一、事故现场
凌晨2点,运维系统的告警打破了平静。
�� 【严重告警】服务器内存使用率:83%
�� 【严重告警】服务器内存使用率:97%
�� 【严重告警】服务器内存使用率:100%
从83%到100%,只用了不到10分钟。紧接着内存直接「爆表」------监控显示使用率飙到了500%+。
重启服务后,内存瞬间降了下来。但仅仅过了 3分钟,一切卷土重来。
这台机器上运行着多个组件(应用服务、Nginx、监控Agent等),贸然重启可能导致其他服务受影响。
二、排查思路:先止血,再全面排查
这次OOM和平时遇到的JVM堆内存泄漏不太一样------内存涨得太快,几乎没有渐变过程。
排查原则:先止血,再全面排查,逐项排除,最后聚焦。
2.1 第一步:止血操作
① 从负载均衡摘除问题实例
先让新流量不再进来,保护现场:
在负载均衡控制台/API上将该实例权重设为0
或者修改Nginx upstream配置,注释掉该实例
② 确认问题进程
ps aux | grep java | grep -v grep
root 22753 0.0 0.0 12345678 123456 ? Ssl 02:00 0:00 java -jar app-service.jar
PID:22753,这就是问题进程。
2.2 第二步:系统级全面排查
先确认不是机器本身的问题。
① 磁盘IO是否异常?
iostat -x 1 5
关注:%util(如果接近100%说明磁盘在疯狂读写)、await(IO等待时间是否异常)
实际结果:磁盘IO正常。
② 磁盘空间是否不足?
df -h
实际结果:各分区使用率正常。
③ 网络是否正常?
查看网络连接状态
netstat -an | awk '/^tcp/ {S$NF++} END {for(a in S) print a, Sa}'
查看是否有大量TIME_WAIT
netstat -an | grep TIME_WAIT | wc -l
实际结果:网络连接状态正常,无大量异常连接。
④ MQ是否正常?
以RabbitMQ为例:检查队列堆积情况
rabbitmqctl list_queues name messages messages_ready messages_unacknowledged
实际结果:队列消息数正常,消费者连接正常。
⑤ 数据库是否正常?
检查活跃连接数
mysql -e "show status like 'Threads_connected';"
检查慢查询
mysql -e "show global status like 'Slow_queries';"
实际结果:数据库连接数正常,无异常慢查询。
⑥ Redis集群是否正常?
检查Redis连接数和内存
redis-cli info clients
redis-cli info memory
实际结果:Redis使用正常。
⑦ 当天是否有发版?
查看服务器上的应用启动时间
ps -eo pid,lstart,cmd | grep java
实际结果:当天有发版记录。
2.3 第三步:JVM进程级排查
系统层面没有问题,开始排查JVM进程。
① 查看GC状态
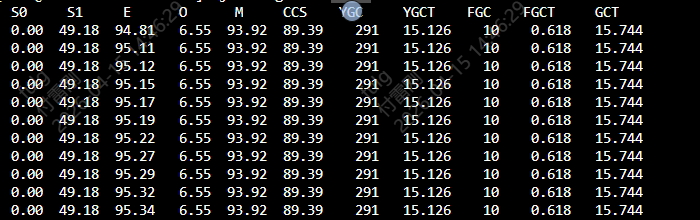
jstat -gcutil 22753 1000
关键指标解读:
|--------------|------------|-------------|----------------|
| 指标 | 含义 | 当前值 | 判断 |
| S0/S1 | Survivor区 | 0% | 正常 |
| E | Eden区 | 100% | Eden区满了 |
| O(Old区) | 老年代 | 93.92% | ⚠️ 老年代几乎满了 |
| M(Metaspace) | 元空间 | 89.39% | ⚠️ 元空间接近上限 |
| FGC | Full GC次数 | 10 | ⚠️ Full GC持续触发 |
| FGCT | Full GC总耗时 | 0.618s | 每次约0.6秒 |
现象分析:
• Old区93.92%接近爆满
• Full GC已经触发10次,但Old区使用率降不下来
• 这不是典型的内存泄漏(泄漏通常FGC次数少但内存一直涨)
• 而是 有大量对象被持续引用,GC无法回收
② 查看线程数
cat /proc/22753/status | grep -E "Threads|VmRSS"
Threads: 1287
VmRSS: 26500000 kB (约25.5GB)
|------------|-------------|-------------|------------|
| 指标 | 正常值 | 实际值 | 判断 |
| 线程数 | 50-100 | 1287 | ⚠️ 暴涨10倍以上 |
| 物理内存 | ~8-10GB | 25.5GB | ⚠️ 严重偏高 |
2.4 第四步:抽丝剥茧------定位阻塞点
① 导出线程栈,分析线程状态
jstack -l 22753 > thread_dump.log
统计各状态线程数量
grep -c "BLOCKED" thread_dump.log
输出:876
grep -c "Waiting on condition" thread_dump.log
输出:321
grep -c "RUNNABLE" thread_dump.log
输出:23
|----------------------|------------|------------|
| 线程状态 | 数量 | 判断 |
| BLOCKED | 876 | ⚠️ 大量线程被阻塞 |
| Waiting on condition | 321 | ⚠️ 大量线程在等待 |
| RUNNABLE | 23 | 正常 |
876个线程处于BLOCKED状态,这太不正常了。
② AI辅助分析线程堆栈
几千行堆栈人工看太费劲。可以借助AI工具分析:
【事故描述】
内存从83%飙升到500%+,10分钟内OOM,重启后3分钟复现
【已有的排查信息】
-
系统层:磁盘IO、网络、MQ、数据库、Redis均正常
-
JVM层:Old区使用率93.92%,Full GC持续触发
-
进程层:线程数1287,BLOCKED线程876个
【请分析】
-
最可能的3个根因方向
-
堆内存爆满但GC回收不掉,最可能的原因是什么?
