目录
[1 · 字符分类函数](#1 · 字符分类函数)
[2 · 字符转换函数](#2 · 字符转换函数)
[3 · strlen](#3 · strlen)
[4 · strcpy](#4 · strcpy)
[5 · strcat](#5 · strcat)
[6 · strcmp](#6 · strcmp)
[7 · strncpy](#7 · strncpy)
[8 · strncat](#8 · strncat)
[9 · strncmp](#9 · strncmp)
[10 · strstr](#10 · strstr)
[11 · strtok](#11 · strtok)
[12 · strerror](#12 · strerror)
在编程的过程中,我们经常要处理字符和字符串,为了方便操作字符和字符串,C语言标准库中提供了一系列库函数。
1 · 字符分类函数
C语言中有一系列的函数是专门做字符分类的,也就是⼀个字符是属于什么类型的字符的。
这些函数的使用都需要包含⼀个头文件是 ctype.h
如下:

这些函数的使用方法都是类似的,我们随便挑一个来使用一下试试:
cpp
#include <stdio.h>
#include <ctype.h>
int main()
{
char c = 0;
scanf("%c", &c);
if (islower(c))
{
c -= 32;
}
printf("%c\n", c);
}效果是输入一个字符并打印,如果输入的是小写字符则会转换成大写字符再打印:
这里用的是 islower ,判断参数部分是否是小写字母,如果是,则返回一个非0值,如果不是则返回0。
2 · 字符转换函数
C语言提供了两个字符转换函数
int tolower ( int c ); //将参数传进去的⼤写字⺟转⼩写
int toupper ( int c ); //将参数传进去的⼩写字⺟转⼤写这两个函数也需要包含头文件ctype.h 。
那么我们上面写的小写字母转大写就可以这样写:
cpp
#include <stdio.h>
#include <ctype.h>
int main()
{
char c = 0;
scanf("%c", &c);
if (islower(c))
{
c = toupper(c);
}
printf("%c\n", c);
}3 · strlen
strlen 是用来求字符串长度的函数,使用需包含头文件 string.h
原型如下:
cpp
size_t strlen ( const char * str );strlen 会统计传参的字符串中 第一个 '\0' 前的字符个数,并作为返回值返回。(不包含'\0')。
注意:strlen 的返回值是一个无符号的整型数据。
所以 strlen - strlen 的结果也是个无符号数,就算相减得负数,也会被当作一个无符号数,将符号位的 1 当作数值位来计算,结果是大于0的。
下面我们模拟实现一下 strlen :
cpp
#include <stdio.h>
#include <string.h>
#include <assert.h>
int MyStrlen1(const char* str)
{
assert(str);
int count = 0;
while (*(str++))
{
count++;
}
return count;
}
int MyStrlen2(const char* str1)
{
assert(str1);
const char* str2 = str1;
while (*(++str2))
{
;
}
return str2 - str1;
}
int MyStrlen3(const char* str)
{
assert(str);
if (*str == '\0')
{
return 0;
}
else
{
return 1 + MyStrlen3(str + 1);
}
}
int main()
{
printf("%d\n", strlen("abcdef"));
printf("%d\n", MyStrlen1("abcdef"));
printf("%d\n", MyStrlen2("abcdef"));
printf("%d\n", MyStrlen3("abcdef"));
return 0;
}运行一下:

这里我们用了三种方式来模拟,分别是 创建变量计数,指针-指针,递归。
4 · strcpy
strcpy 是用来进行字符串拷贝的 ,使用需包含头文件 string.h
我们可以去官网查查这个函数:

原型如下:
cpp
char * strcpy ( char * destination, const char * source );可以看到,需要两个参数,前一个是目的地,后一个是源头,有返回值,返回值是目标空间的起始地址。
效果是将源头的内容拷贝到目的地中(包括 '\0')。
并且还需要保证 source 的源字符串以 '\0' 结尾, destination 指向的空间比打算拷贝的 源字符串 的空间大。
当然,我们可能还有疑虑,如果我们的目的地已有数据,那么会怎样呢,以及如果目的地的空间不足,又会怎样呢?
