Spring有6种bean作用域,但实际项目中,绝大多数bean只用到其中一种:singleton。
很多开发者写了几年Spring代码,从没显式指定过scope。6种作用域记起来不难,面试时也能背出来,真正有意思的问题是:Spring为什么要提供这6种?每种到底在解决什么问题?
理解这6种作用域的设计逻辑,有一个简单的框架:这个bean需不需要共享实例?如果共享,共享的范围多大?它的生命周期应该跟随谁? 这三个问题想清楚,6种作用域各自的定位就很明确了。
Spring支持6种bean作用域:
- singleton
- prototype
- request
- session
- application
- websocket
前两种是任何Spring应用都能用的基础作用域,中间三种是Web环境专属的,websocket是启用了STOMP消息代理后才会注册的。
这6种作用域不是一次性设计出来的。
Spring 1.0只有singleton和prototype。到了2.0版本,Juergen Hoeller设计了Scope接口作为扩展点,request、session这些Web作用域才有了统一的注册机制。singleton和prototype的处理逻辑写死在容器的getBean()方法里,其余4种都是通过Scope SPI注册上去的。
以下源码分析基于Spring Framework 6.0。
绝大多数bean只需要一个实例
日常写的Service、Repository、Controller,都是无状态的。方法接收参数,处理逻辑,返回结果,不在对象内部保存请求间的数据。这类对象,整个应用里有一个实例就够了。
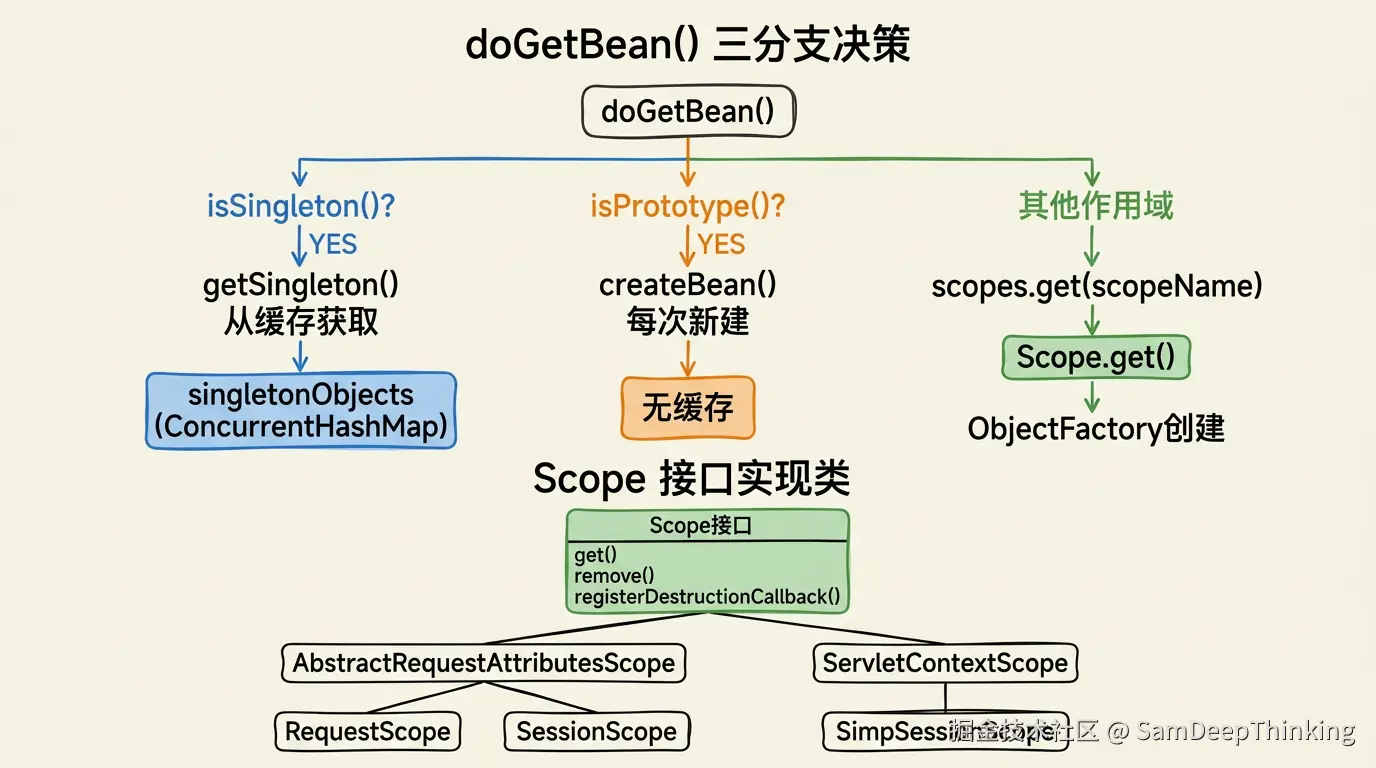
Spring把singleton设为默认作用域。在@Bean或@Component上不指定scope,容器创建出来的就是singleton bean。看AbstractBeanFactory的doGetBean()方法,singleton的处理分支:
scss
if (mbd.isSingleton()) {
sharedInstance = getSingleton(beanName, () -> {
try {
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
destroySingleton(beanName);
throw ex;
}
});
beanInstance = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}getSingleton()内部会先检查缓存,缓存命中就直接返回,没命中才调用ObjectFactory创建。这个缓存定义在DefaultSingletonBeanRegistry里:
typescript
// bean名称到bean实例的映射
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);一个ConcurrentHashMap,以bean名称为key,bean实例为value。Rod Johnson在设计Spring时的一个核心判断是:大部分业务对象都是无状态的服务对象,为它们各自维护一个共享实例是最高效的策略。复用同一个实例,避免重复创建对象的开销,减少GC压力,依赖注入也只需要执行一次。
