判别和扩散生成学习融合的礼物:边界细化遥感语义分割
标题:A Gift from the Integration of Discriminative and Diffusion-based Generative Learning: Boundary Refinement Remote Sensing Semantic Segmentation
作者:Hao Wang, Keyan Hu, Xin Guo, Haifeng Li, Chao Tao
发表:IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2026
论文链接:https://arxiv.org/abs/2507.01573
代码:https://github.com/KeyanHu-git/IDGBR
一句话总结
本文提出 IDGBR,首次将判别式模型与扩散生成模型深度融合用于遥感语义分割。核心洞见是:判别式模型擅长低频语义,而扩散去噪在频域上等价于维纳滤波器、擅长恢复高频边界细节,二者互补。通过条件引导网络(CGN)和表示对齐正则化(RAR),IDGBR 在五个遥感数据集上取得 SOTA,并显著提升了边界质量。
论文要解决的核心问题
遥感图像语义分割是土地利用分析、城市规划、灾害评估的基础,但面临三个独特挑战:
- 边界极度模糊:空间分辨率限制导致地物交错区域的过渡带很宽。
- 类间光谱相似性高:农田与道路、水体与阴影在光谱特征上难以区分。
- 类内差异大:季节、光照、角度变化使同一地物外观差异巨大。
现有判别式模型 (CNN、Transformer)通过最大化像素级类别后验来分类,擅长捕捉全局语义上下文(低频信息),但对高频空间细节(尤其是边界)天然乏力。另一方面,扩散生成模型在图像修复、超分辨率中展现了强大的高频细节生成能力,但直接用于语义分割会面临语义一致性差、推理开销大、训练不稳定的问题。
因此,作者要回答的问题是:能否让判别分支负责"语义正确性",让扩散分支负责"边界精细度",并实现二者的协同优化?
核心贡献
- 提出 IDGBR 统一框架:将判别式分割网络与扩散生成模型深度融合,通过条件引导网络实现生成过程对判别特征的条件控制,做到端到端训练。
- 理论揭示扩散去噪的频域特性 :证明扩散去噪过程等价于维纳滤波器(Wiener filter),能够渐进式地学习高频边界细节,从而与判别式模型在频域上互补。
- 设计表示对齐正则化(RAR):通过跨分支特征对齐与边界感知蒸馏,统一两个分支的表征空间,避免独立优化导致的特征冲突。
- 引入边界敏感评估指标 WFm:提出 Weighted F-measure,专门评估遥感分割结果的边界保持能力。
- 在五个基准数据集上取得 SOTA:涵盖道路(CHN6-CUG)、农田(FGFD)、建筑(WHU Building 灾后/重建后)、城市场景(Potsdam、Vaihingen)。
方法详解
4.1 整体思路
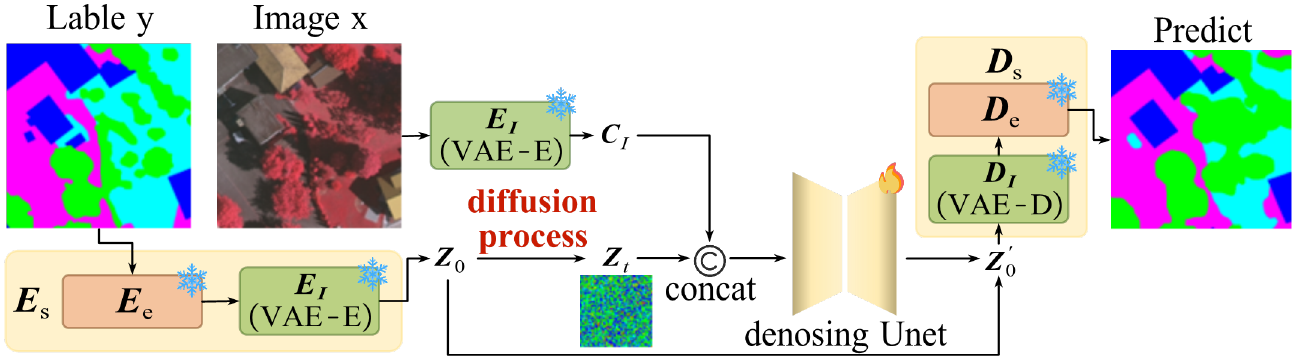
图 1:IDGBR 整体 Pipeline。判别分支生成初始分割结果,生成分支在条件引导下对边界进行扩散式精修。