-
我应该优先验证哪些指标?
AI分析结果直接指向:调用外部服务时无超时设置,导致线程阻塞堆积。
③ 用Arthas实时验证慢调用
连接Arthas
java -jar arthas-boot.jar
select 22753
抓取调用耗时
trace com.xxx.service.NetworkForwardService callVendor '#cost > 100'
如果有大量响应超过100ms的调用,基本确认是外部服务阻塞导致线程堆积。
④ 检查代码,确认根因
// 问题代码
public String callVendor(String param) {
return restTemplate.postForObject(vendorUrl, param, String.class);
}
RestTemplate默认没有设置超时!
三、根因链条
① 服务A 调用 下游厂商服务(走网络隔离转发)
② 代码中没有设置 connectTimeout 和 readTimeout
③ 下游响应慢(网络隔离转发有额外延迟)
④ 请求堆积 → 线程全部BLOCKED
⑤ 线程堆积 → VmRSS从8GB飙到25GB+
⑥ 大量对象被阻塞线程持有引用
⑦ GC无法回收 → Old区爆满 → Full GC频繁触发
⑧ 用户看到页面没反应 → 疯狂刷新重试
⑨ 更多请求堆积 → 内存雪崩 → OOM
⑩ 重启后循环复现
四、解决方案
public String callVendor(String param) {
HttpComponentsClientHttpRequestFactory factory = new HttpComponentsClientHttpRequestFactory();
factory.setConnectTimeout(3000); // 连接超时3秒
factory.setReadTimeout(5000); // 读取超时5秒
factory.setConnectionRequestTimeout(3000); // 请求队列超时3秒
RestTemplate restTemplate = new RestTemplate(factory);
return restTemplate.postForObject(vendorUrl, param, String.class);
}
加上超时之后:
• 请求超过5秒自动断开,不会无限等待
• 线程可以快速释放
• GC能够正常回收对象
• 用户端看到的是明确的超时提示,而不是无限转圈
五、何时可以重启?
只有在以下情况才考虑重启:
|-------------|---------------|
| 条件 | 说明 |
| ✅ 从负载均衡摘除 | 不影响新用户请求 |
| ✅ 已保留排查信息 | jstack、日志等已导出 |
| ✅ 确认重启能解决问题 | 根因已定位并修复 |
重启命令:
优雅停机,等待当前请求处理完
kill -15 22753
或者强制终止(慎用,只有在服务已完全无响应时)
kill -9 22753
六、边缘OOM的全面排查清单
|--------------|--------------------------|------------------------|
| 排查方向 | 命令 | 关键指标 |
| 止血 | 从负载均衡摘除 | 保护现场 |
| 磁盘IO | iostat -x 1 5 | %util > 90% 异常 |
| 磁盘空间 | df -h | Use% > 90% 异常 |
| 网络 | netstat -an | 大量TIME_WAIT/CLOSE_WAIT |
| MQ | rabbitmqctl list_queues | 队列堆积/消费者掉线 |
| 数据库 | show processlist | 连接数暴涨/大量慢查询 |
| Redis | redis-cli info | 连接数/内存/bigkey |
| 发版记录 | ps -eo pid,lstart,cmd | 当天有变更 |
| JVM堆 | jstat -gcutil <pid> | O区/M区使用率、FGC次数 |
| 线程数 | cat /proc/<pid>/status | Threads 远超正常值 |
| 线程栈 | jstack -l <pid> | BLOCKED线程数异常 |
| 慢调用 | arthas trace | 调用耗时 > 阈值 |
七、AI辅助排查prompt模板
遇到类似问题时,这个prompt可以直接用:
【事故描述】
描述你遇到的问题现象,如:内存从83%飙升到100%,10分钟内OOM
【已有的排查信息】
-
系统层:磁盘IO、网络、MQ、数据库、Redis均正常
-
JVM层:Old区使用率93.92%,Full GC持续触发
-
进程层:线程数1287,BLOCKED线程876个
【请分析】
-
最可能的3个根因方向
-
堆内存爆满但GC回收不掉,最可能的原因是什么?
-
我应该优先验证哪些指标?
八、预防措施
|------------|---------------------------|
| 措施 | 具体行动 |
| 超时必须设 | 代码Review检查项,所有HTTP调用必须设超时 |
| 重试要有策略 | 限制重试次数和间隔,避免用户刷新导致雪崩 |
| 线程池监控 | 线程数超过阈值立即告警(如:>500) |
| 内存趋势监控 | 关注Old区使用率和FGC次数变化 |
| 灰度发布 | 新上线先小流量观察,及时回滚 |
| AI辅助排查 | 堆栈和监控数据第一时间发给AI分析方向 |
九、经验总结
这次OOM的特殊之处在于------表面看是内存问题,实际上是线程堆积;表面上要排查JVM,实际上要排查外部依赖。
如果不是按照「止血 → 系统排查 → JVM排查 → 线程分析 → 聚焦根因」的思路,很容易在JVM调优(加大堆、换GC算法)的方向上浪费时间。
建议所有调用外部服务的代码,都加上这三行:
.setConnectTimeout(3000); // 连接超时:3秒
.setReadTimeout(5000); // 读取超时:5秒
.setConnectionRequestTimeout(3000); // 请求队列超时:3秒
泡泡:洛水石