问数项目是一个基于自然语言处理与数据分析技术的智能数据服务系统,面向数据仓库应用场景,旨在帮助用户通过对话方式高效获取数据仓库中的数据洞察。用户无需掌握复杂的查询语法,即可用自然语言提出问题,系统自动完成对数据仓库数据的理解、计算分析与结果可视化,大幅提升数据使用效率,降低数据分析门槛,助力业务决策智能化。
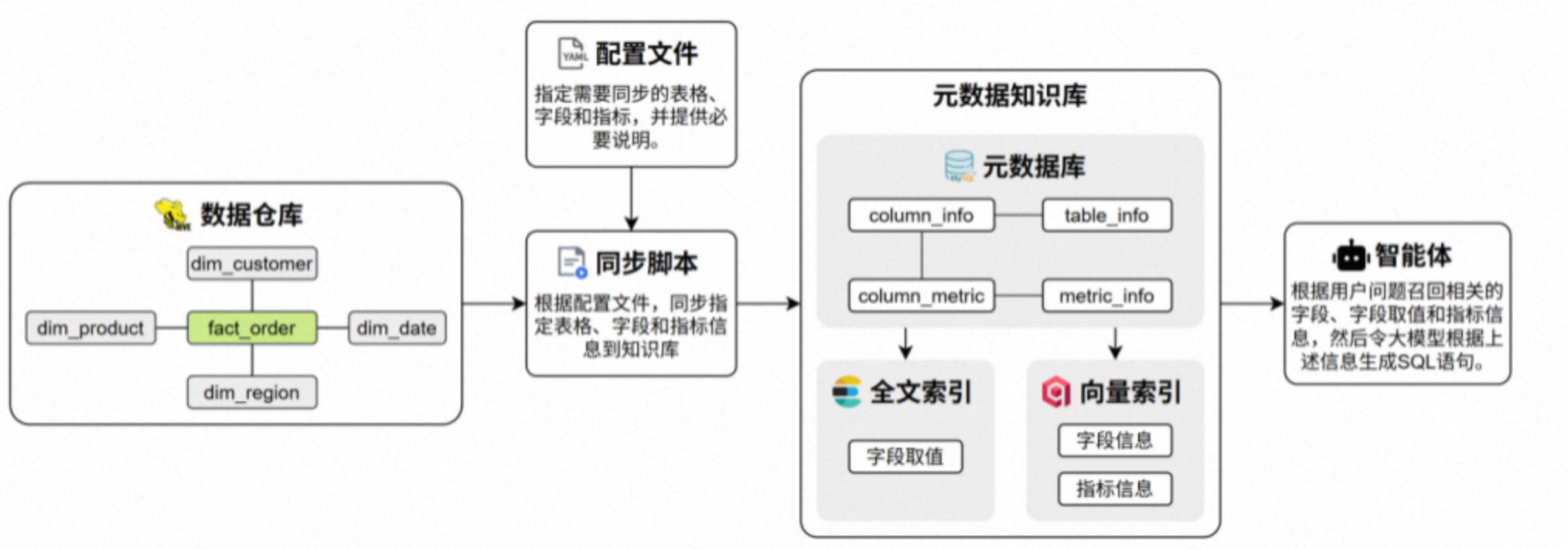
本项目以数据仓库的元数据为核心,使用 MySQL 存储结构化元数据信息,结合 Qdrant 构建语义向量索引、Elasticsearch 构建全文索引,形成统一的元数据知识库。查询过程中,系统首先根据用户自然语言问题进行多路召回,筛选相关表、字段及指标定义,再将元数据信息与用户问题共同输入大模型生成 SQL,最终完成自动查询与结果返回,确保生成结果的准确性与可控性。
架构
元数据库
元数据知识库作为数据仓库的语义基础设施,用于集中管理和高效检索表结构、字段定义、字段取值示例及复杂指标说明等元数据信息,支撑后续的SQL 生成。
完整的元数据统一存储于 MySQL 数据库中,并对其中部分关键信息构建向量索引和全文索引,以提升语义召回与关键词召回的效果。
元数据一共有四张表:

column_info记录所有维度表/事实表的字段信息
table_info记录有多少张维度/事实表