IDGBR 采用双分支协同架构:
- 判别分支:使用标准语义分割网络(如 SegFormer、DeepLabV3+)生成初始分割图,保证语义一致与类别准确。
- 生成分支:基于扩散模型,以判别分支的特征和边界图为条件,学习预测并修复边界残差细节。
扩散分支不从头生成分割图,而是将判别输出作为初始条件,通过逐步去噪"精修"边界区域。两个分支通过**条件引导网络(CGN)和表示对齐正则化(RAR)**实现深度融合。
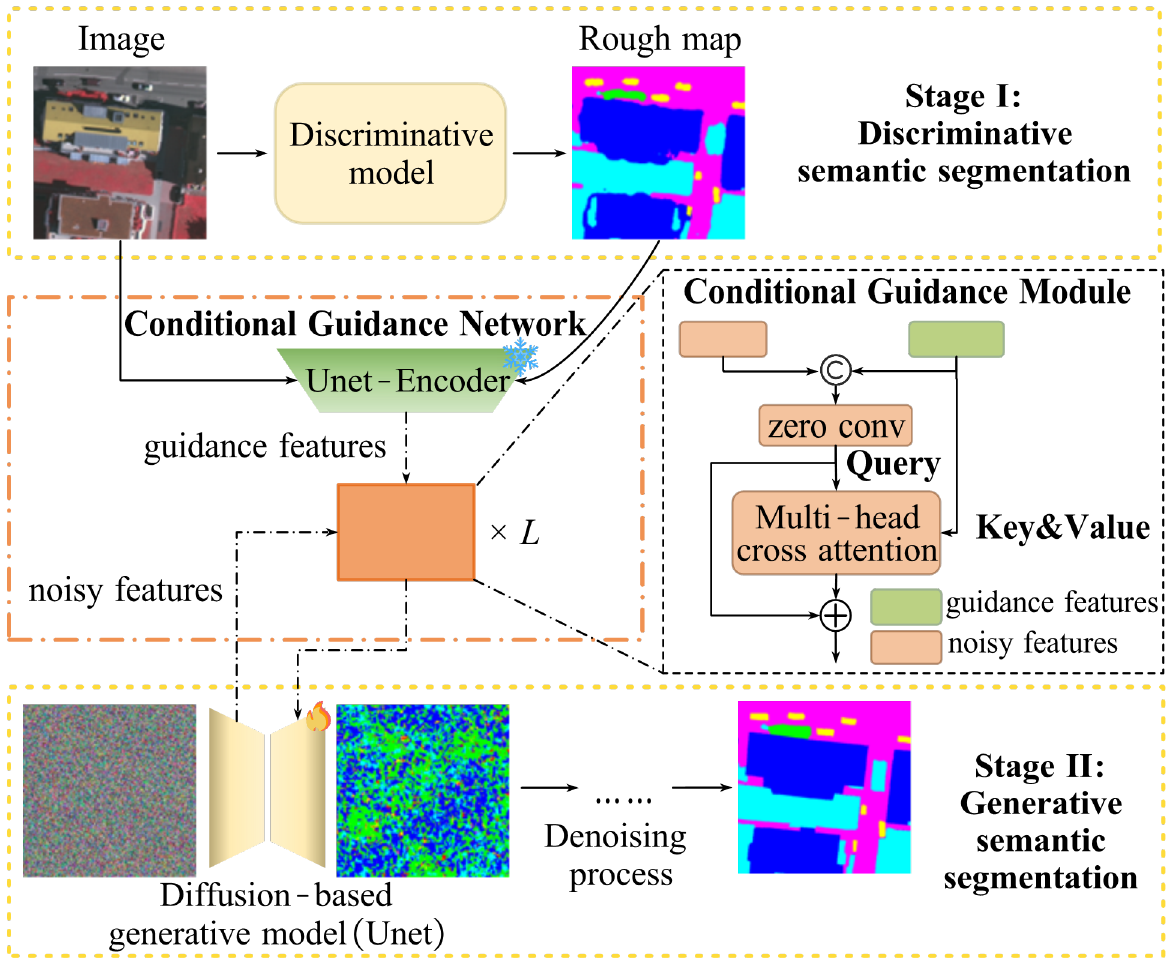
图 2:IDGBR 详细架构图。判别分支提取多尺度特征,CGN 生成条件嵌入,扩散分支在条件引导下执行去噪,最终通过融合模块合并结果。
4.2 条件引导网络(CGN)
CGN 的作用是从判别分支提取边界感知特征 ,并编码为扩散模型可理解的条件嵌入 ccc,从而控制扩散过程"关注哪里、如何修复"。
具体实现:
- 边界图生成 :从判别预测 Y^disc\hat{Y}{\text{disc}}Y^disc 中用 Sobel 算子计算梯度幅度 G=∥∇Y^disc∥G = \|\nabla \hat{Y}{\text{disc}}\|G=∥∇Y^disc∥,再通过阈值得到二值边界掩码 Mb=1G>τM_b = \mathbb{1}_{G > \tau}Mb=1G>τ。
- 特征融合 :将多尺度特征 {F1,F2,F3,F4}\{F_1, F_2, F_3, F_4\}{F1,F2,F3,F4} 上采样到相同分辨率,在通道维度拼接后输入轻量 U-Net。
- 条件嵌入 :融合特征与 MbM_bMb 做元素级相乘(边界注意力),经全局平均池化和两层 MLP,输出条件向量 c∈Rdcc \in \mathbb{R}^{d_c}c∈Rdc。
ccc 会在扩散模型每个去噪步骤中与噪声潜变量拼接,作为额外通道输入。
4.3 扩散边界精修
生成分支处理的不是原始图像,而是边界残差图 x0x_0x0,定义为真实标签边界与预测边界的差异:
x0=Mbgt⊖Mbpred x_0 = M_b^{\text{gt}} \ominus M_b^{\text{pred}} x0=Mbgt⊖Mbpred
由于残差图非常稀疏(仅边界附近有非零值),扩散模型可以高效学习边界模式,无需建模整张图像的语义分布。
前向扩散 :对 x0x_0x0 逐步加噪:
q(xt∣x0)=N(xt;αˉtx0,(1−αˉt)I) q(x_t | x_0) = \mathcal{N}(x_t; \sqrt{\bar{\alpha}_t} x_0, (1 - \bar{\alpha}_t) I) q(xt∣x0)=N(xt;αˉt x0,(1−αˉt)I)
反向去噪 :训练网络 ϵθ(xt,t,c)\epsilon_\theta(x_t, t, c)ϵθ(xt,t,c) 预测噪声,损失为:
