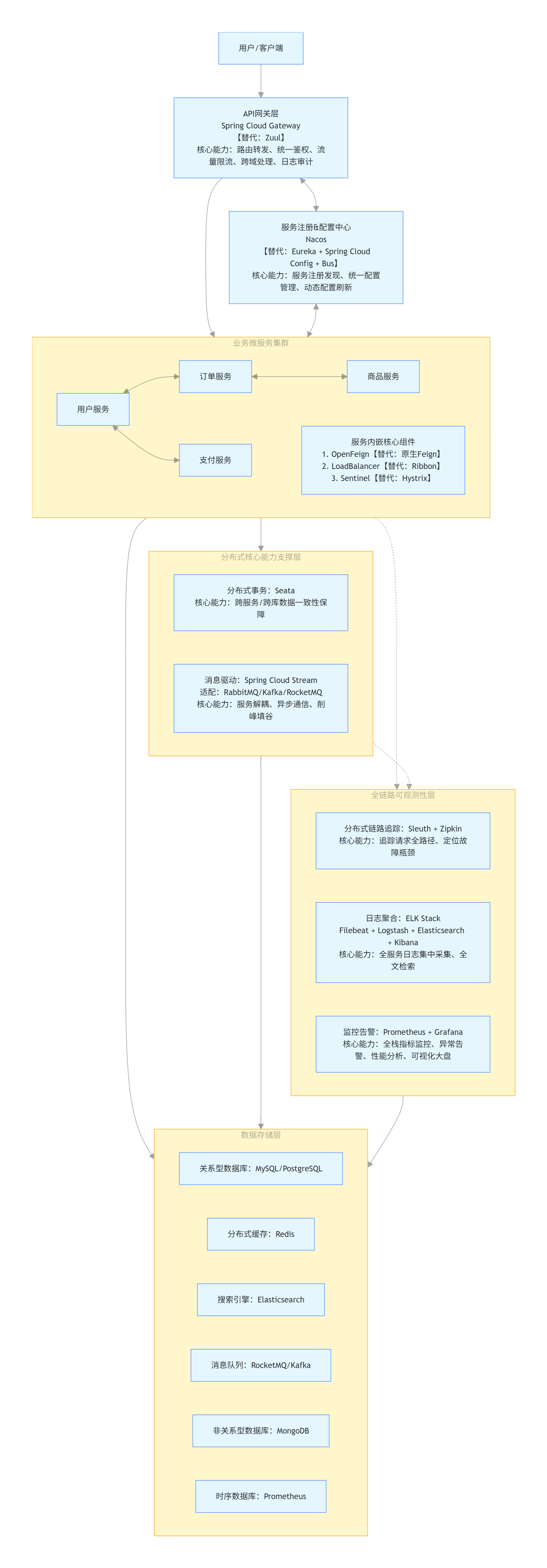
从用户请求开始:Spring Cloud 全组件详解(含演进历程、方案对比、替换原因)
本文严格按照用户请求的完整流转链路 拆解组件,完整覆盖「请求入口→寻址→配置→调用→负载均衡→流量防护→事务保障→链路追踪→日志监控」全流程,同时讲清每一个组件的核心作用、前世方案、今生主流、替换根因、核心特点。
一、Spring Cloud 整体演进背景
Spring Cloud 不是单一框架,而是一套微服务规范的组件合集,整体分为两大时代,所有组件的迭代替换都围绕这个核心背景展开:
- 初代 Netflix 时代(2014-2019) :以 Netflix 开源的一整套组件为核心,是早期微服务的事实标准,2018年起 Netflix 陆续宣布旗下核心组件进入停更维护模式,不再迭代新功能,仅修复致命bug。
- 现代主流时代(2019-至今):形成「Spring 官方原生迭代 + Spring Cloud Alibaba 开源补位」的双主线格局,国内生产环境90%以上采用 Spring Cloud Alibaba 生态,核心解决了初代组件停更、性能不足、功能单一、运维复杂的痛点。
二、用户请求全链路组件详解(按请求流转顺序)
链路第一步:用户请求入口 → 网关层
核心作用:所有用户请求的唯一入口,微服务的「大门」,负责路由转发、鉴权、限流、跨域、日志、协议转换等统一前置处理。
前世:初代方案 Zuul(Netflix)
- 版本迭代:Zuul 1.x → Zuul 2.x
- 核心特点:
- Zuul 1.x 基于 Servlet 同步阻塞IO模型,开发简单,完美适配 Spring MVC 早期生态
- 支持前置/后置/路由/错误4类过滤器,可自定义扩展
- 被淘汰的核心原因 :
- 同步阻塞模型存在致命性能瓶颈,高并发下线程池极易打满,吞吐量极低,线程在等 IO(等待服务响应)时,什么都不干,CPU 空闲,但线程被占着。
- . 不支持长连接、流式、WebSocket 等高阶场景、Servlet 3.1 之前对异步支持很差、WebSocket、推送、SSE 几乎没法玩、无法满足现代网关需求
- Netflix 想救 Zuul,于是重写 Zuul 2.x:基于 Netty 异步非阻塞性能。目标是 Zuul 1.x 的几倍