我们可以调试看看:
覆盖原字符串:
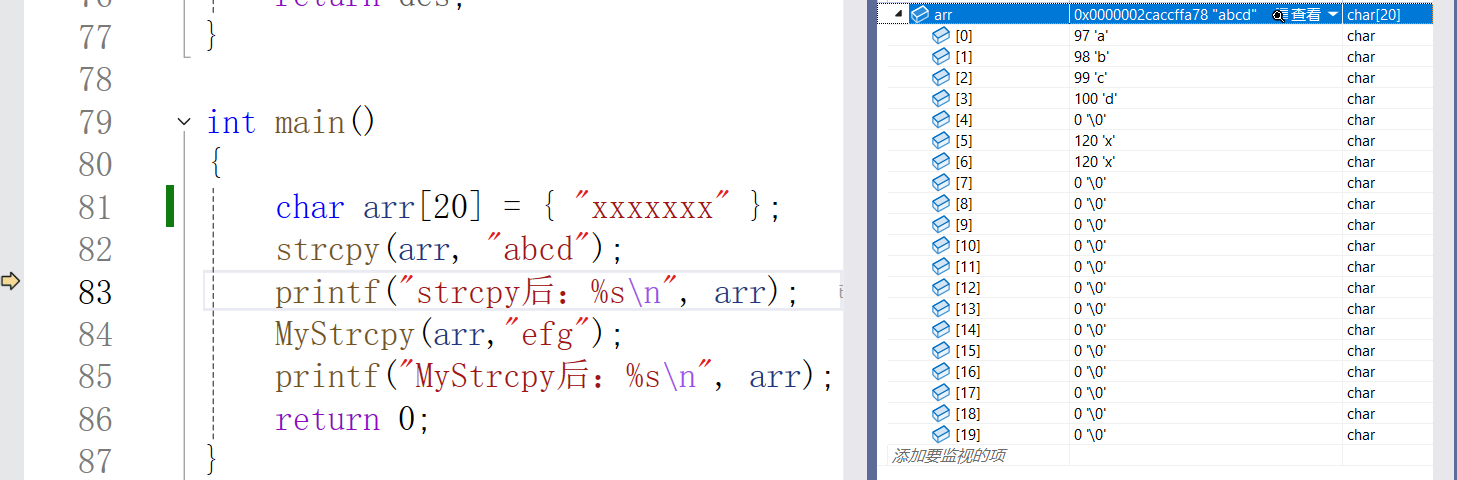
可以看到,如果原本就有数据,并且长于需要拷贝的字符串,那么会覆盖。
目的地不足
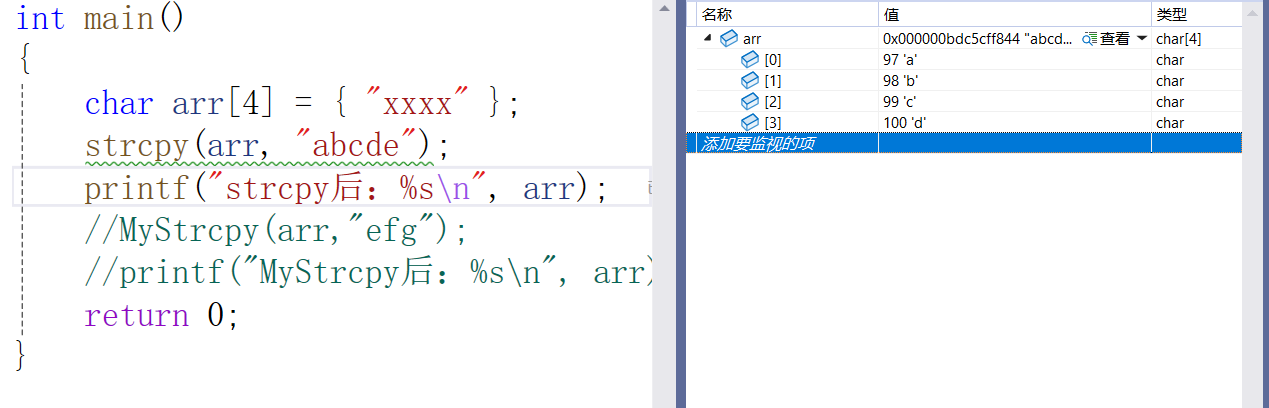
可以看到,依然会一个一个拷贝,并且会越界。
下面我们模拟实现一下:
cpp
#include <stdio.h>
#include <string.h>
#include <assert.h>
char* MyStrcpy(char* des, const char* sou)
{
assert(des);
assert(sou);
char* n = des;
while (*sou)
{
*des = *sou;
des++;
sou++;
}
*des = *sou; //将'\0'进行拷贝
return n;
}
int main()
{
char arr[20] = { "xxxxxxxxxxx"};
strcpy(arr, "abc");
printf("strcpy后:%s\n", arr);
MyStrcpy(arr,"efgh");
printf("MyStrcpy后:%s\n", arr);
return 0;
}MyStrcpy 也可以这样写:
cpp
char* MyStrcpy(char* des, const char* sou)
{
assert(des);
assert(sou);
char* n = des;
while (*des++ = *sou++)
{
;
}
return n;
}运行一下看看:
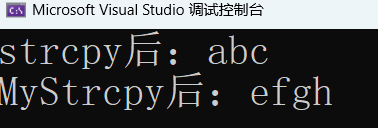
由于strcpy 的返回值是目标空间的起始地址,而我们写的代码中 des 会变化,所以建立了一个变量先存储 des 起始地址,最后返回n 。
5 · strcat
strcat 是用来进行字符串的连接的。使用需包含头文件 string.h
我们可以去官网查查:
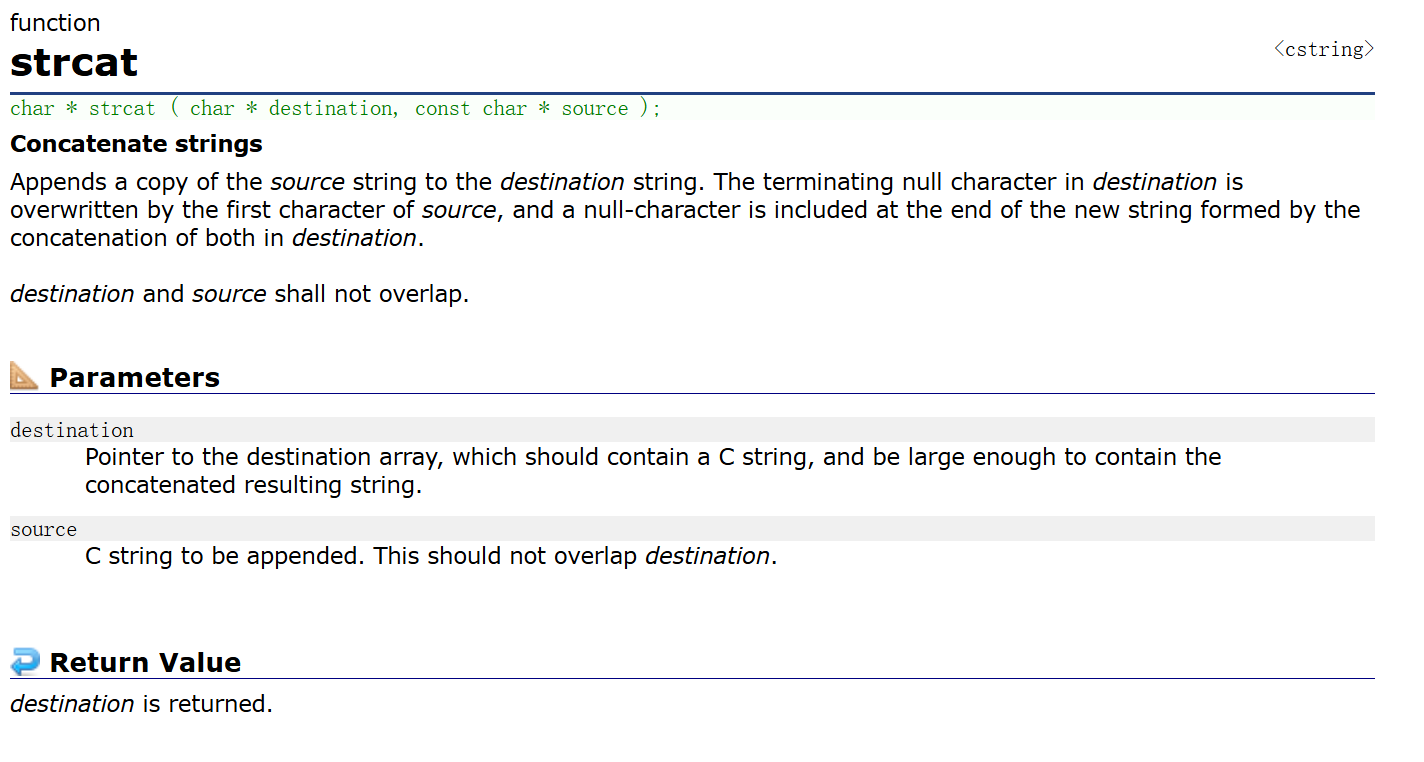
原型如下:
char * strcat ( char * destination, const char * source );可以看到,有两个参数,前一个是目的地,后一个是源字符串,有返回值,返回值是目的地 destination 的首元素地址。