这里有一个概念需要澄清。Spring的singleton和设计模式里的单例模式不是一回事。 设计模式里的单例是每个ClassLoader保证一个类只有一个实例。Spring的singleton是容器级别、bean定义级别的:同一个类可以注册多个bean定义(比如不同的名字),每个bean定义在同一个容器里各有一个实例。它是容器层面的缓存策略,不是类层面的实例化限制。
当bean需要保存状态
实际项目中,singleton覆盖了绝大多数场景。Service、Repository、Controller基本都是无状态的,开发者从头到尾不需要操心作用域的问题。prototype在项目中的出场率很低,很多团队整个应用写完都没显式用过一次。
prototype存在的价值体现在一类特定场景:bean在处理过程中需要在对象内部保存中间状态。
举个例子:一个报表生成器,在生成过程中需要在对象内部记录当前处理到哪一行、累计的统计值是多少。如果这个bean是singleton,两个线程同时生成不同的报表,它们操作的是同一个对象,状态会互相覆盖。这种Bug在单线程测试时不会出现,上了并发环境才暴露。
prototype作用域就是为这类场景准备的。标记为prototype的bean,每次从容器获取时都创建一个全新的实例。doGetBean()中prototype的处理分支:
ini
else if (mbd.isPrototype()) {
Object prototypeInstance = null;
try {
beforePrototypeCreation(beanName);
prototypeInstance = createBean(beanName, mbd, args);
}
finally {
afterPrototypeCreation(beanName);
}
beanInstance = getObjectForBeanInstance(prototypeInstance, name, beanName, mbd);
}没有任何缓存逻辑,每次都走createBean()。
prototype有一个容易被忽略的特性:Spring不管理prototype bean的销毁。 源码在AbstractBeanFactory的registerDisposableBeanIfNecessary方法里:
scss
if (!mbd.isPrototype() && requiresDestruction(bean, mbd)) {第一个条件就是!mbd.isPrototype(),prototype直接跳过销毁注册。即使在prototype bean上定义了@PreDestroy方法,Spring也不会调用它。
这不是遗漏,是有意的设计。 容器无法追踪所有prototype实例的引用,它不知道使用方把这个实例传给了谁、存到了哪里、什么时候不再需要。如果容器为了调用销毁回调而持有所有prototype实例的引用,这些实例就永远无法被GC回收,反而会导致内存泄漏。prototype bean的生命周期只管创建,不管销毁,清理工作由使用方自己承担。
如果prototype bean持有数据库连接、文件句柄这类需要显式释放的资源,用完后必须手动关闭。
遇到需要状态隔离的场景,先评估一下这个状态是不是真的需要放在bean的成员变量里。很多时候把状态封装成方法参数传递,或者直接new一个普通对象(不交给Spring管理),比配置prototype作用域更简单。prototype更适合那些确实需要Spring帮你做依赖注入、AOP增强、初始化回调的有状态对象。
prototype注入singleton的陷阱
prototype解决了状态隔离的问题,但在实际使用中有一个几乎每个Spring开发者都会踩的坑。
