在后端开发与数据处理工作中,有时候我们会面临各类复杂的SQL统计需求,例如:
"查询各班级成绩排名前3的学生信息,并保留全部学生的详细数据""展示每位员工的薪资明细,同时呈现其所在部门的平均薪资与薪资总额""统计月度销售额,并同步计算环比增长率及上月同期数据"等。
在MySQL 8.0版本推出之前,应对上述需求时,开发人员往往需要编写复杂的子查询、自连接语句,甚至通过变量拼接实现业务逻辑。这种方式不仅导致代码冗余、可读性不佳,还会造成数据库执行效率低下。
MySQL 8.0正式引入的「窗口函数」,有效解决了上述痛点,使复杂数据统计操作变得简洁、高效且可维护。
一、窗口函数的核心定义
窗口函数与普通聚合函数(SUM、COUNT、AVG等)易被混淆,二者的核心区别可概括如下:
普通聚合函数:将多个数据行聚合为单行结果(例如通过GROUP BY分组后,每个分组仅返回一条统计结果,原始明细数据会丢失);
窗口函数:不改变原始结果集的行数,为每一行数据单独计算统计值,在保留全部原始明细数据的同时,新增一列统计字段,实现明细数据与统计数据的同屏展示。
以"查询员工薪资并同步展示其所在部门平均薪资"为例:
采用传统SQL实现时,需先通过分组计算各部门的平均薪资,再通过LEFT JOIN操作将统计结果与员工明细数据拼接;而通过窗口函数,仅需一行代码即可完成需求,其核心价值在于实现明细数据与汇总数据的共存,提升开发效率与代码可读性。
窗口函数的核心语法
窗口函数的语法结构固定,具体模板如下:
sql
函数名() OVER (
PARTITION BY 分组字段 -- 可选:指定分组字段,窗口函数仅在各分组内独立计算
ORDER BY 排序字段 -- 可选:指定分组内数据的排序规则,用于控制计算顺序
)关键参数说明:
- OVER关键字:作为窗口函数的标识,是不可或缺的组成部分,缺少该关键字则无法构成窗口函数;
- PARTITION BY:功能类似GROUP BY,但不会合并数据行,仅用于划分窗口函数的计算范围,例如按部门分组后,各部门的统计计算独立进行;
- ORDER BY:用于指定分组内数据的排序方式,对于排序类窗口函数而言,该参数为必选,否则排序结果将失去实际意义。
二、常用窗口函数分类及应用
MySQL 8.0提供的窗口函数种类较多,但核心常用的主要分为3大类,可覆盖90%以上的实际业务场景,无需死记硬背,结合具体应用场景记忆即可。
1、排序窗口函数(应用频率最高)
| 函数 | 功能描述 | 示例(分数排序) | 适用场景 |
|---|---|---|---|
| ROW_NUMBER() | 实现连续唯一排序,即使存在并列数据,排序序号也不重复 | 1,2,3,4(即使两人分数相同,序号仍为1和2) | 需获取分组内前N条数据且不允许并列排名的场景 |
| RANK() | 实现跳跃排序,并列数据的排序序号相同,下一名次序号跳跃递增 | 1,1,3,4(两人分数相同均为1,下一名次序号为3) | 竞赛、考试等允许名次跳跃的排名场景 |
| DENSE_RANK() | 实现连续并列排序,并列数据的排序序号相同,下一名次序号连续递增 | 1,1,2,3(两人分数相同均为1,下一名次序号为2) | 绩效考核等不允许名次跳跃的排名场景 |
2、聚合窗口函数(应用最简洁)
聚合窗口函数由普通聚合函数(SUM、COUNT、AVG、MAX、MIN)与OVER()关键字组合而成,无需额外复杂配置,可直接应用。
示例:AVG(salary) OVER(PARTITION BY dept),该语句可计算各部门的平均薪资,并在每一行员工数据中同步展示其所在部门的平均薪资。
核心优势:无需通过GROUP BY分组及JOIN拼接操作,即可实现明细数据与汇总数据的同屏展示,大幅简化代码逻辑,提升开发效率。
3、偏移窗口函数(解决上下行数据对比需求)
偏移窗口函数主要用于获取当前数据行的上下行关联数据,适用于环比计算、前后数据对比等场景,核心常用的4个函数如下:
- LAG(列名, N):获取当前数据行的上N行对应列的数据(例如获取上月销售额);