效果是将源字符串接到 目的地字符串的后面,从目的地字符串的 '\0' 开始接(包括'\0')。
注意:
目的地处字符串必须要有 '\0',不然不知道从哪开始接
源字符串也需要有 '\0'
目的地的空间要足够大,能容纳下源字符串
目标空间必须可修改
当然,我们可能还有疑虑 目标空间不够会怎么办 , 能不能多次追加,自己追加自己会怎么样。
目标空间不够其实和 strcpy 差不多,会继续往后接,并且会越界。
多次追加和自己追加自己:
cpp
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[20] = { "abcd" };
char arr2[20] = { "xyz" };
strcat(arr1, "efg");
printf("第一次追加:%s\n", arr1);
strcat(arr1, "efg");
printf("第二次追加:%s\n", arr1);
strcat(arr2, arr2);
printf("自己追加自己:%s\n", arr2);
return 0;
}运行一下看看:

下面我们来模拟实现一下:
cpp
#include <stdio.h>
#include <string.h>
#include <assert.h>
char* MyStrcat(char* des, const char* sou)
{
assert(des);
assert(sou);
char* p = des;
while (*++des)
{
;
}
while (*sou)
{
*des = *sou;
sou++;
des++;
}
return p;
}
int main()
{
char arr1[20] = { "abcd" };
char arr2[20] = { "xyz" };
MyStrcat(arr1, "efg");
printf("第一次追加:%s\n", arr1);
MyStrcat(arr1, "efg");
printf("第二次追加:%s\n", arr1);
//MyStrcat(arr2, arr2);//做不到,会死循环
//printf("自己追加自己:%s\n", arr2);
return 0;
}MyStrcat 也可以写成:
cpp
char *my_strcat(char *des, const char*sou)
