📝 前言
在云原生架构中,系统就像一个"黑盒"。如果没有监控,任何故障排查无异于盲人摸象。Prometheus + Grafana 的组合是目前 SRE/运维领域绝对的行业标准。
本文使用 Helm(K8s的包管理器) 一键拉起包含 Prometheus、Grafana、Alertmanager 在内的全栈可观测性平台,并最终呈现专业级的宿主机硬件监控大屏。
1. 项目核心架构
-
Prometheus:负责从集群各个节点和 Pod 中周期性地"拉取(Pull)"指标数据。
-
Node Exporter:安装在宿主机上,采集 CPU、内存、磁盘等硬件指标。
-
Grafana:负责将 Prometheus 里的枯燥数字变成炫酷的图表。
-
Alertmanager:当指标超过阈值(如内存 > 90%)时,负责发送告警。
项目背景: 为解决 Kubernetes 集群缺乏全局可观测性、故障排查困难的问题,主导落地了企业级的开源监控解决方案。
核心技术: Kubernetes, Helm, Prometheus, Grafana, PromQL
主要工作与难点攻克:
使用 Helm 包管理工具实现
kube-prometheus-stack的标准化部署,摒弃了手动维护大量 YAML 文件的低效方式。深度介入网络排障,解决了 Port-forward 机制在特定网络策略下的转发失效问题(Service 端口不对齐导致的 502 错误),确保外部安全访问。
引入并调优业内最佳实践的 Node Exporter (ID:1860) 数据大屏,精准配置 Prometheus 数据源,解决了冷启动时序数据展示丢失(视觉陷阱)的问题。
项目成果: 成功实现了对节点硬件资源(CPU/内存/网络/磁盘IO)的毫秒级实时采集与可视化,为后续的 HPA 弹性伸缩和告警系统提供了坚实的数据底座。
🛠️ 1. 环境准备与 Helm 仓库配置
1.1 确保安装了Helm
sql
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash1.2 添加 Prometheus 官方 Chart 仓库并更新
