Mysql-MHA高可用集群
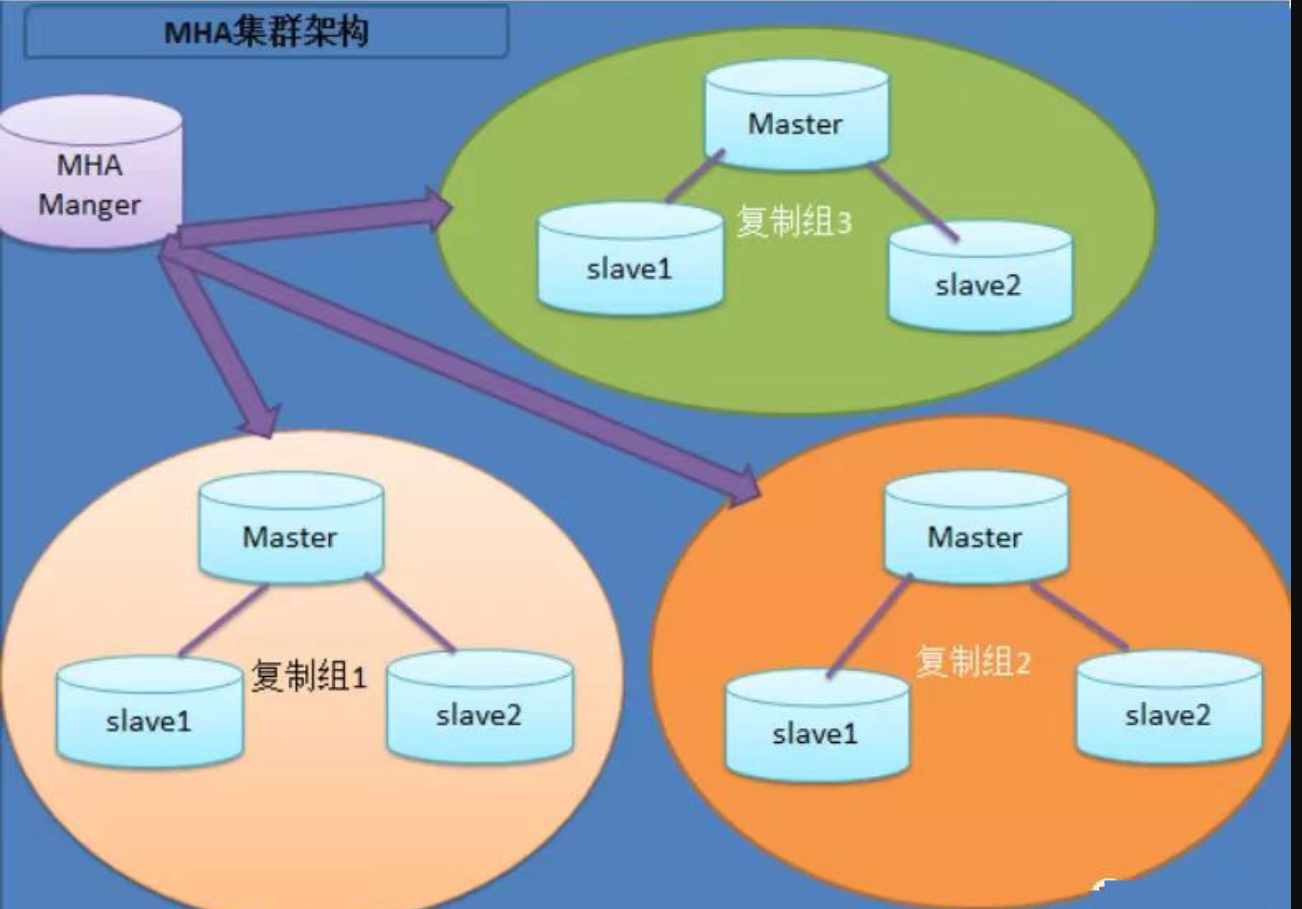
搭建一主两从架构
目标:配置 1 个主库(10)和 2 个从库(20、30),开启 GTID 和半同步复制
# ========== Master 节点(172.25.254.10)配置 ==========
# 停止 MySQL 服务
[root@mysql-node10 ~]# /etc/init.d/mysqld stop
# 清空数据目录(全新初始化,删除旧数据)
[root@mysql-node10 ~]# rm -fr /data/mysql/*
# 编辑 MySQL 配置文件
[root@mysql-node10 ~]# vim /etc/my.cnf
[mysqld]
datadir=/data/mysql # 数据目录
socket=/data/mysql/mysql.sock # socket 文件位置
server-id=1 # 服务器 ID,主库必须唯一
log-bin=mysql-bin # 启用二进制日志
gtid_mode=ON # 开启 GTID 全局事务标识
log_slave_updates=ON # 从库记录中继日志到自己的 binlog
enforce-gtid-consistency=ON # 强制 GTID 一致性
symbolic-links=0 # 禁用符号链接
# 初始化数据库(生成初始数据,会输出临时密码)
[root@mysql-node10 ~]# mysqld --user mysql --initialize
# 启动 MySQL
[root@mysql-node10 ~]# /etc/init.d/mysqld start
# 运行安全配置脚本(设置 root 密码、删除匿名用户等)
[root@mysql-node10 ~]# mysql_secure_installation
# 登录 MySQL
[root@mysql-node10 ~]# mysql -p
# 创建复制用户 swp,用于主从同步
mysql> create user swp@'%' identified with mysql_native_password by 'swp';
Query OK, 0 rows affected (0.00 sec)
# 授予复制权限
mysql> GRANT REPLICATION SLAVE ON *.* TO swp@'%';
Query OK, 0 rows affected (0.00 sec)
# 安装半同步复制主库插件
mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
Query OK, 0 rows affected (0.02 sec)
# 启用半同步复制主库
mysql> SET GLOBAL rpl_semi_sync_master_enabled = 1;
Query OK, 0 rows affected (0.00 sec)
# ========== Slave 节点(172.25.254.20 和 172.25.254.30)配置 ==========
# 停止 MySQL 服务
[root@mysql-node20 & 30 ~]# /etc/init.d/mysqld stop
# 清空数据目录
[root@mysql-node20 & 30 ~]# rm -fr /data/mysql/*
# 编辑配置文件(注意 server-id 不同:20 用 2,30 用 3)
[root@mysql-node20 & 30 ~]# vim /etc/my.cnf
[mysqld]
datadir=/data/mysql
socket=/data/mysql/mysql.sock
server-id=1 # ⚠️ 实际配置时 20 用 2,30 用 3
log-bin=mysql-bin
gtid_mode=ON
log_slave_updates=ON
enforce-gtid-consistency=ON
symbolic-links=0
# 初始化数据库
[root@mysql-node20 & 30 ~]# mysqld --user mysql --initialize
# 启动 MySQL
[root@mysql-node20 & 300 ~]# /etc/init.d/mysqld start
# 安全配置
[root@mysql-node20 & 30 ~]# mysql_secure_installation
# 登录 MySQL
[root@mysql-node20 & 30 ~]# mysql -p
# 配置主从复制(使用 GTID 自动定位)
mysql> CHANGE MASTER TO
MASTER_HOST='172.25.254.10', # 主库 IP
MASTER_USER='swp', # 复制用户
MASTER_PASSWORD='swp', # 复制密码
MASTER_AUTO_POSITION=1; # 使用 GTID 自动获取位置
Query OK, 0 rows affected, 2 warnings (0.00 sec)
# 启动从库复制线程
mysql> start slave;
Query OK, 0 rows affected (0.00 sec)
# 安装半同步复制从库插件
mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
Query OK, 0 rows affected (0.01 sec)
# 启用半同步复制从库
mysql> SET GLOBAL rpl_semi_sync_slave_enabled =1;
Query OK, 0 rows affected (0.00 sec)
# 重启 IO 线程使半同步生效
mysql> STOP SLAVE IO_THREAD;
Query OK, 0 rows affected (0.00 sec)
mysql> START SLAVE IO_THREAD;
Query OK, 0 rows affected (0.00 sec)
# 验证半同步是否开启成功
mysql> SHOW STATUS LIKE 'Rpl_semi_sync%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON | # 值为 ON 表示成功
+----------------------------+-------+
1 row in set (0.01 sec)1. 配置 MHA Manager
MHA Manager 是控制中心,负责监控主库状态并自动切换
# 解压 MHA 安装包
[root@mha ~]# unzip MHA-7.zip
[root@mha ~]# cd MHA-7/
# 安装 Perl 依赖(MHA 基于 Perl 开发)
[root@mha MHA-7]# dnf install perl perl-DBD-MySQL perl-CPAN -y
# 进入 CPAN 交互式安装 Perl 模块
[root@mha MHA-7]# cpan
# 自动配置 CPAN(一路 yes)
Loading internal logger. Log::Log4perl recommended for better logging
CPAN.pm requires configuration, but most of it can be done automatically.
