微调DeepSeek等AI大模型并部署在ollama上
对于很多算力有限(比如只有CPU、没有高端GPU)的小伙伴来说,想拥有一个专属的AI大模型,既不用承担高额的算力成本,又能贴合自己的需求(比如本文的法律小助手),其实并不难。本文就以DeepSeek轻量化模型为例,手把手教大家用llama-factory框架+LoRA算法完成模型微调,最后部署到Ollama上,实现本地对话自由,全程实操无门槛,CPU也能轻松驾驭~
一、前期准备:明确核心工具与选型逻辑
在开始实操前,先和大家说清楚为什么选这些工具,避免盲目跟风,也能帮大家理解每一步的意义。
1. 模型选型:DeepSeek轻量化模型(CPU友好)
核心选型逻辑:轻量化、低资源、CPU可直接运行
既然是CPU部署,核心就是"轻量化"------我最终选用了 DeepSeek-R1-1.5B 模型,这是DeepSeek家族中参数量最小(仅15亿参数量)、资源需求最低的版本,通过蒸馏技术保留了核心能力,同时适配低资源环境,无需GPU,仅靠CPU就能完成微调与推理,完美解决"电脑带不动"的痛点。
如果你的CPU性能稍好,也可以选择DeepSeek-7B的量化版本(推荐Q6或Q8版本),体积更小、运行更快,同样无需GPU支持。
HuggingFace 是一个集中管理和共享预训练模型的平台 https://huggingface.co;
从 HuggingFace 上下载模型有多种不同的方式,可以参考:如何快速下载huggingface模型------全方法总结
bash
1. 首先创建文件夹统一存放所有基座模型
mkdir Hugging-Face
2.修改 HuggingFace 的镜像源
export HF_ENDPOINT=https://hf-mirror.com
3.修改模型下载的默认位置
export HF_HOME=这里放置你的Hugging-Face文件夹所在的绝对路径
#注意:这种配置方式只在当前 shell 会话中有效,如果你希望这个环境变量在每次启动终端时都生效,可以#将其添加到你的用户配置文件中(修改 ~/.bashrc 或 ~/.zshrc)
#检查环境变量是否生效
echo $HF_ENDPOINT
echo $HF_HOME
4.安装 HuggingFace 官方下载工具
pip install -U huggingface_hub
5.执行下载命令
hf download deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B2. 微调框架:llama-factory(新手友好+高效便捷)