metric_info 记录指标的信息
column_metric 记录指标的详细信息
问题:上述元数据库多了两个metrci相关的表(指标)?
在数据仓库中,数据是以"明细(事实)"或"基础聚合"的形式存在的;而"指标(Metric)"通常是一段业务计算逻辑,它不需要在数仓里变成一张单独的表。
指标通常是,比如销量全额这种,通过对事实表的数据表的数据进行计算得到
元数据库的指标信息是给大模型用的。
举个例子:GMV(成交总额),大模型并不知道,如果直接去看数仓的表结构,则获取不到对应的数据。
这就需要元数据库中的metric_info和column_metric了。
metric_info会记录GMV是什么,他的计算逻辑是什么,而column_metric(关联记录表)则会记录这个指标依赖了fact_order表的order_amount字段。
对其数据进行向量索引,当用户提问GMV时,就能检索对应的数据,然后交给大模型,大模型就知道了GMV怎么计算,怎么写sql了。
同步dw数据库(数据仓库)到meta数据库(元数据)
现有dw数据库(一般是在数据仓库(hive),这里先用mysql代替),里面存放着事实表,维度表等相关表。
需要对其同步落到元数据库
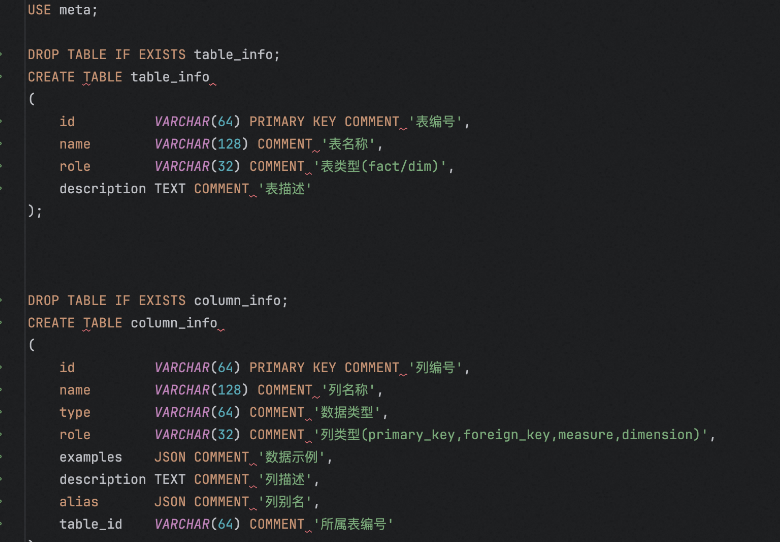