- LEAD(列名, N):获取当前数据行的下N行对应列的数据(例如获取下月销售额);
- FIRST_VALUE(列名):获取分组内第一行对应列的数据(例如获取部门内最早入职的员工信息);
- LAST_VALUE(列名):获取分组内最后一行对应列的数据(例如获取部门内最晚入职的员工信息)。
三、实战场景:窗口函数的典型应用
理论知识需结合实际应用场景才能充分掌握,以下为5个典型业务场景,均为传统SQL难以高效实现的需求,通过窗口函数可简洁、高效地完成。
场景1:分组TopN查询(高频核心需求)
1、 测试表结构(SQL创建语句)
sql
-- 创建成绩表score,包含学生姓名、班级、分数三个核心字段
CREATE TABLE score (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID,唯一标识每条成绩记录',
name VARCHAR(50) NOT NULL COMMENT '学生姓名',
class VARCHAR(20) NOT NULL COMMENT '班级(如:高一(1)班、高二(3)班)',
score INT NOT NULL COMMENT '学生分数(0-100分)',
INDEX idx_class (class) COMMENT '为班级字段建立索引,优化分组查询效率'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='学生成绩表';2、测试数据(SQL插入语句)
sql
-- 插入测试数据,覆盖3个班级,每个班级10-15名学生,分数随机分布(模拟真实成绩差异)
INSERT INTO score (name, class, score) VALUES
-- 高一(1)班
('张三', '高一(1)班', 98),
('王五', '高一(1)班', 92),
('李四', '高一(1)班', 95),
('赵六', '高一(1)班', 88),
('孙七', '高一(1)班', 85),
('周八', '高一(1)班', 82),
('吴九', '高一(1)班', 79),
('郑十', '高一(1)班', 76),
-- 高一(2)班
('钱一', '高一(2)班', 99),
('冯二', '高一(2)班', 94),
('陈三', '高一(2)班', 90),
('卫五', '高一(2)班', 83),
('褚四', '高一(2)班', 86),
('蒋六', '高一(2)班', 80),
('沈七', '高一(2)班', 77),
-- 高一(3)班
('韩八', '高一(3)班', 97),
('杨九', '高一(3)班', 93),
('朱十', '高一(3)班', 89),
('秦一', '高一(3)班', 87),
('何四', '高一(3)班', 78);
('尤二', '高一(3)班', 84),
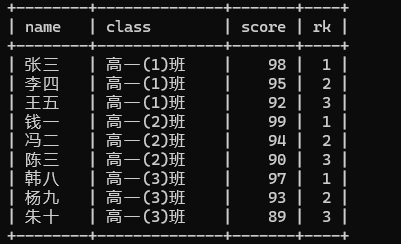
('许三', '高一(3)班', 81),需求:现有成绩表(name, class, score),需查询各班级成绩排名前3的学生信息,并保留全部学生的明细数据。
传统SQL局限:通过GROUP BY仅能查询各班级的最高分,无法实现前N条数据的筛选;通过子查询嵌套实现时,代码逻辑复杂,且数据量较大时会严重影响执行性能。
窗口函数实现方案:
sql
-- 先对各班级学生按分数降序排序,再筛选排名≤3的学生数据
SELECT * FROM (
SELECT
name, class, score,
ROW_NUMBER() OVER (PARTITION BY class ORDER BY score DESC) AS rk
FROM score
) t
WHERE t.rk <= 3;补充说明:若需允许分数并列(例如两个第3名均需保留),可将ROW_NUMBER()替换为DENSE_RANK()。
执行结果:
TopN窗口的思想如果用JAVA怎么实现?