场景是这样的:定义一个prototype的bean,用@Autowired把它注入到singleton的Controller里,期望每次请求进来都能拿到一个新的prototype实例。
kotlin
@Component
@Scope("prototype")
public class OrderProcessor {
private String currentOrderId;
}
@RestController
public class OrderController {
@Autowired
private OrderProcessor processor;
@PostMapping("/order")
public void handle() {
// 期望每次请求拿到新的processor
// 实际上每次都是同一个
processor.process();
}
}这段代码的问题在于:singleton的Controller只初始化一次,@Autowired注入也只执行一次。注入的那个prototype实例会一直被Controller持有,后续所有请求用的都是同一个对象。prototype的作用域在这里形同虚设。
代码层面完全看不出问题。@Autowired注入prototype bean的写法和注入singleton bean一模一样,行为上的差异在运行时才体现。
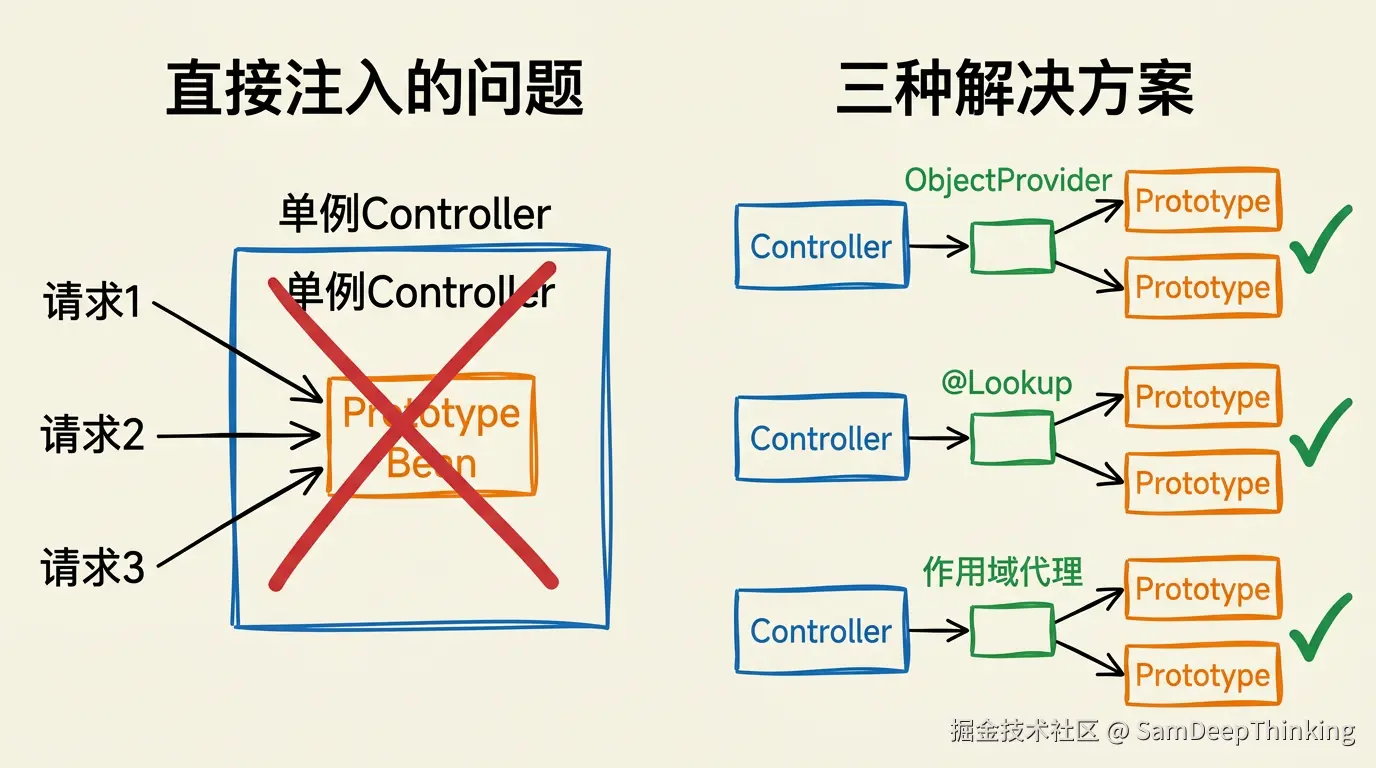
解决这个问题有三种方案。
ObjectProvider
Spring 4.3引入的接口。注入的不是bean本身,而是一个获取bean的入口。每次调用getObject()时,如果目标bean是prototype,Spring会创建新实例。
java
@RestController
public class OrderController {
@Autowired
private ObjectProvider<OrderProcessor> processorProvider;
@PostMapping("/order")
public void handle() {
// 每次调用getObject()都拿到新实例
OrderProcessor processor = processorProvider.getObject();
processor.process();
}
}ObjectProvider还支持getIfAvailable()、getIfUnique()等方法,比直接注入bean多了一层灵活性。日常开发中这是最推荐的方案,侵入性小,用法直观。
@Lookup
标注在方法上,Spring通过CGLIB生成当前类的子类,覆盖这个方法。每次调用该方法时,实际执行的是CGLIB生成的代码,委托给BeanFactory.getBean()获取新实例。
typescript
@Component
public class OrderController {
@Lookup
protected OrderProcessor createProcessor() {
// 这个方法体会被CGLIB覆盖,返回值不重要
return null;
}
public void handle() {
OrderProcessor processor = createProcessor();
processor.process();
}
}@Lookup要求类不能是final的(CGLIB需要生成子类),方法可以有具体实现,Spring会覆盖掉。
