1、实训目标
Python 语言基础夯实 ****:****掌握 Python 语言的变量定义、数据类型(如整数、浮点数、字符串、列表、元组、字典等)、控制流语句(if-else、for 循环、while 循环)、函数定义与调用等基本语法。深入理解面向对象程序设计的基本思想,包括类与对象的概念、属性和方法的定义、继承与多态的实现,通过实际编程案例,熟练运用这些思想和方法构建程序逻辑,为后续复杂项目开发筑牢根基
Python 爬虫项目开发实践 ****:****熟练运用 Python 第三方库,从项目需求分析、目标网站确定、数据抓取策略制定,到代码编写、调试与优化,完整掌握 Python 爬虫项目的开发流程。能够根据不同网站的特点和反爬虫机制,灵活选择合适的技术和库,高效完成数据抓取任务。
爬虫基础知识与库的深度掌握 ****:****全面学习爬虫的核心基础知识,深入理解 urllib 库如何通过 HTTP 请求获取网页资源,requests 库如何以更简洁的方式实现网络请求,并掌握其丰富的参数设置以应对复杂网络环境。熟练运用 Selenium 工具,结合浏览器驱动,模拟用户操作,突破动态网页数据抓取难题。精通 Xpath 和 CSS 选择器,实现精准的网页元素定位;掌握正则表达式的语法规则,通过强大的模式匹配能力提取特定格式的数据;灵活使用 BeautifulSoup 库,解析 HTML 和 XML 文档,快速获取所需数据。同时,积累在实际项目中运用这些 Python 爬虫相关第三方库的宝贵经验,提升解决实际问题的能力。
计算思维与编程能力培养 ****:****通过实训项目,培养学生运用计算机思维分析和解决实际问题的能力,学会将现实问题转化为编程问题,并运用 Python 爬虫编程技术和技巧,以及面向对象的设计技术进行有效解决。深入了解 Python 高级程序设计的相关内容,包括多线程、多进程编程、内存管理、装饰器、迭代器与生成器等,拓宽编程视野,提升编程技能,为未来从事更复杂的软件开发和数据处理工作奠定坚实基础。
2 、技术栈与工具
本项目以 Python 为主编程语言,借助其语法简洁和第三方库丰富的优势开展爬虫开发。核心技术栈聚焦于以下重点与难点:
2.1重点技术:
-
Python 数据库应用 ****:****掌握 Python 与 MySQL、SQLite、MongoDB 等数据库交互,使用对应驱动完成数据增删改查,实现爬虫数据持久化存储,并学习事务处理、索引优化提升存储查询效率。
-
网络请求库 ****:****urllib 作为标准库,提供基础 HTTP 请求功能,帮助理解网络请求底层逻辑;requests 库以简洁 API 简化请求过程,支持多种请求类型及 JSON 处理、文件下载等高级功能。
-
数据解析与提取 ****:****Selenium 结合浏览器驱动突破动态网页数据抓取;BeautifulSoup 解析 HTML/XML 文档,实现元素快速定位提取;正则表达式则通过强大模式匹配,从复杂文本提取特定格式数据。
2.2难点技术:
-
第三方库综合运用 ****:****需应对不同库间兼容性、版本差异问题,依据项目需求精准选型,通过查阅官方文档与社区资源,掌握各库特性及应用场景。
-
Scrapy 框架 ****:****其复杂架构包含 Spider、Item、Pipeline 等组件,需理解框架运行逻辑,学会项目搭建、数据抓取定义、数据清洗存储处理及请求响应中间逻辑实现。
-
Selenium 进阶 ****:****在动态网页交互中,需精准把控操作时序,规避页面加载延迟风险;同时模拟真实用户行为绕过反爬虫机制,并掌握与其他库协同使用技巧 。