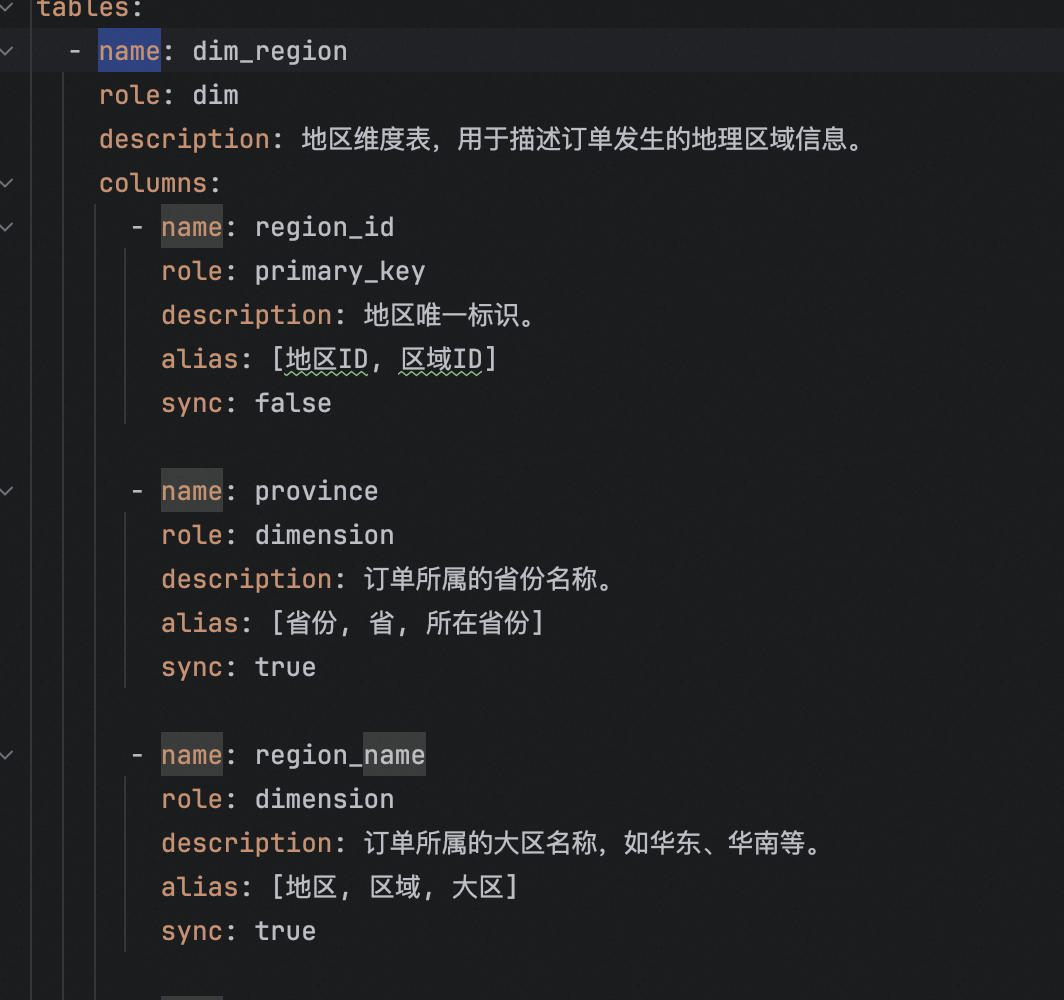
将dw维度事实表的表,表名+字段,抽出落到meta表中,如上,tbale_info和column_info
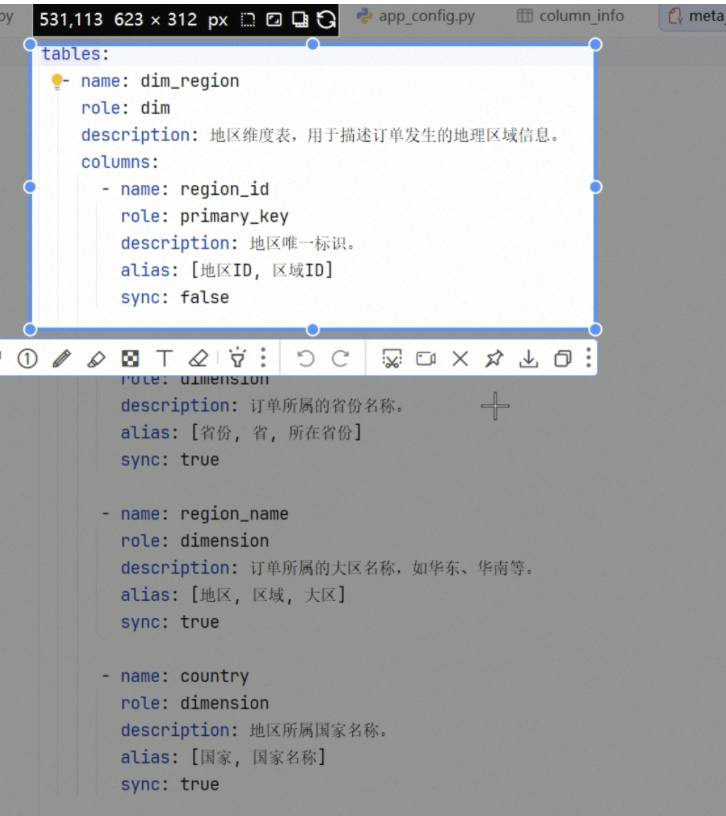
如上,地区维度表中的columns,就是每一条需要落到meta_column_info的数据,而每一个table,就需要落到meta_table_info中。
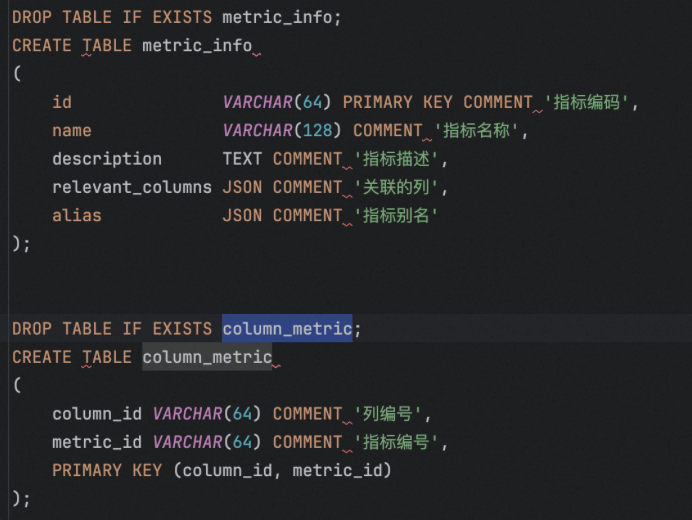
对于指标信息,其不在dw数据库中,但其数据可以通过汇总dw的某些字段所得,故将其落在元数据库中,如meta_mertic_ifon,指标表,meta_column_metric,指标的列信息。
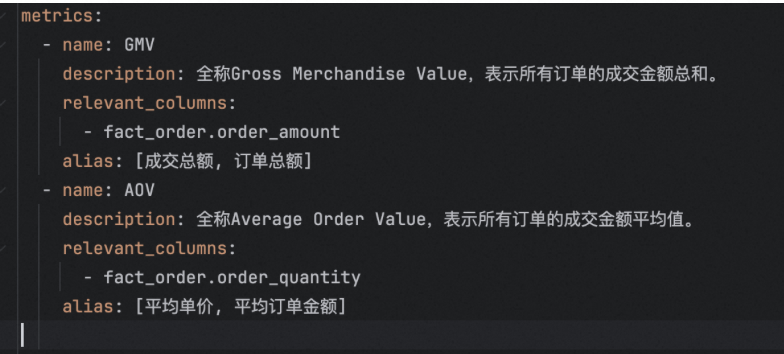
指标的配置文件,将其落到元数据库的metric_info中,其中columns则落到column_metric中。
为元数据库内容建立向量索引
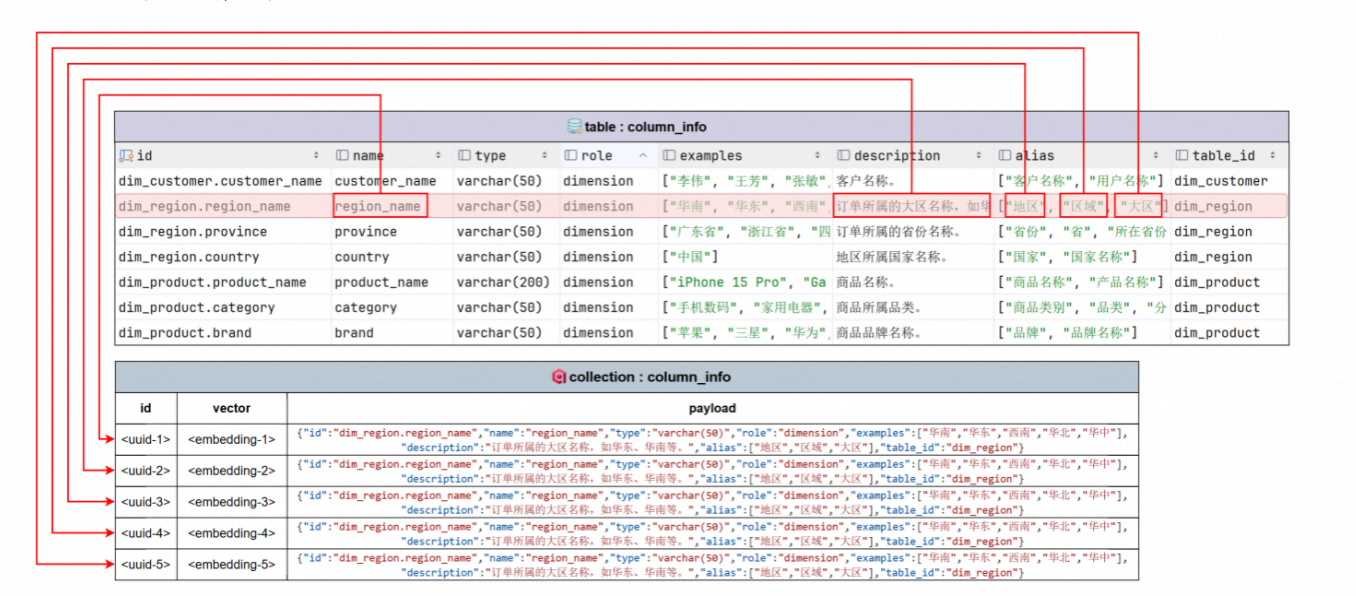
向量索引主要用于对column_info(*字段信息* )和metric_info(*指标信息*)进行语义召回。
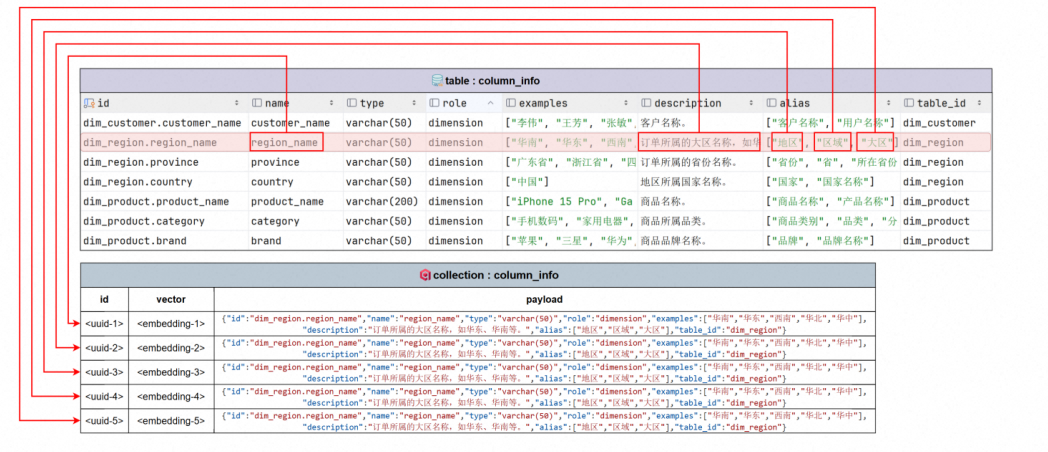