结果:开源一拖再拖、发布后与 Spring Cloud 生态几乎不兼容、配置复杂、文档极少、社区没人跟进、公司不敢上生产 - 官方停止迭代,无新功能更新,bug修复停滞
今生:当前主流方案 Spring Cloud Gateway
- Spring Cloud Gateway 由 Route、Predicate、Filter 三大核心组件构成,底层基于 WebFlux + Netty 实现异步非阻塞;主要功能包括:路由转发、负载均衡、统一鉴权、限流熔断、灰度发布、日志监控、跨域、长连接支持等,是微服务架构的统一流量入口。
- 核心特点:
-
- 基于 Spring WebFlux + Netty 异步非阻塞响应式模型,同等资源下吞吐量是 Zuul 1.x 的3-5倍,性能碾压
- 功能全面:内置「路由断言Predicate + 过滤器Filter」双核心机制,原生支持动态路由、限流熔断、权重路由、黑白名单、SSL、WebSocket
- 生态无缝适配:与 Nacos、Sentinel、LoadBalancer 等全家桶组件完美整合,开发成本极低
- 持续迭代:Spring 官方主力维护,版本更新快,适配最新 Spring Boot/Spring Cloud 版本
java
客户端请求
↓
Netty 接收连接(Reactor 异步非阻塞)
↓
DispatcherHandler(WebFlux 核心分发器)
↓
RoutePredicateHandlerMapping
↓
┌─────────────────────────────────────┐
│ 遍历所有 Route │
│ 对每个 Route 执行 Predicate 断言 │ → 不匹配 → 跳过
└─────────────────────────────────────┘
↓ 匹配成功
确定目标 Route(拿到 URI + 过滤器链)
↓
构建 Filter 执行链:
【GlobalFilter 全局过滤器】 + 【GatewayFilter 路由过滤器】
按 @Order 排序
↓
执行 前置过滤(Pre 逻辑)
如:鉴权、限流、请求头修改、日志
↓
Netty 路由转发
↓ 若 lb:// 则走 LoadBalancer 选取服务实例
↓ 发送请求到微服务
↓
微服务返回响应
↓
执行 后置过滤(Post 逻辑)
如:修改响应头、统一返回格式、耗时统计
↓
返回响应给客户端Netty 是什么?