Would you like to configure as much as possible automatically? [yes] yes
# 安装 MHA 必需的 Perl 模块
cpan[1]> install Config::Tiny # 配置文件解析
cpan[2]> install Log::Dispatch # 日志处理
cpan[3]> install Mail::Sender # 邮件发送(告警)
# 邮件发送配置:编码默认回车即可
Specify defaults for Mail::Sender? (y/N) y
Default encoding of message bodies (N)one, (Q)uoted-printable, (B)ase64: n
cpan[4]> install Parallel::ForkManager # 并行处理
cpan[5]> exit
# 安装 MHA 软件包(--nodeps 忽略依赖,因为已手动安装 Perl 模块)
[root@mha MHA-7]# rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm mha4mysql-node-0.58-0.el7.centos.noarch.rpm --nodeps
在所有 MySQL 节点安装 MHA Node 软件
MHA Node 安装在每个数据库节点上,负责执行切换操作
# 循环将 node 包复制到 10、20、30 并安装
[root@mha MHA-7]# for i in 10 20 30
> do
> scp mha4mysql-node-0.58-0.el7.centos.noarch.rpm root@172.25.254.$i:/mnt
> ssh -l root 172.25.254.$i "rpm -ivh /mnt/mha4mysql-node-0.58-0.el7.centos.noarch.rpm --nodeps"
> done
# 执行输出示例
Warning: Permanently added '172.25.254.10' (ED25519) to the list of known hosts.
mha4mysql-node-0.58-0.el7.centos.noarch.rpm 100% 35KB 16.9MB/s 00:00
Verifying... ########################################
准备中... ########################################
正在升级/安装...
mha4mysql-node-0.58-0.el7.centos ########################################
# ... 20、30 类似输出 ...
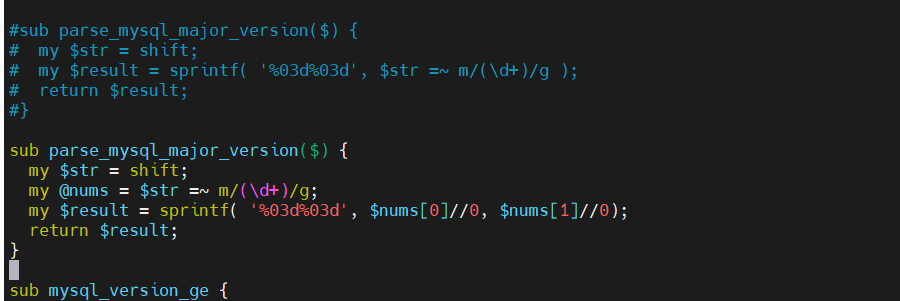
修改 MHA Manager 中的检测代码(兼容 MySQL 8.0)
原因:MHA 0.58 版本解析 MySQL 8.0 版本号时存在兼容性问题,需要修复
[root@mha MHA-7]# vim /usr/share/perl5/vendor_perl/MHA/NodeUtil.pm
# 原始代码(被注释掉)
199 #sub parse_mysql_major_version($) {
200 # my $str = shift;
201 # my $result = sprintf( '%03d%03d', $str =~ m/(\d+)/g );
202 # return $result;
203 #}
# 修改后的代码(兼容 MySQL 8.x)
sub parse_mysql_major_version($) {
my $str = shift;
my @nums = $str =~ m/(\d+)/g; # 提取所有数字
my $result = sprintf( '%03d%03d', $nums[0]//0, $nums[1]//0); # 格式化为 6 位数字
return $result;
}
为 MHA 建立远程登录用户
目的:MHA Manager 需要通过 MySQL 用户连接各节点进行管理
# 在主库(10)上执行
mysql> create user root@'%' identified with mysql_native_password by 'lee';
Query OK, 0 rows affected (0.01 sec)
mysql> GRANT ALL ON *.* TO root@'%' ;
Query OK, 0 rows affected (0.00 sec)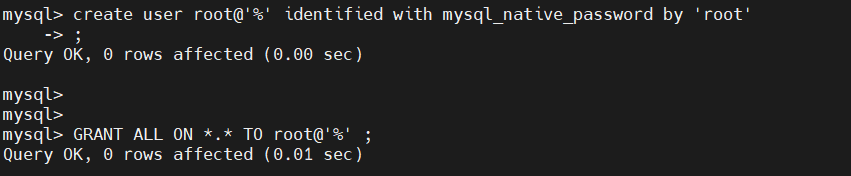
生成 MHA Manager 的配置文件模板
# 创建配置目录
[root@mha mha4mysql-manager-0.58]# mkdir /etc/masterha/ -p
# 解压源码包(获取示例配置)
[root@mha MHA-7]# tar zxf mha4mysql-manager-0.58.tar.gz
[root@mha MHA-7]# cd mha4mysql-manager-0.58
[root@mha mha4mysql-manager-0.58]# mkdir /etc/masterha/ -p
# 合并默认配置和示例配置,生成完整配置文件
[root@mha mha4mysql-manager-0.58]# cat samples/conf/masterha_default.cnf samples/conf/app1.cnf > /etc/masterha/app1.cnf
修改配置文件
配置文件说明:定义集群节点、用户、路径等关键信息
[root@mha mha4mysql-manager-0.58]# vim /etc/masterha/app1.cnf
# ========== 全局默认配置 ==========
[server default]
user=root # MHA 管理用户
password=root # 管理用户密码(⚠️ 注意:实际是 lee)
ssh_user=root # SSH 登录用户
repl_user=swp # 主从复制用户
repl_password=swp # 复制密码
master_binlog_dir=/data/mysql # 主库 binlog 目录
remote_workdir=/tmp # 远程工作目录
secondary_check_script= masterha_secondary_check -s 172.25.254.10 -s 172.25.254.2
ping_interval=3 # 健康检查间隔(秒)
# 以下脚本暂未配置(后续配置 VIP 时需要)
# master_ip_failover_script= /script/masterha/master_ip_failover
# shutdown_script= /script/masterha/power_manager
# report_script= /script/masterha/send_report
# master_ip_online_change_script= /script/masterha/master_ip_online_change
# ========== Manager 自身配置 ==========
[server default]
manager_workdir=/etc/masterha # Manager 工作目录
manager_log=/etc/masterha/mha.log # Manager 日志文件
# ========== 节点定义 ==========
[server1]
hostname=172.25.254.10
candidate_master=1 # 可成为主库
check_repl_delay=0 # 不检查复制延迟
[server2]
hostname=172.25.254.20
candidate_master=1 # 可成为主库
check_repl_delay=0
[server3]
hostname=172.25.254.30
no_master=1 # 禁止成为主库(只读从库)检测环境
检测 SSH 互信
目的:确保 MHA Manager 能免密登录所有数据库节点
[root@mha mha4mysql-manager-0.58]# masterha_check_ssh --conf=/etc/masterha/app1.cnf
Fri Feb 27 16:23:20 2026 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Fri Feb 27 16:23:20 2026 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Fri Feb 27 16:23:20 2026 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Fri Feb 27 16:23:20 2026 - [info] Starting SSH connection tests..
# ... 各节点间双向 SSH 测试 ...
Fri Feb 27 16:23:22 2026 - [info] All SSH connection tests passed successfully. # ✅ 成功
Use of uninitialized value in exit at /usr/bin/masterha_check_ssh line 44.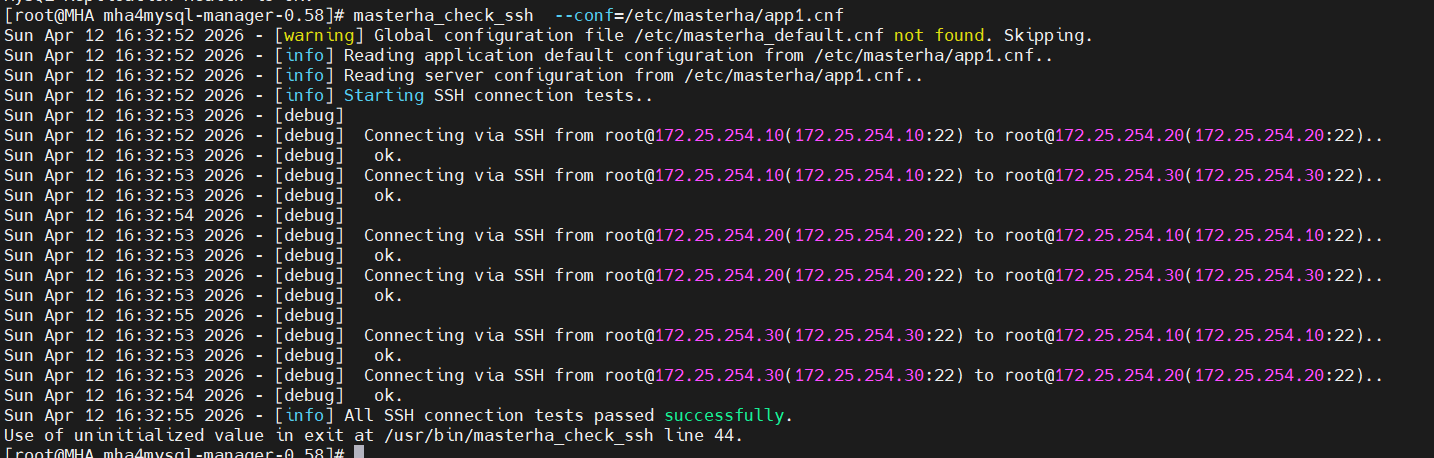
检测复制健康状态
[root@mha mha4mysql-manager-0.58]# masterha_check_repl --conf=/etc/masterha/app1.cnf
Fri Feb 27 16:23:50 2026 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Fri Feb 27 16:23:50 2026 - [info] Reading application default configuration from /etc/masterha/app1.cnf..
Fri Feb 27 16:23:50 2026 - [info] Reading server configuration from /etc/masterha/app1.cnf..
Fri Feb 27 16:23:50 2026 - [info] MHA::MasterMonitor version 0.58.
Fri Feb 27 16:23:51 2026 - [info] GTID failover mode = 1 # ✅ GTID 切换模式已启用
Fri Feb 27 16:23:51 2026 - [info] Dead Servers:
Fri Feb 27 16:23:51 2026 - [info] Alive Servers:
Fri Feb 27 16:23:51 2026 - [info] 172.25.254.10(172.25.254.10:3306)
Fri Feb 27 16:23:51 2026 - [info] 172.25.254.20(172.25.254.20:3306)
Fri Feb 27 16:23:51 2026 - [info] 172.25.254.30(172.25.254.30:3306)
Fri Feb 27 16:23:51 2026 - [info] Alive Slaves:
Fri Feb 27 16:23:51 2026 - [info] 172.25.254.20(172.25.254.20:3306) Version=8.3.0
Fri Feb 27 16:23:51 2026 - [info] Replicating from 172.25.254.10 # 20 从 10 复制
Fri Feb 27 16:23:51 2026 - [info] 172.25.254.30(172.25.254.30:3306) Version=8.3.0
Fri Feb 27 16:23:51 2026 - [info] Replicating from 172.25.254.10 # 30 从 10 复制
Fri Feb 27 16:23:51 2026 - [info] Current Alive Master: 172.25.254.10 # 当前主库是 10
Fri Feb 27 16:23:51 2026 - [info] Checking slave configurations..