{
assert(dest != NULL);
assert(src != NULL);
char *p = des;
while(*des)
{
des++;
}
while((*des++ = *sou++))
{
;
}
return p;
}运行一下看看:

我们写的这个模拟实现能够完成追加另一个字符串的任务,但是无法完成自己追加自己,会死循环。而库函数中的 strcat 是可以做的自己追加自己的。
6 · strcmp
strcmp 是用来进行字符串的比较的,使用需包含头文件 string.h
我们可以去官网查查:

原型如下:
int strcmp ( const char * str1, const char * str2 );从str1 和 str2 的首字符开始比较,如果相同就比较下一个,直到相异或同为 '\0'。
比较的是 ASCII 码值。
第一个字符串大于第二个字符串,返回大于0的数字。
第一个字符串等于第二个字符串,返回0。
第一个字符串小于第二个字符串,返回小于0的数字。
strcmp 我们上一篇中有提到过,下面我们来模拟实现一下:
int MyStrcmp(const char* str1, const char* str2)
{
assert(str1);
assert(str2);
while (*str1 == *str2)
{
if (str1 == '\0')
{
return 0;
}
str1++;
str2++;
}
return *str1 - *str2;
}7 · strncpy
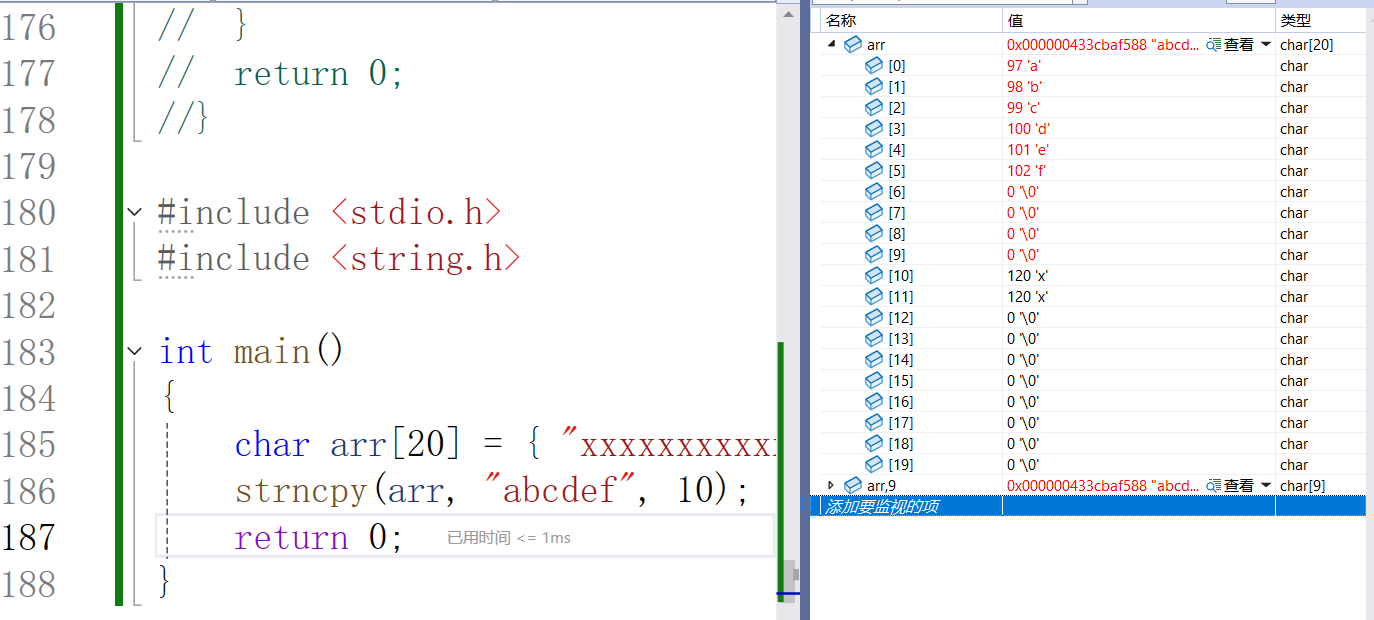
作用和 strcpy 差不多,只是长度受限。使用需包含头文件 string.h
原型如下:
char * strncpy ( char * destination, const char * source, size_t num );从源字符串拷贝num个字符到目标空间。
如果源字符串的长度小于num,则拷贝完源字符串之后,在目标的后边追加''\0',直到num个。
8 · strncat
作用和 strcat 差不多,只是长度受限。使用需包含头文件 string.h
原型如下:
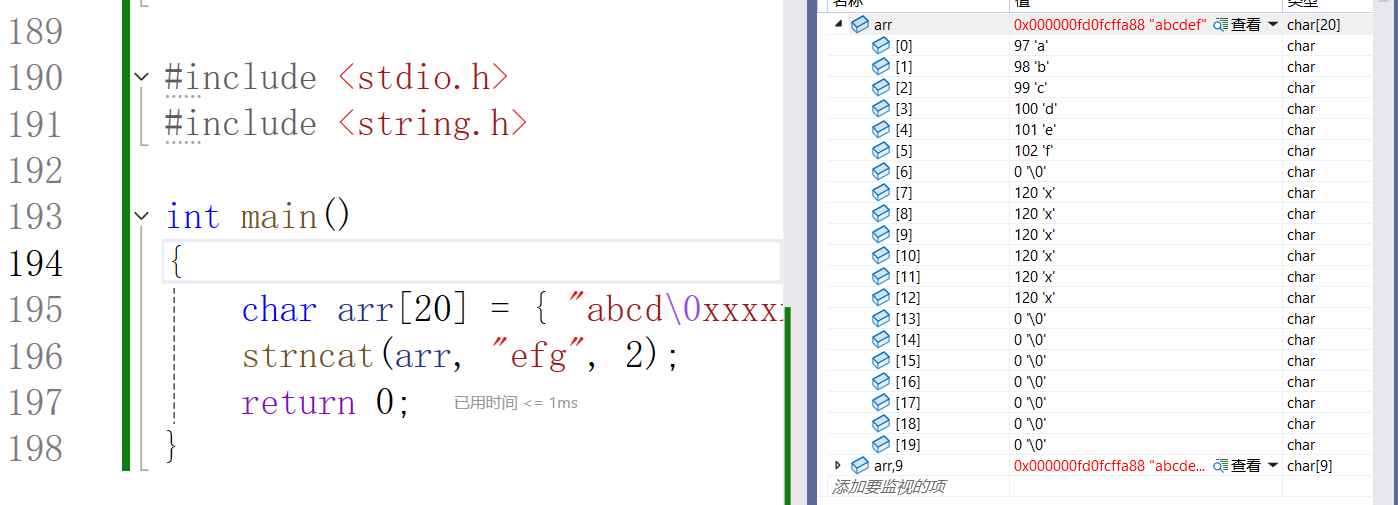
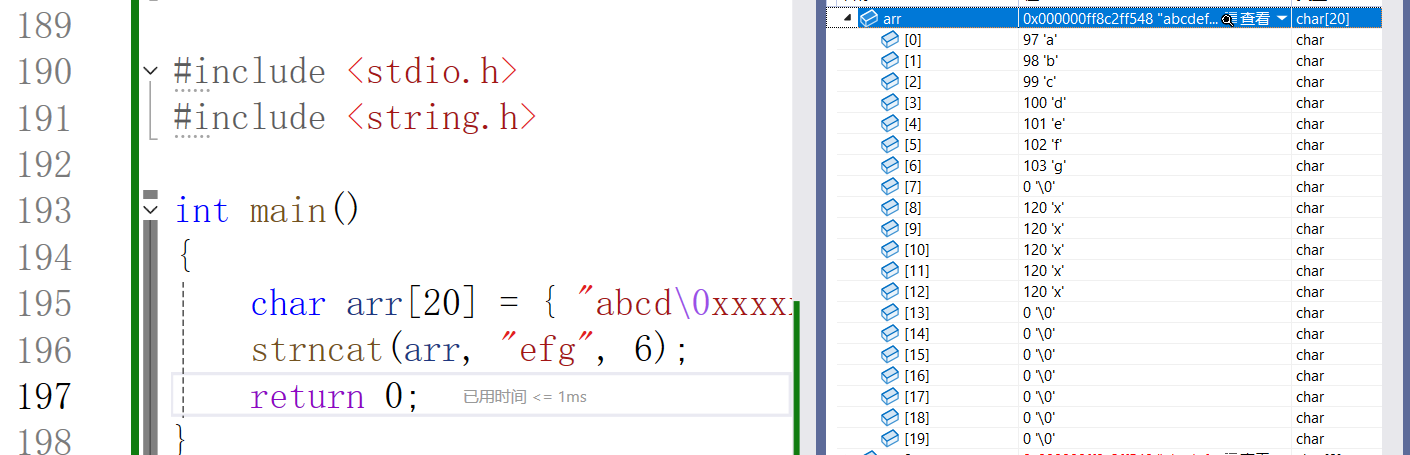