如上,比如一条数据中,在column_info中,有name字段,description字段,alias字段,这些数据,都需要转为一个一个向量。alias更是需要转位多个向量。
按上图为例子,一条元数据内容,可能会转位多个向量点。之所以建立这么多检索目标,就是为了问题能被检索到
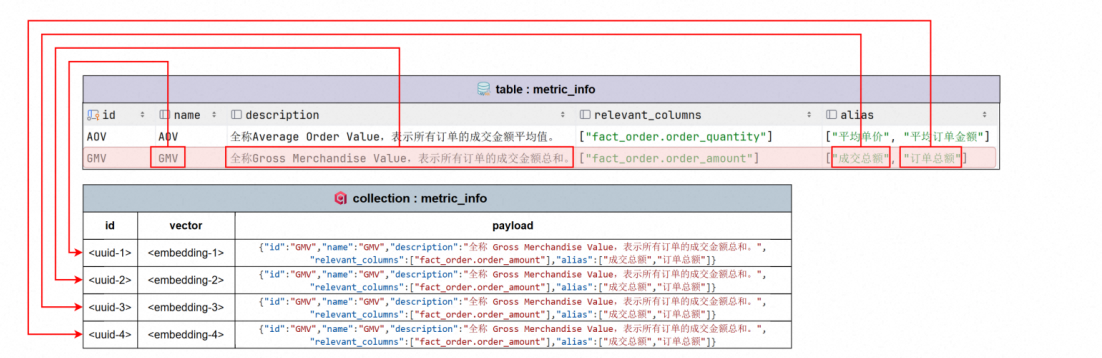
指标元数据,我们要对name,description,alias进行向量索引,跟column_info类似。
对数仓的维度建立全文检索
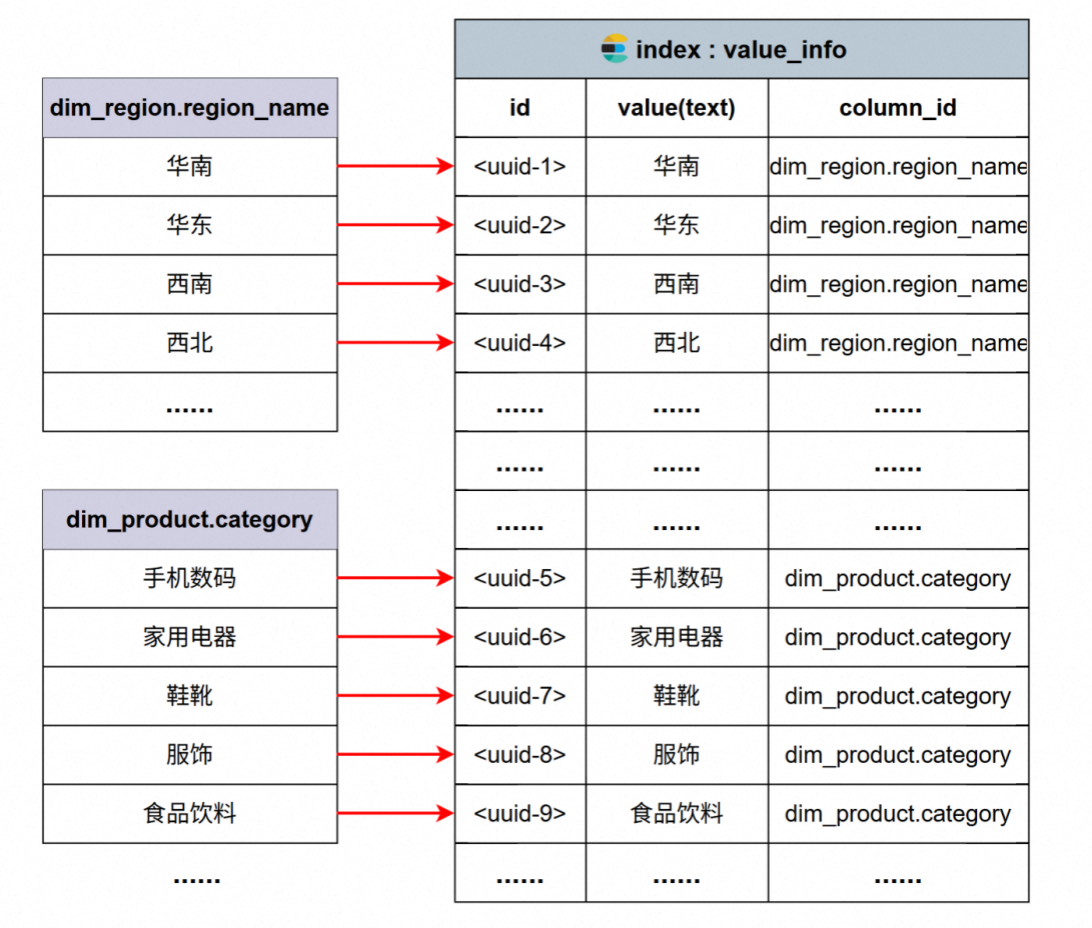
全文索引主要用于对字段取值进行检索与匹配,建立全文索引的主要是数据仓库中的各种维度表中的维度字段
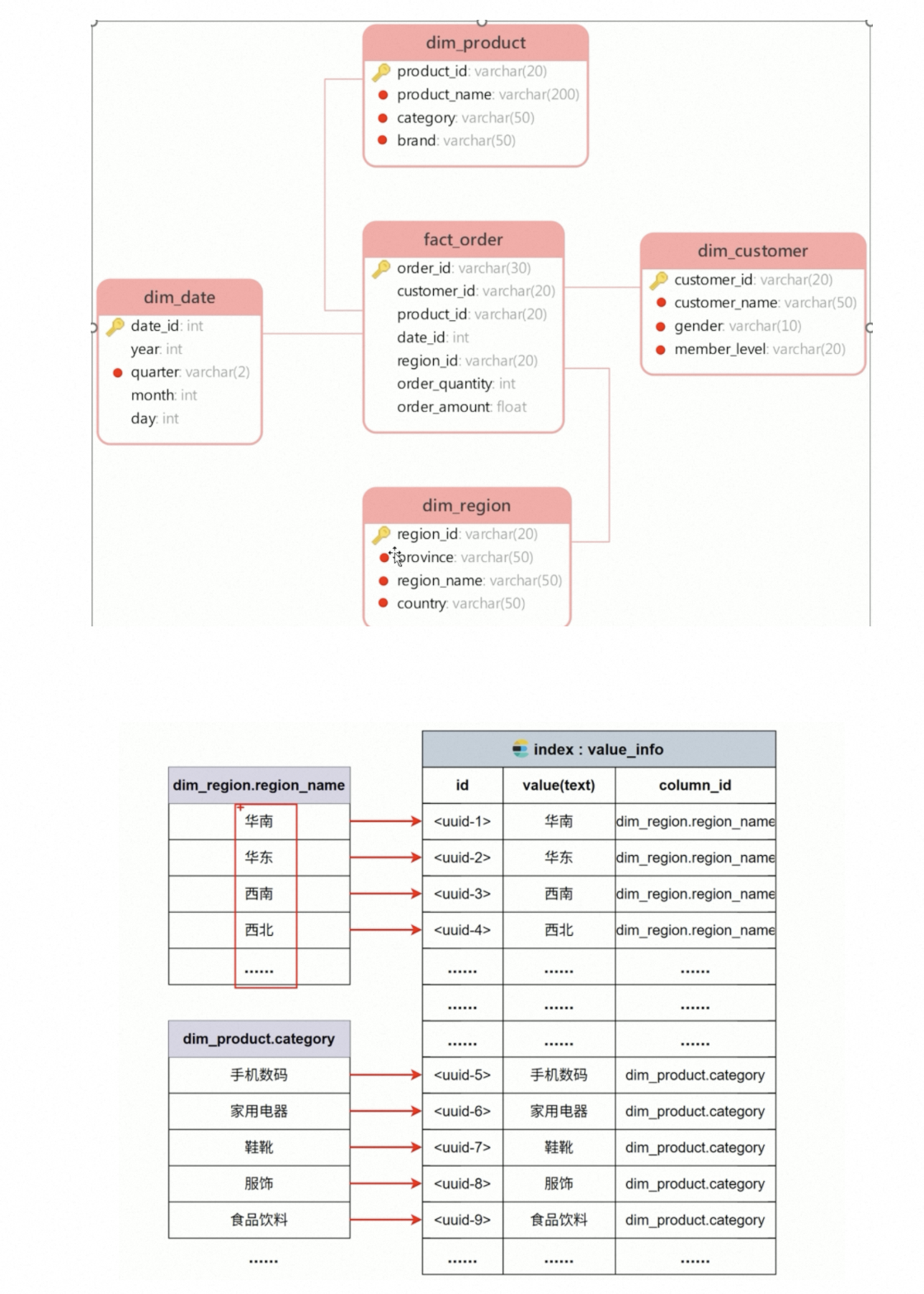
如上,对华南的数据进行全文检索,这里的index暂时存放三个数据,id,value(索引/分词的目标),column_id:索引到的话,可以通过该值从数据库中找到对应的数据。
比如对dim_regoin的地区维度表进行全文检索,首先要拿到p ro vince的所有数据,然后遍历依次建立索引。将所有维度值建立索引即完成。
问题
为什么不能直接对数仓的"数据"建立向量索引?