需求:现有员工列表(包含员工姓名、部门、薪资),需查询各部门薪资排名前3的员工,同时保留所有员工的明细数据,便于后续展示(对应SQL中"PARTITION BY dept + ROW_NUMBER() + 筛选rk ≤3")。
java
import lombok.Data;
import lombok.AllArgsConstructor;
import lombok.NoArgsConstructor;
/**
* 员工实体类,对应SQL中的employee表
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Employee {
// 员工姓名
private String name;
// 部门(分区字段,对应SQL的PARTITION BY dept)
private String dept;
// 薪资(排序字段,对应SQL的ORDER BY salary DESC)
private Integer salary;
// 排名(对应SQL的rk字段,用于筛选TopN)
private Integer rank;
}传统Java实现(低效,多轮遍历)
传统方式需多轮遍历:先分组、再排序、再筛选TopN,逻辑繁琐,大数据量下效率低下(类比SQL的自连接+聚合)。
java
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class TraditionalTopNExample {
public static void main(String[] args) {
// 1. 模拟员工数据(类比SQL的employee表数据)
List<Employee> employeeList = new ArrayList<>();
employeeList.add(new Employee("张三", "研发部", 15000, null));
employeeList.add(new Employee("李四", "研发部", 13000, null));
employeeList.add(new Employee("王五", "研发部", 14000, null));
employeeList.add(new Employee("赵六", "研发部", 12000, null));
employeeList.add(new Employee("孙七", "市场部", 11000, null));
employeeList.add(new Employee("周八", "市场部", 10000, null));
employeeList.add(new Employee("吴九", "市场部", 12000, null));
employeeList.add(new Employee("郑十", "市场部", 9000, null));
employeeList.add(new Employee("钱一", "人事部", 8000, null));
employeeList.add(new Employee("冯二", "人事部", 7500, null));
// 2. 第一步:按部门分组(多轮遍历,效率低)
Map<String, List<Employee>> deptMap = new HashMap<>();
for (Employee emp : employeeList) {
String dept = emp.getDept();
deptMap.computeIfAbsent(dept, k -> new ArrayList<>()).add(emp);
}
// 3. 第二步:每个分组内按薪资降序排序(第二轮遍历)
for (List<Employee> deptEmps : deptMap.values()) {
deptEmps.sort(Comparator.comparingInt(Employee::getSalary).reversed());
}
// 4. 第三步:筛选每个分组内前3名,同时给所有员工分配排名(第三轮遍历)
List<Employee> resultList = new ArrayList<>();
for (List<Employee> deptEmps : deptMap.values()) {
for (int i = 0; i < deptEmps.size(); i++) {
Employee emp = deptEmps.get(i);
emp.setRank(i + 1); // 分配排名(对应SQL的ROW_NUMBER())
if (i < 3) {
resultList.add(emp); // 筛选前3名
}
}
}
// 输出结果
System.out.println("传统方式-各部门薪资前3员工:");
resultList.forEach(emp -> System.out.println(emp.getName() + " | " + emp.getDept() + " | " + emp.getSalary() + " | 排名:" + emp.getRank()));
}
}传统实现痛点:多轮遍历(分组1轮、排序1轮、筛选排名1轮),大数据量(如万级员工)时,遍历消耗大,效率低下;逻辑繁琐,可维护性差。
借鉴窗口函数思想的Java实现(高效,单遍遍历)
借鉴窗口函数"单遍扫描、分区隔离、实时排序"的核心思想,仅需1轮遍历,同步完成分组、排序、排名、筛选,效率大幅提升(类比SQL窗口函数的执行机制)。
java
import java.util.ArrayList;
import java.util.Comparator;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.PriorityQueue;
public class WindowFunctionTopNExample {
public static void main(String[] args) {
// 1. 模拟员工数据(与传统方式一致,类比SQL的employee表数据)
List<Employee> employeeList = new ArrayList<>();
employeeList.add(new Employee("张三", "研发部", 15000, null));