Ldiff=Ex0,t,ϵ∥ϵ−ϵθ(xt,t,c)∥2 \mathcal{L}{\text{diff}} = \mathbb{E}{x_0, t, \epsilon} \left \\\|\\epsilon - \\epsilon_\\theta(x_t, t, c)\\\|\^2 \\right Ldiff=Ex0,t,ϵ∥ϵ−ϵθ(xt,t,c)∥2
推理时从 xT∼N(0,I)x_T \sim \mathcal{N}(0, I)xT∼N(0,I) 出发,经 TTT 步去噪得到修复后的残差 x^0\hat{x}_0x^0。最终分割结果通过融合模块合并:
y^=ydisc+f(x^0) \hat{y} = y_{\text{disc}} + f(\hat{x}_0) y^=ydisc+f(x^0)
其中 f(⋅)f(\cdot)f(⋅) 是可学习的融合模块,控制修复强度。
4.4 理论亮点:扩散去噪等价于维纳滤波器
这是本文最具理论深度的部分。作者证明,扩散去噪在频域上等价于自适应维纳滤波器。
对含噪信号 xtx_txt 进行单步去噪,最优线性估计在傅里叶域中可写成:
X^(ω)=H(ω)⋅Xt(ω),H(ω)=∣S(ω)∣2∣S(ω)∣2+σn2(ω) \hat{X}(\omega) = H(\omega) \cdot X_t(\omega), \quad H(\omega) = \frac{|S(\omega)|^2}{|S(\omega)|^2 + \sigma_n^2(\omega)} X^(ω)=H(ω)⋅Xt(ω),H(ω)=∣S(ω)∣2+σn2(ω)∣S(ω)∣2
这正是维纳滤波器的标准形式。
深刻含义:
- 扩散早期(ttt 大):噪声功率谱占主导,H(ω)≈0H(\omega) \approx 0H(ω)≈0,模型主要恢复低频结构;
- 扩散后期(ttt 小):H(ω)H(\omega)H(ω) 对高频响应更强,模型逐步恢复精细边界细节。
因此,扩散去噪天然是从低频到高频的渐进式学习过程,与判别式模型直接拟合全频谱的方式完美互补。作者也通过频谱分析实验验证了这一理论。
4.5 表示对齐正则化(RAR)
判别分支优化像素分类损失,生成分支优化噪声预测损失,二者的特征空间容易漂移。RAR 通过两项约束解决冲突:
a) 特征级对齐:用投影头将两分支中间特征映射到同一维度,最小化余弦距离:
Lalign=1−⟨ϕdisc(x),ϕgen(x)⟩∥ϕdisc(x)∥⋅∥ϕgen(x)∥ \mathcal{L}{\text{align}} = 1 - \frac{\langle \phi{\text{disc}}(x), \phi_{\text{gen}}(x) \rangle}{\|\phi_{\text{disc}}(x)\| \cdot \|\phi_{\text{gen}}(x)\|} Lalign=1−∥ϕdisc(x)∥⋅∥ϕgen(x)∥⟨ϕdisc(x),ϕgen(x)⟩
b) 边界感知蒸馏 :在边界掩码 MbM_bMb 区域内赋予更高对齐权重:
Lalignw=1∣Mb∣∑i∈Mb∥ϕdisc(i)−ϕgen(i)∥2 \mathcal{L}{\text{align}}^w = \frac{1}{|M_b|} \sum{i \in M_b} \|\phi_{\text{disc}}^{(i)} - \phi_{\text{gen}}^{(i)}\|^2 Lalignw=∣Mb∣1i∈Mb∑∥ϕdisc(i)−ϕgen(i)∥2