作用域代理
在@Scope注解上设置proxyMode为TARGET_CLASS,Spring会创建一个CGLIB代理对象注入到singleton中。代理对象本身的生命周期是singleton的,但每次调用它的方法时,代理会去对应的Scope里获取真实的bean实例。
less
@Component
@Scope(value = "prototype", proxyMode = ScopedProxyMode.TARGET_CLASS)
public class OrderProcessor {
}这种方式对调用方完全透明,不需要改Controller的代码。后面介绍Web作用域时会看到,@RequestScope、@SessionScope这些注解默认就开启了TARGET_CLASS代理,因为Web作用域的bean几乎一定会注入到singleton的Controller里。
三种方案放在一起对比:
| 方案 | 对调用方透明 | 侵入性 | 限制条件 | 推荐场景 |
|---|---|---|---|---|
| ObjectProvider | 否,需改注入方式 | 低 | 无 | 日常开发首选 |
| @Lookup | 否,需调用工厂方法 | 中 | 类不能是final | 适合抽象类或模板方法场景 |
| 作用域代理 | 是,调用方无感知 | 低 | CGLIB代理的固有限制 | Web作用域的默认方式 |
Web环境的三种作用域
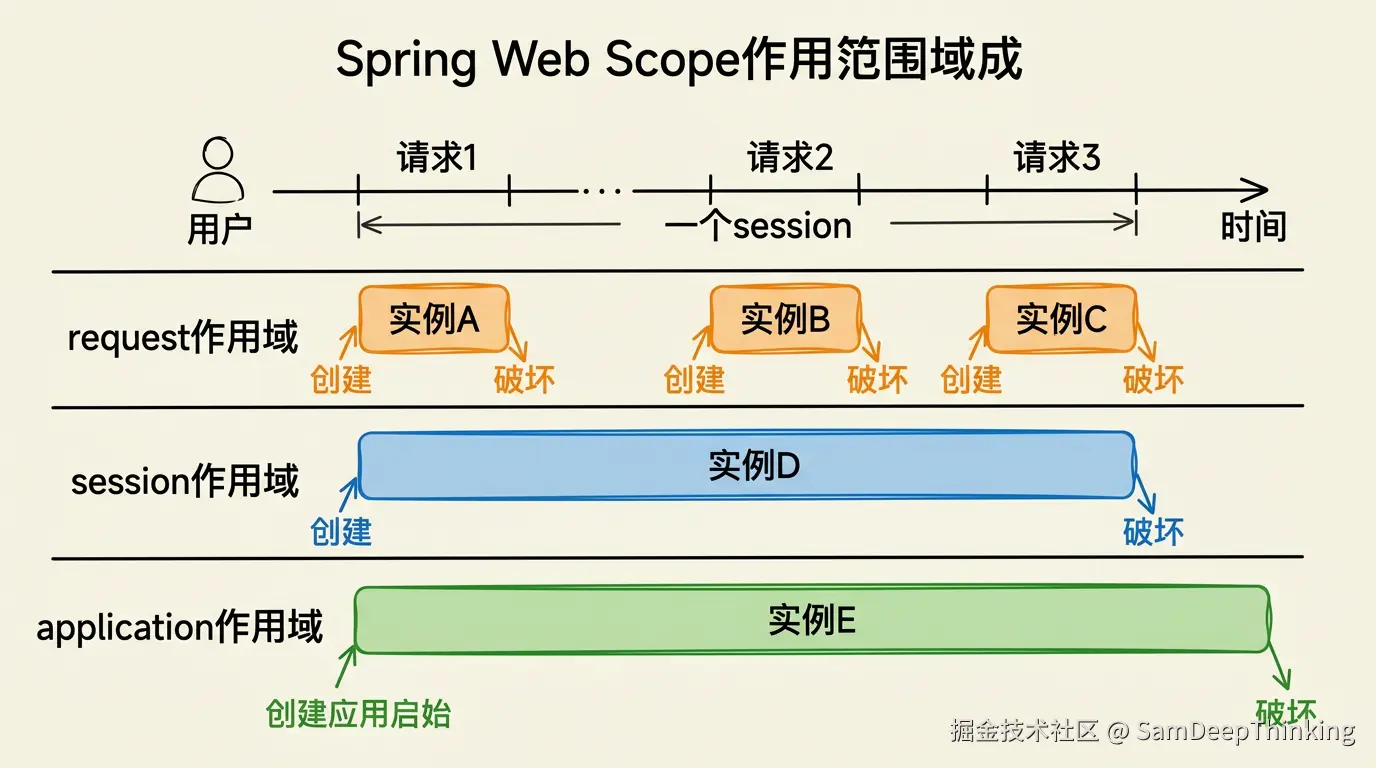
singleton和prototype覆盖了「是否共享实例」这个维度的两个极端:要么全局一份,要么每次新建。Web应用的需求在两者之间:同一个请求内的多个组件需要共享某些数据,但不同请求之间这些数据必须隔离;同一个用户的多次请求之间需要保持会话状态,但不同用户之间必须隔离。回到前面那三个问题:共享范围多大?生命周期跟随谁?request、session、application三种作用域分别给出了不同粒度的回答。
Spring 2.0在引入Scope SPI的同时,提供了request和session两种Web作用域的实现。application作用域在后续版本加入。Web作用域的注册发生在WebApplicationContextUtils.registerWebApplicationScopes()方法里:
ini
beanFactory.registerScope(WebApplicationContext.SCOPE_REQUEST, new RequestScope());
beanFactory.registerScope(WebApplicationContext.SCOPE_SESSION, new SessionScope());
if (sc != null) {
ServletContextScope appScope = new ServletContextScope(sc);
beanFactory.registerScope(WebApplicationContext.SCOPE_APPLICATION, appScope);
}只有在Web环境的ApplicationContext中,这三个Scope才会被注册。在普通的ApplicationContext里使用@RequestScope会报错:No Scope registered for scope name 'request'。