sql
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update🚀 2. 一键部署监控"全家桶"
只需一行命令,Helm 就会自动为你创建所有的 Pod、Service、ConfigMap 以及采集规则。
sql
# 创建独立的命名空间并一键安装整个监控栈
helm install my-monitor prometheus-community/kube-prometheus-stack --namespace monitoring --create-namespace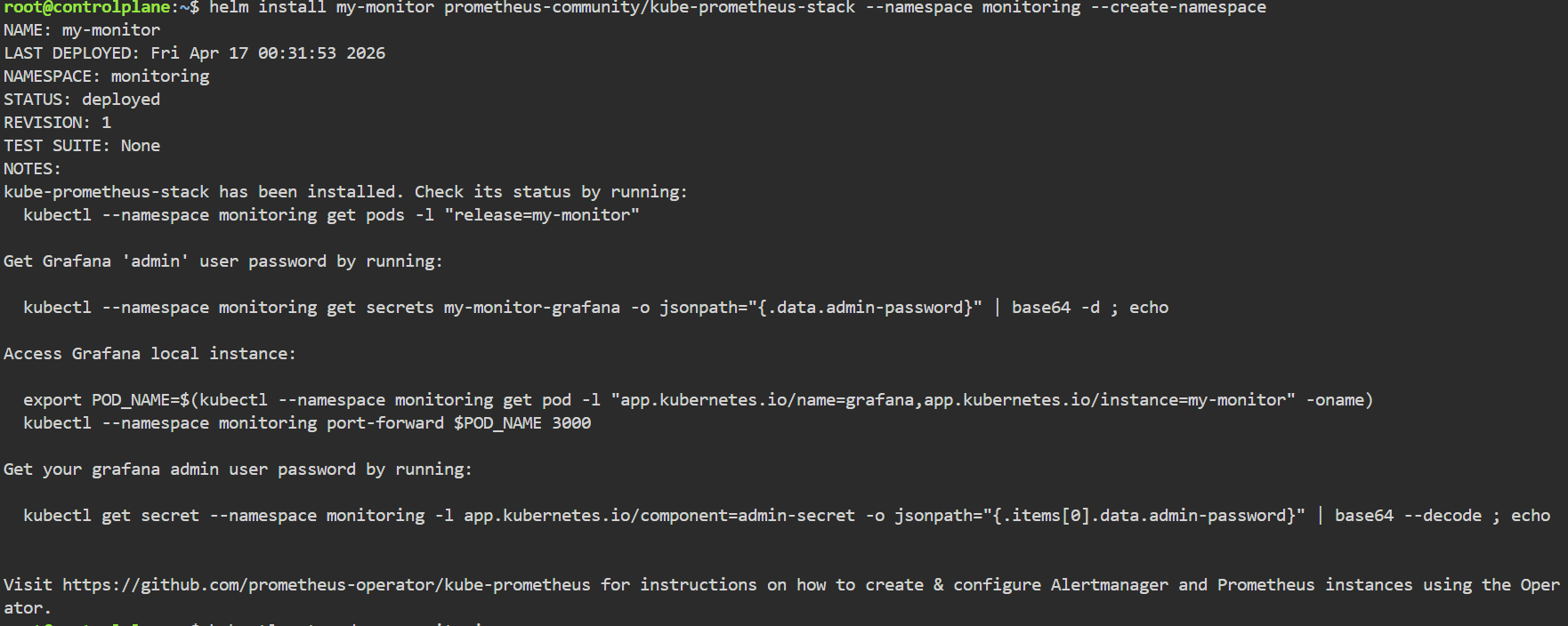
sql
#查看,直到所有 Pod 状态变为 Running
kubectl get pods -n monitoring 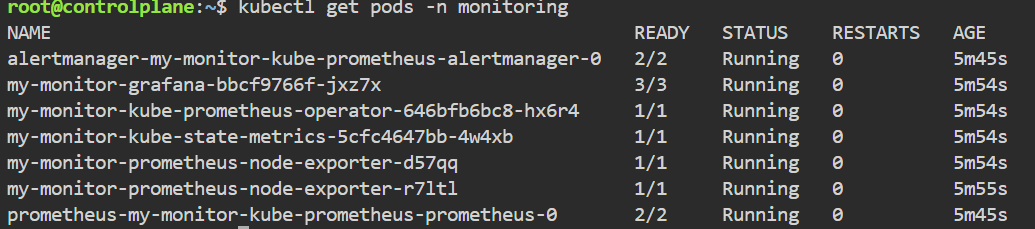
完成!