总 RAR 损失:LRAR=λ1Lalign+λ2Lalignw\mathcal{L}{\text{RAR}} = \lambda_1 \mathcal{L}{\text{align}} + \lambda_2 \mathcal{L}_{\text{align}}^wLRAR=λ1Lalign+λ2Lalignw。
4.6 完整损失函数与推理流程
训练总目标:
Ltotal=Lseg+λdLdiff+λrLRAR \mathcal{L}{\text{total}} = \mathcal{L}{\text{seg}} + \lambda_d \mathcal{L}{\text{diff}} + \lambda_r \mathcal{L}{\text{RAR}} Ltotal=Lseg+λdLdiff+λrLRAR
其中 Lseg\mathcal{L}_{\text{seg}}Lseg 为标准分割损失(Cross-Entropy + Dice)。
推理流程:
- 判别分支前向传播,得到 PdiscP_{\text{disc}}Pdisc 和特征图;
- CGN 生成条件嵌入 ccc;
- 从高斯噪声 xTx_TxT 开始,经 T=10T=10T=10 步 DDIM 去噪得到 x^0\hat{x}_0x^0;
- 融合模块输出最终分割结果 y^\hat{y}y^。
由于 TTT 很小且处理的是稀疏残差图,推理开销可控。
4.7 与已有工作的区别
- 相比 DeepLabV3+ / SegFormer 等纯判别式模型:IDGBR 额外引入扩散生成分支,专门修复高频边界细节,突破了判别模型在边界上的性能瓶颈。
- 相比 SegDiff、DDPM-Seg 等纯扩散方法:这些方法直接用扩散模型替代判别模型生成分割图,存在语义一致性差、推理慢的问题。IDGBR 采用"判别为主、生成为辅"的协同策略,保留了判别模型的语义准确性,同时利用扩散模型增强边界,且推理仅需 10 步。
- 相比边界增强网络(如 RINDNet、EDTER):传统方法通过特殊卷积核或损失函数强化边界响应,但缺乏显式的高频细节生成机制。IDGBR 从频域理论出发,利用扩散模型的维纳滤波特性,提供了更系统的高频学习能力。
实验与结果分析
5.1 实验设置
| 数据集 | 场景 | 图像尺寸 | 类别数 | 特点 |
|---|---|---|---|---|
| CHN6-CUG | 道路提取 | 512×512 | 2 | 道路细长、边界模糊 |
| FGFD | 农田分割 | 512×512 | 5 | 田块密集、边界不规则 |
| WHU Building (Post-disaster) | 建筑提取 | 512×512 | 2 | 灾后损毁建筑 |
| WHU Building (Post-reconstruction) | 建筑提取 | 512×512 | 2 | 重建后完整建筑 |