request作用域把bean的生命周期绑定到单个HTTP请求。bean在当前请求第一次使用时创建,请求处理结束后销毁。底层实现是RequestScope,继承自AbstractRequestAttributesScope,bean实际存储在HttpServletRequest的attribute里。
使用场景比如:请求级别的审计日志收集器,在请求处理的各个环节往里面写数据,请求结束后统一持久化。或者每次请求需要独立初始化的验证器。Spring 4.3提供了@RequestScope注解,等价于@Scope(value = "request", proxyMode = ScopedProxyMode.TARGET_CLASS)。注意它默认就开启了CGLIB代理,原因和前面说的一样:request作用域的bean大概率会注入到singleton的Controller里。
session作用域把bean的生命周期绑定到HTTP Session。同一个用户的多次请求间共享同一个实例,Session过期或失效后bean被销毁。
典型场景:购物车、用户偏好设置、多步骤表单的临时状态。不过在微服务架构下,session作用域用得越来越少。应用通常是无状态部署的,会话数据放在Redis这类外部存储里,不依赖本地HTTP Session。session作用域更多出现在单体应用或传统Spring MVC项目中。
SessionScope的实现有一个值得注意的细节:它的get()和remove()方法都加了synchronized。看源码:
typescript
@Override
public Object get(String name, ObjectFactory<?> objectFactory) {
Object mutex = RequestContextHolder.currentRequestAttributes().getSessionMutex();
synchronized (mutex) {
return super.get(name, objectFactory);
}
}为什么需要同步?因为同一个用户可能同时发送多个请求(比如页面里有多个Ajax调用),这些请求在服务端由不同线程处理,但共享同一个Session。如果不加锁,两个线程可能同时判断session作用域的bean不存在,然后各创建一个,导致同一个session里出现两个实例。
RequestScope没有这个同步逻辑,因为在传统Servlet模型下,一个HTTP请求只在一个线程里处理。
application作用域把bean的生命周期绑定到ServletContext。整个Web应用共享一个实例。ServletContextScope的get()方法直接调用servletContext.getAttribute()和servletContext.setAttribute()来存取bean。
application和singleton的区别
application作用域经常被问到的一个问题是:它和singleton有什么区别?
在Spring Boot应用里,大多数情况下两者表现确实一样,因为通常只有一个ApplicationContext。具体区别如下:
| 维度 | singleton | application |
|---|---|---|
| 作用范围 | per-ApplicationContext | per-ServletContext |
| 存储位置 | BeanFactory内部的ConcurrentHashMap | ServletContext的attribute |