框架核心优势:零代码、可视化WebUI、支持多模型/多算法、新手无门槛,环境变量名统一为 llama-factory
微调框架我选用了 llama-factory(由清华大学相关团队开发,开源社区广泛认可),它是一款一站式大模型微调框架,口号是"让大模型微调像呼吸一样简单",核心优势就是新手友好、支持多种模型和微调算法,而且无需复杂代码编写,甚至提供可视化WebUI,哪怕是零基础也能快速上手。
官方GitHub地址:https://github.com/hiyouga/LLaMA-Factory.git
3. 微调算法:LoRA(低资源+高质量)
算法核心优势:参数量减少90%+、不改动原始模型参数、CPU可快速完成、避免灾难性遗忘
考虑到CPU算力有限,微调算法必须兼顾"高效"和"高质量",LoRA(Low-Rank Adaptation) 算法就是最佳选择。
LoRA的核心原理很简单:不改动原始模型的任何参数(相当于"冻结"基座模型的核心骨架),只在模型层间插入一个轻量级适配器,将微调所需的参数矩阵分解为两个低秩矩阵(B矩阵和A矩阵)的乘积,这样能将微调的参数量减少90%以上,既降低了存储复杂度,让CPU也能快速完成微调,又能最大程度保留原始模型的能力,避免出现"灾难性遗忘",兼顾速度与质量。
二、克隆项目并配置环境(CPU可直接运行)
关键提醒:全程使用统一环境变量名 llama-factory,避免环境冲突,所有命令直接复制粘贴即可运行
这一步的核心是"隔离环境+安装依赖",避免和其他项目的环境冲突,同时确保llama-factory能正常运行,全程用命令行操作,复制粘贴即可。
1. 克隆llama-factory项目
打开终端,输入以下命令,这里本身配备GPU的同学可以直接克隆到本地,没有GPU的同学建议将项目克隆到远程云服务器上:
bash
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
### 2. 查看项目README,明确核心逻辑
克隆完成后,建议先打开项目根目录下的 `README.md` 文件(用记事本、VS Code均可打开),快速浏览核心内容:llama-factory的微调逻辑很简单------通过 `data` 文件夹中的JSON数据集进行训练,数据集格式需和文件夹内的示例文件(如 `alpaca.json`)保持一致,后续我们的法律小助手数据集也会遵循这个逻辑配置。
### 3. 创建并配置conda环境(关键:避免环境冲突)
为了防止项目环境冲突,我们用conda创建一个专属环境,环境变量名统一为 `llama-factory`,步骤如下(前提是你已经安装了Anaconda或Miniconda,没有安装的小伙伴可以先去官网下载,安装后重启终端):
