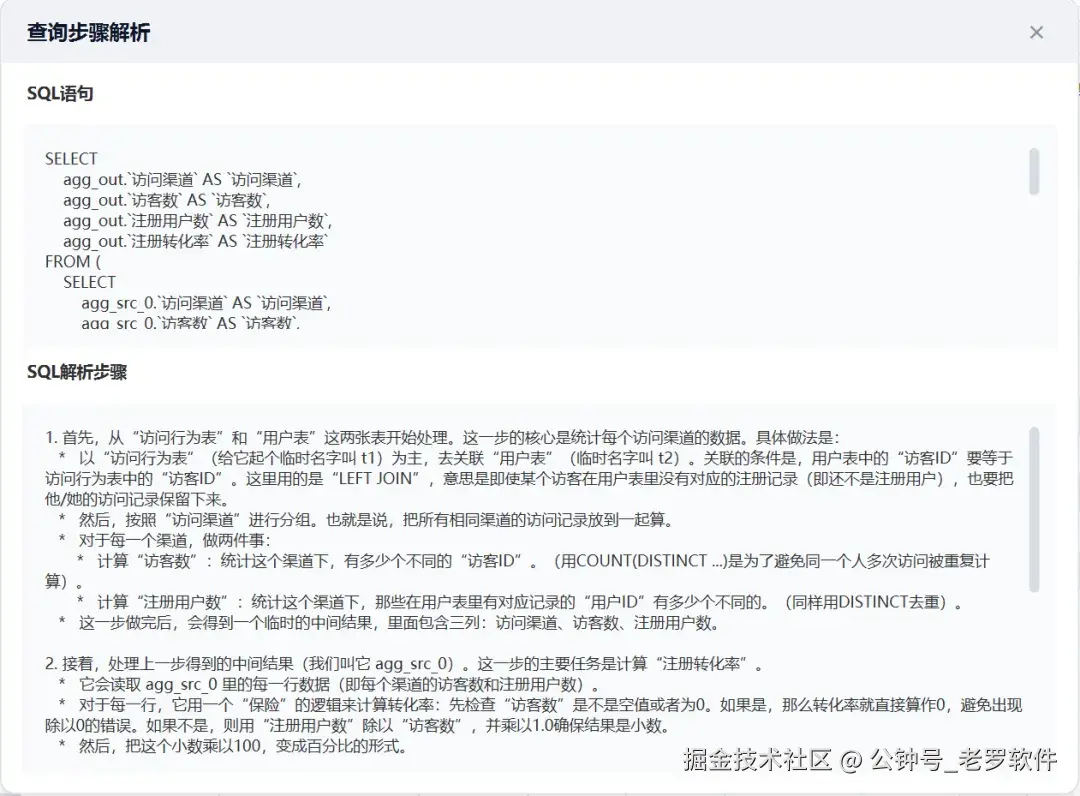
回溯的SQL:
swift
SELECT
agg_out.`访问渠道` AS `访问渠道`,
agg_out.`访客数` AS `访客数`,
agg_out.`注册用户数` AS `注册用户数`,
agg_out.`注册转化率` AS `注册转化率`
FROM (
SELECT
agg_src_0.`访问渠道` AS `访问渠道`,
agg_src_0.`访客数` AS `访客数`,
agg_src_0.`注册用户数` AS `注册用户数`,
ROUND(
(
CASE
WHEN agg_src_0.`访客数` ISNULLOR agg_src_0.`访客数` =0THEN0
ELSE agg_src_0.`注册用户数` *1.0/ agg_src_0.`访客数`
END
) *100,
4
) AS `注册转化率`
FROM (
SELECT
t1.`访问渠道` AS `访问渠道`,
COUNT(DISTINCT t1.`访客ID`) AS `访客数`,
COUNT(DISTINCT t2.`用户ID`) AS `注册用户数`
FROM `访问行为表` t1
LEFTJOIN `用户表` t2 ON t2.`访客ID` = t1.`访客ID`
GROUPBY t1.`访问渠道`
) agg_src_0
) agg_out回溯的统计步骤解析:
markdown
1. 首先,从"访问行为表"和"用户表"这两张表开始处理。这一步的核心是统计每个访问渠道的数据。具体做法是:
* 以"访问行为表"(给它起个临时名字叫 t1)为主,去关联"用户表"(临时名字叫 t2)。关联的条件是,用户表中的"访客ID"要等于访问行为表中的"访客ID"。这里用的是"LEFTJOIN",意思是即使某个访客在用户表里没有对应的注册记录(即还不是注册用户),也要把他/她的访问记录保留下来。
* 然后,按照"访问渠道"进行分组。也就是说,把所有相同渠道的访问记录放到一起算。
* 对于每一个渠道,做两件事:
* 计算"访客数":统计这个渠道下,有多少个不同的"访客ID"。(用COUNT(DISTINCT ...)是为了避免同一个人多次访问被重复计算)。
* 计算"注册用户数":统计这个渠道下,那些在用户表里有对应记录的"用户ID"有多少个不同的。(同样用DISTINCT去重)。
* 这一步做完后,会得到一个临时的中间结果,里面包含三列:访问渠道、访客数、注册用户数。
2. 接着,处理上一步得到的中间结果(我们叫它 agg_src_0)。这一步的主要任务是计算"注册转化率"。
* 它会读取 agg_src_0 里的每一行数据(即每个渠道的访客数和注册用户数)。
* 对于每一行,它用一个"保险"的逻辑来计算转化率:先检查"访客数"是不是空值或者为0。如果是,那么转化率就直接算作0,避免出现除以0的错误。如果不是,则用"注册用户数"除以"访客数",并乘以1.0确保结果是小数。
* 然后,把这个小数乘以100,变成百分比的形式。
* 最后,用 ROUND(..., 4) 把这个百分比结果保留4位小数。
* 这一步完成后,会得到一个新的临时结果,它比上一步多了一列:注册转化率。所以现在有四列:访问渠道、访客数、注册用户数、注册转化率。
3. 最后,处理第二步得到的那个结果(我们叫它 agg_out)。这一步非常简单,就是做最后的"包装"和输出。