| 可见性 | 仅Spring容器内部可访问 | 同一ServletContext下的其他Servlet也可见 |
| 销毁时机 | ApplicationContext关闭时 | ServletContext销毁时(依赖ContextCleanupListener) |
在传统Spring MVC部署方式下,一个应用可能有多个ApplicationContext:ContextLoaderListener创建的根容器和每个DispatcherServlet创建的子容器。singleton bean在父子容器中各有一份(如果各自定义了的话),而application作用域的bean在整个ServletContext里只有一份。
Spring Boot的内嵌容器模式下,一个应用只有一个ApplicationContext和一个ServletContext,上面这些差异基本感知不到。在war包部署到外部Tomcat、且应用内有父子容器配置时,这些区别才会体现出来。
Scope SPI和自定义作用域
除了上面5种,Spring还有websocket作用域,由SimpSessionScope实现,bean的生命周期绑定到WebSocket会话。启用@EnableWebSocketMessageBroker后自动注册,逻辑和session作用域类似,这里不展开。
6种内置作用域之外,Spring允许通过Scope SPI注册自定义作用域。Scope接口在Spring 2.0由Juergen Hoeller设计引入,定义了5个方法:
arduino
public interface Scope {
Object get(String name, ObjectFactory<?> objectFactory);
Object remove(String name);
void registerDestructionCallback(String name, Runnable callback);
Object resolveContextualObject(String key);
String getConversationId();
}其中get()是核心,负责从作用域中获取对象,不存在时用objectFactory创建。remove()移除对象,registerDestructionCallback()注册销毁回调,resolveContextualObject()解析上下文对象(比如HttpServletRequest),getConversationId()返回当前会话标识。只有get()是必须实现的,其余方法可以返回null。
Scope接口的Javadoc里有一句话值得注意:虽然主要用在Web环境的扩展作用域,但这个SPI是完全通用的,可以从任何底层存储机制中获取和存放对象。
容器在doGetBean()中处理自定义Scope的逻辑也在这个方法里。核心流程是:从scopes这个LinkedHashMap<String, Scope>里按scopeName查找对应的Scope实现,调用scope.get()获取bean。Scope内部已有该bean的实例就直接返回,没有就用传入的ObjectFactory创建。如果scopeName没有对应的Scope注册,直接抛IllegalStateException。
注册自定义Scope有两种方式:编程式调用ConfigurableBeanFactory.registerScope(),或者通过CustomScopeConfigurer这个BeanFactoryPostProcessor来声明式注册。