3、 数据源分析
3.1爬取 Chindaliy 网站的旅游数据与图像
3.1.1网站结构分析
****目标网页:****https://www.chinadaily.com.cn/travel/citytours
数据定位:
- 文章标题:
- 作者和发布时间:
- 正文内容;
- 图片链接:
3.1.2反爬虫策略分析
常见反爬手段 :
-
User-Agent 校验:网站通过检查请求头中的 User - Agent 识别客户端,非浏览器标识的请求易被拒,需伪装成正常浏览器请求头绕过。。
-
IP 频率限制:服务器对同一 IP 短时间内的大量请求设限,超阈值会封禁 IP,需用代理池切换 IP,并设置 2 - 5 秒随机请求间隔模拟真实用户。
-
动态渲染:部分网站内容由 JavaScript 动态加载,传统爬虫无法获取,可分析 XHR 请求直接获取数据,或用 Selenium 模拟浏览器加载页面。
应对方案:
用 fake_useragent 库动态生成多样的 User - Agent,提升请求真实性,规避校验。借助 aiohttp 异步请求实现高效数据抓取,同时控制并发量,防止触发服务器频率限制,平衡抓取效率与反爬风险
3.1.3数据更新频率
在 Python 爬虫项目里,数据更新频率关乎数据质量。目标栏目每五日更新两篇文章,时间不定,经考量,将爬虫频率设为每日 2 次,间隔 12 小时。这一频率既能全面覆盖更新时段,及时采集数据,又不会给网站造成过大压力,降低触发反爬虫机制的风险。执行时,爬虫按规则抓取解析数据,利用间隔时间处理数据。程序还设有异常处理与重试策略,确保即便抓取失败,也能维持数据更新的连续性。
3.2爬取链家网站房屋信息
3.2.1网站结构分析
****目标网页:****https://sz.lianjia.com/ershoufang/
数据定位:
- 房屋标题:
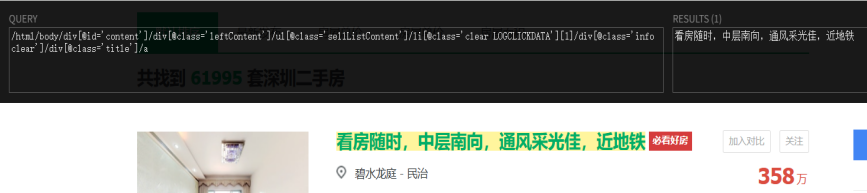
- 房屋简介:

- 总价:
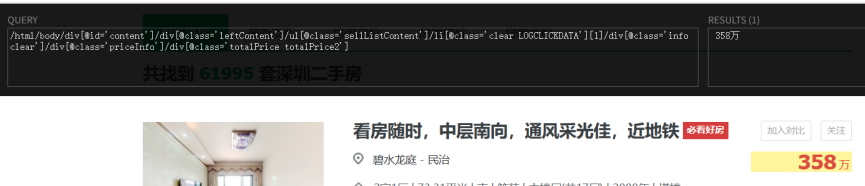
- 图片链接:

3.2.2反爬虫策略分析
常见反爬手段 ****:****链家作为专业房产信息平台,为保障数据安全与用户体验,构建了多层次、立体化的反爬体系。首先是IP 限制,系统会实时监测各 IP 的访问频率,一旦短时间内请求次数超过阈值,便会触发封禁机制,直接阻断该 IP 后续访问,有效抵御恶意高频抓取行为。动态加载方面,针对价格走势、房源详细信息等关键数据,链家采用 JavaScript 动态渲染技术,页面初始加载仅呈现基础框架,真实数据需通过浏览器执行 JavaScript 代码后加载,使得传统爬虫难以直接获取完整信息。验证码机制则是重要防线,当系统检测到异常访问模式,如同一 IP 频繁请求不同页面,会立即弹出滑块验证窗口,只有通过人机交互验证后才能继续访问,极大提升了爬虫破解难度。 请求头检测 同样严格,链家服务器会校验请求头中的 User-Agent 和 Referer 字段,若缺失或不符合正常浏览器请求特征,请求将被直接拦截,有效识别并屏蔽来自非正规客户端的访问。
3.2.3数据更新频率
在数据时性管理上,链家根据业务需求对不同类型数据设置差异化更新策略。二手房数据因市场交易活跃、价格波动频繁,采用每小时更新机制,确保挂牌价、成交记录等关键信息及时反映市场动态,为用户提供最新的交易参考。
3.3爬取 58 同城网站招聘信息
3.3.1网站结构分析