1. **创建环境**(环境名固定为 `llama-factory`,Python版本严格遵循llama-factory官方要求,需≥3.11):
```bash
conda create -n llama-factory python=3.11 -y-
激活环境 (后续所有操作都要在这个
llama-factory环境中进行,至关重要):bashconda activate llama-factory -
安装项目依赖包(复制命令直接运行,耐心等待安装完成,CPU环境无需额外配置GPU相关依赖):
bashpip install -e ".[torch,metrics]"
验证环境 :安装完成后,输入 llamafactory-cli version,若能显示版本号,说明 llama-factory 环境配置成功。
三、准备法律小助手数据集(Alpaca格式)
核心说明 :微调的核心是"数据",大家可根据自身需求准备对应场景的数据集(如医疗、教育、办公等),本文以法律小助手为例,演示数据集的准备方法,格式统一遵循llama-factory支持的Alpaca格式。
我们要训练法律小助手,就需要准备贴合法律场景的问答数据集,格式采用llama-factory支持的Alpaca格式(最通用的微调格式,单轮、多轮对话都支持),同时可以参考最高法的人民法院案例库、法答网中的内容,提取真实法律问答场景,让模型更具实用性。
1. 数据集格式要求
必看要求 :数据集需放在项目的 data 文件夹中,格式为JSON,核心字段如下(必填字段标红):
- instruction :用户指令(必填),比如"解答民法典中关于民间借贷的问题";
- input:用户输入(选填),比如具体的案件细节、疑问点;
- output :模型回答(必填),需准确、专业,可参考法答网的精选答问或人民法院案例库的裁判逻辑;
- system:系统提示词(选填),用于定义模型角色,比如"你是一名专业的法律小助手,熟悉民法典、刑法等相关法律,回答简洁、准确,贴合普通人的理解需求";
- history:对话历史(选填),用于多轮对话训练,单轮对话可留空。
2. 法律小助手数据集示例(可直接复用)
在 data 文件夹中新建一个JSON文件,命名为 law_assistant.json,复制以下内容(结合民法典相关场景,补充真实法律逻辑,可直接作为模板修改):
json
[
{
"instruction": "解答民间借贷相关疑问",
"input": "别人向我借了5万元,没有写借条,只有转账记录,到期后不还钱,我能起诉他吗?",