Netty 是一个基于 NIO 的、高性能、异步非阻塞的网络通信框架。 写高性能网络服务的神器,专门用来做服务器、网关、通信中间件。
BIO(同步阻塞 IO)
一个连接占一个线程,连接一多,线程爆炸,服务器直接卡死。
Netty 是一个基于 Java NIO 的高性能异步非阻塞网络通信框架,封装了复杂的 NIO 操作,提供高效、稳定的网络编程能力。具有高吞吐、低延迟、可靠性强等特点,广泛用于网关、RPC、消息队列等中间件底层。Spring Cloud Gateway 就是基于 Netty 实现的高性能网关,Dubbo、RocketMQ、Elasticsearch、gRPC、Gateway 底层全是它。
传统MVC与Spring WebFlux
- 传统 MVC(Servlet 模型)
一个请求 → 占用一个线程
线程全程阻塞,等数据库、等远程接口、等响应
线程不干活也占着
高并发 → 线程不够用 → 服务卡死
特点:线程是稀缺资源,阻塞就是浪费。 - 响应式 WebFlux
一个线程能同时 handle 成千上万个请求
请求来了 → 注册回调 → 线程去干别的
等数据回来了 → 再找个线程继续处理
全程不阻塞、不等待
特点:CPU 一直在干活,不浪费资源。
响应式的核心思想(3 个关键点)
- 异步非阻塞
不阻塞线程,IO 等待时线程可以处理别的请求。 - 事件驱动
像 "消息通知" 一样:数据准备好了 → 通知处理而不是傻傻等着。 - 背压(Backpressure)
消费者处理不过来时,可以告诉生产者:别发太快,我扛不住
链路第二步:路由寻址 → 服务注册与发现中心
核心作用:微服务的「通讯录」,网关转发请求、服务间调用时,通过注册中心获取目标服务的IP、端口、健康状态,核心能力是服务注册、服务发现、健康检查、元数据管理。
前世:初代方案 Eureka(Netflix)
- 推出背景:Netflix 开源的服务注册发现组件,初代 Spring Cloud 核心标配
- 核心特点:
- 纯AP架构(CAP定理),优先保证可用性和分区容错性,牺牲强一致性,网络抖动时不会误删服务实例
- 自带自我保护机制:15分钟内超过85%的实例心跳异常时,保留所有实例,防止网络分区导致的服务误剔除
- 去中心化集群:节点平等无主从,任意节点宕机不影响集群运行
- 被替代的核心原因 :
- 致命问题:Eureka 2.0 开发计划流产,官方宣布1.x进入停更维护模式,不再更新新功能
- 功能极度单一:仅支持服务注册发现,不支持配置中心、权重路由、灰度发布等生产必备能力,需额外搭配多个组件,架构复杂度高
- 性能瓶颈:单节点支撑的服务实例数有限,大规模集群下性能衰减明显
- 运维门槛高:无中文控制台,不符合国内企业使用习惯
今生:当前主流方案 Nacos(Spring Cloud Alibaba,阿里开源)
- 推出背景:阿里2018年开源,2019年正式纳入 Spring Cloud Alibaba 生态,完美补位 Eureka 停更空白,是国内微服务生态的绝对主流注册中心
- 核心特点 :
- 双模式灵活切换:同时支持AP(高可用,普通服务调用)和CP(强一致性,分布式锁/配置推送)模式,而 Eureka 仅支持AP
- 一站式能力:既是注册中心,也是配置中心,一套集群搞定服务治理+配置管理,大幅降低架构复杂度和运维成本
- 生产级功能全覆盖:原生支持权重路由、灰度发布、健康检查、流量控制、元数据管理、集群同步,完全覆盖生产场景
- 性能强悍:单节点可支撑10万+服务实例,集群水平扩展能力远超 Eureka
- 易用性拉满:自带中文可视化控制台,运维门槛极低,与 Spring Cloud 全生态无缝集成
- 持续迭代:阿里主力维护,社区活跃,经过双11万亿级流量考验,稳定性极强
CAP 理论
一、CAP 是什么
分布式系统三大核心指标,三者不可同时满足,最多三选二:
C 一致性:所有节点数据时刻一致,读写均为最新值
A 可用性:服务持续可用,每次请求都正常响应