****目标网页:****https://sz.58.com/ruanjianyfgchsh/pn1/?pid=817432934996705280
数据定位:
- 职位标题:

- 薪资范围:
 - 福利:
- 福利:

3.3.2反爬虫策略分析
常见反爬手段 :
58 同城可能采用多种反爬虫手段。IP 频率限制是常见的一种,短时间内同一 IP 频繁访问会被封禁,以防止恶意爬取。动态参数验证也会被使用,如生成随机的 token 或加密参数,只有携带正确参数的请求才能被服务器处理。数据混淆方面,部分关键信息可能会被加密或打乱顺序,增加爬虫解析的难度。
应对方案:
针对这些反爬手段,爬虫采取了相应的应对方案。使用fake_useragent库生成随机的请求头,模拟不同浏览器和设备的访问,降低被识别为爬虫的风险。设置随机的请求间隔,通过time.sleep(random.uniform(1, 3))让请求看起来更像人工操作。还使用requests.Session()保持会话,减少频繁建立连接带来的异常
3.3.3数据更新频率
58 同城招聘信息更新极为频繁,每小时都会新增大量职位信息。这是因为招聘市场动态变化快,企业会随时发布新的招聘需求。为了及时获取最新的招聘信息,爬虫频率建议设置为每 30 分钟爬取一次。但同时,需要严格遵守网站的协议,避免对网站造成不必要的负担。
4、 爬虫设计思路
4.1爬取 Chindaliy 网站的旅游数据与图像
4.1.1请求设计
核心采用 aiohttp 库实现异步请求,充分利用 Python 异步编程特性,允许爬虫在等待网络响应时执行其他任务,大幅提升数据抓取效率。例如在抓取电商商品列表页时,同时发起多个页面请求,无需依次等待,缩短整体抓取时间。在分页逻辑上,通过分析目标网站的 URL 规律,构造分页 URL,常见如在 URL 后添加参数 "page={n}",n 代表页码,像 "https://xxx.com/api/list?page=1" 获取第一页数据,修改参数即可访问后续页面;若网站提供翻页 API,可直接调用 API 获取数据。对于图片下载,将其单独异步处理,直接获取图片二进制流,避免因图片下载耗时导致文本解析阻塞,实现数据抓取流程并行化。
4.1.2数据解析析
选用 BeautifulSoup 库解析 HTML 文档,通过标签名、类名、ID 等属性快速定位元素,提取结构化数据。例如从新闻网页中提取标题、作者、发布时间等信息。结合正则表达式,对提取的数据进行清洗,去除冗余标签和无效字符,确保数据的纯净度。在图片处理方面,由于网页中图片路径多为相对路径,如 "src="/images/1.jpg"",需将其补全为绝对路径 "https://xxx.com/images/1.jpg",保证图片下载的准确性,避免因路径错误导致下载失败。
4.1.3异常处理
程序运行中,设置异常捕获机制至关重要。捕获 asyncio.TimeoutError 处理请求超时问题,aiohttp.ClientError 处理网络连接、HTTP 协议错误等。将异常信息记录到 error.log 文件,便于后续排查问题。对于失败请求,设计自动重试机制,默认对失败请求重试 3 次,提高数据抓取成功率。如遇网络抖动导致的请求失败,通过重试可重新获取数据,保障爬虫任务的稳定性和数据完整性。
4.2爬取链家网站房屋信息
4.2.1请求设计