进行向量索引是对列信息进行向量索引
-
因为数据量级不对等 ,且对大模型写 SQL 毫无帮助。
-
向量化成本是天文数字: 数据仓库(DW)里存放的是海量的业务明细数据(例如几亿条订单、几十亿条用户行为日志)。 如果直接对数仓里的每一行数据(比如每一个用户的名字、每一条订单的备注)建立向量索引,你需要把这几十亿条文本全部送给大模型的 Embedding 模型去转换成向量。这会消耗极其庞大的算力和 API 成本,并且每次数仓有新数据写入(每秒都在发生),你都要实时更新向量库,这在工程上是不可接受的灾难。
-
大模型写 SQL 不需要看所有明细数据: 大模型(智能体)的任务是**"把人类的自然语言翻译成 SQL 语句"。 为了写出
SELECT SUM(amount) FROM order_table WHERE city = 'Beijing'这句 SQL,大模型只需要知道**:- 库里有一张表叫
order_table - 这张表里有个金额字段叫
amount - 有个城市字段叫
city
大模型根本不需要知道
order_table里的第 1500 万行数据到底是谁买的什么东西。因此,对海量明细数据做向量索引,对于生成 SQL 没有任何意义。 - 库里有一张表叫
-
为什么必须先同步到一个"元数据库"?
既然不能查明细数据,那直接让大模型去查数仓的**表结构(Schema / Information_schema)**不就行了吗?为什么还要单独建一个 MySQL 的元数据库?
- 语义鸿沟 (Semantic Gap)
- **数仓的底层字段名,大模型根本看不懂:**在真实的业务数仓中,为了规范或者历史遗留原因,表名和字段名往往是极其晦涩的英文缩写。
- 元数据库是用来"加备注(贴标签)"的:我们之所以需要一个元数据库(MySQL),就是为了提供一个中间的业务语义层 。
- 同步脚本会先去数仓把表结构(表名、列名、数据类型)拉过来。
- 然后,数据管理员(或业务专家)会在元数据库里手动(或半自动)补充丰富的业务描述。
- 他们会在元数据库的
column_info表里写上:字段名: usr_actv_flg,中文描述: 用户是否活跃,取值范围: 1代表活跃,0代表不活跃。
- **提供业务指标(Metric)的栖息地:**数仓里没有指标公式,只有基础数据 。像"复购率"、"转化率"这种复杂的业务计算逻辑,必须存放在元数据库的
metric_info表里。数仓的结构里是装不下这些业务公式的。
打个比方,数据仓库就是整个图书馆所有的书,而元数据库就是图书卡的索引目录,向量索引是对索引目录进行操作还是对每一本书进行操作,可想而知。
大模型就像是图书馆管理员,他不知道每本书的具体内容。
代码实现
同步脚本
python
import asyncio
from argparse import ArgumentParser
from pathlib import Path
from app.clients.embedding_client_manager import embedding_client_manager
from app.clients.es_client_manager import es_client_manager
from app.clients.mysql_client_manager import dw_mysql_client_manager, meta_mysql_client_manager
from app.clients.qrant_client_manager import qdrant_client_manager
from app.repositories.mysql.dw.dw_mysql_respository import DwMySQLRepository
from app.repositories.mysql.meta.meta_mysql_respository import MetaMySQLRepository
from app.service.meta_konwledge_service import MetaKnownLedgeService
# 架构层:services处理业务逻辑,respoistory层处理数据库的真实交互
def _init():
# 初始化
dw_mysql_client_manager.init()
meta_mysql_client_manager.init()
qdrant_client_manager.init()
embedding_client_manager.init()
es_client_manager.init()
async def _close():
await dw_mysql_client_manager.close()
await meta_mysql_client_manager.close()
await qdrant_client_manager.close()
await es_client_manager.close()
async def build(config_path: Path):
_init()
# 初始化repository
async with(meta_mysql_client_manager.session_factory() as meta_session, dw_mysql_client_manager.session_factory() as dw_session):
meta_mysql_repository = MetaMySQLRepository(meta_session)
dw_mysql_repository = DwMySQLRepository(dw_session)
# 构建同步service层
meta_knowledge_service = MetaKnownLedgeService(meta_mysql_repository=meta_mysql_repository, dw_mysql_repository=dw_mysql_repository)
# 构建元知识库
await meta_knowledge_service.build(config_path)
await _close()
if __name__ == '__main__':
parser = ArgumentParser()
# 增加options
parser.add_argument('-c', '--conf')
args = parser.parse_args()
# 将传入的conf解析成Path对象
config_path = Path(args.conf)
asyncio.run(build(config_path))同步表配置信息到元数据库
sqlalcehmy操作数据库得先定义model,以table_info为例子
python
from sqlalchemy.orm import DeclarativeBase
class Base(DeclarativeBase):
pass
from sqlalchemy import String, Text
from sqlalchemy.orm import Mapped, mapped_column
from app.models.base import Base
# 定义orm类,操作对象
class TableInfoMySQL(Base):
__tablename__ = "table_info"
id: Mapped[str] = mapped_column(
String(64),
primary_key=True,
comment="表编号"
)
name: Mapped[str | None] = mapped_column(
String(128),
comment="表名称"
)
role: Mapped[str | None] = mapped_column(
String(32),
comment="表类型(fact/dim)"
)
description: Mapped[str | None] = mapped_column(
Text,
comment="表描述"
)然后通过session去操作。
由于我们写业务逻辑的时候不想要实际操作TableInfoMySQL对象,因为以后如果不用mysql,其他地方也要改,所以我们定义一个entities模块,存放着我们的业务对象。
python
# /entities/table_info.py
from dataclasses import dataclass
@dataclass