* 它从 agg_out 中,原样取出"访问渠道"、"访客数"、"注册用户数"、"注册转化率"这四列数据。
* 这一步没有做新的计算或筛选,只是确保最终输出的列名就是我们想要的。
* 然后,把这些数据作为最终的查询结果返回。
最终结果是什么:
最终查出来的结果是一个列表,展示了每个"访问渠道"(比如可能来自搜索引擎、广告链接、直接访问等)的运营数据。具体包括:这个渠道来了多少独立的访客(访客数),其中有多少人最终完成了注册(注册用户数),以及注册人数占访客人数的百分比(注册转化率,以百分比形式显示并保留四位小数)。这个结果可以帮助分析不同渠道吸引用户和促成注册的效果。五、实现原理
1. 统计任务表达更简单
通过 AI 能力层,原本需要手写 SQL 的统计任务被做了统一收口。用户不需要自己拼接 select 、 join 、 group by 、 having 、 order by ,也不用手动推导聚合层级,只需要直接描述"按什么分组、统计什么、排序规则是什么、是否要关联其它表",系统就可以自动理解需求,并生成对应的统计逻辑。
2. 适合单表和多表场景
这一类表统计能力既能处理单表统计,也能处理多表统计。
如果是一张表,就更偏向于基础汇总、分组统计、排行、占比、趋势等分析;如果是多张表,就会基于表之间的关联关系去做联合统计。
这种模式比直接在原始文件层处理更稳定,因为它面对的是已经清洗并入库后的结构化数据表。
3. 数据列式引擎支持千万级分析
在底层执行层面,采用的并不是传统 MySQL 那种更偏事务处理的行式存储思路,而是更适合分析场景的列式引擎。
列式引擎在分组聚合、条件筛选、排序统计、占比分析这类查询中,只需要重点读取与计算相关的字段列,能够减少不必要的数据扫描,因此在大数据量分析任务中更有优势。
也正因为如此,在单表、多表的统计分析场景下,底层能够更好地支撑千万级数据表的计算需求,让大规模数据分析在执行效率和资源消耗之间取得更稳定的平衡。
4. 兼顾准确性和执行效率
为了让统计结果更稳定,系统在执行前会先对用户提示词进行理解和收口,再生成统计查询逻辑。这样能尽量减少字段引用错误、聚合层级混乱、条件表达不完整等问题。
在执行层面,统计逻辑会直接基于已经入库的数据表完成,而不是重新回到原始大文件里做重复处理。这种方式更适合百万级、千万级数据场景下的分析任务,也更有利于保持统计口径的一致性。
5. 支持结果回溯
在通过 AI 做表统计分析时,最终结果是否可信,不只是看输出表格本身,还要看整个分析过程能不能回溯。
因此,除了最终统计结果之外,系统还会保留本次分析对应的结果 SQL,以及统计步骤分析。这样用户可以进一步查看:自己的提示词最终被系统理解成了什么统计任务、生成了什么查询逻辑、分析过程经过了哪些步骤。
这种结果回溯能力对于校验结果、理解统计口径、排查分析偏差都很重要,也更适合真实业务场景下的数据分析使用。
6. 更容易接入完整工作流
表统计本身处在完整数据处理链路的后半段。前面可以接文件获取、表格清洗、数据入库,后面可以接结果导出、后续分析、图表展示等环节。
也就是说,它更适合被放在一条完整的数据处理流程里使用,而不是单独临时跑一次。这样前面的数据准备和后面的统计分析可以连成一个整体,减少重复操作,也让整个分析过程更清晰。
六、总结
如果您不懂任何编程语言,请按照我文章的教程来试一试,数据表格自动化处理教程。有问题可以联系我,我们一块探讨。