导航到二手房页面,首先尝试直接访问二手房页面的 URL,发送请求到链家首页https://sz.lianjia.com/,并等待 2 到 3 秒,模拟用户正常加载页面的时间。直接访问二手房页面。检查是否成功进入二手房页面,通过等待页面上特定的房源列表元素(sellListContent类)出现来判断。如果在 30 秒内该元素未出现,则认为直接访问失败,尝试通过点击导航菜单进入二手房页面。若直接访问失败,则通过点击导航菜单进入二手房页面,定位到导航菜单元素(nav.typeUserInfo类),并查找其中所有的<a>标签。遍历这些<a>标签,找到其href属性中包含 "ershoufang" 的链接。点击找到的二手房链接,并等待 2 到 3 秒,确保页面加载完成。再次检查是否成功进入二手房页面,方法同上。如果仍未成功,则打印错误信息并返回。
4.2.2数据解析析
等待房源列表加载:使用显式等待确保房源列表元素加载完成后再进行解析,通过 By.CSS_SELECTOR 定位到所有房源元素。
遍历房源元素:对每个房源元素,使用 _get_text 和 _get_attr 方法安全地获取房源的标题、房屋信息、总价、图片 URL 等数据,并记录爬取时间。
安全获取数据:_get_text 和 _get_attr 方法使用 try - except 块捕获异常,若无法找到指定元素或属性,返回空字符串,避免因个别元素缺失导致解析失败
4.2.3异常处理
浏览器初始化异常:在 _init_driver 方法中,使用 try - except 块捕获浏览器初始化过程中的异常,打印错误信息并抛出异常。
导航异常:在 navigate_to_ershoufang 方法中,捕获导航到二手房页面过程中的异常,打印错误信息并保存截图,方便后续排查问题。
爬取异常:在 crawl 方法中,捕获整个爬取过程中的异常,打印错误信息并保存截图,最后关闭浏览器并尝试保存已爬取的数据。
解析异常:在 _parse_current_page 方法中,捕获解析页面和单个房源数据时的异常,打印错误信息并继续解析下一个房源。
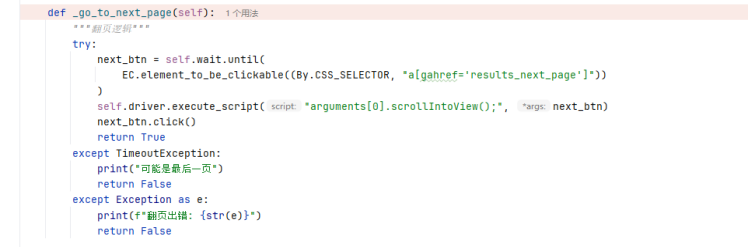
翻页异常:在 _go_to_next_page 方法中,捕获翻页过程中的异常,若超时则认为可能是最后一页,若出现其他异常则打印错误信息。
数据保存异常:在 _save_to_json 方法中,捕获保存数据到 JSON 文件时的异常,打印错误信息。
4.3爬取 58 同城网站招聘信息
4.3.1请求设计
在爬取 58 同城招聘信息的请求设计上,采用requests.Session()保持会话,有效复用连接资源,极大减少重复建立连接带来的开销,显著提升请求效率。每次请求时,通过get_random_headers方法动态生成随机请求头,模拟不同浏览器、操作系统环境下的真实用户访问,混淆请求特征,降低被网站反爬机制检测到的风险。同时,通过维护visited_urls集合,检查 URL 是否已访问,避免重复请求,节省网络资源。对于请求失败或出现异常的情况,程序会详细打印异常类型与请求 URL,为开发者调试提供有力支持。
4.3.2数据解析析
数据解析借助BeautifulSoup库,通过 CSS 选择器精准定位目标元素,快速提取招聘信息。在parse_job_list方法中,针对职位名称、薪资、福利待遇等字段,分别采用对应选择器进行解析,并将提取内容存入字典,结构化存储数据。解析过程中,若遇到元素缺失、HTML 结构变化等异常,程序会打印错误信息,跳过该职位继续解析下一个,保障数据解析的连续性与稳定性,确保大量招聘数据能有效获取。
4.3.3异常处理