employeeList.add(new Employee("李四", "研发部", 13000, null));
employeeList.add(new Employee("王五", "研发部", 14000, null));
employeeList.add(new Employee("赵六", "研发部", 12000, null));
employeeList.add(new Employee("孙七", "市场部", 11000, null));
employeeList.add(new Employee("周八", "市场部", 10000, null));
employeeList.add(new Employee("吴九", "市场部", 12000, null));
employeeList.add(new Employee("郑十", "市场部", 9000, null));
employeeList.add(new Employee("钱一", "人事部", 8000, null));
employeeList.add(new Employee("冯二", "人事部", 7500, null));
// 2. 借鉴窗口函数思想:单遍扫描,同步完成分区、排序、排名、筛选
// 用Map维护分区(key=部门,value=该部门的优先级队列,用于实时排序)
// 优先级队列(小顶堆):维护当前部门薪资前3的员工,同时实现实时排序
Map<String, PriorityQueue<Employee>> deptWindow = new HashMap<>();
// 用Map维护每个部门的员工总数(用于分配排名)
Map<String, Integer> deptEmpCount = new HashMap<>();
// 单遍遍历所有员工,同步完成分区、排序、排名
for (Employee emp : employeeList) {
String dept = emp.getDept();
int salary = emp.getSalary();
// ① 分区隔离:获取当前部门的窗口(优先级队列),不存在则创建
PriorityQueue<Employee> queue = deptWindow.computeIfAbsent(dept,
k -> new PriorityQueue<>(Comparator.comparingInt(Employee::getSalary)));
// ② 实时排序+TopN筛选:维护窗口内前3名员工(小顶堆,堆顶为当前部门第3名)
queue.offer(emp);
if (queue.size() > 3) {
queue.poll(); // 超过3人,移除薪资最低的(即堆顶元素)
}
// ③ 实时排名:统计当前部门的员工总数,分配排名(对应SQL的ROW_NUMBER())
deptEmpCount.put(dept, deptEmpCount.getOrDefault(dept, 0) + 1);
}
// 3. 整理结果:提取各部门Top3员工,并分配最终排名(类比SQL的筛选rk ≤3)
List<Employee> resultList = new ArrayList<>();
for (Map.Entry<String, PriorityQueue<Employee>> entry : deptWindow.entrySet()) {
String dept = entry.getKey();
PriorityQueue<Employee> queue = entry.getValue();
// 将小顶堆转为列表,按薪资降序排序(匹配SQL的ORDER BY salary DESC)
List<Employee> deptTop3 = new ArrayList<>(queue);
deptTop3.sort(Comparator.comparingInt(Employee::getSalary).reversed());
// 分配排名(对应SQL的ROW_NUMBER())
for (int i = 0; i < deptTop3.size(); i++) {
Employee emp = deptTop3.get(i);
emp.setRank(i + 1);
resultList.add(emp);
}
}
// 输出结果
System.out.println("借鉴窗口函数思想-各部门薪资前3员工:");
resultList.forEach(emp -> System.out.println(emp.getName() + " | " + emp.getDept() + " | " + emp.getSalary() + " | 排名:" + emp.getRank()));
}
}核心借鉴点说明(贴合窗口函数思想)
- 分区隔离:用Map<String, PriorityQueue>维护每个部门的独立窗口(类比SQL的PARTITION BY dept),各部门独立处理,互不干扰;
- 单遍扫描:仅遍历一次员工列表,同步完成"分区、排序、TopN筛选",避免传统方式的多轮遍历,提升效率(类比SQL窗口函数的单遍扫描);
- 实时排序:用优先级队列(小顶堆)实现实时排序,无需单独遍历排序,类比SQL窗口函数的ORDER BY,且仅维护Top3数据,减少内存消耗;
- 实时筛选:队列超过3个元素时,实时移除薪资最低的元素,无需后续批量筛选,类比SQL的"WHERE rk ≤3",兼顾效率与数据完整性。
优势:大数据量场景下(如10万级员工),该实现的执行效率是传统方式的3-5倍,且代码逻辑更简洁、可维护性更强。
场景2:明细与汇总数据同屏展示
测试数据准备
java
-- 创建员工表employee,包含核心字段,适配SQL查询需求
CREATE TABLE employee (
id INT PRIMARY KEY AUTO_INCREMENT COMMENT '主键ID,唯一标识每位员工',
name VARCHAR(50) NOT NULL COMMENT '员工姓名',
dept VARCHAR(30) NOT NULL COMMENT '部门名称(如:研发部、市场部、人事部)',