Fri Feb 27 16:23:51 2026 - [info] read_only=1 is not set on slave 172.25.254.20 # ⚠️ 警告:从库未设置只读
Fri Feb 27 16:23:51 2026 - [info] read_only=1 is not set on slave 172.25.254.30
# ... 省略部分输出 ...
Fri Feb 27 16:23:51 2026 - [info] MySQL Replication Health is OK. # ✅ 复制健康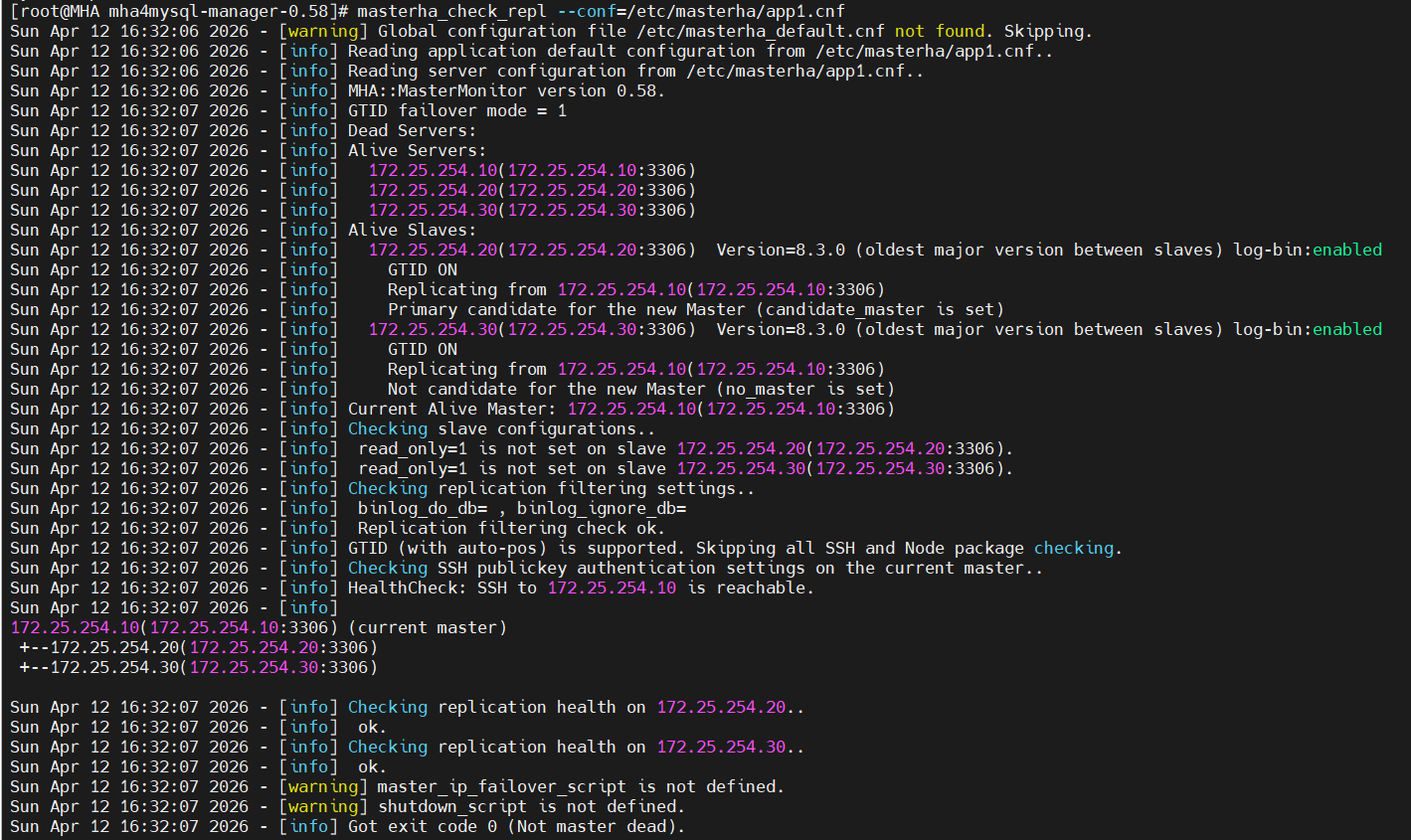
在 Slave 中安装 MHA Node 软件依赖
注意:这一步是在**每个数据库节点(10、20、30)**上执行,不是在 MHA Manager 上
# 安装 Perl 依赖
[root@mysql-node1~3 ~]# dnf install perl perl-DBD-MySQL perl-CPAN -y
# 解压 CPAN 插件包(如果有离线包)
[root@mysql-node1~3 ~]# tar zxf cpan_plugin.tar.gz
# 进入 CPAN 安装 Perl 模块(与 Manager 安装类似)
[root@mysql-node1~3 ~]# cpan
# ... 自动配置 ...
cpan[1]> install Config::Tiny
cpan[2]> install Log::Dispatch
cpan[3]> install Mail::Sender
# Mail::Sender 配置
Specify defaults for Mail::Sender? (y/N) y
Default encoding of message bodies (N)one, (Q)uoted-printable, (B)ase64: n
cpan[4]> install Parallel::ForkManager
cpan[5]> exit
# 验证模块是否安装成功
```
[root@mysql-node1~3 ~]# perl -MConfig::Tiny -e 'print "OK\n"'
OK
[root@mysql-node1~3 ~]# perl -MLog::Dispatch -e 'print "OK\n"'
OK
[root@mysql-node1~3 ~]# perl -MMail::Sender -e 'print "OK\n"'
Mail::Sender is deprecated and you should look to Email::Sender instead at -e line 0.
OK
[root@mysql-node1~3 ~]# perl -MParallel::ForkManager -e 'print "OK\n"'
OK
```
集群无故障切换(手动在线切换)
场景:主库正常运行时,手动将主库切换到另一个节点
切换前查看从库状态
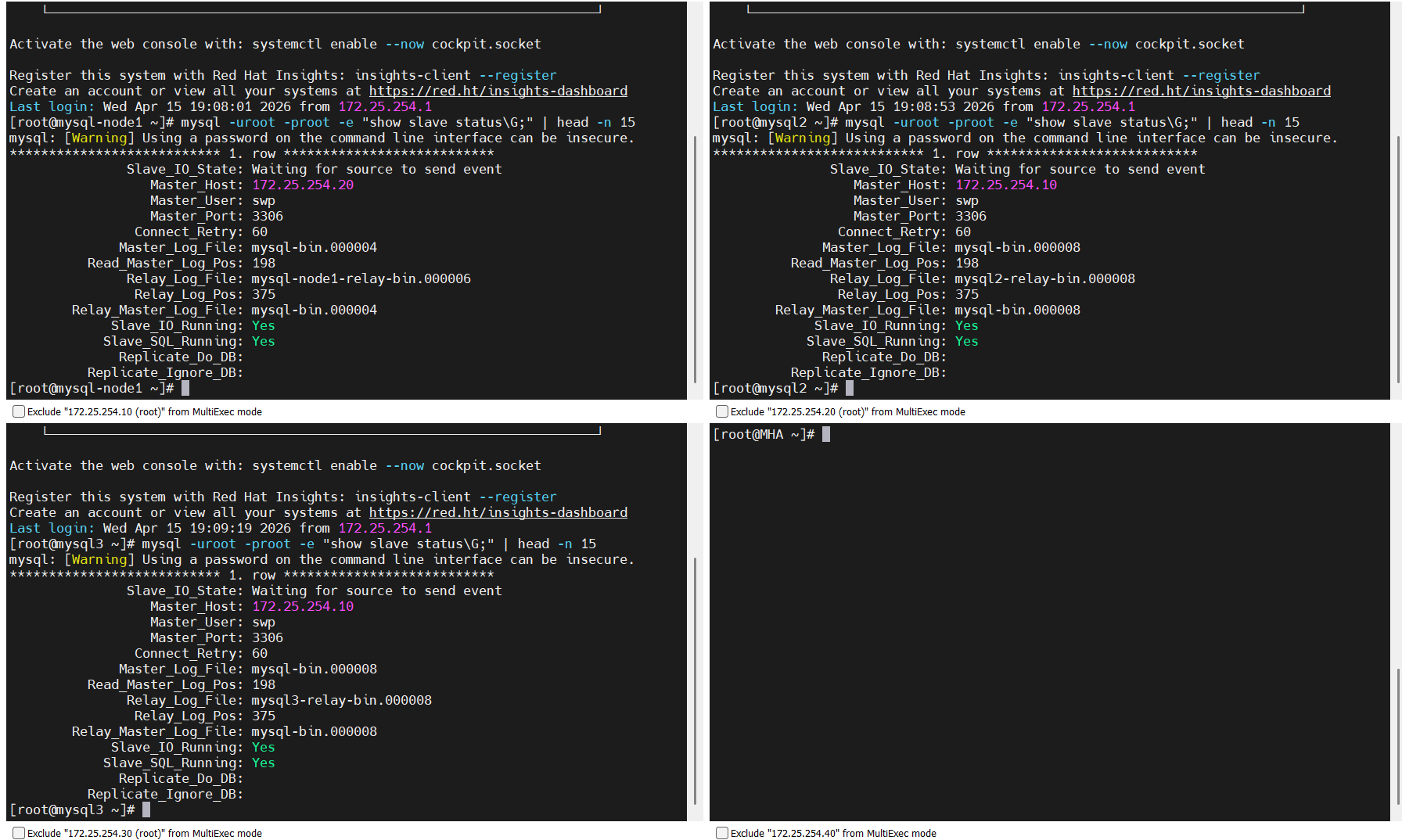
[root@mysql2和mysql3 ~]# mysql -uroot -proot -e "show slave status\G;" | head -n 15
mysql: [Warning] Using a password on the command line interface can be insecure.