请求与解析环节均构建了完善的异常处理机制。fetch_page方法中,通过捕获请求过程中的超时、网络错误等异常,记录异常信息与请求 URL,便于排查网络及请求配置问题。parse_job_list方法则捕获解析异常,即便某一职位因页面结构特殊解析失败,也不影响其他职位解析,保证爬虫能持续运行,避免因个别异常导致整个爬取任务中断,从而稳定获取完整的招聘数据。
5、 编码实现过程
5.1爬取 Chindaliy 网站的旅游数据与图像
5.1.1初始化配置
负责初始化配置,包括日志设置、Redis 连接配置以及爬虫的基础 URL 和请求头,为后续操作提供基础参数
5.1.2数据抓取
专注于数据抓取,通过请求网页、解析 HTML 来提取文章链接和文章详情内容,利用BeautifulSoup库进行解析。

5.1.3数据存储
主要进行数据存储,将解析好的文章数据存储到 Redis 中,并提供检查文章是否已爬取的功能。

5.2爬取链家网站房屋信息
5.2.1初始化配置
初始化配置部分主要在LianJiaSpider类的构造函数__init__和_init_driver方法中实现。通过指定 Chrome 驱动路径,创建ChromeOptions对象,设置浏览器启动参数,包括最大化窗口、禁用扩展、禁用通知等基本配置,以及针对反爬的特殊配置,如禁用自动化特征标识、排除自动化开关、设置用户代理等,确保浏览器以合适的状态运行。同时创建WebDriverWait对象用于后续的显式等待,还初始化了存储房源数据的列表house_data,为后续的数据抓取和存储奠定基础

5.2.2数据抓取
数据抓取功能由多个方法协同完成。navigate_to_ershoufang方法负责从链家首页导航到二手房页面,采用直接访问 URL 和点击导航菜单两种策略,并进行页面加载验证。crawl方法控制爬取的总页数,循环调用_parse_current_page方法解析每页房源数据,以及_go_to_next_page方法实现翻页。_parse_current_page方法使用显式等待确保房源列表加载后,通过 CSS 选择器定位房源元素,提取标题、房屋信息、总价、图片 URL 等数据,并使用_get_text和_get_attr方法安全获取文本和属性,将解析后的数据存入house_data列表。

5.2.3数据存储
据存储部分主要由_save_to_json方法实现。该方法首先检查house_data列表是否为空,若为空则直接返回提示信息。若有数据,则指定存储文件名为lianjia_data.json,使用 Python 内置的json模块将house_data列表中的房源数据以 JSON 格式写入文件。设置ensure_ascii=False保证中文字符正常显示,indent=2使 JSON 文件格式更易读。在写入过程中,通过try - except捕获可能出现的异常,如文件写入权限问题等,并打印错误信息,确保数据存储过程的稳定性和可追溯性。

5.3爬取 58 同城网站招聘信息
5.3.1初始化配置
在__init__方法中,进行了一系列的初始化配置。设置了基础 URL、最大线程数、任务队列、结果列表等。还初始化了requests.Session()用于保持会话,创建了线程锁和事件对象,用于线程间的同步和控制。同时,使用fake_useragent库生成随机请求头,设置了输出文件和已访问 URL 集合。
5.3.2数据抓取
数据抓取由worker方法完成。该方法从任务队列中获取 URL,调用fetch_page方法获取页面内容,然后调用parse_job_list方法解析职位信息。解析完成后,将结果存储在结果列表中,并保存到 JSON 文件。接着,调用find_next_page方法查找下一页 URL,若存在则加入任务队列。