Spring自身提供了两个未默认注册的Scope实现,在特定场景下有用:SimpleThreadScope,用ThreadLocal存储,每个线程一个bean实例;SimpleTransactionScope,每个事务一个bean实例,绑定在TransactionSynchronizationManager上。可以按需注册使用。
6种作用域速查对比
| 作用域 | 实例数量 | 生命周期 | Spring管理销毁 | 线程安全 | 典型场景 | 引入版本 |
|---|---|---|---|---|---|---|
| singleton | 每个容器一个 | 跟随ApplicationContext | 是 | 开发者保证(无状态则无需关心) | Service、Repository、Controller | 1.0 |
| prototype | 每次获取一个新实例 | 不受Spring管理 | 否 | 每个调用方独享 | 有状态对象、非线程安全的工具类 | 1.0 |
| request | 每个HTTP请求一个 | 跟随HTTP请求 | 是 | 单请求单线程(传统Servlet模型) | 请求级上下文、审计收集 | 2.0 |
| session | 每个HTTP Session一个 | 跟随HTTP Session | 是 | SessionScope内部synchronized | 购物车、用户偏好、多步骤表单 | 2.0 |
| application | 每个ServletContext一个 | 跟随ServletContext | 是 | 开发者保证 | 全局配置缓存、共享计数器 | 3.0 |
| websocket | 每个WebSocket会话一个 | 跟随WebSocket Session | 是 | SimpSessionScope内部同步 | WebSocket会话状态 | 4.1 |
选择标准:不指定scope的情况下默认就是singleton,90%以上的bean用它够了。需要状态隔离时,先考虑能不能把状态移出bean(比如放到方法参数或ThreadLocal里),避免引入不必要的作用域。Web环境下需要跟随请求或会话生命周期的数据,用request或session作用域,记得配合作用域代理使用。
小结
Spring的作用域设计有一个务实的演进过程。1.0版本只有singleton和prototype,覆盖了无状态和有状态两大类场景。到了2.0,Web应用的需求越来越多样,Juergen Hoeller没有把request、session这些作用域硬编码进容器,而是设计了通用的Scope SPI,让Web作用域以插件的形式注册进来。容器只硬编码最基础的、所有环境都需要的东西,其余通过SPI扩展。 后来的application、websocket、以及各种自定义作用域,都受益于这个设计。
实际项目中,作用域选错了不会编译报错,而是在并发场景下出数据错乱的Bug,排查成本很高。我的建议是:默认用singleton,碰到需要状态隔离的场景先审视一下这个状态是不是真的需要放在bean里。很多时候把状态放到方法参数里传递,或者用ThreadLocal隔离,比切换作用域更干净。prototype和Web作用域是工具箱里该有的东西,但不该成为第一选择。
希望这篇内容可以帮到你。
我最近在知乎写了一个秒杀专栏(应付6000万会员级别的)和开了星球,有兴趣的可以订阅和加入,一起交流。
- 知乎账号:SamDeepThinking
- 星球:老码头的技术浮生录