char * strncat ( char * destination, const char * source, size_t num );从 目标字符串的 '\0' 开始(包括'\0'),链接 源字符串中前num个字符,并在结尾补上一个'\0'。
如果源字符串的长度小于num,只会将字符串中到 '\0 '的内容追加到destination指向的字符串末尾。
源字符串长度大于num 为了看是不是函数加上的 '\0' , 我们赋值一个 '\0'
源字符串长度小于 num 的情况:
9 · strncmp
作用和 strcmp 差不多,只是长度受限。使用需包含 string.h
原型如下:
int strncmp ( const char * str1, const char * str2, size_t num );比较str1 和 str2 的前 num 个字符 ,如果相等就往后比较,最多比较num 个字符。如果前num 个字符都相等,则返回0。
10 · strstr
作用是查找字符串。使用需包含头文件 string.h
我们可以去官网查查:

原型如下:
const char * strstr ( const char * str1, const char * str2 );去官网我们会看到有两个原型,但是在 C语言中,只有我们上面的这个原型。
在 str1 字符串中搜索 str2 字符串(不包括 str2 字符串中作为结束的 '\0')
如果找到了,返回 str1 中首次出现str2 的地址,如果没找到,返回NULL。
下面我们模拟实现一下:
cpp
const char* MyStrstr(const char* str1, const char* str2)
{
assert(str1);
assert(str2);
char* tmp = (char*)str1;
char* p1 = (char*)str1;
char* p2 = (char*)str2;
if (!*p2)
{
//如果是str2 是 "\0" 直接返回
return tmp;
}
while (*tmp)
{
p2 = (char*)str2;
if (*tmp == *p2)
{
p1 = tmp;
while (*p2 && *p1)
{
if (*p1 == *p2)
{
p1++;
p2++;
}
else
{
break;
}
if (*p2 == '\0')