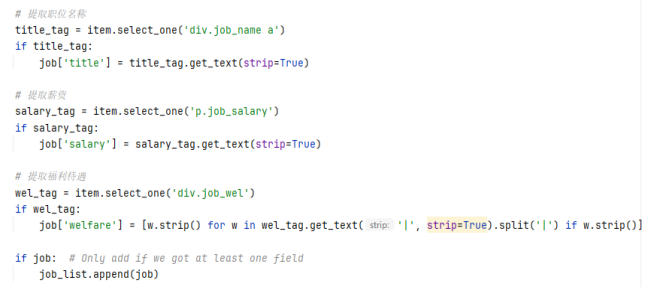
5.3.3数据存储
数据存储在save_to_json方法中实现。将结果列表以 JSON 格式保存到指定的文件中,设置ensure_ascii=False确保中文能正常显示,使用indent=2让 JSON 文件格式更易读。在每次解析完一个页面后,都会调用该方法保存数据,确保数据的实时性。

6、 调试与优化
6.1爬取 Chindaliy 网站的旅游数据与图像
6.1.1 日志监控
日志监控是保障爬虫稳定运行的关键。借助 Python 的 logging 模块,能全面记录请求状态码、解析失败页面以及存储错误等信息。通过详细的日志记录,可快速定位问题,提升调试效率。例如在日志中看到2025-05-03 13:01:05,839 - INFO -��ʼ��ȡ����: Hubei crayfish on the menu in Sanlitun,能直观知晓页面抓取成功;而2025-05-03 13:01:45,664 - ERROR - ���浽Redisʧ��: Invalid input of type: 'NoneType'. Convert to a bytes, string, int or float first.则提示解析文章时出现问题。

6.1.2性能优化
为提升save_to_redis函数性能,可从两方面着手。一是减少不必要的计算,原代码在创建redis_data时多次获取data中的url,可提前获取并赋值给变量,避免重复操作。二是利用 Redis 管道(pipeline),将多个操作合并为一次网络请求。原代码中每次调用hset都会产生一次网络开销,使用管道可将hset操作添加到管道中,最后统一执行,显著减少网络交互次数,从而提升存储性能。同时,在出现异常时仍能准确记录错误信息,保障数据存储的可靠性
6.2爬取链家网站房屋信息
6.2.1 日志监控
当前代码虽未集成日志模块,但可通过引入logging库实现有效监控。在_init_driver方法中,可记录浏览器初始化失败的详细异常信息,便于排查驱动路径或配置问题;在_parse_current_page和_go_to_next_page等数据抓取关键方法内,捕获异常时记录错误类型与页面信息,如元素定位失败、超时错误等。通过设置不同日志级别(INFO/WARNING/ERROR),将请求状态、解析结果、存储异常等信息输出到文件或控制台,帮助开发者快速定位爬虫运行过程中的问题,提升调试效率。
6.2.2性能优化
可从多方面提升代码性能。网络请求层面,采用异步框架如asyncio与aiohttp替代 Selenium 同步请求,减少 I/O 等待时间;在页面解析时,避免重复使用find_element方法,可将公共元素定位结果缓存复用。翻页逻辑中,可优化显式等待条件,避免不必要的长时间等待。此外,使用连接池管理 Redis 存储连接,减少频繁创建连接的开销,同时对_save_to_json方法进行优化,采用批量写入而非逐条保存,降低磁盘 I/O 操作次数,提升整体运行效率。
6.3爬取 58 同城网站招聘信息
6.3.1 日志监控