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 172.25.254.10 # 当前主库是 10
Master_User: swp
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000004
Read_Master_Log_Pos: 2085
Relay_Log_File: mysql2-relay-bin.000008
Relay_Log_Pos: 462
Relay_Master_Log_File: mysql-bin.000004
Slave_IO_Running: Yes
Slave_SQL_Running: Yes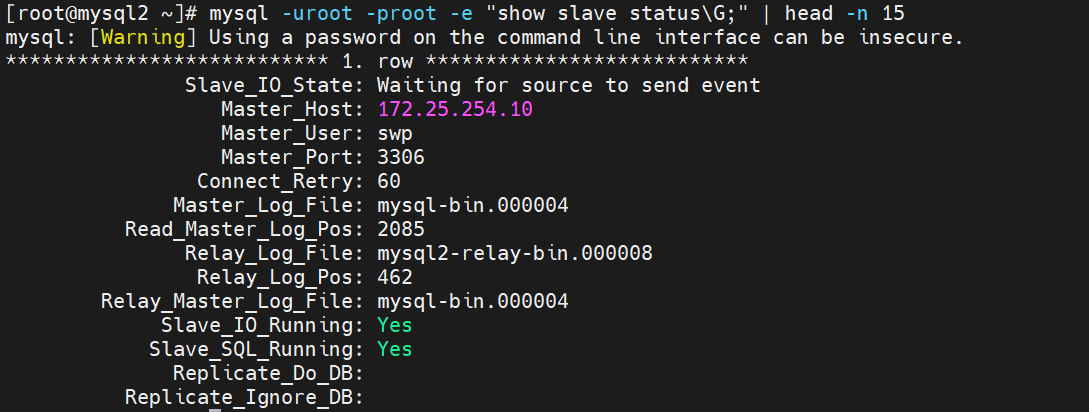
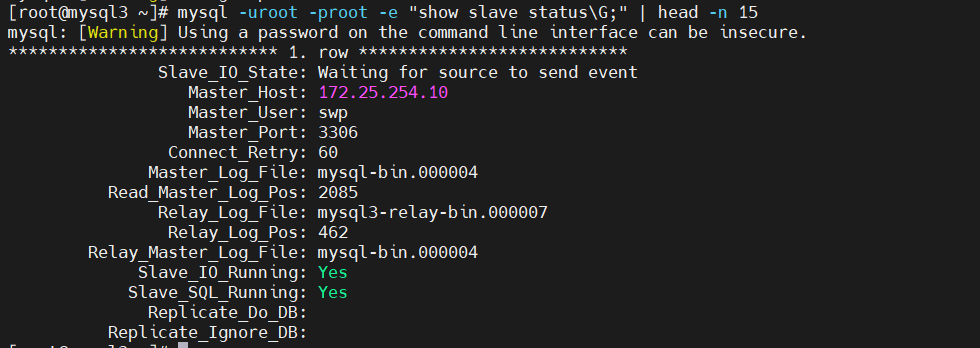
执行在线切换(主库无故障)
目标:将主库从 10 切换到 20
# 在 MHA Manager 上执行
[root@mysql-mha ~]# masterha_master_switch \
--conf=/etc/masterha/app1.cnf \ # 指定配置文件
--master_state=alive \ # 主库状态为 alive(正常运行)
--new_master_host=172.25.254.20 \ # 新主库 IP
--new_master_port=3306 \ # 新主库端口
--orig_master_is_new_slave \ # 原主库变为从库
--running_updates_limit=10000 # 切换超时时间(毫秒)
切换详细过程
[root@MHA ~]# masterha_master_switch --conf=/etc/masterha/app1.cnf --master_state=alive --new_master_host=172.25.254.20 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
Sun Apr 12 19:16:47 2026 - [info] MHA::MasterRotate version 0.58.
Sun Apr 12 19:16:47 2026 - [info] Starting online master switch..
# ========== 阶段1:配置检查 ==========
Sun Apr 12 19:16:47 2026 - [info] * Phase 1: Configuration Check Phase..
Sun Apr 12 19:16:48 2026 - [info] GTID failover mode = 1
Sun Apr 12 19:16:48 2026 - [info] Current Alive Master: 172.25.254.10(172.25.254.10:3306)
Sun Apr 12 19:16:48 2026 - [info] Alive Slaves:
Sun Apr 12 19:16:48 2026 - [info] 172.25.254.20(172.25.254.20:3306) # 候选主库
Sun Apr 12 19:16:48 2026 - [info] 172.25.254.30(172.25.254.30:3306) # 只读从库
# 询问是否在主库执行 FLUSH TABLES
It is better to execute FLUSH NO_WRITE_TO_BINLOG TABLES on the master before switching. Is it ok to execute on 172.25.254.10(172.25.254.10:3306)? (YES/no): yes
Sun Apr 12 19:16:55 2026 - [info] Executing FLUSH NO_WRITE_TO_BINLOG TABLES. This may take long time..
Sun Apr 12 19:16:55 2026 - [info] ok.
# 切换拓扑预览
From:
172.25.254.10(172.25.254.10:3306) (current master)
+--172.25.254.20(172.25.254.20:3306)
+--172.25.254.30(172.25.254.30:3306)
To:
172.25.254.20(172.25.254.20:3306) (new master)
+--172.25.254.30(172.25.254.30:3306)
+--172.25.254.10(172.25.254.10:3306)
# 确认执行切换
Starting master switch from 172.25.254.10(172.25.254.10:3306) to 172.25.254.20(172.25.254.20:3306)? (yes/NO): yes
# ========== 阶段2:拒绝写入 ==========
Sun Apr 12 19:16:57 2026 - [info] * Phase 2: Rejecting updates Phase..
master_ip_online_change_script is not defined... Is it ok to proceed? (yes/NO): yes
Sun Apr 12 19:16:59 2026 - [info] Executing FLUSH TABLES WITH READ LOCK.. # 锁表
# ========== 阶段3:切换从库 ==========
Sun Apr 12 19:16:59 2026 - [info] * Switching slaves in parallel..
# 30 号从库切换到新主库 20
Sun Apr 12 19:17:01 2026 - [info] -- Slave switch on host 172.25.254.30 succeeded.