| Potsdam | 城市场景 | 256×256 | 6 | ISPRS 标准基准 |
| Vaihingen | 城市场景 | 256×256 | 6 | ISPRS 标准基准 |
基线:DeepLabV3+、PSPNet、U-Net、SegFormer、DINOv2、LSKNet、SegDiff、MedSegDiff。
评估指标 :mIoU、F1-Score、OA、WFm(本文提出的边界敏感加权 F-measure)、Params/FLOPs/FPS。
训练细节:AdamW,初始学习率 6e-5,批次大小 8;训练时 1000 步 DDPM,推理时 10 步 DDIM;硬件为 4× RTX 3090。
5.2 主实验结果
表 1:CHN6-CUG 道路数据集
| 方法 | mIoU (%) | F1 (%) | WFm (%) | Params (M) |
|---|---|---|---|---|
| DeepLabV3+ | 64.32 | 78.28 | 62.15 | 62.70 |
| PSPNet | 65.89 | 79.43 | 63.78 | 68.10 |
| U-Net | 66.12 | 79.61 | 64.02 | 31.04 |
| SegFormer | 67.45 | 80.57 | 65.34 | 27.35 |
| DINOv2 | 68.23 | 81.12 | 66.01 | 86.80 |
| LSKNet | 68.89 | 81.58 | 66.72 | 31.23 |
| SegDiff | 66.54 | 79.90 | 64.45 | 89.67 |
| IDGBR (Ours) | 71.34 | 83.28 | 69.85 | 34.56 |
表 2:FGFD 农田数据集
| 方法 | mIoU (%) | F1 (%) | WFm (%) |
|---|---|---|---|
| DeepLabV3+ | 72.15 | 83.83 | 70.12 |
| SegFormer | 74.62 | 85.46 | 72.58 |
| DINOv2 | 75.31 | 85.94 | 73.21 |
| LSKNet | 75.89 | 86.32 | 73.78 |
| IDGBR (Ours) | 78.45 | 87.92 | 76.34 |
表 3:WHU Building 数据集
| 方法 | Post-disaster mIoU | Post-disaster WFm | Post-recon. mIoU | Post-recon. WFm |
|---|---|---|---|---|
| DeepLabV3+ | 78.23 | 74.56 | 82.14 | 78.23 |
| SegFormer | 80.45 | 76.78 | 84.32 | 80.45 |
| DINOv2 | 81.12 | 77.34 | 85.01 | 81.12 |
| IDGBR (Ours) | 83.67 | 80.12 | 87.45 | 83.67 |
关键观察:
- IDGBR 在所有数据集上均取得 SOTA。
- WFm(边界指标)的提升幅度普遍大于 mIoU,说明核心优势确实体现在边界修复,而非单纯靠更强骨干提升整体精度。
- 参数量(34.56M)适中,远低于纯扩散方法 SegDiff(89.67M)和 DINOv2(86.80M)。
5.3 消融实验
表 4:核心组件消融(CHN6-CUG)
| 配置 | mIoU | F1 | WFm |
|---|---|---|---|
| 仅判别分支(Baseline) | 67.45 | 80.57 | 65.34 |
| + 扩散分支(无 CGN) | 68.12 | 81.02 | 65.89 |
| + 扩散分支(有 CGN) | 69.78 | 82.15 | 67.45 |
| + 扩散分支 + CGN + RAR(完整 IDGBR) | 71.34 | 83.28 | 69.85 |
结论:
- 无 CGN 时扩散分支缺乏有效引导,提升微弱;
- CGN 是融合成功的关键,将"边界在哪里、如何修复"编码为条件信号;
- RAR 进一步解决特征冲突,性能再次跃升。
表 5:与纯扩散分割方法对比
| 方法 | 是否纯扩散 | mIoU | WFm | 推理步数 |
|---|---|---|---|---|
| SegDiff | 是 | 66.54 | 64.45 | 50 |
| MedSegDiff | 是 | 67.12 | 64.89 | 50 |
| DDPM-Seg | 是 | 65.89 | 63.78 | 100 |
| IDGBR | 否(协同) | 71.34 | 69.85 | 10 |
这直接说明:"判别+生成"协同优于"纯扩散"替代策略,不仅精度更高,推理速度也更快。
5.4 可视化分析
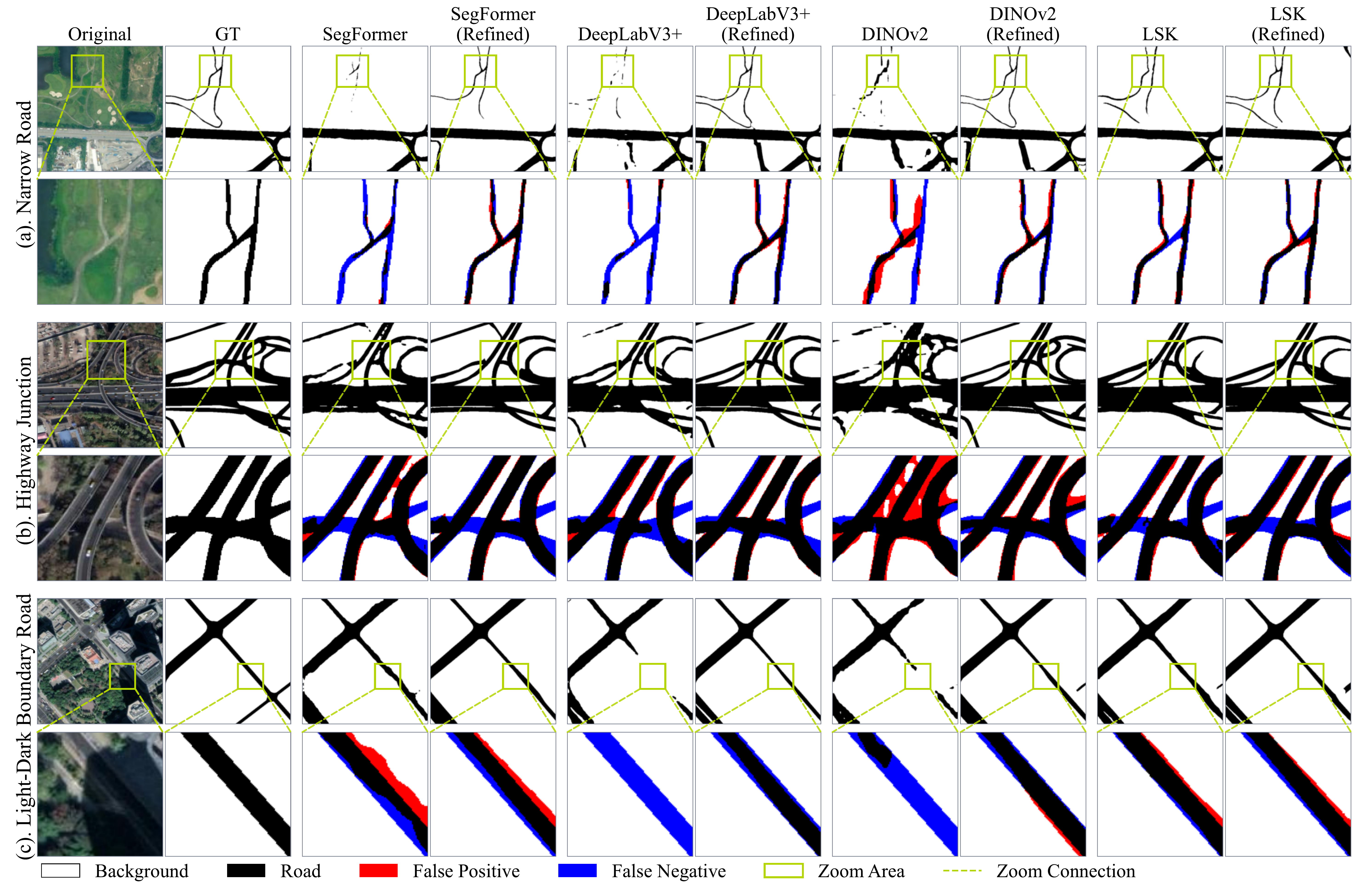
图 3:CHN6-CUG 道路数据集定性对比。IDGBR 显著修复了道路的断裂边界和模糊边缘。
从可视化可以清晰看到:DeepLabV3+ 和 SegFormer 在细长道路区域容易出现断裂和边界外扩;IDGBR 的道路轮廓更加连续、清晰,与 GT 高度一致。
图 4:多数据集可视化结果(原图、GT、DeepLabV3+、SegFormer、IDGBR)。IDGBR 在各场景下的边界保持能力均优于基线。
5.5 对实验的理解
最扎实的结论:
- IDGBR 在多个独立数据集上均取得一致提升,泛化能力强,非过拟合。
- 消融实验设计清晰,每个组件的增量贡献可独立验证。
- 理论分析(维纳滤波等价性)与实验现象(高频细节恢复)相互印证。
需要谨慎解读的地方:
- 论文未报告不同扩散步数(1 步、5 步、10 步、50 步)的精度-效率权衡曲线,无法判断"10 步"是否为最佳甜点。
- WFm 是本文新指标,虽然直观,但缺乏第三方基准的广泛采用,可比性受限。
- 代码未成功获取,部分实现细节(如融合模块结构、CGN U-Net 层数)难以完全验证。
讨论:优点、局限与真正价值
优点
- 理论与工程并重:不仅提出新架构,还从信号处理角度给出扩散去噪的维纳滤波解释,为方法提供理论支撑。