P 分区容忍性:节点间网络中断时,系统仍可正常运行
二、核心结论
只能选择 CP 或 AP,CA 架构在分布式场景中不存在。
三、为什么必须选 P
因为网络不可靠,网络分区必然发生(机房光纤断了、交换机故障、防火墙策略异常、跨区域网络抖动、云厂商网络波动)。若放弃 P,一旦网络异常系统直接瘫痪,无法满足分布式基本要求,因此P 为必选项,只能在 C 和 A 之间取舍。
链路第三步:服务启动&运行时配置 → 配置中心
核心作用:微服务的「配置管家」,统一管理所有服务的配置文件,解决分布式环境下配置分散、修改配置需重启服务的痛点,支持多环境隔离、动态刷新、版本管理、灰度发布。
前世:初代方案 Spring Cloud Config + Spring Cloud Bus
- 推出背景:Spring 官方原生配置中心方案,需配合 Git/SVN 存储配置,配合 Spring Cloud Bus(基于 RabbitMQ/Kafka)实现配置动态刷新
- 核心特点:基于 Git 存储配置,天然支持版本管理、审计追溯,与 Spring 生态原生适配
- 被替代的核心原因 :
- 架构复杂、依赖过多:必须依赖 Git 存储,必须配合 Bus + MQ 才能实现动态刷新,一套配置中心需要至少3个组件,部署运维成本极高
- 动态刷新能力弱:原生不支持配置实时推送,需手动触发或配合 Bus 广播,延迟高、体验差
- 功能缺失:不支持灰度发布、权限控制、配置加密、多租户等生产必备能力,需大量二次开发
- 无原生可视化控制台,配置管理需基于 Git 操作,运维门槛高
今生:当前主流方案 Nacos Config(Spring Cloud Alibaba)
- 推出背景:Nacos 内置的配置中心模块,与 Nacos 注册中心共用一套集群,一套部署搞定两大核心能力
- 核心特点 :
- 架构极简:与注册中心共用集群,无需额外部署组件,运维成本极低
- 原生实时动态刷新:配置修改后毫秒级推送到所有服务实例,无需重启服务,无需额外配合消息总线
- 生产级功能全覆盖:内置多环境隔离、版本管理、灰度发布、配置加密、权限控制、一键回滚、监听查询
- 易用性拉满:自带中文管理界面,配置修改、查询、回滚一键操作
- 无缝迁移:注解与 Spring Cloud Config 几乎完全兼容,老项目迁移成本极低
链路第四步:服务间远程调用 → 服务调用组件
核心作用:网关转发到上游服务后,服务之间的跨节点调用(比如订单服务调用用户/商品服务),让开发者像调用本地方法一样调用远程 HTTP 服务,无需手动封装请求代码。
前世:初代方案 Feign(Netflix)
- 推出背景:Netflix 开源的声明式 HTTP 客户端,初代 Spring Cloud 标配服务调用组件
- 核心特点:基于注解定义接口,无需手动封装 HTTP 请求,原生整合 Ribbon 负载均衡、Hystrix 熔断降级,开箱即用
- 被替代的核心原因 :
- Netflix 宣布 Feign 进入停更维护模式,不再更新新功能
- 原生不支持 Spring MVC 注解,需使用 Feign 自带注解,与 Spring 生态开发体验割裂
- 功能单一,不支持响应式编程、异步调用,无法适配 Spring WebFlux 新生态
今生:当前主流方案 OpenFeign(Spring 官方)
- 推出背景:Spring 官方在 Netflix Feign 基础上二次开发的组件,完全兼容 Spring 生态,是目前官方唯一推荐的服务调用组件
- 核心特点 :
- 完美适配 Spring MVC 注解:可直接使用 @GetMapping、@PostMapping 等常用注解定义接口,零学习成本,与 Spring Boot 开发体验完全一致
- 全生态适配:原生整合 LoadBalancer 负载均衡、Sentinel 熔断降级、Nacos 服务发现,开箱即用