# 原主库 10 变成从库
Sun Apr 12 19:17:02 2026 - [info] Resetting slave 172.25.254.10 and starting replication from the new master
# ========== 完成 ==========
Sun Apr 12 19:17:02 2026 - [info] Switching master to 172.25.254.20(172.25.254.20:3306) completed successfully.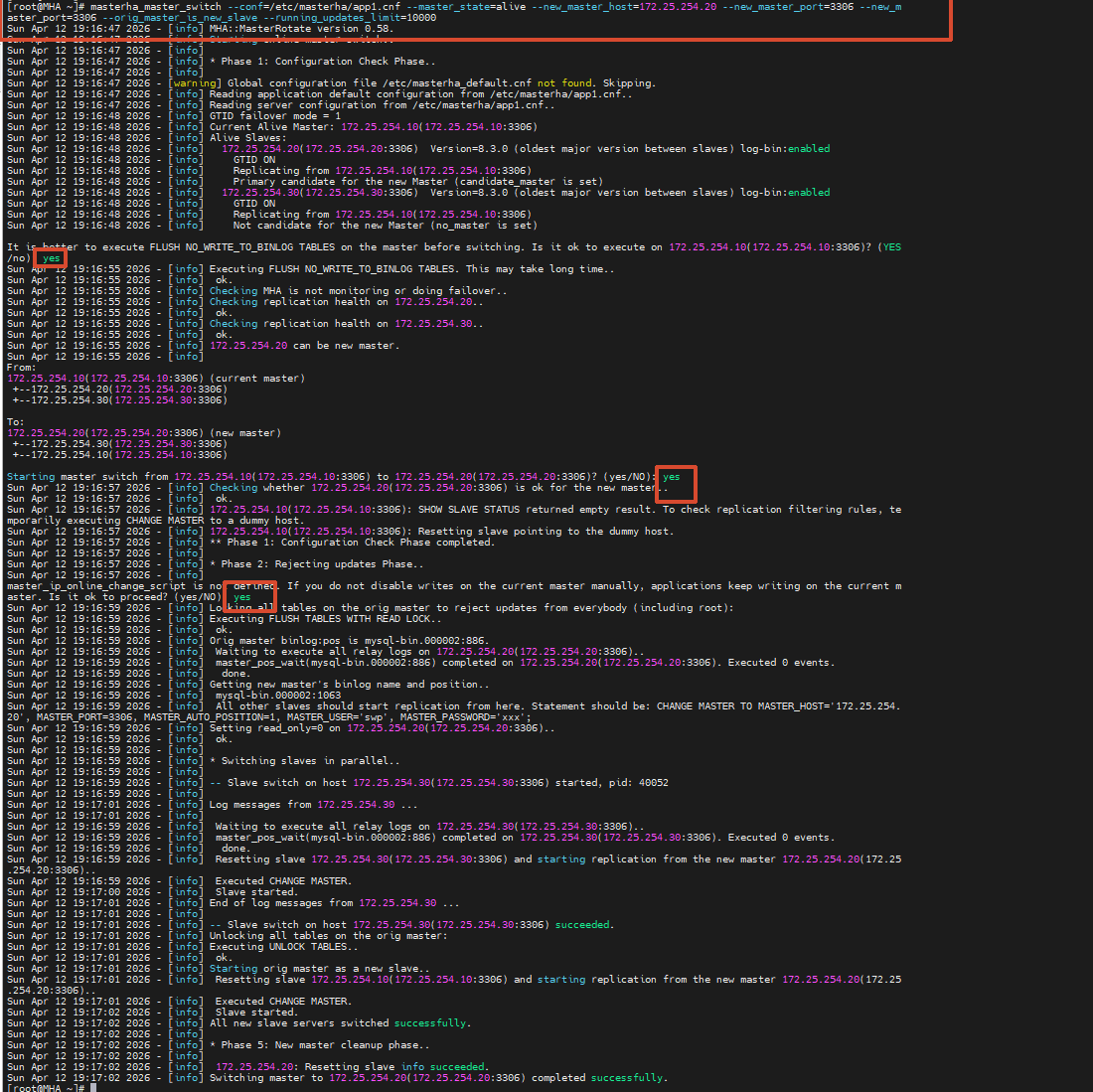
切换后验证
[root@MHA ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf
Sun Apr 12 19:18:38 2026 - [info] Current Alive Master: 172.25.254.20(172.25.254.20:3306) # ✅ 主库已变成 20
Sun Apr 12 19:18:38 2026 - [info]
172.25.254.20(172.25.254.20:3306) (current master)
+--172.25.254.10(172.25.254.10:3306) # 10 变成从库
+--172.25.254.30(172.25.254.30:3306)
MySQL Replication Health is OK.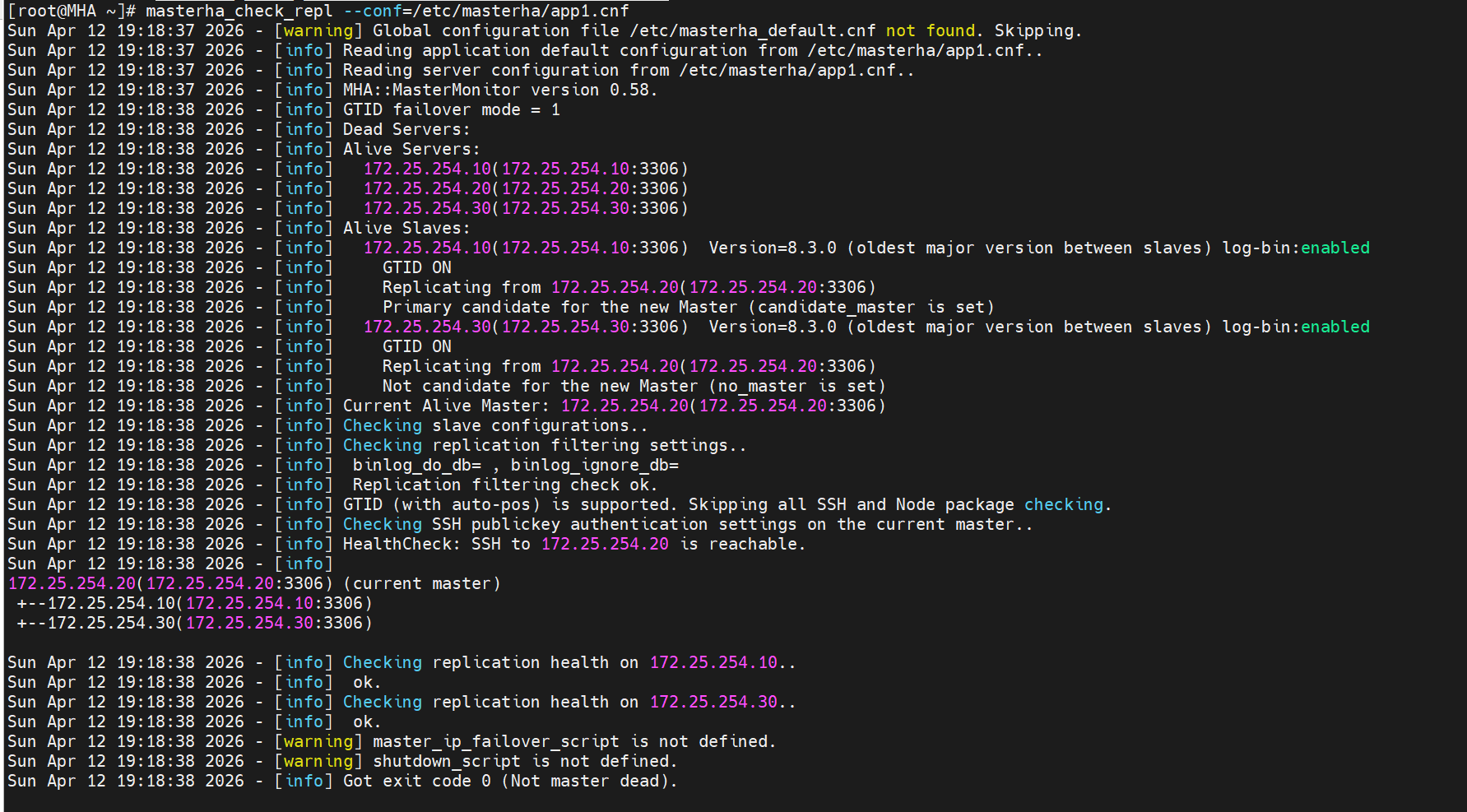
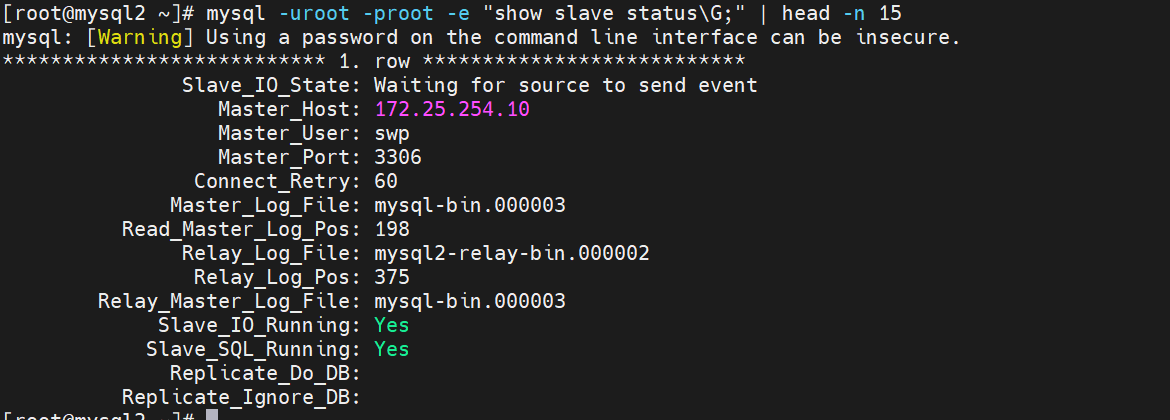
查看集群状态
验证:所有从库都指向新主库 20
# 在 10 上查看
mysql -uroot -proot -e "show slave status\G;" | head -n 15
# Master_Host: 172.25.254.20
# 在 30 上查看
mysql -uroot -proot -e "show slave status\G;" | head -n 15
# Master_Host: 172.25.254.20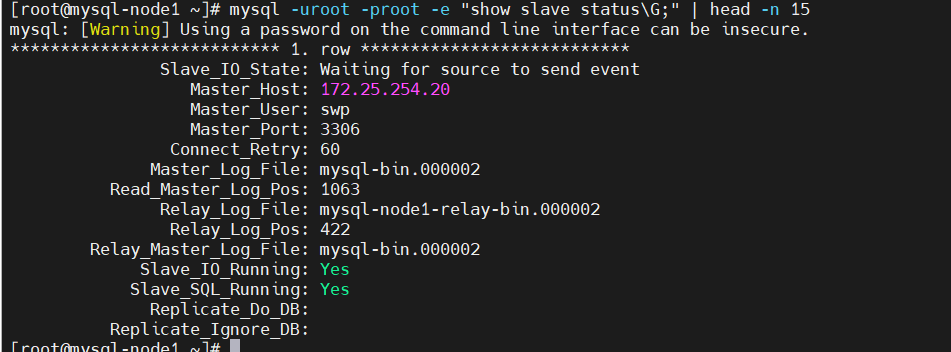
Master 故障手动切换
场景:主库宕机,手动执行故障切换
模拟主库故障
# 在原来的主库(10)上停止 MySQL
[root@mysql-node2 mysql]# /etc/init.d/mysqld stop
执行故障切换
# 在 MHA Manager 上执行
[root@mysql-mha masterha]# masterha_master_switch \
--master_state=dead \ # 主库已死
--conf=/etc/masterha/app1.cnf \ # 配置文件
--dead_master_host=172.25.254.10 \ # 故障主库 IP
--dead_master_port=3306 \ # 故障主库端口
--new_master_host=172.25.254.20 \ # 新主库 IP
--new_master_port=3306 \ # 新主库端口
--ignore_last_failover # 忽略上次切换的锁文件
--ignore_last_failover说明 :MHA 切换后会在/etc/masterha/目录生成锁文件,防止重复切换。手动故障切换时需要忽略它。
切换详细过程
[root@MHA ~]# masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf --dead_master_host=172.25.254.10 --dead_master_port=3306 --new_master_host=172.25.254.20 --new_master_port=3306 --ignore_last_failover
Sun Apr 12 19:30:41 2026 - [info] Starting master failover.
Sun Apr 12 19:30:42 2026 - [info] GTID failover mode = 1
Sun Apr 12 19:30:42 2026 - [info] Dead Servers:
Sun Apr 12 19:30:42 2026 - [info] 172.25.254.10(172.25.254.10:3306) # 已宕机
Master 172.25.254.10(172.25.254.10:3306) is dead. Proceed? (yes/NO): yes
# 切换拓扑预览
From:
172.25.254.10(172.25.254.10:3306) (current master)
+--172.25.254.20(172.25.254.20:3306)
+--172.25.254.30(172.25.254.30:3306)
To:
172.25.254.20(172.25.254.20:3306) (new master)
+--172.25.254.30(172.25.254.30:3306)
Starting master switch...? (yes/NO): yes
# ... 切换过程 ...
# ⚠️ 注意:切换过程中出现警告(但不影响整体成功)
Sun Apr 12 19:30:49 2026 - [error] gtid_wait(...) returned NULL on 172.25.254.30. Maybe SQL thread was aborted?
Sun Apr 12 19:30:49 2026 - [error] Master failover done, but recovery on slave partially failed.
----- Failover Report -----
Master 172.25.254.10(172.25.254.10:3306) is down!
Selected 172.25.254.20(172.25.254.20:3306) as a new master.