"output": "可以起诉。根据《民法典》第六百七十九条规定,自然人之间的借款合同,自贷款人提供借款时成立。转账记录可以作为借款关系成立的证据,虽然没有借条,但结合转账记录、双方沟通记录(如聊天记录)等,能够证明借款事实和借款金额的,法院会支持你的诉讼请求。建议先与对方协商,协商不成的,可向被告住所地或合同履行地法院提起民事诉讼,准备好转账凭证、沟通记录等相关证据。",
"system": "你是一名专业的法律小助手,熟悉《民法典》《民事诉讼法》等相关法律规定,擅长解答普通人常见的法律疑问,回答简洁明了、通俗易懂,同时保证法律专业性,避免误导用户。",
"history": []
},
{
"instruction": "解释自甘风险原则",
"input": "我和朋友一起打球,被朋友不小心撞伤,能要求他赔偿吗?",
"output": "一般情况下不能要求赔偿,适用自甘风险原则。根据《民法典》第一千一百七十六条规定,自愿参加具有一定风险的文体活动,因其他参加者的行为受到损害的,受害人不得请求其他参加者承担侵权责任;但是,其他参加者对损害的发生有故意或者重大过失的除外。打球属于具有一定风险的文体活动,你自愿参加,朋友系不小心撞伤,无故意或重大过失,因此无需承担赔偿责任。",
"system": "你是一名专业的法律小助手,熟悉《民法典》《民事诉讼法》等相关法律规定,擅长解答普通人常见的法律疑问,回答简洁明了、通俗易懂,同时保证法律专业性,避免误导用户。",
"history": []
},
{
"instruction": "解答彩礼返还相关问题",
"input": "我和女方订婚,给了10万元彩礼,现在双方分手,我能要回彩礼吗?",
"output": "可以要求返还彩礼,具体返还比例需结合实际情况。根据《民法典婚姻家庭编司法解释(一)》第五条规定,当事人请求返还按照习俗给付的彩礼的,如果查明属于以下情形,人民法院应当予以支持:(一)双方未办理结婚登记手续;(二)双方办理结婚登记手续但确未共同生活;(三)婚前给付并导致给付人生活困难。你和女方仅订婚,未办理结婚登记手续,符合第一种情形,可要求女方返还彩礼,双方可协商返还金额,协商不成的可向法院起诉。",
"system": "你是一名专业的法律小助手,熟悉《民法典》《民事诉讼法》等相关法律规定,擅长解答普通人常见的法律疑问,回答简洁明了、通俗易懂,同时保证法律专业性,避免误导用户。",
"history": []
}
]3. 配置数据集(关键步骤,避免训练报错)
关键提醒:新建数据集后,必须配置此步骤,否则llama-factory无法识别数据集,导致训练失败
新建数据集后,需要在 data 文件夹中的 dataset_info.json 文件中添加数据集配置(相当于告诉llama-factory"这个数据集是用来训练的"),步骤如下:
-
打开
data/dataset_info.json文件; -
在JSON文件的最上方,添加以下内容(与其他数据集配置格式保持一致):
json"law_assistant": { "file_name": "law_assistant.json", "columns": { "instruction": "instruction", "input": "input", "output": "output", "system": "system", "history": "history" }, "type": "alpaca" } -
添加完成后保存文件,这样llama-factory就能识别我们的法律小助手数据集了。
四、可视化微调模型(WebUI操作,零代码)
核心优势:零代码、可视化操作,无需编写复杂命令,CPU用户可正常运行(训练速度略慢,耐心等待即可)
llama-factory提供了WebUI界面,无需编写复杂命令,点点鼠标就能完成微调,非常适合新手,CPU用户也能正常运行(只是训练速度会比GPU慢一点,耐心等待即可)。
1. 启动WebUI
在终端(已激活 llama-factory conda环境、处于LLaMA-Factory项目目录下)输入以下命令,启动WebUI:
bash
llamafactory-cli webui启动成功后,终端会显示访问地址(通常是 http://127.0.0.1:7860),复制地址在浏览器中打开,即可看到WebUI界面。
2. WebUI参数配置(核心步骤,按以下设置即可)
进入WebUI后,切换到 「Train」 标签页,按照以下步骤配置参数(所有参数都按默认值或以下建议设置,适配CPU环境,关键参数标红):
-
Model(模型配置):
- **Model name **:输入
deepseek-ai/deepseek-r1-1.5b找到对应的模型
- **Model name **:输入
-
Finetuning(微调配置):
- Finetuning method :选择 lora(我们选用的LoRA算法,适配CPU,必选);
-
Dataset(数据集配置):
- Dataset :搜索并选择 law_assistant(我们刚才创建的法律小助手数据集,必选);
-
Hyperparameters(超参数配置,适配CPU,关键设置):
- Per device train batch size :设置为 1(CPU算力有限,避免内存溢出,必改);
- Gradient accumulation steps :设置为 4(累积梯度,提升训练效果,推荐);
