前言
在 MySQL8.0 生态中,传统的 Keepalived、MHA 属于第三方半成品高可用,存在弱一致、停更、运维复杂等问题。
而 InnoDB Cluster 是 MySQL 官方推出的一站式、全栈、强一致、全自动高可用集群方案 ,也是目前 8.0 版本官方唯一推荐的企业级标准集群。
很多开发者只知道它基于 MGR,但搞不懂:
✅ InnoDB Cluster 和原生 MGR 的核心区别?
✅ 三层架构各自作用是什么?
✅ 主库宕机完整自愈流程?
✅ 生产哪些坑必须规避?
✅ 到底什么时候选 MGR,什么时候选 InnoDB Cluster?
一、InnoDB Cluster 核心定义
InnoDB Cluster(简称 IC) 是 MySQL8.0 官方原生、完整、一体化的数据库高可用集群解决方案。
它底层完全基于 MGR 组复制,但屏蔽了 MGR 复杂的底层配置、故障处理、拓扑管理,搭配官方路由与管理工具,实现:
强一致数据同步 + 全自动故障转移 + 自动集群自愈 + 自带读写分离 + 极简运维
简单理解:MGR 是底层内核能力,InnoDB Cluster 是封装好的企业级成品集群。
核心定位:替代 MHA、传统主从,成为 MySQL8.0 新时代标准高可用架构。
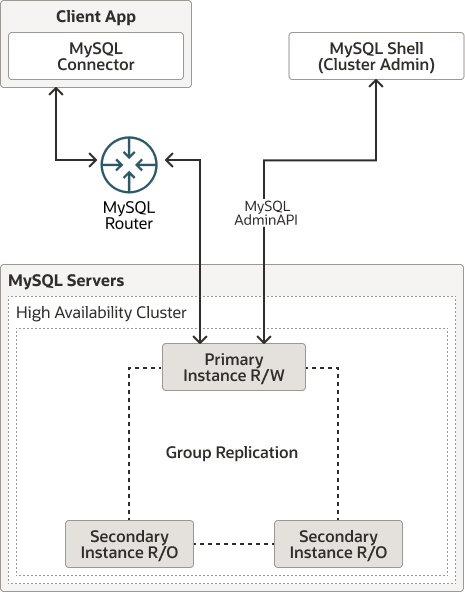
二、InnoDB Cluster 三层架构(核心重点)
InnoDB Cluster 由三大官方核心组件组成,缺一不可,共同构成完整高可用闭环。
2.1 数据层:MGR 组复制集群(底层核心)
集群数据同步、一致性保障的基石。
由 3/5 奇数个 MySQL8.0 节点组成,基于改良 Paxos 共识协议。
核心能力:
-
全局 GTID 事务同步,金融级强一致
-
多数派投票提交,不丢数据、无脑裂
-
节点健康检测、自动角色选举
-
故障节点自动隔离,恢复自动重入
生产默认使用 单主模式:唯一主节点写入,其余节点只读,兼顾一致性与稳定性。
2.2 路由层:MySQL Router(流量入口)
业务唯一访问入口,支持对MGR的主从角色判断,可以配置不同的端口分别对外提供读写服务,实现读写分离,替代 VIP、中间件,实现流量自动调度。
核心能力:
-
自动识别集群主从角色,自动读写分离
-
主节点故障自动熔断、流量秒级切新主
-
从节点负载均衡、故障节点剔除
-
业务零改造,只连接 Router 端口即可
两个默认端口:
-
6446:读写端口,自动路由到主节点
-
6447:只读端口,自动分发到从节点集群
2.3 管理层:MySQL Shell(集群运维中枢)
集群部署、管理、监控、修复的官方工具,替代人工复杂 MGR 配置。
核心能力:
-
一键创建集群、一键添加/剔除节点
-
自动检测节点配置、修复集群异常
-
监控集群健康状态、拓扑状态
-
故障后自动重整集群拓扑
三层架构配合,实现:数据层保一致、路由层保流量、管理层保运维。
三、InnoDB Cluster 完整故障自愈流程(面试必考)
以生产最常用的 3节点单主集群 为例,主节点宕机后,全程全自动、业务无感知。
3.1 步骤1:故障感知与判定
MySQL Shell 持续心跳检测 + MGR 集群节点间通信检测,判定主节点离线、故障。
基于多数派仲裁机制,确认集群有效节点数满足法定人数,避免脑裂。
3.2 步骤2:集群自动选主
集群自动对比剩余从节点的 GTID 事务集合 ,选择数据最完整、最新的节点晋升为新主库。
无需人工干预、无需配置、无需补日志。
3.3 步骤3:路由自动切换流量
MySQL Router 实时监听集群拓扑变化,瞬间识别新主节点。
自动将 6446 读写端口流量切换至新主,拦截旧故障节点请求,业务无中断、无报错。
3.4 步骤4:集群拓扑重整
剩余节点自动跟随新主,同步拓扑信息,集群恢复正常读写状态。
3.5 步骤5:故障节点自愈重入
故障节点重启恢复后,自动拉取集群最新 GTID 事务数据,自动补齐差异,自动重新加入集群,变为从节点。