{
return tmp;
}
}
}
tmp++;
}
return NULL;
}也可以这样写:
cpp
const char* MyStrstr(const char* str1, const char* str2)
{
assert(str1);
assert(str2);
char* tmp = (char*)str1;
char* p1 = (char*)str1;
char* p2 = (char*)str2;
if (!*p2)
{
//如果是str2 是 "\0" 直接返回
return tmp;
}
while (*tmp)
{
p1 = tmp;
p2 = (char*)str2;
while (*p1 && *p2 && !(*p1-*p2))
{
p1++;
p2++;
}
if (*p2 == '\0')
{
return tmp;
}
tmp++;
}
return NULL;
}由于我们的 str1 和 str2 不可修改,所以我们新建一个变量,用来遍历 str1,再建两个变量用来比较,p1 指向当前遍历的位置 ,p2 指向要查找的字符串的首元素。
如果 *p1 == *p2 ,则让 p1 p2 继续向后比较 相同继续,相异退出本次比较,然后继续遍历,由于我们的 p1 p2 可能发生变化了 所以每次循环要先将p1 p2 置为它们应在的位置。
如果p1 p2 比较过后,p2 为 '\0' 说明找到了,如果遍历完毕后都没有提前返回,说明没有找到,返回NULL。
11 · strtok
作用是提取由分隔符隔开的字符串。使用需包含头文件 string.h
原型如下:
cpp
char * strtok ( char * str, const char * sep);sep参数指向⼀个字符串,定义了用作分隔符的字符集合
第⼀个参数指定⼀个字符串,它包含了0个或者多个由sep字符串中⼀个或者多个分隔符分割的标
记。
比如 "abcd@efg/hij"
这里就包含了被两个分隔符 @ / 分割的三个标记 , abcd efg hij
strtok函数找到str中的下⼀个标记,并将其用 \0 结尾,返回⼀个指向这个标记的指针。(注:
strtok函数会改变被操作的字符串,所以被strtok函数切分的字符串⼀般都是临时拷贝的内容并且
可修改。)
如果 strtok 的第一个参数不为 NULL ,将找到第一个 sep 中的分隔符,并保存这个位置,然后返回这个分隔符前面的 标记字符串的首元素地址。
