【系统架构级】电商自动化系统搭建:OCR + 自动上架完整解决方案(从0到1落地)
当你从"做几个商品"走向"批量做商品"时,会遇到一个瓶颈:
👉 人力不够,效率跟不上
典型表现:
-
上架慢(一天几十个)
-
信息整理混乱
-
无法规模化
👉 解决方案只有一个:
👉 搭建电商自动化系统
🚀 一句话核心架构
👉 OCR识别 + 图片处理 + 自动上架 + 数据系统 = 完整电商自动化
一、系统整体架构(核心)
🏗 标准架构如下:
商品数据源(1688 / 淘宝 / AliExpress)
↓
图片采集模块
↓
图片处理(去水印 / 高清化)
↓
OCR识别模块
↓
数据解析模块
↓
商品生成模块
↓
自动上架模块
↓
电商平台(Shopee / Amazon / 拼多多)👉 👉 这是一套"可规模化赚钱"的系统
二、模块拆解(重点)
1️⃣ 图片采集模块
👉 功能:
-
批量抓取商品图片
-
支持URL / 爬虫
2️⃣ 图片处理模块(关键)
👉 包括:
-
去水印
-
图片高清化
👉 为什么重要?
👉 直接影响 OCR 准确率
👉 参考:
3️⃣ OCR识别模块(核心)
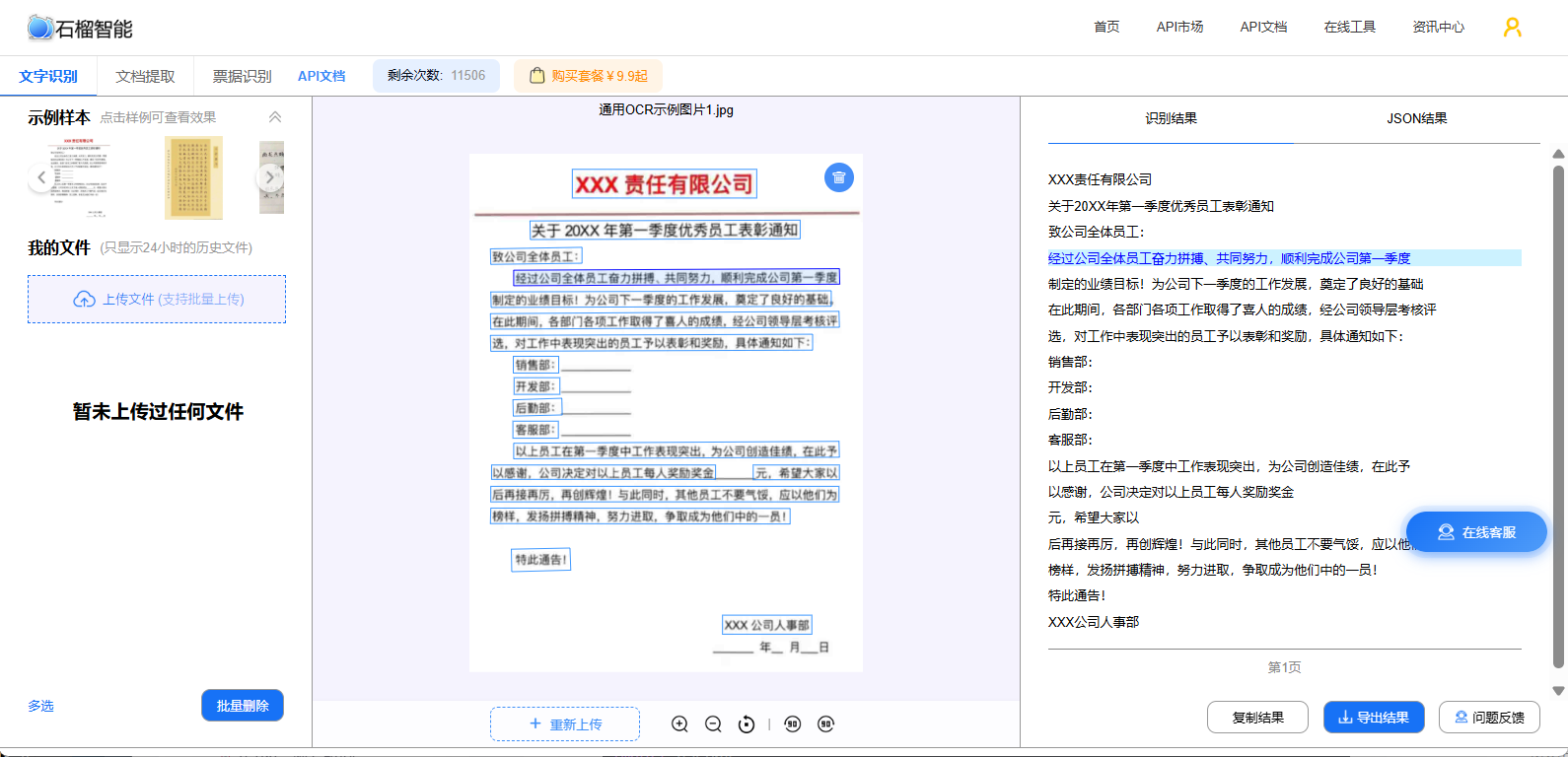
👉 提取:
-
商品标题
-
参数信息
-
标签
👉 示例代码:
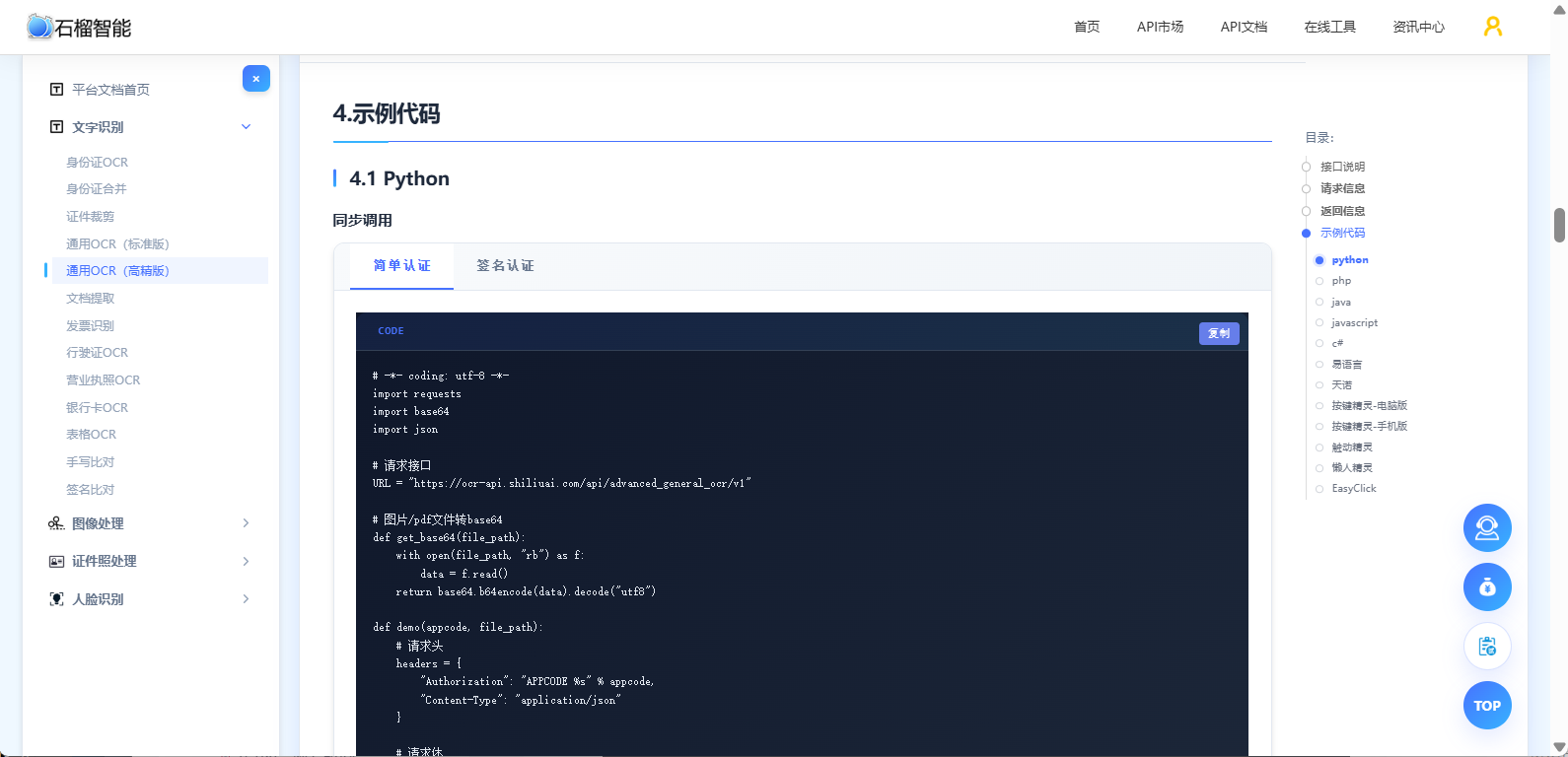
python
#文字识别OCR文档:https://market.shiliuai.com/doc/advanced-general-ocr
# -*- coding: utf-8 -*-
import requests
import base64
import json
# 请求接口
URL = "https://ocr-api.shiliuai.com/api/advanced_general_ocr/v1"
# 图片/pdf文件转base64
def get_base64(file_path):
with open(file_path, "rb") as f:
data = f.read()
return base64.b64encode(data).decode("utf8")
def demo(appcode, file_path):
# 请求头
headers = {
"Authorization": "APPCODE %s" % appcode,