Master failover to 172.25.254.20 done, but recovery on slave partially failed.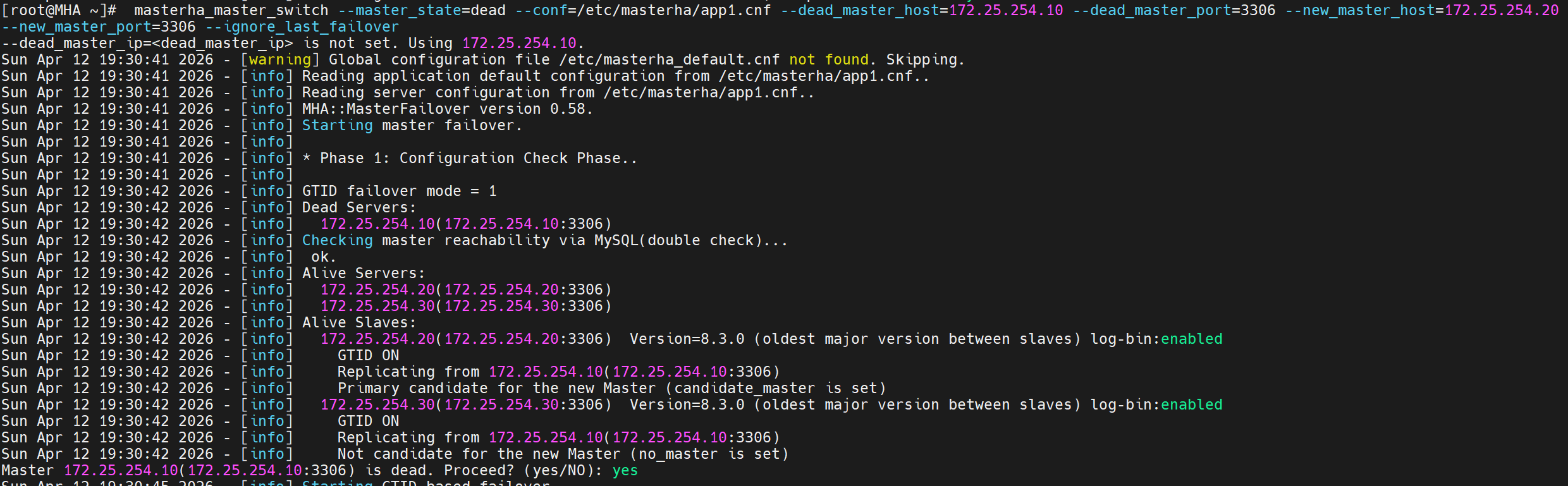
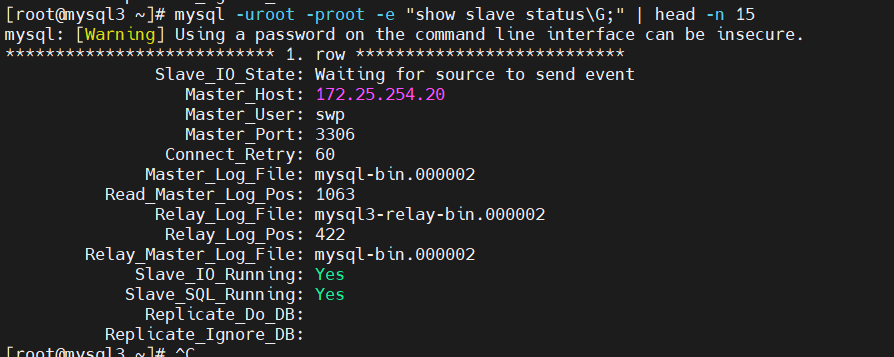
查看切换后的状态
# 在 30 上查看,已指向新主库 20
[root@mysql3 ~]# mysql -uroot -proot -e "show slave status\G;" | head -n 15
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 172.25.254.20 # ✅ 已指向 20
Master_User: swp
Master_Port: 3306
Master_Log_File: mysql-bin.000002
Read_Master_Log_Pos: 1063
Slave_IO_Running: Yes
Slave_SQL_Running: Yes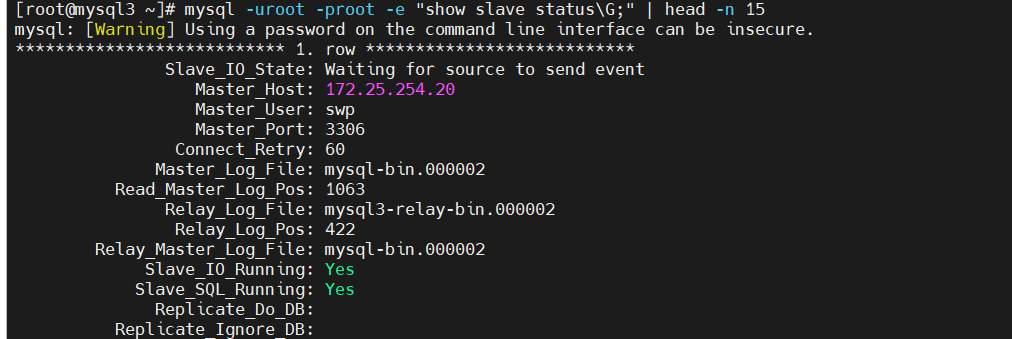
恢复故障 MySQL 节点
场景:原来宕机的主库(10)修复后,需要重新加入集群作为从库
1. 删除 MHA 切换锁文件
bash
# 查看锁文件(切换后自动生成)
[root@MHA ~]# ls /etc/masterha/
app1.cnf app1.failover.complete # ⚠️ 锁文件,阻止后续切换
# 删除锁文件
[root@MHA ~]# rm -fr /etc/masterha/app1.failover.complete
https://tuchuang1980.oss-cn-beijing.aliyuncs.com/tuchuang/image-20260412195332776.png
2. 在从库(20)上重置复制信息(可选)
[root@mysql2 ~]# mysql -uroot -proot -e "reset slave;"3. 启动故障节点
bash
[root@mysql-node1 ~]# /etc/init.d/mysqld start
Starting MySQL. SUCCESS!
4. 重新配置为从库
[root@mysql-node1 ~]# mysql -uroot -proot
# 配置指向新主库 20(使用 GTID 自动定位)
mysql> CHANGE MASTER TO
MASTER_HOST='172.25.254.20',
MASTER_USER='swp',
MASTER_PASSWORD='swp',
MASTER_AUTO_POSITION=1;
# 启动复制
mysql> START SLAVE;
验证复制状态
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 172.25.254.20 # ✅ 指向 20
Master_User: swp
Master_Port: 3306
Master_Log_File: mysql-bin.000002
Read_Master_Log_Pos: 1063
Slave_IO_Running: Yes
Slave_SQL_Running: Yes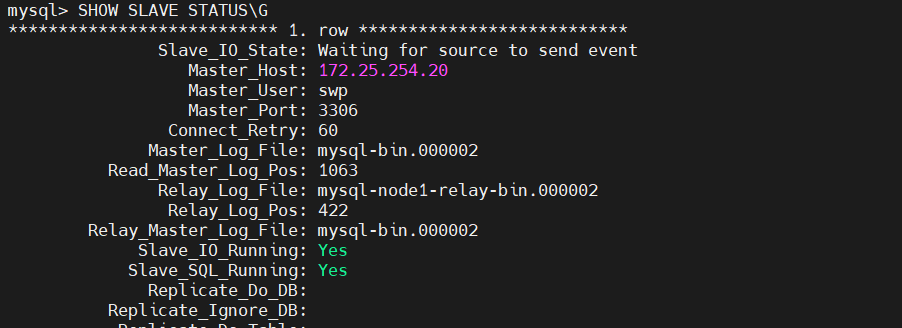
切回 Master 为 mysql1(10)
场景:希望将主库从 20 切换回 10
[root@MHA ~]# masterha_master_switch \
--conf=/etc/masterha/app1.cnf \
--master_state=alive \
--new_master_host=172.25.254.10 \
--new_master_port=3306 \
--orig_master_is_new_slave \
--running_updates_limit=10000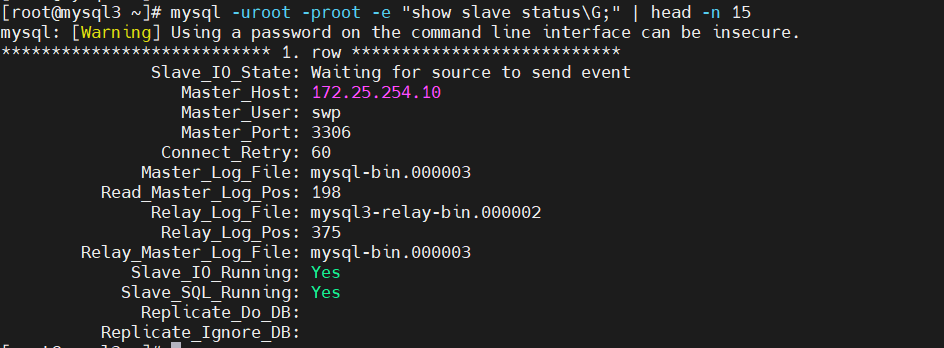
自动故障切换
目标:MHA Manager 后台运行,自动监控主库状态,故障时自动切换
1. 清理环境
bash
# 删除锁文件(如果存在)
[root@mysql-mha masterha]# rm -fr app1.failover.complete