如果 strtok 的第一个参数为 NULL ,则会从保存的位置开始,继续向后寻找分隔符。
所以我们使用 strtok 时 ,首次使用时,前一个参数需传 str ,后续使用时前一个参数就要传NULL了。
如果字符串中不存在更多标记,则返回 NULL
我们使用一下看看:
cpp
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = { "abcd@efg/hij" };
char arr2[30] = { 0 };
char* p = NULL;
strcpy(arr2, arr1);
p = strtok(arr2, "@/");
printf("%s\n", p);
p = strtok(NULL, "@/");
printf("%s\n", p);
p = strtok(NULL, "@/");
printf("%s\n", p);
return 0;
}运行一下看看:
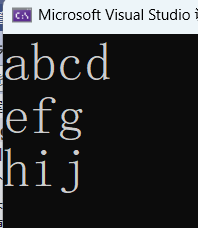
这里我们知道一共有几个分隔符,所以这样写。那如果我们不知道一共有几个分隔符,那就应该这样写:
cpp
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[] = { "abcd@efg/hij" };
char arr2[30] = { 0 };
char* p = NULL;
strcpy(arr2, arr1);
for (p = strtok(arr2, "@/"); p != NULL;p = strtok(NULL,"@/"))
{
printf("%s\n",p);
}
return 0;
}12 · strerror
strerror 函数可以把参数部分错误码对应的错误信息的字符串地址返回来。使用需包含头文件 string.h
原型如下:
cpp
char* strerror ( int errnum );在不同的系统和C语⾔标准库的实现中都规定了⼀些错误码,一般是放在 errno.h 这个头⽂件中说明的,C语言程序启动的时候就会使用一个全局的变量errno来记录程序的当前错误码,只不过程序启动的时候 errno 是0,表示没有错误,当我们在使用标准库中的函数的时候发生了某种错误,就会将对应的错误码,存放在errno中,而一个错误码的数字是整数很难理解是什么意思,所以每⼀个错误码都是有对应的错误信息的。strerror函数就可以将错误对应的错误信息字符串的地址返回。