- 功能全面增强:支持超时配置、重试机制、请求/响应拦截器、日志打印、异步调用、响应式编程,完全覆盖生产场景
- 持续迭代:Spring 官方主力维护,适配最新 Spring Boot/Spring Cloud 版本
链路第五步:流量分发 → 客户端负载均衡组件
核心作用 :当一个服务有多个实例时,决定请求分发到哪个实例,实现流量均匀分发,提升系统可用性和吞吐量。Spring Cloud 体系内均为客户端负载均衡,负载逻辑在消费者本地执行,无需经过中间代理节点。
前世:初代方案 Ribbon(Netflix)
- 推出背景:Netflix 开源的客户端负载均衡组件,初代 Spring Cloud 标配,与 Feign、Eureka 无缝整合
- 核心特点:内置轮询、随机、权重、响应时间加权、最小连接数等多种策略,自带重试容错机制,客户端负载均衡的经典实现
- 被替代的核心原因 :
- Netflix 宣布 Ribbon 进入停更维护模式,不再更新新功能
- 不支持响应式编程,无法适配 Spring WebFlux、Spring Cloud Gateway 等新一代响应式组件
- 代码老旧、架构臃肿,Spring 官方推出了更轻量、更适配新生态的替代方案
今生:当前主流方案 Spring Cloud LoadBalancer(Spring 官方)
- 推出背景:Spring 官方自研的新一代客户端负载均衡组件,专门替代 Ribbon,Spring Cloud 2020版本之后的默认负载均衡组件
- 核心特点 :
- 轻量极简:代码量远小于 Ribbon,无冗余依赖,启动更快、资源占用更低
- 全生态适配:完美适配 OpenFeign、Gateway、Nacos 等全生态组件
- 原生支持响应式编程:适配 Spring WebFlux 响应式生态,完美兼容 Gateway 等新一代组件,这是 Ribbon 完全不具备的能力
- 扩展灵活:内置轮询、随机两种基础策略,支持自定义负载均衡策略,可与 Nacos 权重路由无缝整合
链路第六步:流量防护 → 熔断限流降级组件
核心作用:微服务的「保险丝」,防止服务故障引发级联雪崩,核心能力是流量控制、熔断降级、系统保护,保障高并发下系统的稳定性。
前世:初代方案 Hystrix(Netflix)
- 推出背景:Netflix 开源的熔断器组件,「断路器模式」的经典实现,初代 Spring Cloud 流量防护标配
- 核心特点:经典断路器机制(失败率达标自动熔断),支持线程池/信号量隔离、降级、超时控制,从根源上防止故障扩散
- 被淘汰的核心原因 :
- 致命问题:Netflix 2018年正式宣布 Hystrix 停止开发,进入维护模式,不再更新新功能
- 功能极度单一:仅支持熔断降级,不支持限流、热点参数限流、系统负载保护、集群限流等生产必备能力,需额外搭配多个组件
- 性能损耗大:线程池隔离模式开销大,高并发下性能衰减明显
- 运维成本高:无原生监控界面,需配合 Hystrix Dashboard + Turbine 实现集群监控,架构复杂
今生:当前主流方案 Sentinel(Spring Cloud Alibaba,阿里开源)
- 推出背景:阿里2018年开源,2019年纳入 Spring Cloud Alibaba 生态,国内微服务流量防护的绝对主流,完美补位 Hystrix 停更空白
- 核心特点 :
- 全场景流量防护:不仅支持熔断降级,还原生支持流量控制、热点参数限流、系统负载保护、黑白名单、集群限流,一套组件搞定所有流量防护需求
- 轻量高性能:核心无冗余依赖,单节点QPS可达10万+,性能损耗极低,远超 Hystrix
- 易用性极强:注解与 Hystrix 高度兼容,老项目迁移成本极低
- 运维门槛低:自带中文实时监控控制台,支持流量实时查看、规则动态配置,无需额外部署组件
- 生态全适配:与 Gateway、OpenFeign、Nacos、Dubbo 无缝集成,经过双11万亿级流量考验,稳定性极强