🔑 3.获取动态密码与打通访问隧道
Grafana 默认出于安全考虑,不会在外部直接暴露端口,且密码是随机生成的。
3.1 提取admin初始密码
sql
kubectl get secret --namespace monitoring my-monitor-grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echo(将输出的字符串保存好,这是你的登录凭证)
3.2 建立端口映射通道
避坑指南 :很多新手在这一步会遇到 502 Bad Gateway。原因是本地端口与集群内 Service 端口未对齐。Grafana 的 Service 端口是 80!
sql
# 将主机的 3000 端口映射到 Grafana Service 的 80 端口
kubectl port-forward svc/my-monitor-grafana 3000:80 -n monitoring --address 0.0.0.0 &🎨 4.登录并导入神级大屏 (1860)
1. 登录 Grafana 打开浏览器,访问 http://<你的服务器IP>:3000 (如果是沙盒环境,请使用其提供的流量转发入口)。
-
用户名:
admin -
密码:刚才提取的字符串
2. 导入 Node Exporter 面板
-
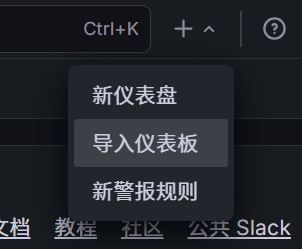
点击左侧菜单栏的 Dashboards -> Import。
-
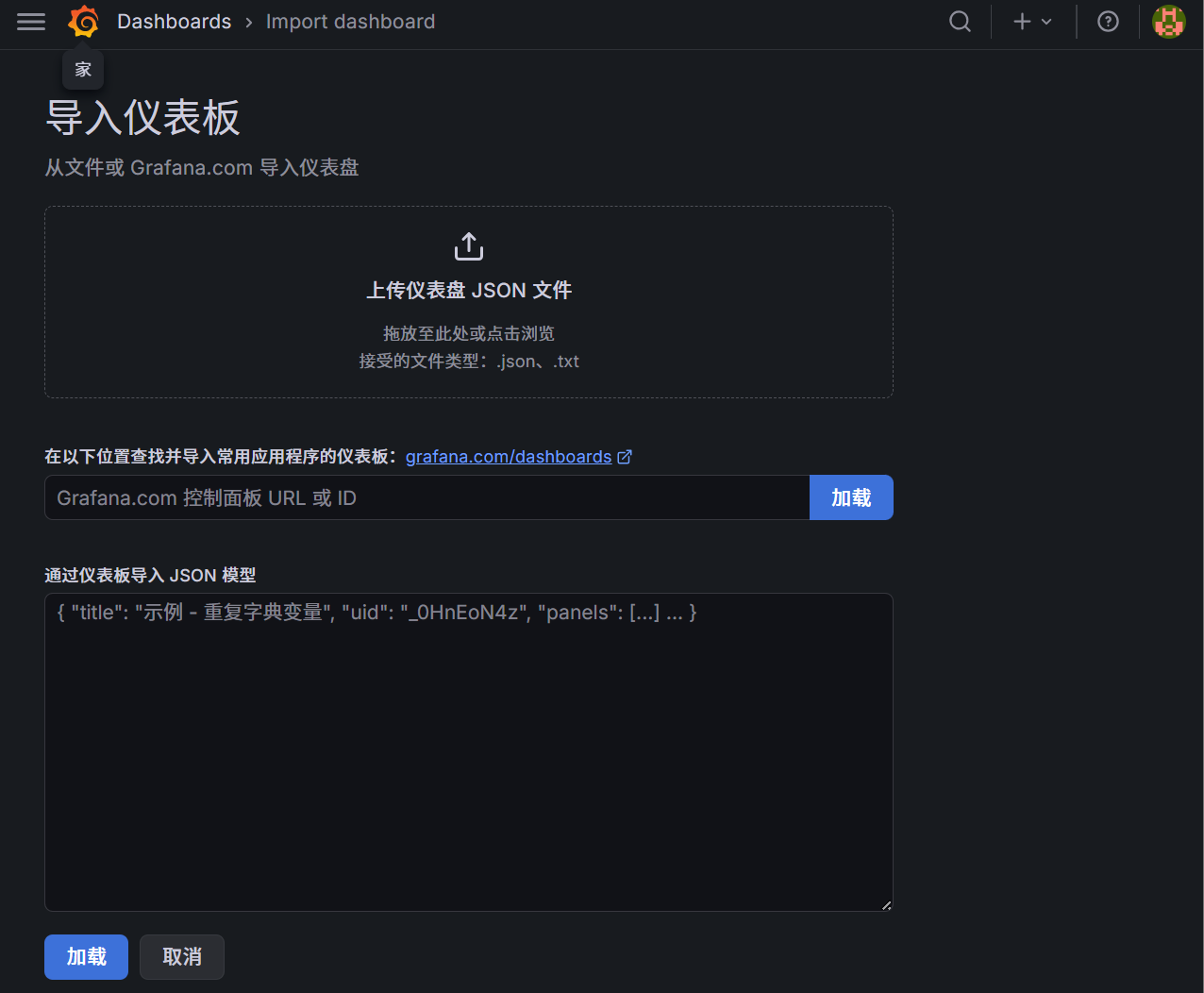
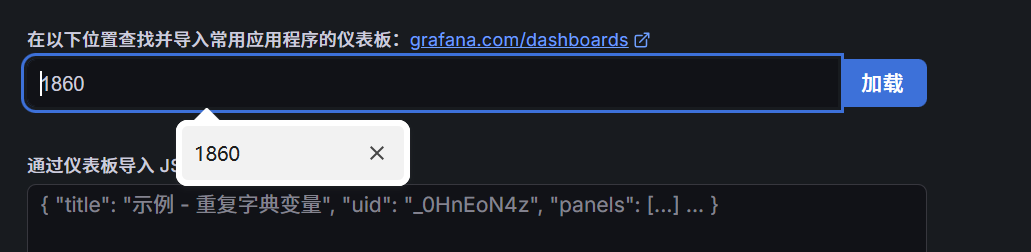
在 "Import via grafana.com" 输入框填入黄金面板 ID:
1860,点击 Load。 -
在最下方的
Prometheus数据源下拉框中,选择已安装的 Prometheus 数据源。 -
点击 Import 按钮。
导入
点击右边的加载后
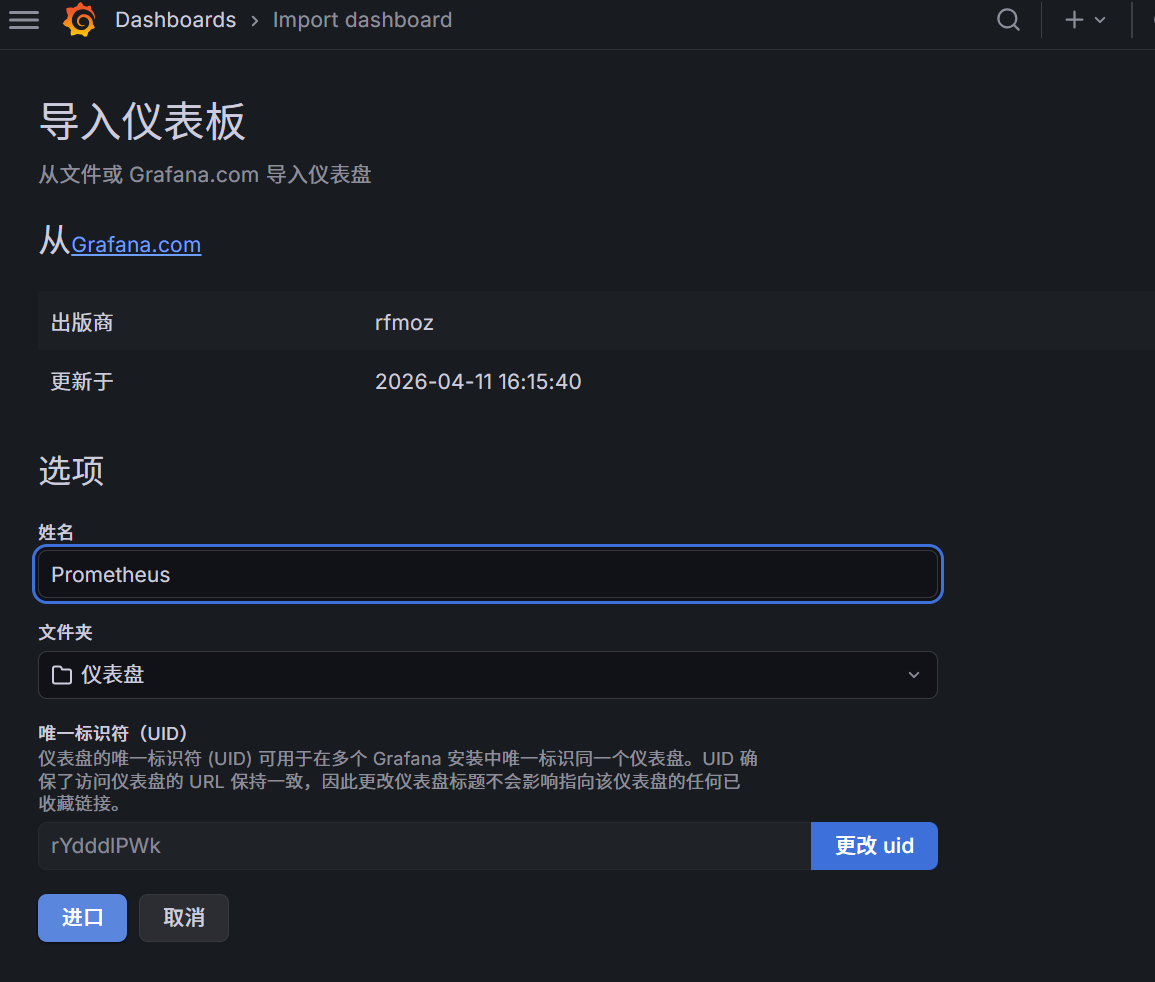