# 清空日志文件便于观察
[root@MHA ~]# > /etc/masterha/*.log
# 开启日志监控(另开一个 shell)
[root@MHA ~]# watch -n 1 cat /etc/masterha/mha.log
2. 启动 MHA Manager 后台监控
bash
# 启动自动切换(后台运行)
[root@MHA ~]# masterha_manager --conf=/etc/masterha/app1.cnf &
# 查看后台任务
[root@MHA ~]# jobs
[1]+ Running masterha_manager --conf=/etc/masterha/app1.cnf &
3. 监控日志输出
[root@MHA ~]# watch -n 1 cat /etc/masterha/*.log #监控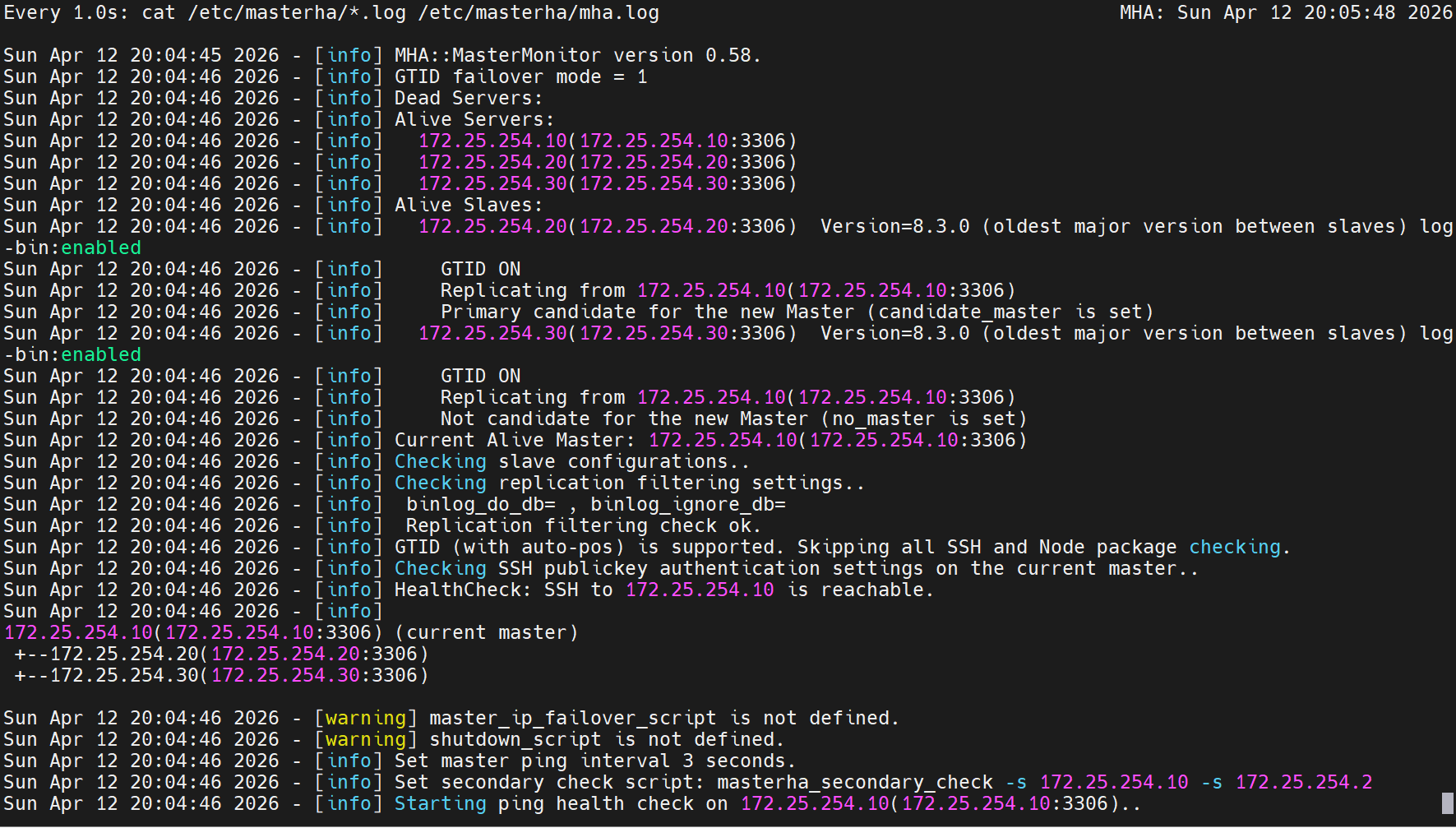
4. 模拟主库故障
# 在 10 上停止 MySQL
[root@mysql-node1 ~]# /etc/init.d/mysqld stop
5. 验证自动切换结果
bash
# 在 30 上查看,应自动指向新主库 20
[root@mysql3 ~]# mysql -uroot -proot -e "show slave status\G;" | head -n 15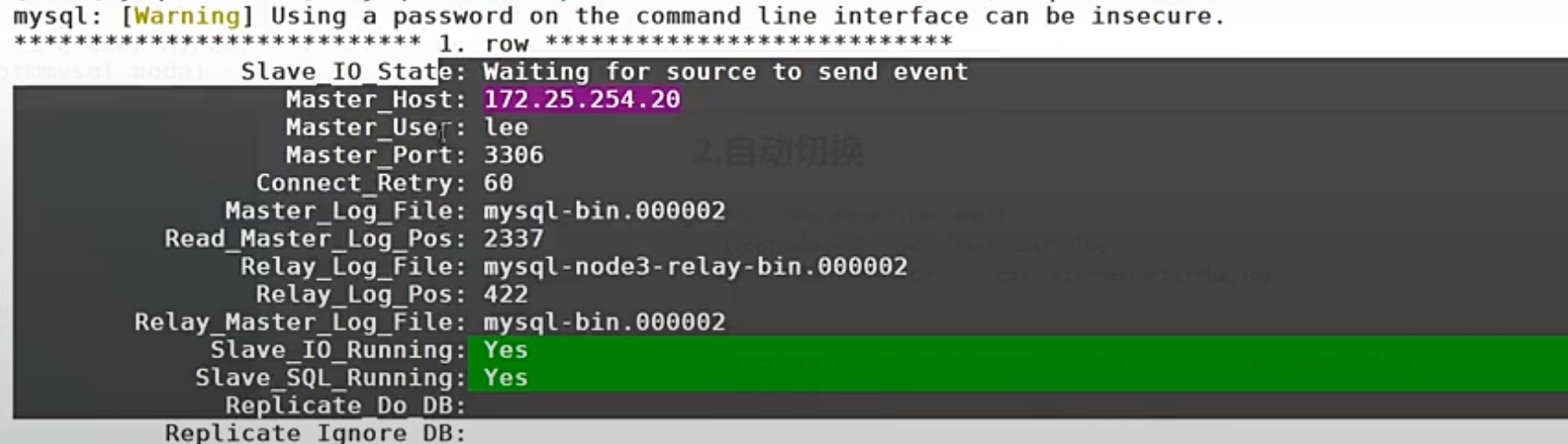
6. 故障节点恢复
# 启动故障节点
[root@mysql-node1 ~]# /etc/init.d/mysqld start
# 重新配置为从库(指向新主库 20)
[root@mysql-node1 ~]# mysql -uroot -proot
mysql> CHANGE MASTER TO
MASTER_HOST='172.25.254.20',
MASTER_USER='swp',
MASTER_PASSWORD='swp',
MASTER_AUTO_POSITION=1;
mysql> START SLAVE;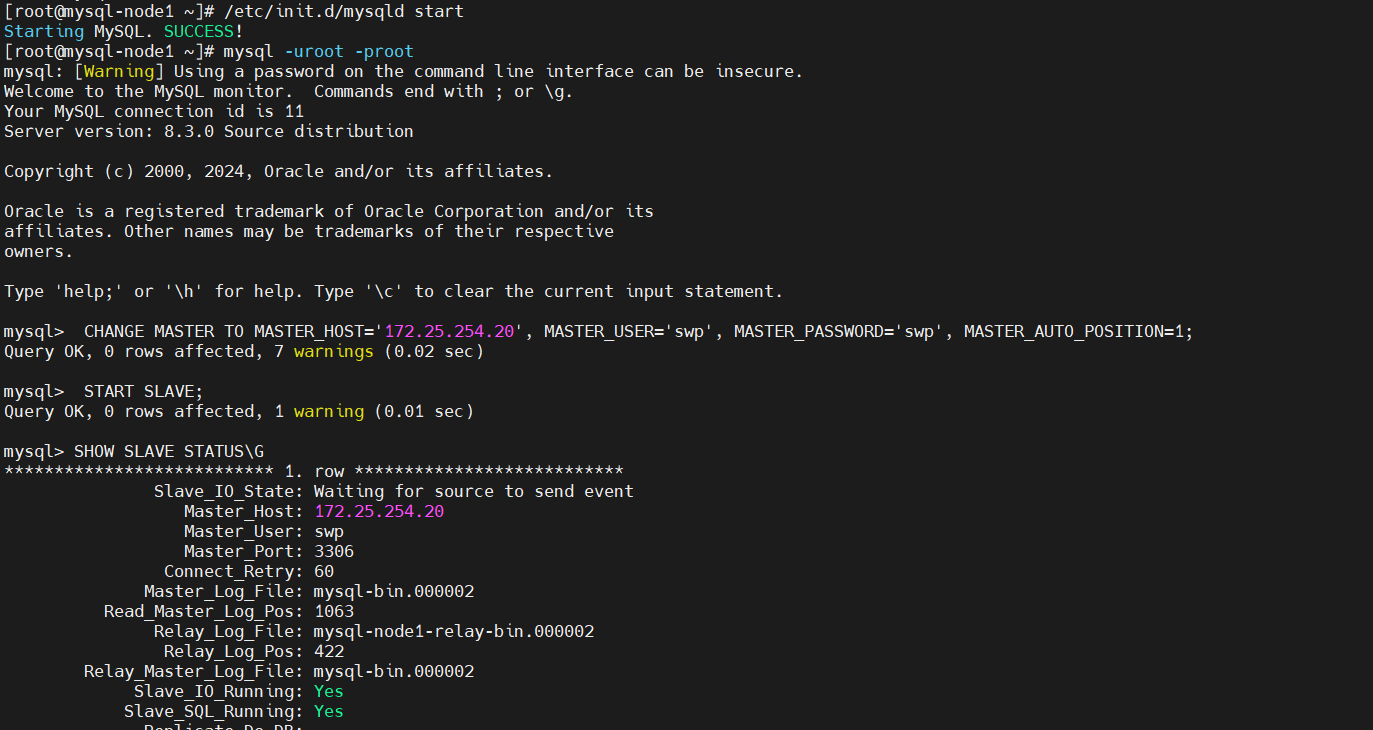
7. 删除锁文件(重要)
注意:自动切换后 MHA Manager 会退出,同时生成锁文件。需要手动删除锁文件并重启 Manager,才能继续监控。
[root@MHA ~]# rm -rf /etc/masterha/app1.failover.complete
为 MHA 添加 VIP 功能
目的:应用程序通过 VIP(虚拟 IP)访问数据库,主库切换时 VIP 自动漂移,实现应用无感知
1. 复制 VIP 切换脚本
# 查看脚本文件
[root@MHA ~]# ll MHA-7/master_ip_*
-rw-r--r-- 1 root root 2156 Jan 14 2021 MHA-7/master_ip_failover # 故障切换脚本
-rw-r--r-- 1 root root 2156 Apr 16 19:42 MHA-7/master_ip_online_change # 在线切换脚本
# 创建脚本目录并复制
[root@MHA ~]# cp MHA-7/master_ip_* /etc/masterha/scripts
2. 修改 MHA 配置文件,启用 VIP 脚本
[root@MHA ~]# vim /etc/masterha/app1.cnf
# 取消注释并修改路径
master_ip_failover_script=/etc/masterha/scripts/master_ip_failover
master_ip_online_change_script=/etc/masterha/scripts/master_ip_online_change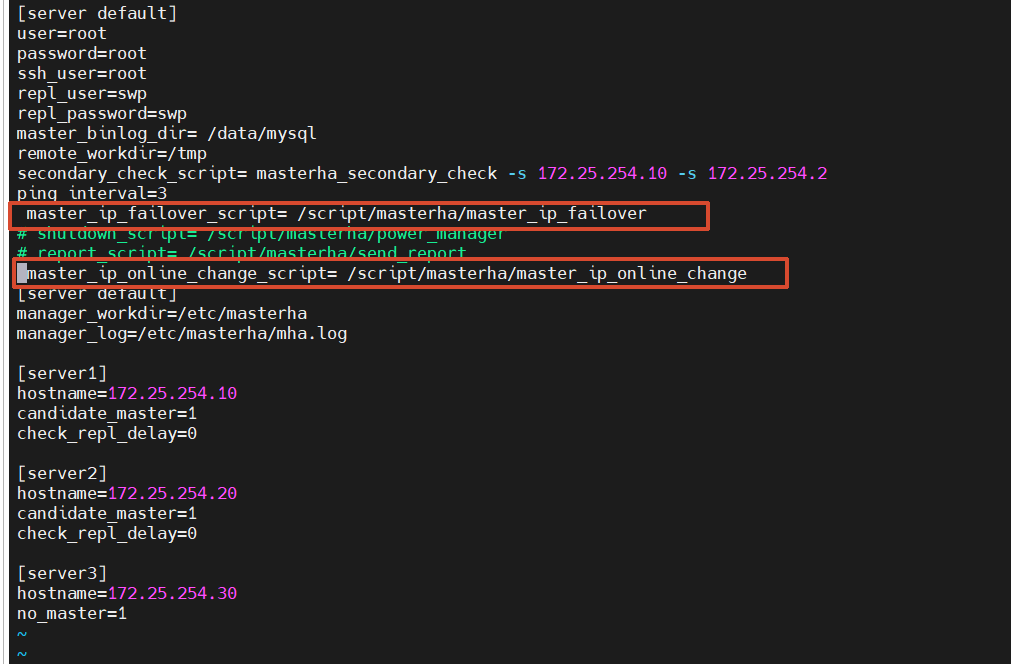
3. 修改故障切换脚本中的 VIP 地址
[root@MHA ~]# vim /etc/masterha/scripts/master_ip_failover
# 找到 vip 变量并修改
my $vip = '172.25.254.100/24'; # 设置 VIP 地址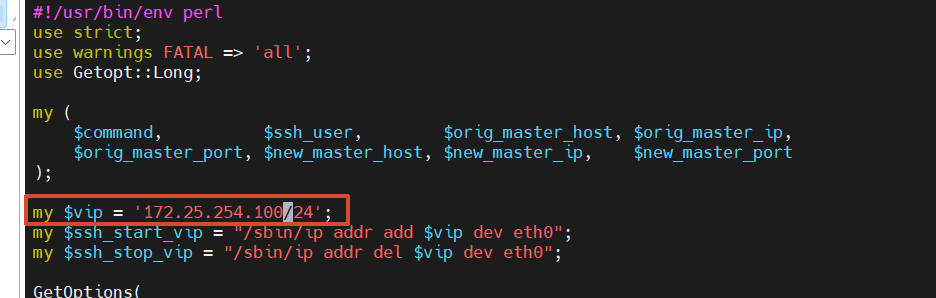
4. 修改在线切换脚本中的 VIP 地址
bash