链路第七步:跨服务数据一致性 → 分布式事务组件
核心作用:解决跨服务、跨数据库的事务一致性问题(比如下单流程:订单服务创建订单、库存服务扣减库存、支付服务扣减余额,需保证所有操作要么全成功、要么全回滚)。
前世:初代无标准化方案
- 早期 Spring Cloud 原生没有官方分布式事务组件,行业内只能手动实现 2PC(JTA/XA)、TCC、SAGA、本地消息表、最大努力通知等方案
- 核心痛点:无标准化框架,开发成本极高、代码侵入性强、运维难度大、无法与 Spring Cloud 生态无缝整合
今生:当前主流方案 Seata(Spring Cloud Alibaba,阿里开源)
- 推出背景:阿里2019年开源,纳入 Spring Cloud Alibaba 生态,国内微服务分布式事务的事实标准,一站式解决分布式事务问题
- 核心特点 :
- 全场景多模式支持:原生支持AT模式(无侵入自动模式)、TCC模式、SAGA模式、XA模式,四大模式覆盖所有分布式事务场景,可根据业务灵活选择
- 零侵入低门槛:王牌AT模式基于本地JDBC数据源自动实现事务提交/回滚,对业务代码零侵入,彻底解决传统分布式事务开发难度大的痛点
- 高性能:经过双11万亿级流量考验,性能远超传统2PC方案,单集群可支撑上万分布式事务并发
- 生态全适配:与 Nacos、Sentinel、OpenFeign、Mybatis 等全生态无缝集成,适配所有主流数据库
- 运维友好:自带中文管理界面,支持事务状态查看、异常事务回滚、集群监控
链路第八步:故障定位 → 分布式链路追踪组件
核心作用:一个请求会经过多个微服务,当出现报错、超时时,通过链路追踪组件还原请求的完整流转路径,快速定位故障点和性能瓶颈。
前世&今生:主流方案 Spring Cloud Sleuth + Zipkin
- 演进说明:该方案是 Spring 官方原生方案,一直持续迭代,至今仍是中小厂首选,无大规模替代,仅存在功能更全面的补充方案
- 组件分工:
- Spring Cloud Sleuth:链路埋点组件,请求进入服务时自动生成 TraceId(整条请求的唯一ID)和 SpanId(每个服务节点的ID),服务间调用时自动传递,对业务代码零侵入
- Zipkin:链路收集、存储、可视化组件,接收 Sleuth 上报的链路数据,提供可视化界面,通过 TraceId 可查询整条请求的流转路径、耗时、异常信息
- 核心特点:零侵入开箱即用,全生态适配,支持网关、OpenFeign、MQ、数据库等全场景链路追踪,可视化能力强
- 演进补充:
- 新兴替代方案:SkyWalking(华为开源)、Pinpoint(Naver开源),属于APM全链路监控工具,不仅支持链路追踪,还覆盖服务监控、性能分析、告警等能力,功能更全面,国内大厂广泛使用
- 未来趋势:Spring Cloud 2023版本之后,Sleuth 停止迭代,官方推荐使用 Micrometer Tracing 替代,适配 Zipkin、OpenTelemetry 等标准
链路第九步:日志排查 → 日志聚合组件
核心作用:解决微服务日志分散存储、排查问题需登录多台服务器的痛点,实现全服务日志的集中采集、存储、检索。
前世&今生:主流方案 ELK Stack(Elasticsearch + Logstash + Kibana + Filebeat)
- 演进说明:ELK 一直是日志聚合的行业标准,持续迭代至今,无大规模替代,仅存在轻量化变体方案(EFK:Elasticsearch + Fluentd + Kibana)
- 组件分工:
- Filebeat:轻量日志采集组件,部署在服务实例所在服务器,负责采集日志文件并上报
- Logstash:日志处理组件,负责日志的过滤、格式化、转换,写入 Elasticsearch
- Elasticsearch:分布式搜索引擎,负责存储日志数据,提供毫秒级全文检索能力