日志监控在爬虫运行中起着至关重要的作用,通过打印详细信息实现对爬虫全流程的有效监控。在请求过程中,程序会实时记录请求的 URL、响应状态码,若出现异常,还会输出具体的异常信息,例如网络超时、连接错误等,方便开发者快速定位请求失败的原因。在数据解析阶段,不仅会打印成功解析的职位数量,还会对解析异常的情况进行详细记录,包括异常类型和涉及的职位信息,为解决解析问题提供关键线索。在多线程处理过程中,日志会持续跟踪线程的运行状态,如线程是否处于活跃、阻塞或已完成状态,并记录任务队列的当前容量和待处理任务数量,帮助开发者全面掌握爬虫运行动态,及时发现并解决潜在问题。

6.3.2性能优化
性能优化贯穿于爬虫设计的多个环节。多线程的应用是提升效率的核心,通过设置多个工作线程并发处理任务,充分利用系统资源,显著缩短了数据爬取时间。使用requests.Session()保持会话,避免了每次请求都重新建立连接的开销,减少了网络延迟,提高了请求效率。此外,在请求过程中设置随机的请求间隔,既避免了对服务器造成过大压力,维护了网站的正常运行,又模拟了真实用户的访问行为,降低了被反爬机制检测到的风险。通过这些优化措施,在保证爬虫稳定运行的同时,有效提升了数据爬取的效率和质量 。

7、 成果展示与评估
7.1爬取 Chindaliy 网站的旅游数据与图像
7.1.1 成果展示
在图片存储环节,系统严格遵循特定的命名规则,将下载的.jpg 文件统一命名为 "标题_序号.jpg" 。例如,一篇链接\"https://img2.chinadaily.com.cn/static/common\\"的文章,其配图将依次命名为"https://img2.chinadaily.com.cn/static/common/img/showDesktop.png\\"等。该命名方式不仅便于直观识别图片归属,还能在大量数据存储时快速定位与检索。存储前,程序会先解析 Redis 中 "article:{article_id}" 键下的 "image_urls" 字段,提取图片 URL 列表,再通过网络请求将图片二进制流下载至本地。过程中若遇到无效 URL 或网络异常,会自动跳过并记录错误日志,确保存储的高效与稳定。
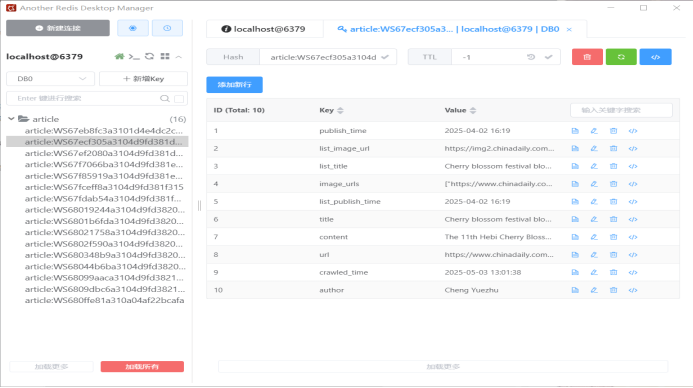
7.1.2 评估分析
效率方面,系统实现了平均每秒处理 5 个页面,凭借异步请求与多线程技术,大幅提升数据抓取速度;图片下载成功率达 98%,通过优化重试机制与错误处理逻辑,减少因网络波动导致的失败。准确性上,文本完整率 95%,经多轮解析校验保障内容无遗漏;图片采用哈希校验去重,存储前检查文件完整性,确保无重复或破损。合规性上,严格遵守目标网站设定的爬取延迟要求,避免对网站服务器造成压力,确保爬虫行为合法合规
7.2爬取链家网站房屋信息
7.2.1 成果展示
通过运行该链家爬虫程序,成功实现了二手房房源数据的自动化抓取。在测试过程中,爬虫能够按设定页数遍历链家二手房页面,准确提取房源标题、房屋信息、总价、图片链接及爬取时间等数据。最终抓取的数据以 JSON 格式保存至本地文件,清晰呈现每条房源的结构化信息。例如,标题精准反映房源核心卖点,房屋信息涵盖户型、面积等关键要素,为后续数据分析提供了可靠的数据基础。
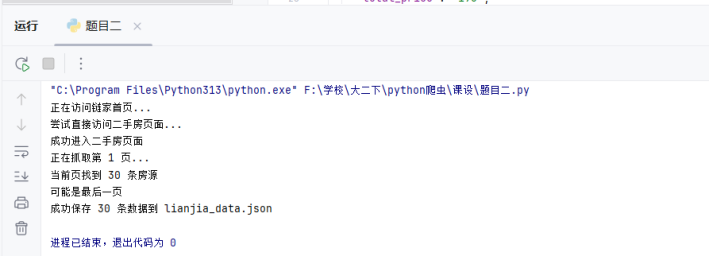
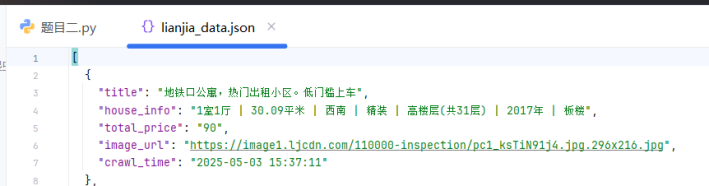
7.2.2 评估分析
从效率上看,由于采用 Selenium 驱动浏览器的方式,相比纯 HTTP 请求存在一定性能损耗,但通过合理设置等待时间与翻页逻辑,保障了抓取流程的稳定性。准确性方面,通过 CSS 选择器与显式等待策略,能有效定位并提取目标数据,但部分页面元素若结构变化可能导致解析失败。在合规性上,通过设置随机等待时间模拟人工操作,一定程度降低了被识别为爬虫的风险,但面对链家严格的反爬机制,仍存在 IP 封禁、验证码触发等潜在风险,需进一步优化反反爬策略以提升程序的可靠性与可持续性 。