真正实现故障自动修复、集群自动自愈。
四、InnoDB Cluster 核心优势
4.1 强数据一致性(金融级)
基于 MGR Paxos 多数派提交,事务必须半数以上节点确认才可落地,零数据丢失、零主从不一致、零脑裂。彻底解决 MHA、Keepalived 异步复制数据风险。
4.2 全自动高可用(无需人工值守)
自动选主、自动切换、自动路由、自动自愈、自动拓扑修复,对比 MHA 架构大幅降低运维压力。
4.3 官方全家桶、无第三方坑
所有组件均为 MySQL 官方原生,版本统一、适配完美,无开源停更、兼容bug问题,适配8.0所有新特性(GTID、Replica新语法、并行复制)。
4.4 自带读写分离与负载均衡
依托 MySQL Router 天然实现读写分离,无需程序改造、无需第三方中间件,读压力自动分散到多从节点。
4.5 极简运维、标准化程度极高
MySQL Shell 一键部署、一键扩容、一键修复,屏蔽 MGR 复杂底层细节,适合企业标准化大规模落地。
五、InnoDB Cluster 生产缺点与限制
5.1 硬性环境约束
-
集群节点必须为奇数(3/5节点),保证仲裁有效
-
所有节点 MySQL 版本、参数、配置必须完全一致
-
节点间网络要求高,延迟建议 ≤10ms,网络抖动易触发节点踢出
5.2 业务SQL约束
-
必须使用 InnoDB 引擎,不支持 MyISAM
-
所有表必须有主键
-
禁止超大事务、长事务,易引发集群同步阻塞、节点失联
5.3 架构相对较重
相比简单主从+Keepalived,组件更多、部署流程更规范,小规模轻量业务略显冗余。
六、InnoDB Cluster VS 原生 MGR 核心区别
很多人误以为两者一样,实际本质完全不同。
| 对比维度 | 原生 MGR(组复制) | InnoDB Cluster |
|---|---|---|
| 定位 | 底层数据同步技术 | 完整企业级高可用集群成品 |
| 运维方式 | 手动配置、手动排障、复杂命令运维 | MySQL Shell 一键自动化运维 |
| 流量管理 | 无路由,需自行搭配VIP/中间件 | 自带 MySQL Router 读写分离、负载均衡 |
| 故障自愈 | 仅数据同步自愈,拓扑需人工干预 | 全程全自动拓扑重整、节点重入 |
| 适用场景 | DBA深度运维、定制化集群 | 企业标准化、规模化、生产通用 |
一句话总结 :MGR 是内核能力,InnoDB Cluster 是封装好的商用成品集群。
七、InnoDB Cluster VS MHA / Keepalived 选型对比
| 方案 | 一致性 | 自动自愈 | 运维难度 | 8.0推荐度 |
|---|---|---|---|---|
| 主从+Keepalived | 弱一致,易丢数据 | 无 | 极低 | ⭐⭐⭐ |
| MHA | 弱一致,尽力保数 | 半自动化 | 高 | ⭐⭐ |
| 原生 MGR | 强一致 | 部分自愈 | 中高 | ⭐⭐⭐⭐ |
| InnoDB Cluster | 金融级强一致 | 全自动集群自愈 | 低 | ⭐⭐⭐⭐⭐ |
八、生产最佳选型策略
-
小型非核心业务:主从+Keepalived(够用、轻量)
-
老旧存量系统:MHA(兼容旧架构)
-
核心交易、金融、新业务 :优先 InnoDB Cluster
-
需要自定义深度运维:原生 MGR 单主模式
九、生产落地硬性规范
-
集群必须部署3个奇数节点,严禁偶数节点部署,防止仲裁失效、集群分裂不可用。
-
所有节点统一 MySQL8.0 版本,统一 GTID、ROW 日志、并行复制参数,禁止差异化配置。
-
业务提前规范:所有表加主键、禁用 MyISAM、拆分超大事务。
-
生产独立部署 MySQL Router,不与数据库节点混部,杜绝路由单点故障。
-
严控机房网络质量,节点间网络延迟过高会频繁触发节点驱逐。
-
禁止手动修改底层 MGR 参数、禁止手动操作 Replica 同步,统一通过 MySQL Shell 管理集群。