- Kibana:可视化控制台,负责日志的查询、检索、可视化、告警,可通过 TraceId 一键查询整条请求的全链路日志
- 核心特点:覆盖日志采集-过滤-存储-检索-告警全流程,全文检索能力极强,生态成熟,是行业标准方案
链路第十步:稳定性保障 → 监控告警组件
核心作用:实时监控微服务的运行状态、CPU、内存、GC、接口响应时间、错误率等指标,异常时及时告警,保障系统稳定运行。
前世:初代方案 Spring Boot Admin
- 推出背景:Spring 社区开源的轻量监控组件,专门针对 Spring Boot/Spring Cloud 服务
- 核心特点:开箱即用,与 Spring Boot 生态完美适配,支持服务健康检查、内存/线程/GC监控、配置查看、日志级别调整,轻量极简
- 局限性:仅支持 Spring 生态服务,无法监控数据库、MQ、服务器等组件;监控指标有限,无法自定义复杂告警规则;不支持大规模集群监控
今生:当前主流方案 Prometheus + Grafana
- 推出背景:Prometheus 是 CNCF 毕业的开源监控系统,Grafana 是可视化工具,目前是云原生、微服务监控的行业标准
- 组件分工:
- Prometheus:时序数据库,通过 Exporter 采集服务、服务器、数据库、MQ 等全栈组件的监控指标,存储并执行告警规则
- Grafana:可视化控制台,对接 Prometheus 制作监控大盘,实现指标可视化展示、多渠道告警通知
- 核心特点 :
- 全栈监控:覆盖服务器、数据库、MQ、微服务、网关等所有组件,一套系统搞定全栈监控
- 自定义能力极强:支持 PromQL 自定义查询,可实现任意复杂的监控规则和告警策略
- 扩展性极强:支持集群部署,水平扩展能力拉满,可支撑超大规模集群监控
- 生态成熟:云原生标准方案,社区活跃,文档丰富,持续迭代
三、Spring Cloud 全链路演进核心逻辑
所有组件的替换,都遵循4个不可逆转的核心原因:
- 停更风险:Netflix 旗下核心组件陆续停止开发,无新功能更新,无法满足生产环境的持续迭代需求
- 性能升级:初代组件大多为同步阻塞模型,高并发下性能不足;新一代组件普遍采用异步非阻塞模型,性能有质的提升
- 架构简化:初代组件大多只解决单一问题,需多个组件配合才能满足生产需求;新一代组件多为一站式解决方案,大幅降低架构复杂度和运维成本
- 生态适配:新一代组件完美适配 Spring Boot/Spring Cloud 最新版本,支持响应式编程、云原生等新趋势,而初代组件架构老旧,无法适配新生态
四、国内生产环境主流 Spring Cloud 技术栈
| 组件职责 | 当前主流方案 | 已淘汰/非主流方案 |
|---|---|---|
| 网关 | Spring Cloud Gateway | Zuul 1.x/2.x |
| 注册中心 | Nacos | Eureka、Consul、Zookeeper |
| 配置中心 | Nacos Config | Spring Cloud Config + Bus |
| 服务调用 | OpenFeign | Netflix Feign |
| 负载均衡 | Spring Cloud LoadBalancer | Netflix Ribbon |
| 熔断限流降级 | Sentinel | Netflix Hystrix |
| 分布式事务 | Seata | 手动实现TCC/SAGA/2PC |
| 链路追踪 | Spring Cloud Sleuth + Zipkin / SkyWalking | 无标准化方案 |
| 日志聚合 | ELK Stack(Elasticsearch+Logstash+Kibana+Filebeat) | 分散日志存储 |
| 监控告警 | Prometheus + Grafana | Spring Boot Admin(仅轻量场景) |
| 消息驱动 | Spring Cloud Stream | 原生MQ API开发 |