"Content-Type": "application/json"
}
# 请求体
b64 = get_base64(file_path)
data = {"file_base64": b64}
# 请求
response = requests.post(url=URL, headers=headers, json=data)
content = json.loads(response.content)
print(content)
if __name__ == "__main__":
appcode = "你的APPCODE"
file_path = "本地文件路径"
demo(appcode, file_path)4️⃣ 数据解析模块
👉 将OCR结果转为结构化数据:
python
文字识别OCR文档:https://market.shiliuai.com/doc/advanced-general-ocr
成功示例:
{
'code': 200,
'msg': 'OK',
'msg_cn': '成功',
'success': True,
'file_id': file id,
'request_id': request id,
'data': data, 具体看下面
}
data = {
"page_count": 5, // int, 文件页面总数
"process_pages": 3, // int, 处理页面数
"status": 2, // int, 处理状态,0: 已加入队列, 1: 正在处理中, 2: 已完成,同步时此值为2
"wait_time": 0.0 // float, 大概还需等待时间,同步时此值为0
// 如果status==2:
"pages": [
{
"width": 2000, // int, 页面宽度
"height": 2500, // int, 页面高度
"prob_mean": 0.98, // float, [0, 1], 页面文字置信度平均值,若is_line,则不返回该项
"prob_std": 0.11, // float, 页面文字置信度标准差,若is_line,则不返回该项
"lines": [
{
"text": "你好", // string, 文字内容
"prob": 0.995, // float, [0, 1], 文字内容置信度