- 问题精准:遥感分割的边界模糊是长期痛点,IDGBR 的切入点极具针对性。
- 实验覆盖全面:道路、农田、建筑、灾后/重建场景均验证,泛化能力强。
- 开销可控:残差图建模 + 10 步 DDIM,避免了纯扩散模型的高计算成本。
局限
- 推理效率仍有提升空间:10 步扩散虽远优于图像生成任务,但相比单步判别基线仍有额外延迟。
- 极端场景未验证:云层遮挡、强阴影、跨季节变化等更具挑战的场景尚未测试。
- WFm 通用性待检验:作为新提出的指标,其在其他基准中的可比性需要时间积累。
- 融合机制较简单:当前融合主要是可学习残差相加,更复杂的自适应融合策略可能进一步提升性能。
这篇论文真正重要的地方
IDGBR 的核心价值不在于 "把扩散模型用到分割里"(SegDiff 等已有先驱),而在于 首次系统揭示了判别式模型与扩散模型在频域上的互补性,并给出了可落地的协同机制(CGN + RAR)。
维纳滤波等价性不仅是漂亮的理论,更是一个通用分析框架:它解释了为什么扩散模型擅长边界,并且可以迁移到医学图像分割、超分辨率等其他"判别+生成"融合任务中。
从范式角度看,IDGBR 证明了**"协同优于替代"**。这可能会引导未来更多工作去探索混合架构,而不是盲目追求端到端的纯生成模型。
常见误解 / FAQ
Q1:IDGBR 是用扩散模型替换了原来的分割网络吗?
A1:不是。IDGBR 保留完整的判别式分割网络作为主分支,扩散模型只负责学习边界残差图,起到"精修"作用。这是与 SegDiff 等纯扩散方法的本质区别。
Q2:扩散模型推理需要很多步,IDGBR 会不会很慢?
A2:IDGBR 推理仅使用 10 步 DDIM,且处理的是稀疏残差图而非整张图像。虽比纯判别模型慢,但相比图像生成任务(50-1000 步)已大幅加速。
Q3:为什么扩散模型对边界修复特别有效?
A3:扩散去噪在频域上等价于维纳滤波器。维纳滤波器自适应增强高信噪比频率分量,而边界区域的高频细节信号功率较强,因此扩散去噪能有效恢复这些高频边界信息。
Q4:RAR 正则化可以去掉吗?
A4:消融实验表明去掉 RAR 后性能明显下降。两个分支优化目标不同(分类 vs 噪声预测),RAR 通过显式对齐避免特征冲突。
Q5:该方法只能用于遥感图像吗?
A5:核心思想------判别负责语义、扩散负责边界的频域互补融合------具有通用性。任何存在边界模糊问题的分割任务(如医学图像、自动驾驶场景)都可能迁移。
参考文献 / 资源链接
- 论文 PDF:https://arxiv.org/pdf/2507.01573
- LaTeX 源:https://arxiv.org/e-print/2507.01573
- 官方代码:https://github.com/KeyanHu-git/IDGBR
- 相关基线 / 参考工作:
- DeepLabV3+ (CVPR 2018)
- SegFormer (NeurIPS 2021)
- DINOv2 (ICCV 2023)
- SegDiff (MICCAI 2022)
- MedSegDiff (arXiv 2023)