- Learning rate :设置为
1.0e-4(学习率,默认值即可,过高易过拟合); - Num train epochs :设置为 3(训练轮数,CPU训练3轮即可,过多易过拟合);
- 其他参数默认即可。
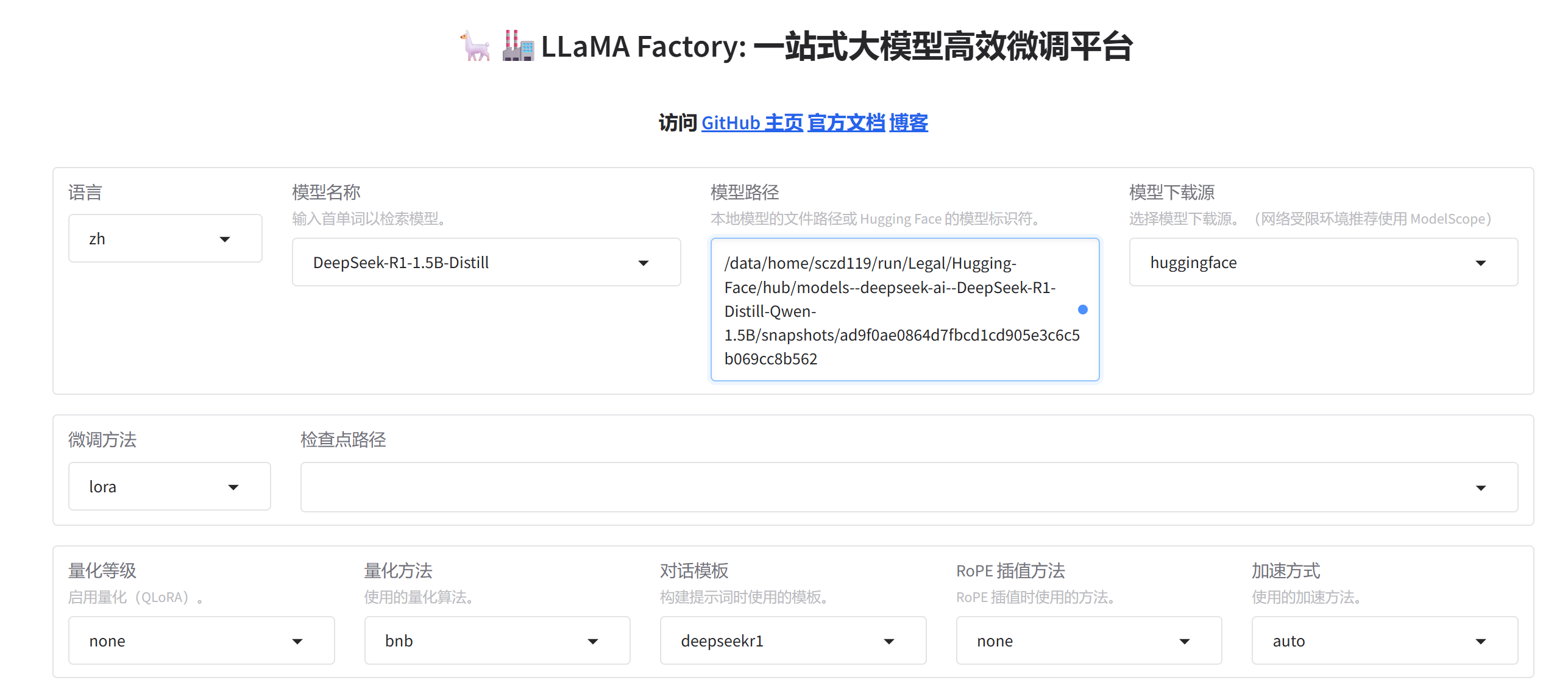
3. 启动训练
提醒:CPU训练速度较慢(1.5B模型,3轮训练大概需要1-2小时,具体看CPU性能),训练期间不要关闭终端和浏览器,耐心等待即可。
参数配置完成后,点击页面底部的 「Start Training」 按钮,即可开始微调。训练过程中,终端会显示训练进度、loss(损失值)等信息,loss值逐渐下降,说明训练正常。
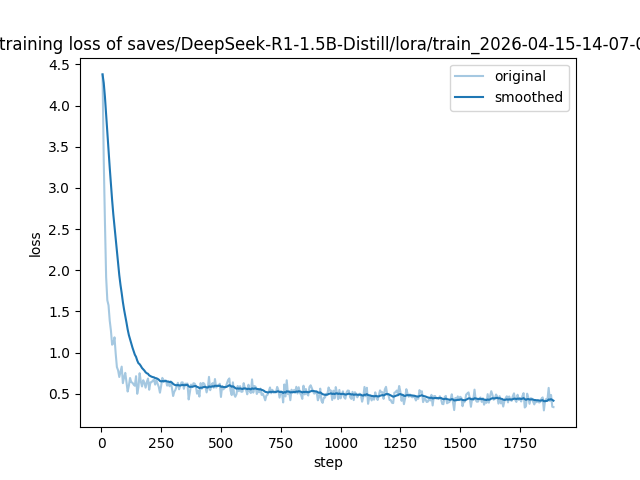
五、模型测评与导出
训练完成后,我们需要先测评模型效果,确认模型学到了目标知识,再导出模型,为后续部署到Ollama做准备。
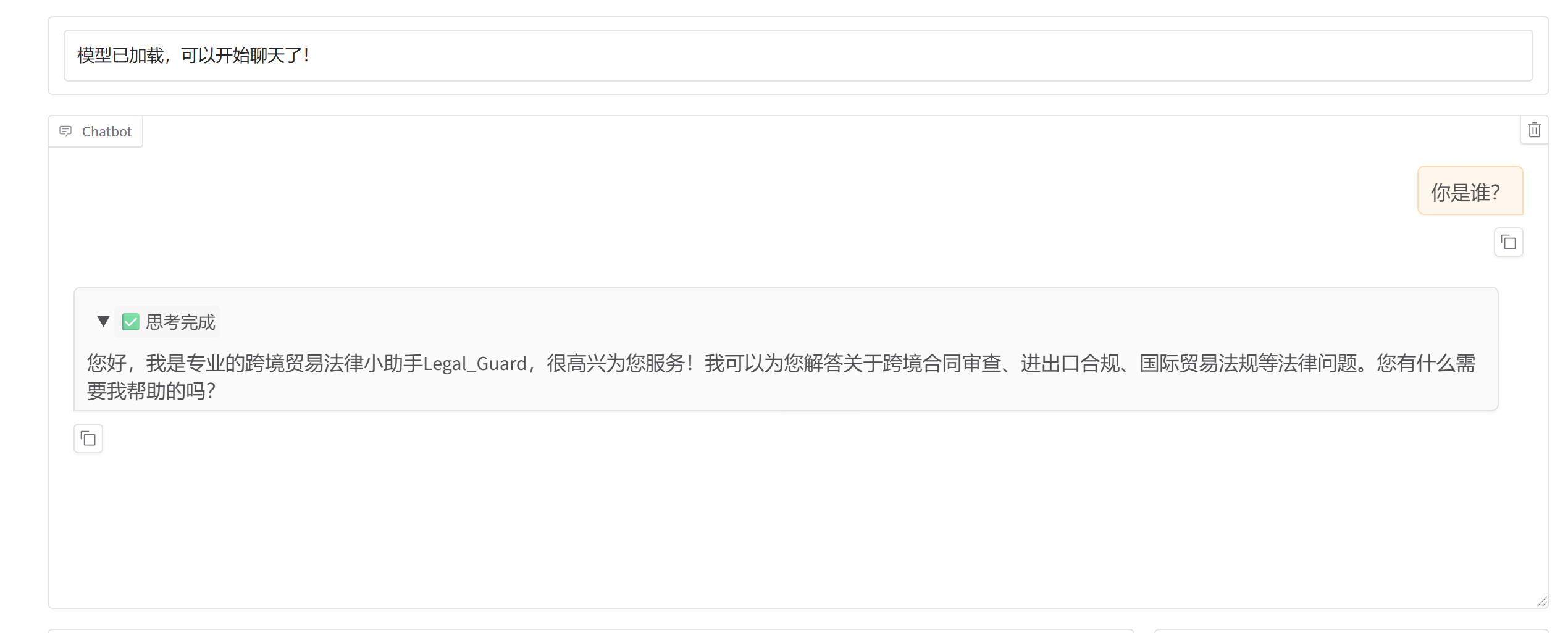
1. 模型测评(简单直观,手动测试)
训练完成后,切换到WebUI的 「Chat」 标签页,选择检查点路径为最新一次的训练文件夹 进行手动测评:
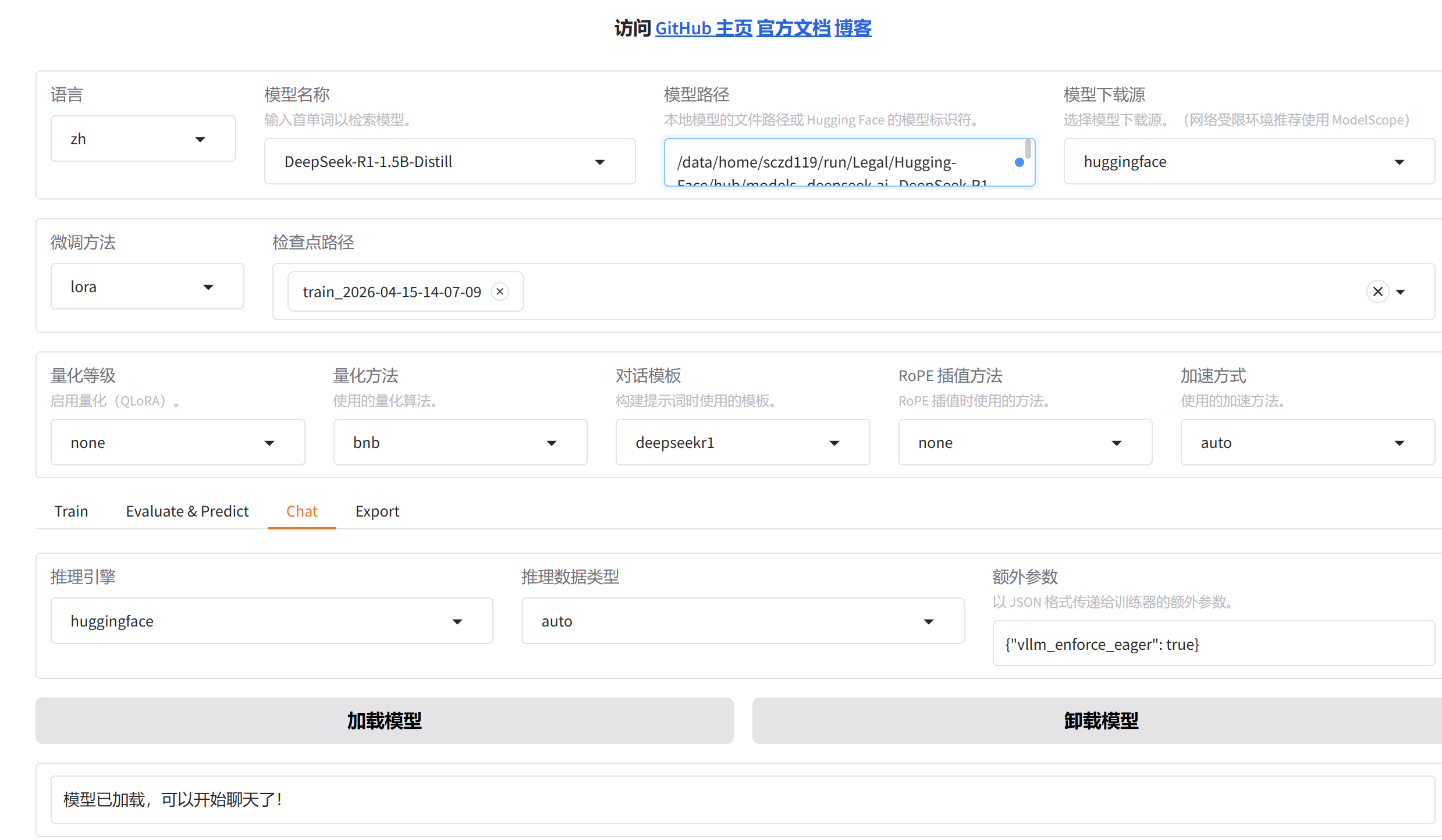
测评标准 :如果模型能准确回答问题,贴合数据集的逻辑,说明测评通过;如果回答不准确,可以增加训练轮数、补充更多数据集,重新训练。

2. 模型导出(转换为Ollama支持的格式,无需安装额外工具)
强烈推荐:无需安装llama.cpp等转换工具,使用Ollama原生命令直接量化转换,操作更简单、效率更高
llama-factory训练完成后,导出的是LoRA适配器权重,需先将其与DeepSeek基座模型合并,再转换为Ollama支持的格式,全程使用Ollama原生命令,无需额外安装转换工具,步骤如下:
-
合并模型 (在终端输入命令,替换路径为你的输出路径,已激活
llama-factory环境):bashllamafactory-cli export \ --model_name_or_path deepseek-ai/deepseek-r1-1.5b \ --adapter_name_or_path saves/deepseek-law-lora \ --output_dir merged-deepseek-law \ --export_type huggingface或者直接在界面上操作即可
这里导出目录大家直接建立一个文件夹粘上绝对路径即可
六、部署模型到Ollama(本地对话自由)