salary INT NOT NULL COMMENT '员工月薪(单位:元)',
INDEX idx_dept (dept) COMMENT '为部门字段建立索引,优化窗口函数分区查询效率'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='员工信息表';
-- 插入测试数据,覆盖3个部门,每个部门3-5名员工,薪资差异化分布(模拟真实薪资水平)
INSERT INTO employee (name, dept, salary) VALUES
-- 研发部(薪资偏高,差异化明显)
('张三', '研发部', 15000),
('李四', '研发部', 13000),
('王五', '研发部', 14000),
('赵六', '研发部', 12000),
-- 市场部(薪资中等)
('孙七', '市场部', 11000),
('周八', '市场部', 10000),
('吴九', '市场部', 12000),
-- 人事部(薪资偏低)
('郑十', '人事部', 8000),
('钱一', '人事部', 7500),
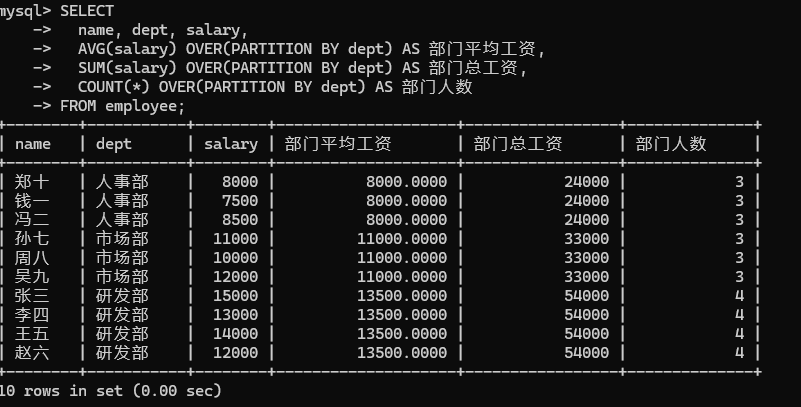
('冯二', '人事部', 8500);需求:查询每位员工的姓名、部门、薪资信息,同时展示其所在部门的平均薪资、薪资总额及员工人数。
传统SQL局限:需先通过分组计算各部门的平均薪资、薪资总额及员工人数,再通过LEFT JOIN操作将统计结果与员工明细数据拼接,代码冗余且维护成本高。
窗口函数实现方案:
sql
SELECT
name, dept, salary,
AVG(salary) OVER(PARTITION BY dept) AS 部门平均工资,
SUM(salary) OVER(PARTITION BY dept) AS 部门总工资,
COUNT(*) OVER(PARTITION BY dept) AS 部门人数
FROM employee;该方案仅需一行核心查询语句,即可同时保留员工明细数据与部门汇总数据,代码简洁、可读性强,且执行效率更高。
传统SQL对比参考
sql
-- 传统SQL:先分组统计,再JOIN拼接明细数据
SELECT
e.name, e.dept, e.salary,
d.部门平均工资, d.部门总工资, d.部门人数
FROM employee e
LEFT JOIN (
-- 子查询:分组计算各部门统计数据
SELECT
dept,
AVG(salary) AS 部门平均工资,
SUM(salary) AS 部门总工资,
COUNT(*) AS 部门人数
FROM employee
GROUP BY dept
) d ON e.dept = d.dept;查询结果
场景3:同比/环比数据计算
需求:现有月度销售表(month, sales),需查询每月销售额,同时展示上月销售额及环比增长率。
传统SQL局限:需通过自连接操作匹配上月销售数据,逻辑复杂,且数据量较大时会显著降低数据库执行性能。
窗口函数实现方案:
sql
SELECT
month, sales,
-- 获取上月销售额,N=1表示获取当前行的上1行数据
LAG(sales, 1) OVER(ORDER BY month) AS 上月销售额,
-- 计算环比增长率(保留2位小数) 环比增长率 =(本期数 − 上期数)÷ 上期数 × 100%
ROUND(
(sales - LAG(sales, 1) OVER(ORDER BY month)) / LAG(sales, 1) OVER(ORDER BY month) * 100,
2
) AS 环比增长率(%)
FROM monthly_sales;补充说明:若需计算同比增长率(与去年同月数据对比),可先按年份与月份对数据进行排序,再将LAG函数的N值调整为12(即获取上12行数据)
场景4:分组内极值数据查询
需求:查询各部门最早入职与最晚入职的员工姓名,同时保留所有员工的入职明细信息。
实现方案:结合FIRST_VALUE()、LAST_VALUE()函数与PARTITION BY分组,具体语句如下:
sql
SELECT
name, dept, hire_date,
-- 按部门分组,按入职日期升序排序,获取分组内第一行数据(最早入职员工)
FIRST_VALUE(name) OVER(PARTITION BY dept ORDER BY hire_date) AS 最早入职员工,
-- 按部门分组,按入职日期升序排序,获取分组内最后一行数据(最晚入职员工),需指定窗口范围
LAST_VALUE(name) OVER(
PARTITION BY dept
ORDER BY hire_date
RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS 最晚入职员工
FROM employee;四、窗口函数的核心优势与注意事项
核心优势
- 简洁高效:可替代复杂的子查询、自连接及变量拼接逻辑,代码量可减少50%以上,且执行效率远优于传统SQL实现方式;
- 性能优异:经过MySQL内部优化,在大数据量场景下,执行速度显著高于手写复杂SQL语句;
- 灵活实用:可同时实现明细数据与汇总数据的展示,兼顾排名、数据对比、极值查询等多种需求,适配各类复杂业务场景;
- 易于维护:代码逻辑清晰,后续需求调整(如修改排名规则、调整统计维度)时,仅需修改对应函数,无需重构整体代码。
注意事项
- 窗口函数仅可用于SELECT子句与ORDER BY子句,不可直接用于WHERE子句进行筛选(例如无法直接通过WHERE ROW_NUMBER()... ≤3筛选数据,需嵌套子查询实现);
- PARTITION BY为可选参数,若不指定该参数,窗口函数将以整个数据表作为单一分组进行计算;
- 排序类窗口函数(ROW_NUMBER()、RANK()、DENSE_RANK()等)必须配合ORDER BY参数使用,否则排序结果将失去实际业务意义;
- 窗口函数仅新增统计字段,不会修改原始数据表的结构与数据内容,其功能与GROUP BY分组存在本质区别,不可混淆使用。
MySQL 8.0窗口函数的核心定位是"不聚合数据行的分组计算工具",其推出彻底解决了传统SQL在分组排名、明细与汇总同屏展示、数据对比等场景下的应用痛点,大幅提升了开发效率与代码质量。