class TableInfo:
id: str
name: str
role: str
description: str业务逻辑统一操作该类型,然后需要操作数据库的时候,我们通过mapper转换一下即可。
python
from dataclasses import asdict
from app.entities.table_info import TableInfo
from app.models.table_info_mysql import TableInfoMySQL
class TableInfoMapper:
@staticmethod
def to_entity(table_info_mysql: TableInfoMySQL) -> TableInfo:
return TableInfo(
id=table_info_mysql.id,
name=table_info_mysql.name,
role=table_info_mysql.role,
description=table_info_mysql.description
)
@staticmethod
def to_model(table_info: TableInfo) -> TableInfoMySQL:
return TableInfoMySQL(**asdict(table_info))如图,对TableInfo和TableInfoMysql的操作封装成一个类
接着再封装真正操作数据库的repository层
所有的数据库操作由这一层进行处理
python
from typing import List
from sqlalchemy.ext.asyncio import AsyncSession
from app.entities.table_info import TableInfo
from app.repositories.mysql.meta.mappers.table_info_mapper import TableInfoMapper
# 操作数据库层
class MetaMySQLRepository:
def __init__(self, session: AsyncSession):
self.session = session
async def save_table_infos(self, table_infos: List[TableInfo]):
# 需要将普通对象转位TableInfoMysql(model)类型
models = [TableInfoMapper.to_model(table_info) for table_info in table_infos]
self.session.add_all(models)如上,将TableInfo数组转位TableInfoMysql数组,然后才去加到数据库中。
这样就可以将数据库层逻辑跟业务层抽离开来。
看下我们的service层
python
class MetaKnownLedgeService:
def __init__(self, meta_mysql_repository: MetaMySQLRepository, dw_mysql_repository: DwMySQLRepository):
self.meta_mysql_repository = meta_mysql_repository
self.dw_mysql_repository = dw_mysql_repository
async def build(self, config_path: Path):
logger.info(f"config_path== {config_path}")
# 1 读取配置字段,同步表信息到元数据库
logger.info("开始读取配置字段,同步表信息到元数据库")
context = OmegaConf.load(config_path) # 读取配置信息
schema = OmegaConf.structured(MetaConfig) # 读取配置信息字段类型
meta_config: MetaConfig = OmegaConf.to_object(OmegaConf.merge(schema, context)) # 合并
# 2 对元数据库的数据进行向量索引
if meta_config.tables:
await self._save_tables_to_meta_db(meta_config)
logger.info("表信息已成功同步到元数据库")
# 3 对数仓的维度字段进行全文索引
# 3 读取配置字段,同步指标信息
# 4 对指标数据进行向量索引
pass
async def _save_tables_to_meta_db(self, meta_config: MetaConfig)-> list[ColumnInfo]:
# 收集表数据
table_infos: List[TableInfo] = []
column_infos: List[ColumnInfo] = []
for table in meta_config.tables:
table_infos.append(TableInfo(
id=table.name,
name=table.name,
role=table.role,
description=table.description,
))
# 查询该表格所有字段的类型
column_types = await self.dw_mysql_repository.get_column_types(table.name)
# {'region_id': 'varchar(20)', 'province': 'varchar(50)', 'region_name': 'varchar(50)', 'country': 'varchar(50)'}
for column in table.columns:
column_values = await self.dw_mysql_repository.get_column_values(table_name=table.name, column_name=column.name, limit=10)
column_infos.append(ColumnInfo(
id=f"{table.name}.{column.name}",
name=column.name,
# 类型待查
type=column_types["column.name"],
role=column.role,
alias=column.alias,
table_id=table.name,
description=column.description,
examples=column_values,
))
# 将数据插入元数据库中,使用with begin写法,会自动俘获报错,并且自动commit,自动事事务管理,两个操作在同一个事务里,任意一个抛异常都会自动rollback
async with self.meta_mysql_repository.session.begin():
await self.meta_mysql_repository.save_table_infos(table_infos)
await self.meta_mysql_repository.save_column_infos(column_infos)
return column_infos首先读取配置信息
遍历表,将表信息落库,然后落库列信息的时候,需要先查询列的类型,以及查询前10条数据,作为例子。注意,这里操作我们使用的是TableInfo和ColumnInfo,是eintties的对象,并不是实际操作的TableInfoMysql的model类型,将其解耦。
对列信息进行向量索引
向量索引使用qdrant操作,回温一下:collection集合,类似于表,point,类似于一行数据,
我们主要对每一个column进行向量索引。
首先我们需要一个qdrant的repository
python
class ColumnQdrantRepository:
collection_name: str = "data-agent-column"
def __init__(self, client: AsyncQdrantClient):
self.client = client
async def ensure_collection(self):
if not await self.client.collection_exists(self.collection_name):