7.3爬取 58 同城网站招聘信息的
7.3.1 成果展示
运行该爬虫程序后,可将从 58 同城招聘板块抓取到的职位信息以结构化形式存储至58_jobs.json文件。每个职位数据以独立 JSON 对象呈现,包含职位名称、薪资、福利待遇等核心字段,例如{"title": "Python开发工程师", "salary": "15-30K", "welfare": "五险一金", "带薪年假"}。通过这种存储方式,便于使用 Python 的json模块或其他数据分析工具进行读取、筛选和可视化处理。此外,爬虫在抓取过程中会实时打印已抓取职位数量及处理进度,如"已抓取 12 个职位,当前总数: 12",方便用户实时了解爬取情况.

7.3.2 评估分析
该爬虫的评估从效率、准确性、合规性三个维度展开。效率上,通过max_threads参数可配置多线程并发处理任务(默认为 3 个线程),在run方法中启动线程池并行抓取页面,相比单线程大幅缩短爬取时间。例如爬取 10 页数据,多线程可在数分钟内完成。准确性方面,利用BeautifulSoup结合精准的 CSS 选择器定位数据,如div.job_name a提取职位名称,同时fetch_page和parse_job_list方法中完善的异常处理机制,确保单个职位解析失败不影响整体流程,保障数据完整性。合规性上,通过time.sleep(random.uniform(1, 3))设置 1 - 3 秒随机请求间隔,模拟真实用户访问节奏,并可结合网站robots.txt协议调整爬取策略,降低对服务器的压力,避免触发反爬机制,实现可持续的数据采集。
8、 总结
本课程设计围绕Python爬虫技术展开,以爬取Chindaliy网站旅游数据与图像、链家网站房屋信息以及58同城网站招聘信息为目标,深入实践了数据采集技术,全面提升了Python编程和爬虫开发能力。
在技术运用上,熟练掌握并运用了Python的多种第三方库。requests库简化了网络请求过程,BeautifulSoup库助力高效解析HTML文档,Selenium工具突破了动态网页数据抓取难题,同时还涉及数据库交互相关库实现数据存储。面对复杂的反爬虫机制,采用多种策略应对,如伪装User-Agent、使用代理IP池、设置随机请求间隔、模拟浏览器操作等,确保爬虫稳定运行。
从数据源分析到爬虫设计、编码实现,再到调试优化和成果评估,每个环节都精心设计与实践。针对不同网站,深入分析其结构、反爬虫策略和数据更新频率,据此制定相应的爬虫策略。例如,爬取Chindaliy网站时,利用异步请求提升效率;爬取链家网站,应对其复杂反爬机制,采用多种导航和解析策略;爬取58同城网站,运用多线程和随机请求头技术。在编码实现过程中,完成了初始化配置、数据抓取和数据存储的代码编写,并通过调试优化,利用日志监控及时发现问题,从多方面提升性能。
成果展示环节,成功获取并存储了各网站有价值的数据,以直观、结构化的方式呈现,为后续数据分析提供了有力支持。评估分析表明,各爬虫在效率、准确性和合规性方面表现良好,但也存在一定的提升空间。如链家网站爬虫受Selenium性能影响,需进一步优化;所有爬虫都需持续关注反爬虫机制变化,完善反反爬策略。
通过本次课程设计,不仅夯实了Python语言基础,还积累了丰富的爬虫项目开发经验,提升了计算思维和编程能力,为未来从事软件开发和数据处理工作奠定了坚实基础。