下面我们可以看看一些错误信息:
cpp
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main()
{
int i = 0;
char* p = NULL;
for (i = 0; i <= 10; i++)
{
p = strerror(i);
printf("%s\n",p);
}
return 0;
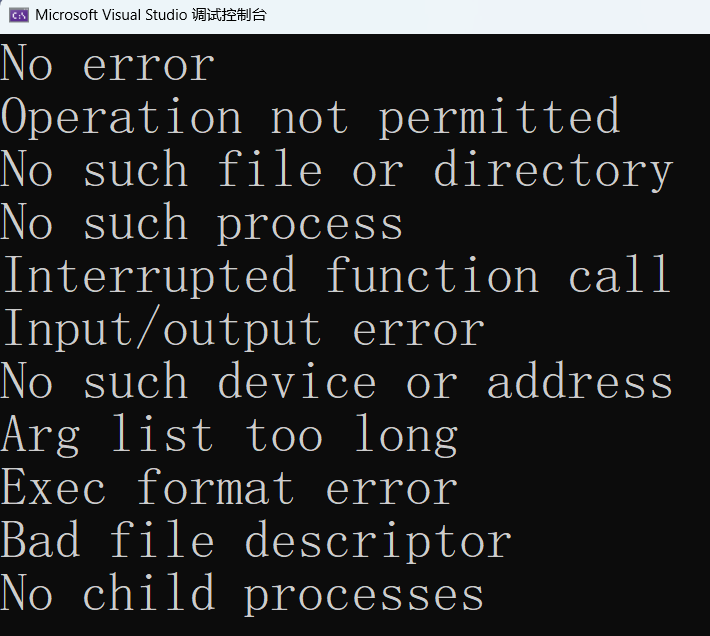
}在 VS2022 运行如下:
下面我们举个栗子:
cpp
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main ()
{
FILE * pFile;
pFile = fopen ("unexist.ent","r");
if (pFile == NULL)
printf ("Error opening file unexist.ent: %s\n", strerror(errno));
return 0;
}运行一下:

我们也可以考虑用 perror 这个函数
perror 函数相当于⼀次将上述代码中的
printf ("Error opening file unexist.ent: %s\n", strerror(errno));
直接将错误信息打印出来。perror函数打印完参数部分的字符串后,再打印⼀个冒号和⼀个空格,再打印错误信息。
cpp
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main()
{
FILE * pFile;
pFile = fopen("unexist.ent", "r");
if (pFile == NULL)
perror("Error opening file unexist.ent");
return 0;
}运行一下:

perror == printf + strerror
想获得错误码就可以用 strerror
想直接打印错误信息就可以用 perror
总结
以上简单介绍了字符和字符串函数相关内容,关于C语言的其余内容,请期待后续更新
以上内容如有错误或不准确之处,欢迎指出,或者你有更好的想法,也欢迎交流。