点击进口,如果报错重新刷新一下就行
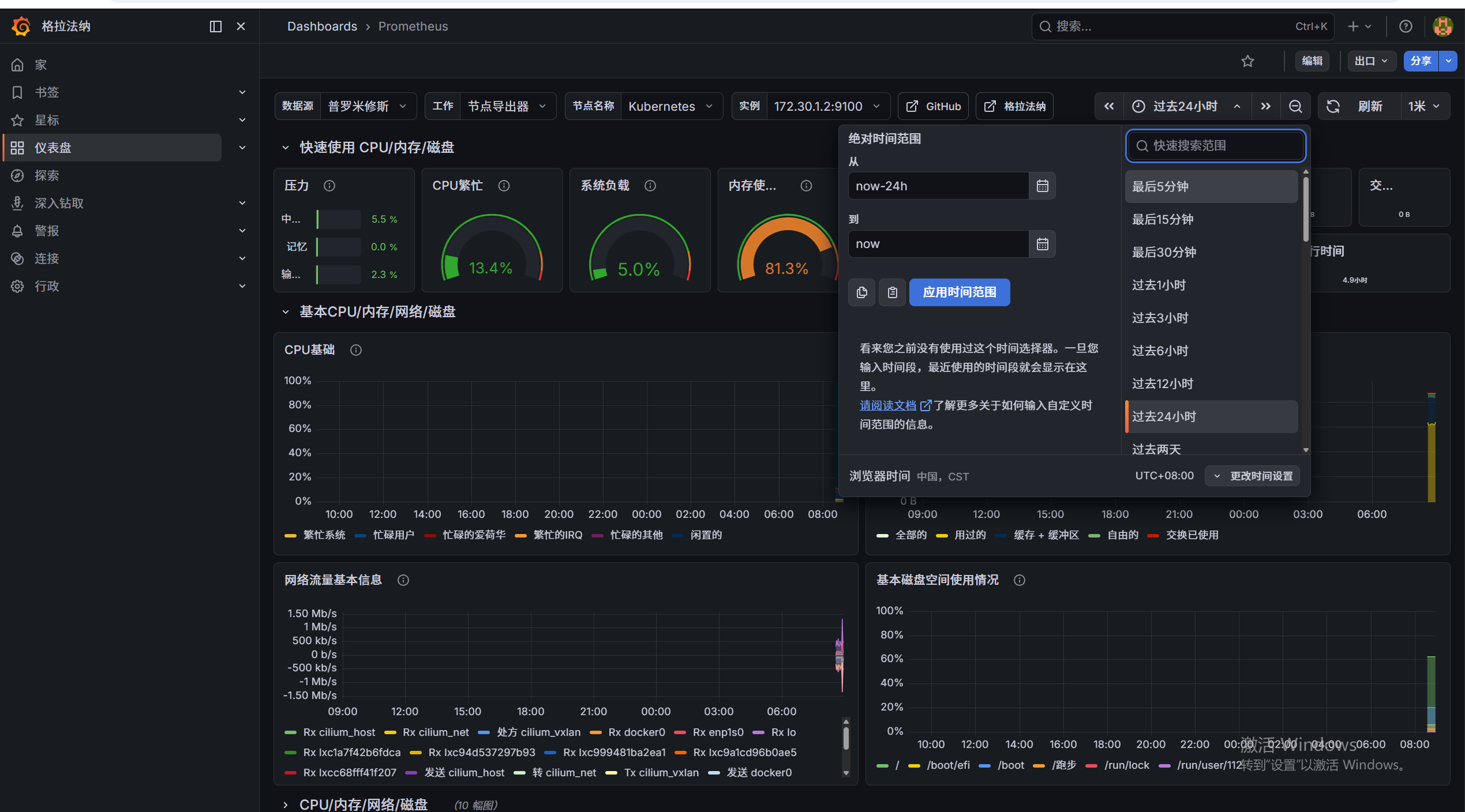
点击最后5分钟(更有动态感)
3. 解决"折线图不显示"的视觉陷阱
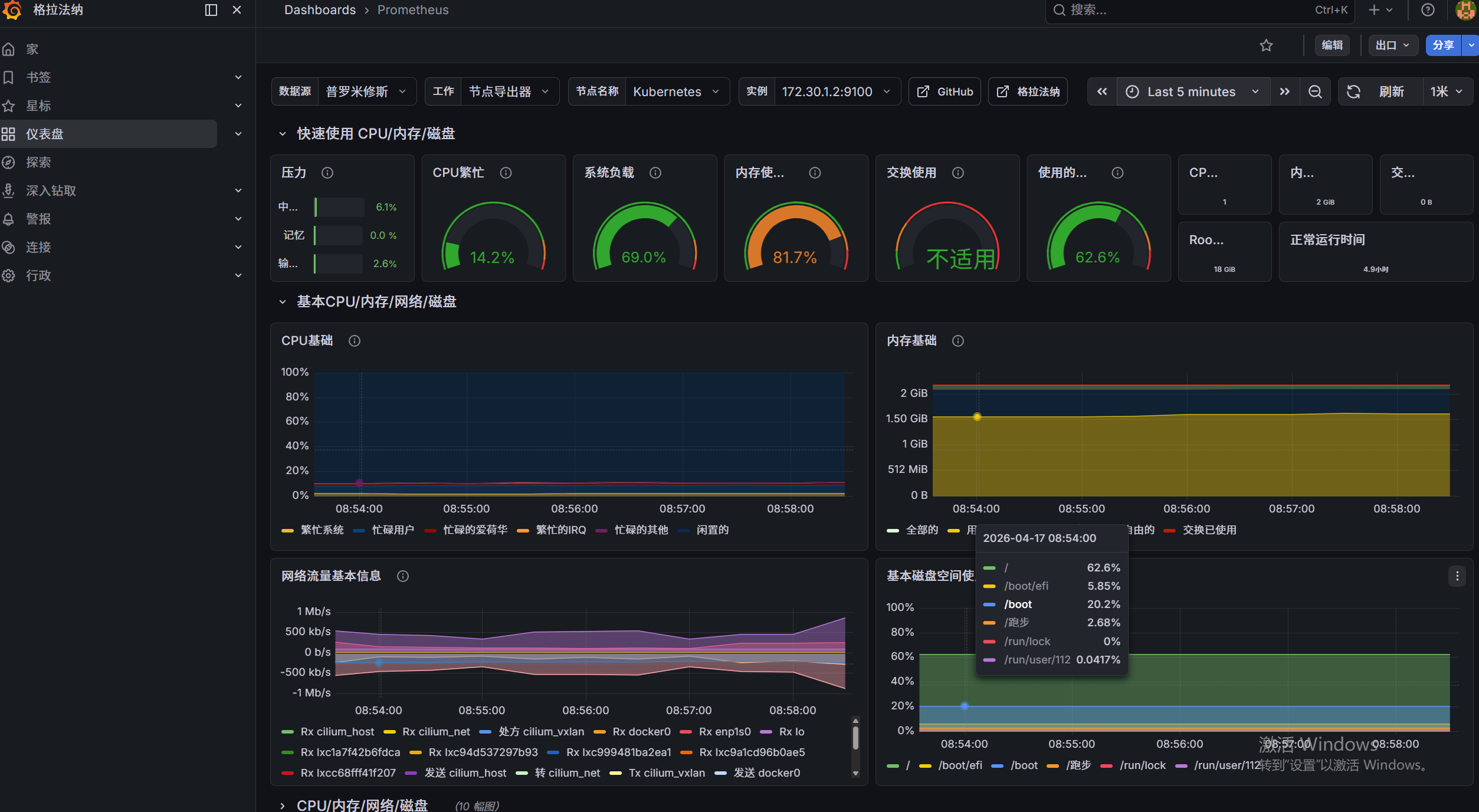
避坑指南 :刚导入面板时,下方图表可能没有线条显示。这不是报错!因为集群刚启动,缺乏历史数据。 解决方法 :点击页面右上角的
Last 24 hours,将其修改为Last 5 minutes。同时点击旁边的刷新按钮设置5s自动刷新。你将立刻看到满屏跳动的精美监控曲线!
🎯 5.验收标准 (Do Definition of Done)
如果你成功完成了该项目,你应该能够:
-
成功登录 Web 界面:不报 502 错误,隧道畅通。
-
数据流打通:在面板中能看到具体的数字(如 CPU 繁忙率、内存使用率)。
-
趋势可视化:在 5 分钟视图下,能清晰看到各硬件指标随时间波动的彩色折线图。