"keypoints": [[50, 20], [150, 20], [150, 60], [50, 60]] // list, [[xi, yi]], 文字区域角点位置,以左上角为起点,按顺时针排列;若is_line,则不返回该项
},
......
]
},
......,
]
}5️⃣ 商品生成模块
👉 自动生成:
-
商品标题
-
描述
-
SKU
6️⃣ 自动上架模块(核心变现)
👉 实现方式:
👉 👉 实现无人操作
三、系统数据流(重点)
图片 → OCR → 文本 → 结构化数据 → 商品信息 → 上架👉 👉 数据是核心资产
四、性能优化(企业级重点)
🚀 优化1:并发处理
from concurrent.futures import ThreadPoolExecutor👉 批量处理能力提升 3~5倍
🚀 优化2:任务队列
👉 使用:
-
Redis
-
RabbitMQ
👉 解耦系统,提高稳定性
🚀 优化3:缓存机制
👉 避免重复识别
🚀 优化4:失败重试机制
👉 提高成功率
五、成本与收益模型(关键)
💰 成本:
-
OCR API:低
-
服务器:低
💰 收益:
👉 自动化后:
-
日处理 1000+ 商品
-
可持续放大
👉 👉 ROI 极高
六、企业级升级(进阶)
🏢 可扩展方向:
🔥 1:多平台支持
-
Amazon
-
Shopee
-
Lazada
🔥 2:多语言系统
👉 OCR + 翻译
🔥 3:数据分析系统
👉 分析:
-
热卖商品
-
转化率
🔥 4:AI优化标题
👉 提升点击率
七、常见架构错误(避坑)
❌ 错误1:直接OCR不做预处理
👉 准确率低
❌ 错误2:无队列设计
👉 系统崩溃
❌ 错误3:手动上架
👉 无法规模化
八、总结(架构核心)
👉 电商自动化系统本质是:
👉 数据流 + 自动化执行
👉 而 OCR:
👉 是整个系统的"入口能力"
🎯 补充
👉 如果你要快速搭建这套系统:
👉 推荐直接使用:
👉 https://market.shiliuai.com/general-ocr
✔ 支持高并发
✔ 多语言识别
✔ 完整API文档
✔ 支持免费在线测试效果,API文档清晰,提供各语言与自动化接入脚本示例
📚 延伸阅读
💡 最后一段
👉 当别人还在手动上架时,
👉 你已经在"跑系统"。
👉 电商的终局不是选品,而是:
👉 系统化运营能力。
👉 谁先完成系统化,谁就拥有规模优势。
#系统架构 #电商自动化 #OCR识别 #API接口 #自动化系统 #跨境电商