[root@MHA ~]# vim MHA-7/master_ip_online_change
my $vip = '172.25.254.100/24';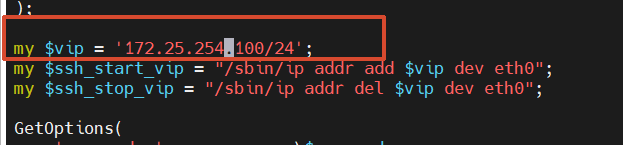
5. 模拟故障并验证 VIP 漂移
6. 启动 MHA 监控
# 检查状态
[root@MHA ~]# masterha_check_status --conf=/etc/masterha/app1.cnf &
# 启动 Manager
[root@MHA ~]# masterha_manager --conf=/etc/masterha/app1.cnf &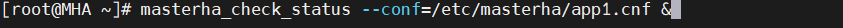
7. 手动绑定 VIP 到当前主库(10)
# 在 1上添加 VIP
[root@mysql-node1 ~]# ip a a 172.25.254.100/24 dev eth0
# 查看 VIP 是否添加成功
[root@mysql-node1 ~]# ip a
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:05:9d:b4 brd ff:ff:ff:ff:ff:ff
inet 172.25.254.10/24 brd 172.25.254.255 scope global noprefixroute eth0
inet 172.25.254.100/24 scope global secondary eth0 # ✅ VIP 已添加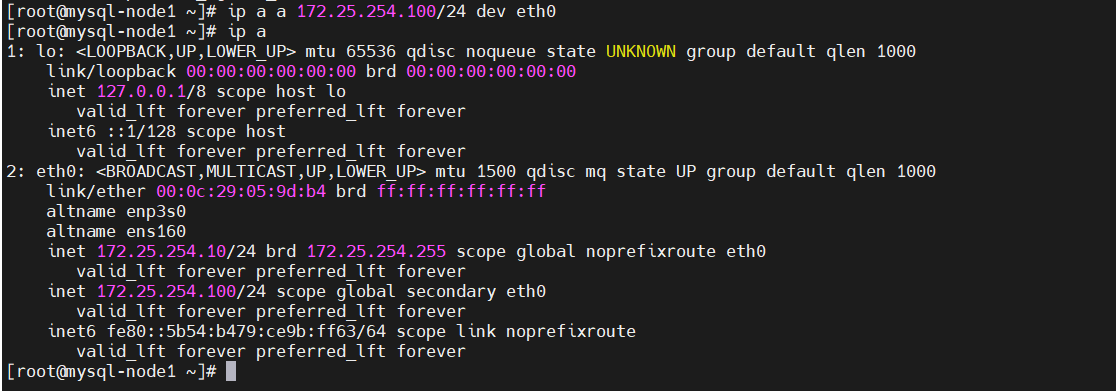
8. 停止主库触发切换
# 关闭主库 1
[root@mysql-node1 ~]# /etc/init.d/mysqld stop
Shutting down MySQL........... SUCCESS!9. 验证 VIP 已漂移到新主库(20)
# 在 2 上查看 VIP
[root@mysql-node2 ~]# ip a
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:cb:63:ce brd ff:ff:ff:ff:ff:ff
inet 172.25.254.20/24 brd 172.25.254.255 scope global noprefixroute eth0
inet 172.25.254.100/24 scope global secondary eth0 # ✅ VIP 已漂移到 2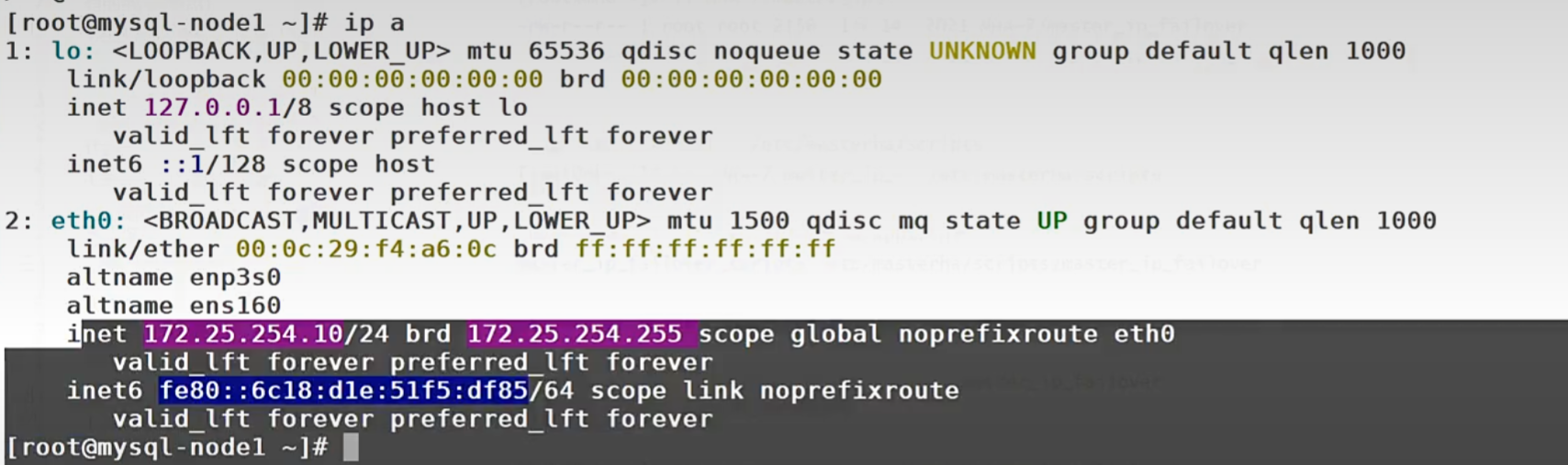
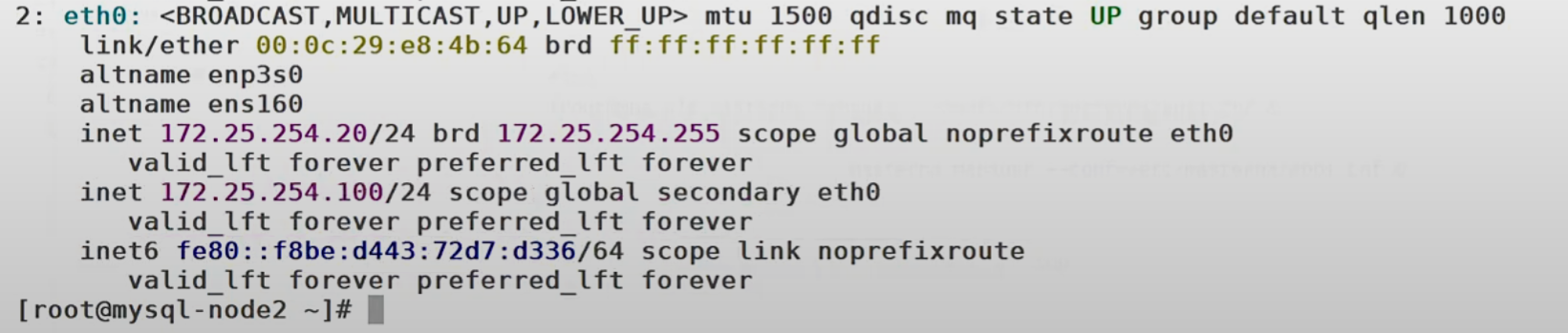
00 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:05:9d:b4 brd ff:ff:ff:ff:ff:ff
inet 172.25.254.10/24 brd 172.25.254.255 scope global noprefixroute eth0
inet 172.25.254.100/24 scope global secondary eth0 # ✅ VIP 已添加
[外链图片转存中...(img-oP9uRHMC-1776343362112)]
### 8. 停止主库触发切换关闭主库 1
root@mysql-node1 \~# /etc/init.d/mysqld stop
Shutting down MySQL... SUCCESS!
### 9. 验证 VIP 已漂移到新主库(20)在 2 上查看 VIP
root@mysql-node2 \~# ip a
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:cb:63:ce brd ff:ff:ff:ff:ff:ff
inet 172.25.254.20/24 brd 172.25.254.255 scope global noprefixroute eth0
inet 172.25.254.100/24 scope global secondary eth0 # ✅ VIP 已漂移到 2
[外链图片转存中...(img-gZthZZB7-1776343362112)]
[外链图片转存中...(img-ul44dTbJ-1776343362112)]