await self.client.create_collection(self.collection_name,
vectors_config=VectorParams(size=app_config.qdrant.embedding_size,
# 使用余弦相似度
distance=Distance.COSINE))
async def upsert(self, ids: List[str], embeddings: List[List[float]], payloads: List[ColumnInfo],
batch_size: int = 20):
# zip会根据顺序将三者整合到一起,转成元祖的数组
zipped = list(zip(ids, embeddings, payloads))
# 批量操作
for i in range(0, len(zipped), batch_size):
batch = zipped[i:i + batch_size]
# 需要将其包装成 PointStruct,payload默认是ColumnInfo对象,不是普通字典,qdrant需要的是普通字典
batch_points = [PointStruct(id=id, vector=embedding, payload=asdict(payload)) for id, embedding, payload in
batch]
# 真正落到向量数据库
await self.client.upsert(collection_name=self.collection_name, points=batch_points)如上,upsert就是主要用来将数据插入到数据库的。
再看怎么将列数据转为向量
python
async def _save_column_info_to_qdrant(self, column_infos: List[ColumnInfo]):
# 确保column_info的collections存在
await self.column_qdrant_repository.ensure_collection()
# 构建待转为向量的数据
points: List[dict] = []
for column_info in column_infos:
# 转换三个字段,name,alias,description
points.append({
"id": uuid.uuid4(),
# 待转换为向量的text
"embedding_text": column_info.name,
"payload": column_info
})
points.append({
"id": uuid.uuid4(),
"embedding_text": column_info.description,
"payload": column_info
})
for alia in column_info.alias:
points.append({
"id": uuid.uuid4(),
"embedding_text": alia,
"payload": column_info
})
# 向量列表
embedding_texts = [point["embedding_text"] for point in points]
embedding_batch_size = 10 # 批量向量化限制
embeddings = []
for i in range(0, len(embedding_texts), embedding_batch_size):
batch_embedding_texts = embedding_texts[i:i + embedding_batch_size]
# 转为向量
batch_embedding = await self.embedding_client.aembed_documents(batch_embedding_texts)
# 类似于js的push(...batch_embedding)
embeddings.extend(batch_embedding)
# id列表
ids = [point["id"] for point in points]
# payload
payloads = [point["payload"] for point in points]
# 按照顺序,将其重新组装 id embedding payload
await self.column_qdrant_repository.upsert(ids=ids, payloads=payloads, embeddings=embeddings)如上,遍历column_infos,然后将需要转位向量的数据提取出来,再批量将embedding_text转为真正的向量,然后拿到ids,embeddings和payloads,将其组合插入到数据库中。
效果:
对数仓的维度值建立es全文检索
es概念:index(类似于表/数据库), documets文档,ES中的最小数据单元,类似于mysql的一行数据,Field字段,文档中的属性,类似于每一列 column。
这里我们只需要定义id,value以及column.id就行了。
涉及到将数据落到es集群上,也需要repository。
python
from dataclasses import asdict
from typing import List
from elasticsearch import AsyncElasticsearch
from app.entities.value_info import ValueInfo
class ValueEsRepository:
index_name = "data-agent-es-value-index"
# 定义mapping
index_mapping = {
# 禁止自动mapping
"dynamic": False,
"properties": {
"id": {"type": "keyword"},
"value": {"type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_max_word"},
"column_id": {"type": "keyword"}
}
}
def __init__(self, client: AsyncElasticsearch):
self.client = client
# 确保index已创建
async def ensure_index(self):
if not await self.client.indices.exists(self.index_name):
await self.client.indices.create(index=self.index_name, mappings=self.index_mapping)
# 批量创建
async def index(self, value_info: List[ValueInfo], batch_size=20):
for i in range(0, len(value_info), batch_size):
batch_value = value_info[i:i + batch_size]
operations = []
for value_info in batch_value:
# 批量插入固定语法
operations.append({
"index", {
"_index": self.index_name,
"_id": value_info.id
}
})
# 只要字典
operations.append(asdict(value_info))
await self.client.bulk(operations=operations)创建index需要指定mapping,批量插入数据需要使用bluk,有固定的语法。
我们需要对"需要同步的列"的所有数据进行全文索引。
python
async def _save_value_info_to_es(self, meta_config: MetaConfig, column_infos: List[ColumnInfo]):
await self.value_es_repository.ensure_index()
# 获取需要同步取值的列
column2sync: dict[str, bool] = {}
for table in meta_config.tables:
for column in table.columns:
column2sync[f"{table.name}.{column.name}"] = column.sync # sync标识是否同步
# 构建value值的列表
value_infos: List[ValueInfo] = []
for column_info in column_infos:
sync = column2sync[column_info.id]
if sync:
# 先查询该列所有的值
table_name = column_info.table_id
column_name = column_info.name
values = await self.dw_mysql_repository.get_column_values(table_name, column_name, limit=10000)
current_value_infos = [
# 去重过的
ValueInfo(id=f"{column_info.id}.{value}", value=value, column_id=column_info.id)
for value in values
]
value_infos.extend(current_value_infos)
# 批量保存到es中
await self.value_es_repository.index(value_infos=value_infos)先取出配置信息中,sync为true的column,然后查表,得到该列的所有数据,再遍历,每一条数据都需要作为一个documents(文档),最后汇总得到所有的列的所有数据,批量插入,因为怕插入太多卡死,选择批量20条进行插入。
对指标数据进行同步元数据落库以及进行向量索引
同步数据库跟维度表/事实表类似
python
async def _save_metric_to_meta_db(self, meta_config: MetaConfig) -> list[MetricInfo]:
metric_infos: List[MetricInfo] = []
metric_column_infos: List[ColumnMetric] = []
for metric in meta_config.metrics:
metric_infos.append(MetricInfo(
name=metric.name,
id=metric.name,
description=metric.description,
alias=metric.alias,
relevant_columns=metric.relevant_columns,
))
for column in metric.relevant_columns:
metric_column_infos.append(ColumnMetric(
column_id=column,
metric_id=metric.name
))
async with self.meta_mysql_repository.session.begin():
await self.meta_mysql_repository.save_metric_infos(metric_infos=metric_infos)
await self.meta_mysql_repository.save_column_metric_infos(column_metric_infos=metric_column_infos)对指标数据进行向量索引
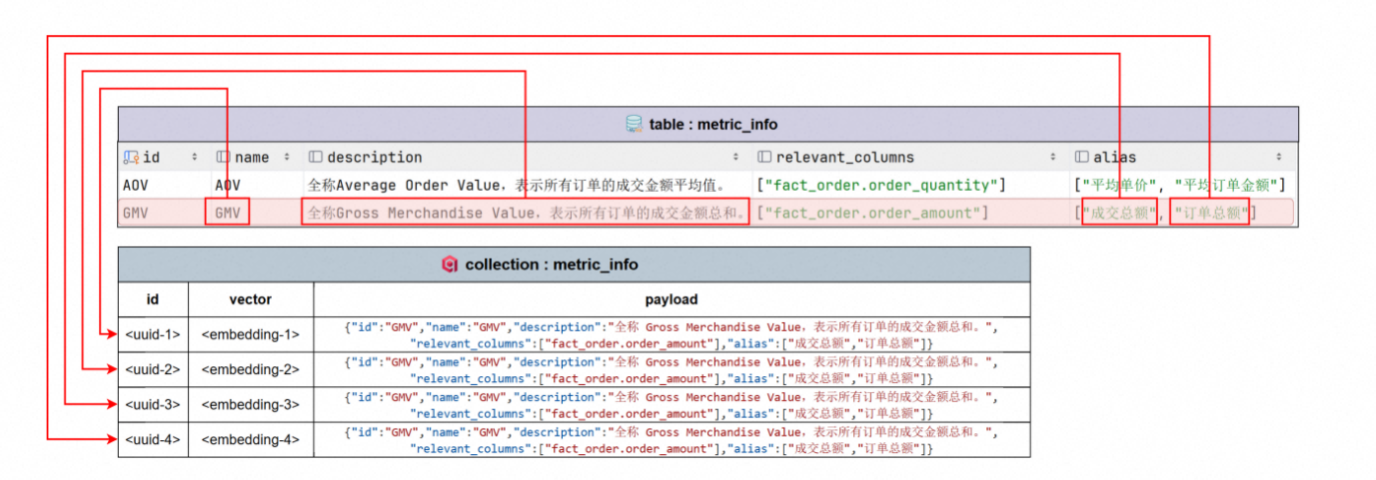
我们需要对每行数据的name,description,alias做索引。
python
async def _save_metric_info_to_qdrant(self, meta_config: MetaConfig, metric_infos: List[MetricInfo]):
await self.metric_qdrant_repository.ensure_collection()
points: List[dict] = []
for metric_info in metric_infos:
points.append({
"id": uuid.uuid4(),
"embedding_text": metric_info.name,
"payload": metric_info
})
points.append({
"id": uuid.uuid4(),
"embedding_text": metric_info.description,
"payload": metric_info
})
for alias in metric_info.alias:
points.append({
"id": uuid.uuid4(),
"embedding_text": alias,
"payload": metric_info
})
# 批量向量化
embedding_texts = []
batch_embedding_size = 20
embeddings = []
for point in points:
embedding_texts.append(point["embedding_text"])
for i in range(0, len(embedding_texts), batch_embedding_size):
batch_embedding_texts = embedding_texts[i:i + batch_embedding_size]
embeddings.extend(await self.embedding_client.aembed_documents(batch_embedding_texts))
await self.metric_qdrant_repository.upsert(ids=[point["id"] for point in points], embeddings=embeddings,
payloads=[point["payload"] for point in points])跟column做向量索引类似,取到所有数据,然后转成point,存储到qdrant中。
mysql优化
以table_info为例子
python
async def save_table_infos(self, table_infos: List[TableInfo]):
# 转为字典对象
rows = [asdict(t) for t in table_infos]
# 指定往 metric_info 表插入 - .values(rows) --- 把整个列表作为批量数据,生成一条多行 INSERT:
stmt = mysql_insert(TableInfoMySQL).values(rows)
# 追加冲突时的更新逻辑
# stmt.inserted 是 SQLAlchemy 提供的特殊对象,对应 MySQL 中的 VALUES(字段名) 函数
stmt = stmt.on_duplicate_key_update(
name=stmt.inserted.name,
role=stmt.inserted.role,
description=stmt.inserted.description,
)
await self.session.execute(stmt)之前用的是session.add_all,如果第二次运行会报错,主键重复。这里使用insert语句
sql
INSERT INTO table_info (id, name, role, description)
VALUES ('dim_region.region_id', 'region_id', 'varchar(20)', '地区唯一标识')
ON DUPLICATE KEY UPDATE
name = VALUES(name),
type = VALUES(type),
description = VALUES(description);批量插入,然后当主键存在的时候,只更新对应的name, role, description
es我们使用index作为批量插入,如果遇到id存在的,会覆盖。
运行之后:
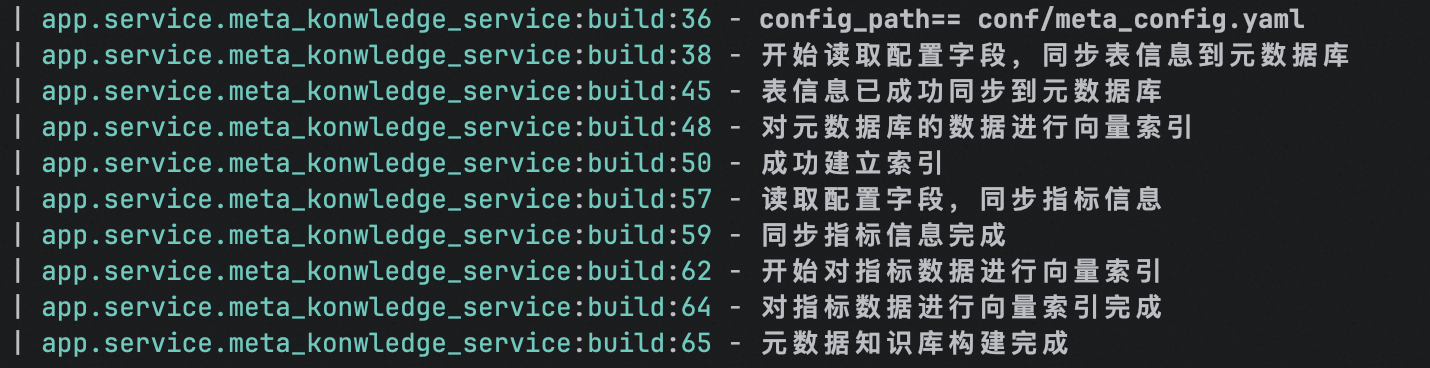
qdrant:
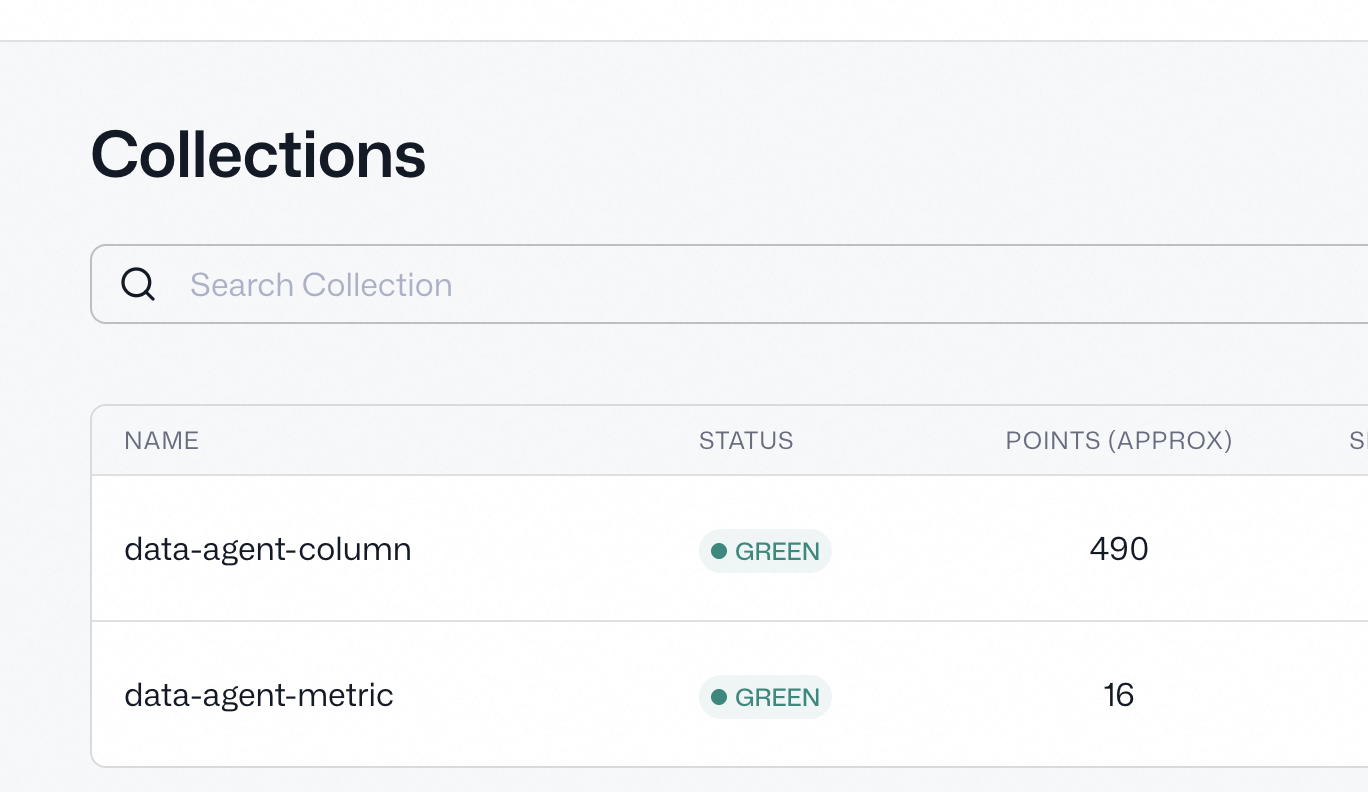
es:

mysql:
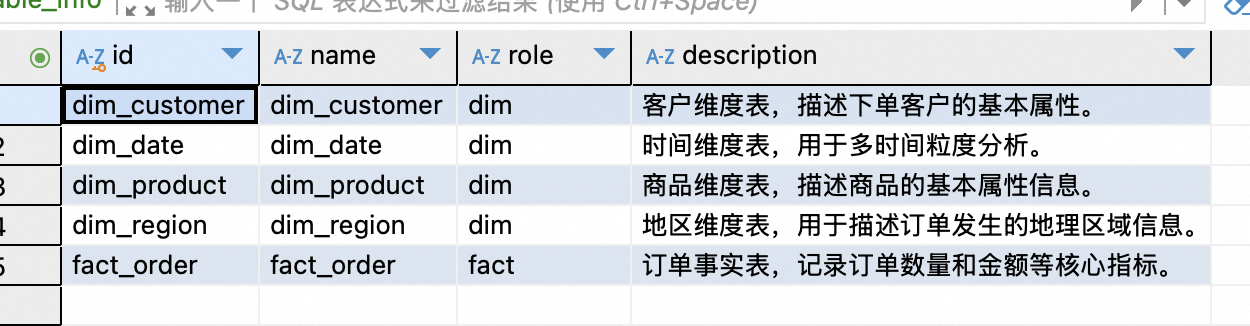
数据已经正常同步