核心优势:轻量级、一键部署、CPU可轻松运行,部署完成后无需网络,可本地自由对话
Ollama是一款轻量级的本地大模型部署工具,支持一键部署、一键对话,操作非常简单,CPU也能轻松运行,下面是详细步骤。
1. 安装Ollama
在终端(已激活 llama-factory conda环境)输入以下命令,通过pip安装Ollama:
bash
pip install ollama验证安装 :安装完成后,输入 ollama --version,若能显示版本号,说明安装成功。
提示:如果pip安装失败,可以去Ollama官方网站(https://ollama.com/)下载对应系统的安装包,手动安装。
2. 导入微调后的模型到Ollama(已通过量化命令完成,无需额外操作)
使用 ollama create deepseek-law -f Modelfile -q 4 命令自动完成模型导入
导入成功后,终端会显示"success"提示,此时模型(命名为 deepseek-law)已成功导入Ollama,可直接启动对话。
3. 运行模型,实现本地对话
在终端(任意环境均可)输入以下命令,启动模型对话:
bash
ollama run deepseek-law启动成功后,就可以输入对应场景问题(如法律场景输入"彩礼能要回吗?""自甘风险是什么意思?"),和我们微调后的专属模型对话了,模型会给出专业、准确的回答。
【此处插入图片6:Ollama运行模型的终端截图,展示对话过程】
退出对话 :对话结束后,输入 /exit 即可退出模型。
七、总结与注意事项
1. 整体流程回顾
整个流程非常清晰,适合CPU用户,全程使用统一环境变量名 llama-factory:选择DeepSeek轻量化模型 → 用llama-factory框架+LoRA算法微调 → 测评模型 → 用Ollama原生命令量化导出 → 直接部署对话,全程无需高端GPU,新手也能快速上手。
2. 注意事项(重点加粗,必看)
- 环境配置 :务必激活
llama-factoryconda专属环境,避免依赖冲突,所有llama-factory相关操作均在此环境中执行; - 数据集配置 :格式必须和Alpaca格式一致,且需在
dataset_info.json中配置,否则训练会报错; - CPU训练:速度较慢,耐心等待,训练期间不要关闭终端和浏览器;
- 模型量化 :优先使用Ollama原生命令
-q量化,无需安装额外工具,4-bit量化最适配CPU; - 模型导入 :量化命令已自动完成导入,无需额外执行
ollama create命令(避免重复操作); - 模型优化:如果模型回答不准确,可增加数据集数量、调整训练轮数或学习率,重新训练。